
存储器层次结构-Cache
为什么需要存储器层次结构?
现在cpu的执行速度和内存的速度相差过大,为了避免cpu因为等待重内存中的数据而导致指令流水线阻塞,浪费cpu资源,就出现了存储器层次结构,cpu不从内存拿去数据,而是从一个靠近cpu内部的高速缓存中拿去数据。由于程序的执行符合局部性原理,因此我们只要使用较小的内存就可足够了,一旦cpu访问cache发生块缺失,cache再从内存中找数据,如果内存中发生也缺失,那么就去外存中找数据,一旦找到了数据,内存和cache都存储一份这个数据的副本,因为时间局部性原理,程序可能接下来还会访问该数据。
即使是现在,cpu依然比内存快上3个的数量级,这意味着,只要访问一次内存或者发生一次块缺失,cpu就要阻塞上1000个时钟周期准备数据,所以我们通过设计不同的存储器层次结构,设计不同的cache映射方式来降低块的缺失率;内存则设计不同的页替换算法来降低页的缺失,还要使用内存来作为外存的高速缓存也是一种方法。例如我的电脑:
Cache的基本原理
Cache就像一个家楼下邮箱,当我们想要获取杂志报纸时,我们只需要下楼取就好了,而不用取邮局或者商店。降低我们获取报纸的时间成本。
Cache的基本单位时块,这个单位比内存单元要大,一个块可能容纳N个内存单元。这里我们假设块的大小是一个字(64位的,也可能是32位的根据平台来定),内存是按字节编址,那么我一个块的大小可以容纳下8个内存单元。
在这一小节,我们只采用直接映射的方式,将每组内存单元中存储的值复制到cache中,当我们要通过虚拟地址查找时,我们可以通过虚拟地址号找到放在cache中的数据。
Cache访问
- 将虚拟地址转换为块地址,就是将虚拟地址 / 块的大小。
- 块地址 % 块的个数,找到这个虚拟地址对应的数据存储在第几个块中。
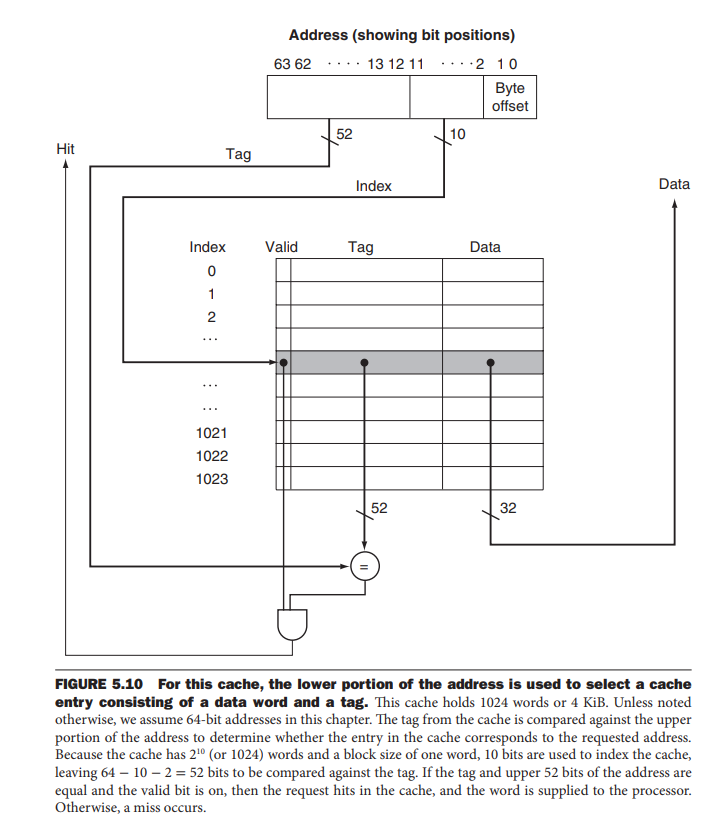
