
Java集合
集合概述
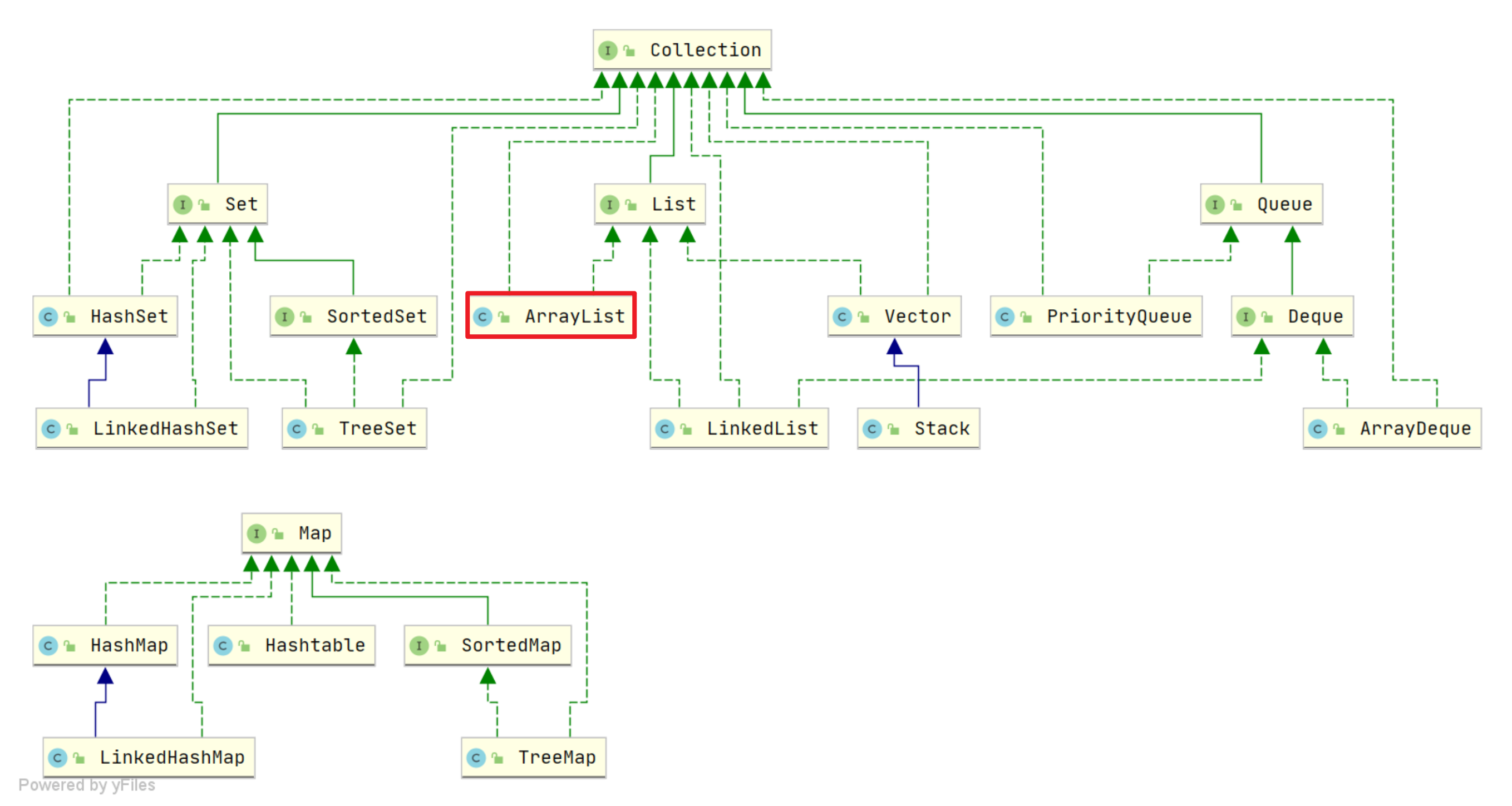
两大接口:
- Collection:用于存放单一元素
- List
- Set
- Queue
- Map:用于存放键值对
面试题
说说 List, Set, Queue, Map 四者的区别?
