A Review of Knowledge Graph Completion
Zamini M, Reza H, Rabiei M. A Review of Knowledge Graph Completion. Information. 2022; 13(8):396.
- 概述
Current real-world knowledge graphs are usually incomplete and need an inference engine to predict links and complete the missing facts among entities available in the KG. Relation classification or inference from information already available KG is called link prediction (链路预测). The process of completing incomplete triples (i.e., (Einstein, ?, Germany)) is called knowledge graph completion (KGC) (知识图谱补全).
An example of it can be seen in Figure 1.
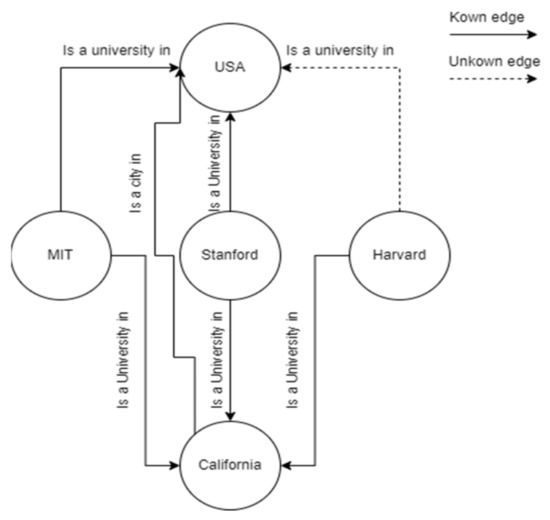
Figure 1. Sample KG where there exists a missing edge between the two nodes.
A common approach in link prediction and knowledge graph completion is via embedding into vector spaces to learn representations of entities and relations and embedding vectors of entities and relations can then be updated by maximizing the global plausibility (最大化全局合理性). Embedding methods generalize from known facts and model triple-level uncertainty. Compared to traditional one-hot representation approaches, knowledge graph embedding can better address semantic computing using a distributed representation method.
However, the reasoning results are not globally consistent. Different models have been proposed to solve this issue. Different scoring functions (评分函数) are defined to measure triples’ plausibility (度量三元组的合理性) to enable updating the representation on the training data (在训练数据上更新表示形式). Using different scoring functions in knowledge graph embeddings will reflect different designing criteria(在知识图嵌入中不同评分函数反映不同的设计标准).
Remark 1: 知识图谱是稀疏且不完整的,由此产生了知识图谱补全(KGC),来向图谱中添加三元组 (h,r,t),h is head entity (头部实体), r is relation (关系), t is tail entity (尾部实体),h通过关系r指向t。
Remark 2: 可分为三个子任务,(?,r,t),(h,?,t),(h,r,?),即预测缺失部分。
- 传统KGC
- Translational Models (平移模型)
Translational models interpret relations as simple translations over hidden entity representations (将关系解释为隐藏实体表示的简单平移). Translational distance models measure the plausibility of a fact (事实的合理性) and exploit distance-based scoring functions (距离评分函数). The translational-based models try to find a low-dimensional vector representation of entities in relation to the translation of entities.
1.1 TransE
TransE将实体和关系定义在相同空间。
Remark 3: TransE 是非常简单的平移模型。原理如下:
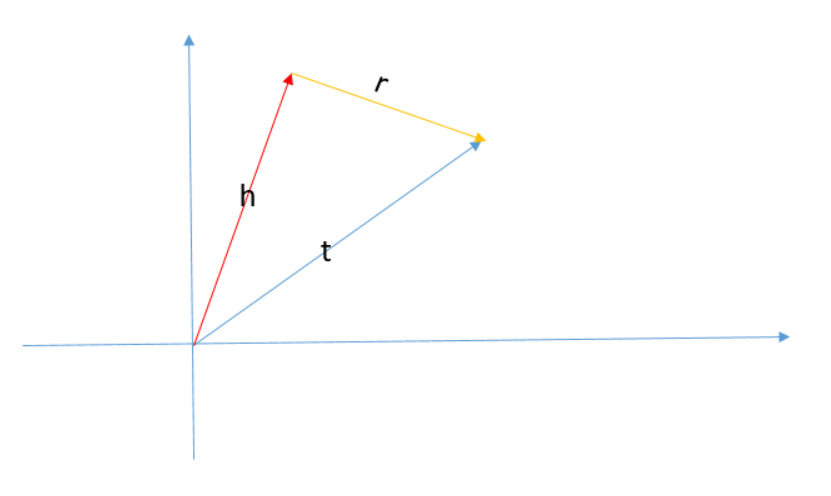
Figure 2. TransE 中的假设 t = h + r,在同一空间.
