Apache Zeppelin
Apache Zeppelin
基于 Web 的笔记本,支持使用 SQL、Scala、Python、R 等进行数据驱动的
交互式数据分析和协作文档。
TECHNOLOGIES
|
Spark Zeppelin 支持带有依赖加载器的Spark、PySpark、Spark R、Spark SQL。 |
SQL Zeppelin 允许您无缝连接任何 JDBC 数据源。Postgresql、Mysql、MariaDB、Redshift、Apache Hive 等。 |
Python Matplotlib、Conda、Pandas SQL 和 PySpark 集成支持 Python。 |
Supported Interpreters
| Zeppelin | 0.8.1 | 0.8.0 | 0.7.3 | 0.7.1 - 0.7.2 | 0.7.0 | 0.6.2 - 0.6.1 | 0.6.0 |
|---|---|---|---|---|---|---|---|
Spark |
1.5.x, 1.6.x, 2.0.x, 2.1.x, 2.2.x, 2.3.x, 2.4.0 | 1.5.x, 1.6.x, 2.0.x, 2.1.x, 2.2.x, 2.3.1 | 1.4.x, 1.5.x, 1.6.x, 2.0.x, 2.1.x, 2.2.0 | 1.4.x, 1.5.x, 1.6.x, 2.0.x 2.1.0 | 1.4.x, 1.5.x, 1.6.x, 2.0.x 2.1.0 | 1.1.x, 1.2.x, 1.3.x, 1.4.x, 1.5.x, 1.6.x, 2.0.0 | 1.1.x, 1.2.x, 1.3.x, 1.4.x, 1.5.x, 1.6.x |
| Support Scala 2.11 | SparkR is available | ||||||
JDBC |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
PostgreSQL,
MySQL,
MariaDB,
Redshift,
Hive, Phoenix, Drill, Tajo are available |
Pig |
O | O | O | O | O | N/A | N/A |
Beam |
O | O | O | O | O | N/A | N/A |
Scio |
O | O | O | O | O | N/A | N/A |
BigQuery |
O | O | O | O | O | O | N/A |
Python |
O | O | O | O | O | O | O |
Livy |
O | O | O | O | O | O | O |
HDFS |
O | O | O | O | O | O | O |
Alluxio |
O | O | O | O | O | O | O |
Hbase |
O | O | O | O | O | O | O |
Scalding |
O | O | O | O | O | O | O |
Elasticsearch |
O | O | O | O | O | O | O |
Angular |
O | O | O | O | O | O | O |
Markdown |
O | O | O | O | O | O | O |
Shell |
O | O | O | O | O | O | O |
Flink |
O | O | O | O | O | O | O |
Cassandra |
O | O | O | O | O | O | O |
Geode |
O | O | O | O | O | O | O |
Ignite |
1.9.0 | 1.9.0 | 1.9.0 | 1.9.0 | 1.7.0 | 1.7.0 | 1.6.0 |
Kylin |
O | O | O | O | O | O | O |
Lens |
O | O | O | O | O | O | O |
PostgreSQL |
O | O | O | O | O | O | O |
有什么新东西
阿帕奇齐柏林飞艇 0.10
Spark 解释器改进
Spark 解释器提供与 Jupyter Notebook 类似的 Python 和 R 用户体验。详情请点击这里。
Flink 解释器改进
Flink 解释器经过重构,支持 Scala、Python 和 SQL。Flink 1.10 及更高版本(Scala 2.11 和 2.12)都受支持。
详情请点击这里。
纱线解释器模式
您可以在 yarn 集群中运行解释器,例如,您可以在 yarn 中运行Python 解释器,在 yarn中运行R 解释器。
内联配置
Generic ConfInterpreter提供了一种在每个注释中配置解释器的方法。
口译员生命周期管理
解释器生命周期管理器在空闲超时时自动终止解释器进程。因此,资源在不使用时会被释放。有关更多详细信息,请参见此处。
什么是 APACHE ZEPPELIN?