| 类型 | 特点 |
|---|---|
| List | 元素有序、可重复 |
| Set | 元素不可重复 |
| Queue | 元素有序、可重复 |
| Map | 存储键值对,K无序不可重复,V无序可重复 |
List
- ArrayList
- LinkedList
- Vector
1. ArrayList
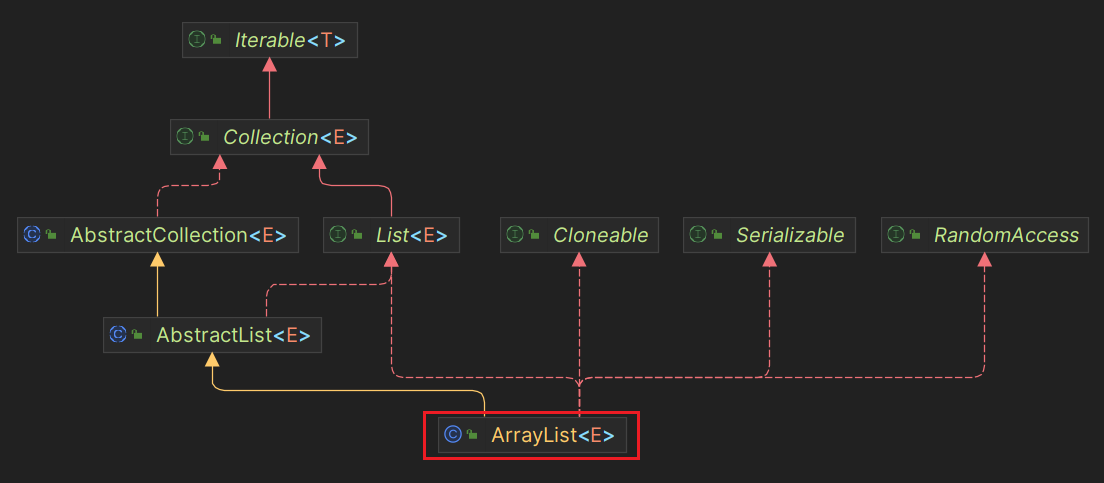
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
}
ArrayList继承于AbstractList,实现了List,RandomAccess,Cloneable,java.io.Serializable这些接口:
List:表明它是一个列表,可以通过下标进行访问,支持添加、删除、查找等操作;RandomAccess:标志接口,表明实现这个接口的List支持快速随机访问。在ArrayList中,我们可以通过元素的序号快速获取元素对象,这就是快速随机访问;Cloneable:表明可以拷贝,可以进行深拷贝或者浅拷贝;Serializable:可以进行序列化操作。可以将对象转换为字节流进行持久化存储或网络传输。
浅拷贝:元素本身不被复制。
如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),则拷贝的是内存地址,如果其中一个对象改变了地址,就会影响到另一个对象。
深拷贝:拷贝所有属性,并拷贝属性指向的动态分配的内存。
当对象和它所引用的对象一起拷贝时即发生深拷贝。相比于浅拷贝速度较慢且开销较大。
ArrayList底层是数组队列,相当于动态数组。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小。
add()方法的事件开销和插入位置有关,addAll()方法的时间开销和添加元素的个数成正比。size(),isEmpty(),get(),set()方法均能在常数时间内完成。
为追求效率,ArrayList没有实现同步,如果需要多个线程并发访问,用户可以手动同步,或者使用Vector替代。
1.1 部分源码
/**
* Default initial capacity.
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
* 用于空实例 的共享空数组实例。
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
* 用于默认大小的空实例的共享空数组实例。
* 我们将其与 EMPTY_ELEMENTDATA 区分开来,以了解添加第一个元素时要扩充多少。
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
1.2 三种构造函数
-
创建一个指定初始容量的
ArrayList,如果知道ArrayList可能会包含多少元素,使用这个构造函数能够提高性能,因为它能够避免不必要的内部数组扩展操作; -
创建一个空的
ArrayList; -
创建一个包含了集合
c中所有元素的ArrayList,这个构造函数的参数是一个集合,这个集合可以是任何实现了Collection接口的类,例如ArrayList、LinkedList、HashSet等。它允许你从一个现有的集合中创建一个新的ArrayList,将集合中的元素复制到新的ArrayList中。
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}
关于ArrayList中的两个静态常量数组(
EMPTY_ELEMENTDATA,DEFAULTCAPACITY_EMPTY_ELEMENTDATA),它们的区别是在数组扩容时发生的变化不同。我的理解是:
EMPTY_ELEMENTDATA:长度指定为0(或是一个空Collection)时被使用。在进行扩容时,会根据ArraysSupport.newLength(int oldLength, int minGrowth, int prefGrowth)方法确定新数组的长度(旧长度、最小增长值,首选增长值,满足最小增长的情况下选择首选增长值)。DEFAULTCAPACITY_EMPTY_ELEMENTDATA:调用空参构造器时被使用。在添加第一个元素时,长度变为10,超出10个元素后的每次扩容,长度会变为原来的1.5倍。
1.3 自动扩容机制
每当向数组中添加元素时,都要检查添加后元素的个数是否会超出当前数组的长度。如果超出,数组将会进行自动扩容,以满足添加数据的需求。
数组扩容通过一个公开的方法ensureCapacity(int minCapacity)来实现。在实际添加大量元素前,我们也可以使用ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数量。
以无参构造方法创建ArrayList时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才对其分配容量。向数组中添加第1个元素时,数组容量扩展为10。当添加第11个元素时,新数组的容量扩为15(扩容前数组的容量的1.5倍),并将这11个元素复制到长度为15的新数组中,后面的扩容以此类推。
部分源码
/**
* This helper method split out from add(E) to keep method
* bytecode size under 35 (the -XX:MaxInlineSize default value),
* which helps when add(E) is called in a C1-compiled loop.
*/
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
*
* @param index index at which the specified element is to be inserted
* @param element element to be inserted
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
rangeCheckForAdd(index);
modCount++;
final int s;
Object[] elementData;
if ((s = size) == (elementData = this.elementData).length)
elementData = grow();
System.arraycopy(elementData, index,
elementData, index + 1,
s - index);
elementData[index] = element;
size = s + 1;
}
// ......
/**
* Increases the capacity to ensure that it can hold at least the
* number of elements specified by the minimum capacity argument.
