hive的inner join
一、试验表和数据
1.1、建表

create table `user`( -- 用户表,分区表 department_id int, age int, sex string, name string ) PARTITIONED BY (`date` string) row format delimited fields terminated by ',' STORED AS TEXTFILE; create table department( -- 部门表 id int, name string, count int ) row format delimited fields terminated by ',' STORED AS TEXTFILE;
1.2、数据
-- /data/hive/user1.txt 1,34,male,zhangsan 1,31,female,lili 3,14,female,liushen 3,24,female,sasa 4,54,male,liubei 4,36,female,yuji 4,25,male,zhaoyun 8,18,male,zhangfei -- /data/hive/user2.txt 3,37,male,wangwu 4,38,female,lisi 3,19,female,caocao 2,22,female,guanyu 1,51,male,wzj 6,31,female,zhenji 6,25,male,sunwukong 6,17,male,tangsz -- /data/hive/department.txt 1,dashuju,8 2,kaifa,9 3,ui,10 4,hr,3 5,shouxiao,12 6,zongjian,3
1.3、数据导入
load data local inpath '/data/hive/user1.txt' into table `user` partition (`date`='2020-12-24'); load data local inpath '/data/hive/user2.txt' into table `user` partition (`date`='2020-12-25'); load data local inpath '/data/hive/department.txt' into table `department`;
1.4、查询数据
SELECT * from `user`;
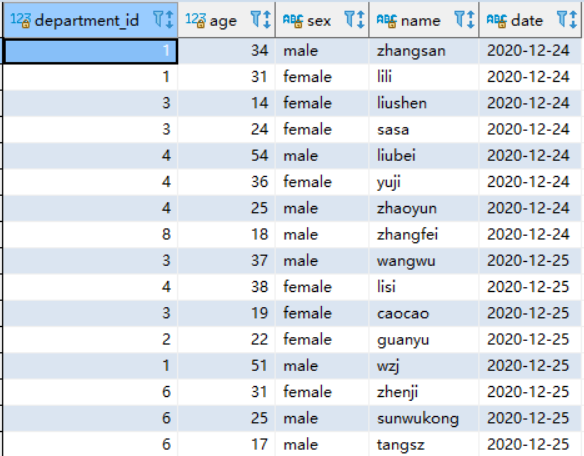
SELECT * from department ;
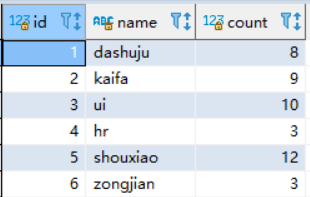
1.5、对表进行分析
ANALYZE TABLE `user` partition(`date`='2020-12-24') COMPUTE STATISTICS; ANALYZE TABLE `user` partition(`date`='2020-12-25') COMPUTE STATISTICS; ANALYZE TABLE department COMPUTE STATISTICS;
如果不进行如上的操作,在下面的实践中会出问题,数据不真实,看不出效果,所以要做explain前对表进行分析,这样更加的准确(刚刚踩了坑,每次explain出来都只有1条数据,统计有问题)
二、inner join下的on和where分析
2.1、不使用分区进行过滤
1、首先看一个没有条件的inner join的结果
SELECT * from `user` u inner join department d on d.id=u.department_id;
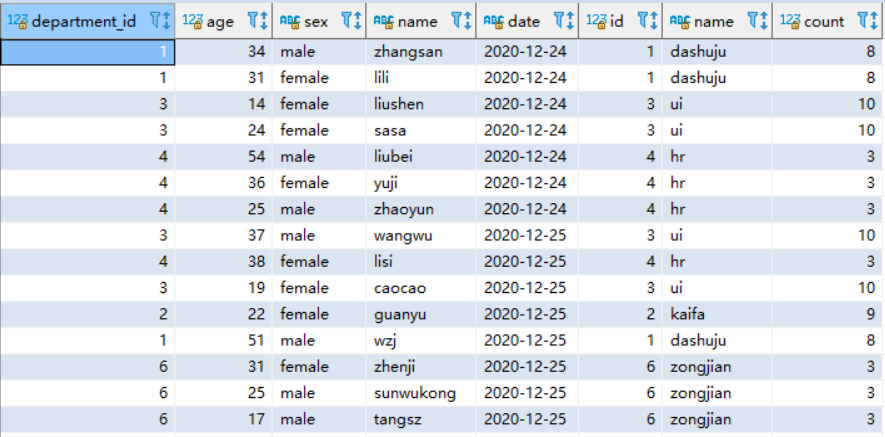
查看执行计划:
explain SELECT * from `user` u inner join department d on d.id=u.department_id;
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
filterExpr: id is not null (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
filterExpr: department_id is not null (type: boolean)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Filter Operator
predicate: department_id is not null (type: boolean)
Statistics: Num rows: 16 Data size: 2944 Basic stats: COMPLETE Column stats: PARTIAL
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3238 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 17 Data size: 3238 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 17 Data size: 3238 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
如上语句没有做任何的条件过滤,也没有使用分区:
- 首先对d表(department)进行全表扫描,扫描到了6条数据,然后默认添加id is not null的过滤条件对其扫描到的6条数据进行过滤(自动优化,如果join下要保留null的行的话需要提前做特殊处理,不然默认就被优化掉了,会导致数据丢失),最终得到过滤后还剩下6条数据参与inner join。
- 然后对u表(user)进行全表扫描,扫描到了16条数据,同样添加默认的过滤条件department_id is not null,最终得到16条数据参与inner join。