但是由于Cache也有换入换出的操作,并且当进程切换后,cache中的内容全都失效了,我们不知道这个块对应的数据是不是我们想要的,因此我们需要增加1个valid位,还要增加一个tag标签,这个tag标签是块地址中,除了第n位以下的位外的其他地址位表示的。
- 查看块表项的valid位是否为1,如果唯一这是块存放的是这个进程的数据,在用虚拟地址与tag相同位置的位来比较,若都相同那么这个块中的数据就是这个虚拟地址对应的数据了。
具体的就是下面图所标识的,不过注意一点,找到了虚拟地址所对应的块还有一点需要补充,因为一个块包含了多个内存单元,例如这张图中所说明了,假定这个cache有1024个块,cache容量位4KiB,那么data字段就是32bit,此时一个块包含4个内存单元,要指明这个虚拟地址的数据是哪个内存单元的就需要一个偏移量,这就是虚拟地址的底两位来标识的,2位二进程可以表示4个数0,1,2,3;data的大小是32位也就是4个Byte刚刚好能够表示。至于为什么cache有1024个块,cache容量4Kib,data字段就是32bit,这是因为4KiB = 1024个 * (8 * 4)Byte。
Cache缺失处理
Cache缺失时,需要Cpu的控制器和Cache的控制器共同完成操作,这是因为,cache缺失将引起流水线阻塞,这个与进程线程阻塞不同,流水线阻塞时指令因为缺乏数据无法继续执行下去,需要等待,直到从内存中取出数据,所以在这里CPU的控制做的应该是流水线阻塞的任务,而Cache控制执行的是通知内存进行读操作,并且将从内存中读取的数据放入Cache中。
指令cache缺失的步骤(数据cache缺失也基本相同):
- 将程序计数器PC的原始值送到存储器中。
- 通知主存执行一次读操作,并等待主存完成访问。
- 将主存取回的数据(块),放入cache中,重新设置tag,tag的值由ALU得出,valid = 1。
- 重启引发指令cache缺失的指令。
写操作处理
写操作的三种处理方法:
