python回顾
重点 !!!
只记录了我感觉需要记得,还有大部分没有记录,希望可以去看网址-------⬇------
python回顾
and(&) or (|)
# 1.当用&与|用于数值计算时
2 & 1 将数值化为2进制计算 10 & 01 结果为0
# 2.当用and 与 or计算数值时
2 and 1 判断两数值是否为0,0为false,非0为true.当两边都为true时,返回后面数值的值;有零就为0
3 or 2 值为第一个且不为0的值 ---> 3
0 or 3 ---> 3
"""所有的非空都是True"""
'一些面试题可能是 函数and函数 ' --- 记住,所有的非空都为True
字符串操作
# 1.切片操作 --- 顾头不顾尾
str[start:end:step]
# 2.常用方法:
'''
1.strip() 去掉空白 \n \t 空格
2.upper() 大写
3.split() 切割, 默认用空白切割
4.replace(old,new) 替换 -- 产生一个新的字符串
5.join() 拼接
6.count() 计数
7.find() 查找 从左往右查找,若没有找到返回-1 找到返回字符的位置数值
rfind() 从右往左查找,若没有找到返回-1
8.index() 索引查找
9.startswith() 以xxx开头
10. len() 长度
'''
字典
dict = {key:value}
key为不可变类型
# 可变对象: 列表、字典、集合。所谓可变是指可变对象的值可变,身份是不变的。
# 不可变对象:数字、字符串、元组。不可变对象就是对象的身份和值都不可变。新创建的对象被关联到原来的变量名,旧对象被丢弃,垃圾回收器会在适当的时机回收这些对象。
dict.setdefault(key,value) # 当key不存在时,则往dict中加入一组新键值。若存在,则不操作字典。两种都返回value
# 1.keys()
获取该字典的所有key
# 2.values()
获取该字典的所有值
# 3.items
获取该字典的key和value
for key,value in dict.items:
pass
驻留机制 --- 节省内存,快速创建对象
a = 'alex'
# 创建a对象时:先开辟内存空间,然后将值写入 在将a指向该内存地址
s = 'alex'
# 当创建s时:同样也是先开辟内存,将值写入时,发现写入的值与a的一致,于是将s也指向a所指向的内存地址
深浅拷贝
网址 -----> 很透彻
列表生成式
在一个列表生成式中,for前面的if ... else是表达式,而for后面的if是过滤条件,不能带else
L1 = ['Hello', 'World', 18, 'Apple', None]
L2 = [i.lower() for i in L1 if isinstance(i, str) ]
print(L2)
if L2 == ['hello', 'world', 'apple']:
print('测试通过!')
else:
print('测试失败!')
if写在for前面必须加else,否则报错
函数式编程
def func(*xx,**yy):
pass
func(*xx,**yy)
'*,**':'形参:聚合, 实参:打散'
闭包
例题非常有用
'''闭包:
内层函数使用外层函数的变量
作用:
1. 保护变量.
2. 常驻内存
'''
# 例题:
def func():
return [lambda x: x * i for i in range(4)]
a = [m(2) for m in func()]
print(a) # [6, 6, 6, 6]
拆分:
def func():
list1 = []
for i in range(4): # 函数m使用了外部函数func的变量i 形成了闭包
def m(x):
f = x*i
return f
list1.append(m)
# 当循环结束后,i的值为3 i=3
return list1
a = [m(2) for m in func()] # 此时a为一个函数列表, m(2)调用函数,变量i常驻内存,--> f = x*i
'一般情况下,在我们认知当中,如果一个函数结束,函数的内部所有东西都会释放掉,还给内存,局部变量都会消失。但是闭包是一种特殊情况,如果外函数在结束的时候发现有自己的临时变量将来会在内部函数中用到,就把这个临时变量绑定给了内部函数,然后自己再结束。'
# 例题:
def func():
return (lambda x: x * i for i in range(4)) # 此时为生成器
a = [m(2) for m in func()] # 当函数调用的时候取出值,每调用一次,拿一次
print(a) # [0,2,4,6]
装饰器
# 双层函数嵌套装饰
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
@log # ----> now = log(now)
def now():
print('2015-3-25')
# 三层函数嵌套装饰
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
@log('execute') # ---> now = log('execute')(now)
def now():
print('2015-3-25')
