2024.9 - 做题记录与方法总结
CSP-S 的丧钟为谁而鸣?它正是为你而鸣! ——《CSP-S为谁而鸣》
2024/09/06#
拖到今天才写,主要是开学了
CF609E Minimum spanning tree for each edge#
题面:
题面翻译
题目描述
给你 \(n\) 个点,\(m\) 条边,如果对于一个最小生成树中要求必须包括第 \(i(1 \le i \le m)\) 条边,那么最小生成树的权值总和最小是多少。
输入格式
第一行有两个整数 \(n\) 和 \(m\)。
接下来 \(m\) 行,每行有三个整数 \(u\),\(v\) 和 \(w\) 表示一条权值为 \(w\) 的边连接 \(u\) 和 \(v\)。
输出格式
总共 \(m\) 行,第 \(i\) 行一个整数代表包括第 \(i\) 条边时的最小权值和。
说明/提示
\(1 \le n \le 2 \times 10^5,n-1 \le m\le 2 \times 10^5\)
\(1 \le u_i,v_i \le n,u_i \neq v_i,1 \le w_i \le 10^9\)
样例 #1
样例输入 #1
5 7 1 2 3 1 3 1 1 4 5 2 3 2 2 5 3 3 4 2 4 5 4样例输出 #1
9 8 11 8 8 8 9
这道题注意考察经典生成树结论: 次小生成树只会从原最小生成树替换掉一条边,替换掉两条边肯定不优!
一个简短的证明:
不难注意到,用 Kruskal 算法求最小生成树时,我们 放弃掉两条最小生成树边,用其他两条权值去替换 和 只放弃掉一条边,用其他一条边替换 ,两种决策显然第二种更优!
那么我们强制使用一条边,先看他是不是在最小生成树上?如果是,直接输出最小生成树权值。
如果不是,我们看如何替换。
当我们求出最小生成树后,再添加一条边,必然出现环,此时就是基环树。
我们都知道,只能在环上断边才能重新变成树,所以问题变成了环上断边。
因为我们要让最小生成树权值最小,我们肯定断环上权值最大的边,考虑树剖。
我们用树剖求出强制边 \((u,v)\) 所在环上最大值:因为 \((u,v)\) 强制,实际上是 \(path : (u,v)\) 上的边权最大值。
所以 sol 就是 Kruskal + 树剖(边权转点权)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int M = 2e5+5,N = M,inf = 0x3f3f3f3f3f3f3f3fLL;
int n,m,ans,det[M],s[N];
array<int,4> e[M];
bool vis[N];
int head[N],nxt[N<<1],to[N<<1],cnt,val[N<<1];
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
int find(int x) {
if(s[x] ^ x) s[x] = find(s[x]);
return s[x];
}
void kruskal() {
for(int i = 1;i<=n;i++) s[i] = i;
int tot = 0;
for(int i = 1;i<=m;i++) {
int fx = find(e[i][1]),fy = find(e[i][2]);
if(fx ^ fy) {
s[fx] = fy;
vis[e[i][3]] = true;
add(e[i][1],e[i][2],e[i][0]);
add(e[i][2],e[i][1],e[i][0]);
ans += e[i][0];
tot++;
if(tot == n - 1) break;
}
}
}
int dep[N],fa[N],siz[N],son[N],id[N],w[N],_w[N],top[N],num;
void dfs1(int x,int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = dep[f] + 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs1(y,x);
w[y] = val[i];
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
void dfs2(int x,int topx) {
top[x] = topx;
id[x] = ++num;
_w[num] = w[x];
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
namespace sgt{
#define ls (p << 1)
#define rs (ls | 1)
#define mid ((pl + pr) >> 1)
int mx[N<<2];
void push_up(int p) {
mx[p] = max(mx[ls],mx[rs]);
}
void build(int p,int pl,int pr) {
if(pl == pr) {
mx[p] = _w[pl];
return;
}
build(ls,pl,mid);
build(rs,mid+1,pr);
push_up(p);
}
int query(int p,int pl,int pr,int l,int r) {
if(l > r) return 0;
if(l <= pl && pr <= r) return mx[p];
if(r <= mid) return query(ls,pl,mid,l,r);
else if(l > mid) return query(rs,mid+1,pr,l,r);
else return max(query(ls,pl,mid,l,r),query(rs,mid+1,pr,l,r));
}
}
int query(int x,int y) {
int re = 0;
while(top[x] ^ top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x,y);
re = max(re,sgt::query(1,1,n,id[top[x]],id[x]));
x = fa[top[x]];
}
if(dep[x] > dep[y]) swap(x,y);
re = max(re,sgt::query(1,1,n,id[x] + 1,id[y]));
return re;
}
int a[N];
signed main() {
init();
n = rd(),m = rd();
for(int i = 1;i<=m;i++)
e[i][1] = rd(),e[i][2] = rd(),e[i][0] = rd(),e[i][3] = i;
sort(e + 1,e + m + 1);
kruskal();
dfs1(1,0),dfs2(1,1);
sgt::build(1,1,n);
for(int i = 1;i<=m;i++) {
if(vis[e[i][3]]) a[e[i][3]] = ans;
else {
int re = query(e[i][1],e[i][2]);
a[e[i][3]] = ans + e[i][0] - re;
}
}
for(int i = 1;i<=m;i++) wt(a[i]),putchar('\n');
return 0;
}
CF1009F Dominant Indices#
题面:
题目描述
你得到一个包含 \(n\) 个顶点的无向树,顶点 \(1\) 是树的根。
我们将顶点 \(x\) 的深度数组定义为一个无限序列 \([d_{x, 0}, d_{x, 1}, d_{x, 2}, \dots]\),其中 \(d_{x, i}\) 是满足以下两个条件的顶点 \(y\) 的数量:
\(x\) 是 \(y\) 的祖先;
从 \(x\) 到 \(y\) 的简单路径正好经过 \(i\) 条边。
顶点 \(x\) 的深度数组的主导索引(简称为顶点 \(x\) 的主导索引)是一个索引 \(j\),满足:对于每个 \(k < j\),\(d_{x, k} < d_{x, j}\);
对于每个 \(k > j\),\(d_{x, k} \le d_{x, j}\)。
对于树中的每个顶点,计算其主导索引。输入格式
第一行包含一个整数 \(n\)(\(1 \le n \le 10^6\)),表示树的顶点数量。
接下来有 \(n-1\) 行,每行包含两个整数 \(x\) 和 \(y\)(\(1 \le x, y \le n\),\(x \ne y\)),表示树中的一条边。
保证这些边构成一棵树。
输出格式
输出 \(n\) 个数字,第 \(i\) 个数字表示顶点 \(i\) 的主导索引
样例 #1
样例输入 #1
4 1 2 2 3 3 4样例输出 #1
0 0 0 0样例 #2
样例输入 #2
4 1 2 1 3 1 4样例输出 #2
1 0 0 0样例 #3
样例输入 #3
4 1 2 2 3 2 4样例输出 #3
2 1 0 0
长链剖分模板题,但是用线段树合并。
这道题长链剖分没看出来,线段树合并一眼!
