
ScaleVLAD
ScaleVLAD: Improving Multimodal Sentiment Analysis via Multi-Scale Fusion of Locally Descriptors
本文发表于2021.12.02
MSA任务中存在的两个较为明显的问题:1.多个模态的表示融合;2.多个模态的对齐问题。
一般来说,模态之间应该先进行对齐,然后再进行模态表示融合。然而,很多工作可能并没有考虑对齐问题,就直接进行融合。本文主要解决以上两个问题。
摘要
信息融合技术是MSA任务中非常重要的一个话题。近期,基于注意力的融合机制相比基于简单操作的融合机制有明显的提升。然而这些融合方法采取的是单一尺度(例如分词级和话语级)的单模态表示(这种方法并不是最优的,因为不同的模态应该使用不同的粒度来进行对齐)。
本文提出了ScaleVLAD的融合框架:使用公共的VLAD从文本、视频和音频中收集多尺度表示,以便对未进行对齐的MSA任务进行提升。这些公共的向量可以看作用来对齐不同模态的公共主题。 此外,本文还提出了一种自监督移位聚类损失(Self-supervised shifted Clustering Loss,S3C Loss),以保持样本间融合特征的差异性,有效利用标签信息(将特征空间中属于同一类别的样本聚类在一起)。
框架的主干是对应三种模态的三个Transformer编码器,融合模块生成聚合的特征,并输入到一个Transformer和一个全连接层以完成预测任务。
在三个benchmark( IEMOCAP, MOSI, and MOSEI)上进行了实验,较于基线模型有明显的提升。
1 Introduction
MSA 主要包括两部分内容:单模态表达和信息融合。 对于单模态表示,当前有很多现成的方法(MFCC for audio and BERT encoding for text)。因此模态融合就成为影响性能的关键因素。