now()
1.先执行log('execute')返回函数decorator ---> now = decorator(now)
2. decorator(now)执行返回wrapper
3.最后执行now()等价于执行wrapper()
# 多个装饰器装饰一个函数:
def add_qx(func):
print("---开始进行装饰权限1的功能--")
def call_func(*args, **kwargs):
print("----这是权限验证1----")
return func(*args, **kwargs)
return call_func
def add_xx(func):
print("---开始进行装饰xxx的功能--")
def call_func(*args, **kwargs):
print("----这是xxx的功能----")
return func(*args, **kwargs)
return call_func
@add_qx
def call_func(*args, **kwargs):
print("----这是xxx的功能----")
return func(*args, **kwargs)
@add_xx # 等价test1 = add_xx(test1) = call_func = add_qx(call_func) = call_func
def test1():
print("-----test1------")
test1()
# 执行过程:
1. test1刚开始被add_xx装饰 --- > test1 = add_xx(test1)执行后返回add_xx中的call_func,func则为test1
2.返回的call_func进一步被add_qx装饰 ---> call_func = add_qx(call_func)
@add_qx
def call_func(*args, **kwargs):
print("----这是xxx的功能----")
return func(*args, **kwargs)
3.装饰后add_qx中的func为add_xx中的call_func
4. 装饰后返回add_qx中的call_func
5.即test1经过多次装饰 ---> test1 = call_func
6.执行test1() --- >等于执行call_func()
生成器
生成器
写生成器的方式:
1. 生成器函数 -> yield
2. 生成器表达式 -> (结果 for循环 if) # 闭包那有
特点:
1. 省内存
2. 惰性机制(面试题)
3. 只能向前. 不能反复
# 期待输出:
# [1]
# [1, 1]
# [1, 2, 1]
# [1, 3, 3, 1]
# [1, 4, 6, 4, 1]
# [1, 5, 10, 10, 5, 1]
# [1, 6, 15, 20, 15, 6, 1]
# [1, 7, 21, 35, 35, 21, 7, 1]
# [1, 8, 28, 56, 70, 56, 28, 8, 1]
# [1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
# 例题:
def triangles():
L =[1]
while True:
yield L[:] # 将L[:]值返回
L.append(0)
L=[L[i]+L[i-1] for i in range(len(L))]
n = 0
results = []
for t in triangles():
results.append(t)
n = n + 1
if n == 10:
break
for t in results:
print(t)
if results == [
[1],
[1, 1],
[1, 2, 1],
[1, 3, 3, 1],
[1, 4, 6, 4, 1],
[1, 5, 10, 10, 5, 1],
[1, 6, 15, 20, 15, 6, 1],
[1, 7, 21, 35, 35, 21, 7, 1],
[1, 8, 28, 56, 70, 56, 28, 8, 1],
[1, 9, 36, 84, 126, 126, 84, 36, 9, 1]
]:
print('测试通过!')
else:
print('测试失败!')
高阶函数
filter
# sorted, map, filter,reduce
sorted(迭代对象, key = func, reverse = xxx)
map(func, iter) 映射
filter(func, iter) 筛选
reduce(func,iter) 将上一次的结果作为参数
map
# map
def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
list(r) ---> [1, 4, 9, 16, 25, 36, 49, 64, 81]
reduce
# reduce
def prod(L):
def f(x, y):
return x * y
value = reduce(f, L)
return value
print('3 * 5 * 7 * 9 =', prod([3, 5, 7, 9]))
if prod([3, 5, 7, 9]) == 945:
print('测试成功!')
else:
print('测试失败!')