*
* @param minCapacity the desired minimum capacity
* @throws OutOfMemoryError if minCapacity is less than zero
*/
private Object[] grow(int minCapacity) {
int oldCapacity = elementData.length;
if (oldCapacity > 0 || elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
int newCapacity = ArraysSupport.newLength(oldCapacity,
minCapacity - oldCapacity, /* minimum growth */
oldCapacity >> 1 /* preferred growth */);
return elementData = Arrays.copyOf(elementData, newCapacity);
} else {
return elementData = new Object[Math.max(DEFAULT_CAPACITY, minCapacity)];
}
}
private Object[] grow() {
return grow(size + 1);
}
面试题
ArrayList和Array的区别?
ArrayList内部基于动态数组实现,比Array(静态数组)使用起来更加灵活:
| ArrayList | Array | |
|---|---|---|
| 长度 | 根据实际存储的元素动态地扩容或缩容 | 被创建后就不能改变它的长度了 |
| 类型安全 | 允许使用泛型来确保类型安全 | 不可以 |
| 存储的元素 | 只能存储对象,对于基本数据类型需要使用其对应的包装类 | 可以直接存储基本数据类型,也可以存储对象 |
| 相关操作 | 支持插入、删除、遍历等操作 | 长度固定,只能按照下标访问元素,不具备动态添加、删除元素的能力 |
| 被创建时 | 不需要指定大小 | 必须指定大小 |
ArrayList可以添加null值吗?
ArrayList可以存储任何类型的对象。包括null值。
不过不建议向ArrayList中添加null值,因为其毫无意义,会让代码难以维护(忘记做判断空处理从而导致空指针异常)。
ArrayList插入和删除元素的时间复杂度?
| 位置 | 插入 | 删除 |
|---|---|---|
| 头部 | 所有元素依次向后移动一个位置,O(n) | 所有元素依次向前移动一个位置,O(n) |
| 尾部 | 不需要扩容时,仅在数组末尾添加元素,O(1) 需要扩容时,先复制 O(n),再添加O(1) |
仅删除,O(1) |
| 指定位置 | 平均移动 n/2 个元素,O(n) | 平均移动 n/2 个元素,O(n) |
ArrayList的自动扩容机制。
详见 [1.3 自动扩容机制](##1.3 自动扩容机制)。
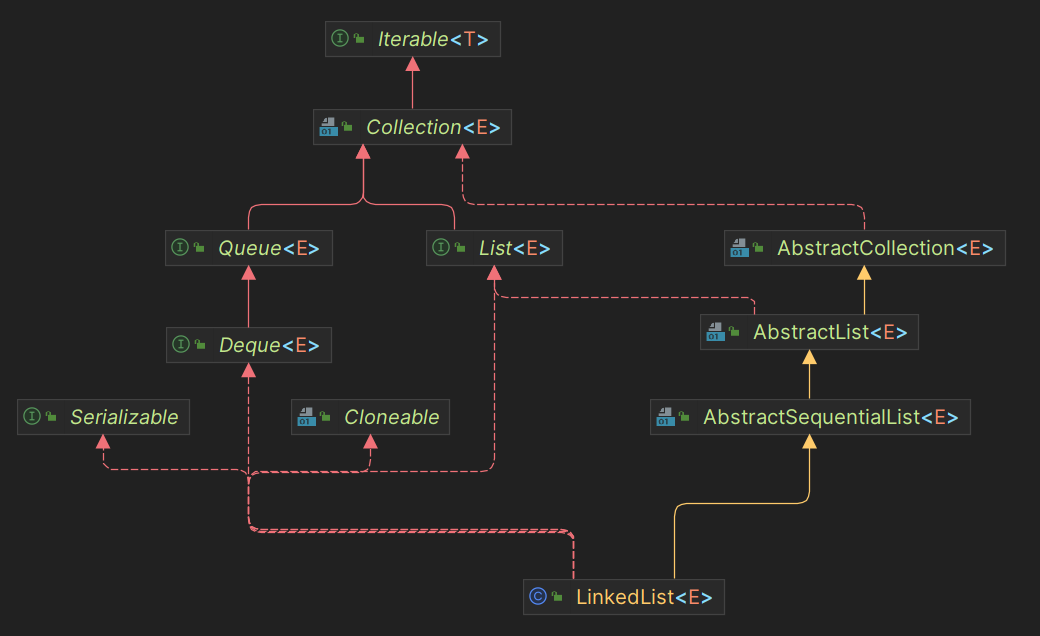
2. LinkedList
基于双向链表实现的集合类
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable{
//...
}
继承了AbstractSequentialList,而AbstractSequentialList继承于AbstractList,ArrayList 同样继承于AbstractList , 所以 LinkedList 会有大部分方法和 ArrayList 相似。
LinkedList实现了一下接口:
List:表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。Deque(读作[dɛk]):继承于Queue接口,具有双端队列的特性,支持从两端插入和删除元素,方便实现栈和队列等数据结构。Cloneable:具有拷贝能力,深拷贝或者浅拷贝。Serializable:能够进行序列化操作,可以将对象转化为字节流进行持久化存储或网络传输。
LinkedList中的元素是通过Node定义的:
private static class Node<E> {
E item;// 节点值
Node<E> next; // 指向的下一个节点(后继节点)
Node<E> prev; // 指向的前一个节点(前驱结点)
// 初始化参数顺序分别是:前驱结点、本身节点值、后继节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
初始化
构造函数:一个有参,一个无参:
- 有参构造函数:创建一个空的链表对象
- 无参构造函数:接受一个集合类型作为参数,创建一个于传入的集合具有相同元素的链表对象
public LinkedList(){
}
public LinkedList(Collection<> extends E> c){
this();
addAll(c);
}
常用方法
| 方法 | 作用 |
|---|---|
add(E e) |
尾部插入元素 |
add(int index, E element) |
指定位置插入元素 |
getFirst() |
获取第一个元素 |
getLast() |
获取最后一个元素 |
get(int index) |
获取指定位置元素 |
removeFirst() |
Remove the first element in LinkedList |
removeLast() |
Remove the last element in LinkedList |
remove(E e) |
删除首次出现的指定元素,如果不存在则返回false |
remove(int index) |
删除指定位置元素 |
void clear() |
删除此链表所有元素 |
面试题
LinkedList为什么不能实现RandomAccess接口?