模态融合方法包括但不限于:simple operation-based、attention-based、tensor-based、translation-based、GANs-based、graph-based、routing-based。 融合的目标是学习一个模态不变(modality-invariant)的嵌入空间,然后利用modality-invariant特征或将modality-invariant特征与 modality-specifific特征相结合,完成最终的预测。
然而,大多数融合方法要么采用单词级(token-level)的单模态表示,要么采用话语级(utterance-level)的单模态表示(均为单一尺度的融合方法)。 由于采样率的变化,视觉和声学特征没有明显的语义边界,
尽管基于注意的方法可以使一个模态中的每个符号覆盖其他模态中的长期上下文, 但仍无法捕获一对多的单词关系。
本文提出了ScaleVLAD:使用公共的VLAD从文本、视频和音频中收集多尺度表示,以处理没有对齐的MSA任务。Scale VLAD利用可学习的公共的隐藏语义向量来自动选择并聚合模态特征,而不是在每个模态中检测不同语义范围的边界。
这些潜在的语义向量被认为是不同的语义主题,在不同的模式和尺度上共享。 因此,它们可以减少模态之间的语义差距,并自然地对齐各种尺度特征。
2 Related works
VLAD,Vector of Locally Aggregated Descriptors
VLAD 在聚合各种场景的区别特征方面取得了很大的成功, 包括视频检索和视频分类。NetVLAD对VLAD进行了扩充,使之能够很容易地插入到很多现存的网络模型中,它是一个端到端的可微层。
本文借鉴了VLAD和NetVLAD的思想来对不同模态进行对齐, 而不是用来作为一个判别特征学习者。
3 Framework
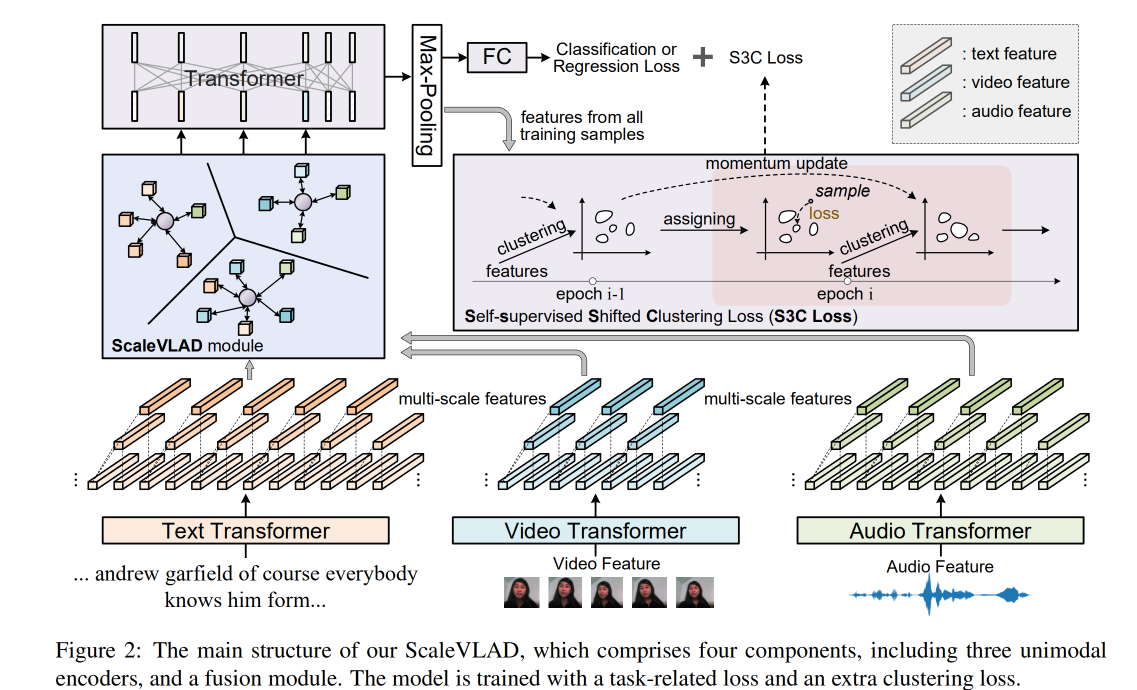
