2024.8 - 做题记录与方法总结
2024.8 - Record of Questions and Summary of Methodology
先分享一个歌单:
永无止境的八月!
2024/08/01
先来点重量级的
P4768 [NOI2018] 归程
题面:
[NOI2018] 归程
题目描述
本题的故事发生在魔力之都,在这里我们将为你介绍一些必要的设定。
魔力之都可以抽象成一个 \(n\) 个节点、\(m\) 条边的无向连通图(节点的编号从 \(1\) 至 \(n\))。我们依次用 \(l,a\) 描述一条边的长度、海拔。
作为季风气候的代表城市,魔力之都时常有雨水相伴,因此道路积水总是不可避免的。由于整个城市的排水系统连通,因此有积水的边一定是海拔相对最低的一些边。我们用水位线来描述降雨的程度,它的意义是:所有海拔不超过水位线的边都是有积水的。
Yazid 是一名来自魔力之都的 OIer,刚参加完 ION2018 的他将踏上归程,回到他温暖的家。Yazid 的家恰好在魔力之都的 \(1\) 号节点。对于接下来 \(Q\) 天,每一天 Yazid 都会告诉你他的出发点 \(v\) ,以及当天的水位线 \(p\)。
每一天,Yazid 在出发点都拥有一辆车。这辆车由于一些故障不能经过有积水的边。Yazid 可以在任意节点下车,这样接下来他就可以步行经过有积水的边。但车会被留在他下车的节点并不会再被使用。
需要特殊说明的是,第二天车会被重置,这意味着:
- 车会在新的出发点被准备好。
- Yazid 不能利用之前在某处停放的车。
Yazid 非常讨厌在雨天步行,因此他希望在完成回家这一目标的同时,最小化他步行经过的边的总长度。请你帮助 Yazid 进行计算。
本题的部分测试点将强制在线,具体细节请见【输入格式】和【子任务】。
输入格式
单个测试点中包含多组数据。输入的第一行为一个非负整数 \(T\),表示数据的组数。
接下来依次描述每组数据,对于每组数据:
第一行 \(2\) 个非负整数 \(n,m\),分别表示节点数、边数。
接下来 \(m\) 行,每行 \(4\) 个正整数 \(u, v, l, a\),描述一条连接节点 \(u, v\) 的、长度为 \(l\)、海拔为 \(a\) 的边。
在这里,我们保证 \(1 \leq u,v \leq n\)。接下来一行 \(3\) 个非负数 \(Q, K, S\) ,其中 \(Q\) 表示总天数,\(K \in {0,1}\) 是一个会在下面被用到的系数,\(S\) 表示的是可能的最高水位线。
接下来 \(Q\) 行依次描述每天的状况。每行 \(2\) 个整数 \(v_0, p_0\) 描述一天:
- 这一天的出发节点为 \(v = (v_0 + K \times \mathrm{lastans} - 1) \bmod n + 1\)。
- 这一天的水位线为 \(p = (p_0 + K \times \mathrm{lastans}) \bmod (S + 1)\)。
其中 \(\mathrm{lastans}\) 表示上一天的答案(最小步行总路程)。特别地,我们规定第 \(1\) 天时 \(\mathrm{lastans} = 0\)。
在这里,我们保证 \(1 \leq v_0 \leq n\),\(0 \leq p_0 \leq S\)。对于输入中的每一行,如果该行包含多个数,则用单个空格将它们隔开。
输出格式
依次输出各组数据的答案。对于每组数据:
- 输出 \(Q\) 行每行一个整数,依次表示每天的最小步行总路程。
样例 #1
样例输入 #1
1 4 3 1 2 50 1 2 3 100 2 3 4 50 1 5 0 2 3 0 2 1 4 1 3 1 3 2样例输出 #1
0 50 200 50 150样例 #2
样例输入 #2
1 5 5 1 2 1 2 2 3 1 2 4 3 1 2 5 3 1 2 1 5 2 1 4 1 3 5 1 5 2 2 0 4 0样例输出 #2
0 2 3 1提示
更多样例
更多样例请在附加文件中下载。
样例 3
见附加文件中的
return3.in与return3.ans。该样例满足海拔为一种,且不强制在线。
样例 4
见附加文件中的
return4.in与return4.ans。该样例满足图形态为一条链,且强制在线。
样例 5
见附加文件中的
return5.in与return5.ans。该样例满足不强制在线。
样例 1 解释
第一天没有降水,Yazid 可以坐车直接回到家中。
第二天、第三天、第四天的积水情况相同,均为连接 1,2 号节点的边、连接 3,4 号点的边有积水。
对于第二天,Yazid 从 2 号点出发坐车只能去往 3 号节点,对回家没有帮助。因此 Yazid 只能纯靠徒步回家。
对于第三天,从 4 号节点出发的唯一一条边是有积水的,车也就变得无用了。Yazid 只能纯靠徒步回家。
对于第四天,Yazid 可以坐车先到达 2 号节点,再步行回家。
第五天所有的边都积水了,因此 Yazid 只能纯靠徒步回家。
样例 2 解释
本组数据强制在线。
第一天的答案是 \(0\),因此第二天的 \(v=\left( 5+0-1\right)\bmod 5+1=5\),\(p=\left(2+0\right)\bmod\left(3+1\right)=2\)。
第二天的答案是 \(2\),因此第三天的 \(v=\left( 2+2-1\right)\bmod 5+1=4\),\(p=\left(0+2\right)\bmod\left(3+1\right)=2\)。
第三天的答案是 \(3\),因此第四天的 \(v=\left( 4+3-1\right)\bmod 5+1=2\),\(p=\left(0+3\right)\bmod\left(3+1\right)=3\)。
数据范围与约定
所有测试点均保证 \(T\leq 3\),所有测试点中的所有数据均满足如下限制:
- \(n\leq 2\times 10^5\),\(m\leq 4\times 10^5\),\(Q\leq 4\times 10^5\),\(K\in\left\{0,1\right\}\),\(1\leq S\leq 10^9\)。
- 对于所有边:\(l\leq 10^4\),\(a\leq 10^9\)。
- 任意两点之间都直接或间接通过边相连。
为了方便你快速理解,我们在表格中使用了一些简单易懂的表述。在此,我们对这些内容作形式化的说明:
- 图形态:对于表格中该项为 “一棵树” 或 “一条链” 的测试点,保证 \(m = n-1\)。除此之外,这两类测试点分别满足如下限制:
- 一棵树:保证输入的图是一棵树,即保证边不会构成回路。
- 一条链:保证所有边满足 \(u + 1 = v\)。
- 海拔:对于表格中该项为 “一种” 的测试点,保证对于所有边有 \(a = 1\)。
- 强制在线:对于表格中该项为 “是” 的测试点,保证 \(K = 1\);如果该项为 “否”,则有 \(K = 0\)。
- 对于所有测试点,如果上述对应项为 “不保证”,则对该项内容不作任何保证。
\(n\) \(m\) \(Q=\) 测试点 形态 海拔 强制在线 \(\leq 1\) \(\leq 0\) \(0\) 1 不保证 一种 否 \(\leq 6\) \(\leq 10\) \(10\) 2 不保证 一种 否 \(\leq 50\) \(\leq 150\) \(100\) 3 不保证 一种 否 \(\leq 100\) \(\leq 300\) \(200\) 4 不保证 一种 否 \(\leq 1500\) \(\leq 4000\) \(2000\) 5 不保证 一种 否 \(\leq 200000\) \(\leq 400000\) \(100000\) 6 不保证 一种 否 \(\leq 1500\) \(=n-1\) \(2000\) 7 一条链 不保证 否 \(\leq 1500\) \(=n-1\) \(2000\) 8 一条链 不保证 否 \(\leq 1500\) \(=n-1\) \(2000\) 9 一条链 不保证 否 \(\leq 200000\) \(=n-1\) \(100000\) 10 一棵树 不保证 否 \(\leq 200000\) \(=n-1\) \(100000\) 11 一棵树 不保证 是 \(\leq 200000\) \(\leq 400000\) \(100000\) 12 不保证 不保证 否 \(\leq 200000\) \(\leq 400000\) \(100000\) 13 不保证 不保证 否 \(\leq 200000\) \(\leq 400000\) \(100000\) 14 不保证 不保证 否 \(\leq 1500\) \(\leq 4000\) \(2000\) 15 不保证 不保证 是 \(\leq 1500\) \(\leq 4000\) \(2000\) 16 不保证 不保证 是 \(\leq 200000\) \(\leq 400000\) \(100000\) 17 不保证 不保证 是 \(\leq 200000\) \(\leq 400000\) \(100000\) 18 不保证 不保证 是 \(\leq 200000\) \(\leq 400000\) \(400000\) 19 不保证 不保证 是 \(\leq 200000\) \(\leq 400000\) \(400000\) 20 不保证 不保证 是
kruskal 重构树!
这个东西太 inba 了,在做kruskal的时候建新点,点权为最小/大生成树上的边权
搬自 luogu日报(OI-Wiki)
强大性质:原图中两个点间所有路径上的边最大权值的最小值,最小生成树上两点简单路径的边最大权值 ,Kruskal 重构树上两点 LCA 的点权。
我们模拟这个过程,开车开到离家最近的最远距离,然后找该点离根节点的最近距离
第 \(2\) 步可以先处理,直接对 根节点 跑一个 dij
关键是第 \(1\) 步,跑最大生成树(跑的越远越好),然后建最大生成树的 kruskal 重构树,
然后找最近的能跑的距离,考虑倍增维护 \(O(\log n)\)
最后找能到的离根的最近距离
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 400005,M = 400005;
struct edge{
int head[N<<1],nxt[M<<1],to[M<<1],val[M<<1],cnt;
edge() {memset(head,-1,sizeof(head));}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
}g,G;
struct ED{
int x,y,a;
}E[M];
struct node{
int x,d;
node(int x,int d) : x(x),d(d){}
friend bool operator < (node a,node b) {
return a.d > b.d;
}
};
bool cmp(ED a,ED b) {
return a.a > b.a;
}
int n,m,dis[N<<1],mn[N<<1],fa[N<<1][21],s[N<<1],v[N<<1];
bool vis[N<<1];
void dij() {
memset(vis,0,sizeof(vis));
memset(dis,0x3f,sizeof(dis));
priority_queue<node> q;
q.emplace(node(1,0));
dis[1] = 0;
while(q.size()) {
node t = q.top();
q.pop();
if(vis[t.x]) continue;
vis[t.x] = true;
for(int i = g.head[t.x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(dis[y] > dis[t.x] + g.val[i]) {
dis[y] = dis[t.x] + g.val[i];
q.emplace(node(y,dis[y]));
}
}
}
}
int find(int x) {
if(s[x] ^ x) s[x] = find(s[x]);
return s[x];
}
void dfs(int x,int f) {
fa[x][0] = f;mn[x] = dis[x];
for(int i = 1;i<=20;i++) fa[x][i] = fa[fa[x][i-1]][i-1];
for(int i = G.head[x];~i;i = G.nxt[i]) {
int y = G.to[i];
dfs(y,x);
mn[x] = min(mn[x],mn[y]);
}
}
void kruskalTree(){
sort(E + 1,E + m + 1,cmp);
int now = n;
for(int i = 1;i<=n * 3;i++) s[i] = i;
for(int i = 1;i<=m;i++) {
int fx = find(E[i].x),fy = find(E[i].y);
if(fx ^ fy) {
s[fx] = s[fy] = ++now;
v[now] = E[i].a;
s[now] = now;
G.add(now,fx,1);G.add(now,fy,1);
}
}
dfs(now,0);
}
void solve() {
memset(g.head,-1,sizeof(g.head));
g.cnt = 0;
memset(G.head,-1,sizeof(G.head));
G.cnt = 0;
n = rd(),m = rd();
for(int i = 1;i<=m;i++) {
int x = rd(),y = rd(),l = rd(),a = rd();
E[i].x = x;E[i].y = y;E[i].a = a;
g.add(x,y,l);g.add(y,x,l);
}
dij();
kruskalTree();
int Q = rd(),K = rd(),S = rd();
int last = 0;
while(Q--) {
int V = rd(),p = rd();
V = (V + K * last - 1) % n + 1;
p = (p + K * last) % (S + 1);
for(int i = 20;i>=0;i--)
if(fa[V][i] && v[fa[V][i]] > p)
V = fa[V][i];
wt(last = mn[V]);
putchar('\n');
}
}
signed main() {
int T = rd();
while(T--) solve();
return 0;
}
2024/08/02
CF19D.Points
只能说“学了这么久的C++,才知道”,用普通的lower_bound去二分set中的元素会比用set配套的set.lower_bound(x) 要慢不少
感谢这位iHatetheWorld提供的评论
本题题面:
Points
题面翻译
在一个笛卡尔坐标系中,定义三种操作:
add x y:在坐标系上标记一个点 \((x,y)\),保证 \((x,y)\) 在添加前不在坐标系上。
remove x y:移除点 \((x,y)\),保证 \((x,y)\) 在移除前已在坐标系上。
find x y:找到所有已标记并在 \((x,y)\) 右上方的点中,最左边的点,若点不唯一,选择最下面的一个点; 如果没有符合要求的点,给出-1,否则给出\((x,y)\)。现有 \(n\) 个操作,对于每个 find 操作,输出结果。
\(n \le 2 \times 10^5\),\(0 \le x,y \le 10^9\)。
样例 #1
样例输入 #1
7 add 1 1 add 3 4 find 0 0 remove 1 1 find 0 0 add 1 1 find 0 0样例输出 #1
1 1 3 4 1 1样例 #2
样例输入 #2
13 add 5 5 add 5 6 add 5 7 add 6 5 add 6 6 add 6 7 add 7 5 add 7 6 add 7 7 find 6 6 remove 7 7 find 6 6 find 4 4样例输出 #2
7 7 -1 5 5
对每个 \(x\) 维护一个 \(y\) 的集合,同时记录在该 \(x\) 上的 \(y\) 的最大值
在线段树上二分找到离点最近的,最大值严格大于 \(y\),横坐标严格大于 \(x\) 的 横坐标,然后在这个横坐标维护的 \(y\) 集合中二分(就是这里,不要使用std中的 lower_bound)
用 set.lower_bound(y) 去找严格大于 \(y\) 的点,返回就可
记得离散化 \(x\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
struct FastIO
{
#define get( ) getchar( )
#define put(x) putchar(x)
public:
inline FastIO &operator >>(char &t) { t = get(); return *this; }
inline FastIO &operator >>(char *t) { while((*t = get()) != '\n') *(++t) = '\0'; return *this; }
template <typename type>
inline FastIO &operator >>(type &x) { x = 0; register int sig = 1; register char ch = get();
while (ch < 48 || ch > 57) { if (ch == '-') sig = -1; ch = get(); }
while (ch > 47 && ch < 58) x = (x << 3) + (x << 1) + (ch ^ 48),
ch = get(); x *= sig; return *this; }
template <typename type>
inline FastIO &operator <<(type x) { if (!x) put('0'); if (x < 0) put('-'), x = -x; static char vec[50];
register int len = 0; while (x) vec[len++] = x % 10 + '0', x /= 10;
while (len--) put(vec[len]); return *this; }
template <typename type>
inline FastIO &operator <<(type *t) { for (; *t; t++) put(*t); return *this; }
inline FastIO &operator <<(char t) { put(t); return *this; }
}IO;
int n;
const int N = 2e5+5;
struct Q{
int opt;
int x,y;
}Q[N];
int t[N],top;
namespace sgt{
#define ls (p << 1)
#define rs (ls | 1)
#define mid ((pl + pr) >> 1)
set<int> s[N];
int mx[N<<2];
inline void init() {memset(mx,-1,sizeof(mx));}
inline void push_up(int p) {mx[p] = max(mx[ls],mx[rs]);}
inline void update(int p,int pl,int pr,int k,int d) {
if(pl == pr) {
s[pl].emplace(d);
mx[p] = *s[pl].rbegin();
return;
}
if(k <= mid) update(ls,pl,mid,k,d);
else update(rs,mid+1,pr,k,d);
push_up(p);
}
inline void del(int p,int pl,int pr,int k,int d) {
if(pl == pr) {
s[pl].erase(d);
if(s[pl].size()) mx[p] = *s[pl].rbegin();
else mx[p] = -1;
return;
}
if(k <= mid) del(ls,pl,mid,k,d);
else del(rs,mid+1,pr,k,d);
push_up(p);
}
inline pair<int,int> query(int p,int pl,int pr,int l,int y,int r = top + 1) {
if(pl == pr) return {pl,*s[pl].lower_bound(y)};
if(l <= mid && mx[ls] >= y) {
pair<int,int> a = query(ls,pl,mid,l,y);
if(~a.first) return a;
}
if(r > mid && mx[rs] >= y){
pair<int,int> a = query(rs,mid+1,pr,l,y);
if(~a.first) return a;
}
return {-1,-1};
}
}
signed main() {
sgt::init();
IO>>n;
for(int i = 1;i<=n;i++) {
char k[20];
scanf("%s",k);
IO>>Q[i].x>>Q[i].y;
if(k[0] == 'a') Q[i].opt = 1;
else if(k[0] == 'r') Q[i].opt = 2;
else Q[i].opt = 3;
t[++top] = Q[i].x;
}
sort(t + 1,t + top + 1);
top = unique(t + 1,t + top + 1) - t - 1;
for(int i = 1;i<=n;i++) Q[i].x = lower_bound(t + 1,t + top + 1,Q[i].x) - t;
for(int i = 1;i<=n;i++) {
int opt = Q[i].opt;
if(opt == 1)
sgt::update(1,1,top + 1,Q[i].x,Q[i].y);
else if(opt == 2)
sgt::del(1,1,top + 1,Q[i].x,Q[i].y);
else {
pair<int,int> a = sgt::query(1,1,top + 1,Q[i].x + 1,Q[i].y + 1);
if(~a.first) IO<<(t[a.first])<<' '<<(a.second)<<'\n';
else IO<<(a.first)<<'\n';
}
}
return 0;
}
P3868 [TJOI2009] 猜数字
题面:
[TJOI2009] 猜数字
题目描述
现有两组数字,每组 \(k\) 个。
第一组中的数字分别用 \(a_1,a_2,\cdots ,a_k\) 表示,第二组中的数字分别用 \(b_1,b_2,\cdots ,b_k\) 表示。
其中第二组中的数字是两两互素的。求最小的 \(n\in \mathbb{N}\),满足对于 \(\forall i\in [1,k]\),有 \(b_i | (n-a_i)\)。
输入格式
第一行一个整数 \(k\)。
第二行 \(k\) 个整数,表示:\(a_1,a_2,\cdots ,a_k\)。
第三行 \(k\) 个整数,表示:\(b_1,b_2,\cdots ,b_k\)。
输出格式
输出一行一个整数,为所求的答案 \(n\)。
样例 #1
样例输入 #1
3 1 2 3 2 3 5样例输出 #1
23提示
对于 \(100\%\) 的数据:
\(1\le k \le 10\),\(|a_i|\le 10^9\),\(1\le b_i\le 6\times 10^3\),\(\prod_{i=1}^k b_i\le 10^{18}\)。
每个测试点时限 \(1\) 秒。
注意:对于
C/C++语言,对 \(64\) 位整型数应声明为long long。若使用
scanf,printf函数(以及fscanf,fprintf等),应采用%lld标识符。
CRT板子
直接上 CRT 就好了,不过要用 __int128
#include<bits/stdc++.h>
using namespace std;
#define int __int128
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const signed N = 11;
void exgcd(int a,int b,int &x,int &y) {
if(b == 0) {
x = 1,y = 0;
return;
}
exgcd(b,a % b,y,x);
y -= (a / b) * x;
}
int CRT(int k,int *a,int *r) {
int n = 1,ans = 0;
for(int i = 1;i<=k;i++)
n = n * r[i];
for(int i = 1;i<=k;i++){
int m = n / r[i],b,y;
exgcd(m,r[i],b,y);
ans = (ans + a[i] * m * b % n) % n;
}
return (ans % n + n) % n;
}
int k,a[N],b[N];
signed main() {
k = rd();
for(int i = 1;i<=k;i++) a[i] = rd();
for(int i = 1;i<=k;i++) b[i] = rd();
wt(CRT(k,a,b));
return 0;
}
P1600 [NOIP2016 提高组] 天天爱跑步
题面:
[NOIP2016 提高组] 天天爱跑步
题目背景
NOIP2016 提高组 D1T2
题目描述
小 C 同学认为跑步非常有趣,于是决定制作一款叫做《天天爱跑步》的游戏。《天天爱跑步》是一个养成类游戏,需要玩家每天按时上线,完成打卡任务。
这个游戏的地图可以看作一棵包含 \(n\) 个结点和 \(n-1\) 条边的树,每条边连接两个结点,且任意两个结点存在一条路径互相可达。树上结点编号为从 \(1\) 到 \(n\) 的连续正整数。
现在有 \(m\) 个玩家,第 \(i\) 个玩家的起点为 \(s_i\),终点为 \(t_i\)。每天打卡任务开始时,所有玩家在第 \(0\) 秒同时从自己的起点出发,以每秒跑一条边的速度,不间断地沿着最短路径向着自己的终点跑去,跑到终点后该玩家就算完成了打卡任务。(由于地图是一棵树,所以每个人的路径是唯一的)
小 C 想知道游戏的活跃度,所以在每个结点上都放置了一个观察员。在结点 \(j\) 的观察员会选择在第 \(w_j\) 秒观察玩家,一个玩家能被这个观察员观察到当且仅当该玩家在第 \(w_j\) 秒也正好到达了结点 \(j\)。小 C 想知道每个观察员会观察到多少人?
注意:我们认为一个玩家到达自己的终点后该玩家就会结束游戏,他不能等待一 段时间后再被观察员观察到。 即对于把结点 \(j\) 作为终点的玩家:若他在第 \(w_j\) 秒前到达终点,则在结点 \(j\) 的观察员不能观察到该玩家;若他正好在第 \(w_j\) 秒到达终点,则在结点 \(j\) 的观察员可以观察到这个玩家。
输入格式
第一行有两个整数 \(n\) 和 \(m\)。其中 \(n\) 代表树的结点数量, 同时也是观察员的数量, \(m\) 代表玩家的数量。
接下来 \(n-1\) 行每行两个整数 \(u\) 和 \(v\),表示结点 \(u\) 到结点 \(v\) 有一条边。
接下来一行 \(n\) 个整数,其中第 \(j\) 个整数为 \(w_j\) , 表示结点 \(j\) 出现观察员的时间。
接下来 \(m\) 行,每行两个整数 \(s_i\),和 \(t_i\),表示一个玩家的起点和终点。
对于所有的数据,保证 \(1\leq s_i,t_i\leq n, 0\leq w_j\leq n\)。
输出格式
输出 \(1\) 行 \(n\) 个整数,第 \(j\) 个整数表示结点 \(j\) 的观察员可以观察到多少人。
样例 #1
样例输入 #1
6 3 2 3 1 2 1 4 4 5 4 6 0 2 5 1 2 3 1 5 1 3 2 6样例输出 #1
2 0 0 1 1 1样例 #2
样例输入 #2
5 3 1 2 2 3 2 4 1 5 0 1 0 3 0 3 1 1 4 5 5样例输出 #2
1 2 1 0 1提示
样例 1 说明
对于 \(1\) 号点,\(w_i=0\),故只有起点为 \(1\) 号点的玩家才会被观察到,所以玩家 \(1\) 和玩家 \(2\) 被观察到,共有 \(2\) 人被观察到。
对于 \(2\) 号点,没有玩家在第 \(2\) 秒时在此结点,共 \(0\) 人被观察到。
对于 \(3\) 号点,没有玩家在第 \(5\) 秒时在此结点,共 \(0\) 人被观察到。
对于 \(4\) 号点,玩家 \(1\) 被观察到,共 \(1\) 人被观察到。
对于 \(5\) 号点,玩家 \(1\) 被观察到,共 \(1\) 人被观察到。
对于 \(6\) 号点,玩家 \(3\) 被观察到,共 \(1\) 人被观察到。
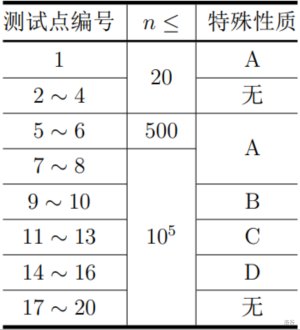
子任务
每个测试点的数据规模及特点如下表所示。
提示:数据范围的个位上的数字可以帮助判断是哪一种数据类型。
测试点编号 \(n=\) \(m=\) 约定 \(1\sim 2\) \(991\) \(991\) 所有人的起点等于自己的终点,即 \(\forall i,\ s_i=t_i\) \(3\sim 4\) \(992\) \(992\) 所有 \(w_j=0\) \(5\) \(993\) \(993\) 无 \(6\sim 8\) \(99994\) \(99994\) \(\forall i\in[1,n-1]\),\(i\) 与 \(i+1\) 有边。即树退化成 \(1,2,\dots,n\) 按顺序连接的链 \(9\sim 12\) \(99995\) \(99995\) 所有 \(s_i=1\) \(13\sim 16\) \(99996\) \(99996\) 所有 \(t_i=1\) \(17\sim 19\) \(99997\) \(99997\) 无 \(20\) \(299998\) \(299998\) 无 提示
(提示:由于原提示年代久远,不一定能完全反映现在的情况,现在已经对该提示做出了一定的修改,提示的原文可以在该剪贴板查看)
在最终评测时,调用栈占用的空间大小不会有单独的限制,但在我们的工作环境中默认会有 \(1 \text{MiB}\) 的限制。 这可能会引起函数调用层数较多时,程序发生栈溢出崩溃,程序中较深层数的递归往往会导致这个问题。如果你的程序需要用到较大的栈空间,请务必注意该问题。
我们可以使用一些方法修改调用栈的大小限制。
- Linux
我们可以在终端中输入下列命令:
ulimit -s 1048576。此命令的意义是,将调用栈的大小限制修改为 \(1048576\text{KiB}=1 \text{GiB}\)。例如,对于如下程序
sample.cpp:#include <bits/stdc++.h> using namespace std; int f[1000005]; void dfs(int a){ if(a == 0){ f[a] = 0; return; } dfs(a - 1); f[a] = f[a - 1] + 1; } int main(){ dfs(1000000); return 0; }将上述源代码用命令
g++ sample.cpp -o sample编译为可执行文件sample后,使用./sample执行程序。如果在没有使用命令
ulimit -s 1048576的情况下运行该程序,sample会因为栈溢出而崩溃;如果使用了上述命令后运行该程序,该程序则不会崩溃。特别地,当你打开多个终端时,它们并不会共享该命令,你需要分别对它们运行该命令。
请注意,调用栈占用的空间会计入总空间占用中,和程序其他部分占用的内存共同受到内存限制。
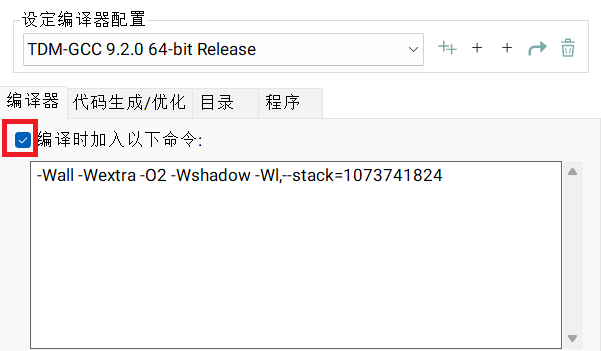
- Windows
如果你使用 Windows 下的 Dev-C++,请选择
工具-编译选项并在如下区域填入以下命令-Wl,--stack=1073741824,填入后注意确认“编译时加入以下命令的”的框是已勾选状态。此处
1073741824的单位是 \(\text{B/Bytes}\)。

线段树合并
这个博主的这个博客写的太好了,我就不写了(肯定不是我懒)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
inline int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
inline void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 300000;
int head[N],nxt[N<<1],to[N<<1],cnt;
inline void init() {memset(head,-1,sizeof(head));}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
int fa[N],son[N],siz[N],dep[N],id[N],top[N],num;
void dfs1(int x,int f) {
fa[x] = f;
dep[x] = dep[f] + 1;
siz[x] = 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs1(y,x);
siz[x] += siz[y];
if(siz[son[x]] < siz[y] ) son[x] = y;
}
}
}
void dfs2(int x,int topx) {
top[x] = topx;
id[x] = ++num;
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
int lca(int x,int y) {
while(top[x] != top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x,y);
x = fa[top[x]];
}
return dep[x] < dep[y] ? x : y;
}
int n,m;
namespace sgt{
int root[N<<1],L[N*55],R[N*55],v[N*55],num;
#define ls (L[p])
#define rs (R[p])
#define mid ((pl + pr) >> 1)
void update(int &p,int pl,int pr,int d,int V) {
if(!p) p = ++num;
if(pl == pr) {
v[p] += V;
return;
}
if(d <= mid) update(ls,pl,mid,d,V);
else update(rs,mid+1,pr,d,V);
}
int query(int p,int pl,int pr,int d) {
if(!p) return 0;
if(pl == pr) return v[p];
if(d <= mid) return query(ls,pl,mid,d);
else return query(rs,mid+1,pr,d);
}
int merge(int x,int y,int pl,int pr) {
if(!x || !y) return x + y;
if(pl == pr) v[x] += v[y];
else {
L[x] = merge(L[x],L[y],pl,mid);
R[x] = merge(R[x],R[y],mid+1,pr);
}
return x;
}
}
int w[N],ans[N];
inline void dfs(int x) {
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x]) {
dfs(y);
sgt::root[x] = sgt::merge(sgt::root[x],sgt::root[y],1,n<<1);
}
}
if(w[x] && n + dep[x] + w[x] <= n * 2)
ans[x] += sgt::query(sgt::root[x],1,n<<1,n + dep[x] + w[x]);
ans[x] += sgt::query(sgt::root[x],1,n<<1,n + dep[x] - w[x]);
}
signed main() {
init();
n = rd(),m = rd();
for(int i = 1;i<n;i++) {
int u = rd(),v = rd();
add(u,v);add(v,u);
}
dfs1(1,0);
dfs2(1,1);
for(int i = 1;i<=n;i++) w[i] = rd();
for(int i = 1;i<=m;i++) {
int x = rd(),y = rd();
int LCA = lca(x,y);
sgt::update(sgt::root[x],1,n<<1,n + dep[x],1);
sgt::update(sgt::root[y],1,n<<1,n + dep[LCA] * 2 - dep[x],1);
sgt::update(sgt::root[LCA],1,n<<1,n + dep[x],-1);
sgt::update(sgt::root[fa[LCA]],1,n<<1,n + dep[LCA] * 2 - dep[x],-1);
}
dfs(1);
for(int i = 1;i<=n;i++) wt(ans[i]),putchar(' ');
return 0;
}
2024/08/03
今天确实适合重构代码,重构完就知道哪里错了
2024-8-3_mx模拟赛
C. 树差
题目描述
输入格式
输出格式
样例
数据范围与提示
老师说的好,遇到奇怪的式子不要慌,说明这题非常好做,让出题人只能用奇怪式子迷惑你
遇到式子,第一步肯定是拆式子
所以
那么,我们把 \(d\) 带回去,再观察一下式子
因为我们是单点查询,我们在查 \(y\) 时,可以在求解时人为加上,不需要进入数据结构
那么我们就对每个点分类加上 \(x\) 带来的贡献
也就是维护 \((-1)^{\operatorname{dep}_x}a\) 、 \((-1)^{\operatorname{dep}_x}b\)、\(- (-1)^{\operatorname{dep}_x}b\operatorname{dep}_x\) 这三个值
考虑开 \(3\) 个线段树维护
最有迷惑性的就是 \(\operatorname{opt}_3\),撤销?