简单的说,我们要找每个点子树内最厚的深度(哪个深度有最多的点,这里的深度指以该点为根的深度),如果有多个答案,选择最浅的深度作为答案。
我们考虑对于每个点,将每个点的深度加入到该点的权值线段树上,然后将子树的线段树合并到该节点,最后全局查询最左的最大深度。
没什么多说的,上代码。
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e6+5;
int n,dep[N],a[N];
int head[N],nxt[N<<1],to[N<<1],cnt;
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
int rt[N];
namespace sgt{
int mx[N * 25],ls[N * 25],rs[N * 25],tot;
#define mid ((pl + pr) >> 1)
void push_up(int p) {mx[p] = max(mx[ls[p]],mx[rs[p]]);}
void update(int &p,int pl,int pr,int k) {
if(!p) p = ++tot;
if(pl == pr) {mx[p]++;return;}
if(k <= mid) update(ls[p],pl,mid,k);
else update(rs[p],mid+1,pr,k);
push_up(p);
}
int query(int p,int pl,int pr) {
if(!p) return 0;
if(pl == pr) return pl;
if(mx[ls[p]] >= mx[rs[p]]) return query(ls[p],pl,mid);
else return query(rs[p],mid + 1,pr);
}
int merge(int x,int y,int pl,int pr) {
if(!x || !y) return x + y;
if(pl == pr) {
mx[x] += mx[y];
return x;
}
ls[x] = merge(ls[x],ls[y],pl,mid);
rs[x] = merge(rs[x],rs[y],mid+1,pr);
push_up(x);
return x;
}
}
void dfs(int x,int f) {
dep[x] = dep[f] + 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs(y,x);
rt[x] = sgt::merge(rt[x],rt[y],1,n);
}
}
sgt::update(rt[x],1,n,dep[x]);
a[x] = sgt::query(rt[x],1,n) - dep[x];
}
signed main() {
init();
n = rd();
for(int i = 1;i<n;i++) {
int u = rd(),v = rd();
add(u,v);add(v,u);
}
dfs(1,0);
for(int i = 1;i<=n;i++) wt(a[i]),putchar('\n');
return 0;
}
2024/09/09#
P4197 Peaks#
题面:
题目描述
在 Bytemountains 有 \(n\) 座山峰,每座山峰有他的高度 \(h_i\)。有些山峰之间有双向道路相连,共 \(m\) 条路径,每条路径有一个困难值,这个值越大表示越难走。
现在有 \(q\) 组询问,每组询问询问从点 \(v\) 开始只经过困难值小于等于 \(x\) 的路径所能到达的山峰中第 \(k\) 高的山峰,如果无解输出 \(-1\)。
输入格式
第一行三个数 \(n,m,q\)。
第二行 \(n\) 个数,第 \(i\) 个数为 \(h_i\)。接下来 \(m\) 行,每行三个整数 \(a,b,c\),表示从 \(a \to b\) 有一条困难值为 \(c\) 的双向路径。
接下来 \(q\) 行,每行三个数 \(v,x,k\),表示一组询问。输出格式
对于每组询问,输出一个整数表示能到达的山峰中第 \(k\) 高的山峰的高度。
样例 #1
样例输入 #1
10 11 4 1 2 3 4 5 6 7 8 9 10 1 4 4 2 5 3 9 8 2 7 8 10 7 1 4 6 7 1 6 4 8 2 1 5 10 8 10 3 4 7 3 4 6 1 5 2 1 5 6 1 5 8 8 9 2样例输出 #1
6 1 -1 8提示
数据规模与约定
对于 \(100\%\) 的数据,\(n \le 10^5\),\(0 \le m,q \le 5\times 10^5\),\(h_i,c,x \le 10^9\)。
不难看出本题是 Kruskal 重构树
建出 Kruskal 最小树重构树后倍增找到可达的最远的 lca ,
然后,对于子树中的叶子进行第 \(k\) 大查询!
然而叶子的编号不是连续的,我们很难用什么数据结构维护。
考虑改变编号,我们用 dfs 序去遍历树,如图:
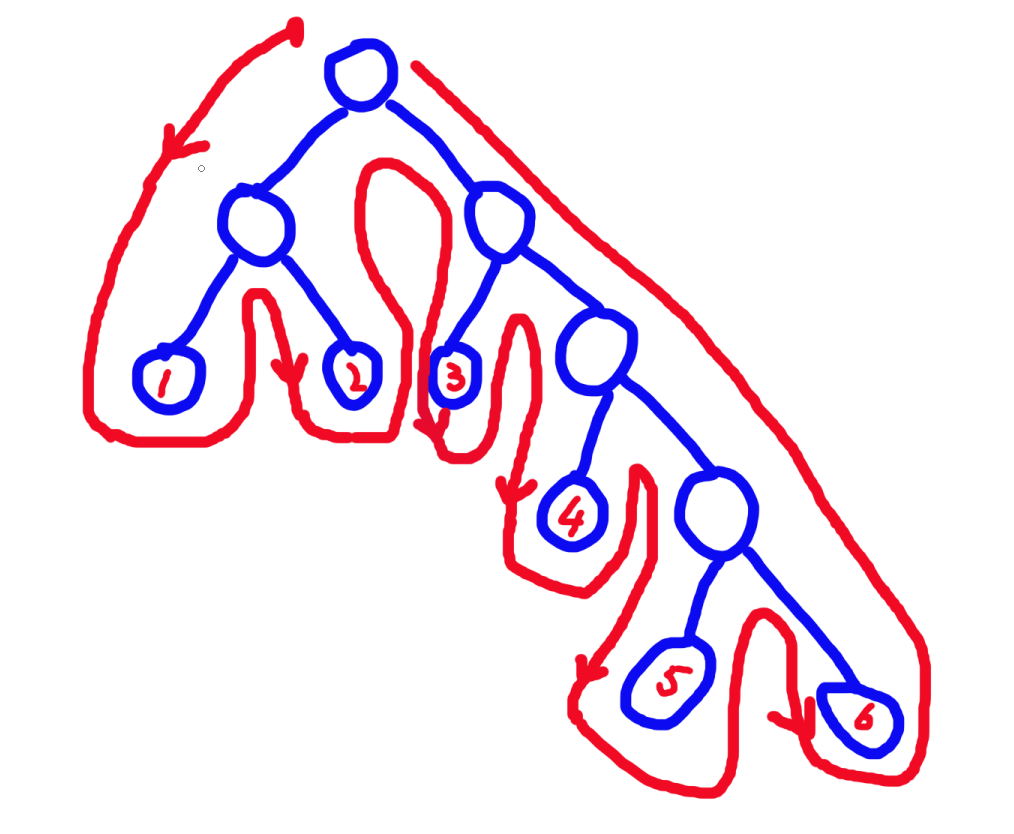
我们发现,因为 dfs 序的性质,一个节点的子树被访问完了之后,才会退出该节点,所以一个子树的叶子节点一定构成一个连续区间,
这样我们就将题目变成了区间第 \(k\) 大查询,用可持久化线段树就可以维护出来了.