给定一组数据,目标是预测它们的情绪。数据用三元组来表示(word token, visual feature, acoustic feature),并将视觉特征和音频特征视作与文本词向量一致的tokens。
3.2 Modality Representation Learning
使用三个包含不同层数的Transformer来编码原始数据。原始的视频和音频特征从以往研究中的预训练工具中提取;使用12层的BERT和12层的T5来提取文本特征。
若上述三个特征 \(\mathcal{F}\) 在输入到后续模块时的维度不等于 \(d_s\) ,则对每个特征使用不同的全连接层以变换特征维度。
3.2 ScaleVLAD Moudle
三种模态的特征融合,尤其时在不同粒度下的融合,其核心问题是对不同的语义单元进行对齐。然而,每种模态的语义单元没有明确的对齐边界并且不能直接融合。一种可行的方法是在这些单模态特征之间假设一些共享的语义向量,并将它们与这些共享的向量对齐。这种共享向量可以看作是共同的主题,也可以在不同的单模态尺度上进行共享。 受上述方法以及VLAD和NetVLAD的启发,本文提出了ScaleVLAD。
不同尺度的单模态表示采用不同核大小的平均池化方法生成(步长与核大小相同)。使用核大小为 \(m\) 的平均池化层来对 \(f_j \in \mathcal{F}_{M_i}\)(其中 \(M \in \{{T,V,A\}}\) )进行调整,使之与共享语义向量 \(\{c_k \in \mathbb{R}^{d_s}|k\in[1,K]\}\) 的维度相同。表示为:
随后计算 \(f_j^{(m)}\) 与共享向量之间的相似性:
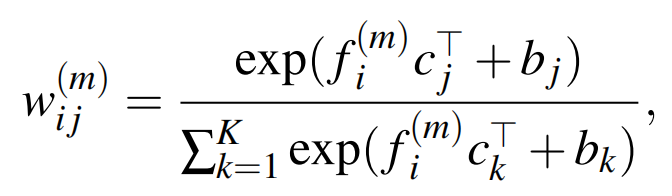
其中 \(b_j\),\(b_k\) 为可学习的偏差。 然后按如下方法生成每个向量上的聚合特征 :
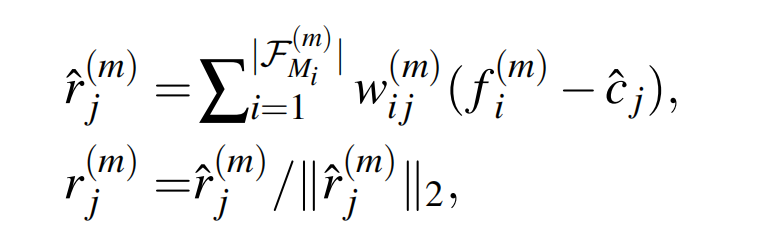
