爬虫01
一. 基本库的使用
1.urllib
python的内置请求库,包含以下4个模块:
- request # 可以用来模拟发送请求,需要提供url以及额外的参数
- error # 异常处理模块,当请求出现错误,可以用来捕获异常
- parse # 一个工具模块,提供许多url处理方法
- robotparser # 用来识别网站的robots.txt文件
发送请求:
1.1 urlopen !!!
import urllib.request
response = urllib.request.urlopen(url='https://pic.netbian.com/')
# 获取响应类型
print(type(response))
<class 'http.client.HTTPResponse'>
# 获取二进制的数据
# print(response.read())
# 将获取到的二进制数据进行转码成为字符串
print(response.read().decode('gbk'))
-
该响应对象主要包括read()、readinto()、getheader(name)、getheaders()、fileno()等方法 以及msg、version、status、reason、debuglevel、closed等属性 -
参数
urlopen函数原型:urllib.request.urlopen(url, data=None, timeout=<object object at 0x10af327d0>, *, cafile=None, capath=None, cadefault=False, context=None) 在日常开发中,我们能用的只有url和data这两个参数。 'url的特性:url必须为ASCII编码的数据值。所以我们在爬虫代码中编写url时,如果url中存在非ASCII编码的数据值,则必须对其进行ASCII编码后,该url方可被使用' -
data参数的使用
- 当我们使用了data参数时,我们所发的请求则为post请求
- 并且data不能接收一个字符串类型的参数
- 需要接收一个字节类型的数据
![image-20210909150104063]()
import urllib.request import urllib.parse # 1.先将post请求发送的参数字典转化为字符串 # 2.指定编码格式,将字符串数据转化为bytes类型 data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8') response = urllib.request.urlopen(url="http://httpbin.org/post", data = data) print(response) -
url特性
import urllib.request response = urllib.request.urlopen(url='https://www.baidu.com/s?wd=人民币')![image-20210909150730586]()
-
解决方法:非ASCII编码的数据值进行ASCII编码
import urllib.request import urllib.parse url = "https://www.baidu.com/s?" parse = urllib.parse.urlencode({"wd":'人民币'}) # wd=%E4%BA%BA%E6%B0%91%E5%B8%81 url = url + parse response = urllib.request.urlopen(url=url) print(response)
-

