
计算机指令
理清几个点:
-
指令中存放的二进制码
例如R型指令:
opcode:操作码 Rm:第二源操作数 Shamt:位移量 Rn:第一源操作数 Rd:目的寄存器 11bit 5bit 6bit 5bit 5bit 例如,这里的Rm位置下的二进制码表示的是二进制的地址(指的是第几个寄存器),这里用的是寄存器寻址,就是说要取的值还在寄存器里,不会把它放入我们的指令中来。
-
字 word 大小依赖平台(cpu一次能处理的位数) 字节 byte 8bit 位 bit 1bit 1KB = 1024Bit、1MB = 1024KB 、1GB = 1024MB
2.1引言
计算机中的基本单词成为指令(如ADD,SUB,CMP
指令集为计算机全部指令——也包括伪指令,不过经过汇编器会被编为基本指令。伪指令就是基本指令的变种。
指令集的两种形式:
- 便于人们书写的(汇编语言)
- 计算机所识别的(二进制码)
2.2计算机硬件的操作
例如:
ADD a b c
这汇编语句对应一条指令,这条指令有且只有三个操作数。
这符合我们设计原则1:简单源于规整。
2.3计算机硬件的操作数
LEGv8算数运算指令的操作数必须来自寄存器。
LEGv8的寄存器为64bit。
LEGv8体系下的字为32bit。
双字为64bit。
LEGv8体系下的寄存器被限制为32个。为什么?
设计原则2:越少越快
大量的寄存器会使时钟周期变成,因为电信号要传的更远。
另一个原因是指令的现在,LEGv8指令格式只给操作数分配5个bit,如果寄存器超出32个,那么指令也会随之变长——因为需要更多的位来表示操作数。
2.3.1存储器操作数
| STUR | Rd | [基址寄存器,#偏移量] |
|---|
寄存器溢出:就是指要存的变量的值多于寄存器的个数,所以我们将不常用的变量的值放在存储器中。
2.4有符号数和无符号数
最低有效位:最右边的一位
最高有效位:最左边的一位
原码表示法:符号和幅值表示法(舍弃不用)
补码:
- 前置位为0:正数
- 前置位都为1:负数
补码负值计算公式:
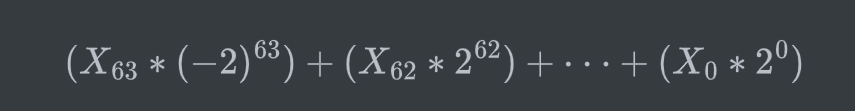
符号扩展——指从存储器中载入寄存器的数值没有64位,那么就要用数字去填充空缺位
- 符号扩展:就是用符号位去填充空缺
- 零扩展:用0去填充空缺位置。
2.5计算机中指令的表示
设计原则3:优秀的设计需要好的权衡和折中
因为有些指令不要三个寄存器,而需要更大位数来表示立即数和跳转地址,但指令长度又被限制于32位,所以好把表示寄存器的位数用于表示立即数。例如无条件跳转指令B,opcode只有6bit剩下的全部用于地址位,还有以下列举的指令类型。
D型指令(load,store):
| opcode | address | op2:操作码的逻辑扩展 | Rn:基址寄存器 | Rt |
|---|---|---|---|---|
| 11bit | 12bit | 2bit | 5bit | 5bit |
I型指令(ADDI,SUBI)
| opcode | immediate | Rn | Rd |
|---|---|---|---|
| 10bit | 12bit | 5bit | 5bit |
重点
计算机构建原则:
- 指令用数的形式表示
- 程序和数据一样,存储在存储器上进行读写。
这两个准则引发了存储程序原理的诞生,使得计算机发挥了巨大的潜力。存储器可以存放各种东西。
2.6逻辑操作
- 左移:LSL
- 右移:LSR
- 与:AND——操作位相同,结果位1
- 或:OR——操作位不同,结果位1
- 取反:NOT——0变1,1变0
- 异或:EOR——操作位不同时未1
2.7决策指令
| CBZ | register | Lable | 如果register为0跳转到Lable |
|---|---|---|---|
| CBNZ | register | Lable | 如果register不为0跳转到Lable |
B.cond 指令 ,cond表示条件
cond用于有符号数:
- EQ:equal
- NE:not equal
- LT:less than
- LE:less equal
- GT:greater than
- GE:greater equal
cond用于无符号数:
- LO:low
- LS:low same
- HI:high
- HS:high same
LEGv8还有一下四个二进制位来表示指令执行状态:
- 负数标志位(N)
- 零标志位(Z)
- 溢出标志位(V)
- 仅为标志位(C):若从最高位借位或者进位就设置条件吗。
到头设置标志位的方法:
- 用指令比较两个寄存器大小,然后根据结果跳转。
- 比较两个寄存器的值,然后用第三个寄存器记录比较是否成功。
只有ADD,ADDI,AND,ADNDI,SUB,SUBI能设置条件码,想要设置条件码就在指令尾加S(ADDS)
2.7.2边界检查
SUBS XZR, X20, X11 --X11=length
B.HS IndexOutOfBounds
检查索引是否越界。
如果一个有符号数(非负数) 减去一个无符号数,如果有符号数>无符号数,运算中产生进位或者借位时,C置为1,
如果有符号数是一个(负数)那么大于无符号数,运算中中产生进位或者借位时,C置为1.