其中 \(\hat{c_j}\) 和 \(c_j\) 的维度相同( 使用两组相似的向量可以提高自适应能力 )。输出的 \(r_j^{(m)}\) 被看作单模态m-scale 的对齐特征。 由此可生成如下 \(\mathcal{F}_{M_i}\) 对应的聚合特征:
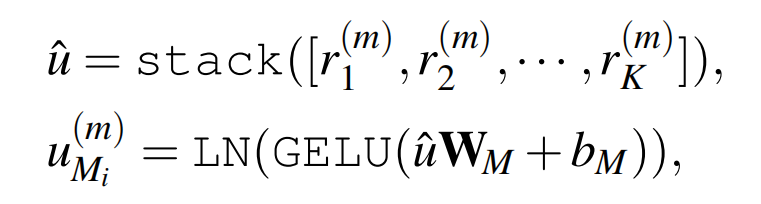
stack为堆栈操作,\(\hat{u} \in \mathbb{R}^{Kd_s}\) ,\(\mathbf{W}_M \in \mathbb{R}^{Kd_s\times d_s}\) 和 \(b_M \in \mathbb{R}^{d_s}\) (其中 \(M \in \{{T,V,A\}}\))为可学习的权重和偏置值,GELU和 LN分别为GELU激活函数和层归一化操作。
使用得到的multi-scale聚合特征 \(u_{M_i}^{(m)}\) 进行融合和预测,将使用不同scale获得的融合特征堆栈在一起得到:
其中 \(|m|\) 是scale的数量,\(\overline{f}_{M_i}\) 是对 \(\mathcal{F}_{M_i}\) 进行平均池化操作的结果。然后使用一个随机初始化的Transformer编码器对学习到的multi-scale进行交互:
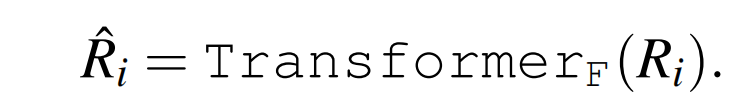
最后的分数和概率可通过最大池化层进行计算:
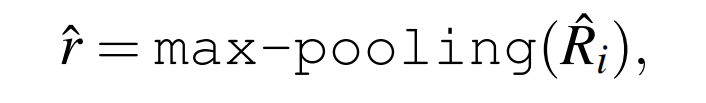
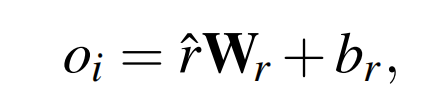
3.3 S3C Loss
对于每个样本的融合特征 \(\hat{r}\) ,首先使用k-means算法获取 \(C\) 个簇,记第 \(i\) 个簇为 \(z_i \in \mathbb{R}^{d_s}\) ,所有的簇记作矩阵 \(Z\in \mathbb{R}^{C \times d_s}\) , 聚类操作是根据训练样本在每个epoch开始的所有表示来计算的。 对于运行周期内的同一样本,我们将其簇中心索引 \(i\) 作为分类标签。 S3C Loss 计算方法如下:
