
声纹识别SR学习
声纹模型基础
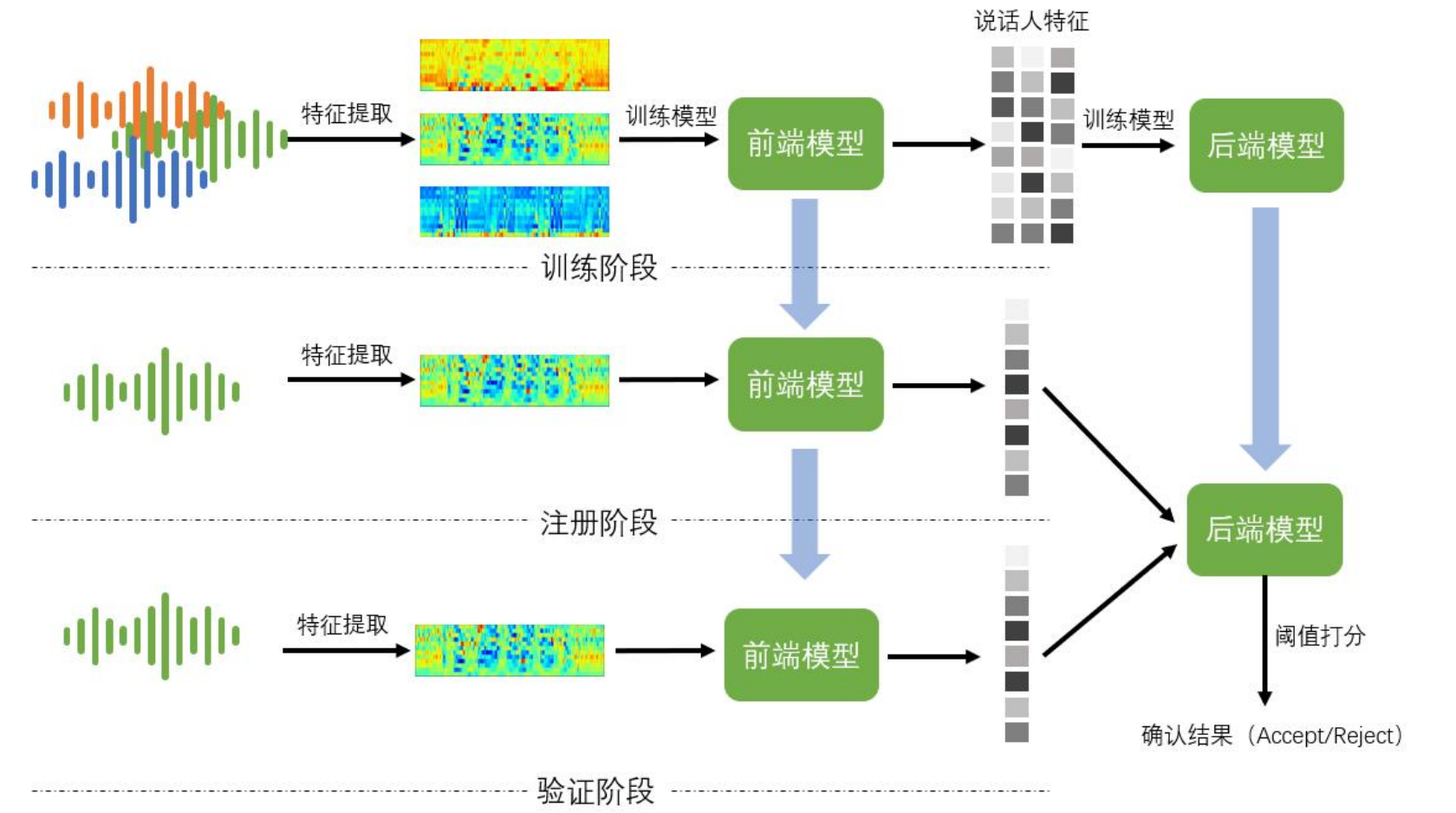
训练、推理的流程框架
ASV简介
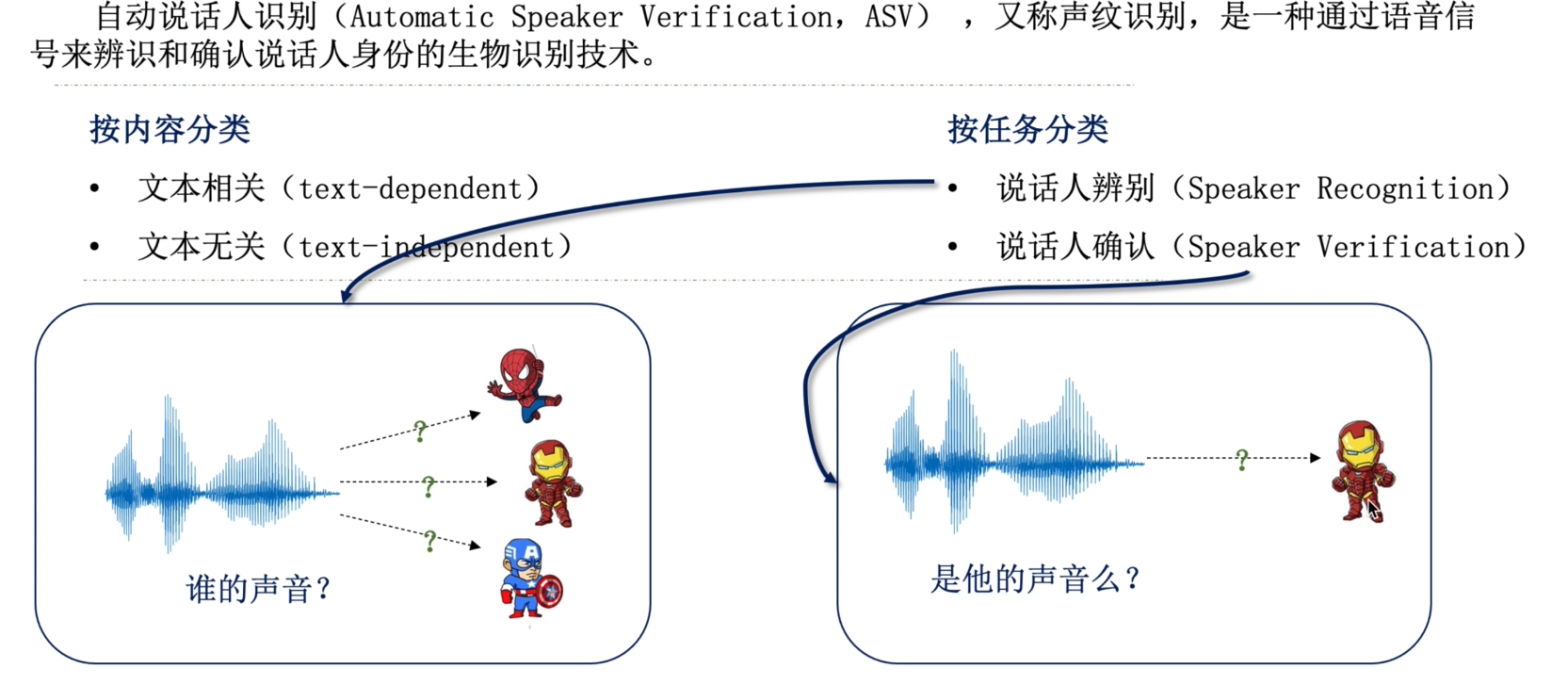
关联任务
- 说话人日志(Speaker diarisation)通过声纹识别把说话人身份表示出来,采访、庭审
- 特定说话人分离 (Target speaker separation)机器在嘈杂场景能听到想听的人的声音
- 特定说话人合成/变声 (Target speaker synthesis/voice conversion)地图导航、私人语音助手
- 目标说话人语音识别 (Target speaker ASR)
- 语音分类任务(Speech Classification)