跳转指令就可以凭借进位标志位(C)是否为1悬着跳转。
2.8对函数的支持
执行函数的步骤:
- 将参数放到函数可以访问到的地方
- 将执行控制权交给函数
- 获得函数执行所需的存储资源
- 执行所需的任务
- 将结果值放在调用程序可访问的地方
- 将控制点放回调用点,因为一个函数在多个地方可能会被调用
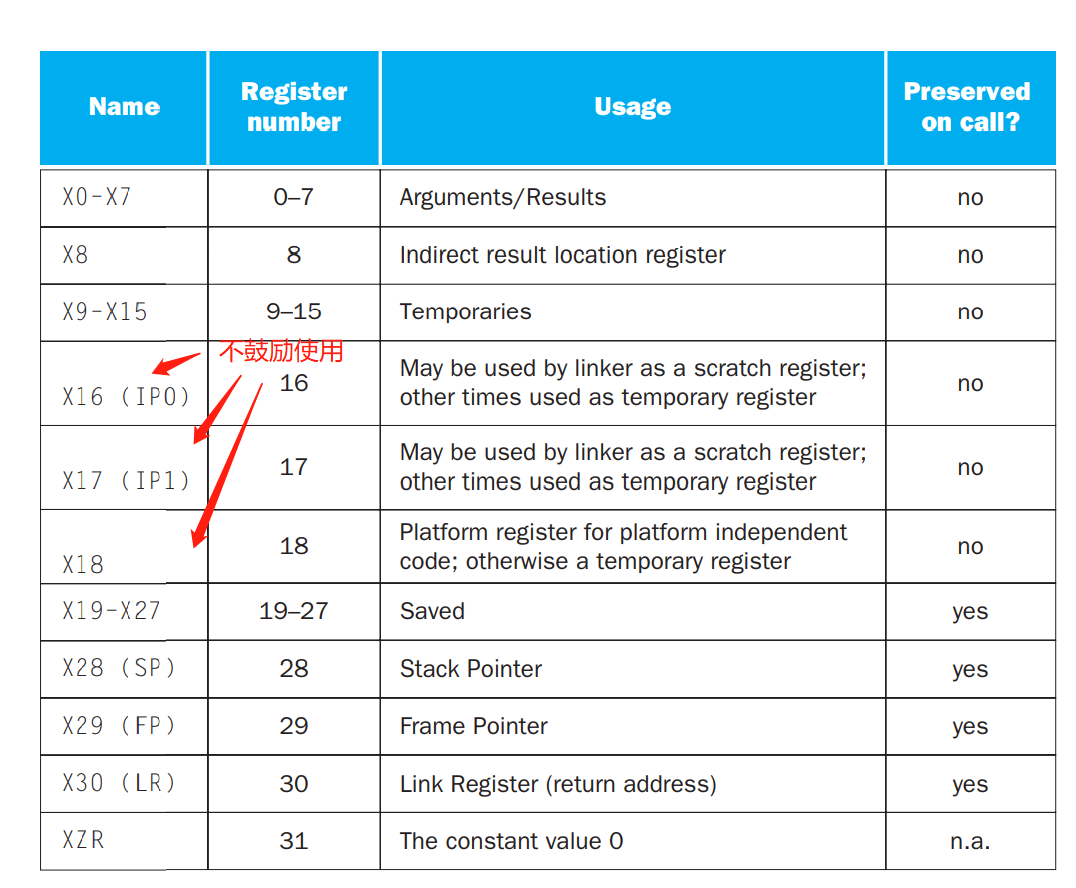
LEGv8为过程(函数)分配寄存器的约定:
- X0~X7:作为参数寄存器用于传递参数和放回结果
- LR(X30):作为放回地址寄存器,用于放回原始调用点。asdas
分支和连接指令(Branch and Link instruction)
BL procedureAddress
用于跳转到某个地址的同时将下一条指令的地址保存在寄存器中。
寄存器跳转指令(Branch register)
BR LR
跳转会原始调用点。
PC:保存当前真正执行的指令地址
- 程序计数器
- 指令地址寄存器
两个都是PC的别名。
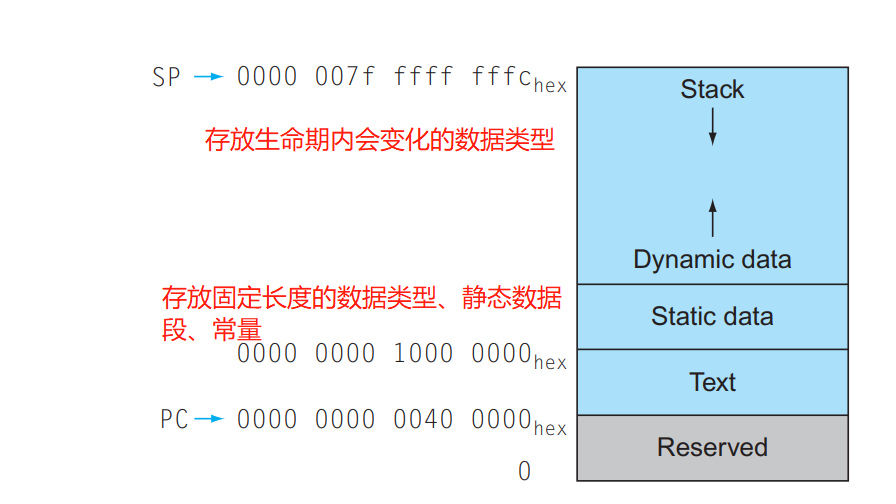
我疑惑:栈为什么要从高地址开始?
早期的系统需要考虑有限内存下的内存布局问题。具体来说,内存的一端放置了静态代码和静态数据之后,剩余的区域,既需要动态数据,又需要可增长的栈,那么合理的方案就是各放一端向中间生长。现在的问题就是两个选项:静态内存放在哪端;栈是在静态内存的同端还是对端。
2.8.1使用更多的寄存器
问题背景当函数需要的寄存器数量超过8个时,编译器就要使用临时的寄存器。
因为临时的寄存器的寄存器可能放一些值被其他的指令所使用,所以编译器使用临时的寄存器不能留下痕迹(就是要回复原始数据)
这里保存和恢复旧数据使用stack,为了避免保存和恢复一个未使用过的寄存器。
LEGv8将寄存器分为两组:
- X9~X17:不需要保留(调用者负责)
- X19~X28:需要保留(被调用者负责)
