Python网络爬虫与数据挖掘——复习笔记
\(\tt requests\) 库应用(爬虫)
一些注意点
raise_for_status()方法通常与try-except方法共同使用,前者用于返回错误,后者用于处理返回的错误类型。encoding会从 \(\tt header\) 中获取网页编码信息,但其不是万能的,当出现乱码问题时,可以使用apparent_encoding从网页的内容中分析网页编码的方式。
\(\tt requests\) 库爬取页面
import requests # 引入库
url = "......" # 爬取的地址
try:
admin = {"User-Agent": "Mozilla/5.0"} # 用户信息,增加成功率,可以不需要
r = requests.get(url, headers = admin)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
r.close()
except:
print("爬取失败!")
\(\tt requests\) 库爬取搜索引擎
搜狗搜索网址:www.sogou.com/web?query=......
import requests
keyword = "......" # 设定关键词
try:
admin = { "User-Agent": "Mozilla/5.0" }
query = {"query" : keyword} # 设定关键词键字对
r = requests.get('https://www.sogou.com/web?', headers = admin, params = query)
r.raise_for_status()
r.encoding = r.apparent_encoding
print(r.text)
r.close()
except:
print("爬取失败!")
\(\tt requests\) 库爬取网络图片
这里同时用到了 \(\tt os\) 库用于本地储存。
import requests
import os
url = "......" # 爬取的地址
root = "......" # 这里输入要储存的本地地址
path = root + url.split('/')[-1] + 'jpg'
try:
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r = requests.get(url)
r.raise_for_status()
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print("文件保存成功")
else:
print("文件已存在")
except:
print("爬取失败")
\(\tt beautifulsoup\) 库应用(格式化内容)
一些注意点
- 这个库主要是用来处理 \(\tt requests\) 库获取的文本的。
\(\tt beautifulsoup\) 获取标签
import requests
r = requests.get("......")
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser') # 以html标准格式化
print(soup.title) # 获取该网页标题
print(soup.a) # 获取a标签
print(soup.b) # 获取b标签:作用是加粗字体
print(soup.p) # 获取第一个p标签
使用 prettify() 方法格式化所获取的内容
import requests
r = requests.get("......")
from bs4 import BeautifulSoup
soup = BeautifulSoup(r.text, 'html.parser') # 以html标准格式化
print(soup.prettify()) # 输出格式化后的内容
print(soup.a.prettify()) # 对且仅对标签<a></a>格式化并输出
演示样例如下:
遍历内容中的所有标签
