MySQL-Part2:连接查询 & 子查询 & 分页查询 & 联合查询
-
连接查询
主要分为内连接(等值连接,非等值连接,自连接),外连接(左外连接,右外连接,全外连接),交叉连接三大类。
sql92标准连接形式: from 表1,表2 ,表3 [where 条件1 and 条件2 and 题目条件] #笛卡尔连接
sql99标准连接形式: from 表1 join 表2 on 条件1 [ join 表3 on 条件2 where 题目条件]-
内连接:表之间通过某种关系建立连接来进行关联查询。其中自连接是针对自身的两次表的查询,必须指定别名来区别查询时使用哪一次的表
-
外连接
-
左连接
table_pri left join table_vic; 右连接table_vic right join table_pri;全连接 :full [outer] join两表交集(通过内连接可实现)+左外连接(A主B副)+左外连接(B主A副)----------->MySQL不支持全外连接。 -
与查询有关的关键字段属于哪个表,哪个表就是主表。
- 例如:查询没有奖金的员工姓名,此时就应该选取员工表e为主表,奖金表s为副表。
SELECT e.e_name FROM e LEFT JOIN s ON e.e_id=s.e_id WHERE s.e_id IS NULL;
- 例如:查询没有奖金的员工姓名,此时就应该选取员工表e为主表,奖金表s为副表。
-
外连接主要用于添加 where语句后筛选出(主表中有但是副表中没有)'s 主表中的对象。
select 字段 from table_m left [outer] join table_vice1 on 表间关联条件1 [left join table_vice2 on 关联条件2 ...] where condition_clause;#条件语句一般为 ... is [not] null .
-
-
交叉连接:交叉连接是笛卡尔积在sql中的实现。 关键字:cross join
-
-
子查询(内查询)
- 定义:出现在其他语句中的select查询语句。
- 按照子查询出现的位置可以主要分为四类:
- select语句中:仅仅支持标量子查询(查询结果为一行一列/单个字段)。
- from语句中:支持表子查询(查询结果为多行多列),即将查询的结果集充当一张'新表'(必须起别名以供调用)。
- where/having 条件语句:支持标量子查询(>.<,=,<>);列子查询(单列多行:判断大小时与in语句,any/some语句或all语句嵌套使用。in可以改写为=any,not in 可以改写为<>all);行子查询(较少应用)。
- exists语句中(相关子查询):表子查询。
- 子查询语句应包含在"()"内,且结束用 右括号")"标识即可,不应再加分号表示子查询语句的结束,分号可能会被误认为是用来标识主查询语句的结束,会报错。
-
分页查询
- 关键字
LIMIT,详见手册13.2.10 Select Statement. - 基本语法:
Limit [ offset ,] row_count ;- 参数释义:
The first argument specifies the offset of the first row to return, and the second specifies the maximum number of rows to return. The offset of the initial row is 0 (not 1) - 两参数一般皆为非负整数常量(在预处理语句以及其他语句中可能为其他值);select 结果为第offset+1行到第offset+row_cout行的数据;当offset为0时,该参数可省略。
- MySQL 同样支持PostgreSQL中的分页语法:
LIMIT row_count OFFSET offset_value - 关于 Limit 查询的优化细节。需要时可参见手册8.2.1.19 LIMIT Query Optimization 一节
- 参数释义:
- 关键字
-
联合查询
- 关键字:Union 将多条查询语句的结果合并成一个结果。
- 应用场景: 要查询的结果来自多个表,且多个表之间没有直接的连接关系,但查询的信息一致时(要显示的字段(类型,列数)是一致的)。
- 特点: 查询的字段数需相等;各字段类型与顺序最好保持一致;union 默认去重,若需包含重复项,可使用union all .
