
线程池-线程池的好处
1.线程池的好处。
线程使应用能够更加充分合理的协调利用cpu 、内存、网络、i/o等系统资源。
线程的创建需要开辟虚拟机栈,本地方法栈、程序计数器等线程私有的内存空间。
在线程的销毁时需要回收这些系统资源。频繁的创建和销毁线程会浪费大量的系统资源,增加并发编程的风险。
另外,在服务器负载过大的时候,如何让新的线程等待或者友好的拒绝服务?这些丢失线程自身无法解决的。所以需要通过线程池协调多个线程,并实现类似主次线程隔离、定时执行、周期执行等任务。线程池的作用包括:
- 利用线程池管理并复用线程、控制最大并发数等。
- 实现任务线程队列缓存策略和拒绝机制。
- 实现某些与时间相关的功能,如定时执行、周期执行等。
- 隔离线程环境。比如,交易服务和搜索服务在同一台服务器上,分别开启两个线程池,交易线程的资源消耗明显要大;因此,通过配置独立的线程池,将较慢的交易服务与搜索服务隔开,避免个服务线程互相影响。
在了解线程池的基本作用后,我们学习一下线程池是如何创建线程的。首先从ThreadPoolExecutor构造方法讲起,学习如何定义ThreadFectory和RejectExecutionHandler,并编写一个最简单的线程池示例。然后,通过分析ThreadPoolExecutor的execute和addWorker两个核心方法,学习如何把任务线程加入到线程池中运行。ThreadPoolExecutor的构造方法如下:
1 public ThreadPoolExecutor( 2 int corePoolSize, //第1个参数 3 int maximumPoolSize, //第2个参数 4 long keepAliveTime, //第3个参数 5 TimeUnit unit, //第4个参数 6 BlockingQueue<Runnable> workQueue, //第5个参数 7 ThreadFactory threadFactory, //第6个参数 8 RejectedExecutionHandler handler) { //第7个参数 9 if (corePoolSize < 0 || 10 maximumPoolSize <= 0 || 11 maximumPoolSize < corePoolSize || 12 keepAliveTime < 0) // 第一处 13 throw new IllegalArgumentException(); 14 if (workQueue == null || threadFactory == null || handler == null)//第二处 15 throw new NullPointerException(); 16 this.corePoolSize = corePoolSize; 17 this.maximumPoolSize = maximumPoolSize; 18 this.workQueue = workQueue; 19 this.keepAliveTime = unit.toNanos(keepAliveTime); 20 this.threadFactory = threadFactory; 21 this.handler = handler; 22 }
- 第1个参数 :corePoolSize 表示常驻核心线程数。如果等于0,则任务执行完成后,没有任何请求进入时销毁线程池的线程;如果大于0,即使本地任务执行完毕,核心线程也不会被销毁。这个值的设置非常关键,设置过大会浪费资源,设置的过小会导致线程频繁地创建或销毁。
- 第2个参数:maximumPoolSize 表示线程池能够容纳同时执行的最大线程数。从上方的示例代码中第一处来看,必须大于或等于1。如果待执行的线程数大于此值,需要借助第5个参数的帮助。缓存在队列中。如果maximumPoolSize 与corePoolSize 相等,即是固定大小线程池。