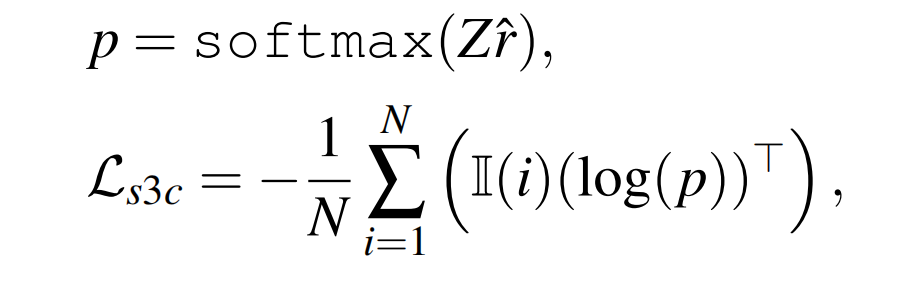
其中 \(\mathbb{I}(i)\) 是长度为 \(C\) 且第 \(i\) 个值为 1 的one-hot向量,\(N\) 为训练样本的数量。
这种损失是自我监督的,但聚类中心在训练初期并不稳定。设置一个起始的epoch \(s_{S3C}\) 对 \(\mathcal{L}_{S3C}\) 进行训练,而不是从训练开始就对 \(\mathcal{L}_{S3C}\) 进行优化。为了使聚类中心更加稳定,在每次迭代时令 \(Z^{(t)}=\alpha Z^{(t-1)} +(1-\alpha)Z\) ,并在每次迭代时用 \(Z^{(t)}\) 替换 \(Z\) ,其中 \(\alpha\) 设置为 0.99。另外设置了多种聚类方式来提升鲁棒性。\(\mathcal{L}_{S3C} = \mathcal{L}_{S3C}^{C_1}+\mathcal{L}_{S3C}^{C_2}+...\) ,\(\mathcal{L}_{S3C}^{C_i}\) 表示 $\mathcal{L}_{S3C} $ 使用 \(C_i\) 个簇进行聚类。
3.4 Training Objectives
模型的目标就是最小化损失函数:
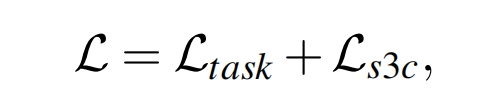
其中 \(\mathcal{L}_{task}\) 针对分类和回归任务有不同的形式,对于分类任务使用交叉熵损失:
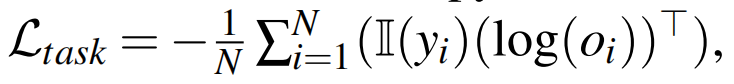
对回归任务使用均方误差:
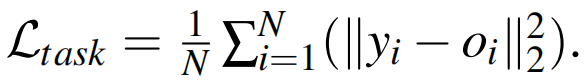
其中 \(y_i\) 均为分类或回归分数的类别,\(N\) 为训练样本的数量。
4 Experiment
4.1 Datasets