多功能笔记本
笔记本是满足您所有需求的地方
- 数据摄取
- 数据发现
- 数据分析
- 数据可视化与协作
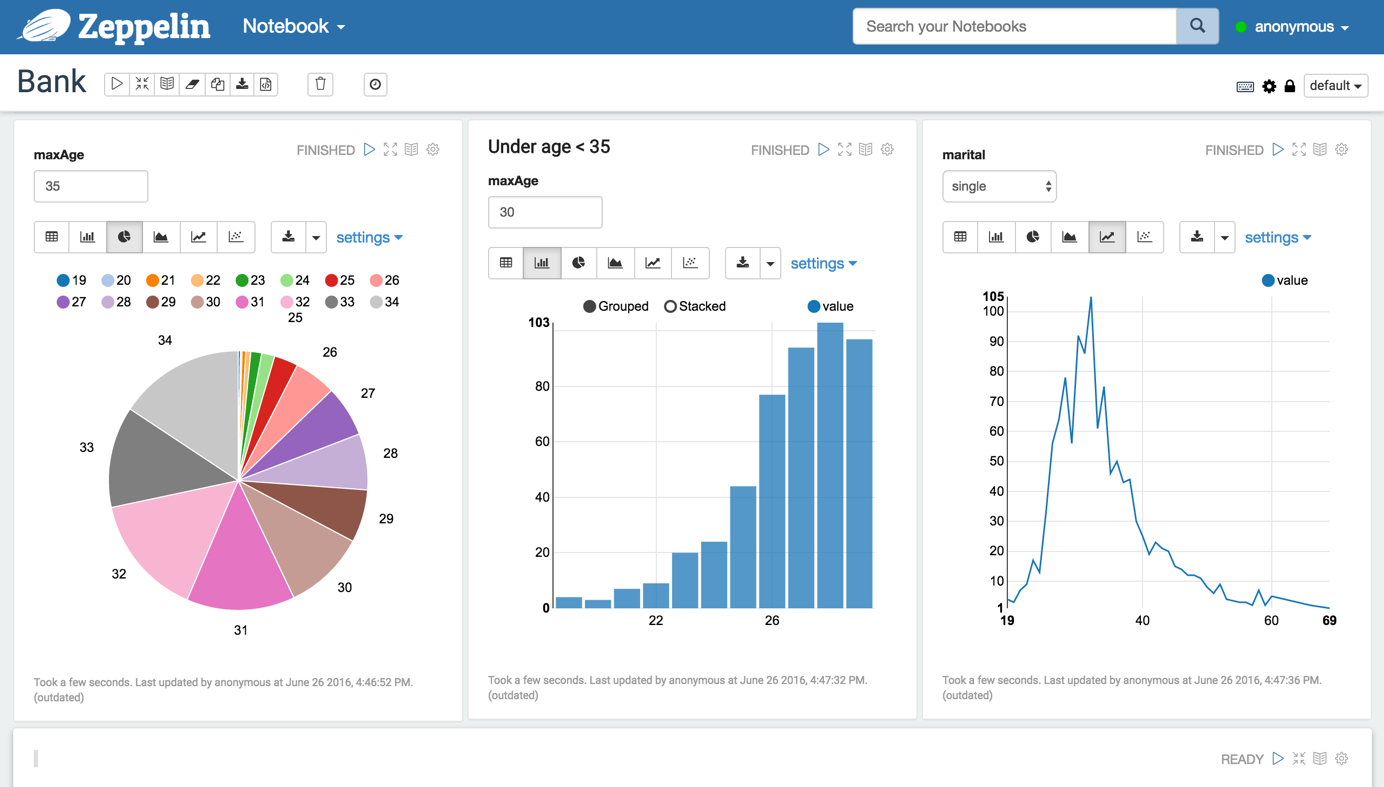
多语言后端
Apache Zeppelin 解释器概念允许将任何语言/数据处理后端插入 Zeppelin。目前 Apache Zeppelin 支持多种解释器,如 Apache Spark、Apache Flink、Python、R、JDBC、Markdown 和 Shell。

添加新的语言后端非常简单。了解如何创建新的解释器。
Apache Spark 集成
特别是 Apache Zeppelin 提供了内置的Apache Spark集成。您不需要为它构建单独的模块、插件或库。
