通过Cgroups来限制容器资源
Cgroups的3个组件
cgroup用于分组管理进程,subsystem(cpu和memory等)用于资源控制。 一个cgroup包含一组进程,可以在一个cgroup上增加subsystem的参数配置,把一组进程和一组subsystem的参数关联起来。
多个cgroup串成一个树状结构,这样的树是一个hierarchy。
系统默认为每个subsystem创建一个默认的hierarchy,例如memory的是/sys/fs/cgroup/memory。
查看memory subsystem的挂载点:mount | grep memory
Cgroups弊端
Cgroups对资源的限制能力不完善,例如proc文件系统。在容器里执行top指令,显示的是宿主机的CPU和内存数据,不是当前容器的数据。原因是top数据来自proc文件系统,proc文件系统不知道Cgroups限制的存在。
lxcfs已解决上面的问题,lxcfs是一个FUSE文件系统,让proc感知到cgroup的存在。
lxcfs把cgroup中容器相关的信息读取出来,存储到lxcfs相关的目录下,通过文件挂载的方式,将lxcfs相关目录映射到容器内的/proc目录下,从而使得容器内执行top、free等命令时显示容器真实数据。
安装
yum install -y fuse fuse-lib fuse-devel
git clone https://gitee.com/mirrors/lxcfs.git
git checkout stable-4.0
cd lxcfs
yum -y install libtool
./bootstrap.sh
./configure
make
make install确认安装成功
lxcfs -h运行lxcfs
lxcfs /var/lib/lxcfs &启动容器
docker run -it --rm -m 256m --cpus 1 \
-v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw \
-v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw \
centos:latest bash确认显示的容器资源正确

OOM处理机制
分配内存机制
和CPU不同,Linux允许进程申请超过实际物理内存上限的内存。
申请成功后,程序没有得到真正的物理内存。物理内存只有程序真的往这个地址写入数据的时候,才会分配给程序。这种内存申请模式的好处是,有效提高系统的内存利用率。
OOM行为控制
memory.oom_control
对于under_oom,表示是否处于OOM状态,内存耗尽时值为1,否则为0。
对于oom_kill_disable,值为0时表示开启oom killer,值为1时表示关闭。
$ sysctl -a | grep oom
# 除0以外的值表示OOM Killer运行时输出进程的列表信息
vm.oom_dump_tasks = 1
# 内存不足时,0是选择消耗内存最多的进程,1是选择触发内存不足的进程
vm.oom_kill_allocating_task = 0