for parent in soup.a.parents:
if parent is None:
print("End")
else:
print(parent.name)
\(\tt Scrapy\) 框架(爬虫框架)
与 \(\tt requests\) 对比
-
两者都可以进行页面请求与爬取,是Python爬虫的两个重要技术路线。
-
小需求一般使用 \(\tt requests\) ,大需求使用 \(\tt Scrapy\) ;高定制使用 \(\tt requests\) 。

运行方式
使用命令行创建和运行爬虫。
scrapy startproject <name>创建一个新工程scrapy genspider创建一个爬虫scrapy crawl运行一个爬虫
\(\tt matplotlib\) 库应用(数据可视化)
一些注意点
- 一般与 \(\tt numpy\) 库(数组处理)共同使用。
plt.rcParams['font.sans-serif'] = ['SimHei']用于设定中文字体plt.xlabel("......")用于设定坐标轴标签文字
绘制折线
在使用 plot 方法绘制时,可以加入一些可变参数用于调节,一般应用比较多的有 color 颜色参数、linewidth 线条宽度参数,如下例
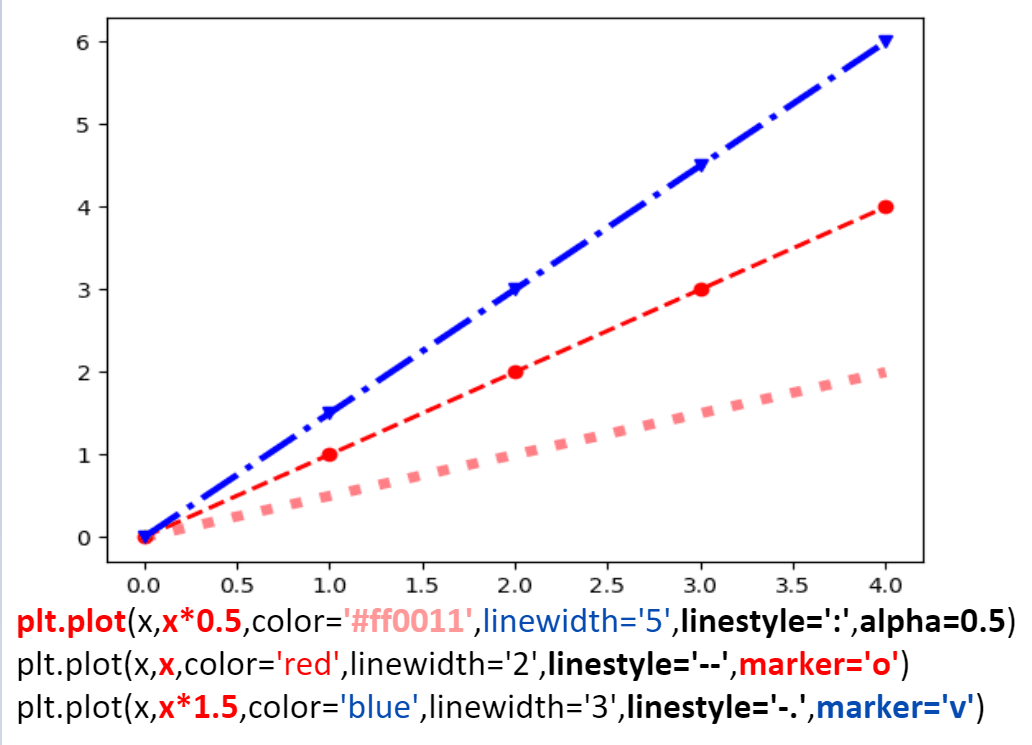
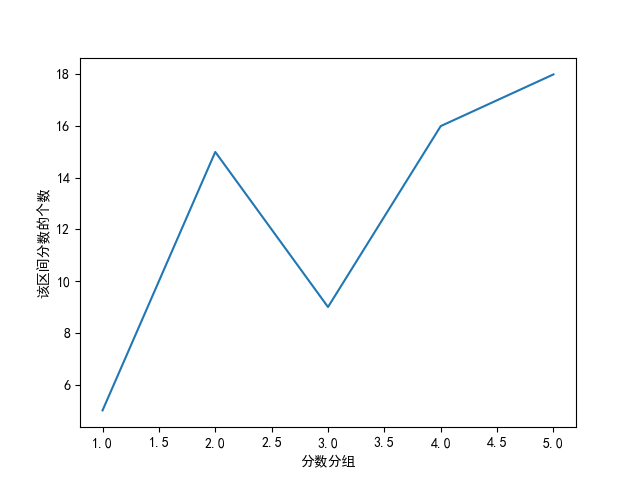
from matplotlib import pyplot as plt
import numpy as np # numpy 库用于设置x、y轴坐标
x = np.arange(1, 6, 1) # 设定x轴始末、间隔
val = np.array([5, 15, 9, 16, 18]) # 数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设定中文字体
plt.xlabel("分数分组")
plt.ylabel("该区间分数的个数")
plt.plot(x, val)
plt.show()
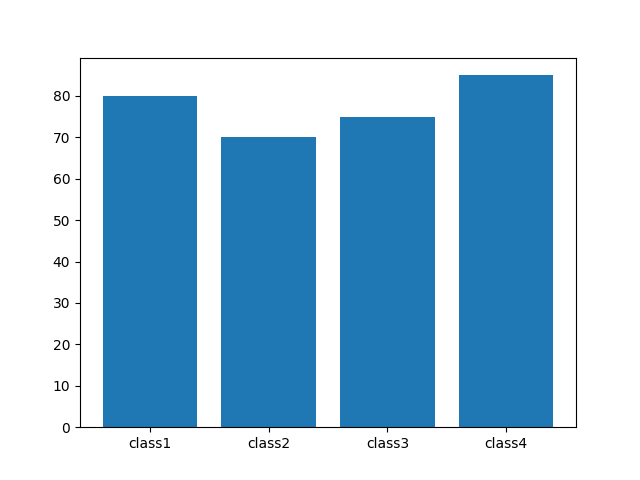
绘制柱状图
bar 常用可变参数(每个参数都可以输入一整个数组,用于分别调整每一根柱):color、width 柱状图宽度参数。
import matplotlib.pyplot as plt
x = [1, 2, 3, 4] # x轴刻度
val = [80, 70, 75, 85] # 数据
x_label = ['class1', 'class2', 'class3', 'class4']
plt.xticks(x, x_label) # 绘制x刻度标签
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设定中文字体
plt.bar(x, val) # 绘制柱状图
plt.show()
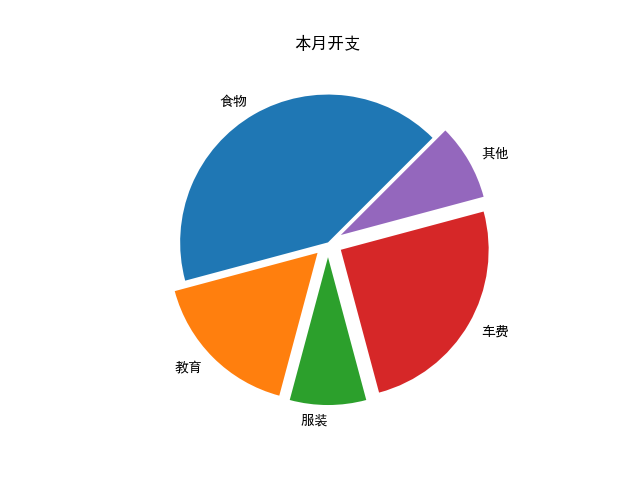
绘制饼图
pie 常用可变参数(每个参数都可以输入一整个数组,用于分别调整每一块饼):
labels该块的说明文字sizes该块的大小explode该块离开中心点的程度startangle起始角度(默认从x轴正方向逆时针 \(0°\) 画起)color
from matplotlib import pyplot as plt
items = ["食物", "教育", "服装", "车费", "其他"]
sizes = [5, 2, 1, 3, 1] # 大小
explode = [0, 0.1, 0.1, 0.1, 0.1] # 离心程度
plt.rcParams['font.sans-serif'] = ['SimHei']
alpha = 45 # 旋转角度
plt.pie(sizes, explode=explode, labels=items, startangle=alpha)
plt.title("本月开支")
plt.show()
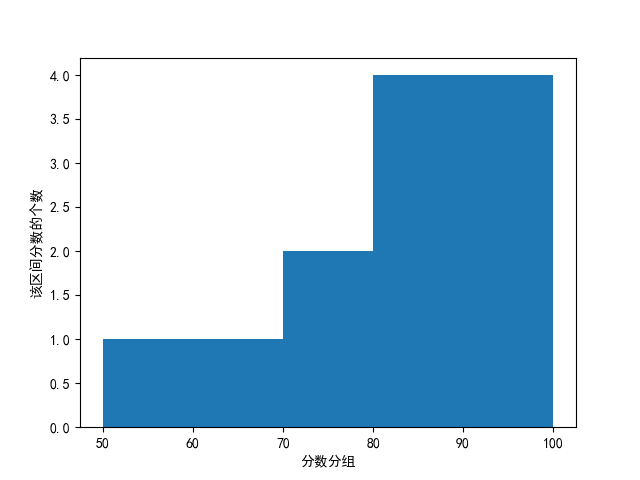
