文件系统
文件系统的布局
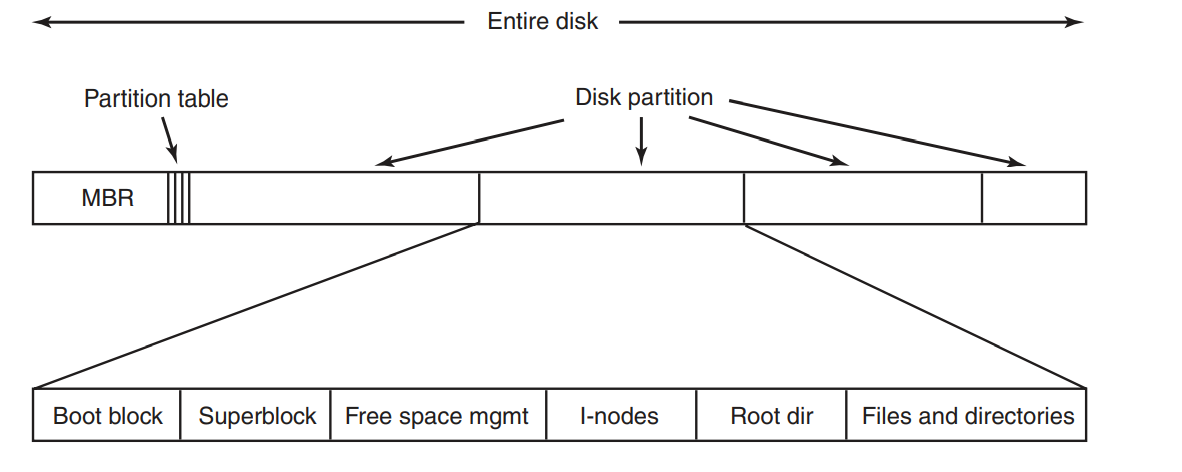
如图,一个磁盘有一个MBR,MBR后面跟随着磁盘的分区表,在计算机启动时,BIOS将MBR载入内存中,并且把CPU的控制权交给MBR,MBR要做的就是确认有多少个活动的分区,并将Boot block载入内存中去执行。
并且一个磁盘可以被分为多个磁盘区,每个磁盘区可能包含Boot block、Superblock等等的块。具体包含哪些块依据不同的文件系统实现而定。
- Boot block是引导计算机启动的时候,将操作系统载入内存中。
- Superblock是文件系统的参数,比如说文件的类型,该分区的磁盘块数其他的管理信息。
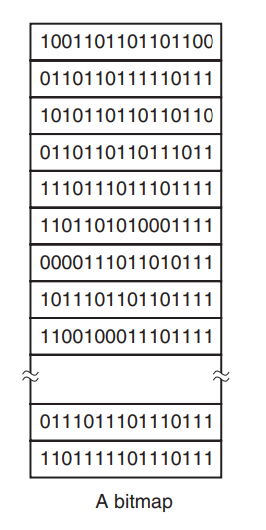
- Free space mgmt是管理磁盘的空闲空间的信息,可以是位图的形式也可以是链表的形式。
- i-nodes是一个数据结构数组,每个文件占一个位置,每个位置说明了文件的信息,比如文件占用哪些磁盘块
- Root dir目录树的根部位置
- Files and directories剩下的就是存放文件和目录了。
文件和目录
文件其实是磁盘地址空间的一个抽象。目录也属于文件。我们可以通过磁盘地址空间的抽象,更容易对磁盘进行数据的存取和其他操作。
但是文件和目录还是有所不同的:
- 文件:是进程创建的信息逻辑单元。也就是我们平时看到的文本文件和可执行文件等等。