# 内存不足时,0是通过杀进程来恢复,1是重启系统
vm.panic_on_oom = 0多层嵌套cgroup
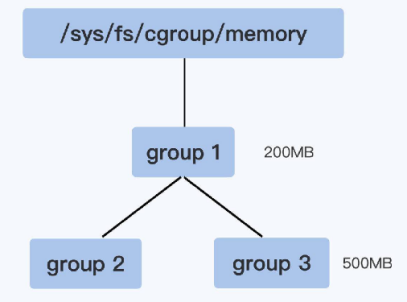
以父cgroup限制为准
group1里的memory.limit_in_bytes值是200MB,它的子控制组group3里memory.limit_in_bytes值是500MB。在group3里所有进程使用的内存总值就不能超过200MB。
oom_score计算方法
每个进程的oom_score_adj值,来自/proc/进程号/oom_score_adj,取值范围是-1000到1000,默认值是0。oom_score_adj值设置成-1000,会使OOM killer对当前进程失效;oom_score_adj值设置成1000,会使当前进程首当其冲被杀掉。
控制组中总的可用页面数乘以oom_score_adj的千分比,加上进程已经使用的物理页面数,计算出来的oom_score值最大的进程,会被系统选中杀死。
Docker配置Cgroups
$ docker run -itd -m 100m nginx:latest
700c59e5b38207399138144ffe44b5879c8776e9acf6234bdc821b9c68ce111d
# Docker为每个容器创建cgroup
# 在挂载了memory subsystem的hierarchy的根目录下
$ find /sys/fs/cgroup/memory -name docker-700c59e*.scope
/sys/fs/cgroup/memory/system.slice/docker-700c59e5b38207399138144ffe44b5879c8776e9acf6234bdc821b9c68ce111d.scope
# 查看容器进程id
$ docker inspect 700c59e | grep -i pid
"Pid": 1790,
"PidMode": "",
"PidsLimit": 0,
# 查看cgroup管理的进程
$ cat /sys/fs/cgroup/memory/system.slice/docker-700c59e5b38207399138144ffe44b5879c8776e9acf6234bdc821b9c68ce111d.scope/tasks
1790
1837
# 查看容器内的进程
$ ps -ef | grep 1790
root 1790 1771 0 21:03 pts/0 00:00:00 nginx: master process nginx -g daemon off;
101 1837 1790 0 21:03 pts/0 00:00:00 nginx: worker process
root 1898 1498 0 21:07 pts/0 00:00:00 grep --color=auto 1790
$ ps -ef | grep 1837
101 1837 1790 0 21:03 pts/0 00:00:00 nginx: worker process