2、接下来看一个有where条件和on条件下的结果
SELECT * from `user` u inner join department d on d.id=u.department_id and d.count > 9 and u.age > 20 where u.age < 30;

接下来看看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
filterExpr: ((count > 9) and id is not null) (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((count > 9) and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 19 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
filterExpr: ((age > 20) and department_id is not null and (age < 30)) (type: boolean)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Filter Operator
predicate: ((age > 20) and department_id is not null and (age < 30)) (type: boolean)
Statistics: Num rows: 1 Data size: 184 Basic stats: COMPLETE Column stats: PARTIAL
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 2 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 2 Data size: 20 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 20 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
结果如上所示:
- 首先扫描d(department)表,全表扫描6条数据,并对其进行过滤:((count > 9) and id is not null) ,过滤结果剩下2条数据进行inner join操作
- 然后扫描u(user)表,也是全表扫描16条数据,并对其进行过滤((age > 20) and department_id is not null and (age < 30)),过滤剩下1条数据(这里是有误差的,其实应该剩余4条数据,hive的执行计划是一个大概的统计执行过程,不完全正确)进行inner join操作
小总结:inner join在不使用分区过滤的情况下,会对其两个表都进行全表扫描,然后自动为join的键(on d.id=u.department_id)添加is not null的过滤条件,然后在配合on和where后面的条件进行过滤,在inner join中where和on是同时进行过滤的。
2.2、使用分区过滤
1、先看一个只有分区过滤的情况
SELECT * from `user` u inner join department d on d.id=u.department_id where u.`date`='2020-12-25';
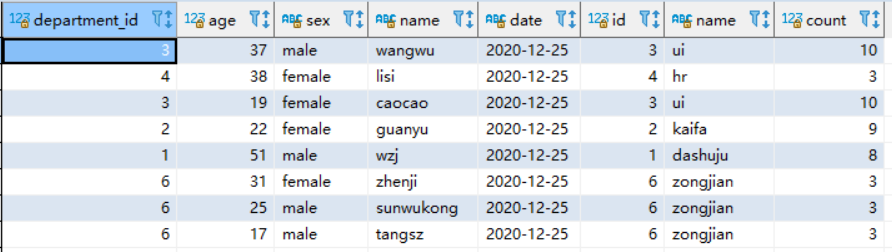
查看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
filterExpr: id is not null (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: id is not null (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
filterExpr: (department_id is not null and (date = '2020-12-25')) (type: boolean)
Statistics: Num rows: 8 Data size: 134 Basic stats: COMPLETE Column stats: NONE #这里一个分区只有8条数据
Filter Operator
predicate: department_id is not null (type: boolean)
Statistics: Num rows: 8 Data size: 134 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col8, _col9, _col10
Statistics: Num rows: 8 Data size: 147 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), '2020-12-25' (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 8 Data size: 147 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 8 Data size: 147 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
结果如上,这里和没有添加分区过的情况对比,就是添加了分区后不会对表u(user)进行全表扫描,这样的话就能提高效率,因为分区的存储就是一个文件夹,所以在分区过滤后就可以指定分区进行扫描,就不会进行全表扫描,这样的情况说明:分区表先进行分区过滤,然后对指定的分区进行全部扫描,然后再使用on和where以及自动添加的is not null条件进行过滤,过滤后的数据才进行inner join