RandomAccess是一个标记接口,用来表示实现该接口的类支持随机访问(通过索引快速访问元素)。LinkedList底层数据结构是链表,内存地址不连续,只能通过指针来定位,不支持随即快速访问,因此不能实现RanfomAccess接口。
LinkedList插入和删除元素的时间复杂度。
头尾:O(1)
指定位置:O(n/2)
ArrayList和LinkedList的区别?
| ArrayList | LinkedList | |
|---|---|---|
| 线程安全 | 不同步,不保证线程安全 | 不同步,不保证线程安全 |
| 底层数据结构 | Object数组 | 双向链表 |
| 插入和删除是否受元素位置的影响 | 有影响。采用数组存储,指定位置插入元素,在它之前或之后的元素都要移动一位 | 没有影响,采用链表存储,指定位置插入或删除元素需要先将指针移动到指定位置O(n) |
| 快速随机访问 | 支持,因为实现了RandomAccess接口 | 不支持,内存地址不连续 |
| 内存空间占用 | 对空间的浪费体现在:list列表的结尾会预留一定的容量空间 | 对空间的花费体现在:每一个元素都要比ArrayList中的元素消耗更多的空间(前驱、数据、后继) |
Set
- HashSet:无序、唯一。基于HashMap实现,底层采用HashMap来保存元素
- LinkedHashSet:LinkedHashSet是HashSet的子类,其内部通过LinkedHashMap来实现
- TreeSet:有序、唯一。红黑树(自平衡的排序二叉树)
HashSet
对HashMap的简单封装,对HashSet的方法调用都会转换为合适的HashMap方法。
面试题
HashSet如何检查重复?
根据hashcode值判断。
当你把对象加入HashSet时,HashSet 会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让加入操作成功。摘自 Head first Java 第二版:
/**
* Adds the specified element to this set if it is not already present.
* More formally, adds the specified element {@code e} to this set if
* this set contains no element {@code e2} such that
* {@code Objects.equals(e, e2)}.
* If this set already contains the element, the call leaves the set
* unchanged and returns {@code false}. 如果元素存在则保持hashSet不变并返回false
*
* @param e element to be added to this set
* @return {@code true} if this set did not already contain the specified
* element
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
Map
HashMap
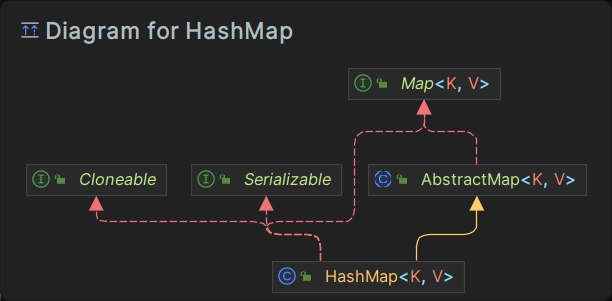
HashMap主要用来存放键值对,基于哈希表的Map接口实现,非线程安全。
HashMap中的元素实际上是对象,一些常见的基本类型可以使用它的包装类。
HashMap可以存储为null的key和value,但是null作为键只能有一个,作为值可以有多个。