sorted
# sorted
sorted([36, 5, -12, 9, -21], key=abs) # 按绝对值排序,默认升序
[5, 9, -12, -21, 36]
# 按照名字排序:
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_name(t): # t为L中的元组 每调用一次,传入一个元组
return t[0]
L2 = sorted(L, key=by_name)
print(L2)
内置模块
random
# random
random.random() # 0-1之间的小数
random.uniform() # 小数 (m,n)
random.randint() 随机整数 [m,n]
random.choice() 从列表中随机选择一个
random.sample() 从列表中随机选择n个
random.shuffle() 打乱
time
# time模块
时间戳
time.time() 当前系统时间, 从1970-01-01 08:00:00
格式化时间
time.strftime("%y-%m-%d %H:%M:%S") 字符串格式化时间 f: format
结构化时间
time.localtime() 本质是一个元组. 用来做转化的
时间戳转化成格式化时间
# 时间戳转为格式化时间
n = 190000000
# 1.先将时间戳转化为结构化时间
struct_time = time.localtime(n)
# 2.将结构化时间再转化为格式化时间
# format_time = time.strftime('格式',struct_time) 按住ctrl进入strftime有哪些格式
format_time = time.strftime('%Y-%m-%d %H:%M:%S',struct_time)
print(format_time)
# 将格式化时间转化为时间戳
fromat_time = input('请输入时间(yyyy-MM-dd HH:mm:ss):')
# 1.将格式化时间转为结构化时间
struct_time = time.strptime(fromat_time,"%Y-%m-%d %H:%M:%S")
# 2.将结构化时间转为时间戳
n = time.mktime(struct_time)
print(n)
datetime
# datetime
from datetime import datetime
now_time = datetime.now() # 获取当前时间 y-m-d H-M-S
# 1.设置时间
dt = datetime(2015, 4, 19, 12, 20)
# 2.将格式化时间转为时间戳
dt = datetime.now()
n = datetime.timestamp(dt) # 需要一个 datetime.datetime 对象
print(n)
# 3.将时间戳转为格式化时间
n = 19000000
format_time = datetime.fromtimestamp(n)
print(format_time)
# 4.将格式化时间字符串('y-m-d H-M-S') 转为datetime类型
format_time = '1970-08-09 05:46:40'
date_time = datetime.strptime(format_time,'%Y-%m-%d %H:%M:%S')
print(date_time)
print(type(date_time)) ----> <class 'datetime.datetime'>
# 5.datetime格式化时间转为字符串格式化时间
now_time = datetime.now()
str_time = datetime.strftime(now_time,'%Y-%m-%d %H:%M:%S')
print(str_time)
print(type(str_time)) ---> <class 'str'>
# 6.datetime加减 需从datetiem导入timedelta
now_time = datetime.now()
print(now_time) 2021-07-13 16:45:50.606782
next_time = now_time + timedelta(hours=1) # 往后推一个小时
print(next_time) 2021-07-13 17:45:50.606782
# 7.本地时间转换为UTC时间 需导入模块timezone
本地时间是指系统设定时区的时间,例如北京时间是UTC+8:00时区的时间,而UTC时间指UTC+0:00时区的时间。
一个datetime类型有一个时区属性tzinfo,但是默认为None,所以无法区分这个datetime到底是哪个时区,除非强行给datetime设置一个时区:
tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00
now_time = datetime.now()
dt = now_time.replace(tzinfo=tz_utc_8)
print(dt)
# 8.时区转换
'utcnow()拿到当前的UTC时间,再转换为任意时区的时间'
# 拿到UTC时间,并强制设置时区为UTC+0:00:
utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc)
# astimezone()将转换时区为北京时间:
bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8)))
# 例题:
def to_timestamp(dt_str, tz_str):
tz = int(tz_str[3:-3]) # 获取时区时间
print(tz)
cday = datetime.strptime(dt_str, '%Y-%m-%d %H:%M:%S') # 将时间转为datetime类型
tz_utc = timezone(timedelta(hours=tz)) # 转化时区
dt = cday.replace(tzinfo=tz_utc) # 将得到的格式化时间强制转化时区
return dt.timestamp() # 将格式化时间转为时间戳
t1 = to_timestamp('2015-6-1 08:10:30', 'UTC+7:00')
assert t1 == 1433121030.0, t1
t2 = to_timestamp('2015-5-31 16:10:30', 'UTC-09:00')
assert t2 == 1433121030.0, t2