2、看一个带条件和分区过滤的结果
SELECT * from `user` u inner join department d on d.id=u.department_id and d.count > 9 and u.age > 20 where u.age < 30 and u.`date`='2020-12-24';

看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
filterExpr: ((count > 9) and id is not null) (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((count > 9) and id is not null) (type: boolean)
Statistics: Num rows: 2 Data size: 19 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
filterExpr: ((age > 20) and department_id is not null and (age < 30)) (type: boolean)
Statistics: Num rows: 8 Data size: 136 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((age > 20) and department_id is not null and (age < 30)) (type: boolean)
Statistics: Num rows: 1 Data size: 17 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col8, _col9, _col10
Statistics: Num rows: 2 Data size: 20 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), '2020-12-24' (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 2 Data size: 20 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 2 Data size: 20 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
结果如上,得出结果与(不使用分区条件过滤且使用on和where过滤)对比,可以看出来,使用分区过滤的区别就是在对表进行扫描的时候是扫描全部还是扫描指定的分区,如果没有分区过滤,则扫描全表,否则,只对指定的分区进行扫描。
2.3、inner join下on和where的总结
在inner join下,如果where条件中使用了分区过滤,则扫描指定的分区的数据,然后在通过where和on条件进行过滤,以及为join的键(on d.id=u.department_id)添加is not null的过滤条件(这里需要注意的是join键为null的数据是否要保留,需要保留的话,就需要对join键进行特殊的处理,否则数据则被过滤掉,导致数据丢失),这里on和where是同时过滤的,不区分先后。
三、left/right join下的on和where分析
由于left join和right join属于同一类型,所以本文只针对left join进行实践。
3.1、非主表在on和where条件下执行
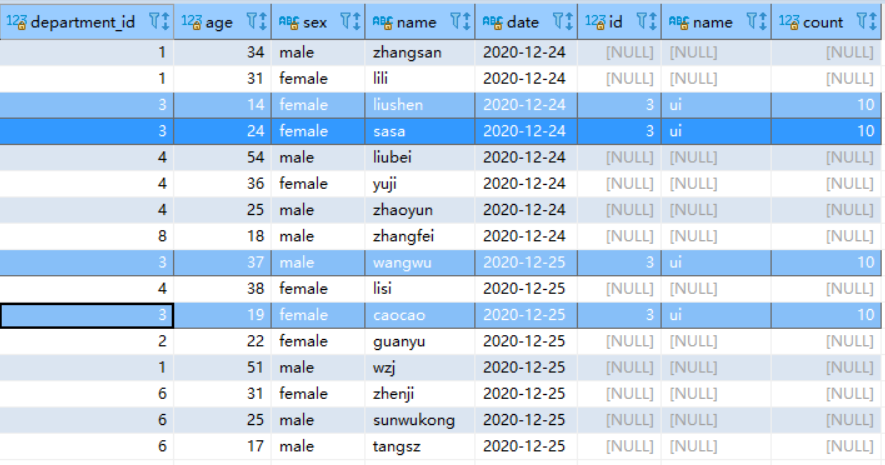
先看一条执行语句的结果(在非主表在on后面添加过滤条件)(约定:u (主表) left join d(非主表))
SELECT * from `user` u
left join department d
on d.id=u.department_id
and d.count > 9
查看结果
然后看一个执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
filterExpr: (count > 9) (type: boolean)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (count > 9) (type: boolean)
Statistics: Num rows: 2 Data size: 19 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Map Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
结果如上,我们发现在left join下,约定:u (主表) left join d(非主表),非主表在on下面的条件d.count > 9过滤有效,最终扫描全部6条数据,通过条件过滤剩下2条数据然后进行left join,主表扫描全表进行left join,这里注意,在left join条件下两个表的join键(on d.id=u.department_id)都没有加上is not null的条件过滤,所以在进行left join的时候需要注意join 键是否为空,为空的情况可以对其进行优化。
看一条执行语句的结果(在非主表在where后面添加过滤条件)(约定:u (主表) left join d(非主表))
SELECT * from `user` u left join department d on d.id=u.department_id where d.count > 9
结果如下:(与非主表在on后面添加的添加结果是不一样的)

看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Map Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (_col10 > 9) (type: boolean)