JDK1.8之前HashMap由数组+链表组成,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法解决冲突”)。JDK1.8之后HashMap在解决哈希冲突时有了较大的变化,当链表长度>=阈值时(默认为8),将链表转化为红黑树,以减少搜索时间(将链表转换为红黑树前会判断,如果当前数组的长度小于64,那么会选择先进行数组扩容,而不是转换为红黑树)。
HashMap的默认初始化大小为16,之后每次扩容,容量变为原来的2倍,并且HashMap总是使用2的幂作为哈希表的大小。
HashMap通过key和hashCode经过扰动函数处理过后的到hash值,然后通过(n - 1) & hash 判断当前元素存放的位置(n指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入元素的hash值以及key是否相同,如果相同的话,直接覆盖,不相同就通过拉链发解决冲突。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// 如果key为null,则返回哈希值为0
// 如果key不为null,则将key的hashCode赋值给h,h 与 它无符号右移的32位二进制码 进行异或操作
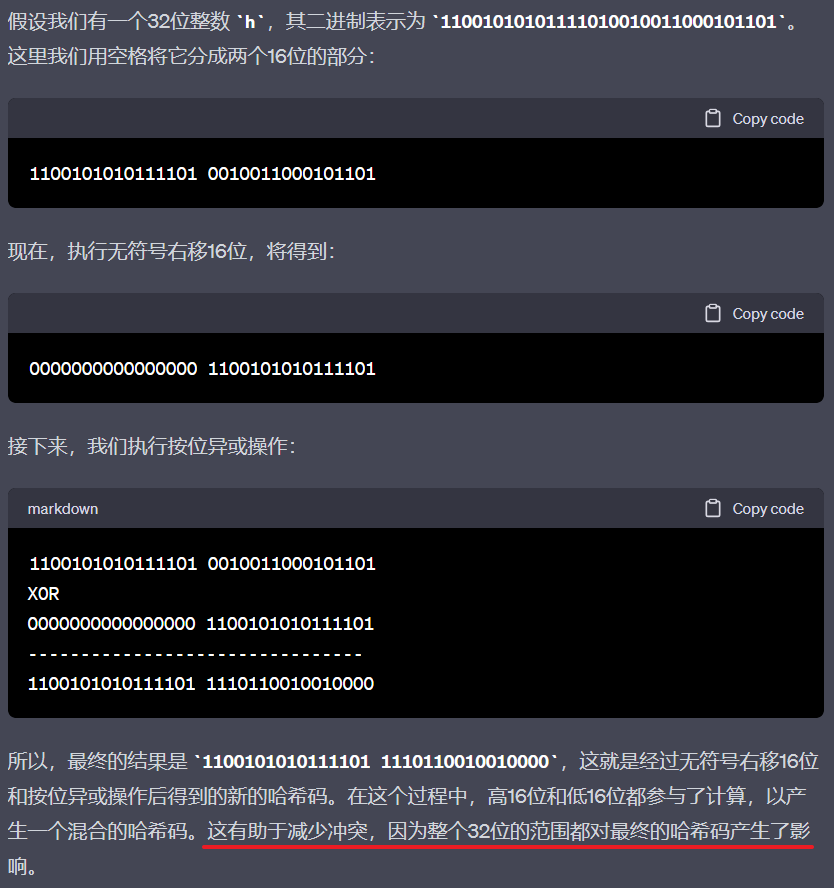
扰动函数就是HashMap的hash方法,使用hash方法是为了减少碰撞的概率。
位置的确定:
(n - 1) & hash是通过将数组长度减去1,然后与哈希码进行按位与(&)运算来确定元素在数组中的位置。这个操作的目的是确保计算结果在数组长度范围内,因为n - 1的二进制表示形式是所有位都为1,按位与操作可以保证结果不超过数组的长度。
JDK 1.8之后在解决哈希冲突时发生了较大的变化。
当链表长度大于阈值时(默认为8),会首先调用treeifyBin()方法。这个方法会根据HashMap数组来决定是否转换为红黑树。只有当数组长度>=64时,才会执行转换红黑树操作,以减少搜索时间。否则,就只是执行resize()方法对数组扩容(即使某个位置的链表长度大于8,但数组长度一直小于64,该位置的链表也不会转换为红黑树)。
loadFactor
负载因子,控制数组存放数据的疏密程度,默认为0.75,表示数组中存放的数据(entry)占数组长度的75%。
Node结点类
// 继承自 Map.Entry<K,V>
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// 哈希值,存放元素到hashmap中时用来与其他元素hash值比较
final K key;//键
V value;//值
// 指向下一个节点
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
// 重写hashCode()方法
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重写 equals() 方法
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
树结点类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // 父
TreeNode<K,V> left; // 左
TreeNode<K,V> right; // 右
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; // 判断颜色
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
// 返回根节点
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
构造方法
- 空参构造器;
- 包含另一个Map的构造器,将这个map的数据存放到新的Map中;
- 指定容量大小得构造函数;
- 指定容量大小和负载因子的构造函数