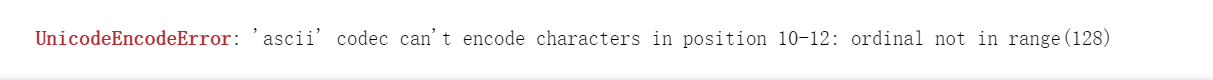
1.2 Request !!!
- 通过上面的urlopen我们已经可以模拟发送一些简单请求了
- 但那其中的参数满足构建一个完整的请求,如果需要加入Headers等信息,我们需要Request类来构建
1.2.1 Request的构造
class urllib.request.Request(url,data=None,headers={},origin_req_host=None,unverifiable=False,method=None)
1.2.2 参数说明
1.url: 请求url,必填参数,其它都为可选参数
2.data: 如果需要传该参,则必须为字节类型数据。如果是字典,可以用urllib.parse中的urlencode()进行编码
3.headers: 就是请求头,一个字典
4.origin_req_host: 请求方的ip地址或host名称
5.unverifiable: 默认值为False,表示该请求无法验证(用户没有足够的权限来选择接收该请求的结果)
6.method: 指定该次请求的方法,例如:GET、POST、PUT等
1.2.3 示例
from from urllib import request, parse
url = "http://httpbin.org/post"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
"Host":'httpbin.org'
}
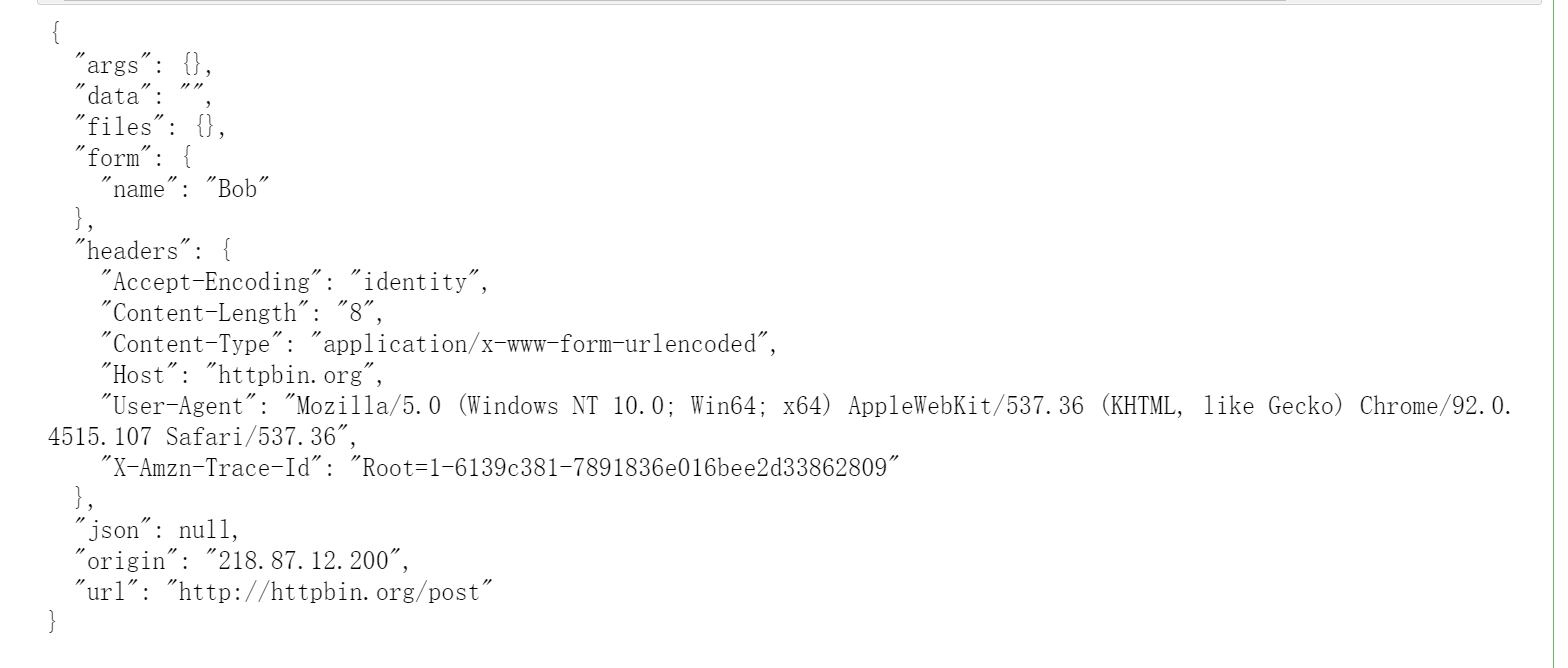
a = {'name': 'Bob'}
# 将要传入data参数的数据转化为字节流
b = bytes(parse.urlencode(a), encoding='utf8')
req = request.Request(url=url, data=b, headers=headers, method='POST')
# data = bytes(parse.urlencode({'word': 'hello'}), encoding='utf8')
# req = request.Request(url=url, data=data, method='POST')
# req.add_header('User-Agent', "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36")
response = request.urlopen(req)
print(response.read().decode('utf-8'))
解析链接
- 处理了url的标准接口,实现了url的各部分的抽取、合并、以及链接转换
1.3 urlparse
- 该方法可以实现url的识别与分段
1.3.1 示例
from urllib.parse import urlparse
result = urlparse('https://www.baidu.com/index.html;user?id=5#comment')
print(type(result))
print(result)

根据打印的结果我们可以大概知晓:
1.scheme: 表示协议
2.netloc: 表示域名
3.path: 访问路径
4.params: 代表参数
5.?后面是查询条件query
6.#后面是锚点,用于直接定位页面内部的下拉位置
1.3.2 构造
urllib.parse.urlparse(url, scheme='', allow_fragments=True)
1.3.3 参数说明
url: 必填参数,即将解析的url
scheme: 默认的协议(http/https等..)