2.8.2过程(函数)嵌套
叶过程:不调用其他过程(函数)
如果存在嵌套过程,即A调用B,B调用C。
此时:
- X0X7与X9X17中所使用的寄存器由调用者负责保存
- X19~X25和LR由被调用者负责保存。
2.8.3在Stack中为新数据分配内存
这个讨论的是,Stack中不仅要保存寄存器的值(寄存器的大小是固定的)还要保存局部变量的值(大小是不固定的,INT32bit,Double64bit)。
过程帧(活动记录):Stack中包含过程所保存的的寄存器和局部变量的片段。
帧指针:指向给定过程中的寄存器和局部变量的值。
- 一种的帧指针指向过程的第一双字。
- 另一种是在一个过程中为本地存储器引用提供一个固定的基址。
2.8.4在堆中为新数据分配内存
堆:类似链表这样的数据结构通常会在生命期内增长或者缩短,这类数据结构对应的段。
LEGv8语言中寄存器的使用约定:
2.9人机交互
- LDURB:将字节从内存中读到寄存器的最右边
- STURB:将寄存器最右边八位写入内存中
表示一个字符串的三种方法:
- 保留字符串的第一个位子用于给出字符串的长度(java)
- 附加一个指明字符串长度的变量
- 字符串最后一个位置用一个字符来标识结尾(C语言)
2.10宽立即数和地址寻址。
2.10.1宽立即数
宽立即数用于更多位的常量或地址(因为LEGv8的指令长度限制了常熟或者地址的大小)
设置寄存器中的16位:
- MOVZ:将寄存器剩下的位置置0
- MOVK:将寄存器剩余的位置不变
LSL实现要加载的16位字段。LSL后面的数(加载完16位字段后剩余的位)取决于需要64位双字的那个象限。例如加载到第四象限,那么后面剩下48位。
例如:
| 被载入的寄存器 | 被载入的数字 | 第几位开始载入 | ||
|---|---|---|---|---|
| MOVZ | X9 | 255 | LSL | 16 |
2.10.2分支寻址