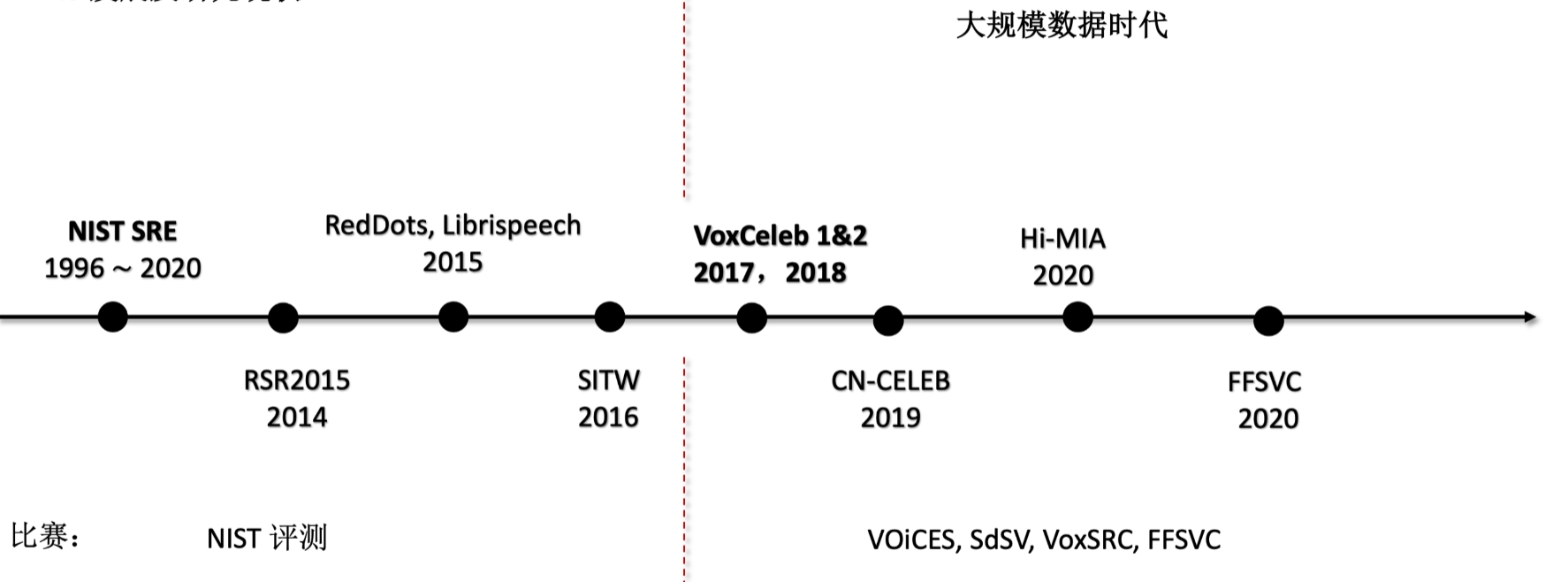
发展历史
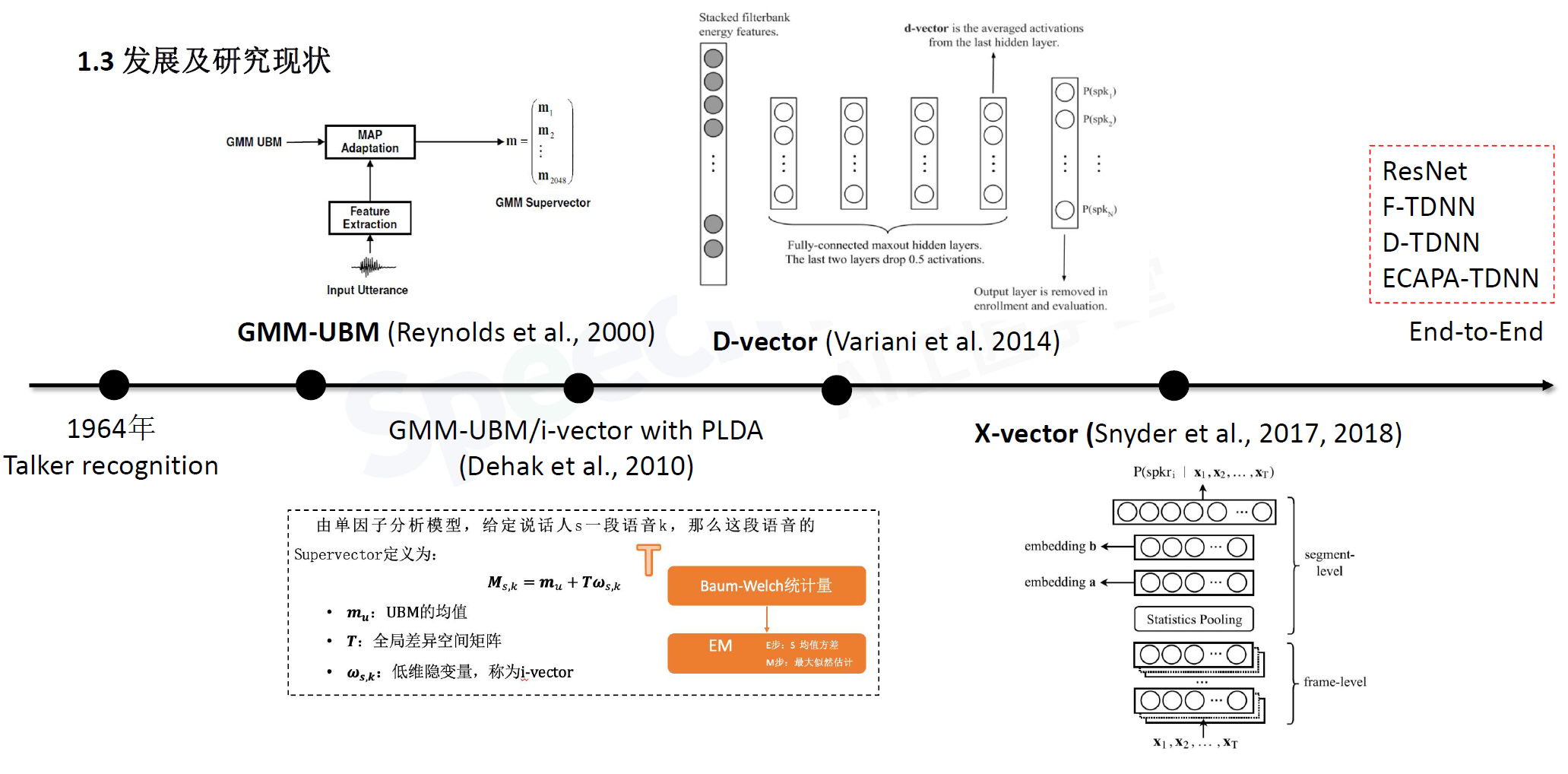
传统的说话人识别系统对比端到端的说话人识别系统
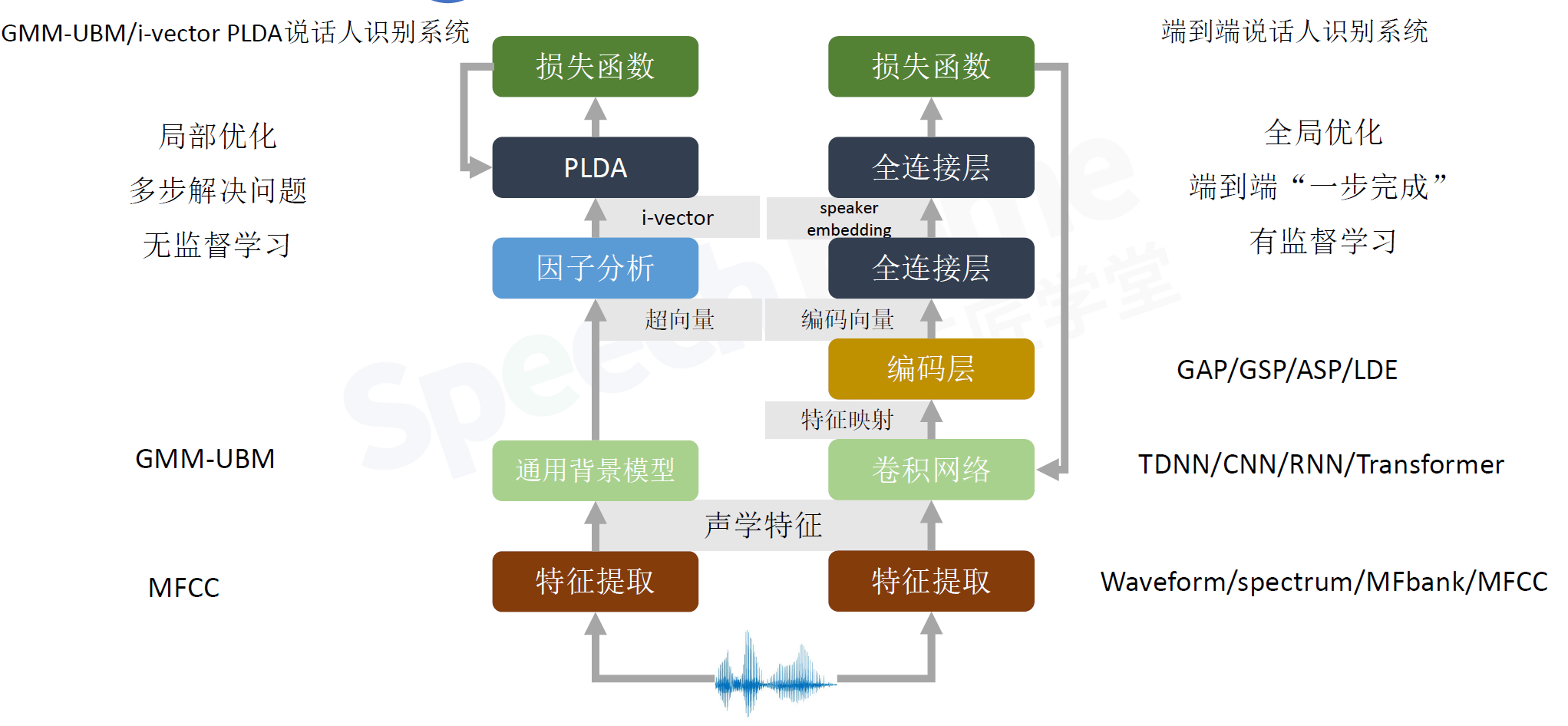
编码层:将不定长的语音得到定长的向量,一般用到pooling层,全局的pooling,全局平均、全局池化
声纹识别数据及工具包
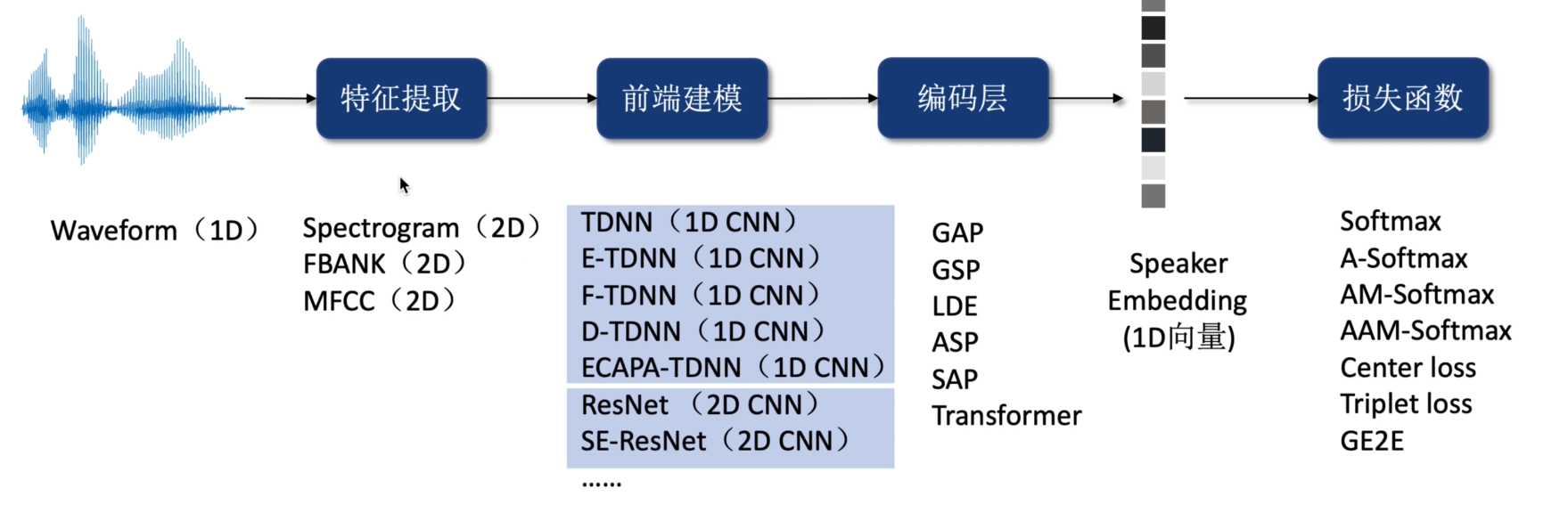
端到端说话人识别
1.模型框架
2.特征提取
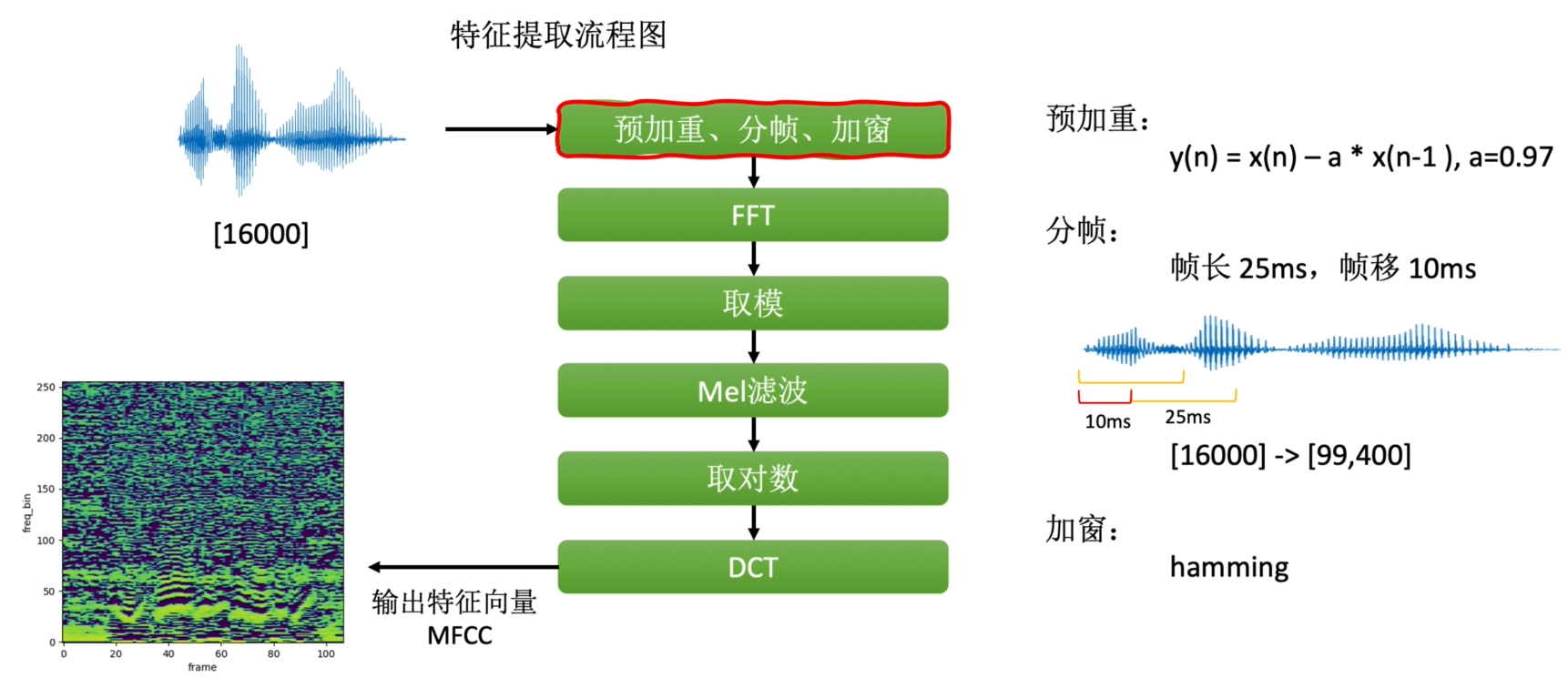
预加重:补偿高频分量损失
分帧:语音信号非平稳,FFT的输入要求是平稳信号,25ms=0.025s ×16000=400个采样点