撤销不过就是反向 \(\operatorname{opt}_1\)
操作一共就 \(10^5\) 次,最坏就 \(25000\) 次撤销,干脆直接暴力 \(O(m)\) 撤销
如何找到需要撤销的点呢?
考虑 \(\operatorname{set}\) 维护每个点的新编号(即 \(\operatorname{dfn}\) 序)
然后二分找到在子树内 \(\operatorname{dfn}\) 最小的需要修改的点,暴力修改,删除,直到 \(\operatorname{dfn}_i\) 的值大于等于 \(\operatorname{dfn_x} + \operatorname{siz}_x - 1\) (不在子树内了)
此题就是这样 \(O(m\log n + n \log n)\) 解决了:
上 AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int mod = 1e9 + 7,N = 2e5+5;
int head[N],nxt[N<<1],to[N<<1],cnt;
void init() {memset(head,-1,sizeof(head));}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
int n,m;
set<int> s;
int fa[N],son[N],siz[N],top[N],id[N],dep[N],num,_id[N];
void dfs1(int x) {
siz[x] = 1;
dep[x] = dep[fa[x]] + 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x]) {
dfs1(y);
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
void dfs2(int x,int topx) {
top[x] = topx;
id[x] = ++num;
_id[num] = x;
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
int f(int x) {return (x & 1) ? -1 : 1;}
struct sgt{
#define ls (p << 1)
#define rs (ls | 1)
#define mid ((pl + pr) >> 1)
int t[N<<2],tag[N<<2];
void push_up(int p) {t[p] = (t[ls] + t[rs] + mod) % mod;}
void addtag(int p,int pl,int pr,int d) {
tag[p] = (tag[p] + d);
t[p] = (t[p] + (pr - pl + 1) * d);
tag[p] %= mod;
t[p] %= mod;
}
void push_down(int p,int pl,int pr) {
if(tag[p]) {
addtag(ls,pl,mid,tag[p]);
addtag(rs,mid+1,pr,tag[p]);
tag[p] = 0;
}
}
void update(int p,int pl,int pr,int l,int r,int d) {
if(l <= pl && pr <= r) {addtag(p,pl,pr,d);return;}
push_down(p,pl,pr);
if(l <= mid) update(ls,pl,mid,l,r,d);
if(r > mid) update(rs,mid+1,pr,l,r,d);
push_up(p);
}
int query(int p,int pl,int pr,int k) {
if(pl == pr) return t[p];
push_down(p,pl,pr);
if(k <= mid) return query(ls,pl,mid,k);
else return query(rs,mid+1,pr,k);
}
}A,B,C;
int ra[N],rb[N];
void add() {
int x = rd(),a = rd(),b = rd();
ra[id[x]] = ra[id[x]] + a,rb[id[x]] = rb[id[x]] + b;
A.update(1,1,n,id[x],id[x] + siz[x] - 1,f(dep[x]) * a);
B.update(1,1,n,id[x],id[x] + siz[x] - 1,f(dep[x]) * b);
C.update(1,1,n,id[x],id[x] + siz[x] - 1,-1 * f(dep[x]) * b * dep[x]);
s.emplace(id[x]);
}
void query() {
int x = rd();
int ans = 0;
ans = (ans + A.query(1,1,n,id[x]) + mod) % mod;
ans = (ans + (B.query(1,1,n,id[x]) * dep[x] + mod) % mod + mod) % mod;
ans = (ans + C.query(1,1,n,id[x]) + mod) % mod;
ans = (ans * f(dep[x]) + mod) % mod;
wt(ans),putchar('\n');
}
void remove() {
int x = rd();
auto it = s.lower_bound(id[x]);
while(it != s.end() && (*it < id[x] + siz[x])){
int a = -ra[*it],b = -rb[*it];
ra[*it] = rb[*it] = 0;
A.update(1,1,n,*it,*it + siz[_id[*it]] - 1,f(dep[_id[*it]]) * a);
B.update(1,1,n,*it,*it + siz[_id[*it]] - 1,f(dep[_id[*it]]) * b);
C.update(1,1,n,*it,*it + siz[_id[*it]] - 1,-1 * f(dep[_id[*it]]) * b * dep[_id[*it]]);
it = s.erase(it);
if(it == s.end()) break;
}
}
signed main() {
init();
n = rd(),m = rd();
for(int i = 2;i<=n;i++) {
fa[i] = rd();
add(i,fa[i]);
add(fa[i],i);
}
dfs1(1);dfs2(1,1);
while(m--) {
int opt = rd();
switch(opt) {
case 1:
add();
break;
case 2:
query();
break;
case 3:
remove();
break;
}
}
return 0;
}
2024/08/07
mx模拟赛
A.简单移动
题目描述
输入格式
输出格式
样例
数据范围与提示
首先不难发现的是,只要字母出现次数对的上,我们必然有一种方法重排(就是假设全部重来,把所有字母都按顺序放到一个空字符串中)
什么样的字母不需要重排呢?
我们发现,我们每拿一个字符,就有一坨字符从前面掉到后面,那么我们就可以通过这个过程来省事
那么我们用双指针,对 \(B\) 的后缀和 \(A\) 的从后往前的子序列 进行最大匹配,就可以求出不用动的字符数
最后用长度一减就完成了
\(O(n)\)
Ac-code:
#include<bits/stdc++.h>
using namespace std;
string a,b;
int t[30];
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
freopen("move.in","r",stdin);
freopen("move.out","w",stdout);
cin>>a>>b;
if(a.size() != b.size()) {puts("-1");return 0;}
for(int i = 0;i<a.size();i++) t[a[i] - 'A']++;
for(int i = 0;i<b.size();i++) t[b[i] - 'A']--;
int len = a.size();
for(int i = 0;i<30;i++) if(t[i]) {puts("-1");return 0;}
int i = len - 1,j = len - 1,ans = 0;
for(;i >= 0 && j >= 0;i--)
if(a[i] == b[j])
j--,ans++;
cout<<len - ans;
return 0;
}
B.星天花雨
题目描述
输入格式
输出格式
样例
数据范围与提示
这个奇怪的描述矩形的方式,一看就很奇怪,非常值得关注
这些 \(1,0\) 直接决定了一行,或一列的情况
我们再来考察 \(1\) 的分布
只有当 \(a_{line},b_{col}\)都是 \(1\),这个位置才是 \(1\)
稍微画画图就知道,对于一个矩形有多少个 \(1\),取决于 \(a\) 区间 \(1\) 的个数 \(\times\) \(b\) 区间 \(1\) 的个数
那么,我们只需要知道有多少 \(a,b\) 中 \(1\) 个数为 \(i\) 的区间数,相乘即可
那么,对于 \(A_i \times B_j = k\),\(A_i,B_j \in Z\),
我们可以处理出每一个含 \(1\) 个数的区间数量,放在桶里
\(O(n^2)\) 可以过 \(80\) 分的点
显然这个地方可以优化————直接针对可能成为答案的区间,并用 \(O(n\phi(n))\) 求出来
什么样的可以成为答案?显然是 \(k\) 的因子
那么我们直接试除法,把每一个因子记录下来
最后针对每一个因子,求包含这么多 \(1\) 的区间
(这里不知道写没写唐,我是出来每一个 \(1\) 的 前缀 \(0\) 个数 + 1、后缀 \(0\) + 1,然后对区间 \(1\) 相乘)
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5,mod = 998244353;
int fa[N],fb[N],p[N],top = -1,tp,nxt[N],lst[N];
signed main() {
freopen("rain.in","r",stdin);
freopen("rain.out","w",stdout);
int n = rd(),m = rd(),k = rd();
vector<int> a(n + 1),b(m + 1);
for(int i = 1;i<=n;i++) a[i] = rd();
for(int i = 1;i<=m;i++) b[i] = rd();
for(int i = 1;i * i <= k;i++) {
if(k % i == 0) {
int j = k / i;
p[++top] = i;
if(i ^ j) p[++top] = j;
}
}
for(int i = 1;i<=n;i++) {
int j = i + 1;
if(a[i]) nxt[++tp] = 1;
if(a[i] && !a[j]){
while(!a[j] && j <= n) j++;
nxt[tp] = j - i;
i = j - 1;
}
}
int T = 0;
for(int i = 1;i<=n;i++) {
int j = i - 1;
if(a[i]) lst[++T] = 1;
if(a[i] && !a[j]) {
while(!a[j] && j >= 1) j--;
lst[T] = i - j;
i = nxt[T] + i - 1;
}
}
for(int i = 0;i<= top;i++) {
for(int j = 1;j<=tp - p[i] + 1;j++) {
int w = j + p[i] - 1;
fa[i] = (fa[i] + lst[j] * nxt[w] % mod) % mod;
}
}
tp = 0;
for(int i = 1;i<=m;i++) {
int j = i + 1;
if(b[i]) nxt[++tp] = 1;
if(b[i] && !b[j]){
while(!b[j] && j <= m) j++;
nxt[tp] = j - i;
i = j - 1;
}
}
T = 0;
for(int i = 1;i<=m;i++) {
int j = i - 1;
if(b[i]) lst[++T] = 1;
if(b[i] && !b[j]) {
while(!b[j] && j >= 1) j--;
lst[T] = i - j;
i = nxt[T] + i - 1;
}
}
for(int i = 0;i<= top;i++) {
for(int j = 1;j<=tp - p[i] + 1;j++) {
int w = j + p[i] - 1;
fb[i] = (fb[i] + lst[j] * nxt[w] % mod) % mod;
}
}
int ans = 0;
for(int i = 0;i<=top;i += 2) {
if(i == top) ans = (ans + fa[i] * fb[i] % mod) % mod;
else {
ans = (ans + fa[i] * fb[i ^ 1] % mod) % mod;
ans = (ans + fa[i ^ 1] * fb[i] % mod) % mod;
}
}
wt(ans % mod);
return 0;
}
C. 野火
题目描述
输入格式
输出格式
样例
数据范围与提示
首先 \(m \leq n\),一上来我还以为我眼花了,这个图还要联通
不是树,就是基环树。
我们以防万一先判断连通性,如果不连通,谈都不用谈,直接输出 \(0\)
然后讨论一下
\(\textcircled{1}\) 树
最简单的,因为根本没得替补,每条边必须上
那么,我们考虑直接二分答案,去找一找如何补缺口使得每条边能撑过 \(mid\)
code:
// C[i] 是边 、C[i].d 是边的边权
int check(int lim) {
int res = 0;
for(int i = 1;i<=top;i++)
if(C[i].d < lim)
res += lim - C[i].d;
return res;
}
......
if(m == n - 1) {
int l = 1,r = 3e9 + 5;
while(l < r - 1) {
int mid = (l + r) >> 1;
if(check(mid) <= L) l = mid;
else r = mid;
}
wt(l);
putchar('\n');
}
\(\textcircled{2}\) 基环树
Q:那么区别在哪呢?
A:环嘛!
Q:那么这个环带来了什么影响呢?
A:这个环的一个边挂掉了后,未响应边能替补上去!
Q:那么替补完后会怎么样呢?
A:另一条边挂掉了,彻底完蛋了!
Q:那么这个环上哪条边会最先挂掉呢?
A:边权最小的地方嘛!
那么,这个替补的操作可以视为 在最小边的边权加上这个替补边的边权,以延长它的寿命
这个替补就是逊了,我们跑一个kruskal求一个最大生成树,留下来的边自然就是替补边
然后我们以替补边的两个端点(肯定在环内),跑一下环(即两点之间的路径)记录一下最小边
因为我们对被加的边是哪一条边没有兴趣,我们只要找到在役边中边权与最小边边权匹配的边,加上这个替补边的边权,就可以和树一样做了
(这个思路还是很自然的,考场没花什么时间,主要是T2细节花了不少时间,还重构了一边)
code:
//vis[] 数组在之前的kruskal中求出了(标记在役边)
if(m == n) {
init_edge();
for(int i = 1;i<=m;i++)
if(vis[i])
add(E[i].v,E[i].u,E[i].d),add(E[i].u,E[i].v,E[i].d); //对在役边建树
dfs1(1,0);
int addition = 0;
for(int i = 1;i<=m;i++)
if(!vis[i])
dfs(E[i].v,E[i].u),addition = E[i].d; // 找替补边
for(int i = 1;i<=top;i++)
if(C[i].d == mn){
C[i].d = mn + addition; //对最小边权匹配的边加上替补边边权
break;
}
int l = 1,r = 3e9 + 5;
while(l < r - 1) {
int mid = (l + r) >> 1;
if(check(mid) <= L) l = mid;
else r = mid;
}
wt(l);
putchar('\n');
}
本题最大坑点:
二分上限是 \(3e9\),我们考虑这样一个情景: 两个点形成了基环,边权都是讨厌的 \(1e9\),你还要加上一个 \(1e9\) 的逆天 \(L\)
害我痛失 44 分
本代码复杂度:\(O(n + m\log V)\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N =2e5+5;
struct edge{
int u,v,d;
friend bool operator < (const edge &a,const edge &b) {
return a.d > b.d;
}
}E[N],C[N];
int s[N],top,n,m,L;
bool vis[N];
void init() {
for(int i = 0;i<=n;i++) s[i] = i;
for(int i = 0;i<=m;i++) vis[i] = false;
}
int find(int x) {if(s[x] ^ x) s[x] = find(s[x]);return s[x];}
void kruskal() {
top = 0;
init();
sort(E + 1,E + m + 1);
int fx,fy,minn = INT_MAX;
for(int i = 1;i<=m;i++) {
fx = find(E[i].v),fy = find(E[i].u);
if(fx == fy) continue;
s[fx] = fy;
vis[i] = true;
C[++top] = E[i];
if(top == n - 1) break;
}
}
int check(int lim) {
int res = 0;
for(int i = 1;i<=top;i++)
if(C[i].d < lim)
res += lim - C[i].d;
return res;
}
int head[N],nxt[N<<1],to[N<<1],val[N<<1],cnt;
void init_edge() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
int fa[N],tp[N],siz[N],son[N],dep[N];
void dfs1(int x,int f) {
dep[x] = dep[f] + 1;
fa[x] = f;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f)
dfs1(y,x);
}
}
int mn = INT_MAX;
void dfs(int x,int y) {
while(x != y) {
if(dep[x] < dep[y]) swap(x,y);
for(int i = head[x];~i;i = nxt[i]) {
int z = to[i];
if(z == fa[x])
mn = min(mn,val[i]);
}
x = fa[x];
}
}
void solve() {
mn = INT_MAX;
n = rd(),m = rd(),L = rd();
for(int i = 1;i<=m;i++)
E[i].u = rd(),E[i].v = rd(),E[i].d = rd();
kruskal();
if(top != n - 1) {puts("0");return;}
if(m == n - 1) {
int l = 1,r = 3e9 + 5;
while(l < r - 1) {
int mid = (l + r) >> 1;
if(check(mid) <= L) l = mid;
else r = mid;
}
wt(l);
putchar('\n');
}else if(m == n) {
init_edge();
for(int i = 1;i<=m;i++)
if(vis[i])
add(E[i].v,E[i].u,E[i].d),add(E[i].u,E[i].v,E[i].d);
dfs1(1,0);
int addition = 0;
for(int i = 1;i<=m;i++)
if(!vis[i])
dfs(E[i].v,E[i].u),addition = E[i].d;
for(int i = 1;i<=top;i++)
if(C[i].d == mn){
C[i].d = mn + addition;
break;
}
int l = 1,r = 3e9 + 5;
while(l < r - 1) {
int mid = (l + r) >> 1;
if(check(mid) <= L) l = mid;
else r = mid;
}
wt(l);
putchar('\n');
}
}
signed main() {
freopen("wildfire.in","r",stdin);
freopen("wildfire.out","w",stdout);
int id = rd(),T = rd();
while(T--) solve();
return 0;
}
2024/08/08
P1084 [NOIP2012 提高组] 疫情控制
题面:
[NOIP2012 提高组] 疫情控制
题目描述
H 国有 \(n\)个城市,这 \(n\) 个城市用\(n-1\)条双向道路相互连通构成一棵树,\(1\)号城市是首都,也是树中的根节点。
H 国的首都爆发了一种危害性极高的传染病。当局为了控制疫情,不让疫情扩散到边境城市(叶子节点所表示的城市),决定动用军队在一些城市建立检查点,使得从首都到边境城市的每一条路径上都至少有一个检查点,边境城市也可以建立检查点。但特别要注意的是,首都是不能建立检查点的。
现在,在 H 国的一些城市中已经驻扎有军队,且一个城市可以驻扎多个军队。一支军队可以在有道路连接的城市间移动,并在除首都以外的任意一个城市建立检查点,且只能在一个城市建立检查点。一支军队经过一条道路从一个城市移动到另一个城市所需要的时间等于道路的长度(单位:小时)。
请问最少需要多少个小时才能控制疫情。注意:不同的军队可以同时移动。
输入格式
第一行一个整数\(n\),表示城市个数。
接下来的 \(n-1\) 行,每行\(3\)个整数,\(u,v,w\),每两个整数之间用一个空格隔开,表示从城市 \(u\)到城市\(v\) 有一条长为 \(w\) 的道路。数据保证输入的是一棵树,且根节点编号为 \(1\)。
接下来一行一个整数 \(m\),表示军队个数。
接下来一行 \(m\)个整数,每两个整数之间用一个空格隔开,分别表示这 \(m\) 个军队所驻扎的城市的编号。
输出格式
一个整数,表示控制疫情所需要的最少时间。如果无法控制疫情则输出 \(-1\)。
样例 #1
样例输入 #1
4 1 2 1 1 3 2 3 4 3 2 2 2样例输出 #1
3提示
【输入输出样例说明】
第一支军队在 \(2\) 号点设立检查点,第二支军队从 \(2\) 号点移动到$ 3$ 号点设立检查点,所需时间为 \(3\) 个小时。
【数据范围】
保证军队不会驻扎在首都。
- 对于 \(20\%\) 的数据,\(2 \le n\le 10\);
- 对于 \(40\%\) 的数据,\(2 \le n\le 50\),\(0<w <10^5\);
- 对于 \(60\%\) 的数据,\(2 \le n\le 1000\),\(0<w <10^6\);
- 对于 \(80\%\) 的数据,\(2 \le n\le 10^5\);
- 对于 \(100\%\) 的数据,\(2\le m\le n≤ 5\times 10^5\),\(0<w <10^9\)。
NOIP 2012 提高组 第二天 第三题
除了细节多,其实理解起来不算难
我们很容易就可以想到,每个军队(仅限不在根节点的)肯定会往上走,往下走肯定不优(控制的节点大幅度减少)
看到这种 求“最少”,不用想都是二分,我们二分这个时间限制,看一看能不能控制住整个树
这就是整个题的难点("\(check\) desu")
我们要快速求出每个军队能跑的最浅节点,自然考虑倍增维护 \(k\) 级父亲和花费
但是军队不能直接到根节点,因为我们要看一看,军队去不去根节点(如果去了,原来的子树可能就没得人了)
对于没有实力到根节点的军队,我们让他们就地驻扎;有实力的军队,我们把它们的剩余时间和来自哪个子树先扔进 选拔集合 里,
现在根的每个子树中已经驻扎的军队都已经标记上了,我们看一看根的每个子树有没有人守的,打上NeedHelp标记
什么样的有实力的军队不能到根节点呢?
如果这个军队跑到根节点,子树没人守了,他却回不去了,肯定是不优的
为什么呢?
对于一个不可以回子树的军队
如果他不跑到根节点,就可以守下这个子树,
如果他跑到根节点,那么必须有一个人帮他守(这个人的剩余价值肯定比他大),然而如果他不跑的话,相当于用一个剩余价值非常小的军队顶上:
那么对于这样的军队,我们让它们 洗洗睡,不要来根节点,同时取消掉这个子树的 NeedHelp 标记
剩下的用排序双指针去跑一个匹配,让实力相匹配的匹配上
最后如果有边匹配不上,那么就需要加大时限,否则就加紧时限
AC-code:
#include <bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-')
w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
long long rdLL() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-')
w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(long long x) {
static int sta[35];
int f = 1;
if (x < 0)
f = -1, x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if (f == -1)
putchar('-');
while (top)
putchar(sta[--top] + 48);
}
const int N = 3e5 + 5;
int head[N], nxt[N << 1], to[N << 1];
long long val[N << 1], cnt = 0;
void init() {
memset(head, -1, sizeof(head));
cnt = 0;
}
void add(int u, int v, long long w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
int fa[20][N];
long long dis[20][N];
void dfs(int x, int f) {
for (int i = head[x]; ~i; i = nxt[i]) {
int y = to[i], w = val[i];
if (y ^ f) {
dis[0][y] = w;
fa[0][y] = x;
for (int j = 1; j <= 19; j++) {
fa[j][y] = fa[j - 1][fa[j - 1][y]];
dis[j][y] = dis[j - 1][fa[j - 1][y]] + dis[j - 1][y];
}
dfs(y, x);
}
}
}
int t[N], n, m, w[N], rest[N], from[N];
bool vis[N], help[N];
vector<array<long long, 2>> root;
vector<long long> tim, csum;
bool state(int x) {
if (vis[x])
return true;
bool block = true, leaf = true;
for (int i = head[x]; ~i; i = nxt[i]) {
int y = to[i];
if (y ^ fa[0][x]) {
leaf = false;
if (!state(y))
return false;
}
}
if (leaf)
return false;
return block;
}
bool check(long long lim) {
tim.clear();
csum.clear();
root.clear();
memset(vis, 0, sizeof(vis));
memset(help, 0, sizeof(help));
for (int i = 1; i <= m; i++)
w[i] = t[i];
for (int i = 1; i <= m; i++) {
long long k = lim;
for (int j = 19; j >= 0; j--)
if (dis[j][w[i]] <= k && fa[j][w[i]] > 1)
k -= dis[j][w[i]], w[i] = fa[j][w[i]];
if (fa[0][w[i]] == 1 && k >= dis[0][w[i]])
root.emplace_back(array<long long, 2> {w[i], k - dis[0][w[i]]});
else
vis[w[i]] = true;
}
for (int i = head[1]; ~i; i = nxt[i])
if (!state(to[i]))
help[to[i]] = true;
sort(root.begin(), root.end(), [&](array<long long, 2> a, array<long long, 2> b) {
return a[1] > b[1];
});
for (int i = 0; i < root.size(); i++)
if (help[root[i][0]] && root[i][1] < dis[0][root[i][0]])
help[root[i][0]] = false;
else
tim.emplace_back(root[i][1]);
for (int i = head[1]; ~i; i = nxt[i])
if (help[to[i]])
csum.emplace_back(dis[0][to[i]]);
sort(tim.begin(), tim.end());
sort(csum.begin(), csum.end());
int a = tim.size(), b = csum.size();
int i = 0, j = 0;
while (i < a && j < b) {
if (tim[i] >= csum[j])
i++, j++;
else
i++;
}
if (j == b)
return true;
else
return false;
}
signed main() {
init();
n = rd();
for (int i = 1; i < n; i++) {
int u = rd(), v = rd();
long long w = rdLL();
add(u, v, w);
add(v, u, w);
}
m = rd();
for (int i = 1; i <= m; i++)
t[i] = rd();
int tot = 0;
for (int i = head[1]; ~i; i = nxt[i])
tot++;
if (tot > m)
puts("-1"), exit(0);
dfs(1, 0);
long long l = 0, r = 5e14;
while (l < r) {
long long mid = (l + r) >> 1;
if (check(mid))
r = mid;
else
l = mid + 1;
}
wt(r);
return 0;
}
2024/08/09
Phoenix and Bits
合并&分裂 01-Trie
湖北怎么这么喜欢01-Trie啊?
我还没想好怎么写,待补
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
int n,q;
const int N = 2e5+5,U = (1<<20) - 1,M = N * 50;
int cnt,ls[M],rs[M],tagl[M],tagr[M],sum[M],tagx[M],rt;
void push_up(int p) {
tagl[p] = tagl[ls[p]] | tagl[rs[p]];
tagr[p] = tagr[ls[p]] | tagr[rs[p]];
sum[p] = sum[ls[p]] + sum[rs[p]];
}
void push_xor(int p,int x,int dep){
if((x >> dep) & 1) swap(ls[p],rs[p]);
int L = tagl[p],R = tagr[p];
tagl[p] = (L & (x ^ U)) | (R & x);
tagr[p] = (L & x) | (R & (x ^ U));
tagx[p] ^= x;
}
void push_down(int p,int dep) {
if(!tagx[p]) return;
push_xor(ls[p],tagx[p],dep - 1);
push_xor(rs[p],tagx[p],dep - 1);
tagx[p] = 0;
}
void insert(int &p,int x,int dep) {
if(!p) p = ++cnt;
if(dep == -1) {
tagl[p] = x ^ U; // 反 x
tagr[p] = x; // x
sum[p] = 1;
return;
}
(x >> dep) & 1 ? insert(rs[p],x,dep - 1) : insert(ls[p],x,dep - 1);
push_up(p);
}
#define mid ((pl + pr) >> 1)
void split(int &x,int &y,int pl,int pr,int L,int R,int dep) {
if(!x) return;
if(L <= pl && pr <= R) {
y = x,x = 0;
return;
}
push_down(x,dep);
y = ++cnt;
if(L <= mid) split(ls[x],ls[y],pl,mid,L,R,dep - 1);
if(R > mid) split(rs[x],rs[y],mid+1,pr,L,R,dep - 1);
push_up(x),push_up(y);
}
void merge(int &x,int y,int dep) {
if(!x || !y) {x += y;return;}
if(dep == -1) return;
push_down(x,dep);
push_down(y,dep);
merge(ls[x],ls[y],dep - 1);
merge(rs[x],rs[y],dep - 1);
push_up(x);
}
void push_or(int &p,int x,int dep) {
if(dep == -1 || !p) return;
if(!(x & tagl[p] & tagr[p])) {
push_xor(p,x & tagl[p],dep);
return;
}
push_down(p,dep);
if((x >> dep) & 1) {
push_xor(ls[p],1 << dep,dep - 1);
merge(rs[p],ls[p],dep - 1);
ls[p] = 0;
}
push_or(ls[p],x,dep - 1);
push_or(rs[p],x,dep - 1);
push_up(p);
}
#undef mid
signed main() {
n = rd(),q = rd();
for(int i = 1;i<=n;i++) insert(rt,rd(),19);
while(q--) {
int opt = rd(),l = rd(),r = rd(),t,x;
split(rt,t,0,U,l,r,19);
switch(opt) {
case 1:
x = rd();
push_xor(t,U,19);
push_or(t,x ^ U,19);
push_xor(t,U,19);
break;
case 2:
x = rd();
push_or(t,x,19);
break;
case 3:
x = rd();
push_xor(t,x,19);
break;
case 4:
wt(sum[t]);
putchar('\n');
break;
}
merge(rt,t,19);
}
return 0;
}
2024/08/10
CSP-2023
T4 种树
[CSP-S 2023] 种树
题目描述
你是一个森林养护员,有一天,你接到了一个任务:在一片森林内的地块上种树,并养护至树木长到指定的高度。
森林的地图有 \(n\) 片地块,其中 \(1\) 号地块连接森林的入口。共有 \(n-1\) 条道路连接这些地块,使得每片地块都能通过道路互相到达。最开始,每片地块上都没有树木。
你的目标是:在每片地块上均种植一棵树木,并使得 \(i\) 号地块上的树的高度生长到不低于 \(a_i\) 米。
你每天可以选择一个未种树且与某个已种树的地块直接邻接(即通过单条道路相连)的地块,种一棵高度为 \(0\) 米的树。如果所有地块均已种过树,则你当天不进行任何操作。特别地,第 \(1\) 天你只能在 \(1\) 号空地种树。
对每个地块而言,从该地块被种下树的当天开始,该地块上的树每天都会生长一定的高度。由于气候和土壤条件不同,在第 \(x\) 天,\(i\) 号地块上的树会长高 \(\max(b_i + x \times c_i, 1)\) 米。注意这里的 \(x\) 是从整个任务的第一天,而非种下这棵树的第一天开始计算。
你想知道:最少需要多少天能够完成你的任务?