Statistics: Num rows: 5 Data size: 1039 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 5 Data size: 1039 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 5 Data size: 1039 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
从如上的执行计划来看,对表u(user)和d(department)是在没有任何过滤的情况下,进行了去全表扫描的left join,在left join获得结果后,然后再对结果使用非主表的where条件d.count > 9进行过滤
小总结:(left join)在非主表下使用on或者使用where进行过滤时的结果是不一样的,如果是在on下面添加条件过滤,则先进行表的数据过滤,然后在进行left join,如果是在where后面添加条件过滤,则是先进行left join,然后在对left join得到的结果进行where条件的过滤,在left join中,不会对join键添加默认的is not null的过滤条件。
3.2、主表在on和where条件下执行
先看一条执行语句的结果(在主表在on后面添加过滤条件)(约定:u (主表) left join d(非主表))
SELECT * from `user` u left join department d on d.id=u.department_id and u.age > 20

看到如上的结果发现,还是保留了16条数据(user表的全部数据),但是发现age<=20的数据好像不参加left join一样,后面的值全都是null。
看看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
filter predicates:
0 {(age > 20)}
1
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Map Join Operator
condition map:
Left Outer Join0 to 1
filter predicates:
0 {(age > 20)}
1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
结果如上,其中在处理d(department表)时,扫描全表6条数据,对表d(department)进行标记age>20的条件,然后对u(user)表进行全表扫描并进行全表的left join,在left join的过程中对d(department)表(来源于d表的 的字段)通过主表的条件age > 20进行筛选,如果u表的age <=20,则来源于d表的字段全部置为null,(如上为个人理解,不一定正确。简单来说,先做个判断标记,然后进行left join,在left join的过程中通过条件进行过滤(不符合条件的数据保留主表的数据,非主表的数据丢弃,置为null)),这里在on后面的条件不会对主表的条数产生影响,也是先进行left join并进行相应的过滤。理解起来比较绕,可以自己对应结果看看。
看一条执行语句的结果(在主表在where后面添加过滤条件)(约定:u (主表) left join d(非主表))
SELECT * from `user` u left join department d on d.id=u.department_id where u.age > 20
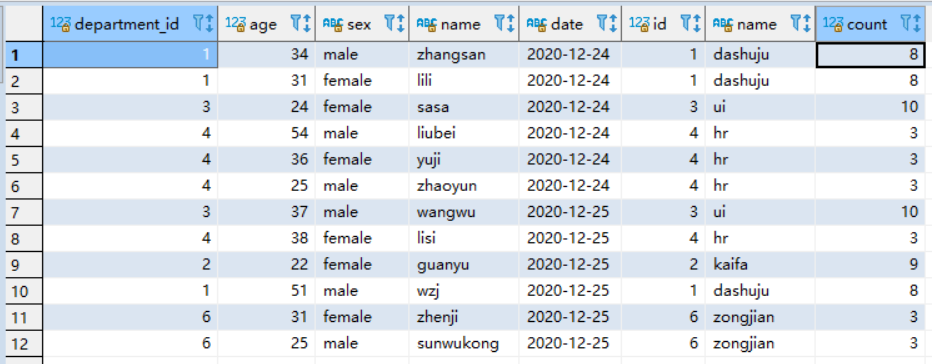
接下来看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
filterExpr: (age > 20) (type: boolean)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Filter Operator
predicate: (age > 20) (type: boolean)
Statistics: Num rows: 5 Data size: 920 Basic stats: COMPLETE Column stats: PARTIAL
Map Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 6 Data size: 63 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 6 Data size: 63 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 6 Data size: 63 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
结果如上,可以明确的看出来当在主表中使用where过滤,会先对主表的数据进行过滤然后在进行left join,主表扫描出16条数据,过滤后剩余5条,然后再进行left join得到最终的结果。
小总结:(left join)在主表下使用on或者使用where进行过滤时的结果是不一样的,当使用where对主表进行过滤的时候,先过滤再进行left join。当使用on对主表进行过滤,先在非主表进行过滤标记,然后再对全表进行left join时根据过滤条件把不符合条件的行中来源于非主表的数据设置为null。
3.3、left/right join使用分区过滤
看如下语句:
SELECT * from `user` u left join department d on d.id=u.department_id where u.age > 20 and u.`date` = '2020-12-24';
结果:
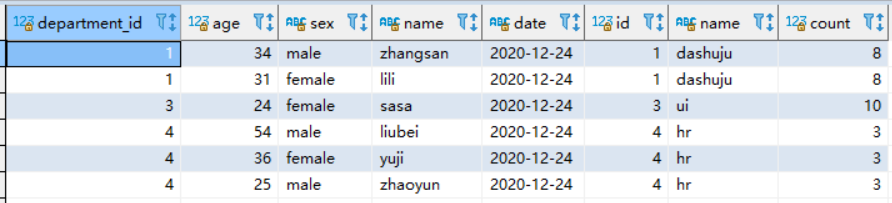
看看执行计划:
STAGE DEPENDENCIES:
Stage-4 is a root stage
Stage-3 depends on stages: Stage-4
Stage-0 depends on stages: Stage-3
STAGE PLANS:
Stage: Stage-4
Map Reduce Local Work
Alias -> Map Local Tables:
d
Fetch Operator
limit: -1
Alias -> Map Local Operator Tree:
d
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
HashTable Sink Operator
keys:
0 department_id (type: int)
1 id (type: int)
Stage: Stage-3
Map Reduce
Map Operator Tree:
TableScan
alias: u
filterExpr: ((age > 20) and (date = '2020-12-24')) (type: boolean)
Statistics: Num rows: 8 Data size: 136 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (age > 20) (type: boolean)
Statistics: Num rows: 2 Data size: 34 Basic stats: COMPLETE Column stats: NONE
Map Join Operator
condition map:
Left Outer Join0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col8, _col9, _col10
Statistics: Num rows: 6 Data size: 63 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), '2020-12-24' (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 6 Data size: 63 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 6 Data size: 63 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Local Work:
Map Reduce Local Work
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
根据如上的执行计划可以看出来,使用分区过滤可以防止全表扫描,如上值扫描了一个分区,所以数据只有8条。
3.4、left/right join下on和where的总结
- 使用分区条件过滤,可以防止全表扫描,最优先过滤
- 在主表下进行过滤,使用on和where过滤的结果是不一样的,当使用where对主表进行过滤的时候,先过滤再进行left join。当使用on对主表进行过滤,先在非主表进行过滤标记,然后再对全表进行left join时根据过滤条件把不符合条件的行中来源于非主表的数据设置为null。
- 在非主表下进行过滤,使用on和where过滤的结果是不一样的,如果是在on下面添加条件过滤,则先进行表的数据过滤,然后在进行left join,如果是在where后面添加条件过滤,则是先进行left join,然后在对left join得到的结果进行where条件的过滤
- left/right join不会对join键自动添加is not null的过滤条件,所以在left/right join的时候要注意join键为null的情况,这里是可以做优化的
四、full join下的on和where分析
4.1、没有过滤条件的full join
直接看一个没有任何条件的full join
SELECT * from `user` u full join department d on d.id=u.department_id
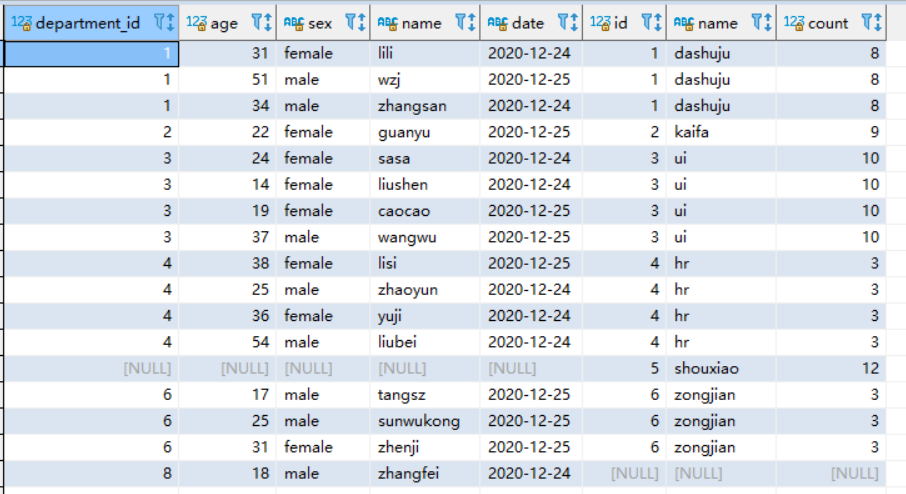
查看执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Reduce Output Operator
key expressions: department_id (type: int)
sort order: +
Map-reduce partition columns: department_id (type: int)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
value expressions: age (type: int), sex (type: string), name (type: string), date (type: string)
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
value expressions: name (type: string), count (type: int)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
执行计划如上,会对每个表进行升序的排序,没有自动优化(添加null过滤),执行全表的full join。
4.2、有where条件的full join
SELECT * from `user` u full join department d on d.id=u.department_id where u.age > 20 and d.count > 9
结果如下