加窗:频谱泄露
FFT:通常采样点512 变成频域信号
取模:得到Spectrogram 频谱图
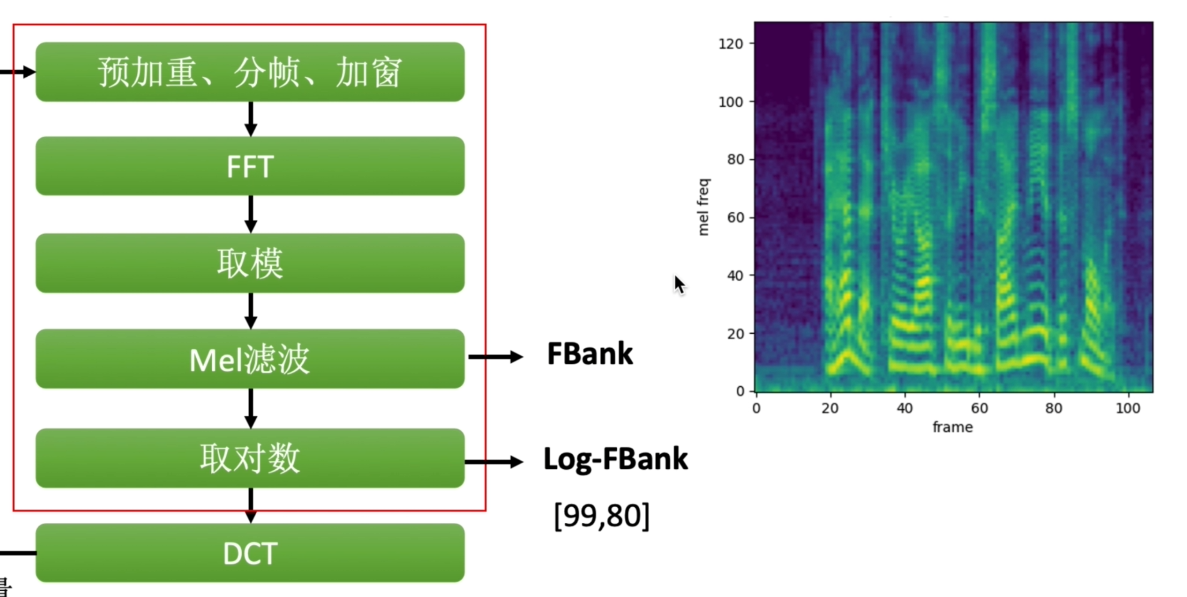
Mel滤波:Spectrogram线性图,而人耳信号是非线性的,将线性谱映射到非线性谱 得到FBank,常用于说话人识别
取对数:得到对数FBank
DCT:离散余弦变换,得到输出特征向量MFCC,常用于ASR
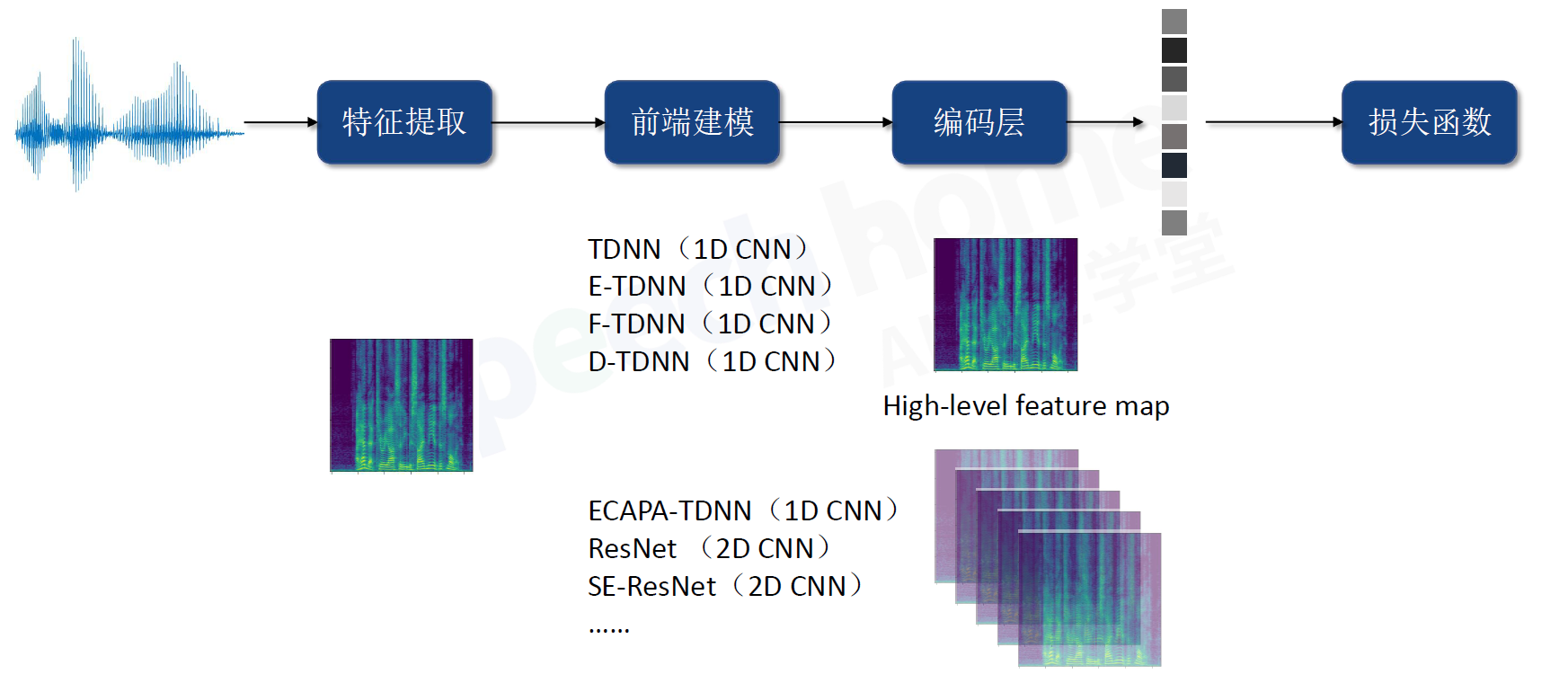
3.前端建模
3.1 D-Vector
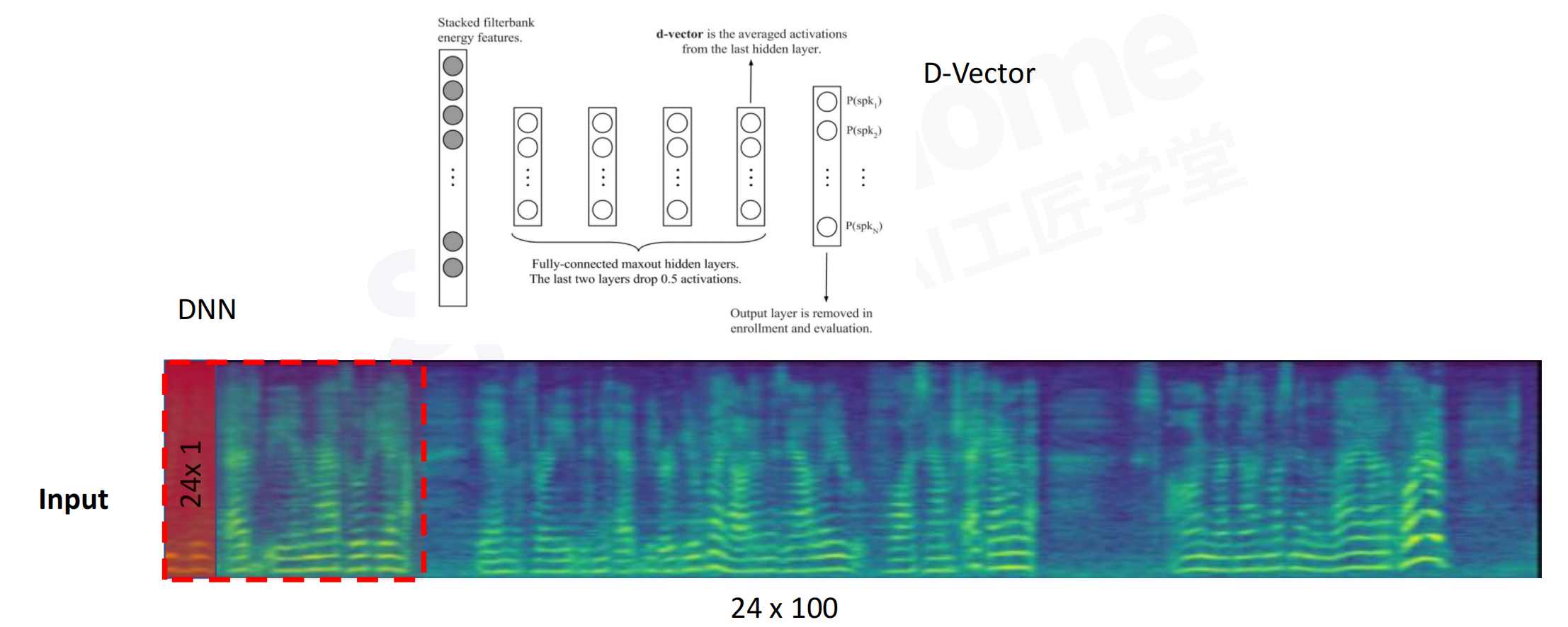
D-Vector:只考虑当前帧的一个信息,每一帧都过全连接层,最后做average,得到embedding
3.2 X-VECTORS(TDNN)
