
什么是生命,这取决于肝脏。——《调音师》影评

调音师是一部很有看点的电影,在朋友的安利下看了两遍!不错!就是两遍!我觉得我爬完这个数据还可以再来一遍!
10分钟的剧情给我反转反转再反转!
是一部人性的剧,最后结局导演给大家留下了一个很悬的疑点:“剧中究竟死了多少人?” !!!
确实,这也成为了大家讨论的点。因为有太多的可能性,一个个镜头的暗喻,一颗看似有无的树居然也有那么大的隐含!?我要重新仔细看一遍了!
现在说说我爬到数据的过程~主要用了scrapy框架,下面简单介绍一下他的模块功能和开发爬虫的流程:
模块功能
Scrapy Engine(引擎):
处理整个系统各个模块间信号
Spiders(爬虫类):
发起起始的请求,返回request给Scheduler
定义如何爬取一个网站,获取数据
Scheduler(调度器):
接收引擎发过来的request请求,压入队列
引擎需要时,取出request请求,返回给引擎
Downloader(下载器):
接收请求,返回响应
ItemPipeline(管道):
数据后续处理,处理Spiders返回的item.
分析目标站点,测试反爬
创建项目:scrapy startproject <项目名>
明确目标
创建爬虫:scrapy genspider <爬虫名> <域名>
保存
上主要代码!
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# author : jin time :2019/3/3
import pandas as pd
from collections import Counter
from pyecharts import Geo, Bar, Scatter
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud, STOPWORDS
import time
#观众地域图中部分注释
#attr:标签名称(地点)
#value:数值
#visual_range:可视化范围
#symbol_size:散点的大小
#visual_text_color:标签颜色
#is_visualmap:是否映射(数量与颜色深浅是否挂钩)
#maptype:地图类型
#读取csv文件(除了词云,其它图表用的源数据)
def read_csv(filename, titles):
comments = pd.read_csv(filename, names = titles, low_memory = False)
return comments
#词云用的源数据(比较小)
def read_csv1(filename1, titles):
comments = pd.read_csv(filename1, names = titles, low_memory = False)
return comments
#观众地域排行榜单
def draw_bar(comments):
data_top20 = Counter(comments['city_name']).most_common(20) #前二十名城市
bar = Bar('《调音师》观众地域排行榜单', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data_top20)
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 4500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众地域排行榜单-柱状图.html')
print('观众地域排行榜单已完成')
#观众评论数量与日期的关系
#必须统一时间格式,不然时间排序还是乱的
def draw_data_bar(comments):
time1 = comments['time']
time_data = []
for t in time1:
if pd.isnull(t) == False and 'time' not in t: #如果元素不为空
date1 = t.replace('/', '-')
date2 = date1.split(' ')[0]
current_time_tuple = time.strptime(date2, '%Y-%m-%d') #把时间字符串转化为时间类型
date = time.strftime('%Y-%m-%d', current_time_tuple) #把时间类型数据转化为字符串类型
time_data.append(date)
data = Counter(time_data).most_common() #data形式[('2019/2/10', 44094), ('2019/2/9', 43680)]
data = sorted(data, key = lambda data : data[0]) #data1变量相当于('2019/2/10', 44094)各个元组 itemgetter(0)
bar =Bar('《调音师》观众评论数量与日期的关系', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data) #['2019/2/10', '2019/2/11', '2019/2/12'][44094, 38238, 32805]
