String
String str1= "abc";
String str2= new String("abc");
String str3= str2.intern();
System.out.println(str1==str2);
System.out.println(str2==str3);
System.out.println(str1==str3);结果
false
false
true为什么使用byte数组来替换char数组?
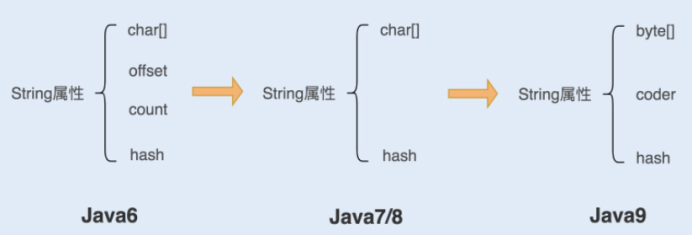
一个 char 字符占 16 位,2 个字节。意味着存储占一个字节的字符非常浪费。
为了节约内存,JDK1.9 的 String 类使用了占 8 位1 个字节的 byte 数组来存放字符串。
String不可变
String类被final关键字修饰了,而且变量char数组也被final修饰了。
第一,保证String对象的安全性,避免String对象被恶意修改。
第二,确保hash值的唯一性,使得HashMap等类实现key-value缓存功能。
第三,实现字符串常量池。
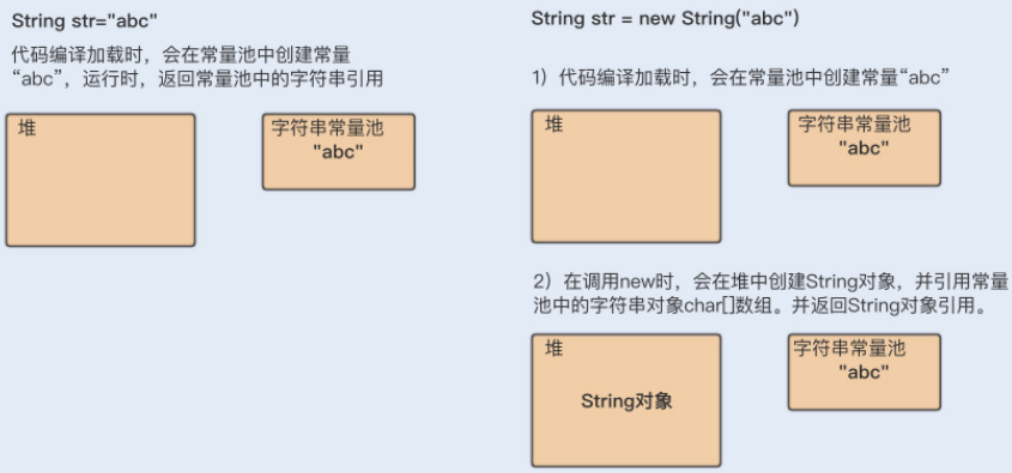
Java通常有两种创建字符串对象的方式
1 通过字符串常量的方式创建,如String str=“abc”
JVM首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用,否则新的字符串将在字符串常量池中被创建。这种方式可以减少同一个值的字符串对象的重复创建,节约内存。
2 字符串变量通过new形式的创建,如String str=new String(“abc”)
在类加载时,“abc"将会在字符串常量池中创建。
在调用new时,JVM调用构造函数,在堆中创建一个String对象,char数组引用字符串常量池中的"abc”字符串。
str指向堆中的String对象。
String对象的优化
如何构建超大字符串?
字符串常量的累计
String str= "ab" + "cd" + "ef";
理论上,首先会生成ab对象,再生成abcd对象,最后生成abcdef对象,
实际上,编译器自动优化这行代码,只有一个对象生成。
String str= "abcdef";
字符串变量的累计
String str = "abcdef";
for(int i=0; i<1000; i++) {
str = str + i;
}
编译器自动优化这行代码
每次循环都会生成一个新的StringBuilder实例,降低性能。
String str = "abcdef";
for(int i=0; i<1000; i++) {
str = (new StringBuilder(String.valueOf(str))).append(i).toString();
}
在字符串拼接时,自己要显示使用StringBuilder来提升性能。
如何使用String.intern节省内存?
String a =new String("abc").intern();
String b = new String("abc").intern();
if(a==b) {
System.out.print("a==b");
}结果
a==b
针对字符串常量,默认会将对象放入字符串常量池。
针对字符串变量,在字符串常量池中创建对象,堆中创建对象,引用字符串常量池中char数组到堆对象中,返回堆对象引用。
如果调用intern方法,查看字符串常量池中是否有同一个值的字符串。如果没有,就在字符串常量池中新增该对象,并返回该对象引用;如果有,就返回字符串常量池中的字符串引用。堆中原有的对象由于没有引用指向它,通过垃圾回收器回收。
a变量
在加载类时,在字符串常量池中创建一个“abc”字符串对象。
在调用new时,在堆中创建一个String对象。
在调用intern方法时,去字符串常量池中查找是否有等于该字符串的对象,发现有。
b变量
在加载类时,因为字符串常量池中有该字符串对象而不再创建。
在调用new时,在堆中创建一个String对象。
在调用intern方法时,去字符串常量池中查找是否有等于该字符串的对象,发现有。
而在堆中的对象,由于没有引用指向它,会被垃圾回收。所以a和b引用的是同一个对象。
intern方法本质上让变量引用字符串常量池中同一个字符串值的对象。
使用intern方法一定要结合实际场景。因为字符串常量池的实现是类似于一个HashTable的实现方式,HashTable(哈希表+单链表)存储的数据越多,遍历的时间复杂度越高。如果数据过大,会增加整个字符串常量池的负担。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号