allow_fragments: 是否忽略fragment.如果被设置为False,fragment部分就会被忽略,
它就会被解析为path、parameters或者query的一部分,而fragment部分就会为空
-
示例
from urllib.parse import urlparse # 在url中含有params和query的状态下将allow_fragments设置为false result = urlparse('https://www.baidu.com/index.html;user?id=5#comment', allow_fragments=False) print(result) ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5#comment', fragment='') # 在url中不含有params和query的状态下将allow_fragments设置为false result = urlparse('https://www.baidu.com/index.html#comment', allow_fragments=False) print(result) ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html#comment', params='', query='', fragment='') -
可以发现,当url中不含有params和query时,fragment将会被解析为path都一部分 -
ParseResult实际上是一个元组,可以通过索引的方式取值或通过属性名来获取值 -
print(result.scheme, result[0], esult.netloc)
1.4 urlunparse
- 既然有了可以将url各部分解析出的方法,当然也有将各部分重新拼接在一起的方法咯
from urllib.parse import urlunparse
data = ['https', 'www.baidu.com', 'index.html', 'user', 'a=6', 'comment']
print(urlunparse(data))
# 按列表元素顺序来将url进行拼接
www.baidu.com://https/index.html;user?a=6#comment
1.5 urlsplit
该方法与urlparse方法非常类似,不过它不再单独解析params这一部分,只返回5个结果。而params会被合并到path当中
-
示例
from urllib.parse import urlsplit result = urlsplit('https://www.baidu.com/index.html;user?id=5#comment') print(type(result)) <class 'urllib.parse.SplitResult'> print(result) SplitResult(scheme='https', netloc='www.baidu.com', path='/index.html;user', query='id=5', fragment='comment') -
SplitResult也同样是一个元组,可以通过索引或属性取值
1.6 urlunsplit
-
与urlunparse类似,也是将链接的各部分拼接到一起,传入的参数也是一个可迭代对象
-
示例
from urllib.parse import urlunsplit data = ['http', 'www.baidu.com', 'index.html', 'a=6', 'comment'] print(urlunsplit(data)) # http://www.baidu.com/index.html?a=6#comment
1.7 urljoin
-
使用
urlunparse和urlunsplit可以完成链接的拼接,但是有弊端 -
那就是我们需要自己手动指定链接的各个部位在迭代对象中的位置,这样使用起来毫无体验
-
所以,这里我们引出另一个方法 :
urljoin我们提供一个base_url(基础链接)作为第一个参数,将新的链接作为第二个参数,该方法会分析base_url的scheme(协议)、netlco(域名)和path(访问路径)这三个内容并对新链接缺失的部分进行补充,最后返回接结果 -
示例
from urllib.parse import urljoin print(urljoin('http://www.baidu.com', 'FAQ.html')) print(urljoin('http://www.baidu.com', 'https://cuiqingcai.com/FAQ.com')) print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.com')) print(urljoin('http://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.com?question=2')) print(urljoin('http://www.baidu.com?wd=abc', '?category=2#comment')) print(urljoin('http://www.baidu.com', '?category=2#comment')) print(urljoin('http://www.baidu.com#comment', '?category=2'))-
结果
http://www.baidu.com/FAQ.html https://cuiqingcai.com/FAQ.com https://cuiqingcai.com/FAQ.com https://cuiqingcai.com/FAQ.com?question=2 http://www.baidu.com?category=2#comment http://www.baidu.com?category=2#comment http://www.baidu.com?category=2
-
-
通过示例可以看出,base_url提供scheme、netloc、path.如果这三项在新的链接中不存在,就使用base_url中的进行补充 如果新的链接存在这三项,就使用本身,并且不会去使用base_url中params、query和fragment任何一项
1.8 urlencode !!!