因为可持久化线段树维护的值可以离散化,果断离散化减少空间
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5,M = N * 16,maxn = N * 16;
int n,m,q,h[maxn],s[maxn],k,v[maxn];
array<int,3> e[M];
int head[maxn],nxt[maxn<<1],to[maxn<<1],cnt;
void init() {memset(head,-1,sizeof(head));}
int find(int x) {
if(s[x] ^ x) s[x] = find(s[x]);
return s[x];
}
void add(int u,int V) {
nxt[cnt] = head[u];
to[cnt] = V;
head[u] = cnt++;
}
void kruskal() {
k = n;
int tot = 0;
for(int i = 0;i<maxn;i++) s[i] = i;
sort(e + 1,e + m + 1);
for(int i = 1;i<=m;i++) {
int fx = find(e[i][1]),fy = find(e[i][2]);
if(fx ^ fy) {
s[fx] = s[fy] = ++k;
add(fx,k);add(fy,k);
add(k,fx);add(k,fy);
v[k] = e[i][0];
tot++;
if(tot == n - 1) break;
}
}
}
int fa[maxn][21],hd[maxn][21],L[maxn],R[maxn],tot;
int rt[maxn],lst[maxn];
namespace sgt{
#define mid ((pl + pr) >> 1)
int rot,siz[N*50],ls[N*50],rs[N*50];
int update(int f,int pl,int pr,int x) {
int rt = ++rot;
ls[rt] = ls[f];
rs[rt] = rs[f];
siz[rt] = siz[f] + 1;
if(pl < pr) {
if(x <= mid) ls[rt] = update(ls[f],pl,mid,x);
else rs[rt] = update(rs[f],mid+1,pr,x);
}
return rt;
}
int query(int x,int y,int pl,int pr,int K) {
if(siz[y] - siz[x] < K) return -1;
if(pl == pr) return pl;
int sz = siz[rs[y]] - siz[rs[x]];
if(K <= sz) return query(rs[x],rs[y],mid + 1,pr,K);
else return query(ls[x],ls[y],pl,mid,K - sz);
}
}
void dfs(int x,int f) {
fa[x][0] = f;hd[x][0] = v[fa[x][0]];
for(int i = 1;i<=20;i++) {
fa[x][i] = fa[fa[x][i - 1]][i - 1];
hd[x][i] = min(hd[fa[x][i - 1]][i - 1],hd[x][i]);
}
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs(y,x);
L[x] = min(L[x],L[y]);
R[x] = max(R[x],R[y]);
}
}
if(x <= n) {
R[x] = L[x] = ++tot;
rt[tot] = sgt::update(rt[tot - 1],1,N,h[x]);
}
}
signed main() {
init();
n = rd(),m = rd(),q = rd();
for(int i = 1;i<=n;i++) lst[i] = h[i] = rd();
for(int i = 1;i<=m;i++)
e[i][1] = rd(),e[i][2] = rd(),e[i][0] = rd();
sort(lst + 1,lst + n + 1);
int top = unique(lst + 1,lst + n + 1) - lst - 1;
for(int i = 1;i<=n;i++)
h[i] = lower_bound(lst + 1,lst + top + 1,h[i]) - lst;
kruskal();
memset(L,0x3f,sizeof(L));
memset(hd,0x3f,sizeof(hd));
v[0] = 0x3f3f3f3f3f3f3f3fLL;
dfs(k,0);
while(q--) {
int S = rd(),x = rd(),K = rd();
for(int i = 20;i >= 0;i--)
if(hd[S][i] <= x)
S = fa[S][i];
if(sgt::siz[rt[R[S]]] - sgt::siz[rt[L[S] - 1]] < K) {puts("-1");continue;}
int ans = sgt::query(rt[L[S] - 1],rt[R[S]],1,N,K);
if(ans == -1) puts("-1");
else wt(lst[ans]),putchar('\n');
}
return 0;
}
2024/09/12#
CF888G Xor-MST#
题面:
题面翻译
- 给定 \(n\) 个结点的无向完全图。每个点有一个点权为 \(a_i\)。连接 \(i\) 号结点和 \(j\) 号结点的边的边权为 \(a_i\oplus a_j\)。
- 求这个图的 MST 的权值。
- \(1\le n\le 2\times 10^5\),\(0\le a_i< 2^{30}\)。
样例 #1
样例输入 #1
5 1 2 3 4 5样例输出 #1
8样例 #2
样例输入 #2
4 1 2 3 4样例输出 #2
8
这里的图是一个完全图,直接跑 \(Kruskal\) 和 \(Prim\) 都会炸掉。
于是 \(Boruvka\) MST算法出现了。
简要说明一下这个算法的本质:
个人认为,这个算法类似于分治,从子问题出发,直到求解出全局答案。(一种 \(Kruskal\) 和 \(Prim\) 的结合)
-
最初,每个点分别归属于一个集合,
-
然后,找出集合之间前 \(\lfloor \frac{n}{2} \rfloor\) 小边(这些边的端点不重合),连接,并合并两个区间
-
重复过程 \(2\) 直到只剩下一个集合
因为过程 \(2\) 会把 \(n\) 个集合缩小到 \(\lceil \frac{n}{2} \rceil\) 个集合,时间复杂度显然是 \(\mathcal{O}(n \log n)\) 。
但是考题中一般不裸考 \(Boruvka\) MST,而关键在于 \(Boruvka\) 算法的思想,自下而上的合并手段。
回到本题,看到异或自然想到 建一颗 \(01\) Trie,
关键在于,在 \(01\) Trie 上反向 \(Borvurka\) !
当我们在判断 Trie 上某一位时,如果左右儿子都存在(即 下一位是 \(0、1\) 的数都出现过)
因为每个点都要相连,而连接时有异或最小的限制,
所以在此时,我们假定 左子树中所有数已经在一个集合里,右子树同理,
然后如同 \(Borvurka\) 的运行过程一样,现在我们要将左右两个集合以最小代价连接起来。
在右子树中找到左子树中每个数在右子树中数的异或最小值,再加上该位左右子树合并的代价 \((即 (1\ <<\ dep))\)
然后递归去做左、右子树中分别建出一颗树的最小代价。
有人说像 反向 \(Kruskal\) 重构树,这样说也不算错,如果有助于理解,也可以这样思考.
在具体实现上,在做 在右子树中找到左子树中每个数在右子树中数的异或最小值时,
将最初的数排序插入,这样左子树和右子树上的数的编号(下标)连续。
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 2e5+5;
int n,a[N],ls[N * 40],rs[N * 40],rt,tot,L[N * 40],R[N * 40];
void insert(int &p,int x,int dep) {
if(!p) p = ++tot;
L[p] = min(L[p],x);
R[p] = max(R[p],x);
if(dep < 0) return;
((a[x] >> dep) & 1) ? insert(rs[p],x,dep - 1) : insert(ls[p],x,dep - 1);
}
int query(int p,int v,int dep) {
if(dep < 0) return 0;
int k = (v >> dep) & 1;
if(k) {
if(rs[p]) return query(rs[p],v,dep - 1);
else return query(ls[p],v,dep - 1) + (1 << dep);
}else {
if(ls[p]) return query(ls[p],v,dep - 1);
else return query(rs[p],v,dep - 1) + (1 << dep);
}
}
long long dfs(int p,int dep) {
if(dep < 0) return 0;
if(R[ls[p]] && R[rs[p]]) {
int mi = 0x3f3f3f3f;
for(int i = L[ls[p]];i<=R[ls[p]];i++) mi = min(mi,query(rs[p],a[i],dep - 1));
return dfs(ls[p],dep - 1) + dfs(rs[p],dep - 1) + mi + (1 << dep);
}
if(R[ls[p]]) return dfs(ls[p],dep - 1);
else if(R[rs[p]]) return dfs(rs[p],dep - 1);
return 0;
}
signed main() {
n = rd();
for(int i = 1;i<=n;i++)
a[i] = rd();
sort(a + 1,a + n + 1);
memset(L,0x3f,sizeof(L));
for(int i = 1;i<=n;i++) insert(rt,i,30);
wt(dfs(rt,30));
return 0;
}
Gym-101194G Pandaria#
简要题意:
给你一个 \(n(n ≤ 10^5)\) 个点,\(m(m ≤ 2 × 10^5)\) 条边的无向图,
每个点有一个颜色 \(c_i\),每条边有一个边权 \(w_i\)。
\(q(q ≤ 2 × 10^5)\) 组询问 \((x, w)\),每次询问从点 \(x\) 出发,只经过边权不超过 \(w\) 的边所能到达的连通块中,出现次数最多的颜色中,编号最小的颜色是多少?