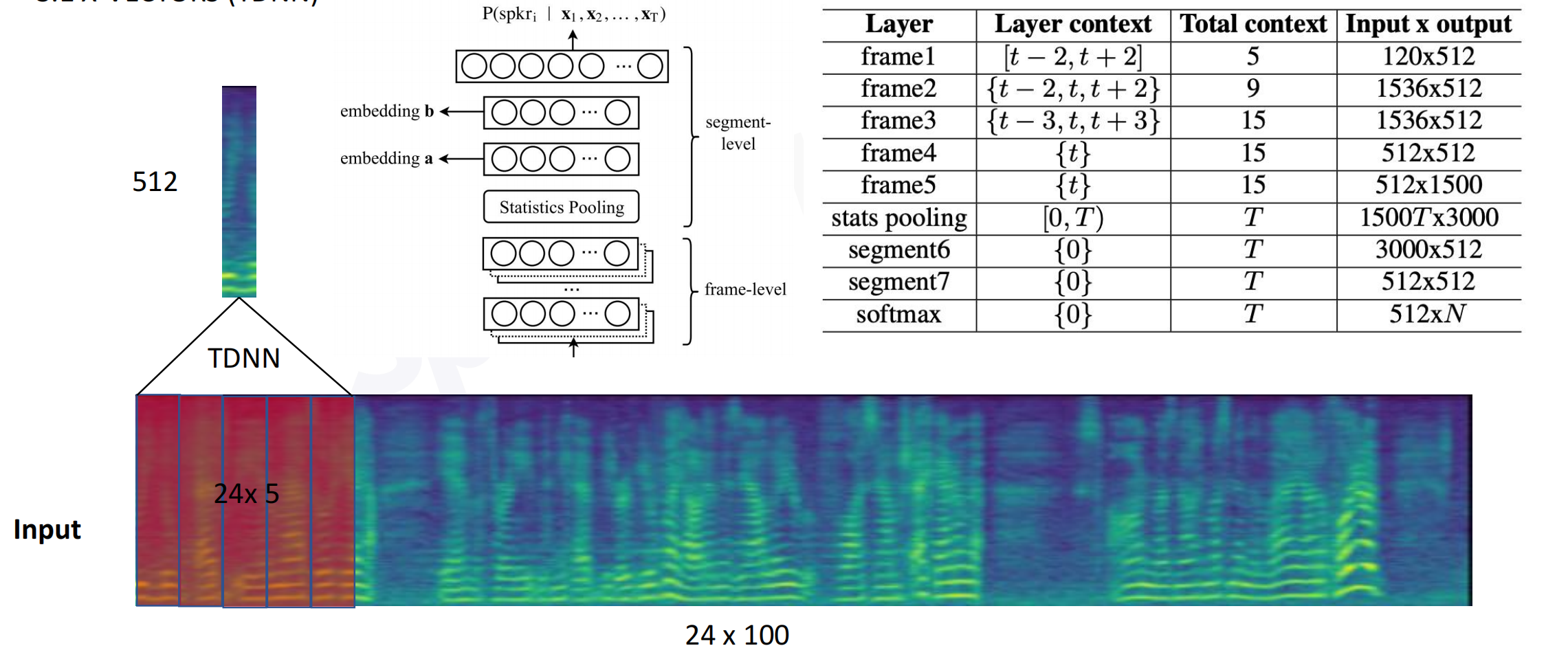
模型框架分为两部分,frame-level帧级别建模,segment-level段级别建模
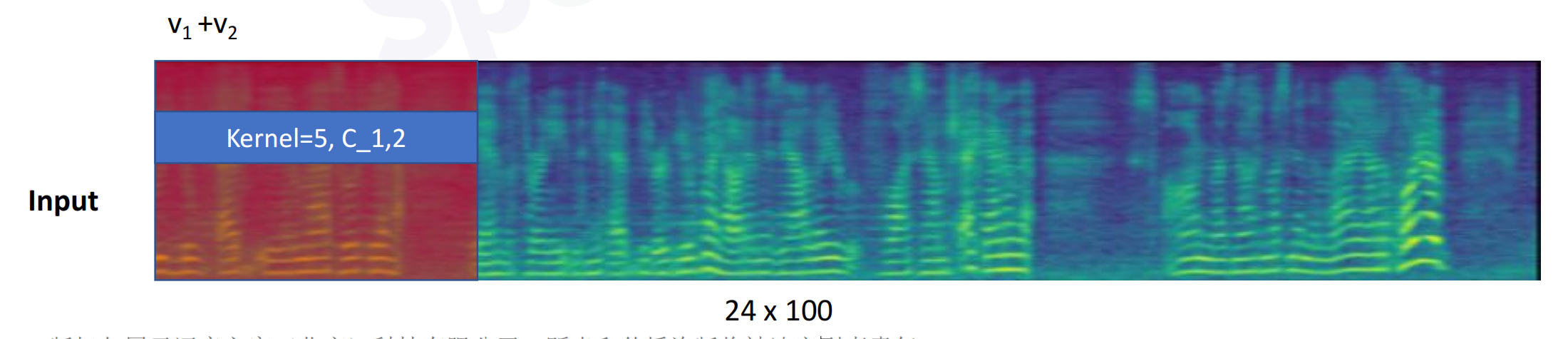
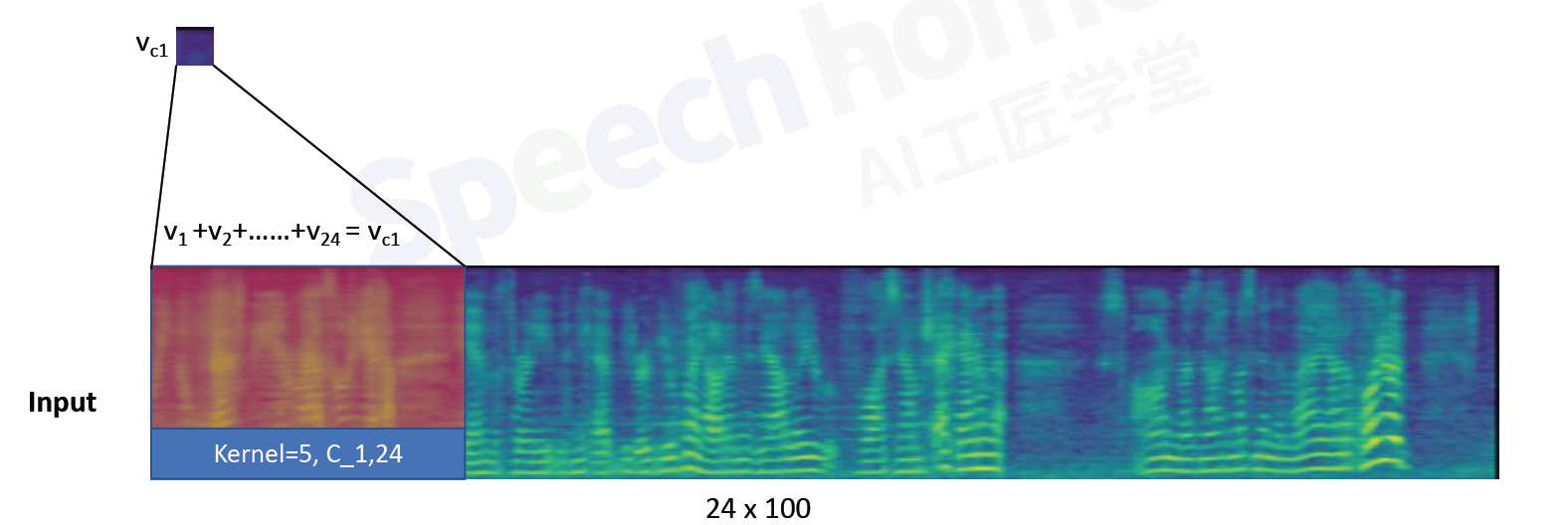
frame1:包含5帧的信息,既有当前帧,也有前后几帧。输入经过全连接层得到512维向量,再滑动平移
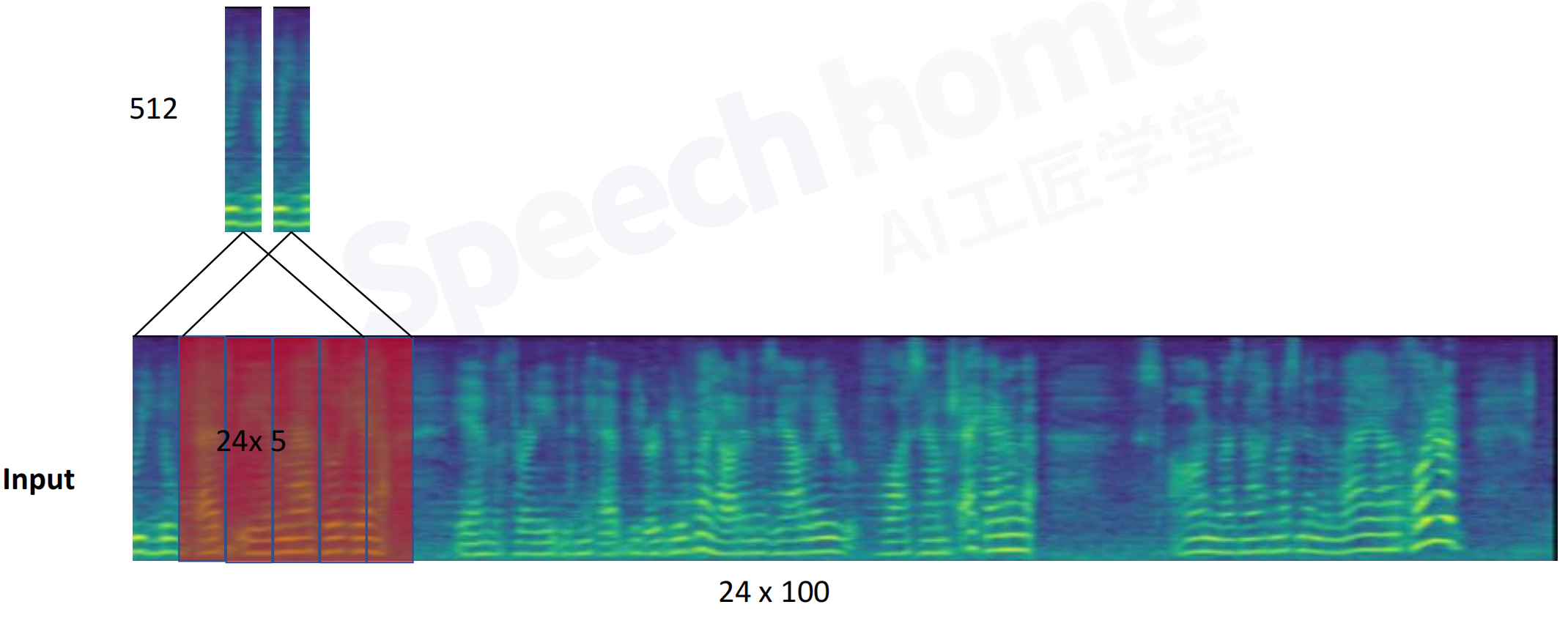
TDNN时延神经网络=1维的卷积神经网络1D CNN:考虑上下语音的信息
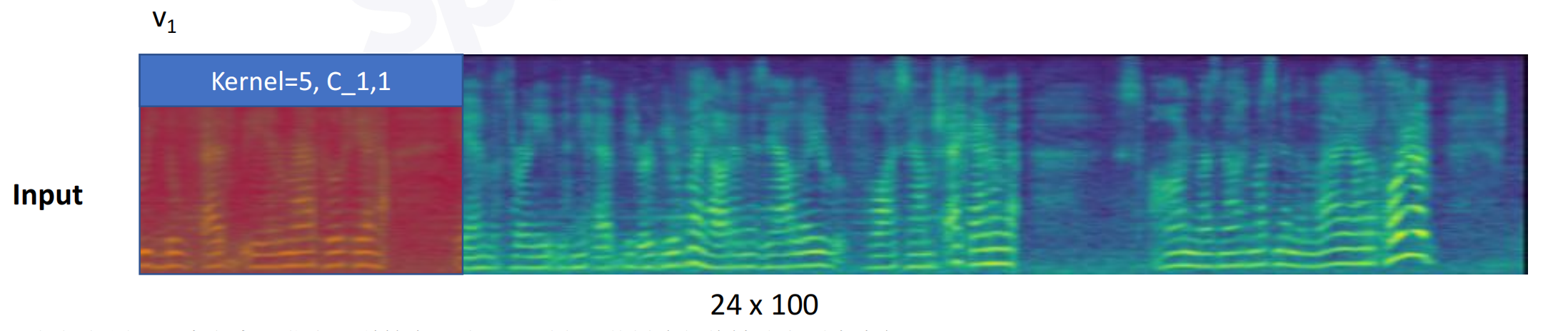
一维卷积(单通道):时间轴上滑动


一维卷积(多通道)