- 第3个参数:keepAliveTime 表示线程池中的线程空闲时间,当空闲时间达到KeepAliveTime 值时,线程被销毁,直到剩下corePoolSize 个线程为止,避免浪费内存和句柄资源。在默认情况下,当线程池的线程大于corePoolSize 时,keepAliveTime 才会起作用。但是ThreadPoolExecutor的allowCoreThreadTimeOut 变量设置为ture时,核心线程超时后也会被回收。
- 第4个参数:TimeUnit 表示时间单位。keepAliveTime 的时间单位通常是TimeUnit.SECONDS。
- 第5个参数: workQueue 表示缓存队列。当请求的线程数大于maximumPoolSize时,线程进入BlockingQueue 阻塞队列。后续示例代码中使用的LinkedBlockingQueue 是单向链表,使用锁来控制入队和出对的原子性,两个锁分别控制元素的添加和获取,是一个生产消费模型队列。
- 第6个参数:threadFactory 表示线程工厂。它用来生产一组相同任务的线程。线程池的命名是通过给这个factory增加组名前缀来实现的。在虚拟机栈分析时,就可以知道线程任务是由哪个线程工厂产生的。
- 第7个参数:handler 表示执行拒绝策略的对象。当超过第5个参数workQueue的任务缓存区上限的时候,就可以通过该策略处理请求,这是一种简单的限流保护。友好的拒绝策略可以使如下三种:
- 保存到数据库进行削峰填谷。在空闲的时候再拿出来执行。
- 转向某个提示页面。
- 打印日志。
从代码第2处来看,队列、线程工程、拒绝处理服务都必须有实例对象,但在实际编码中,很少有程序员对着三者进行实例化,而通过Executors这个线程池静态工厂提供默认实现,那么Executors与ThreadPoolExecutor 是什么关系呢?线程池相关的类图
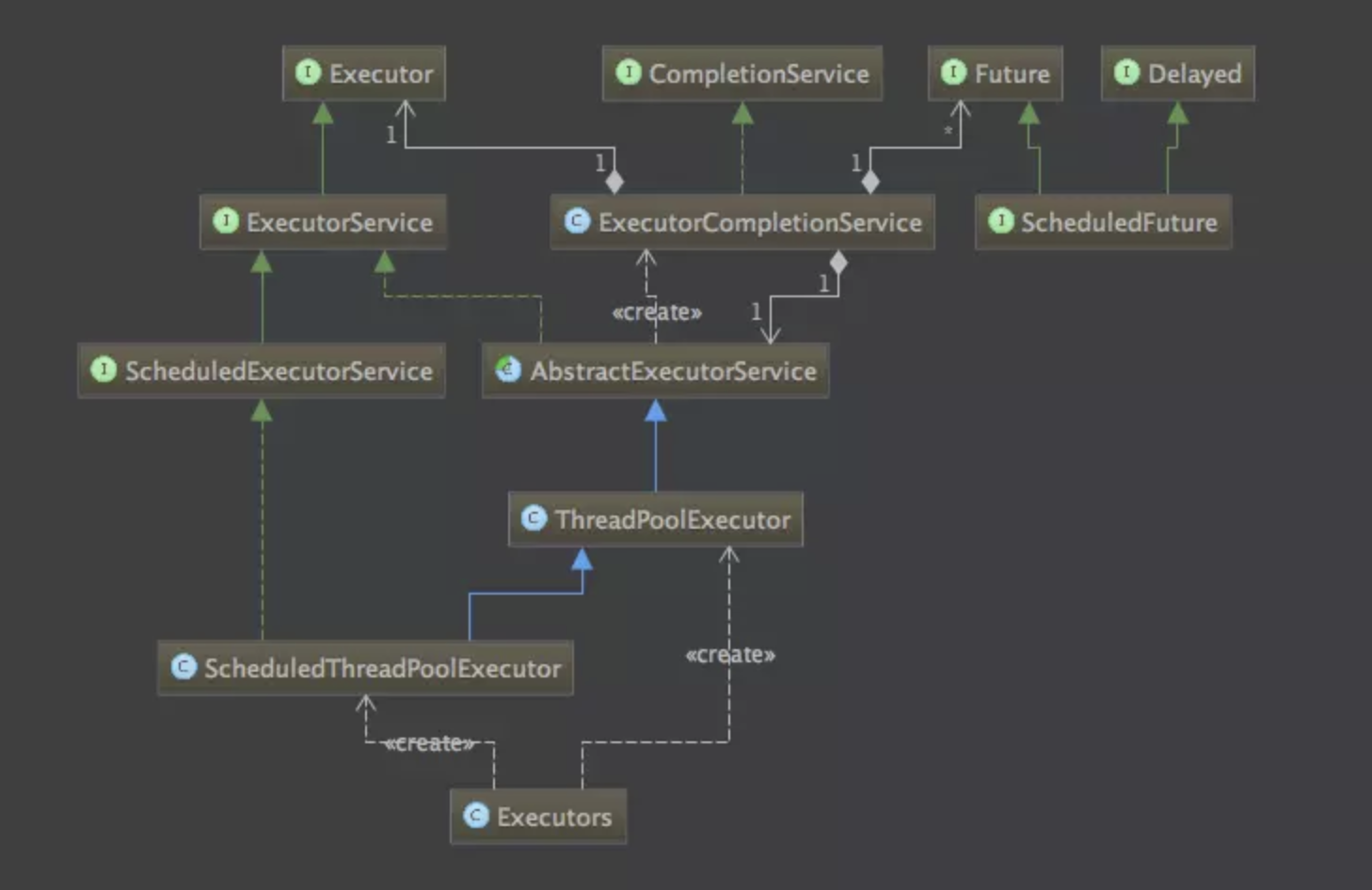
ExecutorService接口继承了Executor接口,定义了管理线程任务的方法。ExecutorService 的抽象类AbstractExecutorService 提供了 submit()、invokeAll()等部分方法的实现,但是核心方法Executor.execute() 并没有在这里实现。因为所有的任务都在这个方法里执行,不同的实现会带来不同的执行策略,这一点在后续的ThreadPoolExecutor解析时,会一步步分析。通过Executor的静态工厂方法可以创建三个线程池的包装对象:ForkJoinPool、ThreadPoolExecutor、ScheduledThreadPoolExecutor。Executors核心方法有5个:
- Executors.newWorkStealingPool:JDK8 引入,创建持有足够线程的线程池,支持给定的并行堵,并通过使用对个队列减少竞争,此构造方法中把cpu的数量设置为模型的并行度:
1 /** 2 * Creates a work-stealing thread pool using all 3 * {@link Runtime#availableProcessors available processors} 4 * as its target parallelism level. 5 * @return the newly created thread pool 6 * @see #newWorkStealingPool(int) 7 * @since 1.8 8 */ 9 public static ExecutorService newWorkStealingPool() { 10 return new ForkJoinPool 11 (Runtime.getRuntime().availableProcessors(), 12 ForkJoinPool.defaultForkJoinWorkerThreadFactory, 13 null, true); 14 }