查看执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Reduce Output Operator
key expressions: department_id (type: int)
sort order: +
Map-reduce partition columns: department_id (type: int)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
value expressions: age (type: int), sex (type: string), name (type: string), date (type: string)
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
value expressions: name (type: string), count (type: int)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: ((_col10 > 9) and (_col1 > 20)) (type: boolean)
Statistics: Num rows: 1 Data size: 207 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 1 Data size: 207 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 1 Data size: 207 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
从执行计划看出来,在full join下的使用where 进行过滤的时候是先进行全表扫描,然后进行full join,full join获得结果后才对where中的条件进行过滤。
4.3、有on条件的full join(留有疑问)
SELECT * from `user` u full join department d on d.id=u.department_id and u.age > 20 and d.count > 9
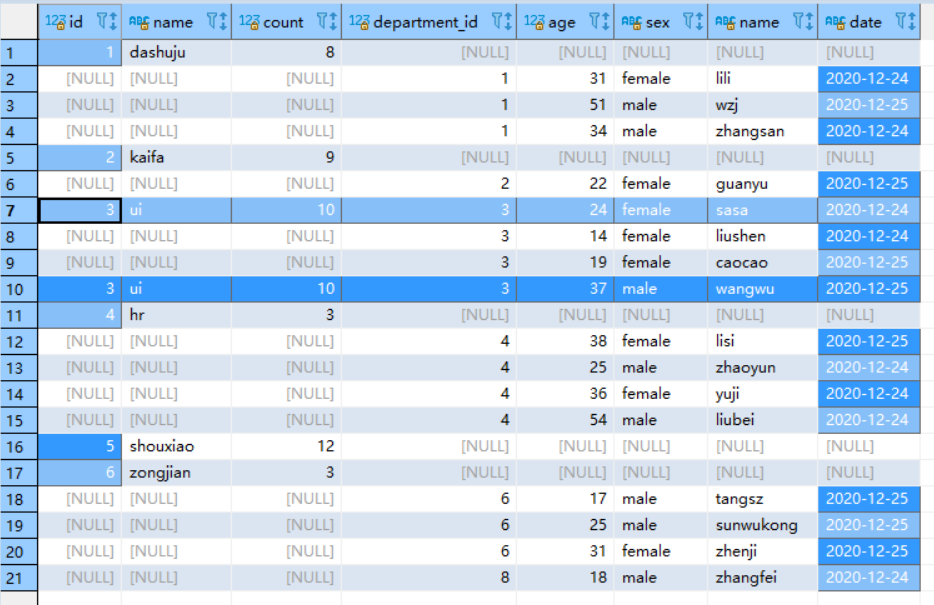
看到如上结果,可能有点意外, (个人能力有限,厉害的博友可以解释解释),个人的理解为就像left join的主表下的on条件一样,都是在full join的过程中进行过滤,然而两个表的全部数据都有保留下来,只有两个条件都成立的情况下,才没有null值。(在full join如果不懂,就尽量使用where条件判断啦)
查看执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Reduce Output Operator
key expressions: department_id (type: int)
sort order: +
Map-reduce partition columns: department_id (type: int)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
value expressions: age (type: int), sex (type: string), name (type: string), date (type: string)
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
value expressions: name (type: string), count (type: int)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
filter predicates:
0 {(VALUE._col0 > 20)}
1 {(VALUE._col1 > 9)}
keys:
0 department_id (type: int)
1 id (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: int), _col2 (type: string), _col3 (type: string), _col4 (type: string), _col8 (type: int), _col9 (type: string), _col10 (type: int)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
留有疑问????,优秀的博友如果理解了,可以在下面留言
4.4、分区过滤的full join
SELECT * from department d full join `user` u on d.id=u.department_id where u.`date`= '2020-12-24';
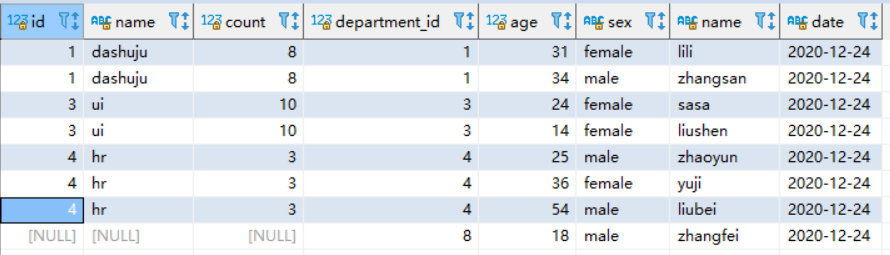
查看执行计划:
STAGE DEPENDENCIES:
Stage-1 is a root stage
Stage-0 depends on stages: Stage-1
STAGE PLANS:
Stage: Stage-1
Map Reduce
Map Operator Tree:
TableScan
alias: d
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
Reduce Output Operator
key expressions: id (type: int)
sort order: +
Map-reduce partition columns: id (type: int)
Statistics: Num rows: 6 Data size: 58 Basic stats: COMPLETE Column stats: NONE