在IEMOCAP, CMUMOSI和CMU-MOSEI上进行实验,这三个数据集提供了未对齐的三种模态数据。
视频特征通过Facet提取,音频特征使用COVAREP进行提取。视频特征主要包含35种面部动作,音频特征主要包括 Melfrequency cepstral coeffificients (MFCCs), pitch tracking and voiced/unvoiced segmenting features, glottal source parameters, peak slope parameters, and maxima dispersion quotients.
Facet&COVAREP:视频特征维度 \(\hat{d_v}\):IEMOCAP 35;CMU-MOSEI 35;CMU-MOSI 47。音频特征维度\(\hat{d_a}\):三个数据集均为74。
OpenFace&Librosa:视频特征维度 \(\hat{d_v}\):709;音频特征维度\(\hat{d_a}\):33
4.2 Experimental Datails
在本文中使用 T5 基础编码器,同时在消融实验中还是用了最基础的BERT;三种模态的Transformer随机初始化,模态融合向量维度设置为 \(d_s=128\) ;使用带有线性表的Adam优化器训练模型。
| 参数 | 数值 |
|---|---|
| fusion dimension: $d_v $ | 128 |
| warmup rate | 0.1 |
| total epoch | 50 |
| learning rate | |
| layers of V and A Transformer / hidden size | {4, 6} / |
| layers of fusin Transformer | 2 |
| multi-scale : \(m\) | |
| number of shared semantic vec: \(K\) | |
