list watch机制
3点需求
只需要感知数据最新的状态,不担心错过数据的变化过程。
需求1: 实时性(即数据变化时,相关组件越快感知越好)
需求2: 保证消息的顺序性(即消息要按发生先后顺序送达目的组件。很难想象在Pod创建消息前收到该Pod删除消息时组件应该怎么处理)
需求3: 保证消息不丢失或者有可靠的重新获取机制(比如说kubelet和kube-apiserver间网络闪断,需要保证网络恢复后kubelet可以收到网络闪断期间产生的消息)
需求1的解决方案
k8s组件间主要通过http2协议(k8s 1.5之前采用http1.1,Go1.7之后开始支持http2)进行数据交互。
方案1: http长轮询(etcd2中watch)
client发起http request,服务端有请求数据后回复一个response(如果没有数据,那么服务端就等到有数据再回复),客户端收到response后马上又发起新的request,如此往复。
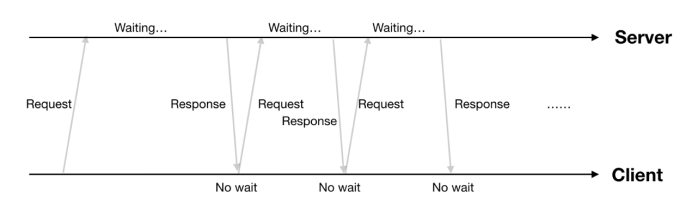
方案1缺点: 通信消耗大(每个response多一个request)
方案2:分块传输编码(watch,http get请求)
client发起http request,服务端有请求数据就回复一个response(回复的http header中会带上"Transfer-Encoding":"chunked")。client收到这种header的response后会继续等待后续数据,服务端有新的数据时会继续通过这条长连接发数据。

方案2缺点: 需要对返回的数据做定制
k8s选择了方案2。
调用watch接口
curl https://192.168.0.165:6443/api/v1/watch/namespaces/kube-system/pods --key ./client.key --cert ./client.crt --cacert ./ca.crt
{"type":"ADDED","object":{"kind":"Pod","apiVersion":"v1","metadata":...
...需求2的解决方案
k8s在ObjectMeta结构体中加了ResourceVersion字段,该字段的值由etcd来保证全局单调递增(每当etcd中写入一个数据时,全局ResourceVersion就加1)。保证不同时刻的数据ResourceVersion不同,并且后产生数据的ResourceVersion较之前数据的ResourceVersion大。client发起watch请求时,只需要带上请求数据在本地缓存中的最新ResourceVersion,server根据ResourceVersion从小到大把大于client ResourceVersion的数据按顺序推送给client,保证了推送数据的顺序性。
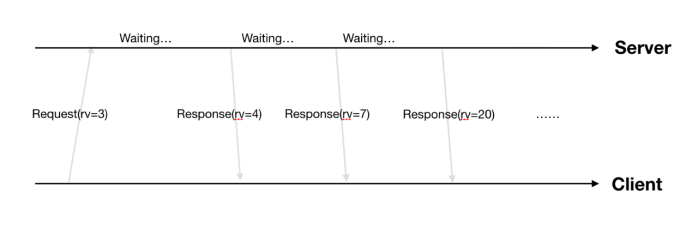
因为etcd保证全局单调+1,所以某类数据的RV可能不会逐步+1变化。
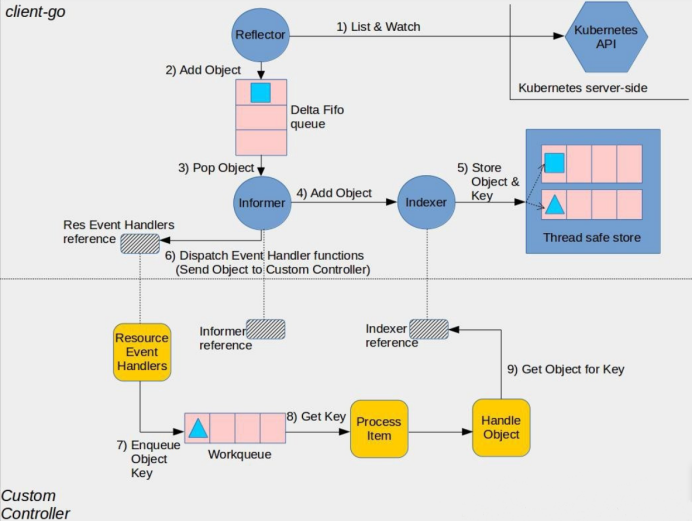
watch时先更新本地全量数据再推送事件到Controller处理。
需求3的解决方案
