MySQL索引
主键索引和普通索引结构上的区别
每一个索引在InnoDB里面对应一棵B+树。
有一个主键列为ID的表,表中有字段k,在k上有索引。
CREATE TABLE T (
id int PRIMARY KEY,
k int NOT NULL,
name varchar(16),
INDEX(k)
) ENGINE = InnoDB;
表中R1~R5的(ID,k)值分别为(100,1)、(200,2)、(300,3)、(500,5)和(600,6)。
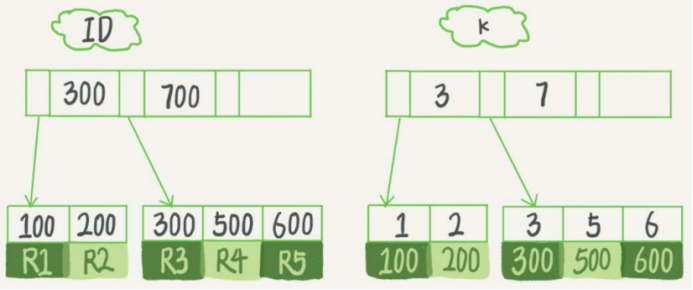
InnoDB中主键索引也称为聚簇索引,主键索引的叶子节点存的是整行数据。
InnoDB中非主键索引也称为二级索引,非主键索引的叶子节点内容是主键的值。
如果非主键索引无法涵盖查询字段,那么就需要通过主键回表查询主键索引。索引可以覆盖查询字段时称为覆盖索引。
自增主键优势
NOT NULL PRIMARY KEY AUTO_INCREMENT
插入新记录时,系统会获取当前ID最大值加1作为新记录的ID值。
从性能角度来说,插入新记录不涉及其他记录的移动,不触发叶子节点的分裂。
从存储角度来说,主键长度越小,普通索引的叶子节点就越小。
为什么MySQL使用B+树?
树的高度会影响磁盘IO次数。
为什么不用二叉搜索树?
如果数据是顺序的,那么二叉树会变成链表样式,查找速度慢。
为什么不用红黑树?
红黑树一个节点只能存储一个数据,存储大量数据场景,红黑树高度大,查找速度慢。
为什么不用B树?
B+树在查找数据方面比B树更方便。
1. B+树的非叶子节点存储索引值,不存储数据行,叶子节点存储数据行。B树节点存储数据行,B+树比B树高度低。
2. 在范围查找时,B+树叶子节点采用双向链表,比B树快。
前缀索引
B+树可以利用索引的最左前缀来定位记录。
联合索引(name,age)
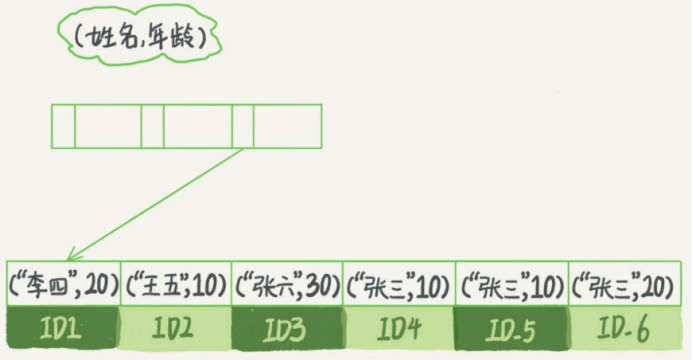
索引项是按照索引定义里面出现的字段顺序排序的。
当查询名字是张三的人时,快速定位到ID4,向后遍历得到结果。
当查询名字第一个字是张的人即where name like ‘张%’,快速定位到ID3,然后向后遍历,直到不满足条件为止。
最左前缀可以是联合索引的最左N个字段,也可以是字符串索引的最左M个字符。
使用联合索引时,考虑索引数量和成本。
索引下推
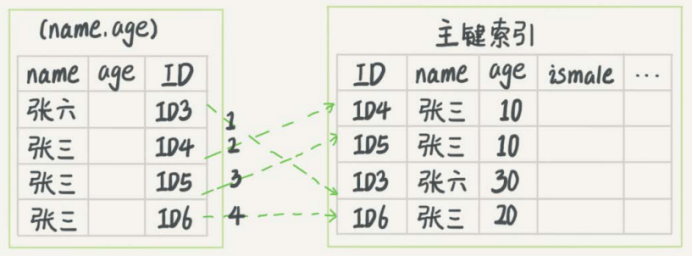
以市民表的联合索引(name, age)为例,检索出表中名字第一个字是张且年龄是10岁的所有男孩的SQL是
select * from tuser where name like '张%' and age=10 and ismale=1;
根据最左前缀原则,只能用 “张”,找到第一个满足条件的记录ID3,比全表扫描好。
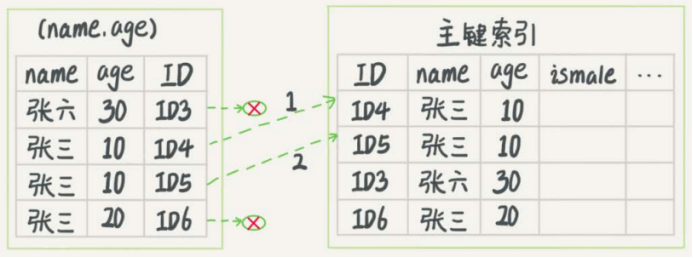
MySQL 5.6之前,只能从ID3开始一个个回表,到主键索引上找出数据行,再对比字段值。MySQL 5.6引入的索引下推优化,在索引遍历过程中,对非主键索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
每一个虚线箭头表示回表一次。
无索引下推执行流程(回表4次)
索引下推执行流程(回表2次)
索引失效的情况
以%开头的like语句执行前导模糊匹配
select * from order where name like '%XX'
or语句前后没有同时使用索引
数据类型出现隐式强制转换
例如,varchar值不加单引号时可能会自动转换成int
select * from user where phone=13800001234
强制类型转换会导致全表扫描
负向条件查询
select * from order where status != 0 and stauts != 1
字段上执行函数计算
select * from order where YEAR(date) < = '2017'
可优化为值计算
select * from order where date < = CURDATE()
或者
select * from order where date < = '2017-01-01'
违反最左前缀匹配
idx_age_name(age, name)
select * from user where name = ‘王五’
范围查询时右侧的列不能使用索引
idx name_age_phoneNumber(name, age, phone_number)
where name = ‘王五’and age > 17 and phone_number = ‘13888888888’
查询行数
COUNT(*)和COUNT(1)没有区别,统计所有,性能差不多,推荐使用COUNT(*);COUNT(列名)不统计该列是NULL的。
在MySQL 5.7.18之前,通过扫描主键来处理COUNT(*)。
在MySQL 5.7.18后,通过扫描最小的二级索引来处理COUNT(*)。如果不存在二级索引,那么扫描聚簇索引。二级索引比主键索引小。
索引对insert、update和delete的影响
insert
不会用到索引,维护索引会耗时。
update
使用基于区分度较高的字段加的索引,更新更快。
使用基于区分度较低的字段加的索引,更新其他字段时有无索引区别不大,更新这个字段时更新更慢。
delete
删除的条件上用到索引更新更快。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号