直方图
from matplotlib import pyplot as plt
import numpy as np
val = [55, 65, 75, 75, 85, 85, 85, 85, 95, 95, 95, 95]
x= np.arange(50, 101, 10)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.xlabel("分数分组")
plt.ylabel("该区间分数的个数")
plt.hist(val, x)
plt.show()
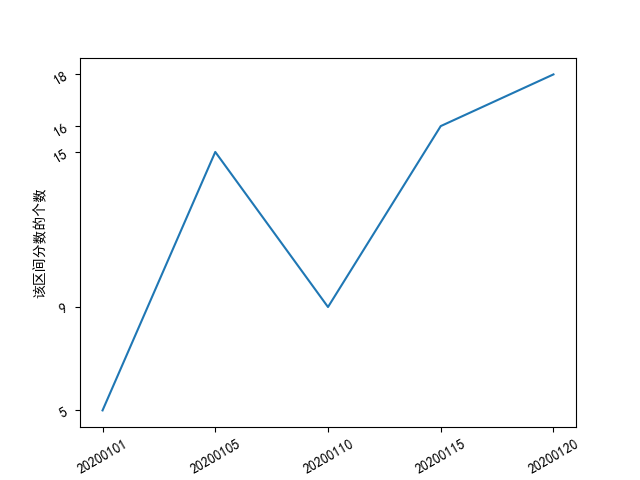
其他常用功能
-
xlim和ylim函数可以控制坐标轴范围,参数为:plt.xlim(..., ...)。 -
xticks和yticks函数可以手动修改坐标轴刻度标签,可以增加一个rotation参数用于调整标签角度。
from matplotlib import pyplot as plt
import numpy as np # numpy 库用于设置x、y轴坐标
x = np.arange(1, 6, 1) # 设定x轴始末、间隔
val = np.array([5, 15, 9, 16, 18]) # 数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设定中文字体
plt.xlabel("分数分组")
plt.ylabel("该区间分数的个数")
plt.xticks(x, ('20200101', '20200105', '20200110', '20200115', '20200120'), rotation=30)
plt.yticks(val, rotation=30)
plt.plot(x, val)
plt.show()
-
title函数可以输出一个位于图标顶部的标题,参数为:
plt.title("......")。 -
grid函数可以输出网格效果,参数为:plt.grid(linewidth='1', linestyle=':')。 -
legend函数可以输出图例,默认位置为 \(2\) (即左上角),\(1\) 为右上角,\(3\) 为左下角,参数为:plt.legend(loc='2')。
figure 函数(绘制多图)
该函数可以绘制多块白板,然后在白板上分别输出图片,让你一次运行可以输出多张图(好像没什么用)。
常用可选参数:
num设定白板的编号figsize设定白板的宽度与高度facecolor背景颜色edgecolor边界颜色
import matplotlib.pyplot as plt
import numpy as np
x = np.arange(0, 10, 0.1)
plt.figure(num=1, figsize=(3, 3))
plt.plot(x, np.cos(x))
plt.show()
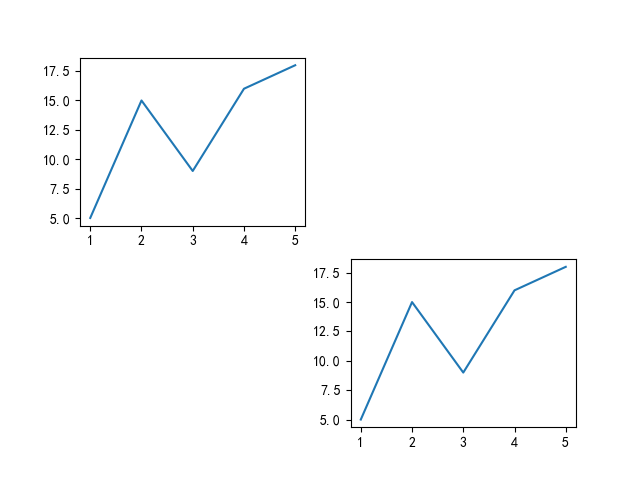
subplot 函数(绘制子图)
参数为:plt.subplot(N, M, K) ,分别代表建立一个 \(N*M\) 的网格并且将图片输出到 \(K\) 位置。
在 plot 函数之前使用 subplot 可以实现子图效果,如下例即为上文“绘制折线图”的子图效果。
from matplotlib import pyplot as plt
import numpy as np # numpy 库用于设置x、y轴坐标
x = np.arange(1, 6, 1) # 设定x轴始末、间隔
val = np.array([5, 15, 9, 16, 18]) # 数据
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设定中文字体
plt.xlabel("分数分组")
plt.ylabel("该区间分数的个数")
plt.subplot(2, 2, 1) # 输出到1号位置
plt.plot(x, val)
plt.subplot(2, 2, 4) # 输出到4号位置
plt.plot(x, val)
plt.show()