| cluster : \(C\) | |
| start epoch \(s_{s3c}\) for loss \(\mathcal{L}_{s3c}\) | 5 |
| batch size | 64 |
4.3 Ablation Studies
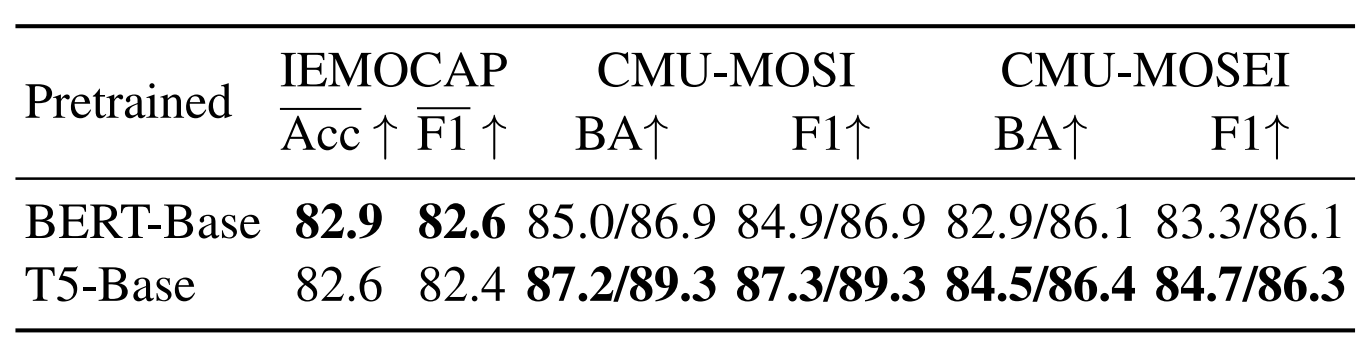
- Text Encoder:对比了 BERT-Base 和 T5-Base 两个预训练模型,T5-Base在CMU-MOSI和CMU-MOSEI上效果较好,在IEMOCAP上效果与BERT-Base效果接近,所以选择T5-Base作为Text Encoder。另外假设使用更大的预训练模型T5-Large可以实现更好的效果,但需要更多的算力。
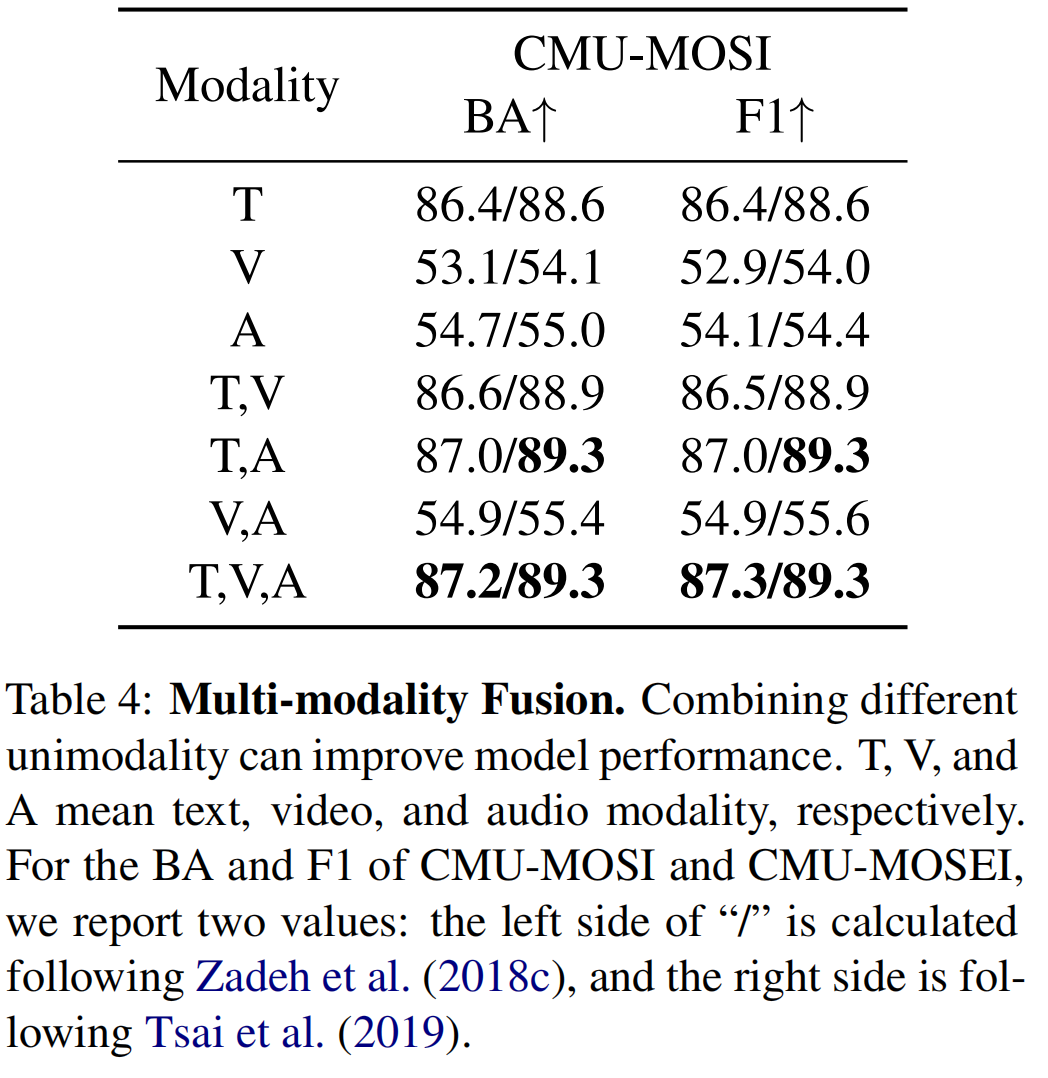
- Multi-scale Fusion:对multi-scale : \(m\) 的取值进行实验,\(m\) 取值为{1,2,10}和{1,2,3,10}效果更好。并且证明了将模态表示以多粒度进行融合会使模型的性能更好。
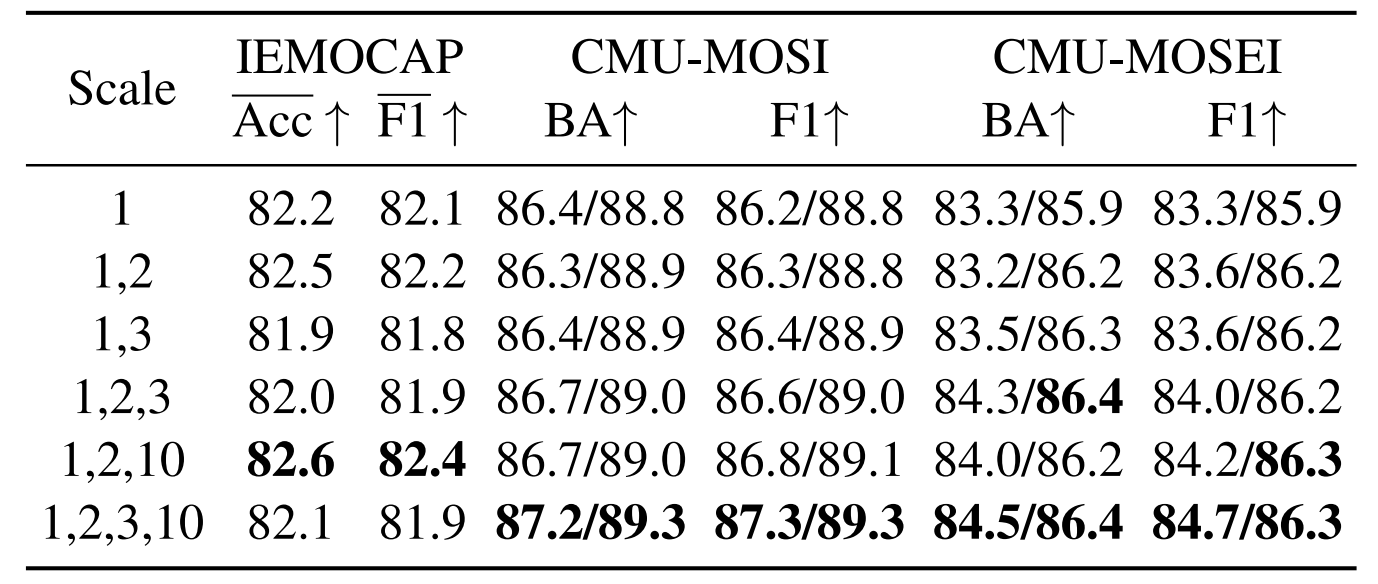
- Cluster NO. in S3C Loss:对S3C Loss中的类被数量进行对比试验,结果表明{10,15}和{15,20}效果更优。
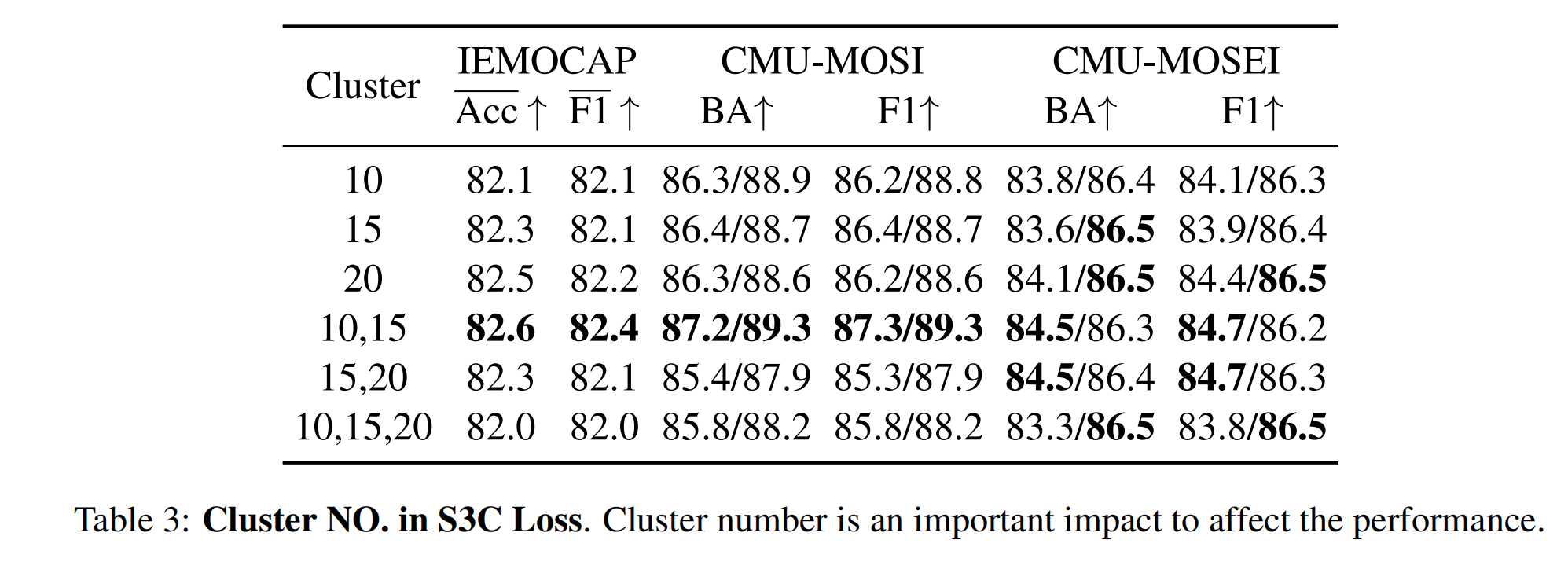
- Multi-modality Fusion:模态融合与单模态相比,能够提供更多的信息,并捕获更多的情感特征。
- Nonverbal Feature:在IEMOCAP上生成不同的非语言特征(视频和音频),结果表明,特征越复杂,结果越好。 此外,我们假设从原始信号进行端到端训练可以提高更多,而不是利用现成的工具提取特征。
4.4 Comparison to State-of-the-art