- 目录:目录是用来保存文件所在位置信息的,是管理文件系统结构的系统文件。
文件
文件的类型有很多,依据文件系统的设计而定,但是主要的还是普通文件和目录。
普通文件又分为ASCII文件和二进制可执行文件:
-
ASCII文件:就是可读的,通过文本编辑器打开我们可以看到文件里的内容。
-
二进制可执行文件不同,它是一个字节序列。只能通过特定的程序才能使用该文件。
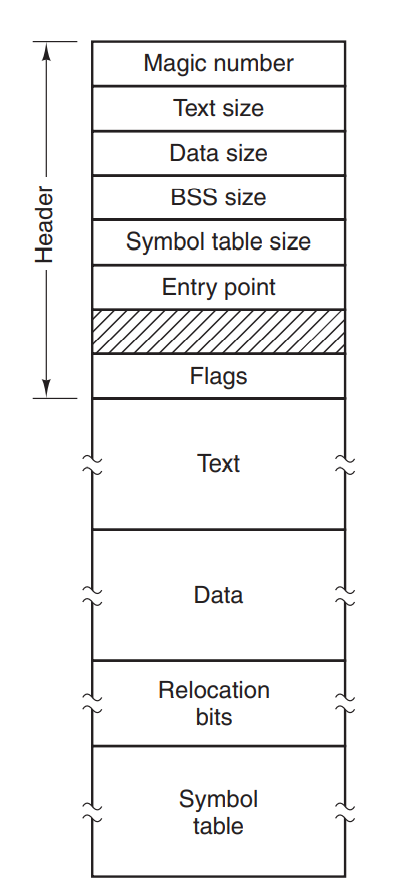
这个文件分为五个段,如图所示,其中:
- magic number是代表这个文件是一个二进制可执行文件。
- Relocation用于程序装入内存时对程序所在实际内存地址的重新定位。
- Symbol table用于程序的调试。
- Entry point是程序的执行入口。
文件的组织方式
-
文件主要以无结构的字节序列来组织,序列具体的含义由相应的进程去解释。
-
还有一种组织文件的结构是,一个文件是一个固定长度记录的序列,每个记录有内部的结构。当我们读操作的时候返回一个记录就是返回一个文件,当我们写操作的是时候在末尾追加一个记录就是追加一个文件,注意,一个文件对应一个记录。
-
记录树形式的文件结构,每个记录(文件)有一个特定的键值,文件的排序按键的字段进行排序,我们可以通过键来寻找特定的文件(这个组织方式用于数据库)。
文件的访问