root 1901 1498 0 21:07 pts/0 00:00:00 grep --color=auto 1837
# 查看容器内存限制(100M)
$ cat /sys/fs/cgroup/memory/system.slice/docker-700c59e5b38207399138144ffe44b5879c8776e9acf6234bdc821b9c68ce111d.scope/memory.limit_in_bytes
104857600Go限制容器资源
代码
package main
import (
"fmt"
"io/ioutil"
"os"
"os/exec"
"path"
"strconv"
"syscall"
)
// 挂载了memory subsystem的hierarchy的根目录位置
const cgroupMemoryHierarchyMount = "/sys/fs/cgroup/memory"
func main() {
if os.Args[0] == "/proc/self/exe" {
// 7.打印容器进程在当前PID命名空间下的PID
fmt.Printf("current pid %d", syscall.Getpid())
fmt.Println()
// 子进程默认加入到父进程的cgroup里面
cmd := exec.Command("sh", "-c", `stress --vm-bytes 200m --vm-keep -m 1`)
cmd.SysProcAttr = &syscall.SysProcAttr{}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
if err := cmd.Run(); err != nil {
fmt.Println(err)
os.Exit(1)
}
}
// 1.准备执行命令
cmd := exec.Command("/proc/self/exe")
cmd.SysProcAttr = &syscall.SysProcAttr{
Cloneflags: syscall.CLONE_NEWUTS | syscall.CLONE_NEWPID | syscall.CLONE_NEWNS,
}
cmd.Stdin = os.Stdin
cmd.Stdout = os.Stdout
cmd.Stderr = os.Stderr
// 2.启动命令的执行
if err := cmd.Start(); err != nil {
fmt.Println("ERROR ", err)
os.Exit(1)
} else {
// 3.得到fork出来的进程映射在外部命名空间的pid
fmt.Printf("container pid is %v\n", cmd.Process.Pid)
// 4.在cgroupMemoryHierarchyMount上创建cgroup
os.Mkdir(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit"), 0755)
// 5.将容器进程加入到这个cgroup中