value expressions: name (type: string), count (type: int)
TableScan
alias: u
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
Reduce Output Operator
key expressions: department_id (type: int)
sort order: +
Map-reduce partition columns: department_id (type: int)
Statistics: Num rows: 16 Data size: 3214 Basic stats: COMPLETE Column stats: PARTIAL
value expressions: age (type: int), sex (type: string), name (type: string), date (type: string)
Reduce Operator Tree:
Join Operator
condition map:
Outer Join 0 to 1
keys:
0 id (type: int)
1 department_id (type: int)
outputColumnNames: _col0, _col1, _col2, _col6, _col7, _col8, _col9, _col10
Statistics: Num rows: 17 Data size: 3535 Basic stats: COMPLETE Column stats: NONE
Filter Operator
predicate: (_col10 = '2020-12-24') (type: boolean)
Statistics: Num rows: 8 Data size: 1663 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: _col0 (type: int), _col1 (type: string), _col2 (type: int), _col6 (type: int), _col7 (type: int), _col8 (type: string), _col9 (type: string), '2020-12-24' (type: string)
outputColumnNames: _col0, _col1, _col2, _col3, _col4, _col5, _col6, _col7
Statistics: Num rows: 8 Data size: 1663 Basic stats: COMPLETE Column stats: NONE
File Output Operator
compressed: false
Statistics: Num rows: 8 Data size: 1663 Basic stats: COMPLETE Column stats: NONE
table:
input format: org.apache.hadoop.mapred.SequenceFileInputFormat
output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat
serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
ListSink
根据执行计划得知:在full join中,就算使用了分区过滤,还是先full join得到结果,然后在通过where条件进行过滤,所以推荐使用子查询先过滤,然后在进行full join。
4.5、full join中的on和where总结
- 这里在on的条件下还是留有疑问。。
- 在where的条件下不管是否使用分区过滤都是先full join,再进行过滤的,所以这里现有通过子查询过滤,再进行full join
- 在full jion中不会自动添加join 键为is not null的条件
五、总结
1、inner join
- inner join首先可以通过分区进行过滤,防止全表扫描。
- inner join会自动为join的键(on d.id=u.department_id)添加is not null的过滤条件
- inner join 下on和where后面的条件进行过滤,在inner join中where和on是同时进行过滤,没有顺序的区别
2、left/right join
- left/right join使用分区条件过滤,可以防止全表扫描,最优先过滤
- left/right join在主表下进行过滤,使用on和where过滤的结果是不一样的,当使用where对主表进行过滤的时候,先过滤再进行left join。当使用on对主表进行过滤,先在非主表进行过滤标记,然后再对全表进行left join时根据过滤条件把不符合条件的行中来源于非主表的数据设置为null。
- left/right join在非主表下进行过滤,使用on和where过滤的结果是不一样的,如果是在on下面添加条件过滤,则先进行表的数据过滤,然后在进行left join,如果是在where后面添加条件过滤,则是先进行left join,然后在对left join得到的结果进行where条件的过滤,所以过滤非主表的时候可以通过on进行条件过滤,这样防止写子查询
- left/right join不会对join键自动添加is not null的过滤条件,所以在left/right join的时候要注意join键为null的情况,这里是可以做优化的
3、full join
- full join中on下条件下过滤(有疑问,还待探究)
- full join中where下条件过滤,不管是不是分区过滤,都是先进行full join,在根据条件进行过滤,这里推荐子查询先过滤在进行full join
- 不会对join键自动添加is not null的过滤条件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号