- Executors.newCachedThreadPool : maximumPoolSize 最大可以至Integer.MAX_VALUE,是高度可以伸缩的线程池,如果达到这个上限,相信没有任何服务器能够继续工作,肯定会抛出OOM异常。keepAliveTime默认为60秒,工作线程处于空闲状态,则回收工作线程。如果任务书增加,再次创建新的线程处理任务。
- Executors.new ScheduledThreadPool: 线程最大至Integer.MAX_VALUE ,与上述相同,存在OOM风险。它是ScheduledExecutorService 接口家族的实现类,支持定时及周期性任务执行。相比Timer,ScheduledExextuorService 更安全,功能更强大,与newCachedThreadExecutor 的区别是不回收工作线程。
- Executors.newSingleThreadExecutor:创建一个单线程的线程池,相当月单线程串行执行所有任务,保证按任务提交的顺序依次执行。
- Executors.newFixedThreadPool: 输入的参数即是固定线程数,既是核心线程数也是最大线程数,不存在空闲线程,所有keepAliveTime 等于0:
1 public static ExecutorService newFixedThreadPool(int nThreads) { 2 return new ThreadPoolExecutor(nThreads, nThreads, 3 0L, TimeUnit.MILLISECONDS, 4 new LinkedBlockingQueue<Runnable>()); 5 }
这里,输入的队列没有指明长度,下面介绍LinkedBlockingQueue的构造方法。
1 public LinkedBlockingQueue() { 2 this(Integer.MAX_VALUE); 3 }
使用这样的无界队列,如果瞬间请求非常大,会有OOM的风险。除newWorkStealingPool 外,其他四个创建方式都存在资源耗尽的风险。
Executors 中默认的线程工程和拒绝策略过于简单,通常对用户不够友好。线程工厂需要做创建前的准备工作,对线程池创建的线程必须明确标识,就像药品的生产批号一样,为线程本身指定有意思的名称和相应的序列号。拒绝策略应该考虑到业务场景返回相应的提示或者友好的跳转 1 public class UserThreadFactory implements ThreadFactory { 2 private final String namePrefix;
3 private final AtomicInteger nextId = new AtomicInteger(); 4 //定义线程组名称,在使用jstack 来排查问题是,非常有帮助 5 UserThreadFactory(String whatFeatureOfGroup){ 6 namePrefix = "UserThreadFactory's"+whatFeatureOfGroup+"-Worker-"; 7 } 8 9 @Override 10 public Thread newThread(Runnable task){ 11 String name = namePrefix+ nextId.getAndIncrement(); 12 Thread thread = new Thread(null,task,name,0);
//打印threadname 13 return thread; 14 } 15 16 public static void main(String[] args) { 17 UserThreadFactory threadFactory = new UserThreadFactory("你好"); 18 String ss = threadFactory.namePrefix; 19 Task task = new Task(ss); 20 Thread thread = null; 21 for(int i = 0; i < 10; i++) { 22 thread = threadFactory.newThread(task); 23 