-
一些思考点
-
5.1 MySQL中 进行等值连接时发现'NULL=NULL'不能作为外连接的等值连接条件,NULL列会被自动忽略(左/右外连接,全连接)。使用安全等于
<=>可以解决这样的问题。-
查询要求:查询各部门(延伸为‘NULL’也是一个部门)中工资不低于本部门平均工资的员工的员工号,姓名以及工资
- 各部门平均工资查询:
select department_id ,avg(salary) as avgs_d from employees e;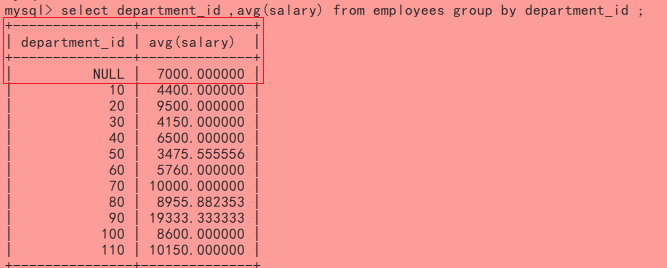
- 注意到上述查询结果中含有department_id 为NULL的行,在employees中查询详情
select * from employees where department_id is null;-------->只有一名员工”属于“NULL部门

- 各部门平均工资查询:
-
尝试解决:使用左外连接,右外连接在不加判断条件(大于本部门avg_s)时发现,该项均不能成功被完整连接-------当然,添加筛选条件后更不会显示出来。
- 左外连接:
select employee_id ,last_name , salary,e.department_id ,avgs_d from employees e left join (select department_id ,avg(salary) as avgs_d from employees group by department_id ) as sub_t on e.department_id = sub_t.department_id;
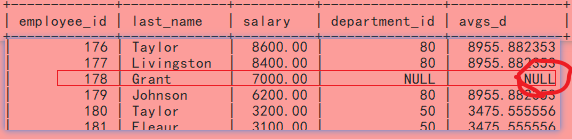
- 右外连接:
select employee_id ,last_name , salary,e.department_id ,avgs_d from employees e right join (select department_id ,avg(salary) as avgs_d from employees group by department_id ) as sub_t on e.department_id = sub_t.department_id;

- 左外连接:
-
解决:使用安全等于
<=>select employee_id ,last_name , salary,e.department_id ,avgs_d from employees e right join ( select department_id ,avg(salary) as avgs_d from employees group by department_id ) as sub_t on e.department_id <=> sub_t.department_id where salary >=avgs_d; #直接添加了筛选条件
-
-
5.2 group by
-
group by 效果可用select 子查询来模拟实现,例如,查询每个部门的详细信息,以及该部门的员工个数
-
group by 语句实现-------常规方式
select d.* ,ifnull(d_c,0) from departments d left join ( select count(*) as d_c,department_id from employees e group by department_id ) as t_c on d.department_id=t_c.department_id ; #此种方式因为group by 作用于employees表,所以无法统计到没有员工的部门的员工的个数(当然该值为0),所以需要使用left join连接,并且,在select 中使用ifnull()函数来处理count值 -
select 子查询实现
select d.* , (select count(*) from employees e where e.department_id = d.department_id ) as 员工个数 from departments d ;- 哪种方式执行效率更高一些?
-
-
group by note 2
-
-
5.3 Exist 子查询的使用。(未充分理解)
博客园'半壁江山'总结详细,可供参考 关键字: 执行顺序&规则,boolean,应用场景,效率。 -
5.4 如题:查询各部门中工资比所在部门平均工资高的员工的员工号,姓名,薪资
-
① 第一想法: 内连接+where clause 子查询 关联三表 ,结果正确,表面也易理解。
select d.department_id , d.department_name ,e.employee_id , e.last_name , e.salary from employees e join departments d on e.department_id = d.department_id where salary > (select avg(salary) from employees em where em.department_id = e.department_id); -
② 将各部门的平均工资通过 select 子查询 命名'建表' ——davg。employees,departments,davg 三表左外连接 。
select d.department_id , d.department_name ,e.employee_id , e.last_name , e.salary , davg.a as 该部平均工资 from departments as d left join employees as e on e.department_id = d.department_id left join (select department_id , avg(salary) a from employees group by department_id ) as davg on davg.department_id = d.department_id where e.salary > davg.a order by davg.a,e.salary; -
③ 当然也可以省略select 字段中的department_name 字段,从而免去departments表与另外两表的连接。只将e表与davg表(通过select 子查询命名的各部门平均薪资表)内连接或者外连接。代码略。
-
-
5.5 如题:查询平均工资最低的部门信息
-
错解1: 子查询所构建的表不识别,失效
SELECT d.*, davg.a FROM departments AS d RIGHT JOIN ( SELECT department_id, avg( salary ) a FROM employees #WHERE department_id IS NOT NULL GROUP BY department_id ) AS davg ON davg.department_id = d.department_id WHERE davg.a = ( SELECT MIN( davg.a ) FROM davg );- 现象:在上述写法中,除去where 语句,运行正常。添加后显示:
Table 'my_employees.davg' doesn't exist。 - ① 通过将where 子查询语句直接更改为‘TRUE’,发现虽然结果为空,但并没有报错。说明错误之处一定是where子查询语句,即where子查询中的davg不能识别
② 猜想:子查询中所调用的只能是当前系统已显式create并存储的当前数据库中的"全局表",各个子查询之间是独立的,所以在right join 语句中所建的表davg不能在where 子查询语句中被识别。
- 现象:在上述写法中,除去where 语句,运行正常。添加后显示:
-
正解1: 使用 order by + limit 的结合语句来实现查询效果
SELECT d.*, davg.a FROM departments AS d LEFT JOIN ( SELECT department_id, avg( salary ) a FROM employees GROUP BY department_id ) AS davg ON davg.department_id = d.department_id #内连接更简? ORDER BY davg.a ASC LIMIT 1;# 可修改行数确定是否最低值是否有并列情况。该策略同样适用于: 其他有关 '最低,最高 '类字眼的查询 (在此不考虑效率问题)
-
正解2:复杂嵌套1
SELECT d.* FROM departments d WHERE department_id = ( #此处 '=' 换用 'in' 更好 SELECT davg.department_id FROM ( SELECT department_id, avg(salary) a FROM employees GROUP BY department_id ) AS davg WHERE a = ( SELECT MIN(该部平均工资) FROM (SELECT avg(salary) AS 该部平均工资 FROM employees GROUP BY department_id ) AS davg # 'AS davg' 必须有,语法要求。尽管前面select min(arg)不加davg也OK ) ) # 两个子查询字段中的别名‘davg’互不影响,当然若写成不一样更易理解。此类嵌套查询解题思路:
①明确各个层次,清晰定义。② 从最内层,最小解题单元开始,逐步完善。③ 耐心,耐心。
疑问:对于mysql中重复出现的语句有没有类似命名定义方法。 -
正解3:复杂嵌套2
SELECT d.* FROM departments d WHERE department_id = ( #此处 '=' 换用 'in' 更好 SELECT department_id FROM employees e GROUP BY department_id HAVING AVG(salary) = ( SELECT MIN( a ) FROM ( SELECT AVG(salary) a FROM employees GROUP BY department_id ) AS davg ) )该解不同与正解3的地方在于Having 子句的使用替代了where子查询嵌套,需要理解的是:
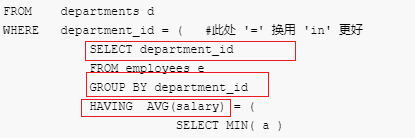
要真正理解group by 子句的所带来的效果/意义,以及各子句之间的执行顺序:
① group by 子句的使用必然与' 需使用聚合类函数的需求'有关(想不出没有使用聚合类函数的需求仍然使用group by 子句的),但: 并不意味着聚合类函数一定[显式]出现在select 语句的字段中,它也可以出现在 having ,where 等子句中(执行顺序在它之后的就OK)
② 执行顺序:from 子句,join ta_name on cond类 子句 , group by 子句 , having 子句 , where 子句,select 子句 ,order by 子句,limit 子句。 -
解5 存储过程?视图?
-
-
5.6 如题:查询平均工资最高的部门的manager的详细信息:last_name ,department_id ,email,salary
-
method 1 :直接瞄准最终目标,由外向内,需要什么就嵌套查询什么。
SELECT last_name ,email,salary,department_id FROM employees WHERE employee_id = ( SELECT d.manager_id FROM departments d WHERE department_id = ( SELECT e.department_id FROM employees e GROUP BY department_id ORDER BY avg(salary) DESC LIMIT 1 ) ) -
method 2 :多表外连接查询----------先忽略精确化要求,select出大体要求的信息,之后在此基础上在进行筛选。
# 1.每个部门的manager的详细信息 SELECT d.department_id,d.manager_id, e.employee_id,e.last_name,e.email,e.salary FROM departments d LEFT JOIN employees e ON d.manager_id = e.employee_id #2-1. 在1的基础上使用where语句以department_id进行筛选(最终不能够显示部门出对应的平均工资) SELECT d.department_id,d.manager_id, e.employee_id,e.last_name,e.email,e.salary FROM departments d LEFT JOIN employees e ON d.manager_id = e.employee_id WHERE department_id = ( SELECT department_id FROM employees e GROUP BY department_id ORDER BY AVG(salary) DESC LIMIT 1 ) #2-2. 在1的基础上使用再次LEFT JOIN 各部门的工资表-------> ①最终能够选择显示部门出对应的平均工资 ② 能够选择显示所有部门的manager的详细信息,及部门平均工资 SELECT d.department_id,d.manager_id, t_avg.d_avgs, e.employee_id,e.last_name,e.email,e.salary FROM departments d LEFT JOIN employees e ON d.manager_id <=> e.employee_id LEFT JOIN ( SELECT department_id ,AVG(salary) as d_avgs FROM employees e GROUP BY department_id ) AS t_avg ON d.department_id <=> t_avg.department_id ORDER BY d_avgs DESC LIMIT 1;
-
-