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit", "tasks"),
[]byte(strconv.Itoa(cmd.Process.Pid)), 0644)
// 6.限制cgroup进程使用内存(如果是100m,那么stress进程会被杀掉)
ioutil.WriteFile(path.Join(cgroupMemoryHierarchyMount, "testmemorylimit",
"memory.limit_in_bytes"), []byte("300m"), 0644)
fmt.Println("prepare to execute stress --vm-bytes 200m --vm-keep -m 1")
}
}步骤
1 创建执行/proc/self/exe命令的容器进程。
2 在/sys/fs/cgroup/memory下创建子目录testmemorylimit,作为cgroup节点。
3 把容器进程ID加入这个cgroup的tasks文件里面。
4 设置cgroup的内存限制。
5 基于容器进程来创建stress进程,stress进程创建一个worker进程。
执行结果
当限制内存为300m时,stress正常运行。
当限制内存为100m时,stress会被OOM kill。
# ./main
container pid is 2014
prepare to execute stress --vm-bytes 200m --vm-keep -m 1
current pid 1
stress: info: [4] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: FAIL: [4] (415) <-- worker 5 got signal 9
stress: WARN: [4] (417) now reaping child worker processes
stress: FAIL: [4] (421) kill error: No such process
stress: FAIL: [4] (451) failed run completed in 0s
exit status 1cgroup cpu设置
cpu统一路径是/sys/fs/cgroup/cpu/kubepods.slice
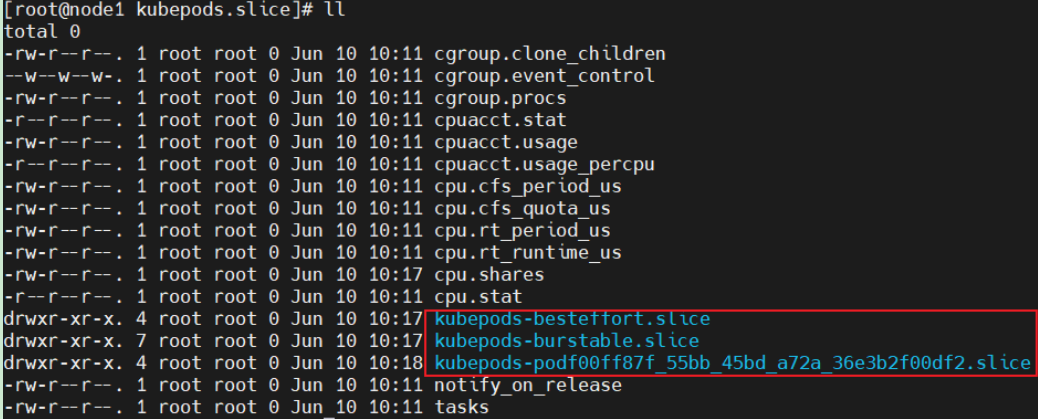
BestEffort:容器级别和Pod级别cpu没有限制


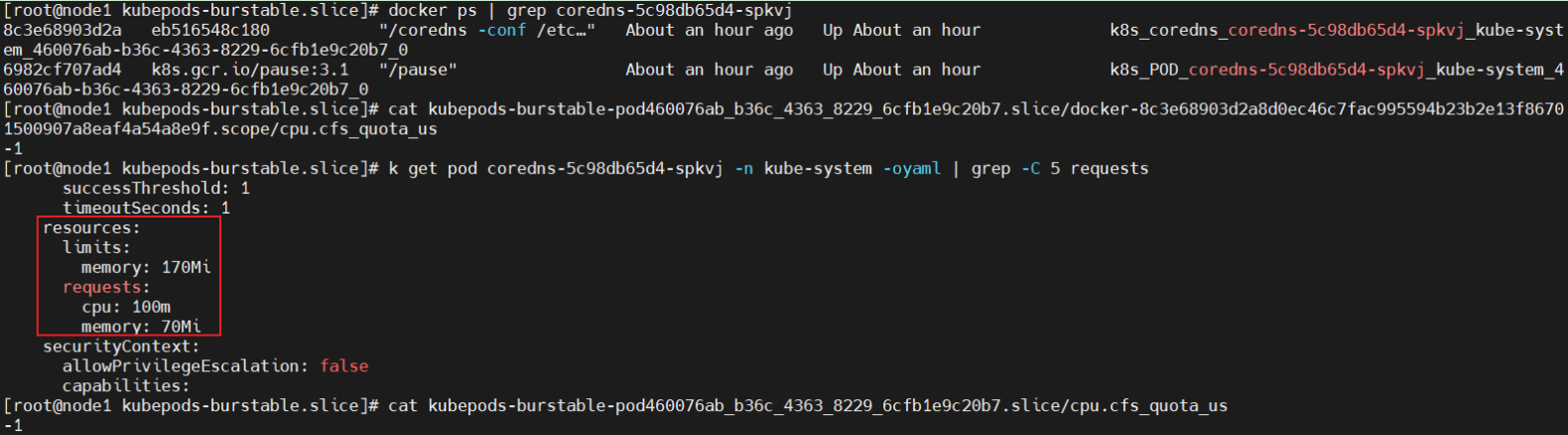
Burstable:容器级别和Pod级别cpu没有限制(没有设置limit场景)
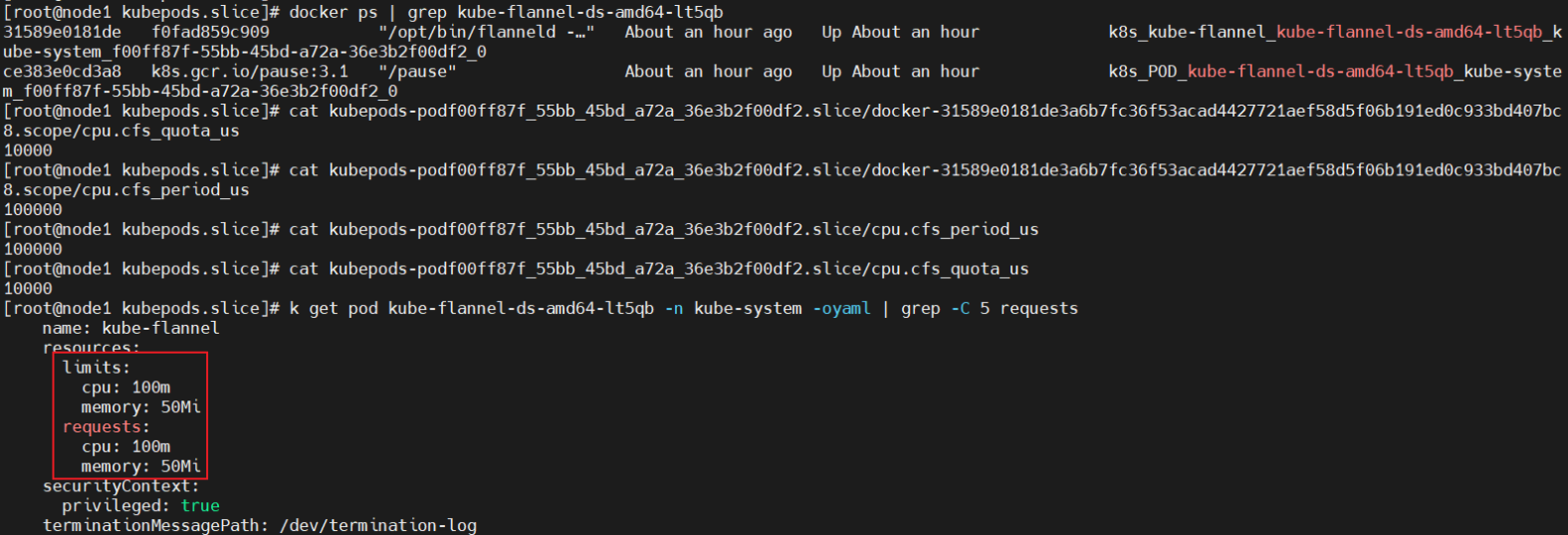
Guaranteed:容器级别和Pod级别cpu有限制(都是0.1个CPU)
按照时间片轮转方式来限制cpu,cpu.cfs_quota_us/cpu.cfs_period_us是cpu限制
参考资料
《自己动手写Docker》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号