多测且强制在线
遇到限制 \(\Rightarrow\) \(Kruskal\) 重构树 + 倍增,
子树颜色最大值查询 \(id\) \(\Rightarrow\) 树上线段树合并
强制在线 \(\Rightarrow\) 离线查询每个 \(Kruskal\) 重构树上的点的答案
然后就没有然后了,很水,但是确实比较板子
AC-code:
#include<bits/stdc++.h>
using namespace std;
using ll = long long;
ll rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(ll x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = (1e5+5),M = 2e5+5,maxN = N << 2;
int n,m,q,s[maxN],T,co[N],tot,V[maxN];
int fa[maxN][21];
ll w[maxN][21];
array<int,3> e[M];
int head[maxN],nxt[maxN<<1],to[maxN<<1],cnt;
void init() {
for(int i = 0;i<maxN;i++) s[i] = i;
memset(head,-1,sizeof(head));
memset(V,0x3f,sizeof(V));
memset(w,0x3f,sizeof(w));
memset(fa,0,sizeof(fa));
cnt = 0;tot = n;
}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
int find(int x) {
if(s[x] ^ x) s[x] = find(s[x]);
return s[x];
}
void kruskal() {
tot = n;
sort(e + 1,e + m + 1);
for(int i = 1;i<=m;i++) {
int fx = find(e[i][1]),fy = find(e[i][2]);
if(fx == fy) continue;
s[fx] = s[fy] = ++tot;
add(fx,tot);add(fy,tot);
add(tot,fx);add(tot,fy);
V[tot] = e[i][0];
if(tot - n == n - 1) break;
}
}
int rt[maxN];
namespace sgt{
#define mid ((pl + pr) >> 1)
int ls[maxN * 30],rs[maxN * 30],siz[maxN * 30],rot;
void init() {
rot = 0;
memset(ls,0,sizeof(ls));
memset(rs,0,sizeof(rs));
memset(siz,0,sizeof(siz));
memset(rt,0,sizeof(rt));
}
void push_up(int p) {siz[p] = max(siz[ls[p]],siz[rs[p]]);}
void update(int &p,int pl,int pr,int v) {
if(!p) p = ++rot;
if(pl == pr) {siz[p]++;return;};
if(v <= mid) update(ls[p],pl,mid,v);
else update(rs[p],mid+1,pr,v);
push_up(p);
}
int query(int p,int pl,int pr) {
if(pl == pr) return pl;
if(siz[ls[p]] >= siz[rs[p]]) return query(ls[p],pl,mid);
else return query(rs[p],mid+1,pr);
}
int merge(int x,int y,int pl,int pr) {
if(!x || !y) return x + y;
if(pl == pr) {
siz[x] += siz[y];
return x;
}
ls[x] = merge(ls[x],ls[y],pl,mid);
rs[x] = merge(rs[x],rs[y],mid+1,pr);
push_up(x);
return x;
}
}
#undef mid
int ans[maxN];
void dfs(int x,int f) {
if(x <= n) sgt::update(rt[x],1,N,co[x]);
fa[x][0] = f;w[x][0] = V[f];
for(int i = 1;i<=20;i++) fa[x][i] = fa[fa[x][i - 1]][i - 1];
for(int i = 1;i<=20;i++) w[x][i] = w[fa[x][i - 1]][i - 1];
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs(y,x);
rt[x] = sgt::merge(rt[x],rt[y],1,N);
}
}
ans[x] = sgt::query(rt[x],1,N);
}
int X,Y,last = 0,popAndPipi;
void solve() {
n = rd(),m = rd();
for(int i = 1;i<=n;i++) co[i] = rd();
init();sgt::init();
for(int i = 1;i<=m;i++)
e[i][1] = rd(),e[i][2] = rd(),e[i][0] = rd();
kruskal();
dfs(tot,0);
putchar('C'),putchar('a'),putchar('s'),putchar('e'),putchar(' '),putchar('#'),wt(++popAndPipi),putchar(':'),putchar('\n');
q = rd();
last = 0;
while(q--) {
X = rd() ^ last,Y = rd() ^ last;
for(int i = 20;i >= 0;i--)
if(w[X][i] <= Y) X = fa[X][i];
wt(last = ans[X]);
putchar('\n');
}
}
signed main() {
T = rd();
while(T--) solve();
return 0;
}
2024/09/14#
CF843D Dynamic Shortest Path#
题面:
题面翻译
有一张 \(n\) 个点 \(m\) 条边的有向带权图,你需要回答如下的 \(q\) 个问题:
1 v询问以 \(1\) 为起点到 \(v\) 的最短路2 c l_1 l_2 ... l_c对于 \(l_1, l_2, \ldots, l_c\) 的边的边权增加 \(1\)。不存在输出
-1。\(1 \leq n, m \leq 10^5\),\(1 \leq q \leq 2000\)。
样例 #1
样例输入 #1
3 2 9 1 2 0 2 3 0 2 1 2 1 3 1 2 2 1 1 1 3 1 2 2 2 1 2 1 3 1 2样例输出 #1
1 0 2 1 4 2样例 #2
样例输入 #2
5 4 9 2 3 1 2 4 1 3 4 1 1 2 0 1 5 1 4 2 1 2 2 1 2 1 4 2 2 1 3 1 4 2 1 4 1 4样例输出 #2
-1 1 2 3 4提示
The description of changes of the graph in the first sample case:
The description of changes of the graph in the second sample case:
很有趣,但很难卡常(可能是我用了array<> 和 queue<>)
我们每次跑一遍最短路肯定行不通,那么只有一种方法,不用每次 迪杰斯特拉 和 Spfa \(\rightarrow\) BFS,将复杂度 \(O(n \log n) \rightarrow O(n)\)
但普通的 BFS 显然不能解决问题,它只能处理边权为 \(1\) 的图
观察数据规模,发现 \(q\) 很小,从 \(q\) 入手
\(q\) 的规模代表一个边的最大 \(\Delta\) 值,那么一条最短路的增量 \(\Delta\) 其实很有限。
因为一共 \(10^5\) 个 点,最短路最多只有 \(10^5 - 1\) 个边,故 \(\Delta_{\max} = 10^5 - 1 + q\)。
读者可以去学习 01-bfs ,我们在这题要用到的思路是 \(桶 + \text{BFS}\)
我们考虑给增量单独建图,先跑一个最短路,记录到 \(dis\)
新图边 \((u,v)\) 的边权就是 \(dis_v - dis_u + w\)。
对于每一次 \(+1\) 我们把对应边的 \(w + 1\)
然后给增量图跑最短路就可以得到新图的最短路增量,将其叠加上原图即是答案。
如何给增量图跑一个 \(O(n)\) 的最短路呢?