顺序访问:就是从头开始访问整个文件,如果我们只想要文件的中的部分信息,那么我们就要先读取部分信息前面的哪些信息,即使我们不需要它我们还是需要读取。顺序访问也可以重复的读取文件只要将读取的点返回起点即可。
随机访问:访问我们只想问访问文件的部分,可以跳过我们不限访问的部分。
文件的实现
-
连续分配
在磁盘中找到一个可以容纳文件的连续的磁盘空闲块。 优点:简单易于实现,访问快速. 缺点:容易产生磁盘碎片,就是磁盘空间利用不全。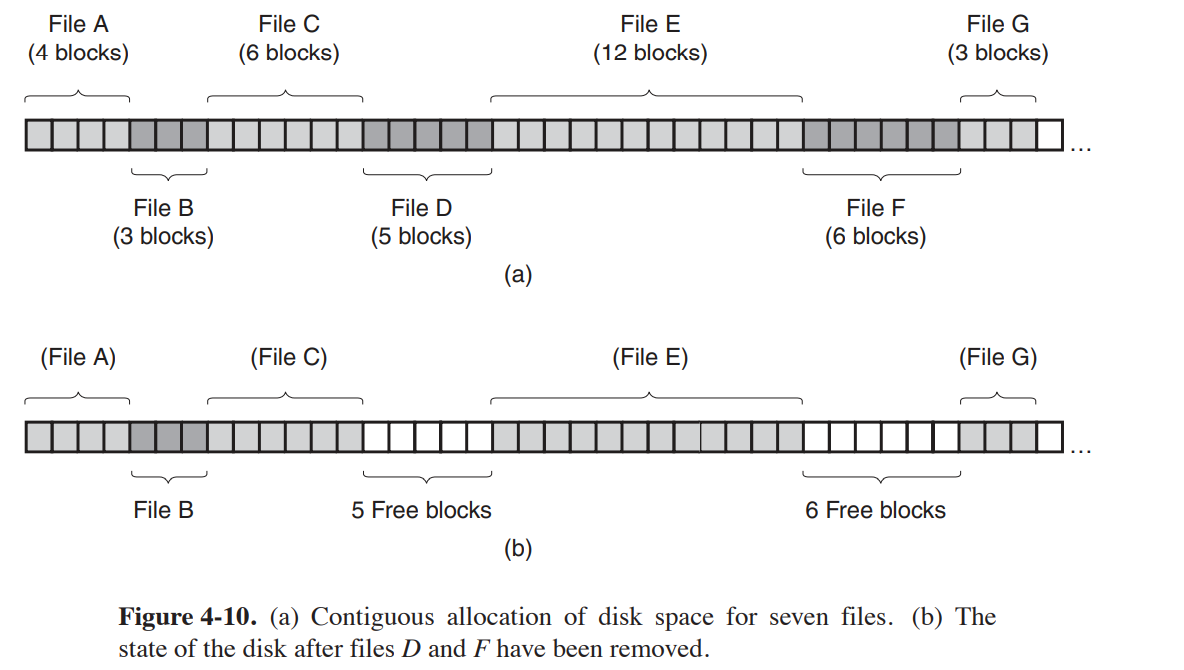
-
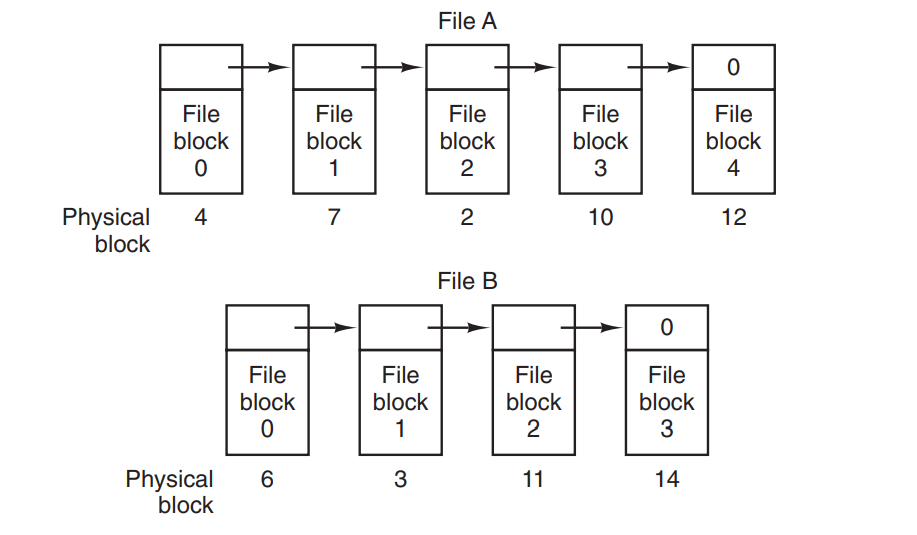
链表分配
一个文件的各部分不用在一起,可以分散到各个空闲块中,通过指针的方式链接所有的磁盘块,组织成一个完整的文件。 优点:提高磁盘空间利用率,减少磁盘碎片。 缺点:访问慢,如果要访问文件的部分信息,就要从文件的第一部分开始找,直到找到我们想要的文件信息。
-
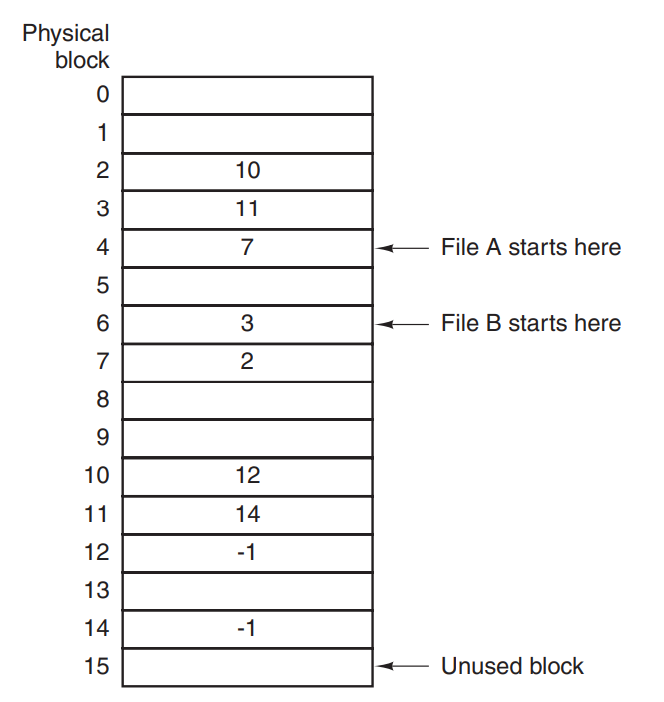
内存中的表进行链表分配
将链表分配方式的指针部分放入内存中的表. 优点:使用这种方式可以避免无法随机访问文件内容的情况,也可以避免由于磁盘块要预留一定空间给指针导致一个块的大小无法全部用来描述文件的部分信息,当我们要读一个块大小的信息的时候,我们就要读两个块,通过信息拼接得到一整个大小的块. 缺点:不过这种方式也有问题,就是内存中存放指向文件表的大小问题,如果文件过多,那么会导致这个表占用过多的内存空间.