-
写直达:同时写入虚拟内存所对应的内存和cache。
这要处理下写缺失,就是虚拟内存所对应的块不在cache中,那么我们就要先将这个块放入cache中,再执行写直达。
-
写缓冲:将数据写入cache和写缓冲。
由写缓冲慢慢写入内存,不过当写缓冲满时,执行store语句时cpu就要阻塞等待写缓冲空闲位置。
-
写回:先写入cache中,等到该块被替换出cache时,再将写数据写入内存中。
Cache的性能改进
我们可以通过提高Cache块的大小来提高cache的命中率,只要程序符合空间局部性的要求,块容量变大意味着我们可以把程序接下来要用的数据提前准备好了,但是提高块容量大小意味着块的数量减小了,块的复用率也降低了,我们可能因为cache中缺少一个数据,导致将整个块换出,块中其他数据可能接下来会接着使用,到时候又要换入。还有不可忽视的一点就是块的容量变大,那么将内存中读的数据再存入cache需要的时间也变高了。
通过块的放置策略改进cache缺失
-
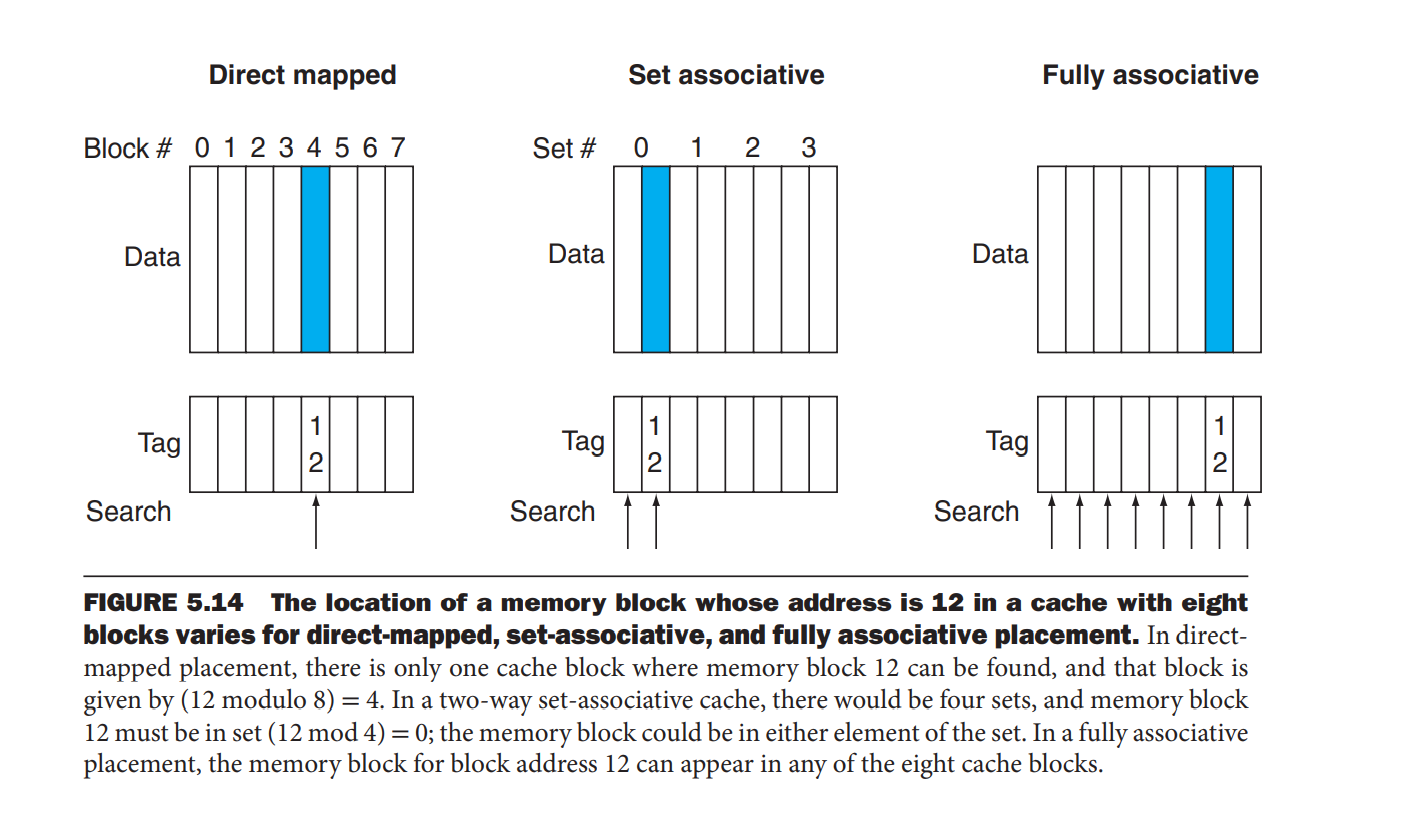
直接映射
可以将直接映射理解为数据结构中的数组, 块号就是整个数组的下标。 优点: 就是检索快简单,实现简单,不用为了降低查找时间而增加其他硬件成本. 缺点: 就是容量小,命中率低 -
全相联
可以将全相联理解为数据结构中的链表, 全相连没有块号,若要检索就要从头开始直到找到块或者块缺失。 优点:容量大,cache命中率就高。 缺点:检索费时,为了降低检索时间,需要增加额外的硬件成本。 -
组相联
组相联就像使用了拉链法解决散列冲突的散列表, 组号相当于索引。 优点:提高cache容量,通过将一组中的多个cache块看成一个大的cache块的方式,提高命中率。提高块的复用率,因为 发现块缺失时,我们不需要将整组的cache块全部替换,只需要根据替换算法,替换组中一个块就好了。 缺点:比直接映射法多了检索的时间,和额外的硬件成本开销,比如n路选择器,但是开销比全相联小。
