MySQL----Leetcode刷题记录
-
第2高
Leetcode 176题 第二高的薪水
获取Employee表中第二高的薪水(Salary)如果不存在第二高的薪水,那么查询应返回nullselect IFNULL(( select distinct Salary from Employee order by Salary DESC limit 1,1 ),NULL) as SecondHighestSalary;涉及到查询类似于 '第几高' 之类的题目,需要注意
① 第一想到order by col_name [DESC] 然后 limit offset, row_count 注:limit两参数只能为非负数值常量
② 要去重 distinct ,避免重复值的出现影响结果
③ select 字段应附加一个嵌套子查询,内层查询结果为为空时,将 Null 附给 SecondHighestSalary 使得其返回值为 Null而不是 空 或报错,当然再嵌套一个IFNULL(Exp_1,NULL) 更易理解(时间更短?)
④ 注意 ISNULL 与IFNULL函数的使用。 -
Leetcode 177题 返回第N高的薪水
解1:使用变量为中介
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN set N:=N-1;#也可以书写为set N=N-1; RETURN ( # Write your MySQL query statement below. select ifnull( (select distinct salary from employee order by salary Desc limit N,1), null) ); END #使用局部变量,会话变量报错 ???解2:利用窗口函数
CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT BEGIN RETURN ( select distinct salary from ( select id,salary , dense_rank() over w as d_r from employee window w as (order by salary DESC) ) AS tab_w where d_r=N ); END /* window w_name as ([partition_defintion] [order_definition] [frame_definition]) win_fun() over([partition_defintion] [order_definition] [frame_definition] 三个参数的介绍详见12.21.2 P2144 及12.21.3介绍 */MySQL8.0之后开始支持窗口函数 详见手册12.21节 也可参考CSDN博客
常见的窗口函数有:
① 排序函数 rank() , dense_rank() , row_number() ;
② 分布函数 cume_dist() ,percent_rank()
③ 前后函数 lag(expr,n) ,lead( expr,n ) :取当前行的前/后第n行的数据,不是前/后 n行的所有数据,即是单个值不是n个值。
④ 头尾函数first_value(expr) , last_value(expr)
⑤ 定位函数 nth_value(expr,n),分级函数ntile(n); 其中n不能为空。 -
返回各部门工资前三高的员工的:部门名,姓名,薪资
解1:使用开窗函数
Select d.Name AS 'Department', e.Name AS 'Employee', e.Salary From Employee e Join Department d On e.DepartmentId = d.Id Join (select Id,Dense_Rank() over(Partition By DepartmentId Order By Salary DESC) as s_r From Employee) As tab_r On tab_r.Id = e.Id Where tab_r.s_r <= 3 Order By Department,Salary DESC;解2:where子句虚拟连接表,搭配聚合函数count
Select d.Name AS 'Department', e1.Name AS 'Employee', e1.Salary From Employee e1 Join Department d On e1.DepartmentId = d.Id Where 3 > (Select count(Distinct e2.salary) From Employee e2 Where e1.salary < e2.salary And e1.DepartmentId = e2.DepartmentId) /*并不太理解此处每一个e1项会对应一个count值(由于两表是虚拟连接,且连接条件是departmentid , 所以潜在的以departmentid分组计算count值?),而不是最终只有一个count值。 记住这种思想*/ Order By Department,Salary DESC;解3:相对于上述的隐式的虚拟连接并分组聚合,下面的where子句中的显式连接,group by + having count 更易理解。