Apache Zeppelin 与 Spark 集成提供
- 自动 SparkContext 和 SQLContext 注入
- 从本地文件系统或 maven 存储库加载运行时 jar 依赖项。了解更多关于依赖加载器的信息。
- 取消作业并显示其进度
有关 Apache Zeppelin 中的 Apache Spark 的更多信息,请参阅Apache Zeppelin 的 Spark 解释器。
数据可视化
Apache Zeppelin 中已经包含了一些基本图表。可视化不仅限于 SparkSQL 查询,任何语言后端的任何输出都可以被识别和可视化。
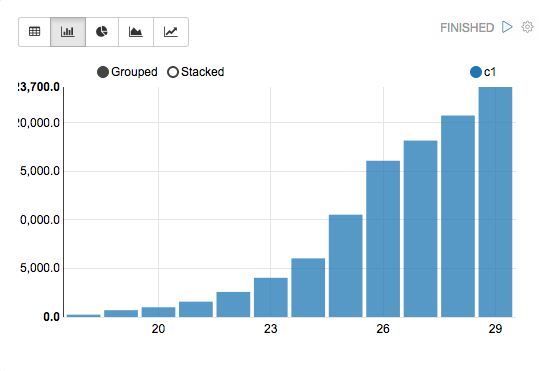

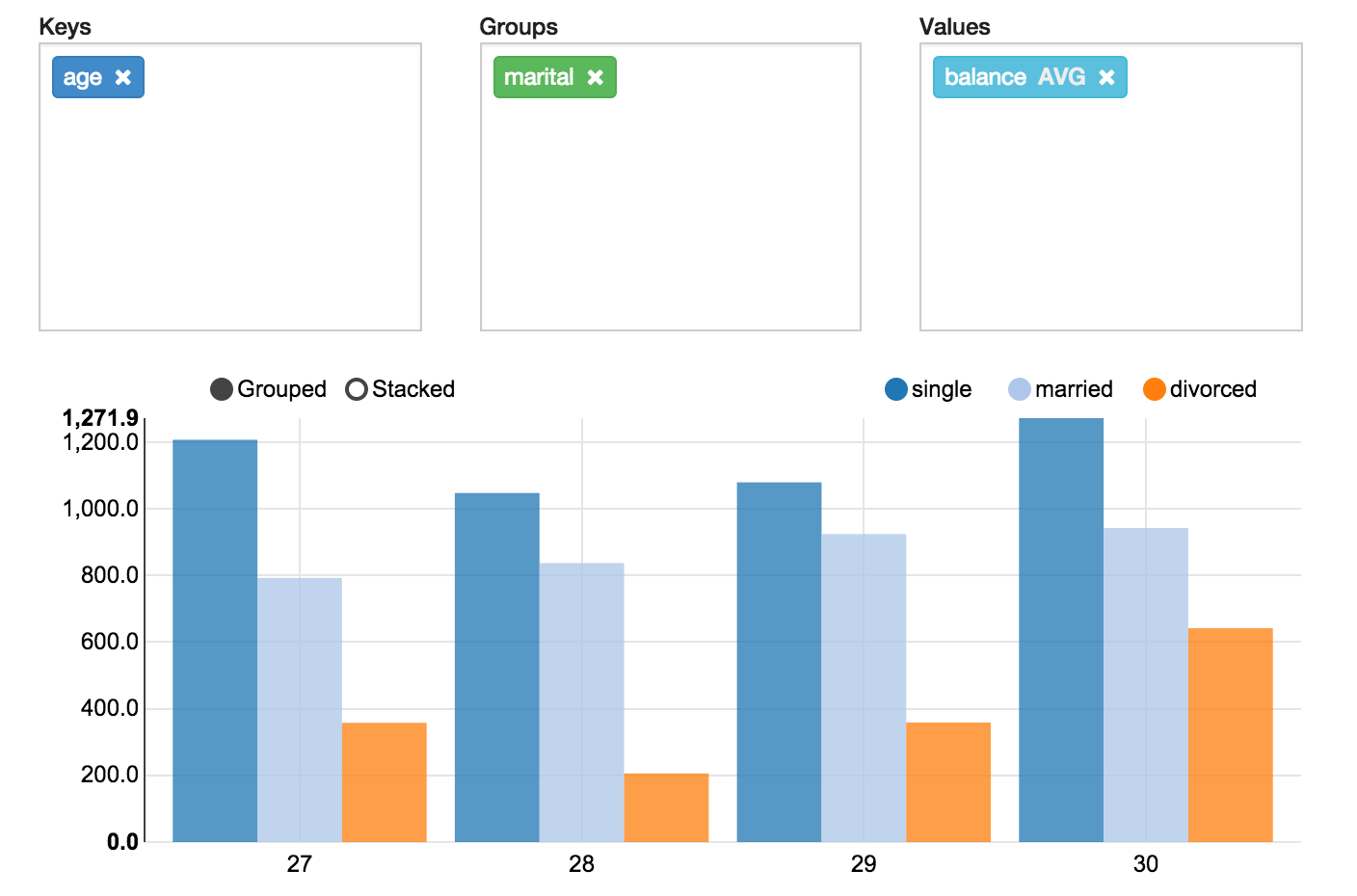
数据透视图
Apache Zeppelin 聚合值并通过简单的拖放将它们显示在数据透视图中。您可以轻松地创建具有多个聚合值的图表,包括总和、计数、平均值、最小值、最大值。
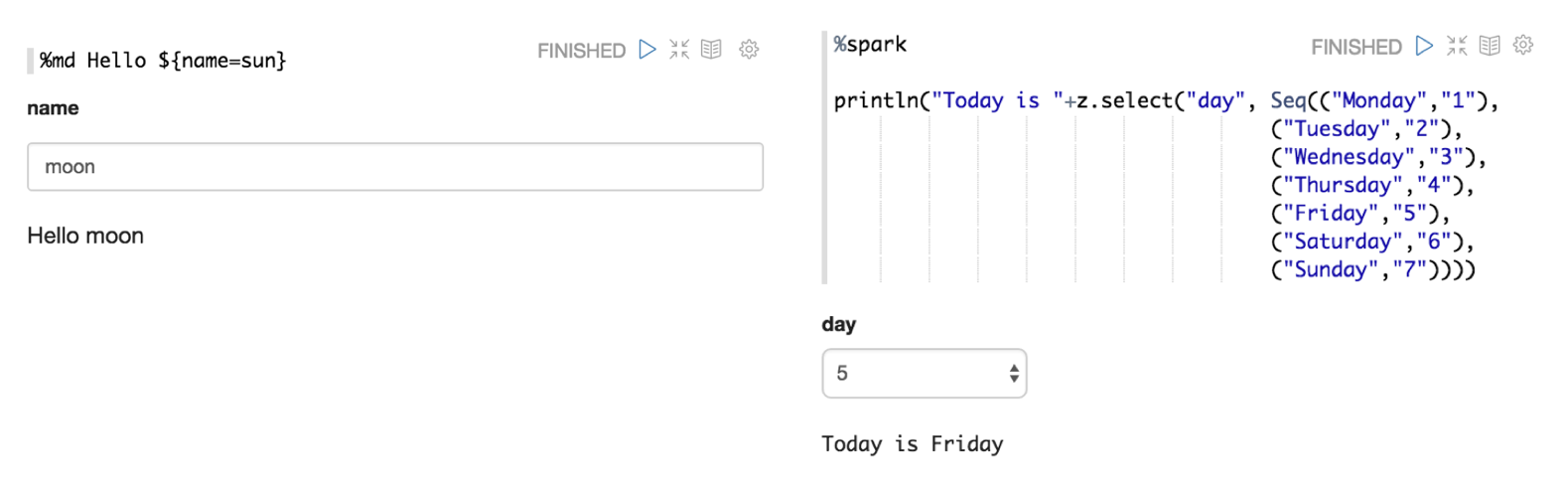
动态表格
Apache Zeppelin 可以在你的 notebook 中动态创建一些输入表单。
通过共享您的笔记本和段落进行协作
您的笔记本 URL 可以在协作者之间共享。然后 Apache Zeppelin 将实时广播任何更改,就像 Google 文档中的协作一样。