// 默认构造函数。
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
// 包含另一个“Map”的构造函数
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);//下面会分析到这个方法
}
// 指定“容量大小”的构造函数
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
// 指定“容量大小”和“负载因子”的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
this.loadFactor = loadFactor;
// 初始容量暂时存放到 threshold ,在resize中再赋值给 newCap 进行table初始化
this.threshold = tableSizeFor(initialCapacity);
}
get()
get()方法调用了getNode()方法。首先根据key计算hash值,得到对应的bucket下标,然后依次遍历链表,通过key.equals(k)方法判断要查询的结点
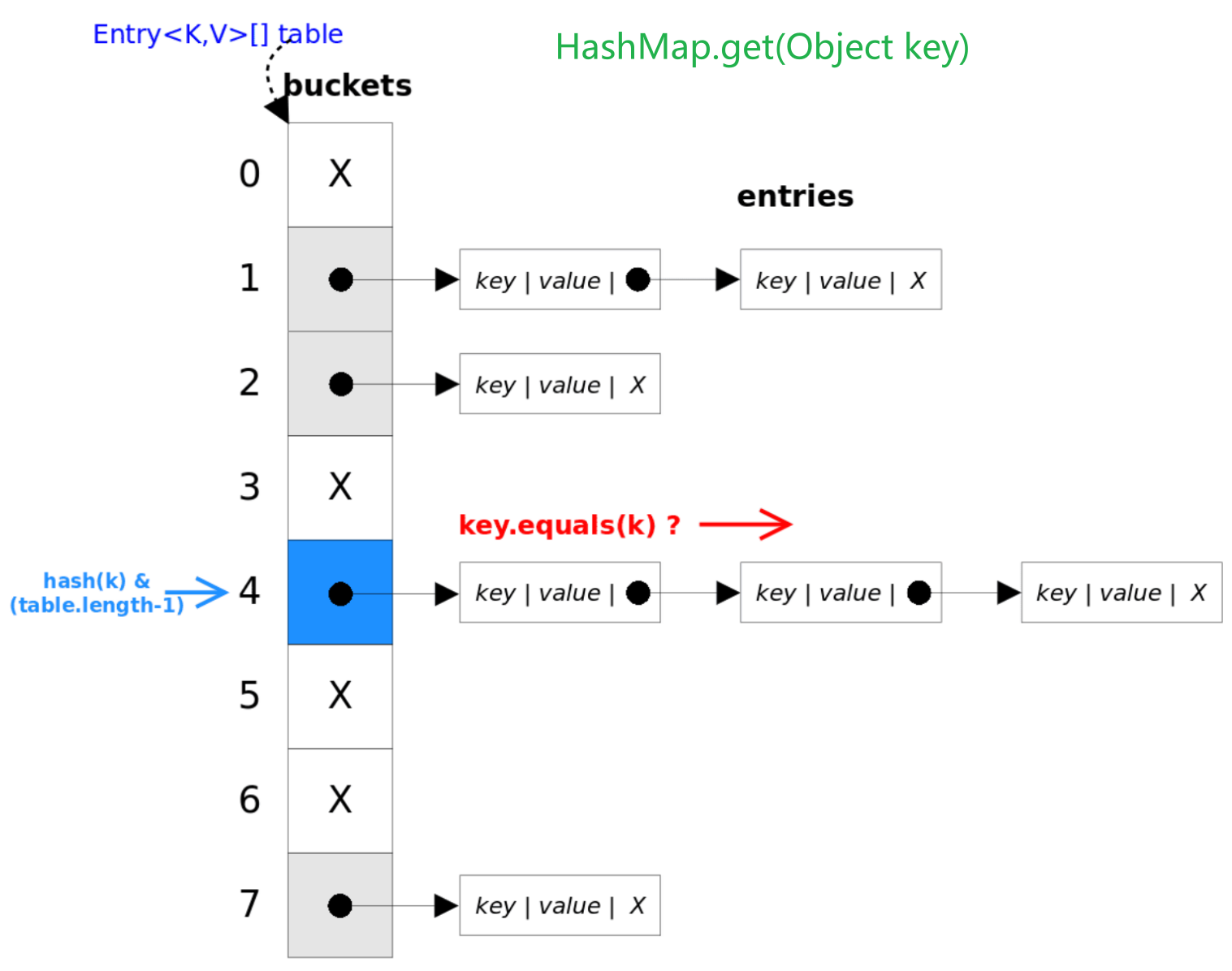
public V get(Object key) {
Node<K,V> e;
return (e = getNode(key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k;
if ((tab = table) != null && (n = tab.length) > 0 && // 首先是一系列非空判断
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
if (first.hash == hash && ((k = first.key) == key || (key != null && key.equals(k))))
return first; // 检查第一个节点
if ((e = first.next) != null) { // 检查后面的结点
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);// 转为树结点查询
do {
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e; // 链表还有元素的情况下查询结点
} while ((e = e.next) != null);
}
}
return null;
}
/*
(n - 1) & (hash = hash(key))
计算key的哈希值,并根据哈希值判断entry在哪个bucket中
*/
put() & putVal()
HashMap只给用户提供了put方法,其中调用了putVal方法。
putVal方法添加元素:
- 如果定位到的数组位置没有元素,就直接插入;
- 如果定位到的数组位置有元素,就和要插入的key进行比较:
- key相同直接覆盖
- key不相同,判断是否为一个树节点:
- 是,调用
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)方法添加元素 - 不是,就遍历链表,将元素插入到链表尾部
- 是,调用
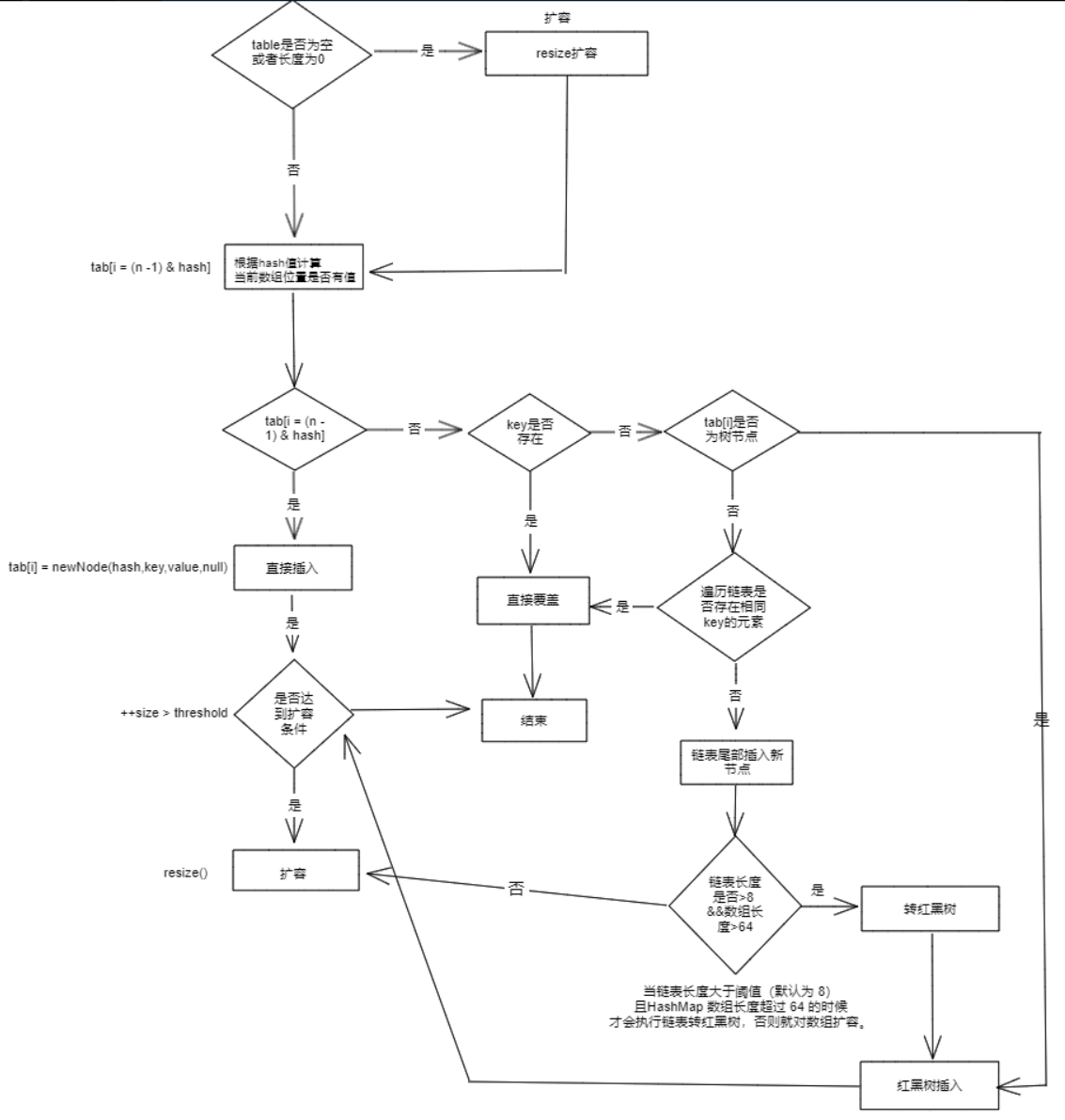
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0) // 空数组则先进行扩容
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // bucket中没有结点,则将该节点添加进去
tab[i] = newNode(hash, key, value, null);