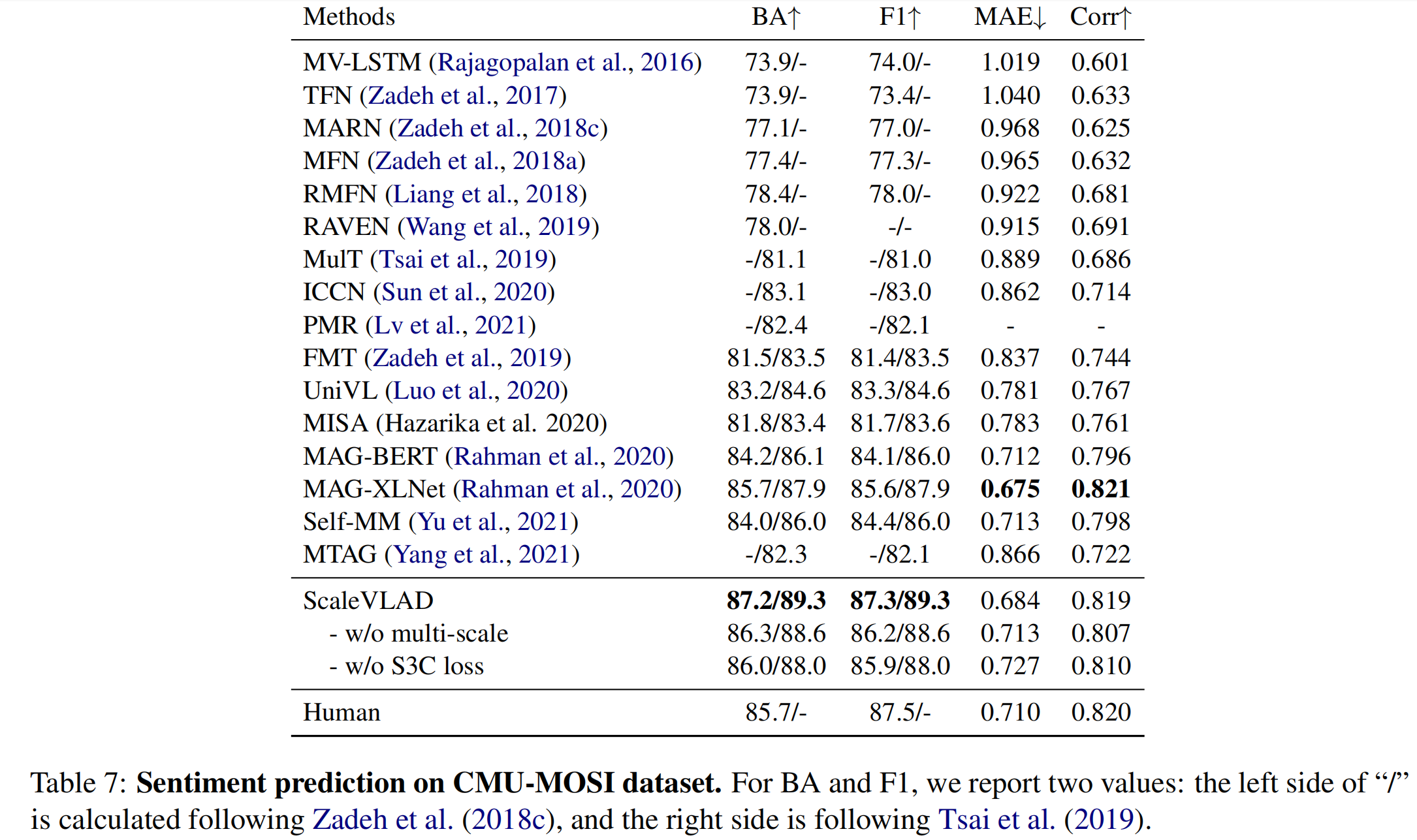
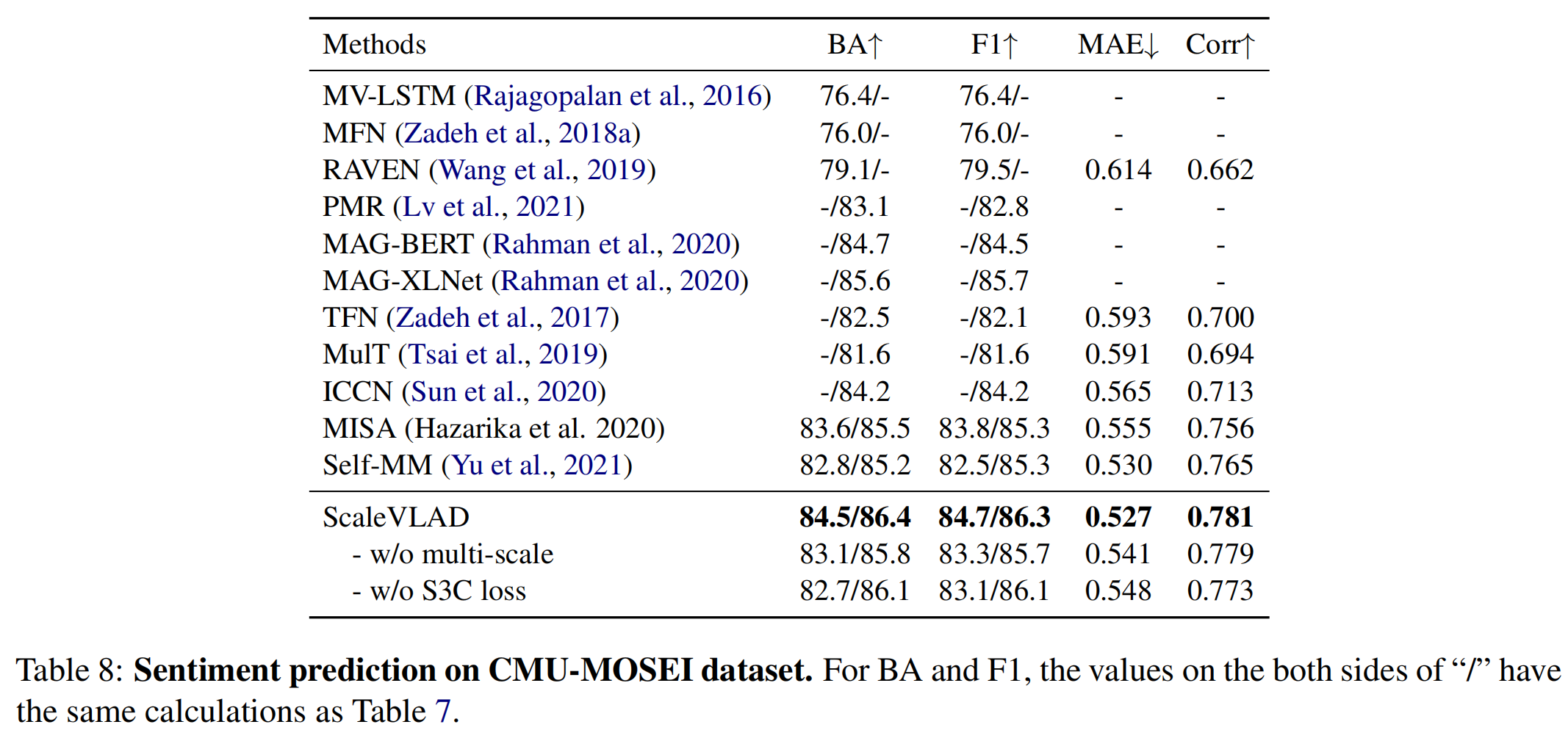
ScaleVLAD与当前的SOTA方法进行比较:
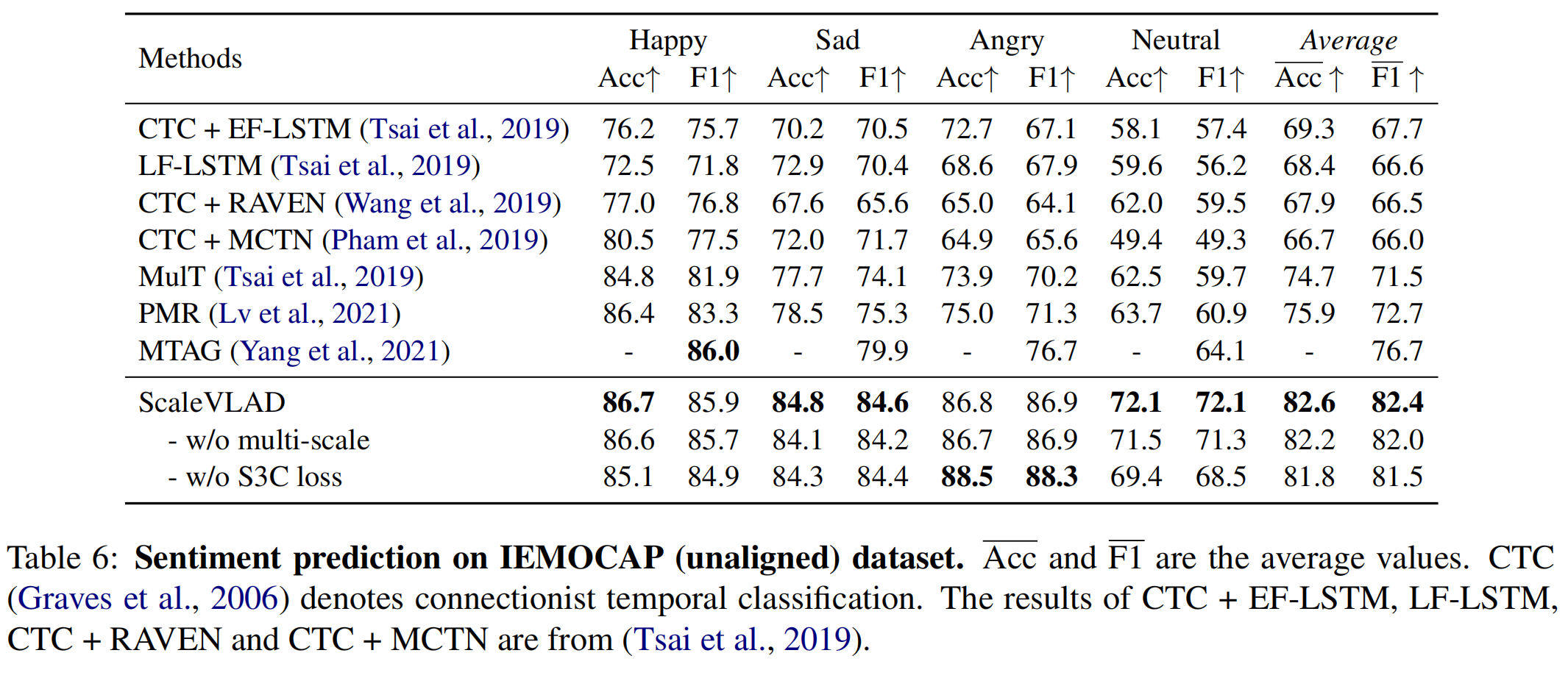
- ScaleVLAD效果在三个数据集上都优于baselines;
- 结果证明了 multi-scale 和 S3C Loss 在所有指标和数据集上的有效性;
- 表7中,基于BERT的模型的结果优于基于BERT特征的模型;
- 表6中,基于T5的特征提升较为显著,也证明了通过大规模语料库的自监督训练,预训练模型具有较强的训练能力。
4.5 Qualitative Analysis
图3显示了使用公式(11)计算融合特征时,是否使用S3C Loss的结果。图3b显示聚类更紧密并且边界更为清晰。
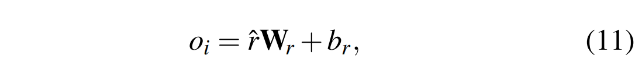
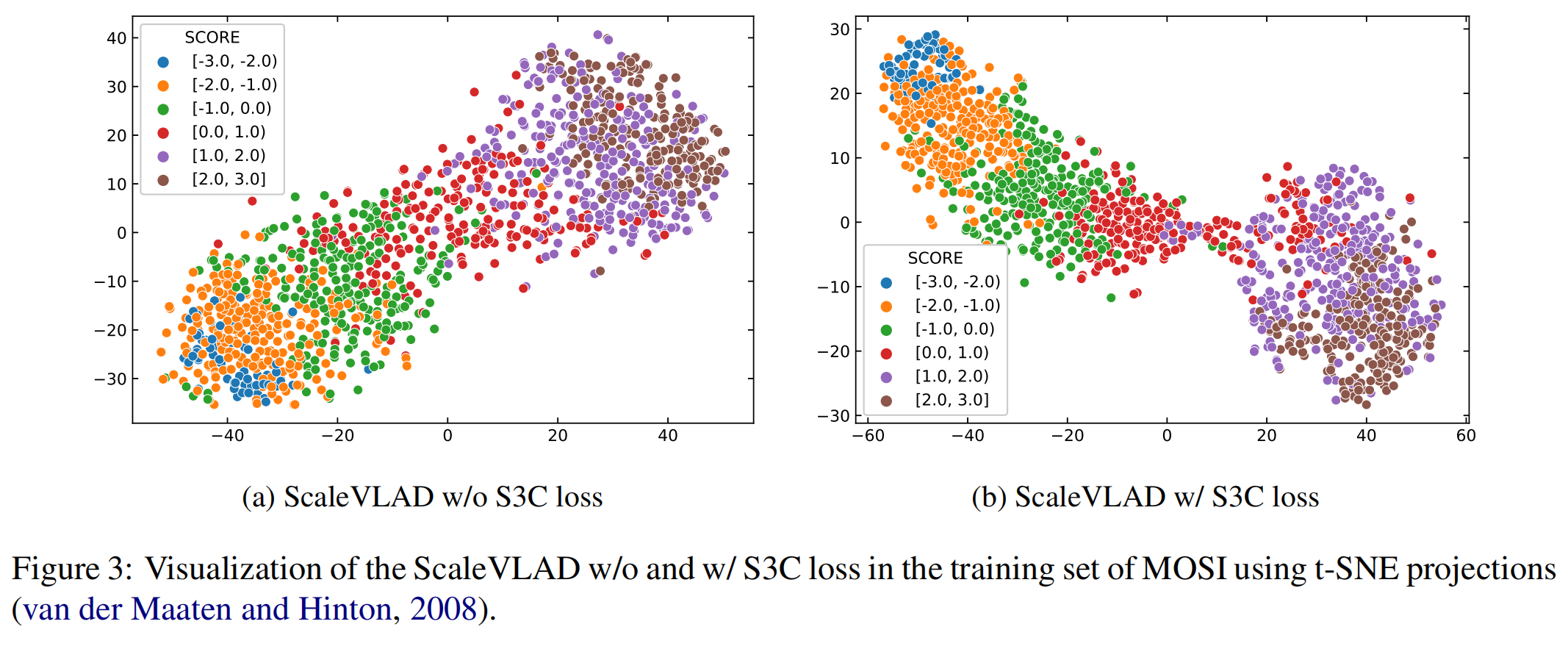
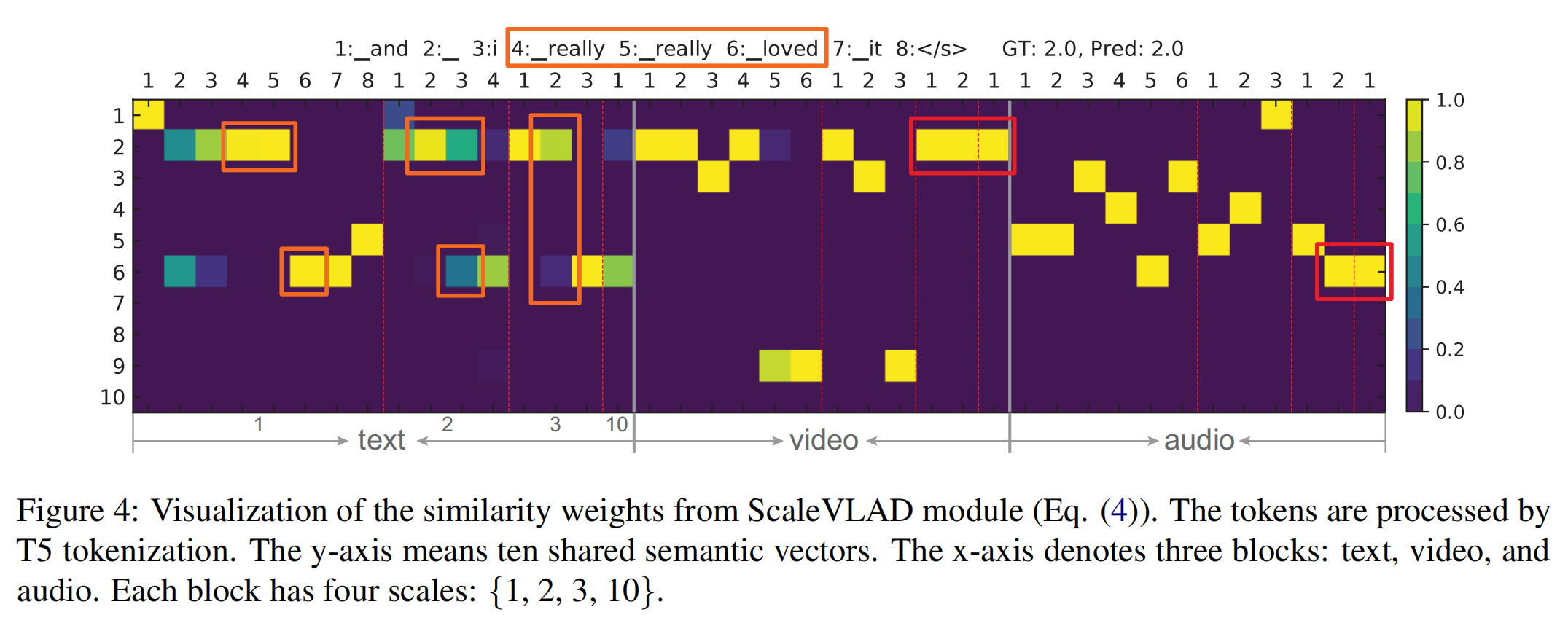
图4显示了使用公式(4)计算相似性的结果。使用不同scale对文本、视频和音频对齐的方式不同,并且这些方式模型可以自动进行学习。本文任务ScaleVLAD性能的提升得益于这种multi-scale对齐。
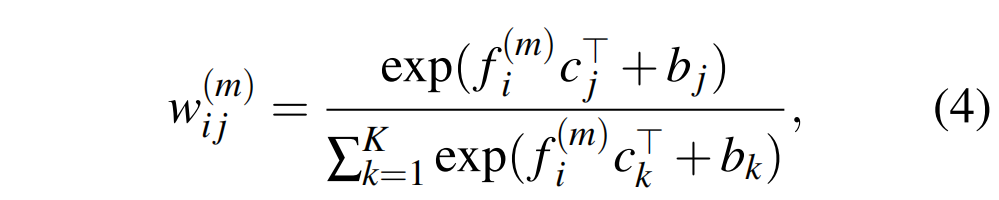
5 Conclusion
- 提出了一个multi-scale的融合方法ScaleVLAD和一个S3C Loss来处理MSA任务中无法对其的问题;
- 该方法通过将不同模态与可训练的隐藏语义向量进行对齐来考虑不同的表示粒度,可以消除单模态的模糊边界;
- S3C Loss 通过保持集群中心的动量更新来保持融合特征的差异性;
- 在三个公开数据集上进行的大量实验表明了该模型的有效性。
