MySQL逻辑架构图
整体架构
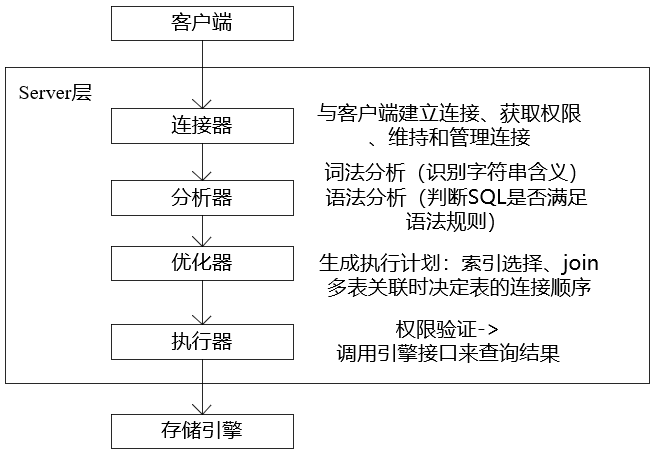
MySQL可以分为Server层和存储引擎层两部分。
不同的存储引擎(不同的表可以设置不同的存储引擎)共用一个Server层(从连接器到执行器)。
查询流程
连接器
Command列显示Sleep表示空闲连接。

如果客户端太长时间没动静,那么连接器会自动将它断开,由参数wait_timeout控制,默认值是8小时。
查询缓存
针对查询请求,先查询缓存(key是查询的语句,value是查询的结果),缓存中没有时再执行语句,执行结果存入缓存。
缓存弊大于利
更新表后,清空该表上所有查询缓存。针对频繁更新场景,查询缓存的命中率低。
弃用缓存
从MySQL 5.7.20开始,不推荐使用查询缓存,在MySQL 8.0中删除
更新流程
因性能问题而使用redolog
如果每次更新都通过磁盘先找到记录再更新,那么IO成本高。
先写日志,再写磁盘。
更新记录时,InnoDB先把记录写到redolog(重做日志,InnoDB引擎独有的日志),更新内存,InnoDB引擎会在空闲时候把这个操作更新到磁盘。
InnoDB的redolog(类似于黑板)是固定大小的,从头开始写,写到末尾又回到开头继续写。

checkpoint是即将擦除记录的位置,向后推移并循环,擦除记录前把记录更新到磁盘。
write pos是当前记录位置,向后推移并循环,写到3号文件末尾后回到0号文件开头。
write pos和checkpoint之间是空白部分,用于记录新的操作。
如果write pos追上checkpoint,那么表示redolog满了,先擦除记录再后移checkpoint。
redolog重做日志与binlog归档日志区别
1.redolog是InnoDB引擎独有的;binlog是MySQL的Server层实现的,所有引擎都可以使用。
2.redolog是物理日志,记录“在某个数据页上做了什么修改”;binlog是逻辑日志,记录语句的原始逻辑,例如“给ID=2这一行的c字段加1 ”。
3.redolog是循环写的,空间固定会用完;binlog是追加写入的,binlog文件写到一定大小后切换到下一个,不覆盖以前的日志。
4.redolog用于MySQL重启恢复,binlog用于MySQL备份恢复和主从复制。之所以不用binlog来恢复,是因为逻辑日志binlog需要转成物理日志redolog,耗时。
update具体流程
执行update T set c=c+1 where ID=2;
1.执行器通过InnoDB来取ID=2这一行。如果这一行所在的数据页在内存中,那么直接返回给执行器;否则,从磁盘读入内存后返回。
2.执行器把这个值加1。
3.InnoDB生成redolog和undolog,redolog进入prepare状态(中间态)。
4.执行器生成binlog。
5.执行器通过InnoDB来提交事务,记录xid先写redolog再写binlog,InnoDB把redolog改成提交状态,更新完成。
6.事务提交之后异步更新数据库磁盘记录。
两阶段提交目的是,确保redolog和binlog逻辑一致。
双1配置表示日志持久化:生成redolog(innodb_fush_log_at_trx_commit)和binlog(sync_binlog)后直接同步到磁盘。
1.写入redolog xid之前MySQL重启,清除redolog和binlog内容。
2.写入binlog xid之前MySQL重启,根据xid,redolog超过binlog部分会回滚,清除redolog和binlog内容。
3.写完binlog xid之后MySQL重启,MySQL继续提交事务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号