\(\tt Pandas\) 库应用(数据结构)
一维序列 \(\tt Series\)
类似于C++中的一个 map<T, int>,索引默认从 \(0\) 开始,值可以是任意类型。
直接创建与直接输出
import pandas as pd
a = pd.Series([1, 2, 3]) # 创建一个 Series
print(a) # 输出Series全部信息以及值的类型
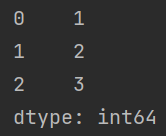
import pandas as pd
a = pd.Series([1, "ooo", 3]) # 创建一个 Series
print(a)
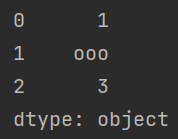
自定义索引
我们可以进一步的将其类比的 multimap<T, T> ,因为其索引也可以自由设定,且索引可以重复。
import pandas as pd
a = pd.Series([1, "ooo", 3], index=[10, 10, 'abc']) # 创建一个 Series
print(a)
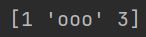
内置方法 values
仅输出值,不输出索引。
import pandas as pd
a = pd.Series([1, "ooo", 3]) # 创建一个 Series
print(a.values)
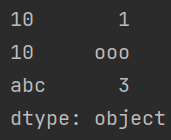
import pandas as pd
a = pd.Series([1, "ooo", 3], index=[10, 10, 'abc']) # 创建一个 Series
print(a.values)
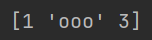
借助下标输出、重赋值
正如上文所说,类比于 multimap ,你可以取出索引后直接输出或是重新为其赋值。
import pandas as pd
a = pd.Series([1, "ooo", 3])
a[1] = "ppp"
print(a)
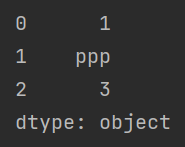
对于重复的索引,会一并进行修改,如下:
import pandas as pd
a = pd.Series([1, "ooo", 3], index=[10, 10, 'abc']) # 创建一个 Series
a[10] = 114514
print(a)
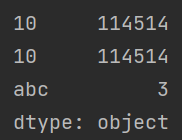
与 \(\tt numpy\) 共同使用
除此之外,该内容还可以与 \(\tt numpy\) 库一起使用,如下例,即向 \(\tt Series\) 中塞入了等差数列。
import pandas as pd
import numpy as np
a = pd.Series(np.arange(1, 10, 2)) # 创建一个 Series
print(a)
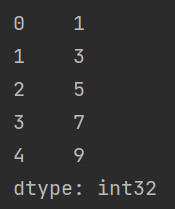
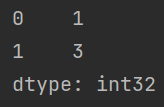
内置方法 head tail
head(x)输出前 \(x\) 行的全部数据,\(x\) 省略时输出全部数据tail(x)输出后 \(x\) 行的全部数据
import pandas as pd
import numpy as np
a = pd.Series(np.arange(1, 10, 2))
print(a.head(2))
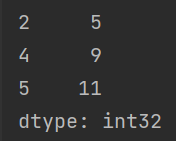
内置方法 take
take([x, y, z, ...])输出索引为 \(x,y,z\) 的数据
import pandas as pd
import numpy as np
a = pd.Series(np.arange(1, 20, 2)) # 创建一个 Series
print(a.take([2, 4, 5]))