基于需求1和需求2的解决方案,需求3主要是对异常状况处理。k8s中结合watch请求增加了list请求,走HTTP短连接。
1. watch请求开始之前,先发起一次list请求,获取集群中当前所有该类数据(同时得到最新的ResourceVersion),之后基于最新的ResourceVersion发起watch请求。
2. 当watch出错时(比如说网络闪断造成client和server数据不同步),重新发起一次list请求获取所有数据,再重新基于最新ResourceVersion来watch。
list-watch流程如下:
具体代码参见: kubernetes/vendor/k8s.io/client-go/tools/cache/reflector.go#ListAndWatch()
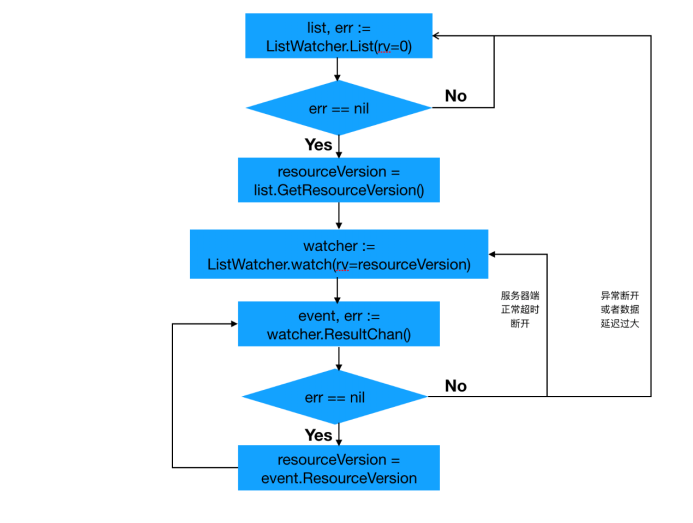
watch处理中的ResourceVersion更新是在watchHandler()中实现的。
总结
1. list请求返回全量数据,如果数据量较大时(比如20wPod),如果watch失败后需要relist,这时list请求成本是很高的。(服务端和客户端都需要对20w数据进行编解码,序列化和反序列化等)。k8s大规模应用场景下,需要尽量减少relist发生次数。
2. http1.1时(kubernetes1.5前)因为长连接是独立的TCP连接,假如网络断了,客户端是感知不到网络断开的,只是以为服务端一直没有数据。tcp keep-alive机制检测到网络断开后(golang默认http client的keep-alive时间是30s),会主动reset掉该连接,然后再次建立新的连接。在http2(大于kubernetes1.5中使用)中因为大家共用一条TCP连接,client各种请求导致keep-alive机制无法发挥作用,最后只能由数据的重传超时来reset掉这条TCP连接,这种场景下对系统的影响可能要大一些。
3. k8s 1.5之前http1.1中每个REST资源的list-watch都有一条长连接,这样对服务器压力很大。http2连接复用机制在k8s 1.5后得到了很好的解决。
4. tcp长连接断开考虑: 因为client不清楚服务端是否还有数据需要发送,所以由server来断开。
5. 如果client挂掉,那么server不知道,这样在kubernets1.5之前(因为使用http1.1)server维护大量的无效连接,造成server资源的大量浪费。k8s的解决方案是: watch请求中带一个超时参数(TimeoutSeconds),默认为5~10min间的随机数。所以server只要超时时间一到就会断开连接。server断开连接,time_wait将砸在server的手里。而time_wait的有效时间为1min~4min,所以5~10min是一个比较好的选择,可以保证server的time_wait保持在一个比较稳定的数量。
k8s采用了基于level trigger(条件触发,只要满足条件就发生)而非edge trigger(边缘触发,每当状态变化时发生)的设计理念,没有额外引入MQ,降低了系统的整体复杂度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号