else { // bucket中有结点
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p; // hash相同,且key相同,直接覆盖
else if (p instanceof TreeNode) // 如果是树节点转为使用存放树节点的方法
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else { //
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null); // 插入链表尾部
/*
结点数量到达阈值时,执行treeifyBin方法,如果数组长度>64,转换为红黑树
*/
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break; // 判断链表中结点的hash以及key是否插入结点的相等
p = e; // 如果当前结点e不是匹配的结点,将p移动到下一个节点继续循环
}
}
// 表示在桶中找到key值、hash值与插入元素相等的结点
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) // onlyIfAbsent为false或者旧值为null
e.value = value; // 替换旧值
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize(); // 大于阈值则扩容
afterNodeInsertion(evict);
return null;
}
在这段代码中:
- `tab`:是数组,代表 `HashMap` 的哈希表数组。
- `p`:是当前桶位置的第一个节点。
- `e`:是用于遍历链表或树的节点。
- `k`:是节点的键。
具体解释:
1. `tab`:是 `HashMap` 的哈希表数组,用于存储节点。在这段代码中,通过 `table` 属性获取。
2. `p`:是当前桶位置的第一个节点。通过 `tab[i = (n - 1) & hash]` 计算得到,其中 `i` 是哈希值与数组长度取余的 结果,表示节点应该放在哈希表的哪个位置。`p` 代表该位置上的第一个节点。
3. `e`:是一个用于遍历链表或树的节点,用于查找目标键是否已存在。
4. `k`:是节点的键。在比较键值时使用。
在这个方法中,首先会判断当前桶的第一个节点 `p` 是否为空,如果为空,说明该桶是空的,可以直接在该位置插入新节点。如果不为空,就需要遍历链表或树来查找目标键是否已存在。
- 如果 `p` 的键与目标键匹配,`e` 就被赋值为 `p`,表示已找到相同的键。
- 如果 `p` 是树节点,则调用树节点的特定方法来执行插入或更新操作。
- 如果 `p` 不是树节点,就通过循环遍历链表,查找目标键是否已存在。如果找到相同的键,`e` 被赋值为当前节点,表 示已找到相同的键。
最终,如果找到了相同的键(`e != null`),表示已存在该键的映射关系,将更新对应的值;如果未找到相同的键,将在链表的末尾插入新的节点。这段代码实现了向 `HashMap` 中插入或更新键值对的逻辑。
putMapEntries()
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
// 判断table是否已经初始化
if (table == null) { // pre-size
/*
* 未初始化,s为m的实际元素个数,ft=s/loadFactor => s=ft*loadFactor, 跟我们前面提到的
* 阈值=容量*负载因子 是不是很像,是的,ft指的是要添加s个元素所需的最小的容量
*/
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ?