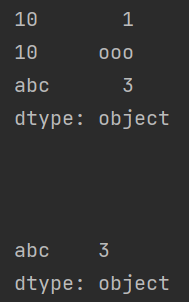
内置删除方法 drop
<Series2> = <Series>.drop([x, y, z, ...])先复制,随后在 \(\tt <Series2>\) 上删除索引为 \(x,y,z\) 的数据( \(\tt <Series>\) 不发生改变)
import pandas as pd
a = pd.Series([1, "ooo", 3], index=[10, 10, 'abc']) # 创建一个 Series
b = a.drop([10])
print(a)
print("\n\n")
print(b)
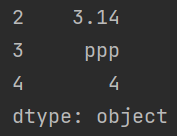
以切片方式访问
当索引为默认时样例如下:
import pandas as pd
a = pd.Series([1, "ooo", 3.14, "ppp", 4])
print(a[2:])
当索引为自定义时比较傻逼(如果这个库是我写的,那我不会允许这种事情发生)玄学,建议理解一下样例:
import pandas as pd
a = pd.Series([1, "ooo", 3.14, "ppp", 4], index=[2, 'b', 'c', 'd', 5])
print(a['c':]) # 直接用自定义索引做切片
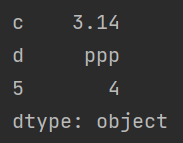
import pandas as pd
a = pd.Series([1, "ooo", 3.14, "ppp", 4], index=[2, 'b', 'c', 'd', 5])
print(a['c': 'e']) # 使用到了未出现过的自定义索引
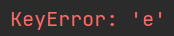 (报错,无输出)
(报错,无输出)
import pandas as pd
a = pd.Series([1, "ooo", 3.14, "ppp", 4], index=[2, 1, 3, 4, 0])
print(a[0:]) # 仍然使用数字作为索引
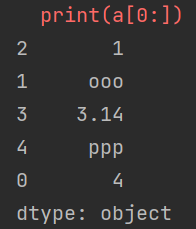 (报错后当作是默认索引,输出)
(报错后当作是默认索引,输出)
import pandas as pd
a = pd.Series([1, "ooo", 3.14, "ppp", 4], index=[2, 1, 3, 4, 0])
print(a[2: 4]) # 仍然使用数字作为索引
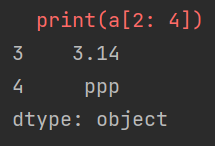 (报错后当作是默认索引,输出)
(报错后当作是默认索引,输出)
import pandas as pd
a = pd.Series([1, "ooo", 3.14, "ppp", 4], index=[5, 7, 6, 2, 0])
print(a[5: 6]) # 使用超出默认索引的数字作为索引
 (报错后当作是默认索引,输出)
(报错后当作是默认索引,输出)
\(\tt DataFrame\) 对象
类比于C++中的结构体数组。
直接创建与直接输出
包含三块内容,一块是值,一块是行索引,一块是列索引。
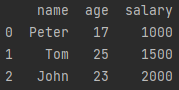
import pandas as pd
a = pd.DataFrame([['Peter', 17, 1000], ['Tom', 25, 1500], ['John', 23, 2000]], index=[0, 1, 2], columns=['name', 'age', 'salary'])
print(a)
以字典形式创建
看起来更符合一般人的习惯
import pandas as pd
p = {'name': ['Peter', 'Tom', 'John'], 'age': [17, 25, 23], 'salary': [1000, 1500, 2000]}
a = pd.DataFrame(p)
print(a)

内置方法 loc iloc
-