24个channel进行卷积,求和

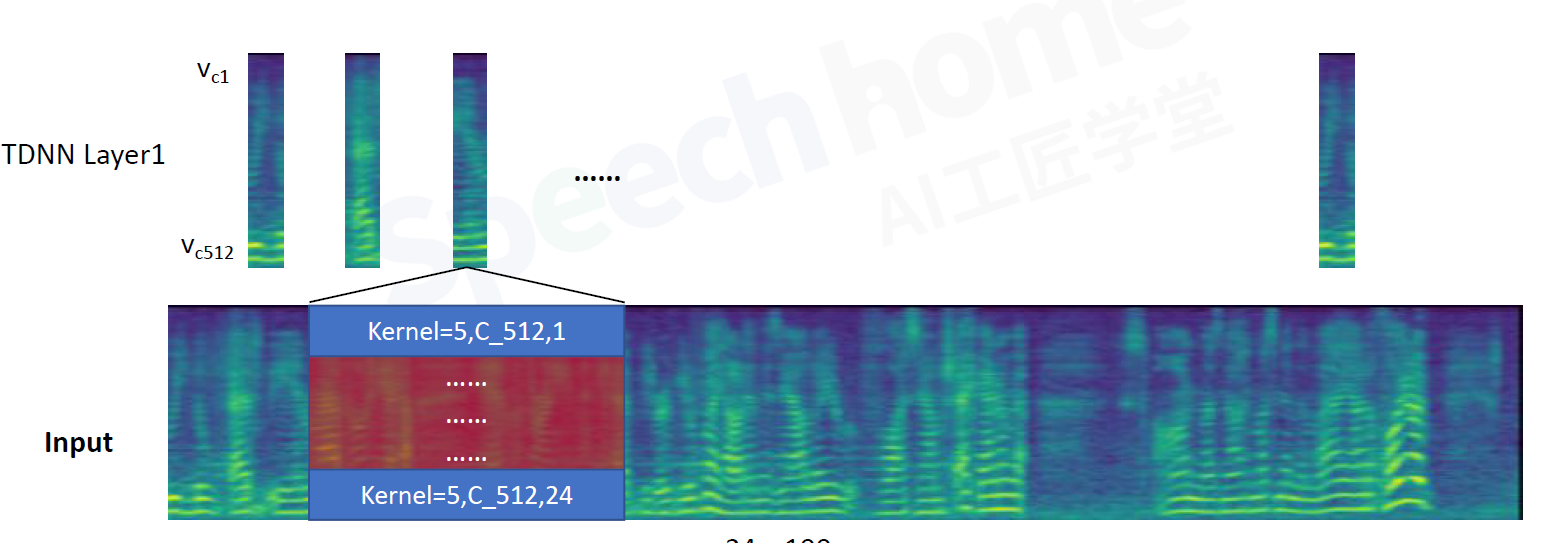
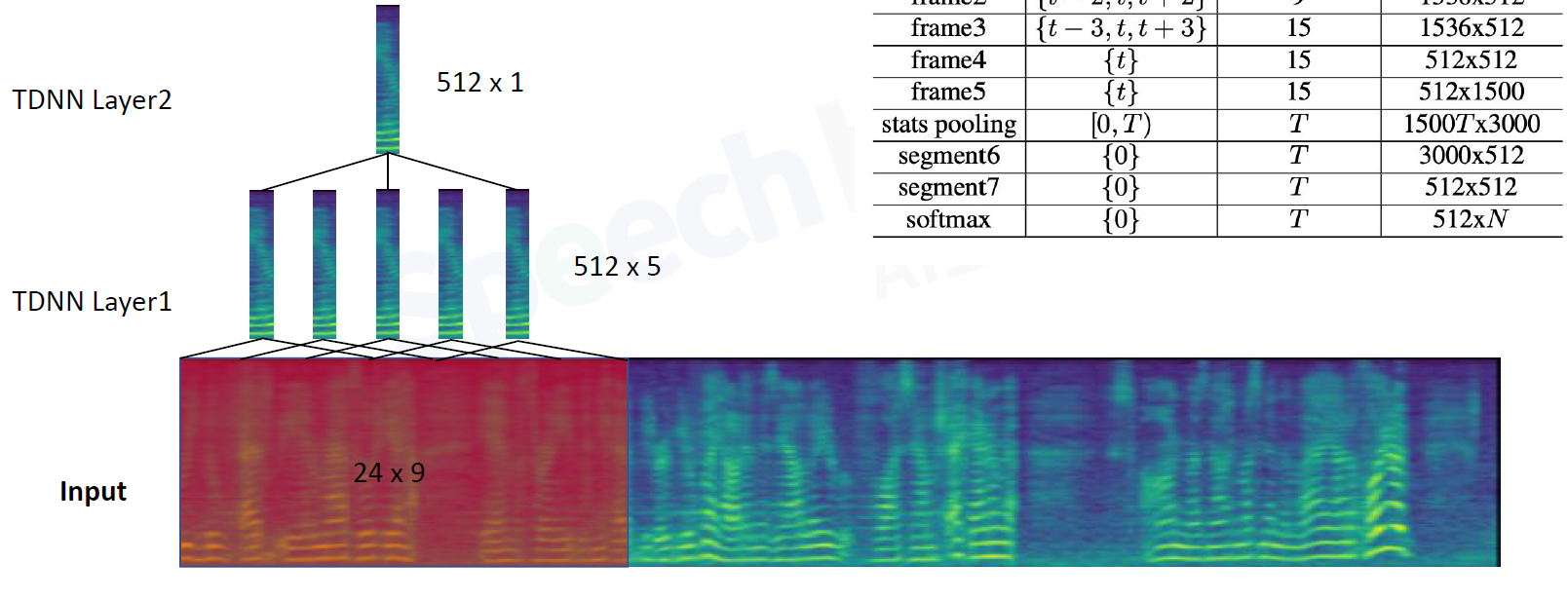
frame2:当前帧5帧,前2帧,后2帧,共9帧
frame3:当前帧9帧,前3帧,后3帧,共15帧.此时layer3
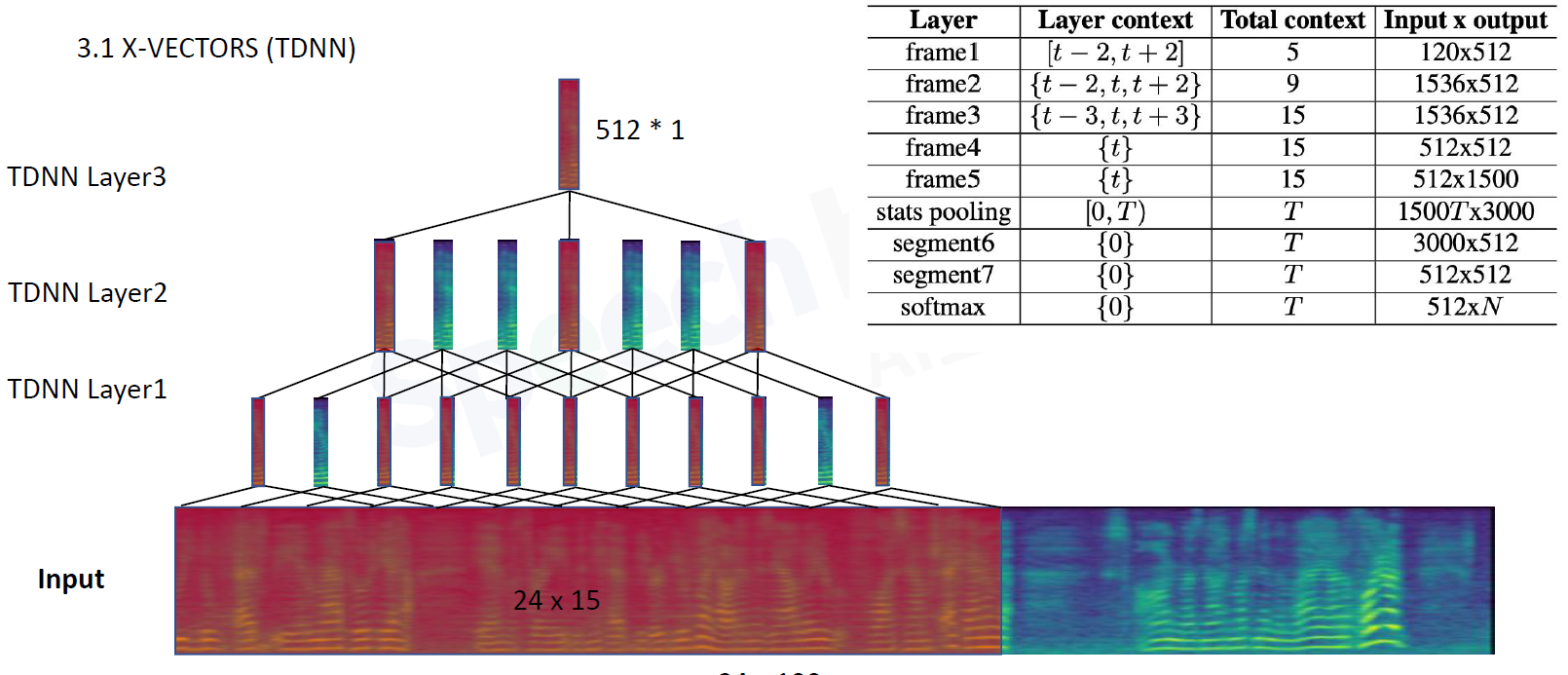
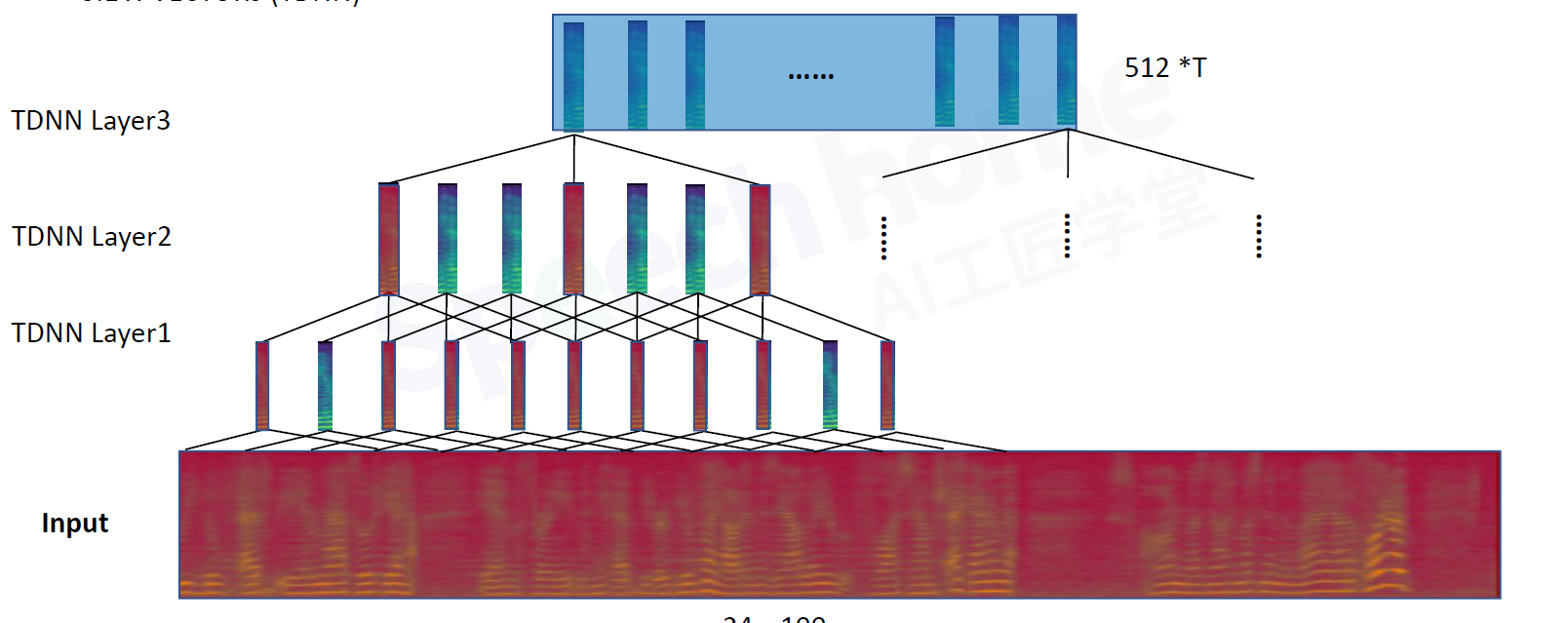
frame4 5:不考虑别的信息了,等价于DNN全连接层
3.3 ResNet(2D CNN)
总结
1D CNN 输出是一张图的高维特征
2D CNN 输出是多通道的特征图(多张图)
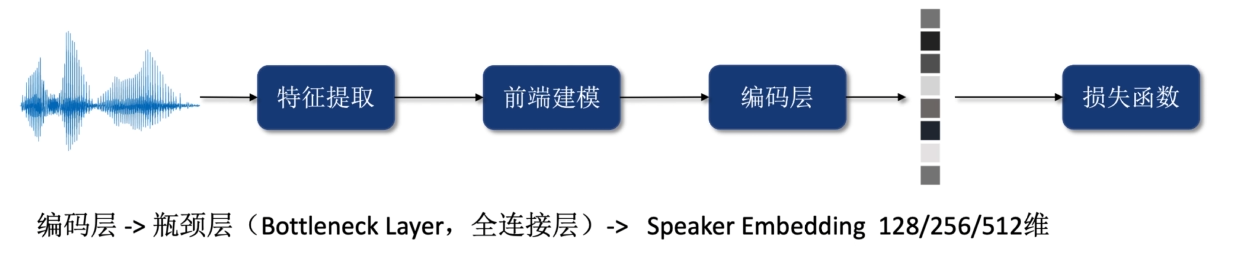