print('ok')
os
os和操作系统相关
1 os.mkdir() 创建一个文件夹
2 os.makedirs() 创建一个多级目录
3 os.rmdir()
4 os.removedirs()
os.listdir() 列出目标文件夹内的所有文件
os.path.isfile
os.path.isdir
os.path.exists
os.path.join
os.path.getsize() 文件大小
collections
'collections' :
- namedtuple 命名元组
- Counter 计数器
- deque 双向队列
# 1.namedtuple
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"]) # 创建了一个类
p1 = Point(1,2) # 创建一个对象
print(p1) ---> Point(x=1, y=2)
print(p1.x) ---> 1
# 2.Counter
c = Counter("哈哈哈哈哈哈")
print(c) ---> Counter({'哈': 6})
c.update('hello')
print(c) ---> Counter({'哈': 6, 'l': 2, 'h': 1, 'e': 1, 'o': 1})
hashlib
# hashlib
# 1.hashlib.md5()
md5 = hashlib.md5() # 创建一个hash对象
md5.update('ashfahsf'.encode('utf8')) # 通过update的方法添加消息,接收bytes,不接受str
print(md5.hexdigest()) # 用hexdigest方法将数据进行加密,加密返回值为32位16进制
'如果数据量过大,可以分批update,加密结果一样'
# 2.hashlib.sha1() SHA1的结果是160 bit字节,通常用一个40位的16进制字符串表示
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in '.encode('utf-8'))
sha1.update('python hashlib?'.encode('utf-8'))
print(sha1.hexdigest())
# 3.加盐 ----> 就是在你原本输入的字符串中加入一些无关的字符
eq:
password = '你的密码'
salt = '无关字符'
md = hashlib.md5()
md.update((password+salt).encode('utf8'))
md.hexdigest()
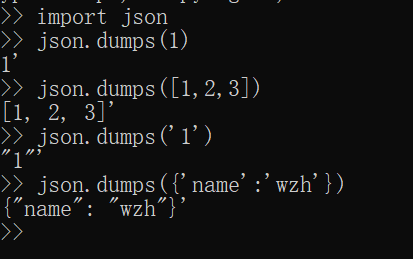
json
json模块:
dumps 数据转化成json
loads json转化回数据
dump 序列化之后的bytes写入文件
load 从文件导出bytes. 反序列化成对象
python json
None null
True true
False false
dict {}
list []
# dump:
a = {"name": 'wzh', 'age': 18}
with open('tset.json','w',encoding='utf8') as f:
json.dump(a,f)
# load:
with open('tset.json','r',encoding='utf8') as f:
aa = json.load(f)
print(aa) ----> {'name': 'wzh', 'age': 18}
re
# re模块 ---- 爬虫写
面向对象
--- 封装,继承,多态
私有变量
class Student(object):
def __init__(self,score):
self.__score = score # 定义私有变量时,解释器会将私有变量改为 _Student__name
s1 = Student(78)
# 获取私有变量值
# __score为私有变量,不能通过s1.__score获取
# 需要定义一个方法 get_score获取
def get_score(self):
return self.__score
# 改变私有变量值的方法
# 1.定义set_score方法
def set_score(self,score):
self.__score = score
s1.set_score(99)
# 2.改变_Student__score的值
s1._Student__score = 99
多态 --- 鸭子模型
def jiao(duck): # 要鸭子
duck.gagagajiao() # 嘎嘎叫
class Duck:
def gagagajiao(self):
print("嘎嘎嘎嘎嘎叫")
class Monkey:
def gagagajiao(self):
print("嘎嘎嘎嘎嘎嘎嘎嘎嘎嘎嘎嘎嘎叫")
jiao(Monkey())
'鸭子模型:不关注对象本身,只关注对象行为'
'在这个实例中,在本身是一个Monkey,在另一个方面它是Duck,因为它会嘎嘎叫。在不同的视角中,它有不同的身份,这就是多态'
继承
class F(object):
name = 'wzh'
def attack(self):
print('阿迪斯')
class S(F): # 继承后可获取父类的方法和属性
def a(self):
super().attack() # 调用父类方法:super().父类方法()
s = S()
s.a()
print(s.name) # 获取父类的属性
获取对象信息
反射
# hasattr,getattr,setattr
class MyObject(object):
def __init__(self):
self.x = 9
def power(self):
return self.x * self.x
my = MyObject()
print(hasattr(my,'x')) True
print(getattr(my,'x')) 9
print(getattr(my,'z','404')) 获取属性z,若不存在返回404
print(setattr(my,'y',6)) 设置一个属性y,并赋值6
print(hasattr(my,'power')) True
print(getattr(my,'power')) <bound method MyObject.power of <__main__.MyObject object at 0x000002A4DF5020C8>>
实例属性和类属性
class Student(object):