输入格式
输入的第一行包含一个正整数 \(n\),表示森林的地块数量。
接下来 \(n\) 行:每行包含三个整数 \(a_i, b_i, c_i\),分别描述一片地块,含义如题目描述中所述。
接下来 \(n-1\) 行:每行包含两个正整数 \(u_i, v_i\),表示一条连接地块 \(u_i\) 和 \(v_i\) 的道路。
输出格式
输出一行仅包含一个正整数,表示完成任务所需的最少天数。
样例 #1
样例输入 #1
4 12 1 1 2 4 -1 10 3 0 7 10 -2 1 2 1 3 3 4样例输出 #1
5提示
【样例 1 解释】
第 \(1\) 天:在地块 \(1\) 种树,地块 \(1\) 的树木长高至 \(2\) 米。
第 \(2\) 天:在地块 \(3\) 种树,地块 \(1, 3\) 的树木分别长高至 \(5, 3\) 米。
第 \(3\) 天:在地块 \(4\) 种树,地块 \(1, 3, 4\) 的树木分别长高至 \(9, 6, 4\) 米。
第 \(4\) 天:在地块 \(2\) 种树,地块 \(1, 2, 3, 4\) 的树木分别长高至 \(14, 1, 9, 6\) 米。
第 \(5\) 天:地块 \(1, 2, 3, 4\) 的树木分别长高至 \(20, 2, 12, 7\) 米。
【样例 2】
见选手目录下的
tree/tree2.in与tree/tree2.ans。【样例 3】
见选手目录下的
tree/tree3.in与tree/tree3.ans。【样例 4】
见选手目录下的
tree/tree4.in与tree/tree4.ans。【数据范围】
对于所有测试数据有:\(1 ≤ n ≤ 10^5,1 ≤ a_i ≤ 10^{18}, 1 ≤ b_i ≤ 10^9,0 ≤ |c_i| ≤ 10^9, 1 ≤ u_i, v_i ≤ n\)。保证存在方案能在 \(10^9\) 天内完成任务。
特殊性质 A:对于所有 \(1 ≤ i ≤ n\),均有 \(c_i = 0\);
特殊性质 B:对于所有 \(1 ≤ i < n\),均有 \(u_i = i\)、\(v_i = i + 1\);
特殊性质 C:与任何地块直接相连的道路均不超过 \(2\) 条;
特殊性质 D:对于所有 \(1 ≤ i < n\),均有 \(u_i = 1\)。
很好很好的题,让我万能二分暴毙
看见式子第一件事:拆式子
观察一下增长高度的式子:
那么,我们发现当 \(c_i \geq 0\) 时,\(\max{\{ b_i + xc_i,1\}} = b_i + xc_i\)
那么分讨一下:
\(\textcircled{1}\ c_i \geq 0\)
对于一颗树,树高的增量 \(\Delta\) 有:
\(\textcircled{2}\ c_i < 0\)
我们看什么时候,\(b_i + xc_i\) 与 \(1\) 的 大小关系会发生突变
也就是这个式子:
因为 \(x\) 有实际意义,\(x \in Z\)
那么 \(x\) 最大取值就是 \(\lfloor \frac{1 - b_i}{c_i} \rfloor\),我们记为 \(k\)
那么对于一颗树,树高的增量 \(\Delta\) 有:
这样,我们就可以求出每个点在一段时间内,最晚什么时候种,仍能达到标准(非常重要)
我们看到这种求最少时间的题面,应该第一时间想到二分答案
我们二分最少时间,判断是否能让所有树都达到标准以上
接下来是 \(check\) desu
主要的问题是 顺序
我们怎样安排种树顺序来保证种法最优
自然是谁更耗时最长谁先种,
我们处理完每个点的最晚种植时间后,用时间排个序,最晚种植时间越小代表越紧急,放到前面种
因为这个延伸的方式有点想玻璃裂缝
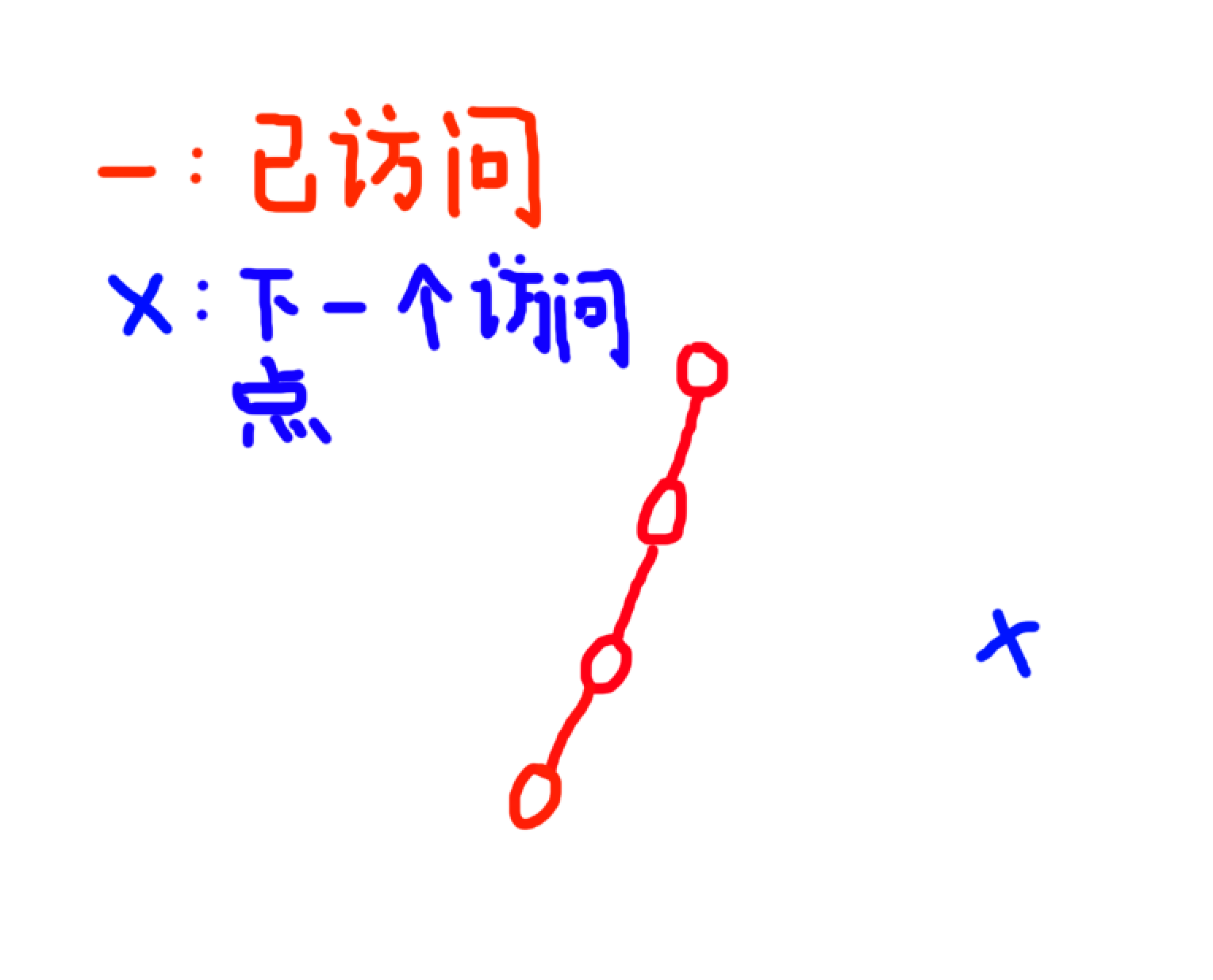
对一个新访问点,我们找路径到 新访问点,并从上到下附上时间戳
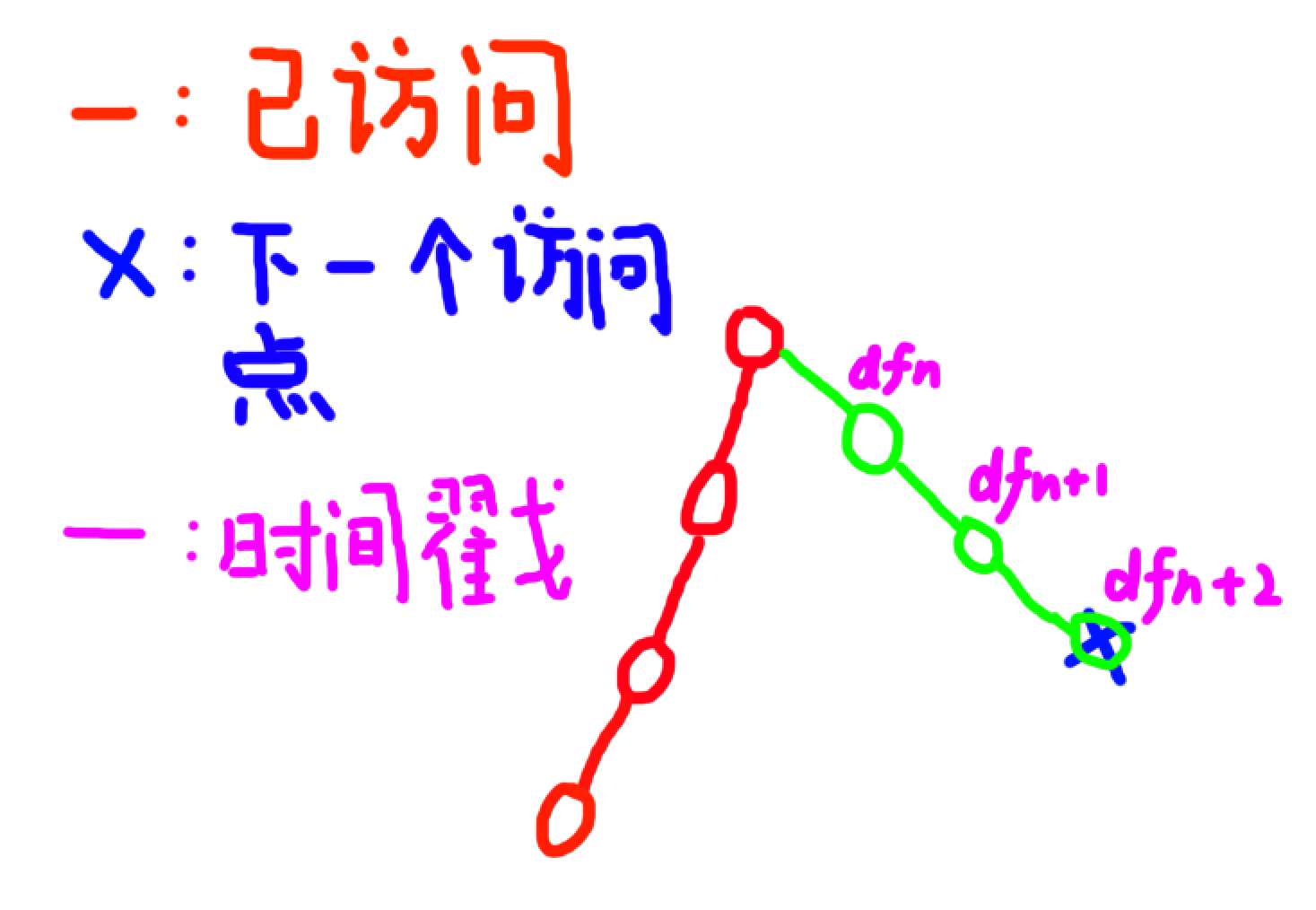
我们可以直接爬父亲,爬到第一个没种树的 \(kth\) 父亲
然后从它往该点的路径上依次附上种植时间,如果有一个种植时间已经超过最晚种植时间,那么这个方案就失败了(其中 \(1\) 的父亲看作已经种植过)如果每一个都完美种植上,那么就成功了
具体实现:
sort(P + 1,P + n + 1,[&](int ida,int idb){return t[ida] < t[idb];}); // P 是 节点编号, t 是节点对于的最晚种植时间
for(int i = 1,x = 0;i<=n;i++) {
int now = P[i],top = 0;
while(!vis[now]) vis[st[++top] = now] = true,now = fa[now]; // 寻找最远未种植父亲 ,放入栈中(以便附上种植时间),同时打上已种树标记
while(top) if(t[st[top--]] < ++x) return false; // 附上时间戳(种植时间),因为这个时间戳并没有什么用,所以只要判断一下是否合法就可以了
}
return true;
注意一下二分就可以AC了:
时间复杂度 \(\mathcal{O}(n\log n \log V)\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
using int128 = __int128;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5;
int n,head[N],nxt[N<<1],to[N<<1],cnt,fa[N],P[N],t[N],st[N];
bool vis[N];
array<int,3> p[N];
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
void dfs(int x,int f) {
fa[x] = f;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) dfs(y,x);
}
}
int128 calc(int id,int128 l,int128 r) {
int a = p[id][0],b = p[id][1],c = p[id][2];
if(c >= 0) return (r - l + 1) * b + (r - l + 1) * (r + l) / 2 * c;
int128 k = (1 - b) / c;
if(k < l) return r - l + 1;
else if(k > r) return (r - l + 1) * b + (r - l + 1) * (r + l) / 2 * c;
else return (k - l + 1) * b + (k - l + 1) * (k + l) / 2 * c + r - k;
}
bool check(int tim){
for(int i = 1;i<=n;i++) {
if(calc(i,1,tim) < p[i][0]) return false;
int dl = 1,dr = n;
while(dl < dr) {
int mid = (dr + dl + 1) >> 1;
if(calc(i,mid,tim) >= p[i][0]) dl = mid;
else dr = mid - 1;
}
P[i] = i;t[i] = dl;vis[i] = false;
}
sort(P + 1,P + n + 1,[&](int ida,int idb){return t[ida] < t[idb];});
for(int i = 1,x = 0;i<=n;i++) {
int now = P[i],top = 0;
while(!vis[now]) vis[st[++top] = now] = true,now = fa[now];
while(top) if(t[st[top--]] < ++x) return false;
}
return true;
}
signed main() {
init();
n = rd();
for(int i = 1;i<=n;i++)
p[i][0] = rd(),p[i][1] = rd(),p[i][2] = rd();
for(int i = 1,u,v;i<n;i++)
u = rd(),v = rd(),add(u,v),add(v,u);
dfs(1,0);
vis[0] = true;
int l = n,r = 1e9;
while(l < r - 1) {
int mid = (l + r) >> 1;
if(check(mid)) r = mid;
else l = mid;
}
wt(r);
return 0;
}
梦熊模拟赛MX-X2 T2
给定序列 \(a\),
我们要找 \(a_i \leq (a_i \oplus a_j) \leq a_j\) 的 \((i,j)\) 二元组对数。
这里提供一个 \(\textcolor{blue}{01trie}\) 做法
首先观察这个条件,因为 \(a_i \leq a_j\),所以我们可以钦定一个 \(a_j\),去找满足条件的 \(a_i\) 的个数。
既然有异或操作,我们可以使用 \(\textcolor{blue}{01trie}\) 来维护每一个值。
不难发现,满足 \((a_i \oplus a_j) \leq a_j\) 是 \(a_i \leq a_j\) 的充分必要条件。
那么,我们考虑 \(a_i \leq (a_i \oplus a_j)\) 这个条件
我们需要从高位往低位思考,可以得到结论:
\(a_i\) 的最高位低于 \(a_j\) 的最高位。
因为 \(a_i \leq a_j\) 并且 如果 \(a_i\) 的最高位等于 \(a_j\) 的最高位时,\((a_i \oplus a_j) \leq \min(a_i,a_j)\)
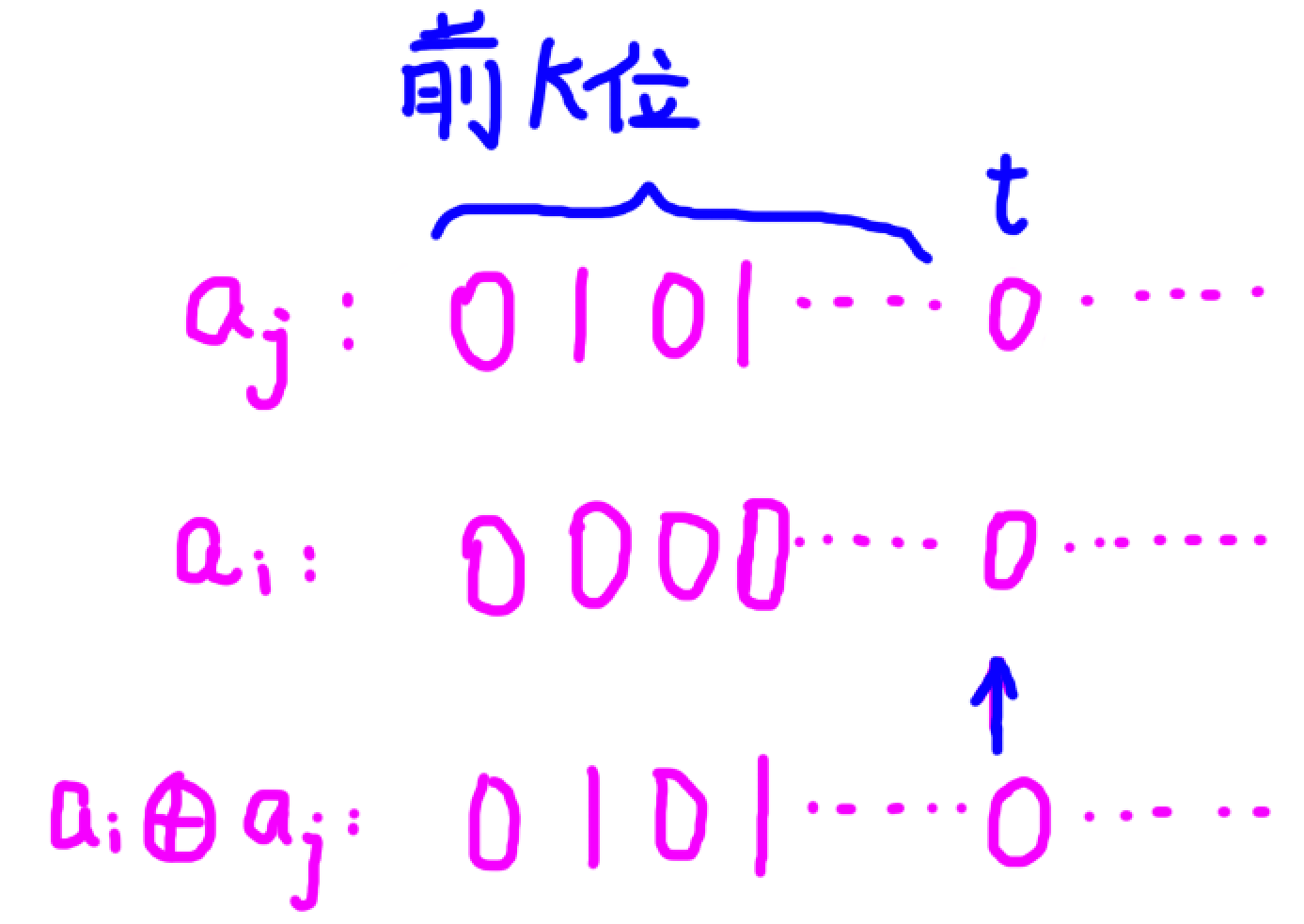
对于 \((a_i \oplus a_j)\) 的前 \(k\) 位与 \(a_j\) 的前 \(k\) 位相等的 \(a_i\)与\(a_j\),如果:
-
\(a_j\) 第 \(t\) 位为 \(0\),那么 \(a_i\) 第 \(t\) 位一定为 \(0\),不然 \((a_i \oplus a_j) \geq a_j\)
例如:
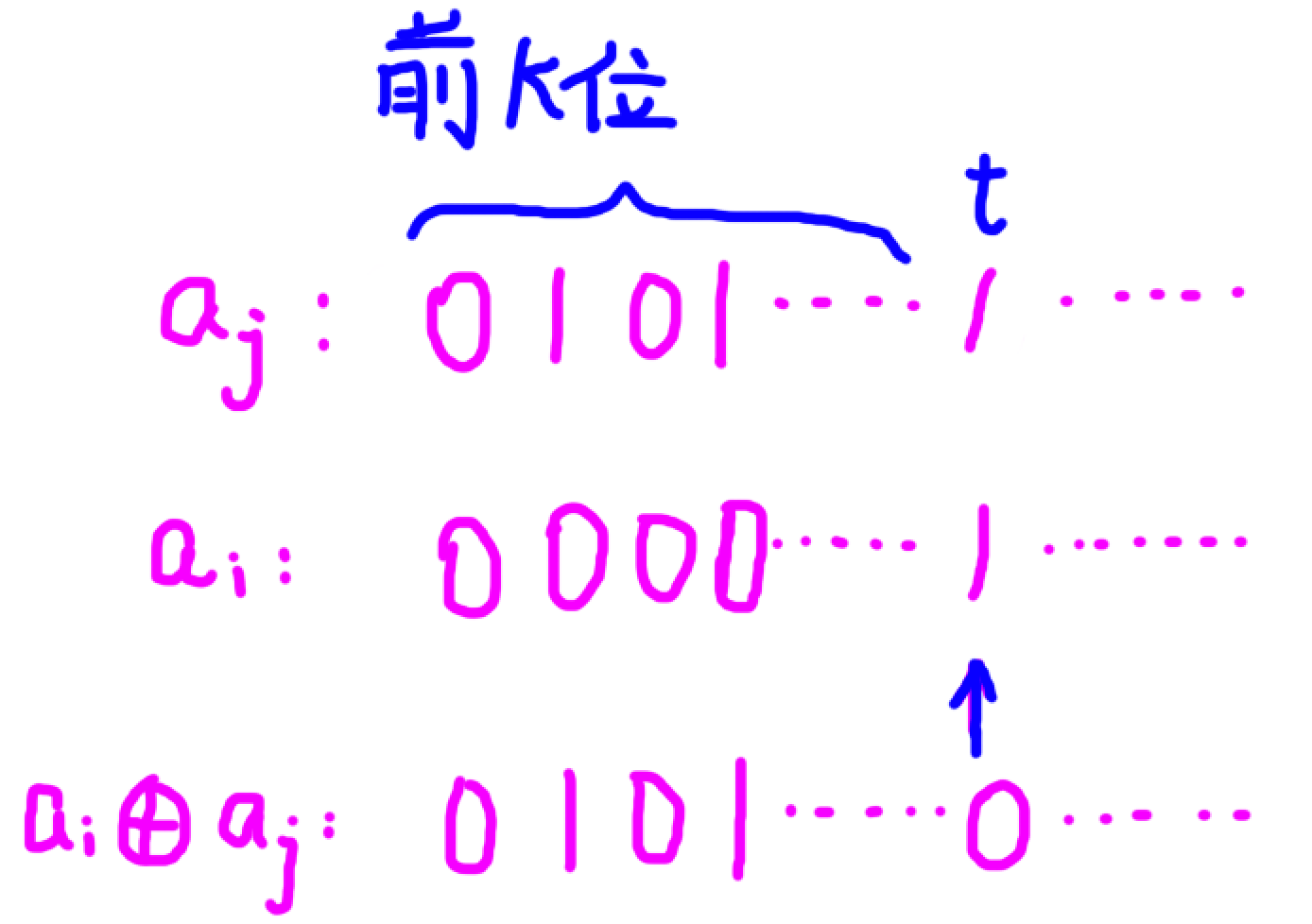
-
\(a_j\) 第 \(t\) 位为 \(1\),那么 \(a_i\) 第 \(t\) 位可以为 \(1\),此时无论此后然后操作,都可以满足 \((a_i \oplus a_j) \geq a_i\)
例如:
-
\(a_j\) 第 \(t\) 位为 \(1\),那么 \(a_i\) 第 \(t\) 位可以为 \(0\),此时需要再往后重复上述判断,直到每一位判断完
例如:
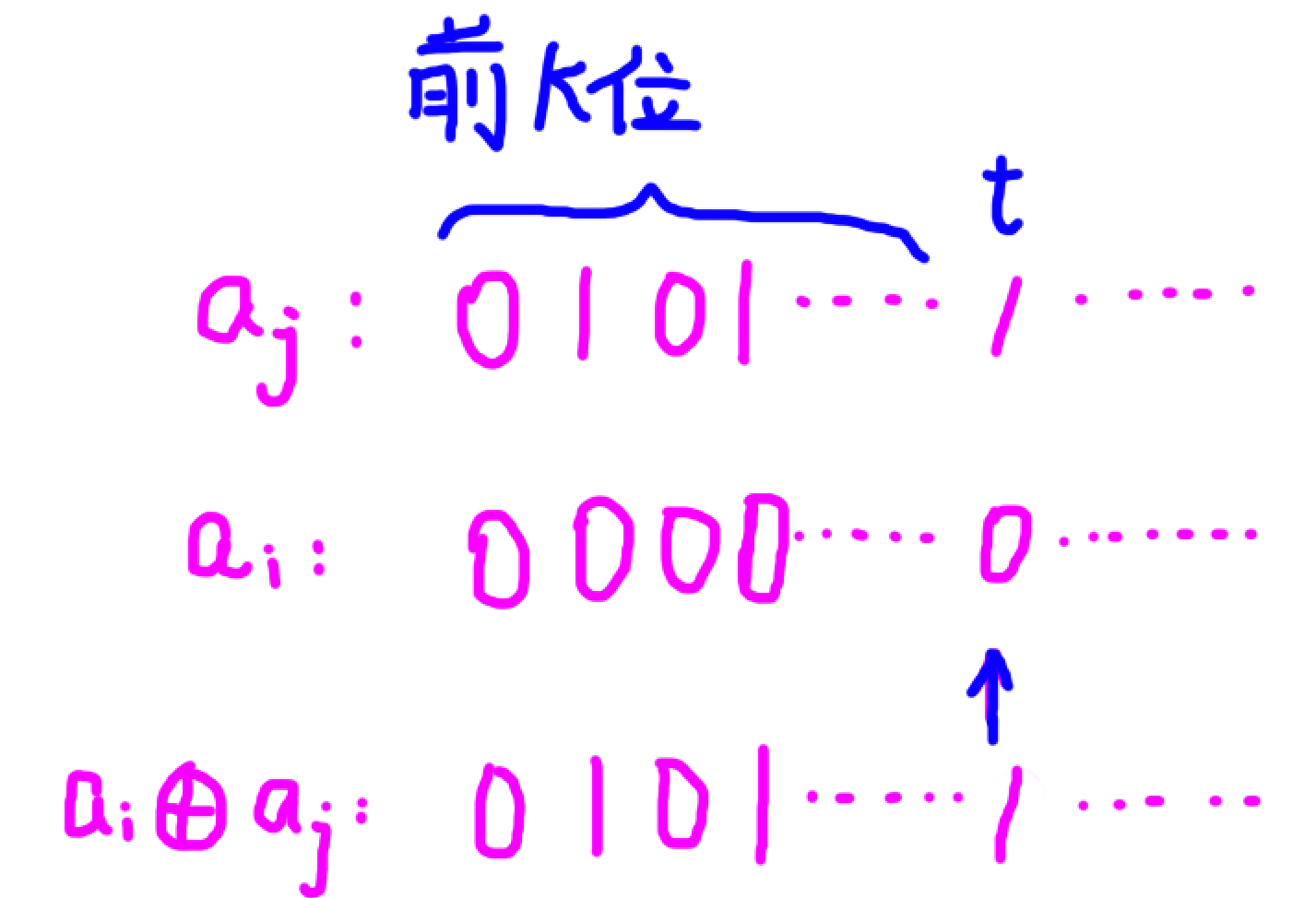
那么建出 \(\textcolor{blue}{01trie}\),类似于动态开点线段树,依照上述方法在这个 \(\textcolor{blue}{01trie}\) 上统计答案即可
时间复杂度: \(\mathcal{O}(\sum n\log V)\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 5e5 + 5;
int rt,ls[N * 30],rs[N * 30],sum[N * 30],cnt;
void push_up(int p) {
sum[p] = sum[ls[p]] + sum[rs[p]];
}
void ins(int &p,int x,int dep) {
if(!p) p = ++cnt;
if(dep == -1) {
sum[p]++;
return;
}
(x >> dep) & 1 ? ins(rs[p],x,dep - 1) : ins(ls[p],x,dep - 1);
push_up(p);
}
int Find(int &p,int x,int dep,bool flag) {
if(!p) return 0;
if(dep == -1) return sum[p];
int res = 0;
if((x >> dep) & 1) {
if(flag) {
res += Find(ls[p],x,dep - 1,true);
res += sum[rs[p]];
}else
res += Find(ls[p],x,dep - 1,true);
}else res += Find(ls[p],x,dep - 1,flag);
return res;
}
void init() {
for(int i = 0;i<=cnt;i++) ls[i] = rs[i] = sum[i] = 0;
cnt = 0;
rt = 0;
}
void solve() {
int n = rd();
vector<int> a(n);
int ans = 0;
init();
for(int i = 0;i<n;i++) a[i] = rd();
for(int i = 0;i<n;i++) ins(rt,a[i],29);
for(int i = 0;i<n;i++)
ans += Find(rt,a[i],29,false);
wt(ans);
putchar('\n');
}
signed main() {
int T = rd();
while(T--) solve();
return 0;
}
2024/08/11
集训接近尾声了,室友今天回家了
拉格朗日插值
很神奇的插值法,NOIP2022 微信步数 考过
上过小学三年级的的同学都知道:给定 \(n\) 个点,可以确定一个经过这所有点的函数 \(f\)
拉格朗日给出的答案是:
证明:我不会
我们 OIer 就只做感性理解了,对于任何一个 \((x,y)\) 二元对
我们令 \(f_i(x_i) = y_i \prod_{j \not = i} \frac{x - x_j}{x_i - x_j}\)
如果对于 第 \(k\) 个二元对 \((x_k,y_k)\),我们会发现 除 \(f_k(x_k) = y_k\) 以外,其他的 \(f_j(x_k) = 0(j \not = k)\),都被这个 \(\prod_{j \not = i} \frac{x - x_j}{x_i - x_j}\) 干成 \(0\) 了
请记住ta!