4.编码层
把不定长的语音向量,变成定长的语音向量。
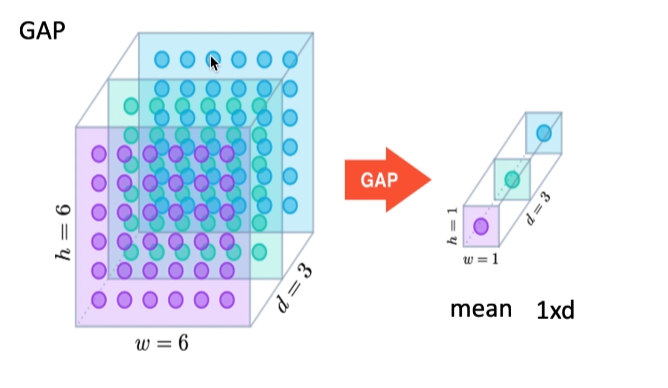
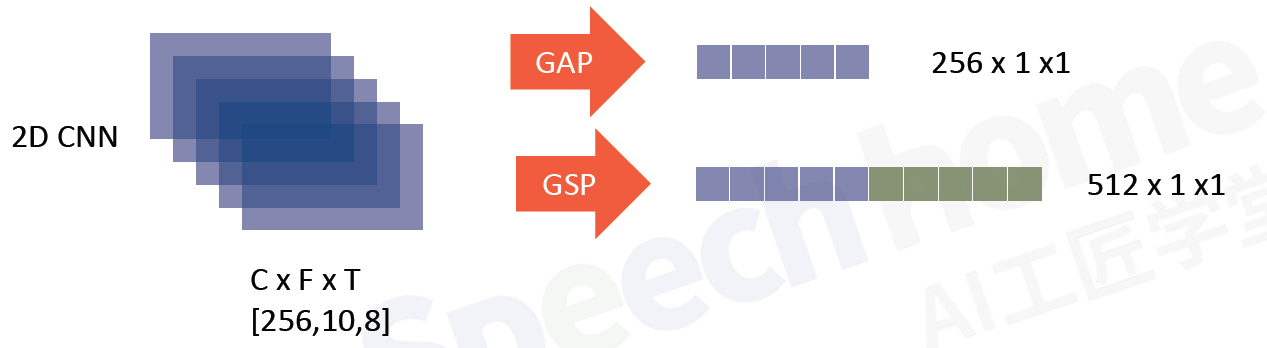
4.1 GAP(Global Average Pooling) GSP(Global Statistics Pooling)
全局平均GAP
统计池化GSP
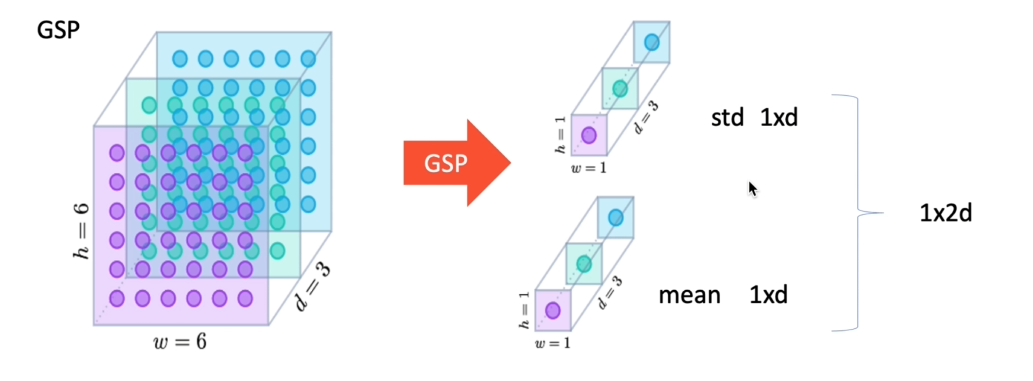
C:channel层
F:频域,通常不变。维度和特征不变
T:时域,随着语音信号长度改变
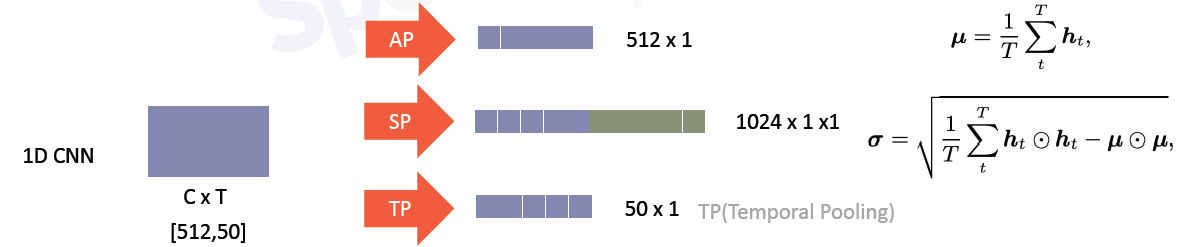
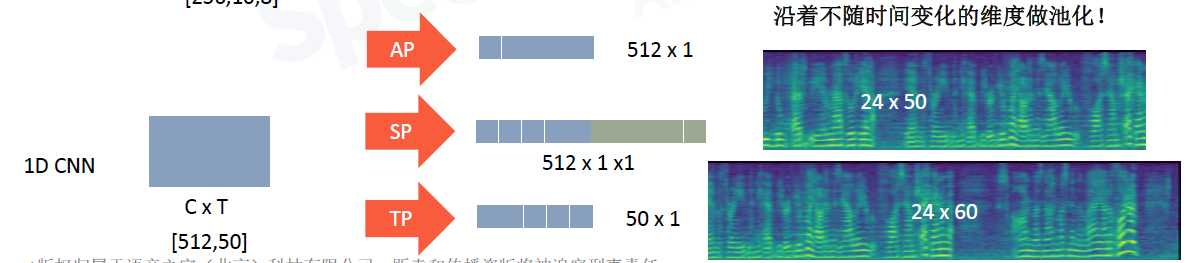
沿着不随时间变化的维度做池化