name = '张三'
stu = student()
print(Student.name) '张三'
print(stu.name) '张三' ----> 类属性可以被实例直接获取
stu.name = '李四' # 实例属性比类属性的优先级高,会把相同属性的类属性屏蔽,但类属性并未消失
Student.name ---> '张三'
# 小结
实例属性属于各个实例所有,互不干扰;
类属性属于类所有,所有实例共享一个属性;
不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
面对对象高级编程
—solts—
# 1.给实例绑定方法 建议直接看4,便于理解
from types import MethodType
class Student(object):
pass
def set_name(self, name):
self.name = name
s1 = Student()
s2 = Student()
s3 = Student()
# 分别给s1和s2实例绑定此方法
s1.set_name = MethodType(set_name, s1) # 跟2版本相比变成两个参数,即去掉了后面的所属类参数
s2.set_name = MethodType(set_name, s2)
s1.set_name('s1')
s2.set_name('s2')
print(hasattr(s1,'name')) # True
print(hasattr(s1,'set_name')) # True
print(getattr(s1,'name')) # s1
print(hasattr(s2,'name')) # True
print(getattr(s2,'name')) # s2
print(hasattr(Student,'name')) # False
print(hasattr(Student,'set_name')) # False
--------分割线-----------
# 2. 给类绑定方法
s1 = Student()
s2 = Student()
s3 = Student()
# 将方法绑定到类上
Student.set_name = MethodType(set_name, Student)
s1.set_name('s1')
s2.set_name('s2')
print(hasattr(s1, 'name')) # True
print(getattr(s1, 'name')) # s2
print(hasattr(Student, 'name')) # True
print(hasattr(Student, 'set_name')) # True
print(getattr(Student, 'name')) # s2
# 3.__solts__限制实例属性,该不能被继承
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
stu = Student()
stu.name = '张三'
stu.score = 99 # 执行这句将出错,因为__slots__中不含有score属性
# 4.例题,有利于理解给类绑定方法
from types import MethodType
class Student(object):
def __init__(self, *args, **kwargs):
self.name = kwargs.pop('name')
self.age = kwargs.pop('age')
self.score = kwargs.pop('score')
def set_score(self, value):
print(self)
self.score = value
def get_score(self):
print(self)
return self.score
Student.set_score = MethodType(set_score, Student) # 绑定到类上面,set_score中的self肯定是类
Student.get_score = MethodType(get_score, Student)
t = Student(name="Bryan", age=24, score=80)
# 最初给实例定义了一个属性 t.score = 80
print(t.score) # 80
t.set_score(100) # 给类定义了一个属性score=100 Student.score = 100
print(t.get_score()) # 100
print(t.score)
@property
'在方法上面@property可以将方法变为属性,访问直接 实例.属性 就可以访问'
'@属性.setter由@property衍生出来,可以设置属性值'
class Screen(object):
def __init__(self):
self._width = 0
self._height = 0
@property
def width(self):
return self._width
@property
def height(self):
return self._height
@width.setter
def width(self,value):
if not isinstance(value,int):
raise ValueError('score must be an integer!')
if value<= 0:
raise ValueError('int must "大于零"')
self._width = value
@height.setter
def height(self,value):
if not isinstance(value,int):
raise ValueError('score must be an integer!')
if value<= 0:
raise ValueError('int must "大于零"')
self._height= value
@property
def resolution(self):
return self._height*self._width
s = Screen()
s.width = 1024 # 调用@width.setter,将1024传入value
s.height = 768 # 调用@height.setter,将768传入value
print('resolution =', s.resolution)
if s.resolution == 786432:
print('测试通过!')
else:
print('测试失败!')