我们可以给每个最短路值开一个队列,
因为最短路最大有用增量边权 \(= \Delta_{\max}\),所以开 \(\Delta_{\max}\) 个队列,
因为跑最短路时,每个点的最短路单调更新,当一个最短路值的队列全部更新完了后,这个队列不会有新的点加入
直接指针挪向后一个权值的队列,继续更新,直到指针超过了 \(\Delta_{\max}\),这样就可以轻松实现 \(O ( n )\) 最短路
然后每次操作并将答案覆盖原最短路值。
为什么是正确的呢?
如果没有操作,
一个不在 \(s \rightsquigarrow t\) 边,则 \(w^{\prime} = dis_v - dis_u + w\) ,这时 \(w^{\prime} \not= 0\),
而在最短路上的边 \(w^{\prime} = dis_v - dis_u + w = 0\) 优先走,答案显然正确。
如果有操作,那么我们就有可能走之前可能不优但现在变优的边,这时增量自动就往小的方向走了,答案显然正确。
本人用STL中的 queue 和 array 所以需要卡复杂度。
如果没有使用 STL 但还是没过的人,可以考虑将头文件拆开,只使用必要的头文件。
如果你 \(bfs\) 和 \(dij\) 用 \(q.size()\) 来判断是否进行循环,那么这个时间会大不少!
一定要用 \(q.empty()\) 判断队列非空
如果你像我一样唐,可以考虑用 SPFA 加 SLF、LLL 优化 代替 迪杰斯特拉,在带上一个超级快读
AC-code:
#include <cstdio>
#include <queue>
using namespace std;
using LL = long long;
#define int long long
constexpr int N = 1e5+5,inf = 0x3f3f3f3f3f3f3f3fLL;
char *p1, *p2, buf[N];
#define nc() (p1 == p2 && (p2 = (p1 = buf) +\
fread(buf, 1, N, stdin), p1 == p2) ? EOF : *p1 ++ )
LL rd()
{
LL x = 0, f = 1;
char ch = nc();
while (ch < 48 || ch > 57)
{
if (ch == '-') f = -1;
ch = nc();
}
while (ch >= 48 && ch <= 57)
x = (x << 3) + (x << 1) + (ch ^ 48), ch = nc();
return x * f;
}
char obuf[N], *p3 = obuf;
#define putchar(x) (p3 - obuf < N) ? (*p3 ++ = x) :\
(fwrite(obuf, p3 - obuf, 1, stdout), p3 = obuf, *p3 ++ = x)
inline void wt(LL x)
{
if (!x)
{
putchar('0');
return;
}
LL len = 0, k1 = x, c[40];
if (k1 < 0) k1 = -k1, putchar('-');
while (k1) c[len ++ ] = k1 % 10 ^ 48, k1 /= 10;
while (len -- ) putchar(c[len]);
}
int _min(int x,int y) {return x > y ? y : x;}
int _max(int x,int y) {return x > y ? x : y;}
int d[N],f[N],n,m,Q;
int head[N],nxt[N<<1],to[N<<1],val[N<<1],cnt;
int vis[N],inq[N];
void init() {for(int i = 1;i<=n;i++) head[i] = -1;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
void spfa() {
for(int i = 1;i<=n;i++) d[i] = inf;
d[1] = 0;
deque<int> q;
q.push_front(1);
inq[1] = true;
int sum = d[1];
int num = 1;
while(!q.empty()) {
int t = q.front();
while(d[t]*num>sum){
q.pop_front();
q.emplace_back(t);
t=q.front();
}
q.pop_front();
inq[t] = false;
sum -= d[t];
num--;
for(int i = head[t];~i;i = nxt[i]) {
int y = to[i];
if(d[y] > d[t] + val[i]) {
d[y] = d[t] + val[i];
if(!inq[y]) {
inq[y] = true;
if(!q.empty() && d[q.front()] < d[y]) q.emplace_back(y);
else q.emplace_front(y);
sum += d[y];
num++;
}
}
}
}
}
queue<int> t[N];
int c,maxx;
void bfs() {
for(int i = 1;i<=n;i++) f[i] = inf;
f[1] = 0;
t[0].emplace(1);
maxx = 0;
for(int i = 0;i<=maxx;i++) {
while(!t[i].empty()) {
int x = t[i].front();
t[i].pop();
if(f[x] < i) continue;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i],w = val[i];
int z = d[x] - d[y] + w;
if(f[y] > f[x] + z) {
f[y] = f[x] + z;
if(f[y] <= n - 1){
t[f[y]].emplace(y);
maxx = _max(maxx,f[y]);
}
}
}
}
}
}
void query() {
int v = rd();
if(d[v] == inf) wt(-1),putchar('\n');
else wt(d[v]),putchar('\n');
}
void update() {
c = rd();
for(int i = 1;i<=c;i++) {
int x = rd();
val[x - 1]++;
}
bfs();
for(int i = 1;i<=n;i++) d[i] = _min(inf,d[i] + f[i]);
}
signed main() {
n = rd(),m = rd(),Q = rd();
init();
for(int i = 1;i<=m;i++) {
int u = rd(),v = rd(),w = rd();
add(u,v,w);
}
spfa();
while(Q--) {
int opt = rd();
switch(opt) {
case 1:
query();
break;
case 2:
update();
break;
}
}
fwrite(obuf, p3 - obuf, 1, stdout);
return 0;
}
附上我通过时的图,时间限制为 \(10s\)

2024/09/15#
CF416E President's Path#
题面:
题面翻译
对于 \(n\) 个点 \(m\) 条边的简单无向图(无重边、自环),记 \(f(s,t)\) 为 \(R_{s,t}\) 类边的数量。\(R_{s,t}\) 类边是指这样一类边:存在一条从 \(s\) 到 \(t\) 的最短路,满足这条边在最短路上。
对于每一对 \(s,t\) ,你都要计算出 \(f(s,t)\) 的值。
输入格式
先是 \(n,m(2\le n\le 500,0\le m\le \frac{n(n-1)}{2})\) ,含义见题面。
接下来 \(m\) 行表述边 \((x_i,y_i,l_i)\) ,分别为连接的两个点的编号,边的长度。
输出格式
仅输出一行,包含 \(\frac{n(n-1)}{2}\) 个数。前 \(n-1\) 个数为 \(f(1,2),f(1,3),\dots,f(1,n)\) ;接下来 \(n-2\) 个数为 \(f(2,3),f(2,4),\dots,f(2,n)\) ;以此类推。
样例 #1
样例输入 #1
5 6 1 2 1 2 3 1 3 4 1 4 1 1 2 4 2 4 5 4样例输出 #1
1 4 1 2 1 5 6 1 2 1
观察 \(n\) 的数据范围,自然想到跑 \(floyd\).
我们如果枚举每一条边,判断是否在最短路上,
对于最短路边 \((u,v)\):
时间复杂度是 \(\mathcal{O}(n^4)\) 不能接受.
考虑优化到 \(\mathcal{O}(n^3)\),
枚举点是否在最短路上,
对于最短路点 \(k\):
令 \(dp_{i,j}\) 为 \(i \rightsquigarrow j\) 上最短边的个数,
根据最短路(一条链)的性质,对于 \(i \rightsquigarrow k \rightsquigarrow j\),我们考虑以计算 \((x,k)\) 边的个数,累加到 \(dp_{i,j}\) 。
我们如何计算 \((x,k)\) 呢?