P8867 [NOIP2022] 建造军营
缩点 + tarjan + 树形dp
很典的题
图上做dp肯定不好
那么用tarjan缩点,对缩完点的树形结构dp是很自然的
为了不重复的记录答案,我们dp时,只针对子树内的情况做讨论
我们就强制不选择 \(fa_x \leadsto x\) 的这条边,在做转移的时候特别考虑
我们由于只对子树内做分析,所以我们默认子树外不选择任何军营
用 \(f_{x,0/1}\) 来表示 在 \(x\) 子树内(包括 \(x\))存在 (没有 / 有)军营的情况(方案数)
故有转移:
我们规定外面不造军营,但是道路我们想守就守。
我们子树内的军营建造完了,同时子树内的军营方案和道路看守方案也都完备了,
那么外面的道路,每个都有 \(2\) 的贡献。
我们考虑记录 \(x\) 子树内的边数,用总边数减去,就是外面的边数
记录表达式:
在 dp 的时候与 \(f_{x,1}\) 计算入答案:
但是当我们到达根节点的时候,我们居然将答案除了个 \(2\)
这明显不对,因为答案肯定是随子树的增大而递增的
我们发现我们没有要处理的子树外的边,(因为 \(\operatorname{root}\) 没有父亲)
所以针对 \(\operatorname{root}\):
最后再谈一谈初始化:
Over!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N = 2e6+5,M = 5e6+5,mod = 1e9 + 7;
int n,m;
struct Edge{
int head[N],nxt[M<<1],to[M<<1],cnt;
Edge() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
};
struct newEdge{
int head[N],nxt[M<<1],to[M<<1],cnt;
newEdge() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
};
Edge g;
newEdge G;
int U[N],V[N],dfn[N],low[N],num,co[N],col,P[N],st[N],top,E[N],_edge[M<<1];
bool vis[M << 1];
void tarjan(int x) {
low[x] = dfn[x] = ++num;
st[++top] = x;
for(int i = g.head[x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(vis[_edge[i]]) continue;
vis[_edge[i]] = true;
if(!dfn[y]){
tarjan(y);
low[x] = min(low[y],low[x]);
} else if(!co[y]) low[x] = min(low[x],dfn[y]);
}
if(low[x] == dfn[x]) {
int v;
++col;
do{
v = st[top--];
co[v] = col;
P[col]++;
}while(v ^ x);
}
}
int qpow(int x,int k) {
int r = 1;
while(k) {
if(k & 1) r = (r * x) % mod;
x = x * x % mod;
k >>= 1;
}
return r;
}
signed s[N];
int ans,f[N][2];
void dfs(int x,int fa) {
s[x] = E[x];
for(int i = G.head[x];~i;i = G.nxt[i]){
int y = G.to[i];
if(y ^ fa) {
dfs(y,x);
s[x] += s[y] + 1;
}
}
}
void dp(int x,int fa) {
for(int i = G.head[x];~i;i = G.nxt[i]) {
int y = G.to[i];
if(y ^ fa) {
dp(y,x);
f[x][1] = (f[x][1] * ((2 * f[y][0] % mod + f[y][1]) % mod) % mod + f[x][0] * f[y][1] % mod) % mod;
f[x][0] = (f[x][0] * 2 % mod * f[y][0]) % mod;
}
}
if(x == 1) ans = (ans + f[x][1]) % mod;
else ans = (ans + f[x][1] * qpow(2,s[1] - s[x] - 1) % mod) % mod;
}
signed main() {
int k,d;
scanf("%lld %lld",&k,&d);
n = k,m = d;
cout<<n<<' '<<m<<'\n';
for(int i = 1;i<=m;i++) {
cin>>U[i]>>V[i];
g.add(U[i],V[i]);_edge[g.cnt - 1] = i;
g.add(V[i],U[i]);_edge[g.cnt - 1] = i;
}
tarjan(1);
for(int i = 1;i<=m;i++)
if(co[U[i]] ^ co[V[i]])
G.add(co[U[i]],co[V[i]]),G.add(co[V[i]],co[U[i]]);
else
E[co[U[i]]]++;
for(int i = 1;i<=col;i++) {
f[i][0] = qpow(2,E[i]) % mod;
f[i][1] = (qpow(2,E[i] + P[i]) - f[i][0] + mod) % mod;
}
dfs(1,0);
dp(1,0);
cout<<ans;
return 0;
}
2024/08/12
梦熊模拟赛
T1 chess
题目描述
输入格式
输出格式
样例
数据范围与提示
我一开始写 bfs,捣鼓了半天
最后还是选择了刷表
行动只有向右、向下两种,所以到达右下角的步数是有限的
那么我们对每一个步数相同的点扫描一遍,看一看能否被选中
走个斜线就可以了
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N = 2005;
char Map[N][N];
bool vis[N][N],pass[N][N];
int dx[4] = {-1,0};
int dy[4] = {0,-1};
string ans;
int n,m;
#define check(x,y) (1 <= x && x <= n && 1 <= y && y <= m)
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
freopen("a.in","r",stdin);
freopen("a.out","w",stdout);
cin>>n>>m;
for(int i = 1;i<=n;i++){
cin>>Map[i];
for(int j = m;j >= 1;j--)
Map[i][j] = Map[i][j - 1];
Map[i][0] = ' ';
}
vis[1][1] = true;
ans.push_back(Map[1][1]);
for(int i = 2;i<=m;i++) {
array<int,2> a;
char minn = 'z';
a[0] = 1,a[1] = i;
while(check(a[0],a[1])) {
for(int j = 0;j<2;j++) {
int kx = dx[j] + a[0],ky = dy[j] + a[1];
if(check(kx,ky) && vis[kx][ky]) {
minn = min(minn,Map[a[0]][a[1]]);
break;
}
}
a[0] = a[0] + 1,a[1] = a[1] - 1;
}
a[0] = 1,a[1] = i;
while(check(a[0],a[1])) {
pass[a[0]][a[1]] = true;
if(Map[a[0]][a[1]] == minn && (vis[a[0] - 1][a[1]] || vis[a[0]][a[1] - 1]))
vis[a[0]][a[1]] = true;
a[0] = a[0] + 1,a[1] = a[1] - 1;
}
ans.push_back(minn);
}
for(int i = 1;i<=m;i++) {
array<int,2> a;
a[0] = n,a[1] = i;
if(pass[a[0]][a[1]]) continue;
char minn = 'z';
while(check(a[0],a[1])) {
for(int j = 0;j<2;j++) {
int kx = a[0] + dx[j];
int ky = a[1] + dy[j];
if(check(kx,ky) && vis[kx][ky]) {
minn = min(minn,Map[a[0]][a[1]]);
break;
}
}
a[0] = a[0] - 1,a[1] = a[1] + 1;
}
a[0] = n,a[1] = i;
while(check(a[0],a[1])) {
pass[a[0]][a[1]] = true;
if(Map[a[0]][a[1]] == minn&& (vis[a[0] - 1][a[1]] || vis[a[0]][a[1] - 1]))
vis[a[0]][a[1]] = true;
a[0] = a[0] - 1,a[1] = a[1] + 1;
}
ans.push_back(minn);
}
cout<<ans;
return 0;
}
T2 glass
题目描述
输入格式
输出格式
样例
数据范围与提示
$ 40%$部分分:
我们考虑每一个联通块需要最少需要多少代价
记录连通块,并记录最后倒在了哪个杯子里,进行状态压缩
然后 枚举全集的子集,分成 \(k\) 块
\(\mathcal{O}(2^{2n}n^2)\)
TLE-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 22,U = (1<<20) - 1;
int n,k;
int c[N][N],f[1<<20][20],g[1<<20];
int ans = 0x3f3f3f3f3f3f3f3fLL;
bool notIn(int x,int y) {return (x ^ y) & (U ^ x);}
void dfs(int d,int t,int E) {
if(d == 1) {
ans = min(ans,t + g[E]);
return;
}
if(t >= ans) return;
for(int i = 1;i<=E;i++) {
if(notIn(E,i)) continue;
if(__builtin_popcount(i) > (n - k + 1)) continue;
if(__builtin_popcount(i ^ E) < d - 1) continue;
dfs(d - 1,t + g[i],E ^ i);
}
}
signed main() {
memset(f,0x3f,sizeof(f));
memset(g,0x3f,sizeof(g));
// freopen("b.in","r",stdin);
// freopen("b.out","w",stdout);
n = rd(),k = rd();
for(int i = 1;i<=n;i++)
for(int j = 1;j<=n;j++)
c[i][j] = rd();
if(n == k) {puts("0");return 0;}
if(k == n - 1) {
int minn = INT_MAX;
for(int i = 1;i<=n;i++)
for(int j = 1;j<=n;j++)
if(i ^ j)
minn = min(minn,c[i][j]);
wt(minn);
return 0;
}
for(int i = 0;i<n;i++)
for(int j = 0;j<n;j++)
f[(1 << i) | (1 << j)][j] = c[i + 1][j + 1];
for(int i = 1;i<(1<<n);i++) {
if(__builtin_popcount(i) <= 2) continue;
if(__builtin_popcount(i) > (n - k + 1)) continue;
for(int j = 1;j<i;j++) {
if(notIn(i,j)) continue;
for(int k = 0;k<n;k++)
if((i >> k) & 1)
for(int p = 0;p<n;p++)
if((j >> p) & 1)
f[i][k] = min(f[i][k],f[i ^ j][k] + f[j][p] + c[p + 1][k + 1]);
}
}
for(int i = 0;i<(1<<n);i++){
if(__builtin_popcount(i) < 2) {
g[i] = 0;
continue;
}
for(int j = 0;j<n;j++)
if((i >> j) & 1)
g[i] = min(g[i],f[i][j]);
}
dfs(k,0,(1<<n) - 1);
wt(ans);
return 0;
}
\(100\) 分:
上面的式子显然不能优化,
肯定是状态设计错了
我们要直接推导出答案!
我们直接考虑最终情况,如果对于一个 \(k\),ta最后要倒进 \(t\) 中,那么肯定有一种方式最优
因为杯子不是倒完就消失并且如果需要途径其他的杯子,只会使答案更优(即 需要的 \(k\) 更小),所以这个最优方式是可以保证的
考虑对邻接矩阵进行 floyd
我们令 \(f_{S}\) 为 最后剩余的杯子为 \(S\)(\(\TextOrMath{}{01}\) 串),有转移:
然后对 \(f_S\) 中 \(\operatorname{popcount}(S) \leq k\) 的进行更新答案
\(\mathcal{O}(2^nn^2)\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 22,U = (1<<20) - 1;
int c[N][N],f[1<<20];
#define lowbit(x) (x & (-x))
signed main() {
// freopen("b.in","r",stdin);
// freopen("b.out","w",stdout);
memset(f,0x3f,sizeof(f));
int n = rd(),k = rd();
for(int i = 0;i<n;i++)
for(int j = 0;j<n;j++)
c[i][j] = rd();
for(int k = 0;k<n;k++)
for(int i = 0;i<n;i++)
for(int j = 0;j<n;j++)
c[i][j] = min(c[i][j],c[i][k] + c[k][j]);
int ans = 0x3f3f3f3f3f3f3f3fLL;
f[(1<<n) - 1] = 0;
static int st[21] = {},top = 0;
for(int i = (1<<n) - 1;i;i--) {
top = 0;
for(int j = 0;j<n;j++)
if((i >> j) & 1)
st[++top] = j;
for(int x = 1;x <= top;x++)
for(int y = 1;y <= top;y++){
if(x == y) continue;
int k_ = st[x],_k = st[y];
f[i ^ (1 << k_)] = min(f[i ^ (1 << k_)],f[i] + c[k_][_k]);
}
if(__builtin_popcount(i) <= k)
ans = min(ans,f[i]);
}
wt(ans);
return 0;
}
2024/08/13
CPU 监控
题面:
题目描述
Bob 需要一个程序来监视 CPU 使用率。这是一个很繁琐的过程,为了让问题更加简单,Bob 会慢慢列出今天会在用计算机时做什么事。
Bob 会干很多事,除了跑暴力程序看视频之外,还会做出去玩玩和用鼠标乱点之类的事,甚至会一脚踢掉电源……这些事有的会让做这件事的这段时间内 CPU 使用率增加或减少一个值;有的事还会直接让 CPU 使用率变为一个值。
当然 Bob 会询问:在之前给出的事件影响下,CPU 在某段时间内,使用率最高是多少。有时候 Bob 还会好奇地询问,在某段时间内 CPU 曾经的最高使用率是多少。
为了使计算精确,使用率不用百分比而用一个整数表示。
不保证 Bob 的事件列表没有出莫名的问题,使得使用率为负………………
输入格式
第一行一个正整数 \(T\),表示 Bob 需要监视 CPU 的总时间。
然后第二行给出 \(T\) 个数表示在你的监视程序执行之前,Bob 干的事让 CPU 在这段时间内每个时刻的使用率达已经达到了多少。
第三行给出一个整数 \(E\),表示 Bob 需要做的事和询问的总数。
接下来 \(E\) 行每行表示给出一个询问或者列出一条事件:
Q X Y:询问从 \(X\) 到 \(Y\) 这段时间内 CPU 最高使用率。A X Y:询问从 \(X\) 到 \(Y\) 这段时间内之前列出的事件使 CPU 达到过的最高使用率。P X Y Z:列出一个事件这个事件使得从 \(X\) 到 \(Y\) 这段时间内 CPU 使用率增加 \(Z\)。C X Y Z:列出一个事件这个事件使得从 \(X\) 到 \(Y\) 这段时间内 CPU 使用率变为 \(Z\)。时间的单位为秒,使用率没有单位。
\(X\) 和 \(Y\) 均为正整数(\(X\le Y\)),\(Z\) 为一个整数。
从 \(X\) 到 \(Y\) 这段时间包含第 \(X\) 秒和第 \(Y\) 秒。
保证必要运算在有符号 32 位整数以内。
输出格式
对于每个询问,输出一行一个整数回答。
样例 #1
样例输入 #1
10 -62 -83 -9 -70 79 -78 -31 40 -18 -5 20 A 2 7 A 4 4 Q 4 4 P 2 2 -74 P 7 9 -71 P 7 10 -8 A 10 10 A 5 9 C 1 8 10 Q 6 6 Q 8 10 A 1 7 P 9 9 96 A 5 5 P 8 10 -53 P 6 6 5 A 10 10 A 4 4 Q 1 5 P 4 9 -69样例输出 #1
79 -70 -70 -5 79 10 10 79 79 -5 10 10提示
数据分布如下:
第 \(1,2\) 个数据保证 \(T\) 和 \(E\) 均小于等于 \(10^3\)。
第 \(3,4\) 个数据保证只有
Q类询问。第 \(5,6\) 个数据保证只有
C类事件。第 \(7,8\) 个数据保证只有
P类事件。对于 \(100\%\) 的数据,\(1\le T,E\le 10^5\),\(1\le X\le Y\le T\),\(-2^{31}\leq Z\lt 2^{31}\)。
我们要维护区间最大值、区间历史最大值,支持区间加、区间赋值
其中,查询函数和区间操作函数 与 正常线段树 没有任何区别
主要在于打标记和传递标记 不喜欢分成多函数式写线段树的同学有喜了
针对区间加,我们要记录 sum 区间加tag,max_sum 历史区间加tag最大值
(因为中间可能存在一次最大区间加,而后面被区间赋值或区间加上一个负数而被顶掉)
针对区间赋值,我们和记录区间加一样————val、max_val
对于区间赋值和区间加的优先级,我们发现:一旦区间被赋值后,我们就可以只针对赋值的数值做操作区间加可以累加到区间赋值的数据上
用 vis 记录是否被进行过区间赋值
对于打区间加tag,我们观察区间赋值情况
如果 \(vis_p \in \textcolor{green}{True}\),那么我们可以更新 \(max \_ val、max\_ ans\),将 \(val、ans \leftarrow \Delta\)
否则,我们就更新 \(max\_ sum、max\_ ans\),将 \(sum、ans \leftarrow \Delta\)
对于区间赋值就比较简单,只要取最值,更新一下就可以了
接下来是push_down部分
因为 区间加 的优先级次于 区间赋值 的优先级
所以,我们先将人畜无害的 区间加 下放
记得将标记清零!
然后看一看是否存在区间赋值操作
再将 区间赋值 下放
记得将标记清零!(还有 vis)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5,inf = 0x3f3f3f3f3f3f3f3fLL;
int T,E,a[N];
int ans[N<<2],history_ans[N<<2];
void getmax(int &a,int b) {if(b > a) a = b;}
namespace sgt{
#define ls (p << 1)
#define rs (ls | 1)
#define mid ((pl + pr) >> 1)
int sum[N<<2],val[N<<2];
bool vis[N<<2];
int max_sum[N<<2],max_val[N<<2];
void push_up(int p) {
ans[p] = max(ans[ls],ans[rs]);
history_ans[p] = max(history_ans[ls],history_ans[rs]);
}
void push_sum(int p,int k,int maxk) {
if(vis[p]) {
getmax(max_val[p],val[p] + maxk);
getmax(history_ans[p],ans[p] + maxk);
val[p] += k;
}else {
getmax(max_sum[p],sum[p] + maxk);
getmax(history_ans[p],ans[p] + maxk);
sum[p] += k;
}
ans[p] += k;
}
void push_val(int p,int k,int maxk) {
if(vis[p]) {
getmax(max_val[p],maxk);
getmax(history_ans[p],maxk);
}else {
vis[p] = true;
max_val[p] = maxk;
getmax(history_ans[p],maxk);
}
ans[p] = val[p] = k;
}
void push_down(int p){
push_sum(ls,sum[p],max_sum[p]);
push_sum(rs,sum[p],max_sum[p]);
sum[p] = max_sum[p] = 0;
if(vis[p]) {
push_val(ls,val[p],max_val[p]);
push_val(rs,val[p],max_val[p]);
vis[p] = 0;
val[p] = max_val[p] = 0;
}
}
void build(int p,int pl,int pr) {
if(pl == pr) {
history_ans[p] = ans[p] = a[pl];
return;
}
build(ls,pl,mid);
build(rs,mid+1,pr);
push_up(p);
}
int query(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return ans[p];
push_down(p);
int res = -inf;
if(l <= mid) res = max(res,query(ls,pl,mid,l,r));
if(r > mid) res = max(res,query(rs,mid+1,pr,l,r));
return res;
}
int queryHistoryAns(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return history_ans[p];
push_down(p);
int res = -inf;
if(l <= mid) getmax(res,queryHistoryAns(ls,pl,mid,l,r));
if(r > mid) getmax(res,queryHistoryAns(rs,mid+1,pr,l,r));
return res;
}
void add(int p,int pl,int pr,int l,int r,int k) {
if(l <= pl && pr <= r) {
push_sum(p,k,k);
return;
}
push_down(p);
if(l <= mid) add(ls,pl,mid,l,r,k);
if(r > mid) add(rs,mid+1,pr,l,r,k);
push_up(p);
}
void assign(int p,int pl,int pr,int l,int r,int k) {
if(l <= pl && pr <= r) {
push_val(p,k,k);
return;
}
push_down(p);
if(l <= mid) assign(ls,pl,mid,l,r,k);
if(r > mid) assign(rs,mid+1,pr,l,r,k);
push_up(p);
}
}
void nowMax() {
int x = rd(),y = rd();
wt(sgt::query(1,1,T,x,y));
putchar('\n');
}
void historyAns() {
int x = rd(),y = rd();
wt(sgt::queryHistoryAns(1,1,T,x,y));
putchar('\n');
}
void getadd() {
int x = rd(),y = rd(),z = rd();
sgt::add(1,1,T,x,y,z);
}
void getcov() {
int x = rd(),y = rd(),z = rd();
sgt::assign(1,1,T,x,y,z);
}
signed main() {
T = rd();
for(int i = 1;i<=T;i++)
a[i] = rd();
sgt::build(1,1,T);
E = rd();
while(E--) {
char opt = getchar();
while(opt == ' ' ||opt == '\n') opt = getchar();
switch(opt) {
case 'Q':
nowMax();
break;
case 'A':
historyAns();
break;
case 'P':
getadd();
break;
case 'C':
getcov();
break;
default:
break;
}
}
return 0;
}
2024/08/19
终于回学校了,北京的景点真没什么好玩的
除了烤鸭和炸酱面,其他的都不算好吃
P2303 [SDOI2012] Longge 的问题
题面:
题目背景
Longge 的数学成绩非常好,并且他非常乐于挑战高难度的数学问题。
题目描述
现在问题来了:给定一个整数 \(n\),你需要求出 \(\sum\limits_{i=1}^n \gcd(i, n)\),其中 \(\gcd(i, n)\) 表示 \(i\) 和 \(n\) 的最大公因数。
输入格式
输入只有一行一个整数,表示 \(n\)。
输出格式
输出一行一个整数表示答案。
样例 #1
样例输入 #1
6样例输出 #1
15提示
数据规模与约定
- 对于 \(60\%\)的数据,保证 \(n\leq 2^{16}\)。
- 对于 \(100\%\)的数据,保证 \(1\leq n< 2^{32}\)。
万恶之源:\(\operatorname{gcd}\)
经典变形:
对于每一个约数,我们分开进行计算
一个约数 \(i\),成为公因数,有 \(\phi(\frac{n}{i})\) 种可能,
因为假设 \(k = i \times d (d \bot n)\),那么 \(\operatorname{gcd}(\frac{k}{i},\frac{n}{i}) = \operatorname{gcd}(d,\frac{n}{i}) = \operatorname{gcd}(d,n) = 1\)
故对于一个约数 \(i\),有 \(\operatorname{ans} \leftarrow i \times \phi(\frac{n}{i})\)
然后做好实现就可以了
时间复杂度:\(\mathcal{O}(\sqrt{n}\phi(n))\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
namespace work{
int phi(int n) {
int r = n;
for(int i = 2;i * i <= n;i++) {
if(n % i == 0) {
r = r * (i - 1) / i;
while(n % i == 0) n /= i;
}
}
if(n > 1) r = r * (n - 1) / n;
return r;
}
int getans(int n) {
int ans = 0;
for(int i = 1;i * i <= n;i ++)
if(n % i == 0)
if(i * i != n)
ans = (ans + i * phi(n / i) + (n / i) * phi(i));
else
ans = (ans + i * phi(n / i));
return ans;
}
}
signed main() {
int n = rd();
wt(work::getans(n));
return 0;
}
P3861 拆分
暂留
CF911G Mass Change Queries
题面:
题面翻译
给出一个数列,有q个操作,每种操作是把区间[l,r]中等于x的数改成y.输出q步操作完的数列.
题目描述
You are given an array\(a\)consisting of\(n\)integers. You have to process\(q\)queries to this array; each query is given as four numbers\(l\),\(r\),\(x\)and\(y\), denoting that for every\(i\)such that\(l<=i<=r\)and\(a_{i}=x\)you have to set\(a_{i}\)equal to\(y\).
Print the array after all queries are processed.
输入格式
The first line contains one integer\(n\)(\(1<=n<=200000\)) — the size of array\(a\).
The second line contains\(n\)integers\(a_{1}\),\(a_{2}\), ...,\(a_{n}\)(\(1<=a_{i}<=100\)) — the elements of array\(a\).
The third line contains one integer\(q\)(\(1<=q<=200000\)) — the number of queries you have to process.
Then\(q\)lines follow.\(i\)-th line contains four integers\(l\),\(r\),\(x\)and\(y\)denoting\(i\)-th query (\(1<=l<=r<=n\),\(1<=x,y<=100\)).
输出格式
Print\(n\)integers — elements of array\(a\)after all changes are made.
样例 #1
样例输入 #1
5 1 2 3 4 5 3 3 5 3 5 1 5 5 1 1 5 1 5样例输出 #1
5 2 5 4 5
线段树合并的进阶:部分合并线段树
我们每次合并线段树,都把整个线段树都合并到一起
在这道题,我们因为权值只有 \(1 \sim 100\) ,非常的小
然后,因为序列长度是有限的,所以用动态开点线段树来对 \(1 \sim 100\) 的权值所在的位置建点
因为我们只需要知道这个位置有没有点就可以了,所以不需要什么push_up函数
然后,对于变换操作,我们想到这个题目,有兴趣的可以看一看
题面:
题目描述
输入格式
输出格式
样例
数据范围与提示
我们去维护这 \(100\) 个数…………吗?
这显然不行,对于这个 \(2\times 10^6\) 如果用一颗线段树,就得开 \(n\log n\) 个点,每个点还得维护转化信息 \(100^2\)
但是我们用 \(100\) 颗合并线段树,对于每个权值开一颗线段树,空间复杂度完全可以接受
对于让区间 \(l,r\) 中 \(x \rightarrow y\),我们就可以让 \(x\) 线段树上 \([l,r]\) 的部分与 \(y\) 线段树上 \([l,r]\) 的部分合并
实现:
#define mid ((pl + pr) >> 1)
int lson[N * 50],rson[N * 50],cnt;
#define ls lson[p]
#define rs rson[p]
void update(int &p,int pl,int pr,int k) {
if(!p) p = ++cnt;
if(pl == pr) return;
if(k <= mid) update(ls,pl,mid,k);
if(k > mid) update(rs,mid+1,pr,k);
return;
}
int merge(int x,int y,int pl,int pr) {
if(!x || !y) return x + y;
if(pl == pr) return x;
lson[x] = merge(lson[x],lson[y],pl,mid);
rson[x] = merge(rson[x],rson[y],mid+1,pr);
return x;
}
void change(int &x,int &y,int pl,int pr,int l,int r) {
if(!y) return;
if(l <= pl && pr <= r) {
x = merge(x,y,pl,pr);
y = 0;
}
if(!x) x = ++cnt;
if(l <= mid) change(lson[x],lson[y],pl,mid,l,r);
if(r > mid) change(rson[x],rson[y],mid+1,pr,l,r);
return;
}
最后对每个线段树上的点进行统计即可
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 200006;
int n,rt[101],ans[N];
namespace sgt{
#define mid ((pl + pr) >> 1)
int lson[N * 50],rson[N * 50],cnt;
#define ls lson[p]
#define rs rson[p]
void update(int &p,int pl,int pr,int k) {
if(!p) p = ++cnt;
if(pl == pr) return;
if(k <= mid) update(ls,pl,mid,k);
if(k > mid) update(rs,mid+1,pr,k);
return;
}
int merge(int x,int y,int pl,int pr) {
if(!x || !y) return x + y;
if(pl == pr) return x;
lson[x] = merge(lson[x],lson[y],pl,mid);
rson[x] = merge(rson[x],rson[y],mid+1,pr);
return x;
}
void change(int &x,int &y,int pl,int pr,int l,int r) {
if(!y) return;
if(l <= pl && pr <= r) {
x = merge(x,y,pl,pr);
y = 0;
}
if(!x) x = ++cnt;
if(l <= mid) change(lson[x],lson[y],pl,mid,l,r);
if(r > mid) change(rson[x],rson[y],mid+1,pr,l,r);
return;
}
void getId(int p,int pl,int pr,int d) {
if(!p) return;
if(pl == pr) {
ans[pl] = d;
return;
}
getId(ls,pl,mid,d);
getId(rs,mid+1,pr,d);
}
};
signed main() {
n = rd();
for(int i = 1;i <= n;i++)
sgt::update(rt[rd()],1,n,i);
int q = rd();
while(q--) {
int l = rd(),r = rd(),x = rd(),y = rd();
if(x == y) continue;
sgt::change(rt[y],rt[x],1,n,l,r);
}
for(int i = 1;i<=100;i++)
sgt::getId(rt[i],1,n,i);
for(int i = 1;i<=n;i++)
wt(ans[i]),putchar(' ');
return 0;
}
CF865D Buy Low Sell High
题面:
题面翻译
题目:
已知接下来N天的股票价格,每天你可以买进一股股票,卖出一股股票,或者什么也不做.N天之后你拥有的股票应为0,当然,希望这N天内能够赚足够多的钱.
输入:
第一行一个整数天数N(2<=N<=300000).
第二行N个数字p1,p2...pN(1<=pi<=10^6),表示每天的价格.
输出: N天结束后能获得的最大利润.
样例解释:
样例1:分别在价格为5,4,2的时候买入,分别在价格为9,12,10的时候卖出,总利润为\(-5-4+9+12-2+10=20\) .
翻译贡献者UID:36080题目描述
You can perfectly predict the price of a certain stock for the next\(N\)days. You would like to profit on this knowledge, but only want to transact one share of stock per day. That is, each day you will either buy one share, sell one share, or do nothing. Initially you own zero shares, and you cannot sell shares when you don't own any. At the end of the\(N\)days you would like to again own zero shares, but want to have as much money as possible.
输入格式
Input begins with an integer\(N\)$ (2<=N<=3·10^{5})$, the number of days.
Following this is a line with exactly\(N\)integers\(p_{1},p_{2},...,p_{N}\)$ (1<=p_{i}<=10^{6})\(. The price of one share of stock on the\)i\(-th day is given by\)p_{i}$.
输出格式
Print the maximum amount of money you can end up with at the end of\(N\)days.
样例 #1
样例输入 #1
9 10 5 4 7 9 12 6 2 10样例输出 #1
20样例 #2
样例输入 #2
20 3 1 4 1 5 9 2 6 5 3 5 8 9 7 9 3 2 3 8 4样例输出 #2
41提示
In the first example, buy a share at\(5\), buy another at\(4\), sell one at\(9\)and another at\(12\). Then buy at\(2\)and sell at\(10\). The total profit is\(-5-4+9+12-2+10=20\).