多重继承
class A(object):
def foo(self):
print('A foo')
def bar(self):
print('A bar')
class B(object):
def foo(self):
print('B foo')
def bar(self):
print('B bar')
class C1(A,B):
pass
class C2(A,B):
def bar(self):
print('C2-bar')
class D(C1,C2):
pass
if __name__ == '__main__':
print(D.__mro__) # 可以得出类执行顺序
d=D()
d.foo()
d.bar()
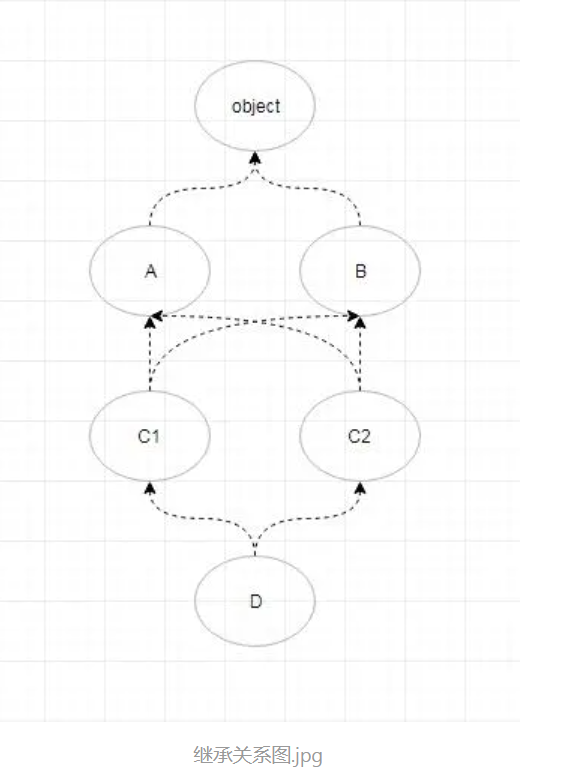
# 1.找入度为0的结点,为D,拿出,并把D相关的边剪掉 ---> D
# 2.继续找入度为0的结点,C1和C2都为0,取最左原则,取出C1,并把C1相关的边剪掉 ---> C1
# 3.继续寻找,如果出现多个0度结点,取最左原则,并将取出结点相关的边剪掉
.....
# 最终结果为 : D,C1,C2,A,B,object,程序执行顺序为也是这样
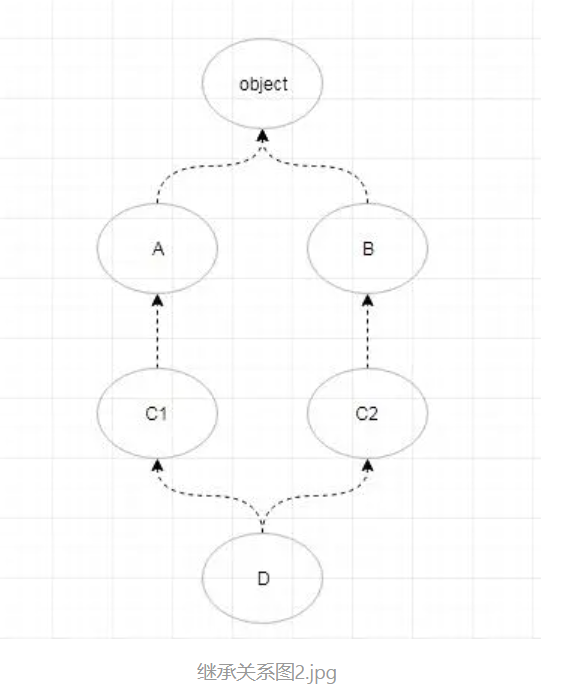
再来一道例题:
class A(object):
def foo(self):
print('A foo')
def bar(self):
print('A bar')
class B(object):
def foo(self):
print('B foo')
def bar(self):
print('B bar')
class C1(A):
pass
class C2(B):
def bar(self):
print('C2-bar')
class D(C1,C2):
pass
if __name__ == '__main__':
print(D.__mro__)
d=D()
d.foo()
d.bar()
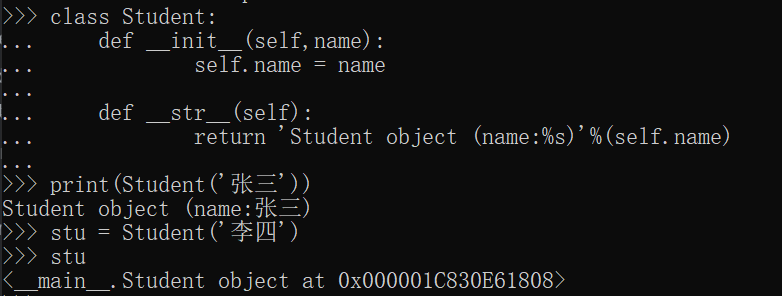
定制类
—str—
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name: %s)' % self.name
# 当执行打印时会调用__str__方法
print(Student('张三')) # Student object (name: 张三)
—repr—
在交互式模式下可以看出:
stu = Student('李四')
stu
<__main__.Student object at 0x000001C830E61808>
'这是因为直接显示变量调用的不是__str__(),而是__repr__(),两者的区别是__str__()返回用户看到的字符串,而__repr__()返回程序开发者看到的字符串,也就是说,__repr__()是为调试服务的。'
# 解决方法:
'解决办法是再定义一个__repr__()。但是通常__str__()和__repr__()代码都是一样的,所以,有个偷懒的写法'
class Student(object):
def __init__(self, name):
self.name = name
def __str__(self):
return 'Student object (name=%s)' % self.name
__repr__ = __str__
—iter—
'如果一个类想被用于for ... in循环,类似list或tuple那样,就必须实现一个__iter__()方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的__next__()方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环'
class Fib(object):
def __init__(self):
self.a, self.b = 0, 1 # 初始化两个计数器a,b
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 100000: # 退出循环的条件