-
这个建议配合上面写的
urlopen一起看urlopen使用data参数- 还有那个url特性需要用到
urlencode - 字符串中文类型可以参考使用
quote
-
可以用于构造get请求参数
-
用法示例
from urllib.parse import urlencode data = {'name':'xiaoming','age':19} base_url = 'https://www.baidu.com?' url = base_url + urlencode(data) print(url) # https://www.baidu.com?name=xiaoming&age=19
1.9 parse_qs和parse_qsl
-
parse_qs-
用于反序列化,将get请求参数反序列为字典
-
示例:
from urllib.parse import parse_qs params = 'name=xiaoming&age=19' print(parse_qs(params)) {'name': ['xiaoming'], 'age': ['19']}
-
-
parse_qsl-
也是用于反序列化,将get请求参数反序列化为列表套元组
-
示例:
from urllib.parse import parse_qsl params = 'name=xiaoming&age=19' print(parse_qsl(params)) [('name', 'xiaoming'), ('age', '19')]
-
1.10 quote和unquote
-
quote-
可以将中文字符转为URL编码
-
示例:
from urllib.parse import quote name = '小明' url = 'https://www.baidu.com/s?wd=' + quote(name) print(url) # https://www.baidu.com/s?wd=%E5%B0%8F%E6%98%8E
-
-
unquote-
将URL编码进行解码
-
示例:
from urllib.parse import unquote url = 'https://www.baidu.com/s?wd=%E5%B0%8F%E6%98%8E' print(unquote(url)) # https://www.baidu.com/s?wd=小明
-
2. requests
2.1 GET请求
2.1.1 示例