反悔贪心
本质就是:抵消选择
比如你选择 \(i \rightarrow j\) 然后发现 \(i \rightarrow k\) 更优,那么我们就让 \(j \rightarrow k\)
只需要在 \(\operatorname{ans}(j - i) \leftarrow k - j \Rightarrow \operatorname{ans}(k - i)\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
priority_queue<int,vector<int>,greater<int>> q;
signed main() {
int n = rd(),ans = 0;
for(int i = 1;i<=n;i++) {
int c = rd();
if(!q.empty() && q.top() < c) ans += c - q.top(),q.pop(),q.push(c);
q.push(c);
}
wt(ans);
return 0;
}
2024/08/20
推荐看番顺序:
凉宫春日的忧郁 \(\rightarrow\) 凉宫春日的消失 \(\rightarrow\) 长门有希酱的消失 \(\rightarrow\) 幸运星
推荐指数: \(\star \star \star \star \star\)
P8868 [NOIP2022] 比赛
题面:
题目描述
小 N 和小 O 会在 2022 年 11 月参加一场盛大的程序设计大赛 NOIP!小 P 会作为裁判主持竞赛。小 N 和小 O 各自率领了一支 \(n\) 个人的队伍,选手在每支队伍内都是从 \(1\) 到 \(n\) 编号。每一个选手都有相应的程序设计水平。具体的,小 N 率领的队伍中,编号为 \(i\)(\(1 \leq i \leq n\))的选手的程序设计水平为 \(a _ i\);小 O 率领的队伍中,编号为 \(i\)(\(1 \leq i \leq n\))的选手的程序设计水平为 \(b _ i\)。特别地,\(\{a _ i\}\) 和 \(\{b _ i\}\) 还分别构成了从 \(1\) 到 \(n\) 的排列。
每场比赛前,考虑到路途距离,选手连续参加比赛等因素,小 P 会选择两个参数 \(l, r\)(\(1 \leq l \leq r \leq n\)),表示这一场比赛会邀请两队中编号属于 \([l, r]\) 的所有选手来到现场准备比赛。在比赛现场,小 N 和小 O 会以掷骰子的方式挑选出参数 \(p, q\)(\(l \leq p \leq q \leq r\)),只有编号属于 \([p, q]\) 的选手才能参赛。为了给观众以最精彩的比赛,两队都会派出编号在 \([p, q]\) 内的、程序设计水平值最大的选手参加比赛。假定小 N 派出的选手水平为 \(m _ a\),小 O 派出的选手水平为 \(m _ b\),则比赛的精彩程度为 \(m _ a \times m _ b\)。
NOIP 总共有 \(Q\) 场比赛,每场比赛的参数 \(l, r\) 都已经确定,但是 \(p, q\) 还没有抽取。小 P 想知道,对于每一场比赛,在其所有可能的 \(p, q\)(\(l \leq p \leq q \leq r\))参数下的比赛的精彩程度之和。由于答案可能非常之大,你只需要对每一场答案输出结果对 \(2 ^ {64}\) 取模的结果即可。
输入格式
第一行包含两个正整数 \(T, n\),分别表示测试点编号和参赛人数。如果数据为样例则保证 \(T = 0\)。
第二行包含 \(n\) 个正整数,第 \(i\) 个正整数为 \(a _ i\),表示小 N 队伍中编号为 \(i\) 的选手的程序设计水平。
第三行包含 \(n\) 个正整数,第 \(i\) 个正整数为 \(b _ i\),表示小 O 队伍中编号为 \(i\) 的选手的程序设计水平。
第四行包含一个正整数 \(Q\),表示比赛场数。
接下来的 \(Q\) 行,第 \(i\) 行包含两个正整数 \(l _ i, r _ i\),表示第 \(i\) 场比赛的参数 \(l, r\)。
输出格式
输出 \(Q\) 行,第 \(i\) 行包含一个非负整数,表示第 \(i\) 场比赛中所有可能的比赛的精彩程度之和对 \(2 ^ {64}\) 取模的结果。
样例 #1
样例输入 #1
0 2 2 1 1 2 1 1 2样例输出 #1
8样例 #2
样例输入 #2
见附件下的 match/match2.in。样例输出 #2
见附件下的 match/match2.ans。样例 #3
样例输入 #3
见附件下的 match/match3.in。样例输出 #3
见附件下的 match/match3.ans。提示
【样例 1 解释】
当 \(p = 1, q = 2\) 的时候,小 N 会派出 \(1\) 号选手,小 O 会派出 \(2\) 号选手,比赛精彩程度为 \(2 \times 2 = 4\)。
当 \(p = 1, q = 1\) 的时候,小 N 会派出 \(1\) 号选手,小 O 会派出 \(1\) 号选手,比赛精彩程度为 \(2 \times 1 = 2\)。
当 \(p = 2, q = 2\) 的时候,小 N 会派出 \(2\) 号选手,小 O 会派出 \(2\) 号选手,比赛精彩程度为 \(1 \times 2 = 2\)。
【样例 2】
该样例满足测试点 \(1 \sim 2\) 的限制。
【样例 3】
该样例满足测试点 \(3 \sim 5\) 的限制。
【数据范围】
对于所有数据,保证:\(1 \leq n, Q \leq 2.5 \times 10 ^ 5\),\(1 \leq l _ i \leq r _ i \leq n\),\(1 \leq a _ i, b _ i \leq n\) 且 \(\{a _ i\}\) 和 \(\{b _ i\}\) 分别构成了>从 \(1\) 到 \(n\) 的排列。
测试点 \(n\) \(Q\) 特殊性质 A 特殊性质 B \(1, 2\) \(\leq 30\) \(\leq 30\) 是 是 \(3, 4, 5\) \(\leq 3,000\) \(\leq 3,000\) 是 是 \(6, 7\) \(\leq 10 ^ 5\) \(\leq 5\) 是 是 \(8, 9\) \(\leq 2.5 \times 10 ^ 5\) \(\leq 5\) 是 是 \(10, 11\) \(\leq 10 ^ 5\) \(\leq 5\) 否 否 \(12, 13\) \(\leq 2.5 \times 10 ^ 5\) \(\leq 5\) 否 否 \(14, 15\) \(\leq 10 ^ 5\) \(\leq 10 ^ 5\) 是 是 \(16, 17\) \(\leq 2.5 \times 10 ^ 5\) \(\leq 2.5 \times 10 ^ 5\) 是 是 \(18, 19\) \(\leq 10 ^ 5\) \(\leq 10 ^ 5\) 是 否 \(20, 21\) \(\leq 2.5 \times 10 ^ 5\) \(\leq 2.5 \times 10 ^ 5\) 是 否 \(22, 23\) \(\leq 10 ^ 5\) \(\leq 10 ^ 5\) 否 否 \(24, 25\) \(\leq 2.5 \times 10 ^ 5\) \(\leq 2.5 \times 10 ^ 5\) 否 否 特殊性质 A:保证 \(a\) 是均匀随机生成的 \(1 \sim n\) 的排列。
特殊性质 B:保证 \(b\) 是均匀随机生成的 \(1 \sim n\) 的排列。
历史版本和线段树(吉司机线段树——SegmentTreeBeats!)
对于每个区间 \([p,q] \in [l,r]\),查询 \(\max_{i = p}^q a_i \times \max_{j = p}^q b_j\) 并累加 \((\operatorname{mod} 2^{64})\)
形式化题意为
给定数组 \(a,b\) ,对于每一个询问 \(l,r\),返回 \(\sum\limits_{i = l}^r \sum\limits_{j = i}^r \max_{p = i}^j a_p \times \max_{q = i}^j b_q (\operatorname{mod}\ 2^{64})\)
首先,我们发现序列最大值会影响到一段区间,我们用单调栈去维护这些区间
然后使用扫描线从 \(1\) 扫到 \(n\)
本题就转化成维护四个操作:
剩下的参考这篇题解
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define ull unsigned long long
int n,q;
const int N = 3e5+5;
#define ls (p << 1)
#define rs (ls | 1)
#define mid ((pl + pr) >> 1)
struct node{
ull taga,tagb,s,sa,sb,h,ha,hb,upd,ans,len;
}t[N<<2];
ull a[N],b[N],ans[N];
void push_up(int p) {
t[p].s = t[ls].s + t[rs].s;
t[p].sa = t[ls].sa + t[rs].sa;
t[p].sb = t[ls].sb + t[rs].sb;
t[p].ans = t[ls].ans + t[rs].ans;
}
void addtag(int p,node d) {
t[p].ans += t[p].s * d.upd + t[p].sa * d.hb + t[p].sb * d.ha + d.h * t[p].len;
t[p].h += t[p].taga * t[p].tagb * d.upd + t[p].taga * d.hb + t[p].tagb * d.ha + d.h;
t[p].ha += t[p].taga * d.upd + d.ha;
t[p].hb += t[p].tagb * d.upd + d.hb;
t[p].s += t[p].sa * d.tagb + t[p].sb * d.taga + d.taga * d.tagb * t[p].len;
t[p].sa += d.taga * t[p].len;
t[p].sb += d.tagb * t[p].len;
t[p].upd += d.upd;
t[p].taga += d.taga;
t[p].tagb += d.tagb;
}
void push_down(int p) {
addtag(ls,t[p]);
addtag(rs,t[p]);
t[p].h = t[p].ha = t[p].hb = t[p].upd = t[p].taga = t[p].tagb = 0;
}
void build(int p,int pl,int pr) {
t[p].len = (pr - pl + 1);
if(pl == pr) return;
build(ls,pl,mid);
build(rs,mid+1,pr);
}
void update(int p,int pl,int pr,int l,int r,ull x,int opt) {
if(l <= pl && pr <= r){
if(opt) addtag(p,(node){0,x,0,0,0,0,0,0,0,0,pr - pl + 1});
else addtag(p,(node){x,0,0,0,0,0,0,0,0,0,pr - pl + 1});
return;
}
push_down(p);
if(l <= mid) update(ls,pl,mid,l,r,x,opt);
if(r > mid) update(rs,mid+1,pr,l,r,x,opt);
push_up(p);
}
ull query(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return t[p].ans;
ull re = 0;
push_down(p);
if(l <= mid) re += query(ls,pl,mid,l,r);
if(r > mid) re += query(rs,mid+1,pr,l,r);
return re;
}
vector<array<int,2>> Q[N];
int sta[N],topa,stb[N],topb;
signed main() {
int T;
scanf("%d %d",&T,&n);
for(int i = 1;i<=n;i++) scanf("%llu",&a[i]);
for(int i = 1;i<=n;i++) scanf("%llu",&b[i]);
scanf("%d",&q);
for(int i = 1;i<=q;i++) {
int l,r;
scanf("%d %d",&l,&r);
Q[r].emplace_back(array<int,2>{l,i});
}
build(1,1,n);
topa = topb = 1;
b[0] = a[0] = n + 1;
for(int i = 1;i<=n;i++) {
while(a[sta[topa]] < a[i]) {
update(1,1,n,sta[topa - 1] + 1,sta[topa],-a[sta[topa]],0);
topa--;
}
update(1,1,n,sta[topa] + 1,i,a[i],0);
sta[++topa] = i;
while(b[stb[topb]] < b[i]) {
update(1,1,n,stb[topb - 1] + 1,stb[topb],-b[stb[topb]],1);
topb--;
}
update(1,1,n,stb[topb] + 1,i,b[i],1);
stb[++topb] = i;
addtag(1,(node){0,0,0,0,0,0,0,0,1,0,0});
for(auto k : Q[i]) ans[k[1]] = query(1,1,n,k[0],i);
}
for(int i = 1;i<=q;i++) printf("%llu\n",ans[i]);
return 0;
}
CF960H Santa's Gift
题面:
题面翻译
给出一棵 \(n\) 个节点的有根树,根为 \(1\)。点 \(2\sim n\) 的父亲为 \(p_2\sim p_n\)。有 \(m\) 种颜色。点 \(i\) 的颜色为 \(f_i\),颜色 \(i\) 的权值为 \(c_i\)。有两种操作共 \(q\) 次:
\(\texttt{1 }x\text{ }y\),将 \(f_x\leftarrow y\)。
\(\texttt{2 }x\),从树中等概率选取一个点 \(i\),得到 \((S_i\times b_x-C)^2\) 的价值。求期望价值。其中 \(S_i\) 表示以 \(i\) 为根的子树中颜色为 \(x\) 的节点数。\(C\) 是给定的常数。
输入格式
第一行四个自然数 \(n,m,q,C\)(\(2\le n\le 5\times 10^4\),\(1\le m,q\le 5\times 10^4\),\(0\le C\le 10^6\))。
第二行 \(n\) 个正整数 \(f_1\sim f_n\)(\(1\le f_i\le m\))。
第三行 \(n-1\) 个正整数为 \(p_2\sim p_n\)(\(1\le p_i\le n\))。
第四行 \(m\) 个正整数 \(b_1\sim b_m\)(\(1\le c_i\le 100\))。
接下来 \(q\) 行每行为一个操作 \(\texttt{1 }x\text{ }y\) 或 \(\texttt{2 }x\)。
输出格式
对于 \(\texttt{2}\) 操作,输出期望。
题目描述
Santa has an infinite number of candies for each of\(m\)flavours. You are given a rooted tree with\(n\)vertices. The root of the tree is the vertex\(1\). Each vertex contains exactly one candy. The\(i\)-th vertex has a candy of flavour\(f_i\).
Sometimes Santa fears that candies of flavour\(k\)have melted. He chooses any vertex\(x\)randomly and sends the subtree of\(x\)to the Bakers for a replacement. In a replacement, all the candies with flavour\(k\)are replaced with a new candy of the same flavour. The candies which are not of flavour\(k\)are left unchanged. After the replacement, the tree is restored.
The actual cost of replacing one candy of flavour\(k\)is\(c_k\)(given for each\(k\)). The Baker keeps the price fixed in order to make calculation simple. Every time when a subtree comes for a replacement, the Baker charges\(C\), no matter which subtree it is and which flavour it is.
Suppose that for a given flavour\(k\)the probability that Santa chooses a vertex for replacement is same for all the vertices. You need to find out the expected value of error in calculating the cost of replacement of flavour\(k\). The error in calculating the cost is defined as follows.
\[$$ Error\ E(k) =\ (Actual Cost\ –\ Price\ charged\ by\ the\ Bakers) ^ 2.$$ </p><p>Note that the actual cost is the cost of replacement of one candy of the flavour $k$ multiplied by the number of candies in the subtree.</p><p>Also, sometimes Santa may wish to replace a candy at vertex $x$ with a candy of some flavour from his pocket.</p><p>You need to handle two types of operations: </p><ul> <li> Change the flavour of the candy at vertex $x$ to $w$. </li><li> Calculate the expected value of error in calculating the cost of replacement for a given flavour $k$$$. \]
输入格式
The first line of the input contains four integers\(n\)(\(2 \leqslant n \leqslant 5 \cdot 10^4\)),\(m\),\(q\),\(C\)(\(1 \leqslant m, q \leqslant 5 \cdot 10^4\),\(0 \leqslant C \leqslant 10^6\)) — the number of nodes, total number of different flavours of candies, the number of queries and the price charged by the Bakers for replacement, respectively.
The second line contains\(n\)integers\(f_1, f_2, \dots, f_n\)(\(1 \leqslant f_i \leqslant m\)), where\(f_i\)is the initial flavour of the candy in the\(i\)-th node.
The third line contains\(n - 1\)integers\(p_2, p_3, \dots, p_n\)(\(1 \leqslant p_i \leqslant n\)), where\(p_i\)is the parent of the\(i\)-th node.
The next line contains\(m\)integers\(c_1, c_2, \dots c_m\)(\(1 \leqslant c_i \leqslant 10^2\)), where\(c_i\)is the cost of replacing one candy of >flavour\(i\).
The next\(q\)lines describe the queries. Each line starts with an integer\(t\)(\(1 \leqslant t \leqslant 2\)) — the type of the query.
If\(t = 1\), then the line describes a query of the first type. Two integers\(x\)and\(w\)follow (\(1 \leqslant x \leqslant n\),\(1 \leqslant w \leqslant m\)), it means that Santa replaces the candy at vertex\(x\)with flavour\(w\).
Otherwise, if\(t = 2\), the line describes a query of the second type and an integer\(k\)(\(1 \leqslant k \leqslant m\)) follows, it means that you should print the expected value of the error in calculating the cost of replacement for a given flavour\(k\).
The vertices are indexed from\(1\)to\(n\). Vertex\(1\)is the root.
输出格式
Output the answer to each query of the second type in a separate line.
Your answer is considered correct if its absolute or relative error does not exceed\(10^{-6}\).
Formally, let your answer be\(a\), and the jury's answer be\(b\). The checker program considers your answer correct if and only if\(\frac{|a-b|}{max(1,b)}\leqslant 10^{-6}\).
样例 #1
样例输入 #1
3 5 5 7 3 1 4 1 1 73 1 48 85 89 2 1 2 3 1 2 3 2 1 2 3样例输出 #1
2920.333333333333 593.000000000000 49.000000000000 3217.000000000000提示
For\(1\)-st query, the error in calculating the cost of replacement for flavour\(1\)if vertex\(1\),\(2\)or\(3\)is chosen are\(66^2\),\(66^2\)and\((-7)^2\)respectively. Since the probability of choosing any vertex is same, therefore the expected value of error is\(\frac{66^2+66^2+(-7)^2}{3}\).
Similarly, for\(2\)-nd query the expected value of error is\(\frac{41^2+(-7)^2+(-7)^2}{3}\).
After\(3\)-rd query, the flavour at vertex\(2\)changes from\(1\)to\(3\).
For\(4\)-th query, the expected value of error is\(\frac{(-7)^2+(-7)^2+(-7)^2}{3}\).
Similarly, for\(5\)-th query, the expected value of error is\(\frac{89^2+41^2+(-7)^2}{3}\).
遇到式子不要慌,第一步:
拆式子!
这个 \(S_i\) 怎么办? 将 \(S_i\) 可能影响到的节点全部加上 \(1\),
也就是说,在根节点到 \(x\) 节点的路径区间加
维护 区间和 和 区间平方和
区间和不在这里讲解
区间平方和如何处理?
因为 \(\sum(x + d)^2 = \sum (x^2 + 2dx + d ^ 2)\)
所以 \(\Delta = \sum(x + d)^2 - \sum x^2 =\sum (2dx + d ^ 2) = 2d\sum x + d \times len\)
就解决了,这应该是最好写的ds紫题
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 5e4 + 5;
int n,m,Q,C,f[N],b[N];
int head[N],nxt[N<<1],to[N<<1],cnt;
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
int fa[N],top[N],siz[N],dep[N],son[N],num,id[N];
void dfs1(int x,int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = dep[f] + 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs1(y,x);
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
int rt[N * 100],ls[N*100],rs[N * 100],tag[N * 100],s[N * 100],v[N * 100];
#define ls (ls[p])
#define rs (rs[p])
#define mid ((pl + pr) >> 1)
void dfs2(int x,int topx) {
top[x] = topx;
id[x] = ++num;
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
void push_up(int p) {
s[p] = s[ls] + s[rs];
v[p] = v[ls] + v[rs];
}
void addtag(int &p,int pl,int pr,int d) {
if(!p) p = ++cnt;
s[p] += 2 * d * v[p] + (pr - pl + 1) * d * d;
v[p] += d * (pr - pl + 1);
tag[p] += d;
}
void push_down(int p,int pl,int pr) {
if(tag[p]) {
addtag(ls,pl,mid,tag[p]);
addtag(rs,mid+1,pr,tag[p]);
tag[p] = 0;
}
}
void update(int &p,int pl,int pr,int l,int r,int d) {
if(!p) p = ++cnt;
if(l <= pl && pr <= r) {addtag(p,pl,pr,d);return;}
push_down(p,pl,pr);
if(l <= mid) update(ls,pl,mid,l,r,d);
if(r > mid) update(rs,mid+1,pr,l,r,d);
push_up(p);
}
void update(int p,int x,int d,int y = 1) {
while(top[x] ^ top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x,y);
update(rt[p],1,n,id[top[x]],id[x],d);
x = fa[top[x]];
}
if(dep[x] > dep[y]) swap(x,y);
update(rt[p],1,n,id[x],id[y],d);
}
void update() {
int x = rd(),y = rd();
update(f[x],x,-1);
f[x] = y;
update(f[x],x,1);
}
void query() {
int x = rd();
printf("%.10lf\n",(double)(b[x] * b[x] * s[rt[x]] - 2 * b[x] * C * v[rt[x]]) / (double)(n) + (double)C * C);
}
signed main() {
init();
n = rd(),m = rd(),Q = rd(),C = rd();
for(int i = 1;i<=n;i++) f[i] = rd();
for(int i = 2;i<=n;i++) {
int p = rd();
add(i,p),add(p,i);
}
for(int i = 1;i<=m;i++) b[i] = rd();
dfs1(1,0);dfs2(1,1);
for(int i = 1;i<=n;i++) update(f[i],i,1);
while(Q--) {
int opt = rd();
switch(opt) {
case 1:
update();
break;
case 2:
query();
break;
default:
break;
}
}
return 0;
}
2024/08/21
P2495 [SDOI2011] 消耗战
题面:
题目描述
在一场战争中,战场由 \(n\) 个岛屿和 \(n-1\) 个桥梁组成,保证每两个岛屿间有且仅有一条路径可达。现在,我军已经侦查到敌军的总部在编号为 \(1\) 的岛屿,而且他们已经没有足够多的能源维系战斗,我军胜利在望。已知在其他 \(k\) 个岛屿上有丰富能源,为了防止敌军获取能源,我军的任务是炸毁一些桥梁,使得敌军不能到达任何能源丰富的岛屿。由于不同桥梁的材质和结构不同,所以炸毁不同的桥梁有不同的代价,我军希望在满足目标的同时使得总代价最小。
侦查部门还发现,敌军有一台神秘机器。即使我军切断所有能源之后,他们也可以用那台机器。机器产生的效果不仅仅会修复所有我军炸毁的桥梁,而且会重新随机资源分布(但可以保证的是,资源不会分布到 \(1\) 号岛屿上)。不过侦查部门还发现了这台机器只能够使用 \(m\) 次,所以我们只需要把每次任务完成即可。
输入格式
第一行一个整数 \(n\),表示岛屿数量。
接下来 \(n-1\) 行,每行三个整数 \(u,v,w\) ,表示 \(u\) 号岛屿和 \(v\) 号岛屿由一条代价为 \(w\) 的桥梁直接相连。
第 \(n+1\) 行,一个整数 \(m\) ,代表敌方机器能使用的次数。
接下来 \(m\) 行,第 \(i\) 行一个整数 \(k_i\) ,代表第 \(i\) 次后,有 \(k_i\) 个岛屿资源丰富。接下来 \(k_i\) 个整数 \(h_1,h_2,..., h_{k_i}\) ,表示资源丰富岛屿的编号。
输出格式
输出共 \(m\) 行,表示每次任务的最小代价。
样例 #1
样例输入 #1
10 1 5 13 1 9 6 2 1 19 2 4 8 2 3 91 5 6 8 7 5 4 7 8 31 10 7 9 3 2 10 6 4 5 7 8 3 3 9 4 6样例输出 #1
12 32 22提示
数据规模与约定
- 对于 \(10\%\) 的数据,\(n\leq 10, m\leq 5\) 。
- 对于 \(20\%\) 的数据,\(n\leq 100, m\leq 100, 1\leq k_i\leq 10\) 。
- 对于 \(40\%\) 的数据,\(n\leq 1000, 1\leq k_i\leq 15\) 。
- 对于 \(100\%\) 的数据,\(2\leq n \leq 2.5\times 10^5, 1\leq m\leq 5\times 10^5, \sum k_i \leq 5\times 10^5, 1\leq k_i< n, h_i\neq 1, 1\leq u,v\leq n, 1\leq w\leq 10^5\)。
虚树由此而来
为什么有了虚树?
对于所以操作,均摊下来时并不大时,虚树就派上了用场
我们在本题发现 \(\Sigma k\) 与 \(m\) 是等阶的数据范围
如果按照朴素的解法,我们对于每一次操作,都去跑一遍树上dp
复杂度直接爆炸!
需要发现的是,每一次需要dp的点均摊下来其实很有限
我们只针对这些需要dp的点dp就可以了,
不去多管闲事。
虚树登场
建虚树的方法来自这个博客,讲的非常好
如何建立虚树
最右链是虚树构建的一条分界线,表明其左侧部分的虚树已经完成构建。我们使用栈\(stak\)来维护所谓的最右链,\(top\)为栈顶位置。值得注意的是,最右链上的边并没有被加入虚树,这是因为在接下来的过程中随时会有某个\(lca\)插到最右链中。
初始无条件将第一个询问点加入栈\(stak\)中。
将接下来的所有询问点顺次加入,假设该询问点为\(now\),\(lc\)为该点和栈顶点的最近公共祖先即\(lc=lca(stak[top],now)\)。
由于\(lc\)是\(stak[top]\)的祖先,\(lc\)必然在我们维护的最右链上。
考虑\(lc\)和\(stak[top]\)及栈中第二个元素\(stak[top-1]\)的关系。
情况一
\(lc=stak[top]\),也就是说,\(now\)在\(stak[top]\)的子树中
这时候,我们只需把\(now\)入栈,即把它加到最右链的末端即可。
情况二
\(lc\)在\(stak[top]\)和\(stak[top-1]\)之间。
显然,此时最右链的末端从\(stak[top-1]->stak[top]\)变成了\(stak[top-1]->lc->stak[top]\),我们需要做的,首先是把边\(lc-stak[top]\)加入虚树,然后,把\(stak[top]\)出栈,把\(lc\)和\(now\)入栈。
情况三
\(lc=stak[top-1]\)。
这种情况和第二种情况大同小异,唯一的区别就是\(lc\)不用入栈了。
情况四
此时有\(dep[lc]<dep[stak[top-1]]\)。\(lc\)已经不在\(stak[top-1]\)的子树中了,甚至也未必在\(stak[top-2],stak[top-3]......\)的子树中。
以图中为例,最右链从\(stak[top-3]->stak[top-2]->stak[top-1]->stak[top]\)变成了\(stak[top-3]->lc->now\)。我们需要循环依次将最右链的末端剪下,将被剪下的边加入虚树,直到不再是情况四。
就上图而言,循环会持续两轮,将\(stak[top],stak[top-1]\)依次出栈,并且把边\(stak[top-1]-stak[top],stak[top-2]-stak[top-1]\)加入虚树中。随后通过>情况二完成构建。
当最后一个询问点加入之后,再将最右链加入虚树,即可完成构建。
一些问题
- 如果栈\(stak\)中仅仅有一个元素,此时\(stak[top-1]\)是否会出问题?
对于栈\(stak\),我们从\(1\)开始储存。那么在这种情况下,\(stak[top-1]=0\),并且\(dep[0]=0\)。此时\(dep[lc]<dep[stak[top-1]]\)恒成立。也就是说,>\(stak[0]\)扮演了深度最小的哨兵,确保了程序只会进入情况一和二。
- 如何在一次询问结束后清空虚树?
不能直接对图进行清空,否则复杂度会退化到\(O(n)\)的复杂度,这是我们无法承受的。在\(dfs\)的过程中每当访问完一个结点就进行清空即可。
如若侵权,请在该评论区联系我,即删
该部分的代码(简单分讨):
bool cmp(int x,int y) {return id[x] < id[y];}
---------------------------------------------
sort(a.begin(),a.end(),cmp);
st[tp = 1] = a[0];
for(int i = 1;i<k;i++) {
int now = a[i];
int LCA = lca(now,st[tp]);
while(1)
if(dep[LCA] >= dep[st[tp - 1]]) {
if(LCA != st[tp]) {
G.add(LCA,st[tp],0);
if(LCA != st[tp - 1])
st[tp] = LCA;
else
tp--;
}
break;
}else {
G.add(st[tp - 1],st[tp],0);
tp--;
}
st[++tp] = now;
}
本题中,我们要求 \(1\) 节点(根节点)与关键点互不连通的最小代价
我们用 \(minv\) 数组存储每个点与根节点不连通的最小代价
这部分的代码(我个人喜欢树剖求LCA,这个部分和树剖放在了一起):
void dfs1(int x,int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = dep[f] + 1;
for(int i = g.head[x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(y ^ f) {
minv[y] = min(minv[x],g.val[i]); <------
dfs1(y,x);
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
对于答案,我们在虚树上统计
如果该点不是关键点,那么我们需要知道ta与子树内关键点不连通的最小代价、和ta本身与根节点不连通的代价,即:
如果该点是关键点,那么我们必须切断该点到根节点的一条边,这条边可能是 \(x \rightarrow fa\) 的 边、或是 \(fa \leadsto root\) 中的边(这个边我们在上面的式子中已经求过了)
所以:
答案为:\(cost_{root}\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 5e5 + 5,inf = 0x3f3f3f3f3f3f3f3fLL;
struct edge{
int head[N],nxt[N<<1],to[N<<1],val[N<<1],cnt;
edge() {memset(head,-1,sizeof(head));cnt = 0;}
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
};
edge g,G;
int n,q,k;
int fa[N],siz[N],top[N],dep[N],id[N],son[N],num,minv[N];
void dfs1(int x,int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = dep[f] + 1;
for(int i = g.head[x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(y ^ f) {
minv[y] = min(minv[x],g.val[i]);
dfs1(y,x);
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
void dfs2(int x,int topx) {
top[x] = topx;
id[x] = ++num;
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = g.head[x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
int lca(int x,int y) {
while(top[x] ^ top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x,y);
x = fa[top[x]];
}
return dep[x] < dep[y] ? x : y;
}
bool cmp(int x,int y) {return id[x] < id[y];}
int st[N],tp;
bool query[N];
int dfs(int x) {
int sum = 0;
int tmp = 0;
for(int i = G.head[x];~i;i = G.nxt[i]) {
int y = G.to[i];
sum += dfs(y);
}
if(query[x])
tmp = minv[x];
else
tmp = min(minv[x],sum);
query[x] = false;
G.head[x] = -1;
return tmp;
}
void solve() {
k = rd();
vector<int> a(k);
for(int i = 0;i<k;i++) a[i] = rd();
for(int i = 0;i<k;i++) query[a[i]] = 1;
sort(a.begin(),a.end(),cmp);
st[tp = 1] = a[0];
for(int i = 1;i<k;i++) {
int now = a[i];
int LCA = lca(now,st[tp]);
while(1)
if(dep[LCA] >= dep[st[tp - 1]]) {
if(LCA != st[tp]) {
G.add(LCA,st[tp],0);
if(LCA != st[tp - 1])
st[tp] = LCA;
else
tp--;
}
break;
}else {
G.add(st[tp - 1],st[tp],0);
tp--;
}
st[++tp] = now;
}
while(--tp)
G.add(st[tp],st[tp + 1],0);
wt(dfs(st[1]));
putchar('\n');
}
signed main() {
minv[1] = inf;
n = rd();
for(int i = 1,u,v,w;i<n;i++) {
u = rd(),v = rd(),w = rd();
g.add(u,v,w);g.add(v,u,w);
}
dfs1(1,0);dfs2(1,1);
q = rd();
while(q--) solve();
return 0;
}
题外话:
这是树剖和倍增求LCA的区别


哪个是倍增不用我多说吧?