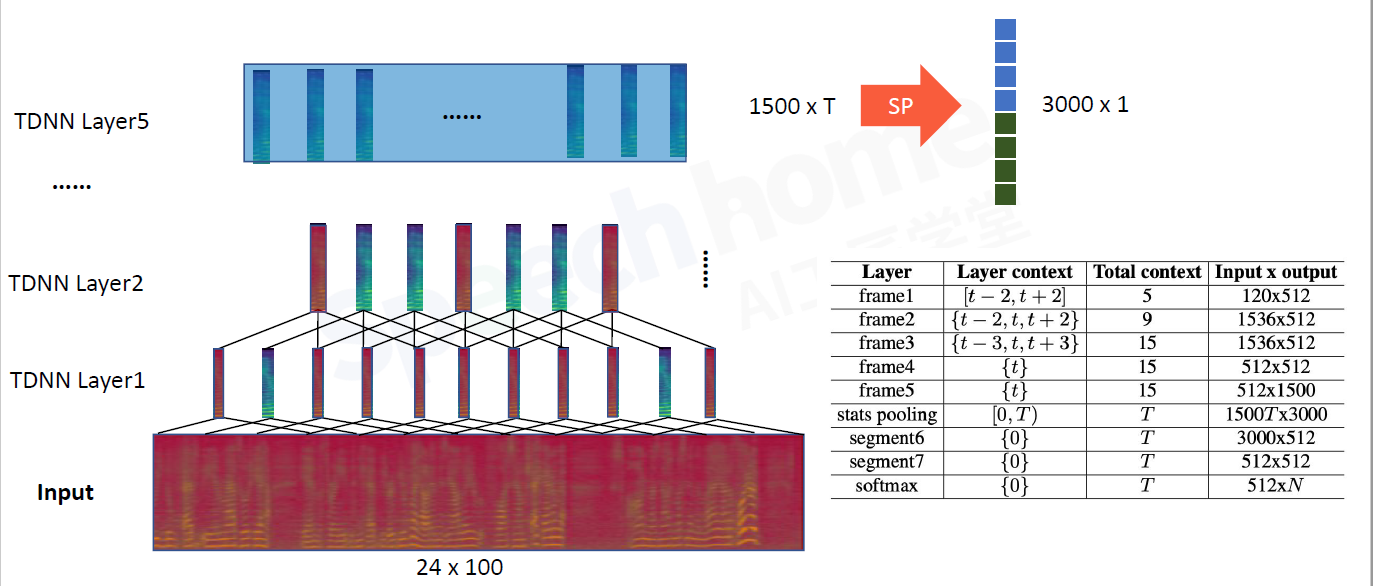
layer5中 一帧就是1500的向量,时间轴是T,沿着频域轴做SP
过两个segment全连接层,再softmax。
segment6的输出作为speaker embedding
4.2 ASP (Attentive Statistics Pooling)
基于注意力机制的统计池化层

给每一帧的特征过一个全连接层,过一个激活函数得到时间轴上这一帧的权重et,再给所有的权重做softmax。得到带权重的均值和方差。
用Transformer代替Attention
5.损失函数
5.1 Softmax

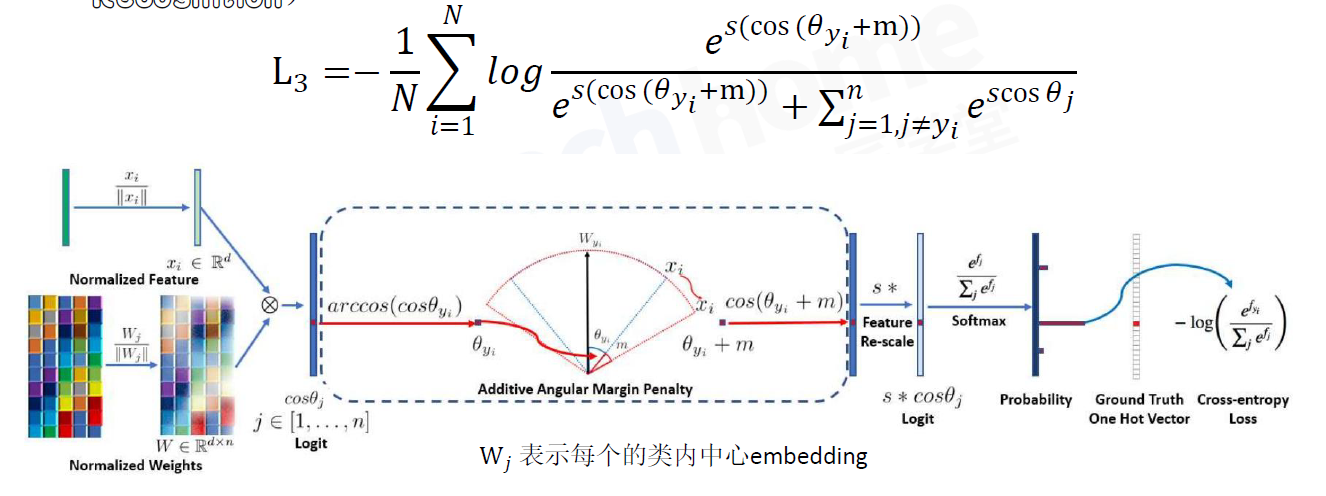