import requests
res = requests.get(url="https://www.baidu.com") # 还可以发送post、put、delete、options等请求方法
print(type(res))
# 获取服务器返回二进制类型响应体数据
print(res.text)
# 获取文本响应体数据
print(res.content)
# 获取cookie
print(res.cookies)
2.1.2 params参数
-
示例
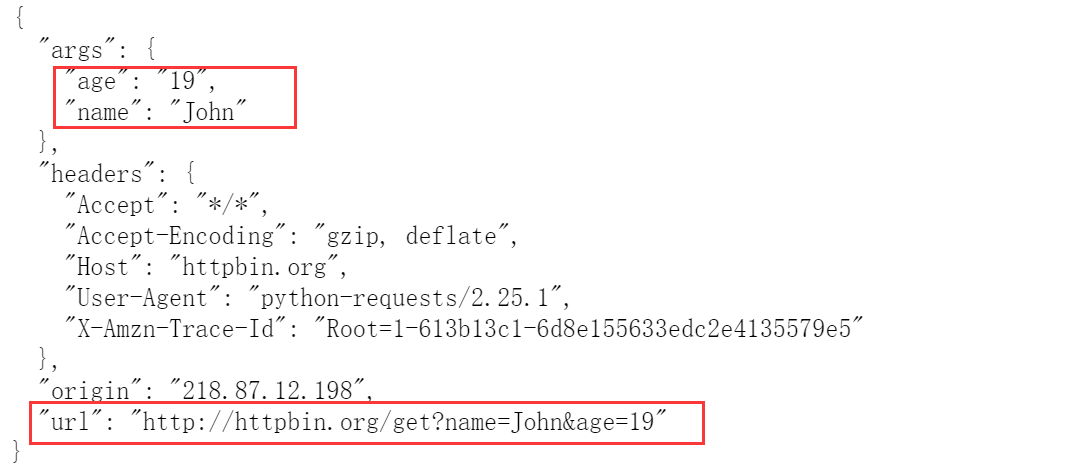
data = {"name": "John", "age": 19} res = requests.get("http://httpbin.org/get", params=data) print(res.text) # 虽然是一个字符串类型的数据,但是可以被json序列化![image-20210910161435286]()
-
若响应返回的数据是可以被json序列化的话,可以直接调用
.json()方法data = {"name": "John", "age": 19} res = requests.get("http://httpbin.org/get", params=data) print(res.json())![image-20210910161703458]()

2.1.3 headers
-
示例
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36", } requests.get(url="http://www.baidu.com", headers=headers)
2.2 POST请求
2.2.1 示例
import requests
data = {'age': '19', 'name': 'John'}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36",
}
res = requests.post(url="http://httpbin.org/post", data=data, headers=headers)
print(res.text)
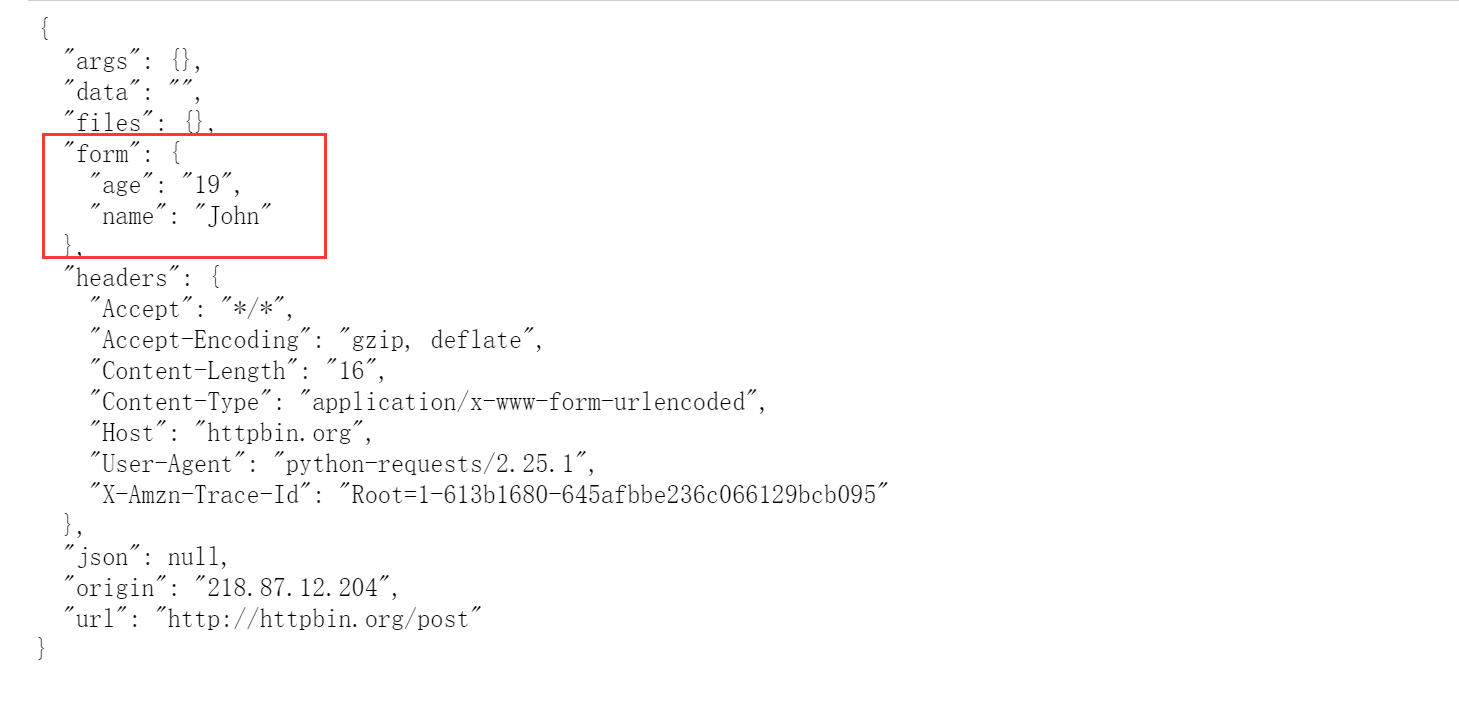
- form存储着我们post提交的数据
2.3 响应
- 见书128页:有状态码的对应表(我这里就不写了....)