-
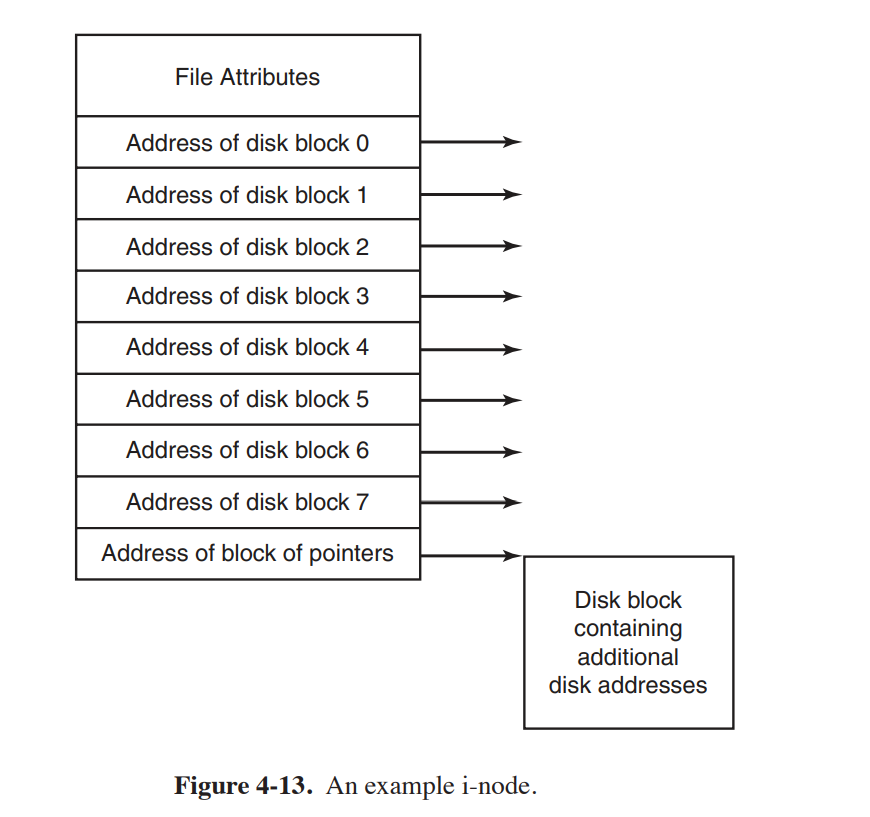
i-nodes
每个i-node包含了关于文件的所有信息,当我们读一个文件的时候,我们可以将文件对应的i-node读入内存中,通过i-node给我们提供的文件在内存中的信息,读取文件的内容。 优点:不会像内存中的表进行链表分配的方式占用大部分内容。 缺点:i-node的大小有限,可能无法包含文件所有磁盘块地址的信息,因此我们需要将最后一个流出来扩展。
目录
目录就是文件夹,作用就是记录文件的位置。
一级目录
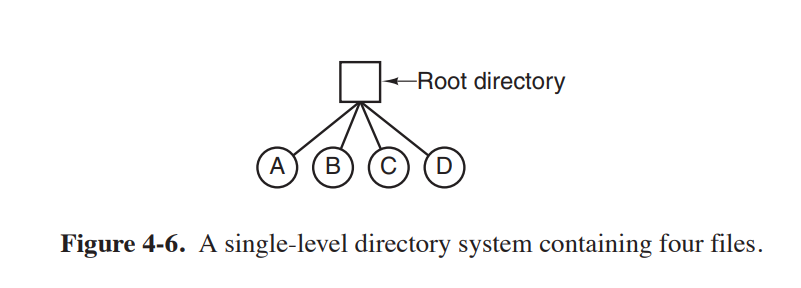
计算只有一个根目录,所有文件存放在根目录上。计算机所有的用户共享一个目录。
多级目录
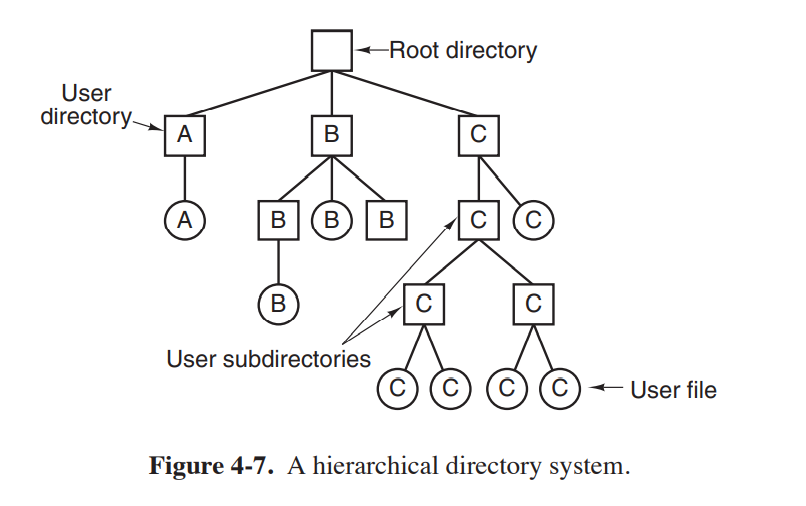
多级目录,可以对文件进行分类,方便检索,如果计算机拥有多个用户,每个用户也可以拥有自己的磁盘空间。
路径
在多级目录的文件系统下,如果要打开一个文件,就要给出文件的具体路径。这个就是绝对路径。