CF786B Legacy
题面:
题面翻译
Rick 和他的同事们做出了一种新的带放射性的婴儿食品(???根据图片和原文的确如此...),与此同时很多坏人正追赶着他们。因此 Rick 想在坏人们捉到他之前把他的遗产留给 Morty。
在宇宙中一共有 \(n\) 个星球标号为 \(1 \sim n\)。Rick 现在身处于标号为 \(s\) 的星球(地球)但是他不知道 Morty 在哪里。
众所周知,Rick 有一个传送枪,他用这把枪可以制造出一个从他所在的星球通往其他星球(也包括自己所在的星球)的单行道路。但是由于他还在用免费版,因此这把枪的使用是有限制的。
默认情况下他不能用这把枪开启任何传送门。在网络上有 \(q\) 个售卖这些传送枪的使用方案。每一次你想要实施这个方案时你都可以购买它,但是每次购买后只能使用一次。每个方案的购买次数都是无限的。
网络上一共有三种方案可供购买:
- 开启一扇从星球 \(v\) 到星球 \(u\) 的传送门;
- 开启一扇从星球 \(v\) 到标号在 \([l,r]\) 区间范围内任何一个星球的传送门。(即这扇传送门可以从一个星球出发通往多个星球)
- 开启一扇从标号在 \([l,r]\) 区间范围内任何一个星球到星球 \(v\) 的传送门。(即这扇传送门可以从多个星球出发到达同一个星球)
Rick 并不知道 Morty 在哪儿,但是 Unity 将要通知他 Morty 的具体位置,并且他想要赶快找到通往所有星球的道路各一条并立刻出发。因此对于每一个星球(包括地球本身)他想要知道从地球到那个星球所需的最小钱数。
输入数据:
输入数据的第一行包括三个整数 \(n\),\(q\) 和 \(s\) 分别表示星球的数目,可供购买的方案数目以及地球的标号。
接下来的 \(q\) 行表示 \(q\) 种方案。
- 输入
1 v u w表示第一种方案,其中 \(v,u\) 意思同上,\(w\) 表示此方案价格。- 输入
2 v l r w表示第二种方案,其中 \(v,l,r\) 意思同上,\(w\) 表示此方案价格。- 输入
3 v l r w表示第三种方案,其中 \(v,l,r\) 意思同上,\(w\) 表示此方案价格。输出格式:
输出一行用空格隔开的 \(n\) 个整数分别表示从地球到第 \(i\) 个星球所需的最小钱数。如果不能到达那个星球,输出-1。
说明:
在第一组测试样例里,Rick 可以先购买第 \(4\) 个方案再购买第 \(2\) 个方案从而到达标号为 \(2\) 的星球.【数据范围】
对于 \(100\%\) 的数据,\(1\le n,q \le 10^5\),\(1\le w \le 10^9\)题目描述
Rick and his co-workers have made a new radioactive formula and a lot of bad guys are after them. So Rick wants to give his legacy to Morty before bad guys catch them.
There are\(n\)planets in their universe numbered from\(1\)to\(n\). Rick is in planet number\(s\)(the earth) and he doesn't know where Morty is. As we all know, Rick owns a portal gun. With this gun he can open one-way portal from a planet he is in to any other planet (including that planet). But there are limits on this gun because he's still using its free trial.
By default he can not open any portal by this gun. There are\(q\)plans in the website that sells these guns. Every time you purchase a plan you can only use it once but you can purchase it again if you want to use it more.
Plans on the website have three types:
- With a plan of this type you can open a portal from planet\(v\)to planet\(u\).
- With a plan of this type you can open a portal from planet\(v\)to any planet with index in range\([l,r]\).
- With a plan of this type you can open a portal from any planet with index in range\([l,r]\)to planet\(v\).
Rick doesn't known where Morty is, but Unity is going to inform him and he wants to be prepared for when he finds and start his journey immediately. So for each planet (including earth itself) he wants to know the minimum amount of money he needs to get from earth to that planet.
输入格式
The first line of input contains three integers\(n\),\(q\)and\(s\)(\(1<=n,q<=10^{5}\),\(1<=s<=n\)) — number of planets, number of plans and index of earth respectively.
The next\(q\)lines contain the plans. Each line starts with a number\(t\), type of that plan (\(1<=t<=3\)). If\(t=1\)then >it is followed by three integers\(v\),\(u\)and\(w\)where\(w\)is the cost of that plan (\(1<=v,u<=n\),\(1<=w<=10^{9}\)). Otherwise it is followed by four integers\(v\),\(l\),\(r\)and\(w\)where\(w\)is the cost of that plan (\(1<=v<=n\),\(1<=l<=r<=n\),\(1<=w<=10^{9}\)).
输出格式
In the first and only line of output print\(n\)integers separated by spaces.\(i\)-th of them should be minimum money to get >from earth to\(i\)-th planet, or\(-1\)if it's impossible to get to that planet.
样例 #1
样例输入 #1
3 5 1 2 3 2 3 17 2 3 2 2 16 2 2 2 3 3 3 3 1 1 12 1 3 3 17样例输出 #1
0 28 12样例 #2
样例输入 #2
4 3 1 3 4 1 3 12 2 2 3 4 10 1 2 4 16样例输出 #2
0 -1 -1 12提示
In the first sample testcase, Rick can purchase\(4\)th plan once and then\(2\)nd plan in order to get to get to planet number\(2\).
线段树优化建图的典典典典题
我们苦恼:
- 如何让一个点连向一个区间内所有的点
- 如何让一个区间内所有的点连向一个点
区间,嗯?区间,嗯!
解决区间!去吧!线段树,就决定是你了!
*线段树使用了分治
先来思考如何让一个点只有一条出边,却能连多个点
地球人都知道,给这多个点(特指目标点)建个超级源点嘛!
让这个点和超级源点相连就好了!
所以,我们利用线段树上的节点做超级源点
那么,我们要连一个区间的点,原需要 \(\mathcal{O}(n)\) 次连边,现只需要 \(\mathcal{O}(\log n)\) 次连边。
但是,光一个线段树肯定不行
这题是建有向边,能卖你无向图?迪杰斯特拉的时候,点不得到处跑
自然,线段树上也应该有方向!
这个博主的 blog 给了我很大帮助!感谢
我们先考虑点连区间 :
上图!
我称之为分散树(\(\color{blue}{segOUT}\))
我们将一个点 \(u\) 连上这个区间 \([l,r]\) 的源点,
这个点 \(u\) 自然可以有路径指向 \([l,r]\) 中每个点
然后是区间连点:
上图!
我称之为汇聚树(\(\color{red}{segIN}\))
我们将这个区间 \([l,r]\) 汇聚到源点,然后这个源点指向了 \(u\),\([l,r]\) 的每个点都有路径指向 \(u\)
!!注意Tip:
- 因为是建图,所以线段树上的叶子节点就是对应指向的节点(很重要,要拿来分析空间!)
- 线段树上每一条边,边权都是 \(0\)(Zero would be nice) (因为方案 \(2,3\) 是购买一次可以解决 \(n\) 条线路
国内充值VIP现状)
时间复杂度就不分析了,因为主要问题在于减少暴力连边次数,
我们已经解决了!
那么重头戏!空间复杂度分析
首先,我们建了多少点?
我们可以按满二叉树算,那么一个线段树我们建的源点有 \(\mathcal{O}(N - 1)\) 个(不会的烦请自行百度)
我们开了两个线段树,建了 \(\mathcal{O}(2N - 2)\) 个
那么总开点数为 \(\mathcal{O}(3N)\)
因为每次操作只会连 \(\mathcal{O}(\log n)\) 条边,线段树上还有 \(\mathcal{O}(n\log n)\) 条边,
所以共需要存约 \(\mathcal{O}(q\log n + 2n\log n)\) 条边
这样本题就彻底结束了!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5,M = 3e5+5;
int n,q,s;
int head[M],to[N * 20],nxt[N * 20],val[N * 20],cnt,po;
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
#define mid ((pl + pr) >> 1)
int ls[M * 20],rs[M * 20];
namespace segIN{
int rt;
void build(int &p,int pl,int pr){
if(pl == pr) {
p = pl;
return;
}
p = ++po;
build(ls[p],pl,mid);
build(rs[p],mid+1,pr);
add(ls[p],p,0);
add(rs[p],p,0);
}
void update(int p,int pl,int pr,int f,int v,int l,int r) {
if(l <= pl && pr <= r) {
add(p,f,v);
return;
}
if(l <= mid) update(ls[p],pl,mid,f,v,l,r);
if(r > mid) update(rs[p],mid+1,pr,f,v,l,r);
}
}
namespace segOUT{
int rt;
void build(int &p,int pl,int pr) {
if(pl == pr) {
p = pl;
return;
}
p = ++po;
build(ls[p],pl,mid);
build(rs[p],mid+1,pr);
add(p,ls[p],0);
add(p,rs[p],0);
}
void update(int p,int pl,int pr,int f,int v,int l,int r) {
if(l <= pl && pr <= r) {
add(f,p,v);
return;
}
if(l <= mid) update(ls[p],pl,mid,f,v,l,r);
if(r > mid) update(rs[p],mid+1,pr,f,v,l,r);
}
}
#undef mid
void SigToSig(){
int u = rd(),v = rd(),w = rd();
add(u,v,w);
}
void SigToRan() {
int v = rd(),l = rd(),r = rd(),w = rd();
segOUT::update(segOUT::rt,1,n,v,w,l,r);
}
void RanToSig() {
int v = rd(),l = rd(),r = rd(),w = rd();
segIN::update(segIN::rt,1,n,v,w,l,r);
}
const int inf = 0x3f3f3f3f3f3f3f3fLL;
int dis[M];
bool vis[M];
priority_queue<array<int,2>,vector<array<int,2>>,greater<array<int,2>>> Q;
void dij(int s) {
memset(dis,0x3f,sizeof(dis));
dis[s] = 0;
Q.emplace(array<int,2>{0,s});
while(Q.size()) {
array<int,2> t = Q.top();
Q.pop();
if(vis[t[1]]) continue;
vis[t[1]] = true;
for(int i = head[t[1]];~i;i = nxt[i]) {
int y = to[i],w = val[i];
if(dis[y] > dis[t[1]] + w) {
dis[y] = dis[t[1]] + w;
Q.emplace(array<int,2>{dis[y],y});
}
}
}
}
signed main() {
init();
n = rd(),q = rd(),s = rd();
po = n;
segIN::build(segIN::rt,1,n);
segOUT::build(segOUT::rt,1,n);
while(q--) {
int opt = rd();
switch(opt) {
case 1:
SigToSig();
break;
case 2:
SigToRan();
break;
case 3:
RanToSig();
break;
default:
puts("Error!");
exit(0);
break;
}
}
dij(s);
for(int i = 1;i<=n;i++)
wt((dis[i] == inf) ? -1 : dis[i]),putchar(' ');
return 0;
}
2024/08/22
今日运势:
有点小累,早上好像没睡醒
LOJ#6039. 「雅礼集训 2017 Day5」珠宝 /「NAIPC2016」Jewel Thief
决策单调性典题
首先,暴力dp肯定是不行的
那么观察数据范围,发现 \(C \leq 300\) 惊人的小
肯定在 \(C\) 上做文章,
我们按 \(C\) 来分组,对于每一组,可以得到一个贪心策略:
体积相同,价高者优先!
我们在每个 \(C\) 上排序 价格 \(大 \leadsto 小\) 并做前缀和
但是复杂度并没有改善。
因为在一个 \(C-class\) 中,每个物品占的体积相同(即模 \(C\) 同余)
又因为越往后选性价比越低,所以不妨猜其有决策单调性
参考:这个博客
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 305,M = 5e4+5;
int n,k,maxn,nw;
vector<int> w[N];
int f[M],g[M],dp[M];
void CDQ(int l,int r,int x,int y) {
if(l > r) return;
int mid = (l + r) >> 1;
f[mid] = g[mid];
int id = mid;
for(int i = x;i <= y && i < mid;i++){
if(mid - i > w[nw].size()) continue;
int k = g[i] + w[nw][mid - i - 1];
if(k > f[mid]) f[mid] = k,id = i;
}
CDQ(l,mid - 1,x,id);CDQ(mid+1,r,id,y);
}
signed main() {
n = rd(),k = rd();
for(int i = 1,c,v;i<=n;i++){
c = rd(),v = rd();
w[c].emplace_back(v);
maxn = max(maxn,c);
}
for(int i = 1;i<=maxn;i++) {
if(w[i].empty()) continue;
sort(w[i].begin(),w[i].end(),[&](int a,int b) {return a > b;});
for(int j = 1;j<w[i].size();j++) w[i][j] += w[i][j - 1];
}
for(int i = maxn;i;i--) {
if(w[i].empty()) continue;
nw = i;
for(int tot = 0,j = 0;j < i;j++,tot = 0) {
for(int s = j;s <= k;s += i) g[++tot] = dp[s];
CDQ(1,tot,1,tot);
for(int s = j,h = 1;s <= k;s += i,h++) dp[s] = f[h];
}
for(int j = 1;j<=k;j++) dp[j] = max(dp[j],dp[j - 1]);
}
for(int i = 1;i<=k;i++) wt(dp[i]),putchar(' ');
return 0;
}
P3224 [HNOI2012] 永无乡
题面:
题目描述
永无乡包含 \(n\) 座岛,编号从 \(1\) 到 \(n\) ,每座岛都有自己的独一无二的重要度,按照重要度可以将这 \(n\) 座岛排名,名次用 \(1\) 到 \(n\) 来表示。某些岛之间由巨大的桥连接,通过桥可以从一个岛到达另一个岛。如果从岛 \(a\) 出发经过若干座(含 \(0\) 座)桥可以 到达岛 \(b\) ,则称岛 \(a\) 和岛 \(b\) 是连通的。
现在有两种操作:
B x y表示在岛 \(x\) 与岛 \(y\) 之间修建一座新桥。
Q x k表示询问当前与岛 \(x\) 连通的所有岛中第 \(k\) 重要的是哪座岛,即所有与岛 \(x\) 连通的岛中重要度排名第 \(k\) 小的岛是哪座,请你输出那个岛的编号。输入格式
第一行是用空格隔开的两个整数,分别表示岛的个数 \(n\) 以及一开始存在的桥数 \(m\)。
第二行有 \(n\) 个整数,第 \(i\) 个整数表示编号为 \(i\) 的岛屿的排名 \(p_i\)。
接下来 \(m\) 行,每行两个整数 \(u, v\),表示一开始存在一座连接编号为 \(u\) 的岛屿和编号为 \(v\) 的岛屿的桥。
接下来一行有一个整数,表示操作个数 \(q\)。
接下来 \(q\) 行,每行描述一个操作。每行首先有一个字符 \(op\),表示操作类型,然后有两个整数 \(x, y\)。
- 若 \(op\) 为
Q,则表示询问所有与岛 \(x\) 连通的岛中重要度排名第 \(y\) 小的岛是哪座,请你输出那个岛的编号。- 若 \(op\) 为
B,则表示在岛 \(x\) 与岛 \(y\) 之间修建一座新桥。输出格式
对于每个询问操作都要依次输出一行一个整数,表示所询问岛屿的编号。如果该岛屿不存在,则输出 \(-1\) 。
样例 #1
样例输入 #1
5 1 4 3 2 5 1 1 2 7 Q 3 2 Q 2 1 B 2 3 B 1 5 Q 2 1 Q 2 4 Q 2 3样例输出 #1
-1 2 5 1 2提示
数据规模与约定
- 对于 \(20\%\) 的数据,保证 \(n \leq 10^3\), \(q \leq 10^3\)。
- 对于 \(100\%\) 的数据,保证 \(1 \leq m \leq n \leq 10^5\), \(1 \leq q \leq 3 \times 10^5\),\(p\) 为一个 \(1 \sim n\) 的排列,\(op \in \{\texttt Q, \texttt B\}\),\(1 \leq u, v, x, y \leq n\)。
一眼线段树合并,比较板子
我们要在连通块中找出排名第 \(k\) 的编号,
求排名第 \(k\) 肯定是线段树二分,
连通块 的所有编号的价值得放在一个数据结构里
说实话,真的非常显然,使用并查集,将并查集中的根作为线段树的根
建桥操作:就是 并查集合并 + 线段树合并
先用并查集把连通块连起来,再将两个连通块的信息整合到一起
查询的时候对连通块的头作为根的线段树二分
由于太显然,已经不知道还有讲什么
那么直接放代码
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5;
int n,m,s[N];
void init() {for(int i = 1;i<=n;i++) s[i] = i;}
int rt[N],ls[N * 50],rs[N * 50],w[N * 50],cnt;
#define mid ((pl + pr) >> 1)
int _w[N];
void push_up(int p) {w[p] = w[ls[p]] + w[rs[p]];}
void update(int &p,int pl,int pr,int k) {
if(!p) p = ++cnt;
if(pl == pr) {w[p]++;return;}
if(k <= mid) update(ls[p],pl,mid,k);
else update(rs[p],mid+1,pr,k);
push_up(p);
}
int merge(int x,int y,int pl,int pr) {
if(!x || !y) return x + y;
if(pl == pr) {
w[x] += w[y];
return x;
}
ls[x] = merge(ls[x],ls[y],pl,mid);
rs[x] = merge(rs[x],rs[y],mid+1,pr);
push_up(x);
return x;
}
int query(int p,int pl,int pr,int k) {
if(pl == pr) return _w[pl];
if(k <= w[ls[p]]) return query(ls[p],pl,mid,k);
else if(k > w[ls[p]]) return query(rs[p],mid + 1,pr,k - w[ls[p]]);
return -1;
}
int find(int x) {
if(s[x] ^ x) s[x] = find(s[x]);
return s[x];
}
void merge(int x,int y) {
x = find(x),y = find(y);
if(x ^ y) {
s[y] = x;
rt[x] = merge(rt[x],rt[y],1,n);
}
}
signed main() {
n = rd(),m = rd();
init();
for(int i = 1;i<=n;i++) {
int W = rd();
_w[W] = i;
update(rt[i],1,n,W);
}
for(int i = 1;i<=m;i++) {
int x = rd(),y = rd();
merge(x,y);
}
int q = rd();
while(q--) {
char opt = getchar();
while(opt != 'Q' && opt != 'B') opt = getchar();
int x = rd(),y = rd();
switch(opt) {
case 'Q':
wt(query(rt[find(x)],1,n,y));
putchar('\n');
break;
case 'B':
merge(x,y);
break;
}
}
return 0;
}
P6185 [NOI Online #1 提高组] 序列
题面:
题目背景
由于本题数据较难构造,所以无法保证卡掉所有错误做法。
题目描述
小 D 有一个长度为 \(n\) 的整数序列 \(a_{1 \dots n}\),她想通过若干次操作把它变成序列 \(b_i\)。
小 D 有 \(m\) 种可选的操作,第 \(i\) 种操作可使用三元组 \((t_i,u_i,v_i)\) 描述:若 \(t_i=1\),则她可以使 \(a_{u_i}\) 与 \(a_{v_i}\) 都加一或都减一;若 \(t_i=2\),则她可以使 \(a_{u_i}\) 减一、\(a_{v_i}\) 加一,或是 \(a_{u_i}\) 加一、\(a_{v_i}\) 减一,因此当 \(u_i=v_i\) 时,这种操作相当于没有操作。
小 D 可以以任意顺序执行操作,且每种操作都可进行无限次。现在给定序列与所有操作,请你帮她判断是否存在一种方案能将 \(a_i\) 变为 \(b_i\)。题目保证两个序列长度都为 \(n\)。若方案存在请输出
YES,否则输出NO。输入格式
本题输入文件包含多组数据。
第一行一个正整数 \(T\) 表示数据组数。对于每组数据:
第一行两个整数 \(n,m\),表示序列长度与操作种数。
第二行 \(n\) 个整数表示序列 \(a_i\)。
第三行 \(n\) 个整数表示序列 \(b_i\)。
接下来 \(m\) 行每行三个整数 \(t_i,u_i,v_i\),第 \(i\) 行描述操作 \(i\)。
注意:同一个三元组 \((t_i,u_i,v_i)\) 可能在输入中出现多次。
输出格式
对于每组数据输出一行一个字符串
YES或NO表示答案。样例 #1
样例输入 #1
3 1 1 1 3 1 1 1 2 3 1 2 4 5 1 1 2 2 1 2 1 1 2 3 3 1 2 3 5 5 4 1 1 2 1 1 3 2 2 3样例输出 #1
YES YES YES提示
样例 1 解释
第一组数据:使用一次操作 \(1\)。
第二组数据:使用三次操作 \(1\)。
第三组数据:使用三次操作 \(1\),令 \(a_1,a_2\) 都增加 \(3\),再使用一次操作 \(2\),令 \(a_1,a_3\) 都增加 \(1\)。
数据范围与提示
对于测试点 \(1 \sim 5\):\(n=2\),\(m=1\),\(a_i,b_i \le 99\),\(u_1 \ne v_1\),\(t_1=1\)。
对于测试点 \(6 \sim 10\):\(n=2\),\(m=1\),\(a_i,b_i \le 99\),\(u_1 \ne v_1\),\(t_1=2\)。
对于测试点 \(11 \sim 12\):\(n=2\),\(a_i,b_i \le 99\),\(u_i \ne v_i\)。
对于测试点 \(13 \sim 16\):\(t_i=2\)。
对于测试点 \(17\):\(n,m \le 20\)。
对于测试点 \(18\):\(n,m \le 10^3\)。
对于所有测试点:\(1 \le T \le 10\),\(1 \le n,m \le 10^5\),\(1 \le a_i,b_i \le 10^9\),\(t_i \in \{1,2\}\),\(1\le u_i,v_i \le n\)。
二分图染色!NOIP2023考了
我们发现每个 \(\operatorname{opt}_2\) 就像流水,可以在两个点中任意流转
那么,我们先将每个 \(\operatorname{opt}_2\) 配合并查集连边缩点,
再记 \(c_S = \sum_{i \in S} b_i - a_i\),相同的本质就是让每一个 \(c_S = 0\)
然后我们考虑对 \(\operatorname{opt}_1\) 连边,形成一个图:
-
若该图是二分图,两边同加同减,只要二分图两边总和相同即可
-
若该图不是二分图,必然有一边内部有一条 \(\operatorname{opt}_1\) 的边
つまり,有一边或两边总和都可以进行 \(+2\)、\(-2\) 的操作,
而这种操作不会改变两边的奇偶性!故判断两边总和奇偶性是否相同!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
constexpr int N = 2e5+5;
int n,m,a[N],b[N],d[N],s[N],co[N],p[N],top;
array<int,3> q[N];
int find(int x) {
if(s[x] ^ x) s[x] = find(s[x]);
return s[x];
}
int head[N],nxt[N << 1],to[N<<1],cnt;
void init() {
for(int i = 0;i<=n;i++) head[i] = -1;
for(int i = 0;i<=n;i++) d[i] = 0,s[i] = i,co[i] = 0;
cnt = 0;top = 0;
}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
bool dfs(int x, int col) {
co[x] = col, p[col] += d[x];
bool ok = 1;
for (int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if (co[y] == co[x]) ok = 0;
if (!co[y] && !dfs(y, 3 - col)) ok = 0;
}
return ok;
}
bool solve(){
n = rd(),m = rd();
for(int i = 1;i<=n;i++) a[i] = rd();
for(int i = 1;i<=n;i++) b[i] = rd();
init();
for(int i = 1;i<=m;i++) {
array<int,3> c;
c[0] = rd(),c[1] = rd(),c[2] = rd();
if(c[0] == 2) {
int fx = find(c[1]),fy = find(c[2]);
s[fx] = fy;
}else q[++top] = c;
}
for(int i = 1;i<=n;i++) d[find(i)] += b[i] - a[i];
for(int i = 1;i<=top;i++) {
int fx = find(q[i][1]),fy = find(q[i][2]);
add(fx,fy);add(fy,fx);
}
for(int i = 1;i<=n;i++)
if(find(i) == i && !co[i]) {
p[1] = p[2] = 0;
bool ok = dfs(i,1);
if(ok && p[1] != p[2]) return false;
if(!ok && ((p[1] ^ p[2]) & 1)) return false;
}
return true;
}
signed main() {
int T = rd();
while(T--) puts(solve() ? "YES" : "NO");
return 0;
}
P1129 [ZJOI2007] 矩阵游戏
题面:
题目描述
小 Q 是一个非常聪明的孩子,除了国际象棋,他还很喜欢玩一个电脑益智游戏――矩阵游戏。矩阵游戏在一个 \(n \times n\) 黑白方阵进行(如同国际象棋一般,只是颜色是随意的)。每次可以对该矩阵进行两种操作:
- 行交换操作:选择矩阵的任意两行,交换这两行(即交换对应格子的颜色)。
- 列交换操作:选择矩阵的任意两列,交换这两列(即交换对应格子的颜色)。
游戏的目标,即通过若干次操作,使得方阵的主对角线(左上角到右下角的连线)上的格子均为黑色。
对于某些关卡,小 Q 百思不得其解,以致他开始怀疑这些关卡是不是根本就是无解的!于是小 Q 决定写一个程序来判断这些关卡是否有解。
输入格式
本题单测试点内有多组数据。
第一行包含一个整数 \(T\),表示数据的组数,对于每组数据,输入格式如下:
第一行为一个整数,代表方阵的大小 \(n\)。
接下来 \(n\) 行,每行 \(n\) 个非零即一的整数,代表该方阵。其中 \(0\) 表示白色,\(1\) 表示黑色。输出格式
对于每组数据,输出一行一个字符串,若关卡有解则输出
Yes,否则输出No。样例 #1
样例输入 #1
2 2 0 0 0 1 3 0 0 1 0 1 0 1 0 0样例输出 #1
No Yes提示
数据规模与约定
- 对于 \(20\%\) 的数据,保证 \(n \leq 7\)。
- 对于 \(50\%\) 的数据,保证 \(n \leq 50\)。
- 对于 \(100\%\) 的数据,保证 \(1 \leq n \leq 200\),\(1 \leq T \leq 20\)。
图匹配最难三连问:这道题在考匹配?如何匹配?图怎么建?
这道题很神奇的在考二分图匹配。
为什么?
我们将矩阵看做 \(i:(1 \sim n) \leadsto j:(n + 1 \sim n + n)\) 连边的邻接矩阵
其中 \(1\) 表示有连边,\(0\) 表示未连边
那么,这交换两行/两列操作在干吗?
假设我们有这样的一个二分图
我们将这两列连边情况交换: \(a_{left}:[1\sim n] \rightleftarrows b_{left}:[1\sim n]\)
其实就是交换 \(a_{left}、b_{left}\),(以交换 \(1,3\) 举例)如图
交换行也是一样的,即: \(a_{right} \rightleftarrows b_{right}\)
我们要让主对角线全为 \(1\)
也就是
如图:
(? 代表我们不需要知道是否有连边)
也就是对应的左右边两点有连边,即:
这个时候就可以使用二分图完美匹配
也就是二分图最大匹配 + 二分图每个点都被匹配
因为这个是 \(n \times n\) 的矩阵,所以二分图中的左右两边的点肯定为偶数个
(tips:非偶数个点的二分图无法完美匹配,必定有一个点无法匹配)
跑一个二分图匹配,判断是否有 \(n\) 条边匹配就大功告成了
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 205;
int match[N * N],n,vis[N * N];
int head[N * 2],nxt[N * N * 2],to[N * N * 2],cnt;
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
void solve() {
memset(head,-1,sizeof(head));
cnt = 0;
n = rd();
for(int i = 1;i<=n;i++)
for(int j = 1;j<=n;j++)
if(rd())
add(i,j + n),add(j + n,i);
int ans = 0;
memset(match,0,sizeof(match));
memset(vis,0,sizeof(vis));
auto dfs = [&](auto self,int x,int tag) -> bool{
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(vis[y] == tag) continue;
vis[y] = tag;
if(!match[y] || self(self,match[y],tag)) {
match[y] = x;
return true;
}
}
return false;
};
for(int i = 1;i<=n;i++) ans += dfs(dfs,i,i);
if(ans == n) puts("Yes");
else puts("No");
}
signed main() {
int T = rd();
while(T--) solve();
return 0;
}
2024/08/23
CF613D Kingdom and its Cities
题面:
题面翻译
一个王国有n座城市,城市之间由n-1条道路相连,形成一个树结构,国王决定将一些城市设为重要城市。
这个国家有的时候会遭受外敌入侵,重要城市由于加强了防护,一定不会被占领。而非重要城市一旦被占领,这座城市就不能通行。
国王定了若干选择重要城市的计划,他想知道,对于每个计划,外敌至少要占领多少个非重要城市,才会导致重要城市之间两两不连通。如果外敌无论如何都不可能导致这种局面,输出-1
感谢@litble 提供的翻译
题目描述
Meanwhile, the kingdom of K is getting ready for the marriage of the King's daughter. However, in order not to lose face in front of the relatives, the King should first finish reforms in his kingdom. As the King can not wait for his daughter's marriage, reforms must be finished as soon as possible.
The kingdom currently consists of\(n\)cities. Cities are connected by\(n-1\)bidirectional road, such that one can get from any city to any other city. As the King had to save a lot, there is only one path between any two cities.
What is the point of the reform? The key ministries of the state should be relocated to distinct cities (we call such cities important). However, due to the fact that there is a high risk of an attack by barbarians it must be done carefully. The King has made several plans, each of which is described by a set of important cities, and now wonders what is the best plan.
Barbarians can capture some of the cities that are not important (the important ones will have enough protection for sure), after that the captured city becomes impassable. In particular, an interesting feature of the plan is the minimum number of cities that the barbarians need to capture in order to make all the important cities isolated, that is, from all important cities it would be impossible to reach any other important city.
Help the King to calculate this characteristic for each of his plan.
输入格式
The first line of the input contains integer\(n\)(\(1<=n<=100000\)) — the number of cities in the kingdom.
Each of the next\(n-1\)lines contains two distinct integers\(u_{i}\),\(v_{i}\)(\(1<=u_{i},v_{i}<=n\)) — the indices of the cities connected by the\(i\)-th road. It is guaranteed that you can get from any city to any other one moving only along the existing roads.
The next line contains a single integer\(q\)(\(1<=q<=100000\)) — the number of King's plans.
Each of the next\(q\)lines looks as follows: first goes number\(k_{i}\)— the number of important cities in the King's plan, (\(1<=k_{i}<=n\)), then follow exactly\(k_{i}\)space-separated pairwise distinct numbers from 1 to\(n\)— the numbers of important cities in this plan.
The sum of all\(k_{i}\)'s does't exceed\(100000\).
输出格式
For each plan print a single integer — the minimum number of cities that the barbarians need to capture, or print\(-1\)if all the barbarians' attempts to isolate important cities will not be effective.