iloc[x, y]以行索引号 \(x\) 和列索引号 \(y\) 来定位,可以看作是一般的数组定位方式。如上方样例,a.iloc[0, 0]的结果是Peter;a.iloc[2, 1]的结果是23。 -
loc[x, y]以索引名来定位。如上方样例,a.loc[0, 'name']的结果是Peter;a.loc[2, 'age]的结果是23。 -
除此之外,还有个允许你使用混杂索引号和索引名来定位的
ix方法,但是这个函数一看就很弱智,极易造成歧义,所以我压根没去深入了解。
排列方法 sort_values sort_index
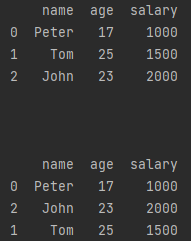
<DataFrame2> = <DataFrame>.sort_values(by=['...'], ascending=True)先复制,随后在 \(\tt DataFrame2\) 上对 \(...\) 序列升序排列(True)。
import pandas as pd
a = pd.DataFrame([['Peter', 17, 1000], ['Tom', 25, 1500], ['John', 23, 2000]], index=[0, 1, 2], columns=['name', 'age', 'salary'])
print(a)
print('\n\n')
b = a.sort_values(by=['age'], ascending=True)
print(b)
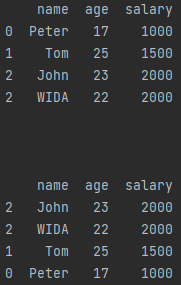
<DataFrame2> = <DataFrame>.sort_index(ascending=False)先复制,随后在 \(\tt DataFrame2\) 上对索引降序排列(Flase)。
import pandas as pd
a = pd.DataFrame([['Peter', 17, 1000], ['Tom', 25, 1500], ['John', 23, 2000], ['WIDA', 22, 2000]], index=[0, 1, 2, 2],
columns=['name', 'age', 'salary'])
print(a)
print('\n\n')
b = a.sort_index(ascending=False)
print(b)
以列为单位进行运算
<DataFrame>['...'].mean()对 \(\tt <DataFrame>\) 的...列计算平均数<DataFrame>['...'].median()对 \(\tt <DataFrame>\) 的...列计算中位数<DataFrame>['...'].quantile(0.25)<DataFrame>['...'].quantile(0.5)<DataFrame>['...'].quantile(0.75)对 \(\tt <DataFrame>\) 的...列计算四分位数。<DataFrame>['...'].var()对 \(\tt <DataFrame>\) 的...列计算方差<DataFrame>['...'].std()对 \(\tt <DataFrame>\) 的...列计算标准差
import pandas as pd
a = pd.DataFrame([['Peter', 17, 1000], ['Tom', 25, 1500], ['John', 23, 2000], ['WIDA', 22, 2000]], index=[0, 1, 2, 2],
columns=['name', 'age', 'salary'])
print(a)
print(a['salary'].mean())

文件交互
to_csv("...", encoding="utf-8")输出 \(\tt csv\) 文件至...路径,编码方式为utf-8。read_csv("...", encoding="utf-8")从...路径中读取 \(\tt csv\) 文件,编码方式为utf-8。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号