thread.start(); 24 } 25 26 } 27 } 28 29 class Task implements Runnable{ 30 String poolname; 31 Task(String poolname){ 32 this.poolname = poolname; 33 } 34 private final AtomicLong count = new AtomicLong(); 35 36 @Override 37 public void run(){ 38 System.out.println(poolname+"_running_"+ count.getAndIncrement()); 39 } 40 }
上述示例包括线程工厂和任务执行体的定义,通过newThread 方法快速、统一地创建线程任务,强调线程一定要是欧特定的意义和名称,方便出错时回溯。
下面简单地实现一下RejectedExecutionHandler,实现了接口的rejectExecution方法,打印当前线程池状态,源码如下。
1 public class UserRejectHandler implements RejectedExecutionHandler { 2 3 @Override 4 public void rejectedExecution(Runnable task, ThreadPoolExecutor executor){ 5 System.out.println("task rejected."+ executor.toString()); 6 } 7 }
在ThreadPoolExecutor 中提供了4个公开的内部静态类:
- AbortPolicy (默认):丢弃任务并抛出RejectExecutionException 异常。
- DiscardPolicy:丢弃任务,但是不抛出异常,这是不推荐的做法。
- DiscardOldestPolicy : 抛弃队列中等待最久的任务,然后把当前任务加入队列中。
- CallerRunsPolicy : 调用任务的run方法绕过线程池直接执行。
根据之前实现的线程工厂和拒绝策略,线程池的相关代码实现如下:
public class UserThreadPool { public static void main(String[] args) { BlockingQueue queue = new LinkedBlockingQueue(2); UserThreadFactory f1 = new UserThreadFactory("第一机房"); UserThreadFactory f2 = new UserThreadFactory("第二机房"); UserRejectHandler handler = new UserRejectHandler(); ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(1,2,60, TimeUnit.SECONDS,queue,f1,handler); ThreadPoolExecutor threadPoolExecutor2 = new ThreadPoolExecutor(1,2,60, TimeUnit.SECONDS,queue,f2,handler); Runnable task1 = new Task(""); for (int i = 0;i<200;i++){ threadPoolExecutor.execute(task1); threadPoolExecutor2.execute(task1); } } }
当任务被拒绝的时候,拒绝策略会打印出当前线程池的大小以及达到了maximumPoolSize=2 ,且队列已满。
我的博客即将同步至腾讯云+社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=5cjrpedpyda8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号