也可以设置工作路径,一般来说就是用户自己的文件下,通过相对于工作文件夹的访问文件的路径是相对路径。
目录的实现
目录的主要功能就是记录该目录下的文件的信息,该目录下的文件可能是目录,也可以是普通文件,那么目录就要给出在这个目录下的文件的磁盘地址。如果我们要访问文件,我们首先有解析用户给的文件路径,通过逐层查找,直到找到文件存在的位置。
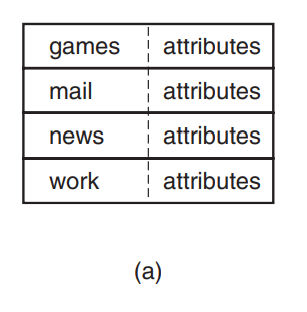
如果文件的名字是定长:
-
目录项(文件名+文件的属性)
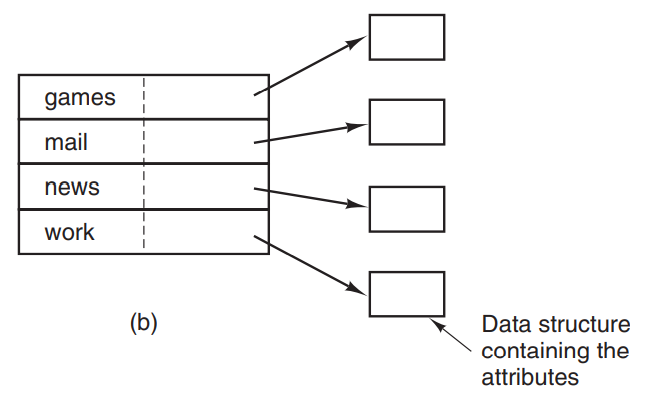
-
目录项(文件名+i-node)
文件名非定长:
就是文件名可能过长,也可能补偿,如果预留太多的位置给文件名,对导致目录过大。
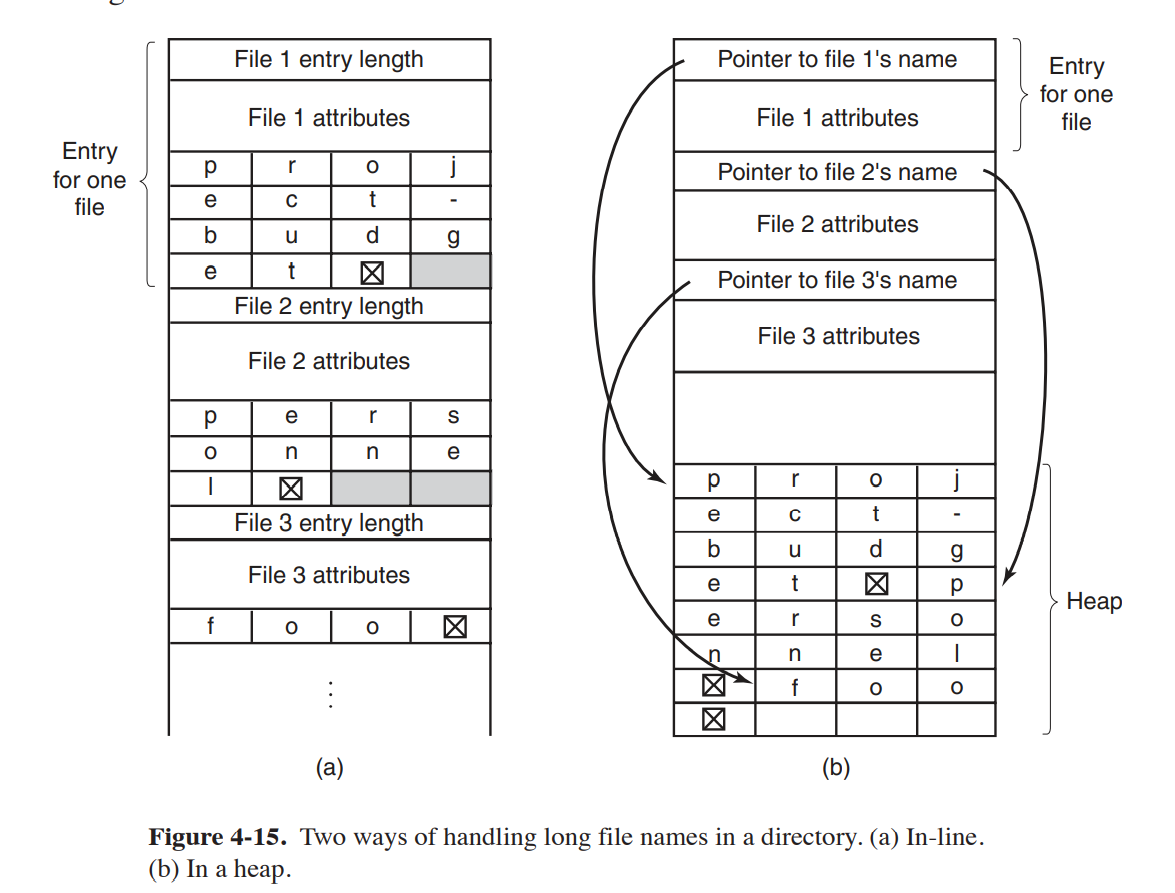
如果按(a)的方式组织目录项,就是将固定长度的段放前面,不定长的文件名放在目录项的后面。
这个方法会浪费空间,如果文件名无法填满整个字的话,就要用其他字符填充。还有就是删除一个目录项是的时候,会导致磁盘碎片,因为所有文件不可能都是同样的大小的。还有一点就是一个目录项目在多个分页上,那么读取文件名的时候,就会导致缺页异常。
