
复合数据类型,英文词频统计
1.列表,元组,字典,集合分别如何增删改查及遍历。
列表
list=['30','50']
list.append( '20' )#增加元素
del list[1]#删除第二个元素
list[1]='10' #更改第二个元素
list.insert(2,'10') #插入列表
list.index('20')#查找元素的位置
list.index['50'] # 查看元素50的位置
list.count('30') #统计元素个数
list.copy()复制列表
for i in list: printf(list[i]) #遍历
tr=['30','50'] tr2=['20','30']#元组
# 元组不能进行增加和修改删除元组中的元素,其实就是要把元组看做一个整体,对一个元组进行删除和增加。
del tr #删除整个元组
tr3=tr+tr2 #把两个元组组合在一起,结果为tr3=['30','50','20','30']
printf(tr[0]) #查找元组中的第一个元素
for i in range(len(tr)): printf(tr[i]) #遍历
d['a']=11 #字典修改键a 的值
del d['a'] #删除键a
a=d['a'] #查看键a的值
d.clear() #删除字典中的所有条目
str(d) #输出字典
for key in d:printf(d[key]) #遍历
a=set('a')#集合
a.add('b') #增加元素
a.remove('b') 或者 a.discard('b') #删除元素
a.pop() #随机删除元素
集合无序,不能查找和修改指定的元素
2.总结列表,元组,字典,集合的联系与区别。参考以下几个方面:
括号
列表[]; 元组(); 字典{};集合()或者{}
有序无序
列表和元组有序,字典和集合无序
可变不可变
列表,字典可变,元组不可变,集合可变也可不变
重复不可重复
列表,元组,字典可重复,集合不可重复
存储与查找方式
列表:存储在连续的内存地址中,利用下标索引号查找。
元组:偏移存取,可以进行索引查找
字典:键-值存储方式 ,通过键查找值
集合:存储的元素是无序且不重复 ,可以通过in或not in查找
3.词频统计
-
-
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
-
8.输出TOP(50)
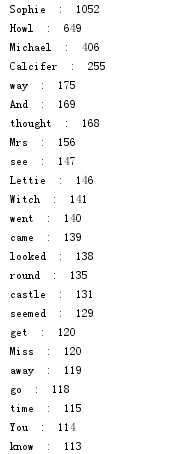
-
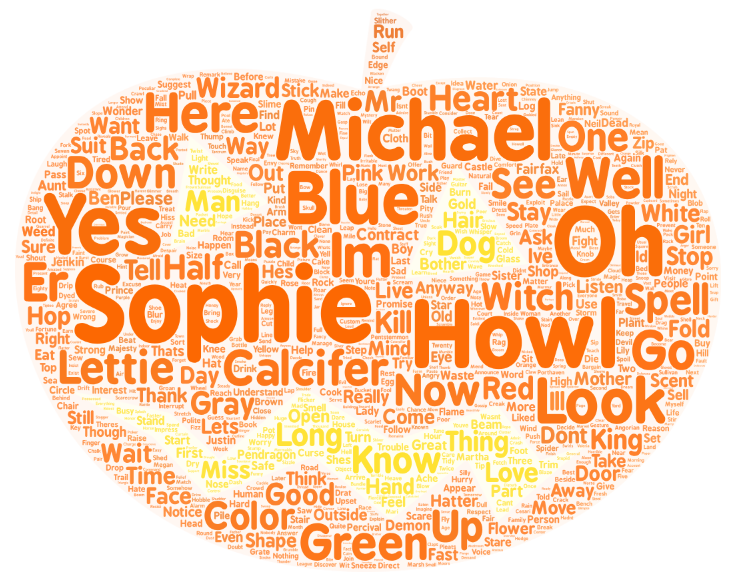
- 9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create
代码如下所示
import re
import pandas
from stop_words import get_stop_words
stop_words = get_stop_words('english')
file = open("Howl’s Moving Castle.txt", "r+", encoding='UTF-8')
str = file.read()
str = re.sub('[\r\n\t,!?:;“‘’.\"]', '', str)
words = str.split(" ")
single = [] # 分词数组
excluding_words = [] # 排除的单词
quantity = [] # 单词次数
for word in words:
if (word not in single and word not in stop_words):
single.append(word)
tmp = single.copy()
while tmp:
# print(tmp[0], "出现次数:", words.count(tmp[0]), end=" ")
quantity.append(words.count(tmp[0]))
tmp.pop(0)
dic = dict(zip(single, quantity)) # 合成字典
dic = sorted(dic.items(), key=lambda item: item[1], reverse=True) # 排序
for i in range(50):
print(dic[i][0], " : ", dic[i][1])
pandas.DataFrame(data=dic).to_csv('fenci.csv', encoding='utf-8')
print(stop_words)
file.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号