我们将边备份给 \(g_{i,j}\),然后对于 \(i\rightsquigarrow k\) 计算 \(i \rightsquigarrow x \rightarrow k\) 的个数,用:
判断。
然后枚举起点 \(i\),以上述方法更新 \(dp_{i,j}\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
constexpr int N = 505,inf = 0x3f3f3f3f3f3f3f3fLL;
int n,m,f[N][N],g[N][N],dp[N][N],con[N];
signed main() {
n = rd(),m = rd();
for(int i = 1;i<=n;i++)
for(int j = 1;j<=n;j++)
f[i][j] = f[j][i] = g[i][j] = g[j][i] = inf;
for(int i = 1;i<=m;i++) {
int u = rd(),v = rd(),w = rd();
g[u][v] = g[v][u] = f[u][v] = f[v][u] = min(w,f[u][v]);
}
for(int i = 1;i<=n;i++) f[i][i] = 0;
for(int k = 1;k<=n;k++)
for(int i = 1;i<=n;i++)
for(int j = 1;j<=n;j++)
f[j][i] = f[i][j] = min(f[i][j],f[i][k] + f[k][j]);
for(int i = 1;i<=n;i++) {
for(int j = 1;j<=n;j++) con[j] = 0;
for(int j = 1;j<=n;j++)
for(int k = 1;k<=n;k++)
if(f[i][k] + g[k][j] == f[i][j])
con[j]++;
for(int j = 1;j<=n;j++)
for(int k = 1;k<=n;k++)
if(f[i][k] + f[k][j] == f[i][j])
dp[i][j] += con[k];
}
for(int i = 1;i<=n;i++)
for(int j = i + 1;j<=n;j++) {
if(f[i][j] >= inf) dp[i][j] = 0;
wt(dp[i][j]),putchar(' ');
}
return 0;
}
CF986F Oppa Funcan Style Remastered#
题面:
题面翻译
给定 \(n\) 与 \(k\),问是否能将 \(n\) 分为若干个 \(k\) 的因数(\(1\) 除外)之和,每个因数都可以被选多次。
\(n\leq 10^{18}\),\(k\leq 10^{15}\),最多 \(50\) 种不同的 \(k\)。
一共 \(t\) 组询问,\(t\leq 10^4\)。
样例 #1
样例输入 #1
3 7 7 3 8 5 6样例输出 #1
YES NO YES
\(k\) 只有 \(50\) 种,考虑离线一起求解
分解 \(k\),因为 \(k \leq 10^{15}\),所以预处理质因数 \(\sqrt{10^{15}} \approx 3.2 \times 10^7\) 个
分解质因数,分类讨论(因为质因数如果只有 \(1\) 个的话可以直接判断;只有 \(2\) 个的话,因为分解出来很大,不适合跑最短路,可以用同余式直接求解)
-
如果质因数有 \(1\) 个
判断 \([k \mid x]\) 即可 -
如果质因数有 \(2\) 个,设为 \((a,b)\)
那么:
只要找到最小的 \(ax\),和 \(n\) 判断一下就可以了
- 如果质因数有 \(3\) 个以上,那么,我们相当于在求,对于 质因数\((a,b,c,\ldots)\):
是否有 \((x,y,z,\ldots)\) 的可行解。
我们自然想到同余最短路,判断在 \(\operatorname{mod}\ a\) 下与 \(n\) 同余的最小值 \(x\),是否比 \(n\) 大。
这样这题就解决了!
AC-code:
#include<bits/stdc++.h>
using namespace std;
long long rd() {
long long x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
const int N = 1e5+5,M = 3.2e7;
int p[M],top;
bool pr[M];
void init() {
pr[1] = 1;
for(int i = 2;i < M;i++) {
if(!pr[i]) p[++top] = i;
for(int j = 1;j<=top && i * p[j] < M;j++) {
pr[(long long)i * p[j]] = true;
if(i % p[j] == 0) break;
}
}
}
long long a[N];
void dec(long long x,int &t) {
t = 0;
for(int i = 1;i<=top && p[i] * p[i] <= x;i++) {
if(x % p[i] == 0) {
a[++t] = p[i];
while(x % p[i] == 0) x /= p[i];
}
}
if(x > 1) a[++t] = x;
}
long long qpow(long long X,int K,int mod) {
long long re = 1;
X %= mod;
while(K) {
if(K & 1) (re *= X) %= mod;
(X *= X) %= mod;
K >>= 1;
}
return re;
}
long long dis[N],vis[N];
bool ans[N];
map<long long,vector<array<long long,2>>> mp;
void solve(long long k,vector<array<long long,2>> &id) {
int tp = 0;
if(k == 1) return;
dec(k,tp);
if(tp == 1) {
for(array<long long,2> t : id)
ans[t[1]] = t[0] % a[1] ? 0 : 1;
}
else if(tp == 2) {
for(array<long long,2> t : id) {
long long K = t[0] % a[1] * qpow(a[2],a[1] - 2,a[1]) % a[1];
ans[t[1]] = K * a[2] <= t[0];
}
}
else {
memset(dis,0x3f,sizeof(dis));
for(int i = 0;i<=a[1];i++) vis[i] = 0;
dis[0] = 0;
priority_queue<array<long long,2>> q;
q.emplace(array<long long,2>{0,0});
while(!q.empty()) {
long long t = q.top()[1];
q.pop();
if(vis[t]) continue;
vis[t] = true;
for(int i = 2;i<=tp;i++) {
long long y = (long long)((long long)t + (long long)a[i]) % a[1];
if(dis[y] > dis[t] + a[i]) {
dis[y] = dis[t] + a[i];
q.emplace(array<long long,2>{-dis[y],y});
}
}
}
for(auto t : id)
ans[t[1]] = dis[t[0] % a[1]] <= t[0];
}
return;
}
signed main() {
init();
int t = rd();
for(int i = 1;i<=t;i++) {
long long x = rd(),y = rd();
mp[y].emplace_back(array<long long,2>{x,i});
}
for(auto tp : mp) solve(tp.first,tp.second);
for(int i = 1;i<=t;i++)
ans[i] ? puts("YES") : puts("NO");
return 0;
}
2024/09/16#
P3812 【模板】线性基#
题面:
题目描述
给定 \(n\) 个整数(数字可能重复),求在这些数中选取任意个,使得他们的异或和最大。
输入格式
第一行一个数 \(n\),表示元素个数
接下来一行 \(n\) 个数
输出格式
仅一行,表示答案。
样例 #1
样例输入 #1
2 1 1样例输出 #1