发送请求后,我们可以从返回的响应获取想要的内容(content/text). 此外还有很多属性和方法可以用来获取其它的信息,比如状态码、响应头、Cookies等
-
示例
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36", } res = requests.get("https://www.jianshu.com", headers=headers) # 获取状态码 print(type(res.status_code), res.status_code) # 获取响应头 print(type(res.headers), res.headers) # 获取cookie,下面会有用处 print(type(res.cookies), res.cookies) # 获取请求url print(type(res.url), res.url) # 获取请求历史 print(type(res.history), res.history)![image-20210910163628845]()

2.4 高级用法
2.4.1 文件上传
import requests
files = {
'file':open('./222.png', 'rb')
}
res = requests.post('https://httpbin.org/post', files=files)
print(res.text)

2.4.2 Cookies
-
基于cookie的访问
import requests # 这里我已经登录的哔哩哔哩,所以我在这里直接将cookie抽取出来了 headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36", "Cookie":"_uuid=98B69C11-8AA9-F1CF-42AC-E1DFAE08D37D78511infoc; b_nut=1628518980; buvid3=F5116D7B-DFF8-47F9-AC34-FA5A60607DA5167611infoc; fingerprint=618010dfc570d6bc2ee837d24c4b8859; buvid_fp=498D58DE-AB85-4465-B3ED-AA1D91356FD5167629infoc; buvid_fp_plain=7BC53A8C-178C-4347-8C17-76FCCE36A676167616infoc; SESSDATA=a54e64b0%2C1644071017%2C2143e%2A81; bili_jct=e2fc5d3af8a953a6bb20a0cd6204adfc; DedeUserID=509492817; DedeUserID__ckMd5=53bf666e00c2a53c; sid=k4ovyjpk; CURRENT_FNVAL=80; blackside_state=1; rpdid=|(J|)Rlmk~mJ0J'uYk)lum|J); LIVE_BUVID=AUTO4616286463153359; CURRENT_QUALITY=80; bp_t_offset_509492817=565415213117629972; PVID=1; bp_video_offset_509492817=565876849086092730; innersign=0; bsource=search_baidu" } res = requests.get(url="https://space.bilibili.com/509492817", headers=headers) print(res.text)![image-20210910171648969]()
-
第二种
- 通过设置cooies参数来,需要设置RequestsCookieJar对象
import requests cookies = "_uuid=98B69C11-8AA9-F1CF-42AC-E1DFAE08D37D78511infoc; b_nut=1628518980; buvid3=F5116D7B-DFF8-47F9-AC34-FA5A60607DA5167611infoc; fingerprint=618010dfc570d6bc2ee837d24c4b8859; buvid_fp=498D58DE-AB85-4465-B3ED-AA1D91356FD5167629infoc; buvid_fp_plain=7BC53A8C-178C-4347-8C17-76FCCE36A676167616infoc; SESSDATA=a54e64b0%2C1644071017%2C2143e%2A81; bili_jct=e2fc5d3af8a953a6bb20a0cd6204adfc; DedeUserID=509492817; DedeUserID__ckMd5=53bf666e00c2a53c; sid=k4ovyjpk; CURRENT_FNVAL=80; blackside_state=1; rpdid=|(J|)Rlmk~mJ0J'uYk)lum|J); LIVE_BUVID=AUTO4616286463153359; CURRENT_QUALITY=80; bp_t_offset_509492817=565415213117629972; PVID=1; bp_video_offset_509492817=565876849086092730; innersign=0; bsource=search_baidu" jar = requests.cookies.RequestsCookieJar() headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36", } for cookie in cookies.split(';'): key, value = cookie.split('=', 1) jar.set(key, value) # 设置好每个cookie的key和value # 调用get方法将设置好的jar传递给cookie参数 res = requests.get(url="https://space.bilibili.com/509492817", headers=headers, cookies=jar) # 可以发现依然可以打印登录后的信息 print(res.text)

2.4.3 Session
- 是不是觉得上面设置cookie太麻烦了?还需要自己手动先去获取
- 这里我们将介绍Session,它会主动去处理cookie
- 例如当我们登录某个url之后如果具有cookie,它会将cookie保存下来
- 等再次访问该url就不需要再次进行登录操作,因为Session自己带了上一次保存下来的cookie
from requests import Session
# 创建一个Session实例化对象
session = Session()
# 请求该网址时,会设置一个cookie,名字为number,内容为1234567
# 使用实例化对象发送请求,该请求方式会保存产生的cookie
session.get('http://httpbin.org/cookies/set/number/1234567')
# 再次使用session访问该网址,可以拿到所设置的cookie
res = session.get('http://httpbin.org/cookies')
print(res.text)

2.4.4 代理
-
当我们向一个url频繁发送请求时,好一点是设置了访问频率,坏一点对方发现你是爬虫,可能就会封禁掉我们的ip 所以需要设置代理,需要用到proxies参数 代理自己去网上搜,这里我只告诉用法 -
示例
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36", } proxies = { 'http':'21.226.152.218:8080', # 'https':'xxxx.xxx.xx.x:y' } res = requests.get(url='http://www.baidu.com', headers=headers,proxies=proxies) print(res.text)
2.4.5 超时设置
-
当网络不好或对方服务器响应太慢时,我们可以设置超时时间,当时间超过设置时,就主动抛出异常 -
示例
import requests headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36", } res = requests.get(url='https://www.baidu.com', headers=headers, timeout = 1) # 单位:1秒 print(res.text)
3.正则表达式
3.1 常用的匹配规则
单字符:
. : 除换行以外所有字符
[] :[aoe] [a-w] 匹配集合中任意一个字符
\d :数字 [0-9]
\D : 非数字
\w :数字、字母、下划线、中文
\W : 非\w
\s :所有的空白字符包,括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。
\S : 非空白
数量修饰:
* : 任意多次 >=0
+ : 至少1次 >=1
? : 可有可无 0次或者1次
{m} :固定m次 hello{3,}
{m,} :至少m次
{m,n} :m-n次
边界:
$ : 以某某结尾
^ : 以某某开头
分组:
(ab)
贪婪模式: .*
非贪婪(惰性)模式: .*?