1.2 TransH
TransH将实体向量和尾部向量沿法线投影到关系r的超平面上。
TransH模型提出让一个实体在不同的关系下拥有不同的表示。对于关系r,TransH模型同时使用平移向量和超平面法向量来表示它。由于关系r可能存在无限个超平面,TransH简单地令两个向量正交来选取一个超平面,同时它仍然将实体和关系放在相同的语义空间中。
1.3 TransR
TransR认为一个实体是多种属性的综合体,不同关系关注实体的不同属性,而不同的关系拥有不同的语义空间。TransR使用了投影矩阵,将实体从实体投影到关系空间。
但也有很多缺点:1. 在同一个关系r下,头、尾实体共享相同的投影矩阵;2. 让投影矩阵仅与关系有关是不合理的,实体和关系之间是交互的过程;3. 参数增加,计算复杂度大大提高。
1.4 TransD
TransD设置了两个投影矩阵,分别将头实体和尾实体投影到关系空间,显然这两个投影矩阵与关系和实体都有关,而且,只利用两个投影向量构建投影矩阵,就解决了上述问题。
1.5 RotatE
RotatE能够同时建模和推断各种关系模式,是对关系模式进行建模和推断,包括:对称/反对称,反演和合成。 具体而言,RotatE模型将每个关系定义为在复矢量空间中从源实体到目标实体的旋转。
比如婚姻关系是对称的,亲子关系是反对称的,‘hypernym’和‘hyponym’是对立的,还有其他的关系比如我的爸爸的妻子是我的妈妈。
1.6 HAKE
HAKE从语义层次上进行建模,它将实体映射到了极坐标系。他们认为极坐标系中的同心圆能够反映层次结构,径向坐标旨在对层次结构不同层次的实体进行建模,半径较小的实体预计应位于较高的层次;角坐标旨在区分层次结构中同一层的实体,并且这些实体的半径应大致相同,但角度不同。但也存在维度太高等问题。
- Tensor Dompositional Models (张量分解模型)
张量分解模型利用基于相似性的评分函数,通过匹配实体的潜在语义和向量空间表示中包含的关系来度量事实的可信性。
2.1 RESCAL(又叫双线性模型)
RESCAL通过使用一个向量表示每个实体来获得它的潜在语义。每个关系都表示为一个矩阵即关系矩阵Mr,该矩阵对潜在因素之间的成对交互作用进行了建模。它把事实(h,r,t)评分函数定义为一个双线性函数。该模型容易过拟合。
2.2 DistMult
DistMult通过将Mr限制为对角矩阵来简化RESCAL,这种过度简化的模型只能处理对称的关系。
2.3 ComplEx
ComplEx通过引入复值嵌入来扩展DistMult,以便更好地对非对称关系进行建模。在ComplEx中,实体和关系嵌入h,r, t不再存在于实空间中,而是存在于复空间中。
2.4 Tucker
RESCAL,DistMult都是对张量运用不同的分解方法来解决链接预测问题的线性模型,ConvE模型并非透明,可解释性差。由此,Tucker使用一种基于二元张量塔克分解的不同分解模型来计算一个较小的核心张量和一个由三个矩阵组成的序列,其中每个矩阵分别代表实体嵌入和关系嵌入。
- Neural Network Models
3.1 SME
SME采用神经网络结构进行语义匹配。给定一个事实三元组(h,r,t),它首先将实体和关系投影到输入层中的嵌入向量。然后将关系r与h组合得到g(h,r),r和t组合得到隐藏层中的g(t,r)。则评分函数由两者点积定义。SME有线性和双线性两个版本。
3.2 NTN
NTN是另外一种神经网络结构,给定一个事实,它首先将实体投影到输入层中的嵌入向量。然后,将这两个实体h,t由关系特有的张量M_r(以及其他参数)组合,并映射到一个非线性隐藏层。最后,一个特定于关系的线性输出层给出了评分。NTN的表达能力非常好,但参数很大,不能处理大型知识图谱。
- Convolutional-Based Models
4.1 ConvE
ConvE 具有与DistMult和R-GCN相同的性能,参数要少得多,并且在建模高度节点方面是有效的。它使用二维卷积层进行链路预测,该层由卷积层、处理嵌入维度的投影层和内积层组成。ConvE通过将每个向量包裹在几行上并连接矩阵来生成矩阵。每个卷积滤波器生成不同的特征映射张量来提取全局信息。虽然该模型在计算机视觉方面的表现优于常见的卷积模型,但其他领域仍然很浅,需要研究更深入的模型以提高其性能。