(b)的方式组织目录项,就可以避免空间的浪费,但是还是会导致缺页中断。
文件系统
日志结构文件系统
日志文件系统
在操作系统对磁盘做操作之前,先将要执行的操作写入磁盘中的日志项中,写完后才进行对磁盘的操作。这样做是防止设备突然断电或者操作系统崩溃时,导致文件系统的不一致性。
写入日志中的操作一定是要幂等的,就是可以进行重复操作的。例如书上的两个例子:
1.重复查找一个文件并删除一个文件。(幂等操作)
2.把从i节点K新释放的块计入空闲表的末端(非幂等的)
这里先解释下1.为什么是幂等的,因为我们重复查找文件和删除文件不会对文件系统本身带来其他的影响,如果该文件存在就删除(因为它本来就要被删除,只是因为意外没有被删除),但是如果文件不存,删除操作和查找操作就无法进行。不会对文件系统其他部分有任何的影响
但是这里的2.操作就是非幂等的,重复做的操作会对文件系统有影响,举例来说,如果先前释放操作没有完成,那么没问题,做这个操作不会对文件系统有任何的影响,但是如果操作成功了,i节点k可能被分配给了新的文件,那么我们将这i节点k对应的文件释放了将i节点k加入空闲节点表,显然会对文件系统本身照成影响,因为我们对一个本不该删除的文件做了删除的操作。
磁盘操作具有和数据一样的原子事务,就是说一组对磁盘的操作要么都成功要么都失败。
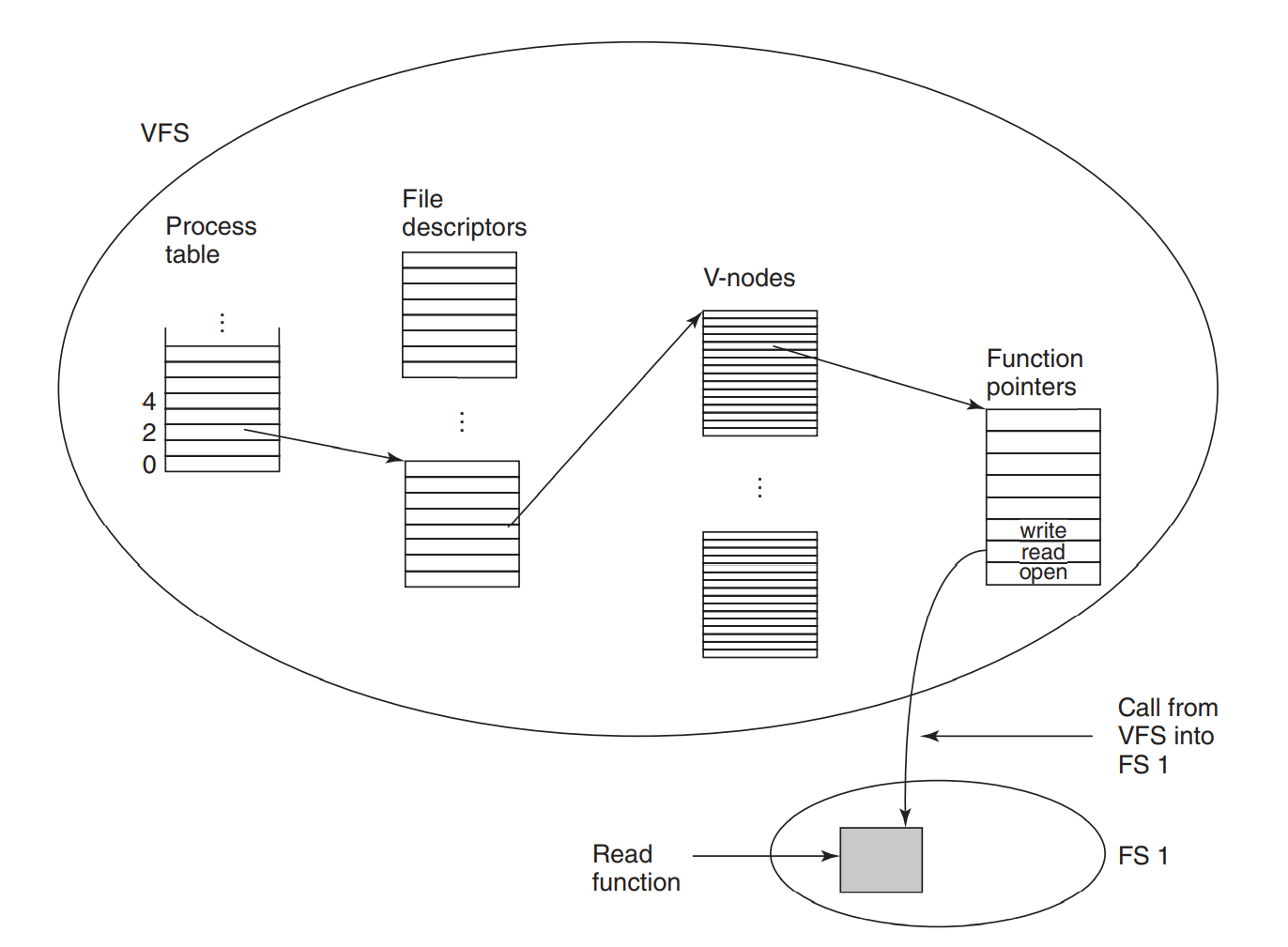
虚拟文件系统
虚拟文件系统的实现和java的JDBC一致。
就是说虚拟文件系统也是对上层用户提供一组API,提供给用户操作文件的可能,但是虚拟文件系统对API的具体实现是交给不同文件系统的实现的者实现的。
这点就是和JDBC中,java为程序员提供一组对数据库的同一操作,而具体操作的实现由数据库开发人员提供。
对于操作系统开发人员来说,这个简化了对操作文件功能的实现,对于java程序员来说这个简化了他们对操作数据库的功能实现。
虚拟文件系统就好比一个抽象类,任何想要挂载到这个操作系统的文件系统就要实现这个抽象类。
文件系统有几个内部类,Superblock,v-node,目录。