raise StopIteration()
return self.a # 返回下一个值
for n in Fib(): # 此时Fib()是一个迭代器,每循环一次调用next()方法
print(n)
—getitem—
'定义 : __getitem__(self, key)'
1.# 虽然Fib可以进行与list一样进行for循环,但依然不可以根据下标取值
# 要表现得像list那样按照下标取出元素,需要实现__getitem__()方法:
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
f = Fib()
f[10] ---> 89 # 将10传入—getitem—得到返回值
2.# 在用 for..in.. 迭代对象时,如果对象没有实现 __iter__ __next__ 迭代器协议,Python的解释器就会去寻找__getitem__ 来迭代对象,
class Animal:
def __init__(self, animal_list):
self.animals_name = animal_list
def __getitem__(self, index): # index为可以理解为元素的索引下标,依次为 0 1 2
return self.animals_name[index]
animals = Animal(["dog","cat","fish"])
for animal in animals:
print(animal) # 依次输出"dog","cat","fish"
—getattr—
# 正常情况下,当我们调用类的方法或属性时,如果不存在,就会报错。比如定义Student类:

'如果需要避免产生此类错误,我们可以定义__getattr__()'
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99
stu = Student()
# 当实例对象获取不存在的属性时会调用__getattr__()来尝试获取属性值
print(stu.score) --> 99
'注意,只有在没有找到属性的情况下,才调用__getattr__,已有的属性,比如name,不会在__getattr__中查找'
# 利用完全动态的__getattr__,我们可以写出一个链式调用:
'自己如果重新看的话,自己慢慢看,很简单的,当时写了流程图,忘了沾上来...造孽啊'
class Chain(object):
def __init__(self, path=''):
self._path = path
def __getattr__(self, path):
return Chain('%s/%s' % (self._path, path))
def __str__(self):
return self._path
__repr__ = __str__
# 交互模式下运行的,可以直接得出结果
>>> Chain().status.user.timeline.list
'/status/user/timeline/list'
—call—
'该方法可以调用实例对象本身'
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self):
print('My name is %s.' % self.name)
stu = Student('张三') # 类加()是成为一个实例化对象
stu() ---> 会主动调用__call__()
# 那么怎么判断一个对象是否可以被调用呢? 用callable()方法,返回为True,即可被调用
callable(对象)
int(),len(),str(),list()这些可被直接调用
元类
'基本用不上'
如果需要理解,对照廖雪峰的网址,然后再结合自己元类的代码 D:\python项目\元类和rom
结合这两个可以比较透彻的理解一下
ORM(Object Relational Mapping) --->对象关系映射
这个比较有用处了,为django后面的ORM操作打基础,可以大概知道ORM怎么来的
D:\python项目\元类和rom

 浙公网安备 33010602011771号
浙公网安备 33010602011771号