Remark 4: 之前提出的模型如disMult,Trans系列模型,这些浅层模型,虽然比较简单,参数较少、训练模型速度较快,但是这些模型相比于深的模型,更少能够抓到复杂的信息。因此,提出模型ConvE模型,利用卷积的方式进行知识图谱补全,能够适用于更加复杂的图。
ConvE模型使用二维卷积在嵌入上预测知识图中的缺失环节。ConvE是用于链接预测的最简单的多层卷积体系结构:它由单个卷积层、嵌入维数的投影层和内积层定义。ConvE的亮点在于:1. 参数利用率高(相同表现下参数是DistMult的八分之一,R-GCN的十七分之一),使用了1-N score使训练和测试加快了三百倍; 2. NLP中使用的CNN都是Con1D(比如Text-CNN),一维卷积以句子为单位来卷积。ConV2D的实现方法是由二维卷积获得。
4.2 ConvKB
ConvKB使用CNN来捕获实体和关系之间的全局关系和过渡特征。该模型中每个三元组由一个三列矩阵表示,其中每列代表三元组每个元素的向量。作者认为ConvE只考虑了局部不同维度的关系没有考虑全局相同维度的关系,而ConvKB对三个元素都进行了卷积。
- 图神经网络
- Graph Convolution Network Models
1.1 R-GCN
关系图卷积网络(R-GCN)是为链路预测和实体分类等知识库完成任务开发的众所周知的方法之一。GCN代表一个图形编码器,但为了使其能够完成特定任务,它需要开发成R-GCN,该R-GCN通过分层传播规则平等对待每个实体的邻域,以适合有向图。它将特定关系变换矩阵与邻域信息聚合。编码器将每个实体映射到实值向量,解码器(评分函数)根据顶点表示重建图形的边缘。在这个模型中,DistMult分解被用作评分函数,其中每个关系都与对角矩阵相关。优化交叉熵损失促使模型选择比负三元组更好的三元组。然而,R-GCN没有考虑到实体之间的关系或属性相似性。此外,使用R-GCN的评分函数会为正三元组产生许多负三元组。
Remark5: 假设知识库主要以三元组的形式(主语、谓语、宾语)进行存储。比如说,Mikhail 在 Vaganova 学院上学,我们把 Mikhail 和 Vaganova 学院称为实体,受教育称为关系,每个实体会有自己的类型,这样便构成一张知识网络:
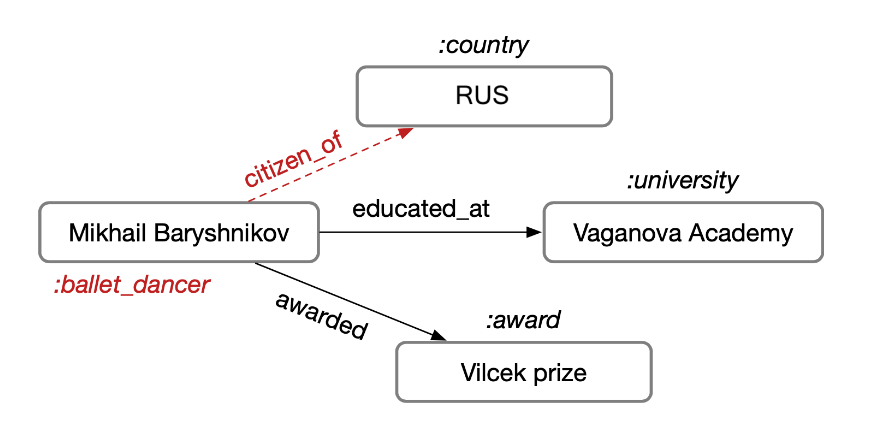
Figure 3: 一个例子.
主要考虑两个任务,包括链接预测和实体分类。在这种情况下,可以对很多缺失信息进行补全,比如说:知道 Mikhail 在 Vaganova 学院受过教育,我们便可以知道他居住在俄罗斯(RUS),并且有自己的 label(如图中红色部分)。
作者设计了一个编码器模型,并将其应用于这两个任务中,简单来说: 1. 对于实体分类来说,将在编码器后面接一个 softmax 分类器用于预测节点的标签; 2. 对于链路预测来说,可以后面接一个解码器,将分类器视为自编码器,从而完成节点的预测。编码器将每个实体映射到实值向量,解码器(评分函数)根据顶点表示重建图形的边缘。优化交叉熵损失促使模型选择比负三元组更好的三元组。但R-GCN没有考虑到实体之间的关系或属性相似性,而且R-GCN的评分函数会为正三元组产生许多负三元组。
R-GCN 开创了使用 GCN 框架去建模关系网络的先河,证明了 GCN 可以应用于关系网络中,特别是链接预测和实体分类中,并引入权值共享和系数约束的方法使得 R-GCN 可以应用于关系众多的网络中。
1.2 CompGCN
COMPGCN 还利用KGE模型中的各种实体关系组合操作,对多关系图中的节点和边缘使用联合向量表示学习。
Remark 6: 传统的GCN算法广泛应用于同质图,而同质图算法远不能满足知识图谱需求,CompGCN便是针对于Multi-relational Graphs提出的异质图表征算法,CompGCN能够同时对node和relation进行表征学习,在节点分类,链接预测和图分类任务上都取得Sota效果。
CompGCN的动机:1. GCN等对于建模无向、单关系的图或网络是有效的;2. 现实生活中的知识图谱大多是多关系图,需要对关系进行编码;3. 随着关系的增大,引入过多关系矩阵,会导致参数爆炸模型无法训练。CompGCN则便是为了解决两大问题:1.联合学习一个多关系图中的节点嵌入和关系表示;2. 解决之前多关系图表示工作R-GCN等存在的参数过载问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号