1样例 #2
样例输入 #2
4 1 5 9 4样例输出 #2
13提示
$ 1 \leq n \leq 50, 0 \leq S_i < 2 ^ {50} $
异或线性基;
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 55;
int p[63],n;
void greedy(int x) {
for(int i = 50;i>=0;i--) {
if(x >> i & 1) {
if(!p[i]) {
p[i] = x;
break;
}
x ^= p[i];
}
}
}
signed main() {
n = rd();
for(int i = 1;i<=n;i++) {
int x = rd();
greedy(x);
}
int ans = 0;
for(int i = 50;i >= 0;i--)
ans = max(ans,ans ^ p[i]);
wt(ans);
return 0;
}
P4570 [BJWC2011] 元素#
题面:
题目描述
相传,在远古时期,位于西方大陆的 Magic Land 上,人们已经掌握了用魔法矿石炼制法杖的技术。那时人们就认识到,一个法杖的法力取决于使用的矿石。
一般地,矿石越多则法力越强,但物极必反:有时,人们为了获取更强的法力而使用了很多矿石,却在炼制过程中发现魔法矿石全部消失了,从而无法炼制出法杖,这个现象被称为“魔法抵消” 。特别地,如果在炼制过程中使用超过一块同一种矿石,那么一定会发生“魔法抵消”。后来,随着人们认知水平的提高,这个现象得到了很好的解释。经过了大量的实验后,著名法师 Dmitri 发现:如果给现在发现的每一种矿石进行合理的编号(编号为正整数,称为该矿石的元素序号),那么,一个矿石组合会产生“魔法抵消”当且仅当存在一个非空子集,那些矿石的元素序号按位异或起来为零(如果你不清楚什么是异或,请参见下一页的名词解释 )。
例如,使用两个同样的矿石必将发生“魔法抵消”,因为这两种矿石的元素序号相同,异或起来为零。并且人们有了测定魔力的有效途径,已经知道了:合成出来的法杖的魔力等于每一种矿石的法力之和。人们已经测定了现今发现的所有矿石的法力值,并且通过实验推算出每一种矿石的元素序号。
现在,给定你以上的矿石信息,请你来计算一下当时可以炼制出的法杖最多有多大的魔力。
输入格式
第一行包含一个正整数 \(N\),表示矿石的种类数。
接下来 \(N\) 行,每行两个正整数\(\mathrm{Number}_i\) 和 \(\mathrm{Magic}_i\),表示这种矿石的元素序号和魔力值。
输出格式
仅包含一行,一个整数代表最大的魔力值。
样例 #1
样例输入 #1
3 1 10 2 20 3 30样例输出 #1
50提示
样例解释
由于有“魔法抵消”这一事实,每一种矿石最多使用一块。
如果使用全部三种矿石,由于三者的元素序号异或起来:\(1\ \mathrm{xor}\ 2\ \mathrm{xor}\ 3 = 0\) ,则会发生魔法抵消,得不到法杖。
可以发现,最佳方案是选择后两种矿石,法力为 \(20+30=50\)。
数据范围
对于全部的数据:\(1\leq N \leq 1000\),\(1\leq \mathrm{Number}_i \le 10^{18}\),\(1\leq \mathrm{Magic}_i \le 10^4\)。
我们知道贪心法构造的线性基,可以保证线性基里的元素可以异或且异或和最大
这道题可以先从大到小排序,插入进线性基。
为什么最优?我们将每一个数位看作一个坑;每可以插入一个数,相当于填了一个数位的坑。
对于每个数,它的数位决定了它能填哪个坑,如果它能填的坑都已经用价值大的填上了,这个数自然就填不上。
最后将所有数插入线性基,对于每个数位,将数位上填入的价值累加,就是答案。
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 2e3+5;
int n;
array<int,2> p[70],c[N];
void insert(array<int,2> k) {
for(int i = 60;i >= 0;i--) {
if(k[1] >> i & 1) {
if(p[i][1])
k[1] ^= p[i][1];
else {
p[i] = k;
break;
}
}
}
}
signed main() {
n = rd();
for(int i = 1;i<=n;i++)
c[i][1] = rd(),c[i][0] = rd();
for(int i = 0;i<70;i++) p[i][0] = p[i][1] = 0;
sort(c + 1,c + n + 1,[&](array<int,2> a,array<int,2> b){return a[0] > b[0];});
for(int i = 1;i<=n;i++)
insert(c[i]);
int ans = 0;
for(int i = 0;i<=60;i++) ans += p[i][0];
wt(ans);
return 0;
}
CF1100F Ivan and Burgers#
题面:
题面翻译
给一个长为 \(n\) 的序列,\(q\) 次询问,问从 \(a_l,a_{l+1},\cdots,a_r\) 中选若干个数,异或和最大为多少。
\(1\le n,q\le 5\times 10^5\),\(0\le c_i\le 10^6\)。
样例 #1
样例输入 #1
4 7 2 3 4 3 1 4 2 3 1 3样例输出 #1
7 3 7样例 #2
样例输入 #2
5 12 14 23 13 7 15 1 1 1 2 1 3 1 4 1 5 2 2 2 3 2 4 2 5 3 3 3 4 3 5 4 4 4 5 5 5样例输出 #2
12 14 27 27 31 14 25 26 30 23 26 29 13 13 7
区间查询最大异或和(前缀和线性基)
类似于 可持久化线段树,读者可以类比
我们需要记录每个数位被数占领的时间和数值,
我们插入一个数,就建立一个新的版本,其的内容是复制上一个版本(这里是完全赋值,不是可持久化线段树的直接接上),
然后我们考虑插入数,如果有数位可以填入,就填入;如果有的数位填入的时间太早,我们考虑用这个数替换,然后用被替换的数继续做线性基
为什么要替换呢?因为我们记录每个数占领的时间,当我们询问 \((l,r)\) 时,对于版本 \(r\),有效的数需要满足 \(time_{i} \geq l\)。
而这个位置不考虑插入时间时,可能有多个数字可以胜任,但是考虑插入时间后,其中能胜任的只有 \(time_{i} \geq l\),其中最保险的自然是 \(time_{i\max}\)。
如果 \(time_{i\max}\) 都无法胜任,那么 插入时间为 \(r\) 之前的没有数字可以胜任,这样构造的答案一定合法。
大体思路就是这样,结合代码再思考应该就能理解。
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 5e5 + 5;
int p[N][31],pos[N][31],n,m;
void insert(int x,int id) {
for(int i = 0;i<=30;i++) {
p[id][i] = p[id - 1][i];
pos[id][i] = pos[id - 1][i];
}
int P = id;
for(int i = 30;i >= 0;i--) {
if(x >> i & 1) {
// if(!p[id][i]) {
// p[id][i] = x;
// pos[id][i] = P;
// break;
// }
if(pos[id][i] < P)
swap(p[id][i],x),swap(pos[id][i],P);
x ^= p[id][i];
}
}
}
int query(int l,int r) {
int ans = 0;
for(int i = 30;i >= 0;i--) {
if(pos[r][i] >= l)
ans = max(ans,ans ^ p[r][i]);
}
return ans;
}
signed main() {
n = rd();
for(int i = 1;i<=n;i++) {
int x = rd();
insert(x,i);
}
m = rd();
while(m--) {
int l = rd(),r = rd();
wt(query(l,r));putchar('\n');
}
return 0;
}
2024/09/28#
[NOIP2018 提高组] 旅行#
题面:
题目背景
NOIP2018 提高组 D2T1
题目描述
小 Y 是一个爱好旅行的 OIer。她来到 X 国,打算将各个城市都玩一遍。