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 3500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众评论日期-柱状图.html')
print('观众评论数量与日期的关系已完成')
#观众评论数量与时间的关系
#这里data中每个元组的第一个元素要转化为整数型,不然排序还是乱的
def draw_time_bar(comments):
time = comments['time']
time_data = []
real_data = []
for t in time:
if pd.isnull(t) == False and ':' in t:
time = t.split(' ')[1]
hour = time.split(':')[0]
time_data.append(hour)
data = Counter(time_data).most_common()
for item in data:
temp1 = list(item)
temp2 = int(temp1[0])
temp3 = (temp2,temp1[1])
real_data.append(temp3)
data = sorted(real_data, key = lambda x : x[0])
bar = Bar('《调音师》观众评论数量与时间的关系', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data)
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 3500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众评论时间-柱状图.html')
print('观众评论数量与时间的关系已完成')
#词云,用一部分数据生成,不然数据量有些大,会报错MemoryError(64bit的python版本不会)
def draw_word_cloud(comments):
data = comments['comment']
comment_data = []
print('由于数据量比较大,分词这里有些慢,请耐心等待')
for item in data:
if pd.isnull(item) == False:
comment_data.append(item)
comment_after_split = jieba.cut(str(comment_data), cut_all = False)
words = ' '.join(comment_after_split)
stopwords = STOPWORDS.copy()
stopwords.update({'可以','好看','电影', '非常', '这个', '那个', '因为', '没有', '所以', '如果', '演员', '这么', '那么', '最后', '就是', '不过', '这个', '一个', '感觉', '这部', '虽然', '不是', '真的', '觉得', '还是', '但是'})
wc = WordCloud(width = 800, height = 600, background_color = '#000000', font_path = 'simfang', scale = 5, stopwords = stopwords, max_font_size = 200)
wc.generate_from_text(words)
plt.imshow(wc)
plt.axis('off')
plt.savefig('G:\\影评\\WordCloud.png')
plt.show()
#观众评分排行榜单
def draw_score_bar(comments):
score_list = []
data_score = Counter(comments['score']).most_common()
for item in data_score:
if item[0] != 'score':
score_list.append(item)
data = sorted(score_list, key = lambda x : x[0])
bar = Bar('《调音师》观众评分排行榜单', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data)
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 4500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众评分排行榜单-柱状图.html')
print('观众评分排行榜单已完成')
#观众用户等级排行榜单
def draw_user_level_bar(comments):
level_list = []
data_level = Counter(comments['user_level']).most_common()
for item in data_level:
if item[0] != 'user_level':
level_list.append(item)
data = sorted(level_list, key = lambda x : x[0])