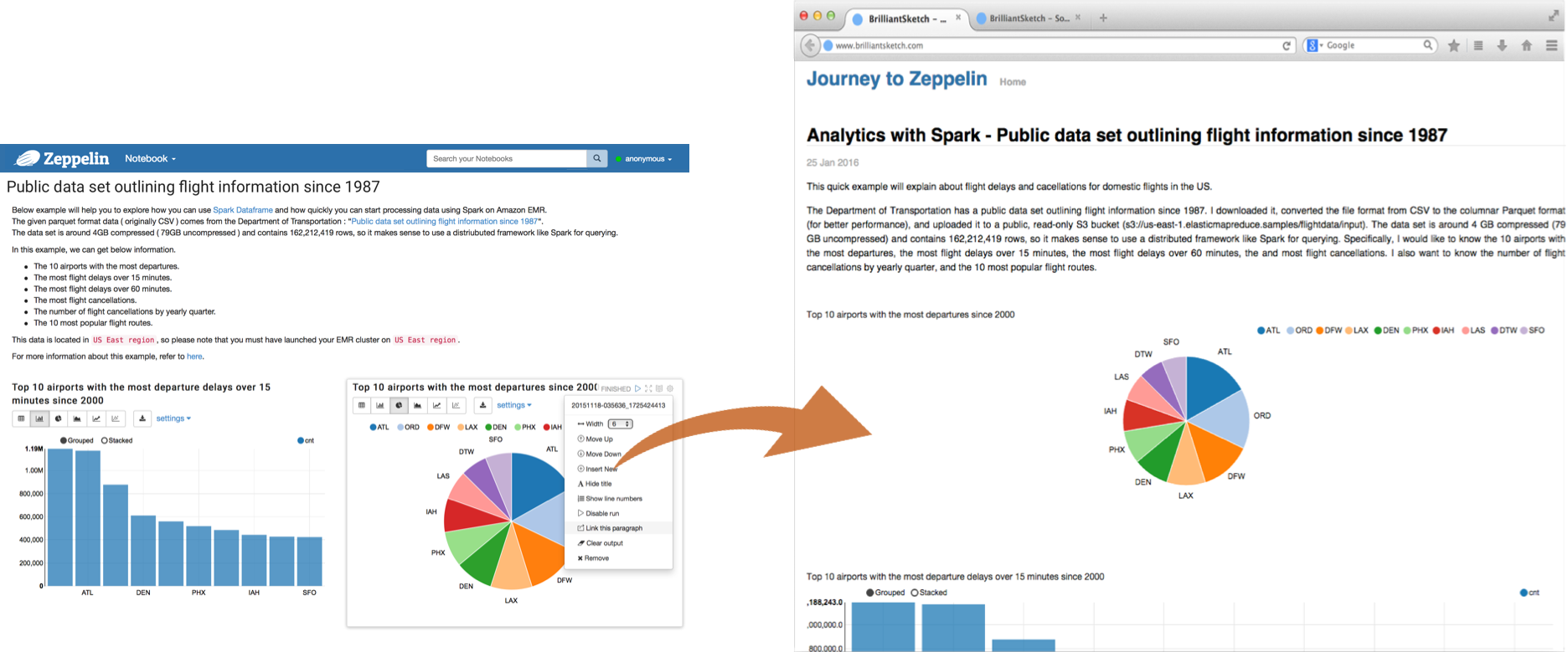
Apache Zeppelin 提供了一个 URL 来仅显示结果,该页面不包括笔记本内的任何菜单和按钮。您可以通过这种方式轻松地将其作为 iframe 嵌入到您的网站中。如果您想了解有关此功能的更多信息,请访问此页面。
100% 开源
Apache Zeppelin 是 Apache2 许可软件。请查看源存储库以及如何贡献。Apache Zeppelin 有一个非常活跃的开发社区。加入我们的邮件列表并在Jira 问题跟踪器上报告问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号