B指令的指令格式:
- 分支指令
- 分支和链接指令
| 6bit | 26bit |
|---|
CBZ等条件分支指令和依赖条件码分支指令的格式
| 8bit | 19bit | 5bit |
|---|
$$
程序计数器=寄存器内容+分支地址偏移量
$$
这个计算式表明:19位来表示一个地址可能不够用了,因为一个程序不可能小于2^19。
因此我们要指定一个寄存器将它与分支地址偏移量相加,得到跳转的地址。
这里我们要采用PC寄存器,因为条件分支转移地址倾向于转移到附近的指令。SPEC测试中显示转移的范围来16个字以内(16条指令以内,因为一条指令的长度就是一个字)。运用这个公式我们可以转移到2^18个字内,(只要用逻辑操作将分支偏移量*4 因为LEGv8的地址是按字节编址的)。
条件分支和跳转指令(B)采用PC相对寻址。
分支和链接指令采用其他寻址方式。
2.11并行与指令:同步
同步:一个线程若需要其他线程产生的结果那么它需要停下来等待,就是一个个做。
线程同步:即当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作, 其他线程才能对该内存地址进行操作,而其他线程又处于等待状态,实现线程同步的方法有很多,临界区对象就是其中一种。
例程:某个系统对外提供的功能接口或者服务集合。
lock和unlock可以直接建立互斥区,允许当个处理器操作。
处理器对锁单元加锁的方法使用一个寄存器的1与该锁(锁在临界区里)地址里的值交换,若寄存器为1,表面临界区在被使用,若为0则可以被占用。
同步交换(atomic)由当个不可中断的指令对实现。
指令对:
- LDXR:取出锁值
- STXR:对临界区进行操作。
STXR由两个功能:
STXR X23, X9, [X20] -- Memory[X20] = X23 如果成功x9 = 0否则x9 = 1
- 将存储地址写入X20
- 将X9置为1或者0.