(int)ft : MAXIMUM_CAPACITY);
/*
* 根据构造函数可知,table未初始化,threshold实际上是存放的初始化容量,如果添加s个元素所
* 需的最小容量大于初始化容量,则将最小容量扩容为最接近的2的幂次方大小作为初始化。
* 注意这里不是初始化阈值
*/
if (t > threshold)
threshold = tableSizeFor(t);
} else {
// Because of linked-list bucket constraints, we cannot
// expand all at once, but can reduce total resize
// effort by repeated doubling now vs later
while (s > threshold && table.length < MAXIMUM_CAPACITY)
resize(); // 已初始化,并且m元素个数大于阈值,进行扩容处理
}
// 将m中的所有元素添加至HashMap中,如果table未初始化,putVal中会调用resize初始化或扩容
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
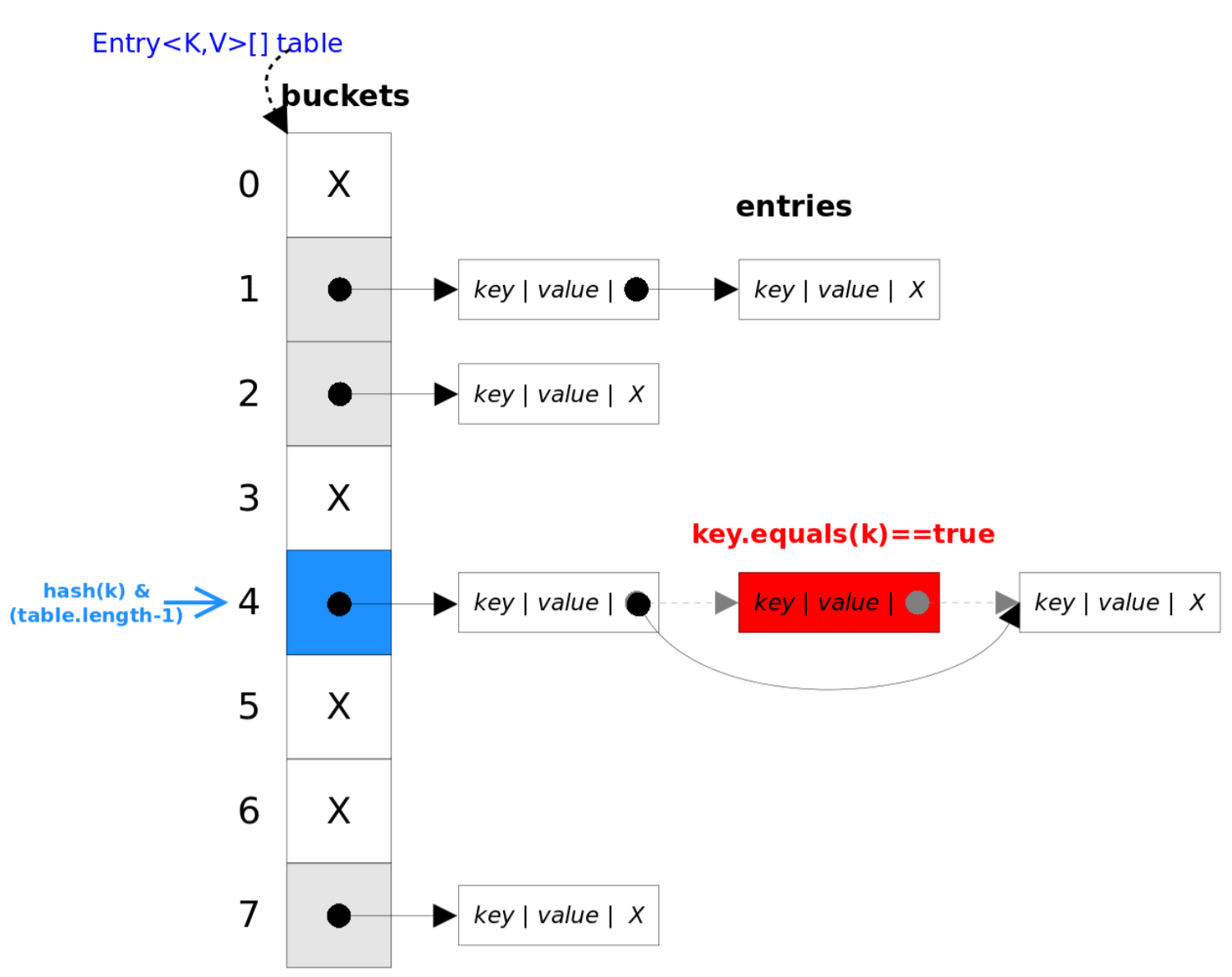
remove()
首先找到key值对应的entry,随后删除该entry
resize()
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中的所有元素,非常耗时。编写程序时尽量避免resize。resize方法实际上是将table初始化和table扩容给进行了整合,底层行为都是给table赋值一个新的数组
面试题
HashMap和HashSet的区别。
HashSet底层基于HashMap实现。
| HashMap | HashSet | |
|---|---|---|
| 接口实现 | Map接口 | Set接口 |
| 存储的元素 | 键值对 | 仅存储对象 |
| 添加元素 | put() | add() |
| hashcode | 使用key计算hashcode | 使用成员对象计算hashcode,对于两个对象来说 hashcode可能相同,所以equals()方法用来判断对象的相等性 |
HashMap的长度为什么是2的幂次方?

HashMap多线程操作导致死循环。
HashMap为什么不安全?
待更新......


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人