Select d.Name AS 'Department', e.Name AS 'Employee', e.Salary From Employee e Join Department d On e.DepartmentId = d.Id WHERE e.id in (Select e1.id From Employee e1 Join Employee e2 On e1.DepartmentId = e2.DepartmentId And e1.Salary <= e2.Salary Group By e1.Id Having count(Distinct e2.salary)<=3 ) Order By Department,Salary DESC; #当然此解也可以讲where子查询查询出的count于前两表连接,然后where count<=3 -
关于报错:
leetcode 196题:删除重复的邮箱
# 1090 ms , 在所有 MySQL 提交中击败了98.79% 的用户 delete from person where Id not in ( select min(id) # 不加min ,此子查询结果也是1,2。整体不报错,但是操作无效,不解。 from (select * from person) t_person /*此处不可以直接from person 会报错:You can't specify target table for update in FROM clause */ group by Email )That is, if you're doing an
UPDATE/INSERT/DELETEon a table, you can't reference that table in an inner query (you can however reference a field from that outer table...)可参见You can't specify target table for update in FROM clause以及How to Select From an Update Target in MySQL
-
Leetcode 262题: 查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。
取消率(Cancellation Rate)保留两位小数。官方题目歧义,测试用例,及解答歧义。
#解1 SELECT Request_at as `Day`, Cast( count(if(status!='completed',status,null))/count(status) As DECIMAL(3,2) )As `Cancellation Rate` From Trips t Join Users u1 On t.Client_Id = u1.Users_Id And u1.Banned = 'No' # Join Users u2 On t.Driver_Id = u2.Users_Id And u2.Banned = 'No' Where Request_at between '2013-10-01' And '2013-10-03' Group By Request_at ORDER BY Request_at; #解2: 巧用Avg函数 SELECT Request_at As `Day`, Cast( avg(status!='completed') as DECIMAL(3,2) # AVG(col_name/exp),此处status!='completed' ,根据status值,又生成了一列0,1序列值,avg即是对新生成的该列求平均值。 )As `Cancellation Rate` From Trips t Join Users u1 On t.Client_Id = u1.Users_Id And u1.Banned = 'No' # Join Users u2 On t.Driver_Id = u2.Users_Id And u2.Banned = 'No' Where Request_at between '2013-10-01' And '2013-10-03' Group By Request_at ORDER BY Request_at; #解3 SELECT Request_at as `Day`, Cast( sum(if(status!='completed',1,0))/count(status) #解2的显式表达,更易理解。 as DECIMAL(3,2) )As `Cancellation Rate` From Trips t Join Users u1 On t.Client_Id = u1.Users_Id And u1.Banned = 'No' # Join Users u2 On t.Driver_Id = u2.Users_Id And u2.Banned = 'No' Where Request_at between '2013-10-01' And '2013-10-03' Group By Request_at ORDER BY Request_at; # 上述cast(data as fromate) 可以换用 convert(data,formate),round(data,保留的小数位),formate(data,保留小位数 [,分隔数])(此处不太适用)注意跳出思维局限性,不是只有count(*/具体字段)的用法,count , if , avg 各函数间可以嵌套使用,转换使用。
-
mysql判断连续三行(多行)是否皆满足某一条件
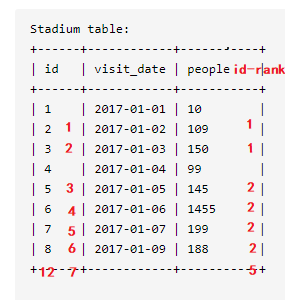
Leetcode 601题:体育馆的人流量
编写一个 SQL 查询以找出每行的人数大于或等于