bar = Bar('《调音师》观众用户等级排行榜单', '数据来源:Mr.W', title_pos = 'center', width = 1200, height = 600)
attr, value = bar.cast(data)
# is_more_utils = True 提供更多的实用工具按钮
bar.add('', attr, value, is_visualmap = True, visual_range = [0, 4500], visual_text_color = '#fff', is_more_utils = True, is_label_show = True)
bar.render('G:\\影评\\观众用户等级排行榜单-柱状图.html')
print('观众用户等级排行榜单已完成')
if __name__ == '__main__':
filename = 'G:\\info.csv'
filename2 = 'G:\\info.csv'
titles = ['city_name','comment','user_id','nick_name','score','time','user_level']
comments = read_csv(filename, titles)
comments2 = read_csv1(filename2, titles)
draw_map(comments)
draw_bar(comments)
draw_data_bar(comments)
draw_time_bar(comments)
draw_word_cloud(comments2)
draw_score_bar(comments)
draw_user_level_bar(comments)
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pandas as pd
class MaoyanPipeline(object):
def process_item(self, item, spider):
dict_info = {'city': item['city'], 'content': item['content'], 'user_id': item['user_id'],
'nick_name': item['nick_name'],
'score': item['score'], 'time': item['time'], 'user_level': item['user_level']}
try:
data = pd.DataFrame(dict_info, index=[0]) # 为data创建一个表格形式 ,注意加index = [0]
data.to_csv('G:\info.csv', header=False, index=True, mode='a',
encoding='utf_8_sig') # 模式:追加,encoding = 'utf-8-sig'
except Exception as error:
print('写入文件出错-------->>>' + str(error))
else:
print(dict_info['content'] + '---------->>>已经写入文件')
# -*- coding: utf-8 -*-
import scrapy
import random
from scrapy.http import Request
import datetime
import json
from maoyan.items import MaoyanItem
class CommentSpider(scrapy.Spider):
name = 'comment'
allowed_domains = ['maoyan.com']
thisua = random.choice(uapools)
header = {'User-Agent': thisua}
current_time = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
current_time = '2019-04-03 11:20:49'
end_time = '2019-04-03 00:18:00' # 电影上映时间
url = 'http://m.maoyan.com/mmdb/comments/movie/1239544.json?_v_=yes&offset=0&startTime=' +current_time.replace(' ','%20')
def start_requests(self):
current_t = str(self.current_time)
if current_t > self.end_time:
try:
yield Request(self.url, headers=self.header, callback=self.parse)
except Exception as error:
print('请求1出错-----' + str(error))
else:
print('全部有关信息已经搜索完毕')
def parse(self, response):
item = MaoyanItem()
data = response.body.decode('utf-8', 'ignore')