当文件系统注册到虚拟文件系统上是,文件系统为VFS提供一组操作该文件系统的具体实现,这个就是上面说的,如果一个文件系统要挂载到操作系统上是,就要实现抽象类。所以VFS就知道了怎么从这个文件系统中读一个文件。
当VFS解析一个路径时,首先通过已经装载文件系统的超快表中找到相应的文件系统,然后找到该文件系统对应的根目录,就可以进行下一步的路径解析,这是VFS创建v-node(这个v-node是在内存中的),然后找到对应文件的i-node,将i-node的信息和对该文件的操作函数的地址向量一直封装到v-node中。VFS在文件描述符中创建一个项用来存放指向这个v-node的指针。最后VFS向调用者(进程)返回指向改文件描述符的指针。进程就可以通过文件描述符对文件进行操作。
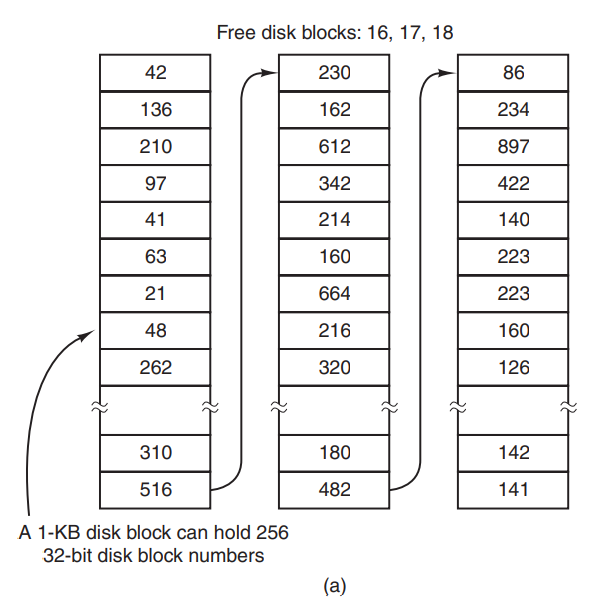
空闲块的管理
其实空闲块的管理和内存中空闲地址空间的管理是一致的,都是通过链表或者位图法。
磁盘块链表方式
通过使用空闲块来记录空闲块的块号,为了尽量的减少占用空闲块的个数,我们就要尽量多的在一个空闲块中塞入空闲块号.
位图法
用n位位图来表示磁盘中n个块的使用情况,空闲块用1表示,非空闲块用0表示。