
Python正则表达式学习与运用
一、什么是正则表达式
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。
二、正则表达式的特点
- 1. 灵活性、逻辑性和功能性非常强;
- 2. 可以迅速地用极简单的方式达到字符串的复杂控制。
- 3. 对于刚接触的人来说,比较晦涩难懂。
- ^ 开始
- () 域段
- [] 包含,默认是一个字符长度
- [^] 不包含,默认是一个字符长度
- {n,m} 匹配长度
- . 任何单个字符(\. 字符点)
- | 或
- \ 转义
- $ 结尾
- [A-Z] 26个大写字母
- [a-z] 26个小写字母
- [0-9] 0至9数字
四、运用实例
题目:爬取英文取名网站中的英文名、性别、寓意、简介。
1.通过网页界面寻找其反爬虫的请求头:
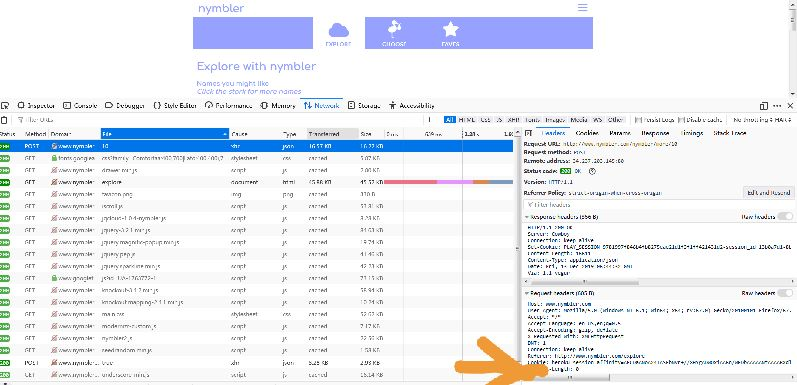
解析响应:
1 response = requests.post('http://www.nymbler.com/nymbler/more/5')#响应请求
2 docx=(response.text)#获得解析文件
利用正则表达式获取主要内容:
1 name=re.findall(r'"name":"([^"]+)"',docx)#从text文件资源里面获取name标签后的字符串内容
2 gender=re.findall(r'"gender":"([^"]+)"',docx)#从text文件资源里面获取gender标签后的字符串内容
3 info=re.findall(r'"info":"([^"]+)"',docx)#从text文件资源里面获取info标签后的字符串内容
4 meaning=re.findall(r'"meaning":"([^"]+)"',docx)#从text文件资源里面获取meaning标签后的字符串内容
成功获取:

可实现源代码:
1 import requests
2 import re
3 headers = {
4 'Cookie':"heroku-session-affinity=AECDaANoA24IAaj0sYj+//8HYgAH2hNiAAsB42EDbAAAAANtAAAABXdlYi4zbQAAAAV3ZWIuMm0AAAAFd2ViLjFqTiF9lGfQyz4HBcluZEIivsLibgo_; PLAY_SESSION=e625836109d6e09af14be41657c35e808ca31e72-session_id=240bcff7-ebb5-49ee-8fa4-ffcc5ba32e48; _ga=GA1.2.408125030.1575511582; _gid=GA1.2.1377013858.1575511582; td_cookie=18446744071831041204; _gat_gtag_UA_1763772_1=1"
5 }
6 response = requests.post('http://www.nymbler.com/nymbler/more/5')#响应请求
7 docx=(response.text)#获得解析文件
8 name=re.findall(r'"name":"([^"]+)"',docx)#从text文件资源里面获取name标签后的字符串内容
9 gender=re.findall(r'"gender":"([^"]+)"',docx)#从text文件资源里面获取gender标签后的字符串内容
10 info=re.findall(r'"info":"([^"]+)"',docx)#从text文件资源里面获取info标签后的字符串内容
11 meaning=re.findall(r'"meaning":"([^"]+)"',docx)#从text文件资源里面获取meaning标签后的字符串内容
12 print("姓名:\n",name)#将获取的内容以字典格式输出
13 print("性别:\n",gender)
14 print("名字寓意:\n",meaning)
15 print("名字简介:\n",info)
五、补充说明
re库常用函数:
- re.compile() :
将正则表达式模式编译成一个正则表达式对象,它可以用于匹配使用它的match ()和search ()方法,如下所述。
可以通过指定flags值修改表达式的行为。值可以是任何以下变量,使用组合 OR ( |运算符)。
但使用re.compile()和保存所产生的正则表达式对象重用效率更高时该表达式会在单个程序中多次使用。
- re.escape():
返回的字符串与所有非字母数字带有反斜杠;这是有用的如果你想匹配一个任意的文本字符串,在它可能包含正则表达式元字符
简单理解:把字符串按照可能会是正则表达式来理解,这样就需要把特殊字符都转义。这样才能方便匹配时精确匹配每个字符。
字符'[a-z]'这个字符串可以看作是正则表达式的模式,这样就不能作为被匹配的字符串。如果想把这个字符串作为被匹配的模式就需要转义这些特殊字符。print(re.escape('[a-z]'))
\[a\-z\]
- re.findall():
作为一个字符串列表,在字符串中,返回所有非重叠匹配的模式。该字符串是从左到右扫描的,匹配按照发现的顺序返回。如果一个或多个组是本模式中,返回一个列表的群体 ;如果该模式具有多个组,这将是元组的列表。空匹配包含在结果中,除非他们接触到另一场匹配的开头。
返回一个匹配的所有内容的列表。如果没有匹配内容则返回空列表。
- re.match():
如果在字符串的开头的零个或更多字符匹配这个正则表达式,将返回相应的作法实例。返回没有如果,则该字符串与模式不匹配请注意这是不同于零长度匹配。
简单理解:就是从字符串的开始做正则匹配。能匹配到的最大位置返回。返回的对象用group/groups方法读取。可以不匹配到字符串的末尾。但是字符串的开始必须匹配,否则返回空字符串。
-
re.search():
扫描字符串寻找第一个匹配位置,在此正则表达式产生的匹配,并返回相应的MatchObject实例。如果没有字符串中的位置匹配模式返回空 。
可选的第二个参数pos给索引在字符串中搜索在哪里开始;它将默认为0。这并不完全等于切片的字符串 ; ' ^'模式字符匹配在真正开始的字符串和位置刚换行,但不是一定是在开始搜索的索引
可选参数endpos限制了多远的字符串将被搜索 ;它将,如果字符串是endpos个字符长,因此,只有从pos到字符endpos - 1将搜索匹配项。如果endpos小于pos,没有比赛会发现,否则,如果rx是已编译的正则表达式对象, rx.search (字符串, 0, 50)相当于rx.search (字符串 [: 50], 0)。
注意:如果查找字符时用*则会默认匹配0个对应的字符。这样就会返回空字符串。
- re.split():将字符串拆分的模式的匹配项。如果在模式中使用捕获括号,则然后也作为结果列表的一部分返回的文本模式中的所有组。如果maxsplit不为零,顶多maxsplit分裂发生,并且该字符串的其余部分将作为列表的最后一个元素返回。
参考博文:https://www.cnblogs.com/mehome/p/9513492.html