json_data = json.loads(data)['cmts']
count = 0
for item1 in json_data:
if 'cityName' in item1 and 'nickName' in item1 and 'userId' in item1 and 'content' in item1 and 'score' in item1 and 'startTime' in item1 and 'userLevel' in item1:
try:
city = item1['cityName']
comment = item1['content']
user_id = item1['userId']
nick_name = item1['nickName']
score = item1['score']
time = item1['startTime']
user_level = item1['userLevel']
item['city'] = city
item['content'] = comment
item['user_id'] = user_id
item['nick_name'] = nick_name
item['score'] = score
item['time'] = time
item['user_level'] = user_level
yield item
count += 1
if count >= 15:
temp_time = item['time']
current_t = datetime.datetime.strptime(temp_time, '%Y-%m-%d %H:%M:%S') + datetime.timedelta(
seconds=-1)
current_t = str(current_t)
if current_t > self.end_time:
url1 = 'http://m.maoyan.com/mmdb/comments/movie/1239544.json?_v_=yes&offset=0&startTime=' + current_t.replace(
' ', '%20')
yield Request(url1, headers=self.header, callback=self.parse)
else:
print('全部有关信息已经搜索完毕')
except Exception as error:
print('提取信息出错1-----' + str(error))
else:
print('信息不全,已滤除')
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
city = scrapy.Field() # 城市
content = scrapy.Field() # 评论
user_id = scrapy.Field() # 用户id
nick_name = scrapy.Field() # 昵称
score = scrapy.Field() # 评分
time = scrapy.Field() # 评论时间
user_level = scrapy.Field() # 用户等级
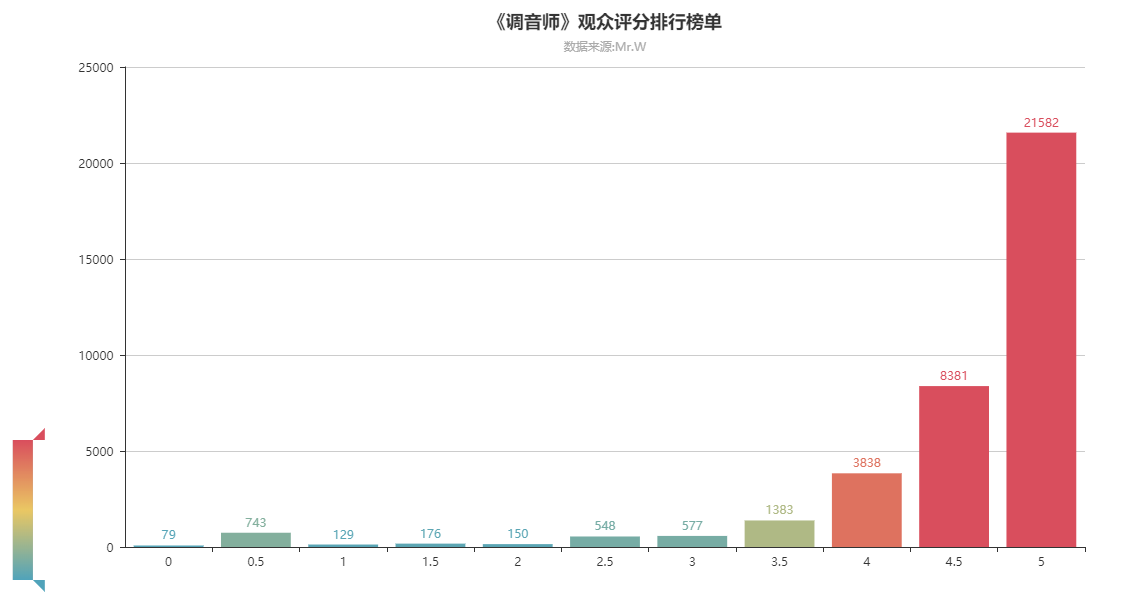
爬出来的大家对这部剧的评分,还是很高的哦~5分居多
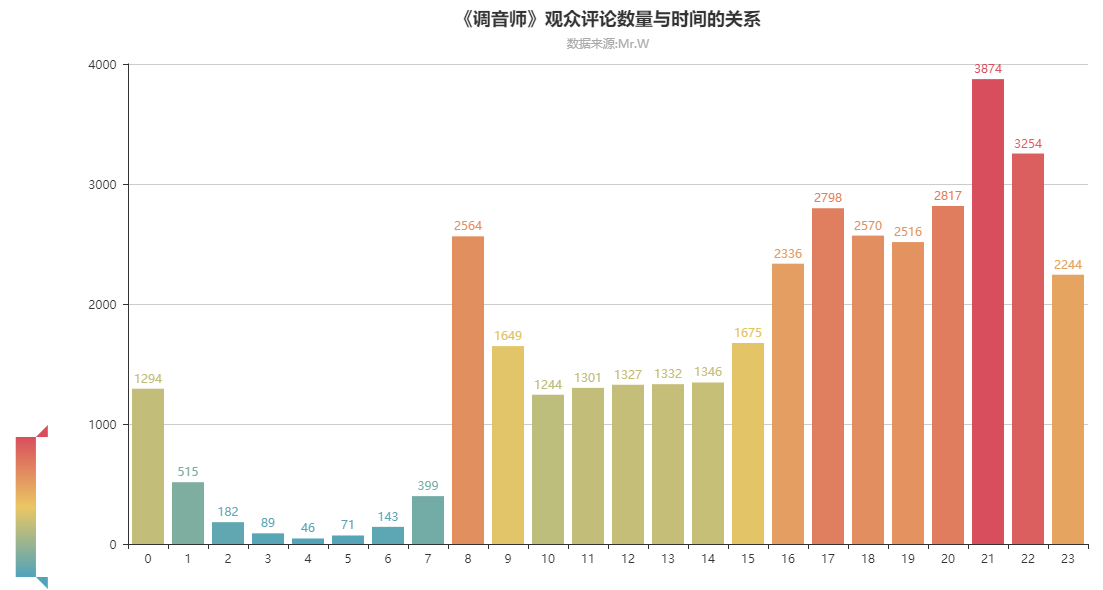
这部剧从31号开始点映,3号正式上映以来观看人数不断上升,看的人越来越多好评也越来越多,讨论的人数也随着观看的人数出现了越来越多的可能性和越来越多的猜测。
有的人说“男主最后和医生卖掉了坏女人,获得了一笔资金”有的人说“男主最后逃了出来,获得富婆的赞助来到了外国”,还有的人说“医生一开始就是想卖了男主,所以男主最后把两个人都杀了,眼睛也好了”等等。
还有很多人认为男主最后那一棍,不是随意的,而是愤怒的一棍因为女主不是他喜欢的样子了,人性最后还是会改变的,等等。

过滤掉了一些无用的词,后再过滤一开始占榜首的“好看”,最后结果如上图所示。
男主、结局、反转、结尾、果然是讨论最多的。细心的会发现还有几个人们讨论最多的词“看见”、“看到”、“应该完全”,根据剧情其实可以推断出大家更倾向的结局是****(怕没看过的人觉得我是剧透,我把推断出的东西写在后面~~)
剧透:慎看

1、我觉得剧情从这颗树开始就有种男主自导自演的感觉。男主从一开始眼睛在水里其实就明显一只不是全部的瞎了,一手捂住坏女人这个动作,觉得男主其实一开始是不是就有一点看得见了。
2、从数据挖出来的一些评论,基本上很多人是认为男主后面视力是恢复了的。
3、那是怎么恢复了的呢?我个人更倾向与男主把坏女人和医生杀了,然后把他们两个一起卖掉,拿了钱恢复了视力来到了伦敦。从警察局那里男主想象自己爆出事实的拍摄手法来看和后面树开始的手法是一样的,所以可以认为从那开始是男主自己想象的。
4、隐藏节点:片头那句.....说来话长,咖啡?
础论据:隐藏节点,电影开始的时候,是以一句说来话长,咖啡?也就是说,本电影节点一以前所以的故事也是由男主讲述的,除了苏菲参与的部分,以及新闻报道等现实能查证的事情以外,别的故事都有可能是男主编造的。
个人观点不喜勿喷~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号