样例 #1
样例输入 #1
4 1 3 2 3 4 3 4 2 1 2 3 2 3 4 3 1 2 4 4 1 2 3 4样例输出 #1
1 -1 1 -1样例 #2
样例输入 #2
7 1 2 2 3 3 4 1 5 5 6 5 7 1 4 2 4 6 7样例输出 #2
2提示
In the first sample, in the first and the third King's plan barbarians can capture the city 3, and that will be enough. In the second and the fourth plans all their attempts will not be effective.
In the second sample the cities to capture are 3 and 5.
首先,如果关键点靠在一起(父亲&儿子关系),那么无解
虚树!
我们对关键点建一颗虚树,
然后考虑dp,
- 如果当前点是关键点!
子树有关键点 \(\rightarrow\) 毁掉到子树的边上的任意一个点(\(ans\uparrow\)) - 如果当前是非关键点!
多个子树内有关键点,自毁(\(ans\uparrow\))
Over!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
template<int Vsiz,int Esiz>
struct Graph{
int head[Vsiz],nxt[Esiz],to[Esiz],cnt;
Graph(){memset(head,-1,sizeof(head));cnt = 0;}
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
};
const int N = 2e5+5;
int n,q;
Graph<N,N<<1> g,G;
int fa[N],son[N],siz[N],top[N],id[N],dep[N],num;
void dfs1(int x,int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = dep[f] + 1;
for(int i = g.head[x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(y ^ f) {
dfs1(y,x);
siz[x] += siz[y];
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
void dfs2(int x,int topx) {
id[x] = ++num;
top[x] = topx;
if(!son[x]) return;
dfs2(son[x],topx);
for(int i = g.head[x];~i;i = g.nxt[i]) {
int y = g.to[i];
if(y ^ fa[x] && y ^ son[x]) dfs2(y,y);
}
}
int lca(int x,int y) {
while(top[x] ^ top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x,y);
x = fa[top[x]];
}
return dep[x] < dep[y] ? x : y;
}
int o[N],ans;
void dp(int x) {
if(o[x]) {
for(int i = G.head[x];~i;i = G.nxt[i]) {
int y = G.to[i];
dp(y);
if(o[y]) ans++,o[y] = 0;
}
}else {
for(int i = G.head[x];~i;i = G.nxt[i]) {
int y = G.to[i];
dp(y);
o[x] += o[y];
o[y] = 0;
}
if(o[x] > 1) ans++,o[x] = 0;
}
G.head[x] = -1;
}
void solve() {
int k = rd();
vector<int> a(k);
for(int &x : a) x = rd();
for(int x : a) o[x] = 1;
sort(a.begin(),a.end(),[&](const int &x,const int &y){return id[x] < id[y];});
for(int x : a) if(o[fa[x]]) {puts("-1");for(int x : a) o[x] = 0;return;}
static int st[N] = {},tp = 0;
st[tp = 1] = 1;
if(a[0] != 1) st[++tp] = a[0];
for(int i = 1;i<k;i++) {
int now = a[i];
int LCA = lca(now,st[tp]);
while(1)
if(dep[LCA] >= dep[st[tp - 1]]) {
if(LCA != st[tp]) {
G.add(LCA,st[tp]);
if(LCA != st[tp - 1])
st[tp] = LCA;
else
tp--;
}
break;
}else {
G.add(st[tp - 1],st[tp]);
tp--;
}
st[++tp] = now;
}
while(--tp)
G.add(st[tp],st[tp + 1]);
ans = 0;
dp(1);
wt(ans);
G.cnt = 0;
memset(o,0,sizeof(o));
putchar('\n');
}
signed main() {
n = rd();
for(int i = 1;i<n;i++) {
int u = rd(),v = rd();
g.add(u,v);g.add(v,u);
}
dfs1(1,0);dfs2(1,1);
int q = rd();
while(q--) solve();
return 0;
}
CF1209E2 Rotate Columns (hard version)
题面:
题面翻译
给定一个 \(n \times m\) 的矩阵,你可以对每一列进行若干次循环移位
求操作完成后每一行的最大值之和的最大值
\(1 \leq n \leq 12\),\(1 \leq m \leq 2000\)
样例 #1
样例输入 #1
3 2 3 2 5 7 4 2 4 3 6 4 1 5 2 10 4 8 6 6 4 9 10 5 4 9 5 8 7 3 3 9 9 9 1 1 1 1 1 1样例输出 #1
12 29 27提示
In the first test case you can shift the third column down by one, this way there will be\(r_1 = 5\)and\(r_2 = 7\).
In the second case you can don't rotate anything at all, this way there will be\(r_1 = r_2 = 10\)and\(r_3 = 9\).
一看这个 \(n\),就知道从哪下手了.
\(1 \leq n \leq 12\),经典的状态压缩范围,考虑状压dp
我们的各种操作都是对 列 进行的,
不妨重新审视一下问题:
也就是该问题等价于:在 \(m\) 列中选定 \(\mathbf{S}_i\) 这些数(在操作完循环移位之后),使得到的值最大
然后对每一列进行循环移位,考察如何让该列的 \(j \in \mathbf{S}_i\) 行价值和最大
code:
for(int j = 0;j<(1<<n);j++){
w[j] = 0;
for(int k = 0;k<n;k++){
int re = 0;
for(int l = 0;l<n;l++)
if((j >> l) & 1)
re += (~c[i])[(l + k) % n];
w[j] = max(w[j],re);
}
}
然后进行dp,对第 \(i\) 列选中哪几行遍历,记录前 \(i - 1\) 列选中哪些行取得哪些最大值,进行转移:
code:
for(int j = 0;j<(1<<n);j++){
if(i == 0) {
dp[i][j] = w[j];
continue;
}
for(int k = j;k;k = (k - 1) & j)
dp[i][j] = max(dp[i][j],dp[i - 1][k] + w[j ^ k]);
}
然后我们得到了复杂度为 \(\mathcal{O}(mn^22^n)\) 的做法,
我们还没有把 \(m\) 这个可恶的家伙干掉!
Q:这个 \(m\) 在干什么?
A: ta 在遍历每一列!
那么问题就很清晰了,我们是不是一定要遍历每一列?
答案显然是否(不然这题不就不可做了吗)
因为每一行都至少要选一个,我们如果贪心的每一列只选最大的那一个,然后选前 \(n\) 大
虽然这个贪心是错的,但是肯定比 每一列只选最大但是选的不是前 \(n\) 大的方案要优,那么也肯定比 部分最大值小于前 \(n\) 大的列选择的方案要更优!
(这里的解释可能有点唐,请读者自行画图理解)
总之,我们发现有用的列只有 \(n\) 个,即:列最大值为前 \(n\) 大的 \(n\) 列
我们将前 \(n\) 大的列排序到前面,做上述dp,就可以将复杂度降到 \(\mathcal{O}(n^32^n)\),完全可以通过!
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
namespace workspace{
const int N = 13,M = 2005;
int n,m;
struct col{
int b[N],maxn;
void init() {for(int i = 0;i<n;i++) b[i] = 0;maxn = 0;}
void get() {for(int i = 0;i<n;i++) maxn = max(maxn,b[i]);}
int* operator~ (){return b;}
friend bool operator < (const col &x,const col &y) {return x.maxn > y.maxn;}
};
col c[M];
int dp[N][1<<N],w[1<<N];
void solve() {
n = rd(),m = rd();
for(int i = 0;i<m;i++) c[i].init();
for(int i = 0;i<n;i++)
for(int j = 0;j<m;j++)
(~c[j])[i] = rd();
for(int i = 0;i<m;i++)
c[i].get();
sort(c,c + m);
for(int i = 0;i<min(n,m);i++) {
for(int j = 0;j<(1<<n);j++){
w[j] = 0;
for(int k = 0;k<n;k++){
int re = 0;
for(int l = 0;l<n;l++)
if((j >> l) & 1)
re += (~c[i])[(l + k) % n];
w[j] = max(w[j],re);
}
}
for(int j = 0;j<(1<<n);j++){
if(i == 0) {
dp[i][j] = w[j];
continue;
}
for(int k = j;k;k = (k - 1) & j)
dp[i][j] = max(dp[i][j],dp[i - 1][k] + w[j ^ k]);
}
}
wt(dp[min(n,m) - 1][(1<<n) - 1]);
memset(dp,0,sizeof(dp));
putchar('\n');
}
}
signed main() {
int t = rd();
while(t--) workspace::solve();
return 0;
}
CF165E Compatible Numbers
题面:
题面翻译
有两个整数a,b。如果a&b=0,那么我们称a与b是相容的。比如90(1011010)与36(100100)相容。给出一个序列aa ,你的任务是对于每个ai,找到在序列中与之相容的aj 。如果找不到这样的数,输出-1。
贡献者:An_Account\(1 \leq n \leq 10^6,1\leq a_i \leq 4\times 10^6\)
题目描述
Two integers\(x\)and\(y\)are compatible, if the result of their bitwise "AND" equals zero, that is,\(a\)$ &$$ b=0$. For example, numbers\(90\)$ (1011010_{2})$and\(36\)$ (100100_{2})$are compatible, as\(1011010_{2}\)$ &$$ 100100_{2}=0_{2}$, and numbers\(3\)$ (11_{2})$and\(6\)$ (110_{2})$are not compatible, as\(11_{2}\)$ &$$ 110_{2}=10_{2}$.
You are given an array of integers\(a_{1},a_{2},...,a_{n}\). Your task is to find the following for each array element: is this element compatible with some other element from the given array? If the answer to this question is positive, then you also should find any suitable element.
输入格式
The first line contains an integer\(n\)(\(1<=n<=10^{6}\)) — the number of elements in the given array. The second line contains\(n\)space-separated integers\(a_{1},a_{2},...,a_{n}\)(\(1<=a_{i}<=4·10^{6}\)) — the elements of the given array. The numbers in the array can coincide.
输出格式
Print\(n\)integers\(ans_{i}\). If\(a_{i}\)isn't compatible with any other element of the given array\(a_{1},a_{2},...,a_{n}\), then\(ans_{i}\)should be equal to -1. Otherwise\(ans_{i}\)is any such number, that\(a_{i}\)$ &$$ ans_{i}=0\(, and also\)ans_{i}\(occurs in the array\)a_{1},a_{2},...,a_{n}$.
样例 #1
样例输入 #1
2 90 36样例输出 #1
36 90样例 #2
样例输入 #2
4 3 6 3 6样例输出 #2
-1 -1 -1 -1样例 #3
样例输入 #3
5 10 6 9 8 2样例输出 #3
-1 8 2 2 8
高维前缀和!
简单的说,普通的前缀和(\(1\sim 3\) 维),我们经常使用容斥
但是,维度一高,容斥的复杂度大的吓人!
我们得换一种全新的方法!————高维前缀和 闪亮登场!
我们不妨来考虑这样一个事情:
我们的终极目标是把 \(1\leq i \leq x,1\leq j \leq y,\ldots\) 上的所有点累加到 \((x,y,\ldots)\) 上
那么,我们可以像著名游戏 2048 那样,每次直接搞定一个维度,将所有维度搞定之后,前缀和就做完了
以二维举例:
假设我们的原数组是这样的:
我们对 \(x\) 维先做一个前缀和:
然后再对 \(y\) 维做一个前缀和:
我们再举一个例子,加深印象:
\(x-Transform:\)
\(y-Transform:\)
回到正题,高维前缀和和这个有什么关系呢?
高维前缀和还有子集求和的功能!
对于一个 \(\mathbf{S}(2)\) 的 \(01\) 串,我们让 \(f_{\mathbf{S}} = \sum_{\mathbf{S^\prime} \in \mathbf{S}} a_{\mathbf{S^\prime}}\)
根据高维前缀和的搞法,可以得到
这道题,我们发现,\(a\And b = 0 \Leftrightarrow b \subseteq (a \oplus U)\)
那么,对于一个数,我们只需要找到ta补集子集中可行的的一个答案就可以了
对于一个数 \(s\),我们将 \(f_s = s\);
我们将 \(1 \sim 2^{22}(4\times 10^6 \leq 2^{22} \leq 5\times 10^6)\) 的 \(f_i\) 做一次"高维前缀和"(非狭义中的和,指保存可能的答案之一)
最后对询问 \(a\),访问 \(\mathbf{U} \oplus a\) 子集中是否有答案即可!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e6+5,M = 5e6+5,U = (1 << 22) - 1;
int a[N],f[M],n;
signed main() {
n = rd();
for(int i = 1;i<=n;i++) {
a[i] = rd();
f[a[i]] = a[i];
}
for(int i = 0;i<=21;i++)
for(int j = 0;j<(1<<22);j++)
if((j & (1 << i)) && f[j ^ (1 << i)])
f[j] = f[j ^ (1<<i)];
for(int i = 1;i<=n;i++) {
int b = U ^ a[i];
wt(f[b] ? f[b] : -1);putchar(' ');
}
return 0;
}
这种东西叫做 \(SOS\ dp\) 高维前缀和-动态规划
本博客:
监督:MingJunYi
超监督:凉宫春日
2024/08/24
AtCoder Beginner Contest 367 A ~ F(\(\not\)D)
几天前就已经vp过了,但是忘写题解了
今天才想起来
痛,早知道这么简单,我就不在家里摆烂了
A.Shout Everyday
罚了好几发,我打比赛一如既往的抽象
问题陈述
在 AtCoder 王国,居民们每天都要在 \(A\) 点大声喊出他们对章鱼烧的热爱。
住在 AtCoder 王国的高桥每天 \(B\) 点睡觉, \(C\) 点起床( \(24\) 小时钟)。他醒着的时候可以喊出对章鱼烧的爱,但睡着的时候却不能。判断他是否每天都能喊出对章鱼烧的爱。这里,一天有 \(24\) 小时,他的睡眠时间小于 \(24\) 小时。
如果 \(B < C\),那么 \(0 \sim B - 1 \bigwedge C + 1 \sim 24\) 是清醒的
如果 \(B > C\),那么 \(C + 1 \sim B - 1\) 是清醒的
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
signed main() {
int a = rd(),b = rd(),c = rd();
if(b < c) {
if(a < b || a > c) puts("Yes");
else puts("No");
}else {
if(a < b && a > c) puts("Yes");
else puts("No");
}
return 0;
}
B. Cut .0
赛时唐完了,jiangly好像也是用string(乐
问题陈述
一个实数 \(X\) 的小数点后第三位。
请在下列条件下打印实数 \(X\) 。
- 小数部分不能有尾数 "0"。
- 小数点后不能有多余的尾数。
这道题如果用 string ,那么恭喜你走了弯路!
这道题直接 cin >> 即可
#include<iostream>
using namespace std;
int main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
double x;
cin>>x;
cout<<x;
return 0;
}
C.Enumerate Sequences
问题陈述
按升序排列,打印所有满足以下条件的长度为 \(N\) 的整数序列。
- 第 \(i\) 个元素介于 \(1\) 和 \(R_i\) (含)之间。
- 所有元素之和是 \(K\) 的倍数。
什么是序列的词典顺序?如果下面的 1. 或 2. 成立,则序列 \(A = (A _ 1, \ldots, A _ {|A|})\) 在词法上**小于 \(B = (B _ 1, \ldots, B _ {|B|})\) :
- \(|A|<|B|\) 和 \((A _ {1},\ldots,A _ {|A|}) = (B _ 1,\ldots,B _ {|A|})\) 。
- 存在一个整数 \(1\leq i\leq \min\\{|A|,|B|\\}\) ,且以下两个条件均为真:
- \((A _ {1},\ldots,A _ {i-1}) = (B _ 1,\ldots,B _ {i-1})\)
- \(A _ i < B _ i\)
数据范围这么小!
这道题是直接暴搜!
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 10;
int n,k;
int a[N],b[N];
void dfs(int now,int s) {
if(now == n + 1) {
if(s % k == 0) {
for(int i = 1;i<=n;i++) wt(b[i]),putchar(' ');
putchar('\n');
}
return;
}
for(int i = 1;i<=a[now];i++) {
b[now] = i;
dfs(now + 1,s + i);
}
}
signed main() {
n = rd(),k = rd();
for(int i = 1;i<=n;i++) a[i] = rd();
dfs(1,0);
return 0;
}
E.Permute K times
问题陈述
给你一个长度为 \(N\) 的序列 \(X\) ,其中每个元素都在 \(1\) 和 \(N\) 之间(包括首尾两个元素),以及一个长度为 \(N\) 的序列 \(A\) 。
打印在 \(A\) 上执行以下操作 \(K\) 次的结果。
- 将 \(A\) 替换为 \(B\) ,使得 \(B _ i = A _ {X _ i}\) .
将 \(X_i\) 看做 \(i\) 的父亲,其实这道题就是基环树上求 \(kth\) 父亲
直接考虑倍增
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 2e5+5;
int n,k,a[N],b[N];
int f[60][N];
signed main() {
n = rd(),k = rd();
for(int i = 1;i<=n;i++) f[0][i] = rd();
for(int i = 1;i<=n;i++) a[i] = rd();
for(int i = 1;i<=n;i++) b[i] = i;
for(int j = 1;j<60;j++)
for(int i = 1;i<=n;i++)
f[j][i] = f[j - 1][f[j - 1][i]];
for(int j = 59;j >= 0;j--)
if((k >> j) & 1)
for(int i = 1;i<=n;i++)
b[i] = f[j][b[i]];
for(int i = 1;i<=n;i++)
wt(a[b[i]]),putchar(' ');
return 0;
}
F.Rearrange Query
问题陈述
给你长度为 \(N\) 的正整数序列: \(A=(A _ 1,A _ 2,\ldots,A _ N)\) 和 \(B=(B _ 1,B _ 2,\ldots,B _ N)\) .
给你 \(Q\) 个查询,让你按顺序处理。下面将对 \(i\) -th 查询进行解释。
- 给定正整数 \(l _ i,r _ i,L _ i,R _ i\) 。如果可以重新排列子序列 \((A _ {l _ i},A _ {l _ i+1},\ldots,A _ {r _ i})\) 以匹配子序列 \((B _ {L _ i},B _ {L _ i+1},\ldots,B _ {R _ i})\) ,则打印 "是",否则打印 "否"。
查询区间多重集元素是否相同?
仙人指路:P3792
可以Hash 做,但是我不会
考虑正确性高的做法,维护 \(n\) 次方和
用线段树维护 \(\sum_{l}^r x^{1\sim 3}\)
我赛时维护到了 \(7\) 次方(比较唐)
#include<bits/stdc++.h>
using namespace std;
#define int unsigned long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N =2e5+5;
int n,q;
struct sgt{
#define ls (p << 1)
#define rs (p << 1 | 1)
#define mid ((pl + pr) >> 1)
int o[N];
int s[N<<2],s2[N<<2],s3[N<<2],mx[N<<2],mn[N<<2],s4[N<<2],s5[N<<2],s6[N<<2],s7[N<<2];
void push_up(int p) {
mx[p] = max(mx[ls],mx[rs]);
mn[p] = min(mn[ls],mn[rs]);
s[p] = s[ls] + s[rs];
s2[p] = s2[ls] + s2[rs];
s3[p] = s3[ls] + s3[rs];
s4[p] = s4[ls] + s4[rs];
s5[p] = s5[ls] + s5[rs];
s6[p] = s6[ls] + s6[rs];
s7[p] = s7[ls] + s7[rs];
}
void build(int p,int pl,int pr) {
if(pl == pr) {
mx[p] = mn[p] = s[p] = o[pl];
s2[p] = o[pl] * o[pl];
s3[p] = o[pl] * o[pl] * o[pl];
s4[p] = o[pl] * o[pl] * o[pl]* o[pl];
s5[p] = o[pl] * o[pl] * o[pl]* o[pl]* o[pl];
s6[p] = o[pl] * o[pl] * o[pl]* o[pl]* o[pl]* o[pl];
s7[p] = o[pl] * o[pl] * o[pl]* o[pl]* o[pl]* o[pl]* o[pl];
return;
}
build(ls,pl,mid);
build(rs,mid+1,pr);
push_up(p);
}
int query_s(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return s[p];
int re = 0;
if(l <= mid) re += query_s(ls,pl,mid,l,r);
if(r > mid) re += query_s(rs,mid+1,pr,l,r);
return re;
}
int query_s2(int p,int pl,int pr,int l,int r){
if(l <= pl && pr <= r) return s2[p];
int re = 0;
if(l <= mid) re += query_s2(ls,pl,mid,l,r);
if(r > mid) re += query_s2(rs,mid+1,pr,l,r);
return re;
}
int query_s3(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return s3[p];
int re = 0;
if(l <= mid) re += query_s3(ls,pl,mid,l,r);
if(r > mid) re += query_s3(rs,mid+1,pr,l,r);
return re;
}
int query_s4(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return s4[p];
int re = 0;
if(l <= mid) re += query_s4(ls,pl,mid,l,r);
if(r > mid) re += query_s4(rs,mid+1,pr,l,r);
return re;
}
int query_s5(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return s5[p];
int re = 0;
if(l <= mid) re += query_s5(ls,pl,mid,l,r);
if(r > mid) re += query_s5(rs,mid+1,pr,l,r);
return re;
}
int query_s6(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return s6[p];
int re = 0;
if(l <= mid) re += query_s6(ls,pl,mid,l,r);
if(r > mid) re += query_s6(rs,mid+1,pr,l,r);
return re;
}
int query_s7(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return s7[p];
int re = 0;
if(l <= mid) re += query_s7(ls,pl,mid,l,r);
if(r > mid) re += query_s7(rs,mid+1,pr,l,r);
return re;
}
int query_mx(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return mx[p];
int re = 0;
if(l <= mid) re = max(re,query_mx(ls,pl,mid,l,r));
if(r > mid) re = max(re,query_mx(rs,mid+1,pr,l,r));
return re;
}
int query_mn(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return mn[p];
int re = INT_MAX;
if(l <= mid) re = min(re,query_mn(ls,pl,mid,l,r));
if(r > mid) re = min(re,query_mn(rs,mid+1,pr,l,r));
return re;
}
}A,B;
signed main() {
n = rd(),q = rd();
for(int i = 1;i<=n;i++) A.o[i] = rd();
for(int i = 1;i<=n;i++) B.o[i] = rd();
A.build(1,1,n);B.build(1,1,n);
while(q--) {
int l = rd(),r = rd(),L = rd(),R = rd();
bool flag1 = (A.query_s(1,1,n,l,r) == B.query_s(1,1,n,L,R));
bool flag2 = A.query_s2(1,1,n,l,r) == B.query_s2(1,1,n,L,R);
bool flag3 = A.query_s3(1,1,n,l,r) == B.query_s3(1,1,n,L,R);
bool flag4 = A.query_mn(1,1,n,l,r) == B.query_mn(1,1,n,L,R);
bool flag5 = A.query_mx(1,1,n,l,r) == B.query_mx(1,1,n,L,R);
bool flag6 = A.query_s4(1,1,n,l,r) == B.query_s4(1,1,n,L,R);
bool flag7 = A.query_s5(1,1,n,l,r) == B.query_s5(1,1,n,L,R);
bool flag8 = A.query_s6(1,1,n,l,r) == B.query_s6(1,1,n,L,R);
bool flag9 = A.query_s7(1,1,n,l,r) == B.query_s7(1,1,n,L,R);
if(flag1 && flag2 && flag3 && flag4 && flag5&& flag6&& flag7&& flag8&& flag9) puts("Yes");
else puts("No");
}
return 0;
}
2024/08/26
P8820 [CSP-S 2022] 数据传输
【一目了然,不言而喻】
题面:
题目描述
小 C 正在设计计算机网络中的路由系统。
测试用的网络总共有 \(n\) 台主机,依次编号为 \(1 \sim n\)。这 \(n\) 台主机之间由 \(n - 1\) 根网线连接,第 \(i\) 条网线连接个主机 \(a_i\) 和 \(b_i\)。保证任意两台主机可以通过有限根网线直接或者间接地相连。受制于信息发送的功率,主机 \(a\) 能够直接将信息传输给主机 \(b\) 当且仅当两个主机在可以通过不超过 \(k\) 根网线直接或者间接的相连。
在计算机网络中,数据的传输往往需要通过若干次转发。假定小 C 需要将数据从主机 \(a\) 传输到主机 \(b\)(\(a \neq b\)),则其会选择出若干台用于传输的主机 \(c_1 = a, c_2, \ldots, c_{m - 1}, c_m = b\),并按照如下规则转发:对于所有的 \(1 \le i < m\),主机 \(c_i\) 将信息直接发送给 \(c_{i + 1}\)。
每台主机处理信息都需要一定的时间,第 \(i\) 台主机处理信息需要 \(v_i\) 单位的时间。数据在网络中的传输非常迅速,因此传输的时间可以忽略不计。据此,上述传输过程花费的时间为 \(\sum_{i = 1}^{m} v_{c_i}\)。
现在总共有 \(q\) 次数据发送请求,第 \(i\) 次请求会从主机 \(s_i\) 发送数据到主机 \(t_i\)。小 C 想要知道,对于每一次请求至少需要花费多少单位时间才能完成传输。
输入格式
输入的第一行包含三个正整数 \(n, Q, k\),分别表示网络主机个数,请求个数,传输参数。数据保证 \(1 \le n \le 2 \times {10}^5\),\(1 \le Q \le 2 \times {10}^5\),\(1 \le k \le 3\)。
输入的第二行包含 \(n\) 个正整数,第 \(i\) 个正整数表示 \(v_i\),保证 \(1 \le v_i \le {10}^9\)。
接下来 \(n - 1\) 行,第 \(i\) 行包含两个正整数 \(a_i, b_i\),表示一条连接主机 \(a_i, b_i\) 的网线。保证 \(1 \le a_i, b_i \le n\)。
接下来 \(Q\) 行,第 \(i\) 行包含两个正整数 \(s_i, t_i\),表示一次从主机 \(s_i\) 发送数据到主机 \(t_i\) 的请求。保证 \(1 \le s_i, t_i \le n\),\(s_i \ne t_i\)。
输出格式
\(Q\) 行,每行一个正整数,表示第 \(i\) 次请求在传输的时候至少需要花费多少单位的时间。
样例 #1
样例输入 #1
7 3 3 1 2 3 4 5 6 7 1 2 1 3 2 4 2 5 3 6 3 7 4 7 5 6 1 2样例输出 #1
12 12 3提示
【样例解释 #1】
对于第一组请求,由于主机 \(4, 7\) 之间需要至少 \(4\) 根网线才能连接,因此数据无法在两台主机之间直接传输,其至少需要一次转发;我们让其在主机 \(1\) 进行一次转发,不难发现主机 \(1\) 和主机 \(4, 7\) 之间都只需要两根网线即可连接,且主机 \(1\) 的数据处理时间仅为 \(1\),为所有主机中最小,因此最少传输的时间为 \(4 + 1 + 7 = 12\)。
对于第三组请求,由于主机 \(1, 2\) 之间只需要 \(1\) 根网线就能连接,因此数据直接传输就是最优解,最少传输的时间为 \(1 + 2 = 3\)。
【样例 #2】
见附件中的
transmit/transmit2.in与transmit/transmit2.ans。该样例满足测试点 \(2\) 的限制。
【样例 #3】
见附件中的
transmit/transmit3.in与transmit/transmit3.ans。该样例满足测试点 \(3\) 的限制。
【样例 #4】
见附件中的
transmit/transmit4.in与transmit/transmit4.ans。该样例满足测试点 \(20\) 的限制。
【数据范围】
对于所有的测试数据,满足 \(1 \le n \le 2 \times {10}^5\),\(1 \le Q \le 2 \times {10}^5\),\(1 \le k \le 3\),\(1 \le a_i, b_i \le n\),\(1 \le s_i, t_i \le n\),\(s_i \ne t_i\)。
测试点 \(n \le\) \(Q \le\) \(k =\) 特殊性质 \(1\) \(10\) \(10\) \(2\) 是 \(2\) \(10\) \(10\) \(3\) 是 \(3\) \(200\) \(200\) \(2\) 是 \(4 \sim 5\) \(200\) \(200\) \(3\) 是 \(6 \sim 7\) \(2000\) \(2000\) \(1\) 否 \(8 \sim 9\) \(2000\) \(2000\) \(2\) 否 \(10 \sim 11\) \(2000\) \(2000\) \(3\) 否 \(12 \sim 13\) \(2 \times {10}^5\) \(2 \times {10}^5\) \(1\) 否 \(14\) \(5 \times {10}^4\) \(5 \times {10}^4\) \(2\) 是 \(15 \sim 16\) \({10}^5\) \({10}^5\) \(2\) 是 \(17 \sim 19\) \(2 \times {10}^5\) \(2 \times {10}^5\) \(2\) 否 \(20\) \(5 \times {10}^4\) \(5 \times {10}^4\) \(3\) 是 \(21 \sim 22\) \({10}^5\) \({10}^5\) \(3\) 是 \(23 \sim 25\) \(2 \times {10}^5\) \(2 \times {10}^5\) \(3\) 否 特殊性质:保证 \(a_i = i + 1\),而 \(b_i\) 则从 \(1, 2, \ldots, i\) 中等概率选取。
这道题的 \(k\) 很小,又是 多测 + dp
自然让我们想到动态dp!
考虑 \(k = 1\) 的情况:
很简单,就是链上求和
考虑 \(k = 2\) 的情况:
这个也不难想到,直接在链上跳,因为跳出链需要 \(2\),跳进链也需要 \(2\),然后的目的地和出发点也只有 \(2\),非常的不值啊!
故有转移:(我们定义 \(f_{x,i}\) 表示到达离 \(x\) 距离为 \(i\) 的点的代价)
考虑 \(k = 3\) 的情况:
这时情况略有不同,跳出链是否可行呢?
我们发现,跳出链可能更优秀!
有转移:
这个 \(\min\) 里面套 \(\min\) 很烦人!
我们发现 \(f_{v,0} + \operatorname{minn}_u > f_{v,0}\) !
而且, \(f_{u,0} = \min(f_{v,0},f_{v,1},f_{v,2}) + \operatorname{val}_u\)
所以,\(f_{u,1} = \min(f_{v,1} + \operatorname{minn}_u,f_{v,0},f_{v,2} + \operatorname{val}_u +\operatorname{minn}_u)\)
构造出矩阵:
\(k = 1\) 时,
\(k = 2\) 时,
\(k = 3\) 时,
然后用树上倍增跑动态dp!
Tips : 本人对动态dp计算的误区——矩阵没有交换律!!!