5.2 AAM-Softmax(ArcFace:Additive Angular Margin Loss for Deep Face Recognition)
5.3 CosFace=AM-Softmax
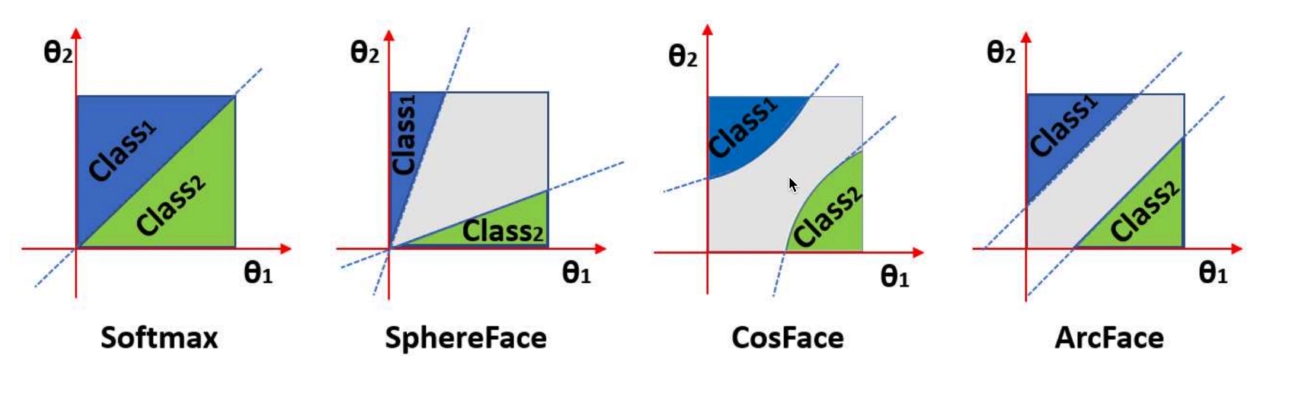
更推荐使用AM-Softmax
6.模型评估
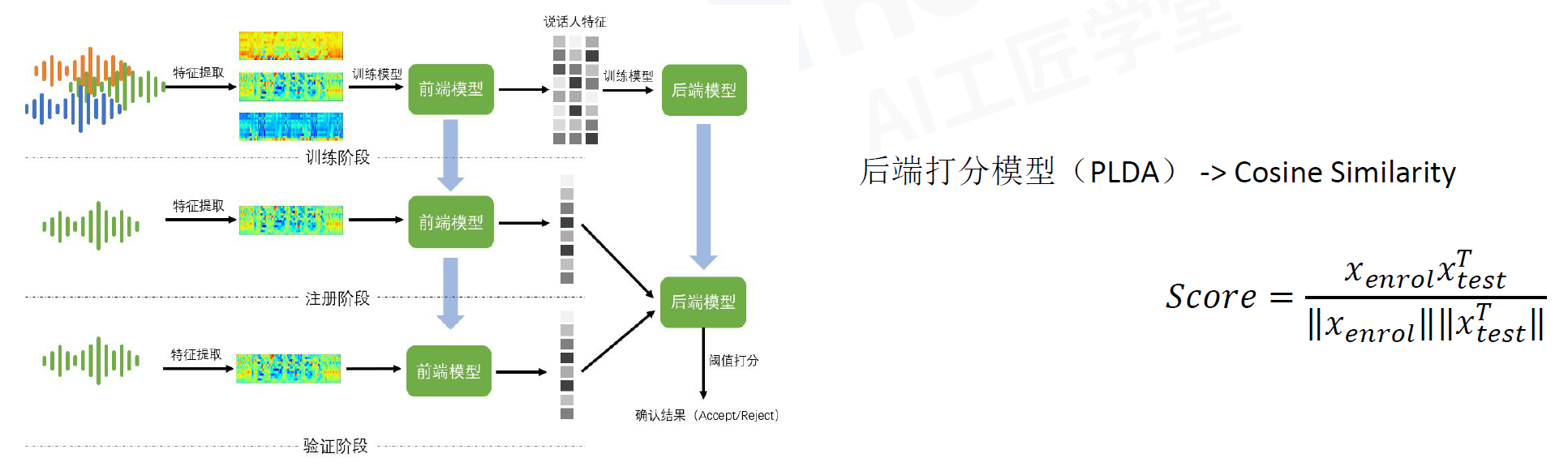
现在打分常用余弦相似度Cosine Similarity
我们需要用大量的注册语音和测试语音来验证模型性能
Trial file


eg:当阈值为0.6 FAR=1/3 FRR=1/3


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?
· 如何调用 DeepSeek 的自然语言处理 API 接口并集成到在线客服系统