注意一点:若通过并行检索的方式进行全相联和组相联的块检索,那么对比直接映射的方法只提高了额外的硬件成本。
在Cache中查找块
和之前介绍的直接映射法查找Cache块一样,我们通过虚拟地址提供的地址信息来查找数据,我们将虚拟地址划分为一下的组成部分:
若相联度每翻一倍,那么Index就要减小以为,因为一个组拥有更多的块,那么组的数量就要变少,同时Tag就要增加一位。Tag用来比对组中哪个块是我们想要的。

具体的实现如下图
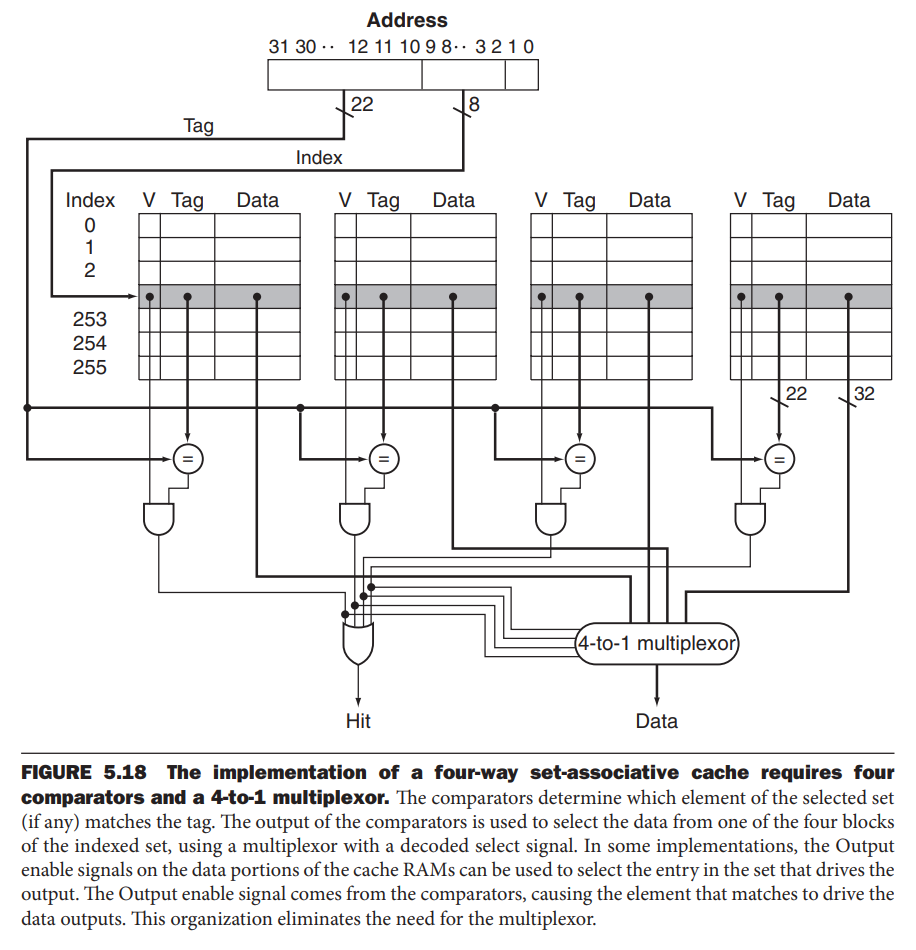
替换块的选择
这个其实和分页的替换算法差不多,页的替换算法能用的也同样能用在cache中,具体的见操作系统部分
使用多级cache
通过增加多级cache的组合来减少缺失代价,具体的做法就是,第一级用小容量高速的cache减小cpu的访问时间,第二cache使用比第一级cache容量大的多的但是速度稍慢的cache解决块缺失照成的访存的代价,除非二级cache也缺失了,不得不访存或者存在第三级cache,若是这样,那访存需要等到第三级cache也缺失。所以多级cache其实使用减少因一级cache块缺失导致访问内存的概率,或者说时减少访存大代价。
1、为什么更多的相联可以提高命中率。
首先,如果是直接映射的方法(特殊的组相联--单组组相联)一个内存中一个块对应cache中一个块,那么当相应块只被复用很少的次数,就被内存中的另外一块给取代了,这样相比于采取多组相联的模式确实命中率更低,因为多组相联的模式种,内存中的相同一组的块,在cache可以同时存放,这样避免了cache块种复用率低的概率性。
2、不管是那种减少页表占用内存的方法, 其实主要核心我感觉都是只要添加有用的页表项到页表中,就是说,虚拟页号要是没有对应的物理页号,那么我们就不用把这个页表项加入页表。页表的作用就是提到虚拟页号到物理页号的映射。