2.12翻译并启动程序
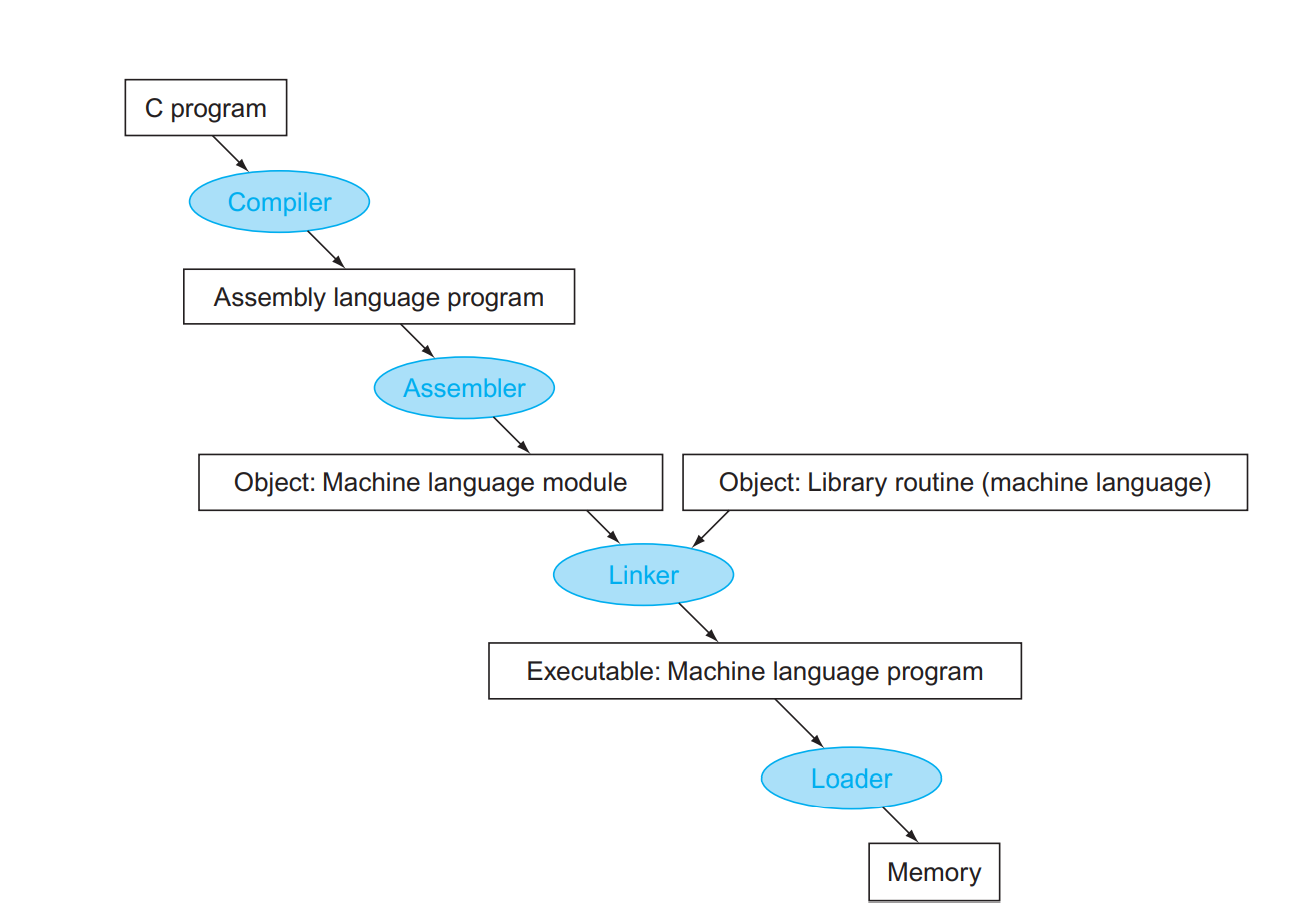
编译器:将高级语言编译为汇编语言
汇编器:可以识别并转换为功能等价的机器语言
目标文件(.o,.obj)包含的内容:
- 目标托文件
- 代码的
- 静态数据段
- 重定位信息
- 符号表 ——程序中出现的(符号和地址)对。
- 调试信息
连接器:将改变代码不需要重新编译所有的,只需要编译和汇编某一行在用连接器缝合。
工作的步骤:
- 将代码和数据块象征性的放入内存。
- 决定数据和指令标签的地址
- 修补内部和外部引用。
连接器可以生成可运行的文件,内容和目标文件差不多,但不包括未解决的引用。
加载器:
- 读取可执行文件头来确定代码段的地址空间
- 为代码和数据创建一个足够大的地址空间
- 将可执行文件的指令和数据复制到内存中
- 把主程序的参数复制到栈中
- 初始化处理器中的相关寄存器,将栈指针指向第一个空位置
- 条状到启动例程,该例程将参数复制到参数寄存器并且调用程序的main函数。