100且id连续的三行或更多行记录# 正解1:开窗求差值 Select id ,visit_date, people From (Select id ,visit_date, people , (id-Rank() over(Order By id)) as dif_v From Stadium Where people>=100) as tab_dif Where dif_v In( Select dif_v From (Select id ,visit_date, people , (id-Rank() over(Order By id)) as dif_v From Stadium Where people>=100) as tab_dif Group By dif_v Having count(1)>=3 ) Order By Id #此解Rank函数,可用dense_rank,row_number等函数替代,在此情景下,这些排序函数效果相同。![image-20210205203038313]()
/*正解2:由于各个子查询建立的虚拟表之间不能被相互识别,解1中的虚拟表代码重合,可以考虑使用 with子句 疑问:with 子句建立虚拟表的用法与通过视图建立的虚拟表有什么区别??? 不单独成句与单独成句的区别*/ With tab_dif as ( Select id ,visit_date, people , (id-Rank() over(Order By id)) as dif_v From Stadium Where people>=100 ) Select id ,visit_date, people From tab_dif Where dif_v In( Select dif_v From tab_dif Group By dif_v Having count(1)>=3 ) /*①注意此处思想应该是以差值为筛选条件,而不是id */① 关于with(Common Table Expressions )
13.2.15 WITH (Common Table Expressions)
A common table expression (CTE) is a named temporary result set that exists within the scope of a single statement and that can be referred to later within that statement, possibly multiple times. The following discussion describes how to write statements that use CTEs.(Page 2400)with创建的虚拟表(一个命名的零时结果集) 作用范围只局限与本语句中(在该语句的后文中被引用),with 语句不单独使用。
② 关于count:数据量较小且不忽略null值建议使用count(1); 数据量较大且不忽略null值建议使用count(*); 数据量较大且需要忽略null值建议使用count(字段)#正解3:视图view创建虚拟表 create or replace view v_dif as select id , visit_date , people , (id-rank() over(order by id) )as dif_val from stadium where people>=100; select id , visit_date , people from v_dif where dif_val in (select dif_val from v_dif group by dif_val having count(1)>=3); #该解为两条语句。leetcode报错,且报错点在两句交界处。但本地执行无误,猜测leetcode潜在要求输入为1条语句,故报错。 #正解4:开窗函数(此处没开窗)lag,lead select id , visit_date , people from ( select id , visit_date , people , lag(people,2) over() as lag2_p , lag(people,1) over() as lag1_p , lead(people,1) over() as lead1_p , lead(people,2) over() as lead2_p from stadium ) as tab_ll where (people>=100 and lag1_p>=100 and lag2_p>=100 ) or(people>=100 and lag1_p>=100 and lead1_p>=100) or(people>=100 and lead1_p>=100 and lead2_p>=100) /*该解为最初解题思想,但 1.初期考虑不周,where子句三个条件没有考虑全面 2.对lead,lag机制存疑,网络论坛资料表达不精确,存在一定误导,leetcode环境不可靠,交互性差————教训:多本地验证,多查看官方文档 前后函数 lag(expr,n) ,lead( expr,n ) :取当前行的前/后**第n行**的数据,而不是前/后 n行的所有数据,是单个值不是n个值 3.该解可扩展性差,若题目要求连续10行,100行...则需要多添加20个,200个...字段,where筛选条件也相应增长。故了解lag,lead 函数即可,思想不宜吸收。 -
msyql中巧用位运算处理奇偶问题
leetcode 620题:有趣的电影 判断奇数
① 直接使用mod函数 mod( value,2)
② 直接使用mod操作符 value mod 2
③ 巧妙运用 ‘与’ 运算:value&1 基本原理:若value为奇数,结果为1;若为偶数,结果为0。 执行效率最高。leetcode 626题 换座位 改变相邻两学生的座位,若最后一位同学id为奇数,则不变
总体来讲:从变换 id入手,而不是调换student 姓名
① 巧妙运用‘异或’运算:value^1
基本原理:若value为奇数,则结果变为偶数value -1 ; 若value为偶数,则结果变为奇数value+1;