re.I : 忽略大小写
re.M :多行匹配
re.S :单行匹配
re.sub(正则表达式, 替换内容, 字符串)
3.2 match
该方法会从字符串的开头匹配正则表达式,如果匹配,就返回匹配成功的结果。否则则返回None
-
示例
import re content = "Hello 123 World " result = re.match('Hel.*?123\s\w{5}', content) print(result) print(result.group()) print(result.span())![image-20210910222715483]()
-
group()可以看到正则匹配的结果 span()可以输出匹配结果在原字符串中的位置范围 -
示例2(提取想要的内容)
import re content = "Hello 123 World " result = re.match('Hel.*?\s(.*?)\s\w{5}', content) print(result.group()) print(result.group(1)) -
可以在使用正则的时候将想要提取的内容用()包裹,而每一个()对应一个分组 调用group(index)方法,再传入某个()的索引就可以拿到该值

3.3 search
上面我们可以知道,match是从字符串开头进行匹配的,如果开头匹配不成功,那么就会返回None,这是非常不方便的,因为我们大部分提取的内容也不会在开头
所以我们这里再介绍一种方法:search
该方法在匹配时会扫描整个字符串,然后进行字符串的匹配,然后返回第一个成功匹配的结果。如果搜索完了也没有匹配到则返回None
-
示例:
import re content = "Hello 123 World 456 Where" result = re.search('.*?\s(.*?)\s(\w{5})', content) print(result.group(1)) # 123 print(result.group(2)) # World # 但是无法拿出456和where,因为它只能取出匹配成功的第一个结果,那怎么办捏?往下看![image-20210910222631213]()

3.4 findall
从上面的search方法可以看出该方法只能拿出匹配成功的第一个结果
如果还想要拿出第二个、第三个等结果我们可以使用findall方法
该方法会搜索整个字符串,并且返回匹配成功的所有内容
结果为一个列表,每一个元素为元组,每一个元组中存储着匹配成功的结果
-
示例
import re content = "Hello 123 World 456 Where" result = re.findall('.*?\s(.*?)\s(\w{5})', content) print(result)![image-20210910222603911]()

3.5 sub
-
可以用来修改文本
-
示例
import re content = "fah2ugh5iuu3g5287fasdf7asfddsdfds987GSDG" # 将不是数字的替换为空 result = re.sub('\D', '', content) print(result) -
第一个参数传入\D匹配非数字,第二个参数为替换的字符串(可以赋值为空),第三个参数为原字符串
3.6 compile
-
该方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用 -
示例
import re content1 = "2021-9-10 22:32" content2 = "2021-9-10 22:33" content3 = "2021-9-10 22:34" pattern = re.compile('\d{2}:\d{2}') result1 = re.sub(pattern, '', content1) result2 = re.sub(pattern, '', content2) result3 = re.sub(pattern, '', content3) print(result1, result2, result3)![image-20210910223855501]()
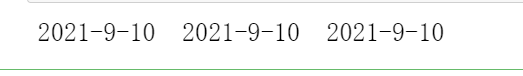

 浙公网安备 33010602011771号
浙公网安备 33010602011771号