小 Y 了解到,X 国的 \(n\) 个城市之间有 \(m\) 条双向道路。每条双向道路连接两个城市。 不存在两条连接同一对城市的道路,也不存在一条连接一个城市和它本身的道路。并且, 从任意一个城市出发,通过这些道路都可以到达任意一个其他城市。小 Y 只能通过这些 道路从一个城市前往另一个城市。
小 Y 的旅行方案是这样的:任意选定一个城市作为起点,然后从起点开始,每次可 以选择一条与当前城市相连的道路,走向一个没有去过的城市,或者沿着第一次访问该 城市时经过的道路后退到>上一个城市。当小 Y 回到起点时,她可以选择结束这次旅行或 继续旅行。需要注意的是,小 Y 要求在旅行方案中,每个城市都被访问到。
为了让自己的旅行更有意义,小 Y 决定在每到达一个新的城市(包括起点)时,将 它的编号记录下来。她知道这样会形成一个长度为 \(n\) 的序列。她希望这个序列的字典序 最小,你能帮帮她吗? 对于两个长度均为 \(n\) 的序列 \(A\) 和 \(B\),当且仅当存在一个正整数 \(x\),满足以下条件时, 我们说序列 \(A\) 的字典序小于 \(B\)。
- 对于任意正整数 \(1 ≤ i < x\),序列 \(A\) 的第 \(i\) 个元素 \(A_i\) 和序列 \(B\) 的第 \(i\) 个元素 \(B_i\) 相同。
- 序列 \(A\) 的第 \(x\) 个元素的值小于序列 \(B\) 的第 \(x\) 个元素的值。
输入格式
输入文件共 \(m + 1\) 行。第一行包含两个整数 \(n,m(m ≤ n)\),中间用一个空格分隔。
接下来 m 行,每行包含两个整数 \(u,v (1 ≤ u,v ≤ n)\) ,表示编号为 \(u\) 和 \(v\) 的城市之 间有一条道路,两个整数之间用一个空格分隔。
输出格式
输出文件包含一行,\(n\) 个整数,表示字典序最小的序列。相邻两个整数之间用一个 空格分隔。
样例 #1
样例输入 #1
6 5 1 3 2 3 2 5 3 4 4 6样例输出 #1
1 3 2 5 4 6样例 #2
样例输入 #2
6 6 1 3 2 3 2 5 3 4 4 5 4 6样例输出 #2
1 3 2 4 5 6提示
【数据规模与约定】
对于 \(100\%\) 的数据和所有样例, $1 \le n \le 5000 $ 且 \(m = n − 1\) 或 \(m = n\) 。
对于不同的测试点, 我们约定数据的规模如下:
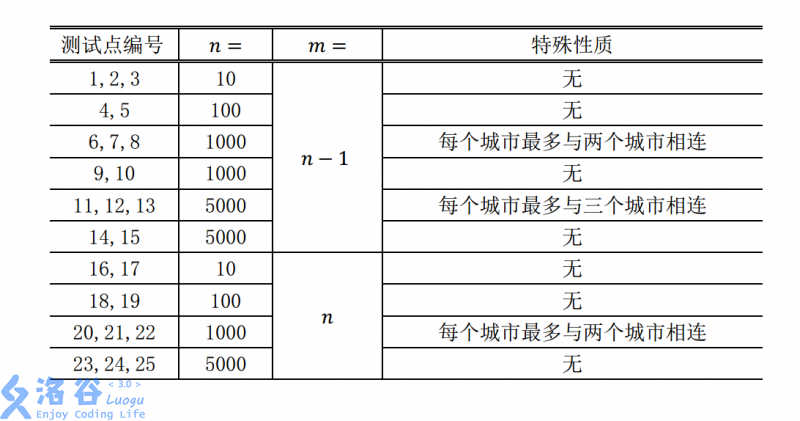
还是那个奇怪的数据范围: \(m = n - 1\) / \(m = n\)
这说明形成的图不是树,就是基环树。
先来考虑树:
如何得到字典序最小的解呢?
不难想到给边排序,让 dfs 每次往最小的节点走,记录 dfs序。
我们不需要在 dfs 的时候考虑这件事,
我们可以在建图的时候通过排序,直接确定走的顺序。
然后是基环树:
和普通的树的唯一区别是:有个环!
我们看到数据范围 \(n \leq 5000\) ,直接暴力断边,可以通过。
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 5e5+5;
int n,m,s[N];
int head[N],nxt[N<<1],to[N<<1],cnt;
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
array<int,2> e[N << 1];
vector<int> ans;
void dfs(int x,int fa) {
ans.emplace_back(x);
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa)
dfs(y,x);
}
}
int dep[N],fa[N],vis[N],son[N],siz[N],top[N],num,id[N];
void dfs1(int x,int f) {
dep[x] = dep[f] + 1;
fa[x] = f;
siz[x] = 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs1(y,x);
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
void dfs2(int x,int topx) {
top[x] = topx;
id[x] = ++num;
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
int cirmax;
void addvis(int u,int v) {
while(u ^ v) {
if(dep[u] < dep[v]) swap(u,v);
vis[u] = true;
cirmax = max(cirmax,u);
u = fa[u];
}
vis[u] = true;
}
int u,v;
signed main() {
// freopen("P5022_20.in","r",stdin);
init();
n = rd(),m = rd();
for(int i = 1;i<=m;i++)
e[i][0] = rd(),e[i][1] = rd();
for(int i = 1;i<=m;i++)
e[i + m][0] = e[i][1],e[i + m][1] = e[i][0];
if(m == n - 1) {
sort(e + 1,e + m + m + 1,[&](array<int,2> x,array<int,2> y) {
if(x[0] == y[0]) return x[1] > y[1];
return x[0] < y[0];
});
for(int i = 1;i<=m + m;i++) add(e[i][0],e[i][1]);
dfs(1,0);
}
else {
auto find = [&](auto self,int x) -> int{
if(s[x] ^ x) s[x] = self(self,s[x]);
return s[x];
};
for(int i = 1;i<=n;i++) s[i] = i;
for(int i = 1;i<=m;i++) {
int fx = find(find,e[i][0]),fy = find(find,e[i][1]);
if(fx ^ fy) s[fx] = fy;
else u = e[i][0],v = e[i][1];
}
for(int i = 1;i<=m + m;i++) {
if((e[i][0] == u && e[i][1] == v) || (e[i][1] == u && e[i][0] == v)) continue;
add(e[i][0],e[i][1]);
}
dfs1(1,0);dfs2(1,1);
addvis(u,v);
init();
sort(e + 1,e + m + m + 1,[&](array<int,2> x,array<int,2> y) {
if(x[0] == y[0]) return x[1] > y[1];
return x[0] < y[0];
});
init();
for(int i = 1;i<=m + m;i++) {
if((e[i][0] == u && e[i][1] == v) || (e[i][1] == u && e[i][0] == v)) continue;
add(e[i][0],e[i][1]);
}
dfs(1,0);
for(int x = n;x>=1;x--) {
if(vis[x] && vis[fa[x]])
u = x,v = fa[x];
else continue;
init();
for(int i = 1;i<=m + m;i++) {
if((e[i][0] == u && e[i][1] == v) || (e[i][1] == u && e[i][0] == v)) continue;
add(e[i][0],e[i][1]);
}
vector<int> ab = ans;
ans.clear();
auto cmp = [&](vector<int> a,vector<int> b) -> bool{
for(int i = 0;i<a.size();i++)
if(a[i] < b[i]) return true;
else if(a[i] > b[i]) return false;
return false;
};
dfs(1,0);
if(cmp(ab,ans)) ans = ab;
}
}
for(int i : ans) wt(i),putchar(' ');
return 0;
}
作者:MingJunYi
出处:https://www.cnblogs.com/WG-MingJunYi/p/18400869
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】