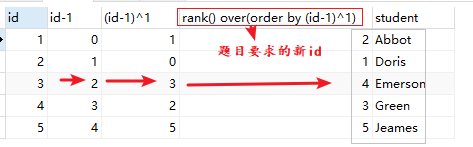
本题:select rank() over (order by (id-1)^1) as id ,student from seat order by id; #首先将id-1,再与1异或,实现原始奇数不变,偶数减2.按照该列rank。 #为方便理解整个变化过程,下图按照原id(非新id)升序排列![image-20210206164945858]()
② 非位运算思想:case when
select (case when mod(id,2)=1 and id = select count(1) from seat) then id when mod(id,2)=1 then id+1 else id-1 end ) as id , student # 注意此处结束标志为end,而非end case from seat order by id; #when 语句的第一种情况 取最大的id,还可以使用last_value(id) over()或者max(id) -
充分理解case when 与 group by
leetcode 1179题 重新格式化部门表
select id, sum(case when month = 'Jan' then revenue end) as Jan_Revenue, sum(case when month = 'Feb' then revenue end) as Feb_Revenue, sum(case when month = 'Mar' then revenue end) as Mar_Revenue, sum(case when month = 'Apr' then revenue end) as Apr_Revenue, sum(case when month = 'May' then revenue end) as May_Revenue, sum(case when month = 'Jun' then revenue end) as Jun_Revenue, sum(case when month = 'Jul' then revenue end) as Jul_Revenue, sum(case when month = 'Aug' then revenue end) as Aug_Revenue, sum(case when month = 'Sep' then revenue end) as Sep_Revenue, sum(case when month = 'Oct' then revenue end) as Oct_Revenue, sum(case when month = 'Nov' then revenue end) as Nov_Revenue, sum(case when month = 'Dec' then revenue end) as Dec_Revenue from department group by id; order by id;上述代码的执行语序问题:
- . from子句,然后 group by 子句 ,大致是这样
![image-20210206190119564]()
- . select子句 , 共13个字段(列),第一列为 id , 即部门编号,这个较好理解。
- . 然后理解剩余12列的值,每有一个id必然会有其对应的12列(月份)的值。当id=1时,进入到经过分组的id为1 的表中,首先为jan_revenue列赋值,遍历该id表的所有行,通过case when 选定对应的revenue或null,然后将选定的这些值sum(详见注解) ,赋值给id的jan_revenue。如此,依次赋值给其他11列。同理,select 其他id值时进入对应id表内...
注解:{遍历整个id表,针对每个月或者说针对每条case when 语句,其实只有一个renvenue或根本没有,即都是null值。
①'只有一个revenue' : 按照表的定义,每个id分组表内month列的值绝不会有重复,也就是说一个部门在某个月的的收入不会分为两条来记录,该说法也与题目中 'id与month 为联合主键'的说法一致(主键唯一)
②'都是null值':id表中没有一行的month值为当前case when月份所对应的,即在数据库中,该部门没有录入当月的收入。
③'使用sum聚合函数': 因为‘只有一个revenue’,'都是null值',所以使用sum,max,min 等聚合函数效果都是一样的。使用sum更易让人忽略细节,且更易于让人粗略的,模糊的结合group by 接受并理解。
④'不使用类似的聚合函数':不可以。group by 分组后,在mysql中,若不使用聚合函数来提取值,直接select只会select出当前id表的第一行(某个月份),这也意味着在为当前id的12列赋值时,每次都是遍历这一行。结果就是只有与与改行月份对应的那个case when 语句的列会被赋值为revenue,其他皆判断为不符合(即该id的其他列都是null值)
⑤其实不太能理清sum与case语句执行的先后关系,个人认定为先case ,后sum :推翻上述的过程' 3). ', 为某id部门的某个月(对应的列)赋值时,先进入对应id表,先case when ,遍历group by 后该id表的第一行(结合④理解),然后该id的该列被赋值为null或者revenue值,然后发现外面嵌套聚合函数sum,返回case when 完整的遍历该id表,最终根据具体的聚合函数形式(此处为sum)得到该id(部门)该列(月份)的最终正确值。该id其他列,以及其他id的各列皆是如此。}
以上,若理解有误,请指正。
- . from子句,然后 group by 子句 ,大致是这样


 浙公网安备 33010602011771号
浙公网安备 33010602011771号