为什么这个很重要呢?
看这段代码:
matrix<1,3> query(int x,int y) {
matrix<3,3> c;
for(int i = 0;i<3;i++) c[i][i] = 0;
while(top[x] ^ top[y]) {
if(dep[top[x]] < dep[top[y]]) swap(x,y);
c = c * sgt::query(1,1,n,id[top[x]],id[x]);
x = fa[top[x]];
}
if(dep[x] > dep[y]) swap(x,y);
c = c * sgt::query(1,1,n,id[x],id[y]);
matrix<1,3> ans;
ans = ans * c;
return ans;
}
这个喜提 \(0\) 分,
因为他跳链计算的方式完全是乱的,但是这个广义矩阵乘法又没有交换律,故得出的答案也是完全错误!
而 P4719 这道题用树剖 + 线段树为什么是对的呢?
因为ta要求的答案是全局答案!并且修改的时候会对链头的父亲进行修改,而不是对整条链的修改!
而本题是一种类似于爬山的方式进行的矩阵乘法,如图:
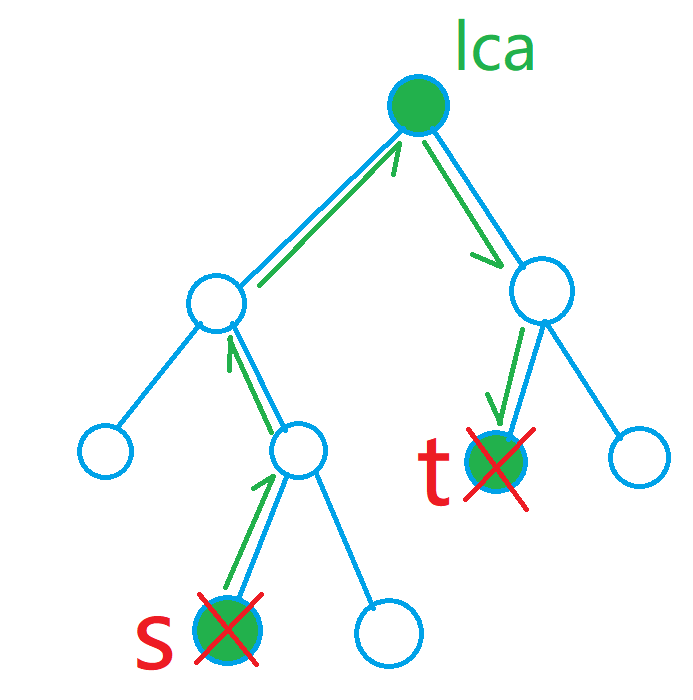
这个时候,我们考虑用树上倍增模拟这个爬山过程:
- 求出 \(\operatorname{lca}(s,t)\)
- 以上升的方式倍增求 \(\operatorname{mat}_1 = \prod\limits_{i:[s \sim lca]} \begin{bmatrix} \operatorname{val} & 0 & \infty \\ \operatorname{val} & \operatorname{minn} & \infty \\ \operatorname{val} & \operatorname{minn} + \operatorname{val} & 0 \\ \end{bmatrix}\)
-
以下降的方式倍增求 \(\operatorname{mat}_2 = \prod\limits_{i:[lca \sim t]} \begin{bmatrix} \operatorname{val} & 0 & \infty \\ \operatorname{val} & \operatorname{minn} & \infty \\ \operatorname{val} & \operatorname{minn} + \operatorname{val} & 0 \\ \end{bmatrix}\)
-
最后将答案 \(\operatorname{re} = \operatorname{mat}_1 \times mat_{\operatorname{[min\{fa,minn\}]}} \times \operatorname{mat}_2\)
答案就是 : \(re_{0,0}\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
#define log2(x) __lg((x))
template<int N,int M,class T = long long>
struct matrix {
T m[N][M];
matrix(){memset(m,0x3f,sizeof(m));}
T* operator [] (const int pos) {return m[pos];}
};
template<int N,int M,int R,class T = long long>
matrix<N,R,T> operator * (matrix<N,M,T> a,matrix<M,R,T> b) {
matrix<N,R,T> c;
for(int i = 0;i<N;i++)
for(int j = 0;j<M;j++)
for(int k = 0;k<R;k++)
c[i][k] = min(c[i][k],a[i][j] + b[j][k]);
return c;
}
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
const int N = 2e5+5,inf = 0x3f3f3f3f3f3f3f3fLL;
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
int n,q,k,v[N],minn[N];
int head[N],nxt[N<<1],to[N<<1],cnt;
void init() {
memset(head,-1,sizeof(head));
cnt = 0;
}
void add(int u,int v) {
nxt[cnt] = head[u];
to[cnt] = v;
head[u] = cnt++;
}
int fa[19][N],dep[N];
matrix<3,3> down[19][N],up[19][N];
matrix<3,3> get(int id,int fav = inf) {
matrix<3,3> c;
switch(k) {
case 1:
c[0][0] = v[id];
break;
case 2:
c[0][1] = 0;
c[0][0] = c[1][0] = v[id];
break;
case 3:
c[0][0] = c[1][0] = c[2][0] = v[id];
c[1][1] = min(minn[id],fav);
c[2][1] = min(minn[id],fav) + v[id];
c[0][1] = c[1][2] = 0;
break;
}
return c;
}
void dfs(int x,int f){
fa[0][x] = f;
dep[x] = dep[f] + 1;
minn[x] = inf;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i];
if(y ^ f) {
dfs(y,x);
minn[x] = min(minn[x],v[y]);
}
}
down[0][x] = up[0][x] = get(x);
}
matrix<1,3> f;
int lca(int x,int y) {
if(dep[x] < dep[y]) swap(x,y);
int d = dep[x] - dep[y];
for(int j = 18;j >= 0;j--) if(d >> j & 1) x = fa[j][x];
if(x == y) return x;
for(int j = 18;j >=0;j--) if(fa[j][x] ^ fa[j][y]) x = fa[j][x],y = fa[j][y];
return fa[0][x];
}
matrix<3,3> getDown(int u,int k) {
matrix<3,3> re;
for(int i = 0;i<3;i++) re[i][i] = 0;
for(int j = 18;j >= 0;j--) if(k >> j & 1) re = down[j][u] * re,u = fa[j][u];
return re;
}
matrix<3,3> getUp(int u,int k) {
matrix<3,3> re;
for(int i = 0;i<3;i++) re[i][i] = 0;
for(int j = 18;j >= 0;j--) if(k >> j & 1) re = re * up[j][u],u = fa[j][u];
return re;
}
int query(int s,int t) {
int LCA = lca(s,t);
matrix<1,3> re = f * getUp(s,dep[s] - dep[LCA]) * get(LCA,v[fa[0][LCA]]) * getDown(t,dep[t] - dep[LCA]);
return min({re[0][0] - v[t],re[0][1],re[0][2]}) + v[t];
}
signed main() {
init();
n = rd(),q = rd(),k = rd();
f[0][k - 1] = 0;
v[0] = inf;
for(int i = 1;i<=n;i++) v[i] = rd();
for(int i = 1;i<n;i++) {
int u = rd(),v = rd();
add(u,v);add(v,u);
}
dfs(1,0);
for(int j = 1;j<=18;j++) {
for(int i = 1;i<=n;i++) fa[j][i] = fa[j - 1][fa[j - 1][i]];
for(int i = 1;i<=n;i++) down[j][i] = down[j - 1][fa[j - 1][i]] * down[j - 1][i];
for(int i = 1;i<=n;i++) up[j][i] = up[j - 1][i] * up[j - 1][fa[j - 1][i]];
}
while(q--) {
int s = rd(),t = rd();
wt(query(s,t));
putchar('\n');
}
return 0;
}
校内模拟赛("扫地"杯 Day 1?)
道路修建
题面:
题目背景
liouzhou_101最悲痛的回忆就是NOI2011的道路修建,当时开了系统堆栈,结果无限RE…
题目描述
出于某种报复心理,就把那题神奇了一下:
在Z星球上有N个国家,这N个国家之间只能建造N-1条道路且全部建完这N-1条道路后这N个国家相互连通,修建每条道路都有相应的花费。但是他们都很吝啬,于是决定只随机选出两个不同的国家(为了国家的平等,当然这两个国家是无顺序可言的),建造该建造的道路,使得这两个国家相互连通,自然费用越少越好。然后问你,在所有情况中,修建道路花费的平均值。
假若您认为本题题目叙述太渣,那就形象地描述一遍:给出一棵边上带权的树,求任意两个不同的点的距离的期望值。
输入格式
第一行包括一个正整数N,N表示国家的数量。
接下来N-1行每行包括三个正整数x、y和w,表示国家x和国家y之间有一条花费为w的道路。
输出格式
仅一行,包含一个最简分数,格式为A/B,详见样例。
样例 #1
样例输入 #1
4 1 2 1 1 3 1 1 4 1样例输出 #1
3/2提示
【提示】
共存在6种情况:
①(1,2) 距离 1;
②(1,3) 距离 1;
③(1,4) 距离 1;
④(2,3) 距离 2;
⑤(2,4) 距离 2;
⑥(3,4) 距离 2;
所以平均值为(1+1+1+2+2+2)/6=3/2。
30%的数据,满足n<=1,000;
50%的数据,满足n<=10,000;
100%的数据,满足1<=n<=100,000,1<=w<=1,000。
【时限】
1s
计数题,我们求期望时考虑将贡献拆开:我们算每条边会经过多少次!
我们每条边对于一个父亲点指向儿子点
我们发现一条边被经过,只有选中上述的儿子点内的子树和子树外的一点形成的路径
所以可以树剖(只是小dfs)后对每个点子树内的大小 \(\times\) 子树外的大小 \(\rightarrow \operatorname{ans}\),即:
因为树上一共有 \(\dbinom{n}{2}\) 条路径,所以答案为 \(\frac{2\operatorname{ans}}{n(n - 1)}\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e5+5;
int n;
int head[N],nxt[N<<1],to[N<<1],val[N<<1],cnt;
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
int siz[N],son[N],dep[N],fa[N],ans;
void dfs1(int x,int f) {
fa[x] = f;
siz[x] = 1;
dep[x] = dep[f] + 1;
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i],w = val[i];
if(y ^ f) {
dfs1(y,x);
siz[x] += siz[y];
ans += siz[y] * (n - siz[y]) * w;
if(siz[son[x]] < siz[y]) son[x] = y;
}
}
}
signed main() {
init();
n = rd();
for(int i = 1;i<n;i++) {
int u = rd(),v = rd(),w = rd();
add(u,v,w);add(v,u,w);
}
dfs1(1,0);
int mo = n * (n - 1) / 2;
int gcd = __gcd(mo,ans);
ans /= gcd;
mo /= gcd;
wt(ans),putchar('/'),wt(mo);
return 0;
}
破坏基地
题面:
题目背景
在Z国和W国之间一直战火不断。好不容易,W国的间谍把完整的Z国的军事基地的地图到手了。于是W国决定再次出击,一举击破Z国的防线。
题目描述
W国认真研究了Z国的地形,发现Z国有N个军事基地,我们不妨编号成1..N,而且经过深刻研究,发现1号军事基地是资源补给基地,而N号军事基地是前线。由于地形的缘故,只有M对军事基地两两可达,当然是有距离的。此时W国的弹头紧缺,当下的弹头只能去毁灭一个军事基地。当然了,最重要的就是毁灭一个军事基地,使得资源补给基地与前线的最短距离发生变化。但是Z国也不是白痴,他们的资源补给基地与前线有着极高的防御力,所以W国只能去炸掉其余的N-2个基地,当然炸掉某个基地后,这个基地就不可达了。于是问题就来了,炸掉哪些基地后会使得资源补给基地与前线的最短距离发生变化呢?
注:假若炸掉某个基地后,1号基地和N号基地不连通,那么我们也认为他们的最短距离发生了变化。
输入格式
输入数据第一行是两个正整数N,M,意义如题所述。
接下来M行,每行包括三个正整数x,y,d,表示有一条边连接x、y两个地点,其距离为d。
数据保证图是连通的。
输出格式
输出数据的第一行包含一个整数K,表示有K个基地可毁灭,且毁灭其中任意一个后,资源补给基地与前线的最短距离发生变化。
接下来K行,每行输出一个军事基地的编号,要求编号递增。
在wyl8899神犇的率领下,W国必胜!!!
因此一定不会存在K=0的情况。样例 #1
样例输入 #1
6 7 1 2 3 1 5 2 2 3 5 2 4 3 2 5 4 2 6 5 3 4 2样例输出 #1
1 2提示
【提示】
对于30%的数据,N<=100,M<=1,000;
对于60%的数据,N<=2,000,M<=20,000;
对于100%的数据,N<=10,000,M<=100,000,1<=d<=10,000;
【时限】
1s
一眼,最短路计数
首先可以确定的一点是,更改点只能是最短路上的点,因为改其他的根本不会有影响!
然后,更改点还得经过所有最短路!不然还有漏网的最短路!
为确定哪些点经过所有最短路,我们从 \(s,t\) 两边跑最短路计数:
如图:
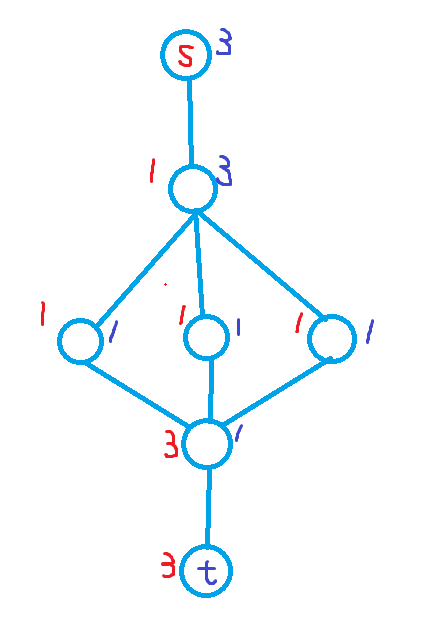
我们发现,当一个点两个最短路计数乘积等于 \(s \leadsto t\) 最短路个数时,这个点在所有最短路上
本题跑 dij,然后回溯最短路求解(Tip:注意输出格式)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 1e4+5,M = 1e5+5;
int n,m;
int head[N],nxt[M<<1],to[M<<1],val[M<<1],cnt;
void init() {memset(head,-1,sizeof(head));cnt = 0;}
void add(int u,int v,int w) {
nxt[cnt] = head[u];
to[cnt] = v;
val[cnt] = w;
head[u] = cnt++;
}
vector<int> c[N];
int dis[N],v[N],p[N];
bool vis[N];
priority_queue<array<int,2>,vector<array<int,2>>,greater<array<int,2>>> q;
void dij(int s) {
memset(dis,0x3f,sizeof(dis));
memset(vis,0,sizeof(vis));
memset(v,0,sizeof(v));
dis[s] = 0;v[s] = 1;
q.push(array<int,2>{0,s});
while(q.size()) {
array<int,2> t = q.top();
q.pop();
if(vis[t[1]]) continue;
vis[t[1]] = true;
int x = t[1];
for(int i = head[x];~i;i = nxt[i]) {
int y = to[i],w = val[i];
if(dis[y] == dis[x] + w) {
v[y] += v[x];
if(s == 1)c[y].emplace_back(x);
}
if(dis[y] > dis[x] + w) {
dis[y] = dis[x] + w;
v[y] = v[x];
if(s == 1)c[y].clear();
if(s == 1)c[y].emplace_back(x);
q.emplace(array<int,2>{dis[y],y});
}
}
}
}
set<int> ans;
void dfs(int s) {
for(int t : c[s]) {
if(t == 1) continue;
if(v[t] * p[t] == p[n])
ans.emplace(t);
dfs(t);
}
}
signed main() {
init();
n = rd(),m = rd();
for(int i = 1;i<=m;i++) {
int u = rd(),v = rd(),w = rd();
add(u,v,w);add(v,u,w);
}
dij(1);
memcpy(p,v,sizeof(p));
dij(n);
dfs(n);
wt(ans.size());putchar('\n');
for(int x : ans) wt(x),putchar('\n');
return 0;
}
/*
12 16
1 9 1
9 8 1
8 5 1
8 6 1
6 2 2
6 3 2
6 4 2
5 2 2
5 3 2
5 4 2
2 10 5
3 10 5
4 10 5
10 12 100
1 11 2
11 6 1
*/
诡异的数学题
题面:
题目背景
liouzhou_101 从 NOI 归来后文化课像坨屎,于是决定去补做一些作业,结果翻开作业的第一题就傻眼了
题目描述
设 a、b、c 为实数,且满足 a+b+c=15,a2+b2+c^2=100,则 a 的最大值和最小值的积为____。
话说这题他都没有想出来怎么做,就开始自己 YY,把这题牛逼成了:
设 a1、a2、…、an 为实数,且 a1+a2+…+an=x,a1^2 + a2^2 +…+an^2=y,则 a1 的最大值和最小
值的积为____。liouzhou_101 这种傻×自然不会做了,于是来向你请教
输入格式
输入的第一行是一个正整数 T,表示测试组数。
接着对每组测试数据,输入只有一行,三个正整数 N、x 和 y,之间以一个空格隔开
输出格式
对于每组测试数据,输出只有一行,假若不存在满足题目要求的,就输出“WA RE CE TLE MLE OLE”(不含引号);否则输出一个精确到小数点后 6 位的浮点数,即 a1 的最大值和最小值的积。
样例 #1
样例输入 #1
2 3 15 100 1 4 15样例输出 #1
8.333333 WA RE CE TLE MLE OLE提示
【提示】
对于第一组,a1 最大是 9.082483,最小是 0.917517,乘起来就是 8.333333。
对于第二组,明显不可能存在 a1 满足题意。
对于 10%的数据,N=1;
对于 20%的数据,N<=2;
对于 40%的数据,N<=3;
对于 70%的数据,N<=100;
对于 100%的数据,1<=T<=10,
1<=N<=10,000,0<=x<=10,000,0<=y<=10,000。
【时限】
1s
你得会大名鼎鼎的均值不等式!
我会,但是我没做出来!鉴定为思维不够
先看 \(n\) 元均值不等式:
因为 \(x = \sum_{i = 1}^na_i,y = \sum_{i = 1}^na_i^2\)
有:
先检验 \(\Delta = b^2 - 4ac \geq 0\)
对于这个二次函数,用韦达定理:
如果 \(n = 1\),构不成二次函数,请朴素的直接判断是否 \(y = x ^2\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
void work(){
int n = rd(),x = rd(),y = rd();
if(n == 1) {
if(y != (x * x)) puts("WA RE CE TLE MLE OLE");
else printf("%.6lf\n",(double)(x * x) + 0.000000000001);
return;
}
int b = -2 * x;
int a = n;
int c = x * x - (n - 1) * y;
int delta = b * b - 4 * a * c;
if(delta < 0) puts("WA RE CE TLE MLE OLE");
else printf("%.6lf\n",(double)(x * x - (n - 1) * y) / (double)(n)+ 0.000000000001);
}
signed main() {
int T = rd();
while(T--) work();
return 0;
}
2024/08/27
校内模拟赛(扫地杯Day2?)
染色问题
题面:
题目背景
做了 HEOI2012 的赵州桥(bridge)之后,liouzhou_101 就感到极其的不爽,首先那题题目叙述巨渣,
然后做法极坑题目描述
不过那题是一道和染色有关的问题,于是在此同时也启发 liouzhou_101 想到了这样一个简单的问题:
在一串未打结的项链上(意思就是说项链的左端和右端不相连),有 N 颗珠子,你有 M 种颜色,然后就问你有多少种方法将每一颗珠子都染上颜色,使得任意两颗相邻的珠子的颜色不同。
liouzhou_101 这种傻×自然不会做了,于是来向你请教…
当然,由于 liouzhou_101 的脑子构造极其简单,你不要想太多,请不要考虑 Polya 之类的本质相同,否则的话仅凭liouzhou_101 的理解能力是不能理解的…
输入格式
输入只有一行,三个正整数 N、M 和 P,之间以一个空格隔开
输出格式
输出只有一行,表示染色的方法总数模 P。
样例 #1
样例输入 #1
5 4 13样例输出 #1
12提示
【提示】
一共有 324 种染色方法,对 13 取模后是 12。
对于 10%的数据,N=1,M<=10,P<=10;
对于 20%的数据,N<=10,M<=10,P<=100;
对于 50%的数据,N,M,P<=1,000,000,000;
对于 100%的数据,
1<=N,M,P<=1,000,000,000,000,000,000,且 M>=2。【时限】
1s
计数?快速幂!
我们假定上一个珠子颜色为 \(x\),下一个只能是非 \(x\) 中的一个,有 \(m - 1\) 种情况
故 \(ans = m \times (m - 1)^{n - 1}\)
上快速幂就可以了
#include<bits/stdc++.h>
using namespace std;
#define int __int128
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
int n,m,p;
int qpow(int x,int k) {
int re = 1;
while(k) {
if(k & 1) re = (re * x) % p;
x = (x * x) % p;
k >>= 1;
}
return re;
}
signed main() {
n = rd(),m = rd(),p = rd();
int ans = m;
ans = ans * qpow(m - 1,n - 1) % p;
wt(ans);
return 0;
}
旅游景点
题面:
题目背景
liouzhou_101 住在柳侯公园附近,闲暇时刻都会去公园散散步。
很那啥的就是,柳侯公园的道路太凌乱了,假若不认识路就会走着走着绕回原来的那条路。
liouzhou_101 就开始自己 YY,假若给他当上那啥管理者,就会想尽量减少道路回圈的个数,但是大
范围的改变道路终归不是什么良策。题目描述
经过调查,发现公园有 N 个景点,为了显示景点之间的优越性,我们按照 1,2,…,N 来把这 N 个景点编号,当然编号越小就说明越重要。
为了显示自己的英明决策,liouzhou_101 决定,前 K 重要的景点最为重要,当然他们是标号为 1…K了的。需要保证这 K 个景点不在任何一个环上,原因很简单,这前 K 个景点是很重要的景点,>参观的人也很多,自然不会希望参观的人因为在兜圈子而迷路吧。
于是,我们所能够做的就是把之前建造好的一些道路清除掉,使得保证前 K 重要的景点不在任何一个环上。
输入格式
第一行包括三个正整数 N,M 和 K,N 表示景点的数量,M 表示公园里的路径条数,K 表示前 K 个景点最为重要。
再接下来 M 行,每行有两个正整数 x 和 y,表示景点 x 和景点 y 之间有一条边.
输出格式
仅一行,输出至少去除多少条路径,使得前 K 个重要的景点不在任何一个环上。
样例 #1
样例输入 #1
11 13 5 1 2 1 3 1 5 3 5 2 8 4 11 7 11 6 10 6 9 2 3 8 9 5 9 9 10样例输出 #1
3提示
【提示】
我们的删边方案是,删除(2,3)(5,9)(3,5)这三条边,这样节点 1 到 5 都不在任何一个环上。而且可知删除三条边已经是最少的了。30%的数据,满足 N≤10,M≤20;
60%的数据,满足 N≤1,000,M≤10,000;
100%的数据,满足 N≤100,000,M≤200,000。
注意:给出的无向图可能有重边和自环。
【时限】
1s
因为所有不是重要点之间的边都可以直接连边
对于有重要点的连边,考虑是否会形成环,用并查集判断
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N = 2e5+5,M = 4e5+5;
int n,m,k,ans,s[N];
int e[M][2];
int find(int x){return s[x]==x? x: s[x]=find(s[x]);}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
cin>>n>>m>>k;
for(int i = 1;i<=m;i++) cin>>e[i][0]>>e[i][1];
for(int i = 1;i<=n;i++) s[i] = i;
for(int i = 1;i<=m;i++)
if(e[i][0] > k && e[i][1] > k) {
int fx = find(e[i][0]);
int fy = find(e[i][1]);
s[fx] = fy;
ans++;
}
for(int i = 1;i<=m;i++) {
int fx = find(e[i][0]);
int fy = find(e[i][1]);
if(fx == fy) continue;
s[fx] = fy;
ans++;
}
cout<<m - ans;
return 0;
}
CF718C Sasha and Array
题面:
题面翻译
- 在本题中,我们用 \(f_i\) 来表示第 \(i\) 个斐波那契数(\(f_1=f_2=1,f_i=f_{i-1}+f_{i-2}(i\ge 3)\))。
- 给定一个 \(n\) 个数的序列 \(a\)。有 \(m\) 次操作,操作有两种:
- 将 \(a_l\sim a_r\) 加上 \(x\)。
- 求 \(\displaystyle\left(\sum_{i=l}^r f_{a_i}\right)\bmod (10^9+7)\)。
- \(1\le n,m\le 10^5\),\(1\le a_i\le 10^9\)。
输出格式
For each query of the second type print the answer modulo\(10^{9}+7\).
样例 #1
样例输入 #1
5 4 1 1 2 1 1 2 1 5 1 2 4 2 2 2 4 2 1 5样例输出 #1
5 7 9提示
Initially, array \(a\) is equal to \(1\) , \(1\) , \(2\) , \(1\) ,\(1\).
The answer for the first query of the second type is\(f(1)+f(1)+f(2)+f(1)+f(1)=1+1+1+1+1=5\).
After the query 1 2 4 2 array\(a\)is equal to\(1\),\(3\),\(4\),\(3\),\(1\).
The answer for the second query of the second type is\(f(3)+f(4)+f(3)=2+3+2=7\).
The answer for the third query of the second type is\(f(1)+f(3)+f(4)+f(3)+f(1)=1+2+3+2+1=9\).
矩阵加速递推大家都会!不会左转luogu模板
放到线段树上就好了!
每一个线段树上的点维护一个 \(\begin{bmatrix}f_i & f_{i - 1}\end{bmatrix}\)
因为在矩阵乘法中存在结合律,即:
那么我们在线段树上push_up时,可以对两个节点做 \(+\) 操作
区间修改就用 \(lazy\ tag\) 存矩阵快速幂的结果
初始化的时候用 \(\begin{bmatrix}0 & 1\end{bmatrix}\) 来表示 \(\begin{bmatrix}f_0 & f_{-1}\end{bmatrix}\)
后面正常操作就可以了
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
const int N = 1e5+5,mod = 1e9 + 7;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
template<int N,int M,class T = long long>
struct matrix{
T m[N][M];
matrix() {memset(m,0,sizeof(m));}
matrix(bool _){memset(m,0,sizeof(m));for(int i = 0;i< N && i < M;i++) m[i][i] = 1;}
void unit() {memset(m,0,sizeof(m));for(int i = 0;i< N && i < M;i++) m[i][i] = 1;}
T* operator[] (const int pos) {return m[pos];}
bool empty() {
for(int i = 0;i<N;i++)
for(int j = 0;j<M;j++)
if(i != j && m[i][j])
return false;
return true;
}
};
template<int N,int M,int R,class T = long long>
matrix<N,R,T> operator * (matrix<N,M,T> a,matrix<M,R,T> b) {
matrix<N,R,T> c;
for(int i = 0;i<N;i++)
for(int j = 0;j<M;j++)
for(int k = 0;k<R;k++)
c[i][k] = (c[i][k] + a[i][j] * b[j][k] % mod) % mod;
return c;
}
template<int N,int M,class T = long long>
matrix<N,M,T> operator + (matrix<N,M,T> a,matrix<N,M,T> b) {
matrix<N,M> c;
for(int i = 0;i<N;i++)
for(int j = 0;j<M;j++)
c[i][j] = (c[i][j] + a[i][j] + b[i][j]) % mod;
return c;
}
template<int N,class T = long long>
matrix<N,N,T> qpow(matrix<N,N,T> x,int k) {
matrix<N,N,T> re;
re.unit();
while(k){
if(k & 1) re = re * x;
x = x * x;
k >>= 1;
}
return re;
}
matrix<2,2> base;
matrix<1,2> s;
int a[N],n,m;
namespace sgt{
matrix<1,2> t[N<<2];
matrix<2,2> lazy[N<<2];
#define ls (p << 1)
#define rs (ls | 1)
#define mid ((pl + pr) >> 1)
void push_up(int p) {t[p] = t[ls] + t[rs];}
void build(int p,int pl,int pr) {
lazy[p].unit();
if(pl == pr) {
t[p] = s * qpow(base,a[pl]);
return;
}
build(ls,pl,mid);
build(rs,mid+1,pr);
push_up(p);
}
void push_down(int p) {
if(!lazy[p].empty()) {
t[ls] = t[ls] * lazy[p];
lazy[ls] = lazy[ls] * lazy[p];
t[rs] = t[rs] * lazy[p];
lazy[rs] = lazy[rs] * lazy[p];
lazy[p].unit();
}
}
matrix<2,2> upd;
void update(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) {
t[p] = t[p] * upd;
lazy[p] = lazy[p] * upd;
return;
}
push_down(p);
if(l <= mid) update(ls,pl,mid,l,r);
if(r > mid) update(rs,mid+1,pr,l,r);
push_up(p);
}
matrix<1,2> query(int p,int pl,int pr,int l,int r) {
if(l <= pl && pr <= r) return t[p];
push_down(p);
if(r <= mid) return query(ls,pl,mid,l,r);
else if(l > mid) return query(rs,mid+1,pr,l,r);
else return query(ls,pl,mid,l,r) + query(rs,mid+1,pr,l,r);
}
}
void update() {
int l = rd(),r = rd(),x = rd();
sgt::upd.unit();
sgt::upd = sgt::upd * qpow(base,x);
sgt::update(1,1,n,l,r);
}
void query() {
int l = rd(),r = rd();
wt(sgt::query(1,1,n,l,r)[0][0]);
putchar('\n');
}
signed main() {
base[0][0] = base[0][1] = base[1][0] = 1;
s[0][0] = 0,s[0][1] = 1;
n = rd(),m = rd();
for(int i = 1;i<=n;i++) a[i] = rd();
sgt::build(1,1,n);
while(m--) {
int opt = rd();
switch(opt) {
case 1:
update();
break;
case 2:
query();
break;
default:
puts("ERROR");
exit(0);
break;
}
}
return 0;
}
不得不说,模板template 真是好用
P1850 [NOIP2016 提高组] 换教室
题面:
题目描述
对于刚上大学的牛牛来说,他面临的第一个问题是如何根据实际情况申请合适的课程。
在可以选择的课程中,有 \(2n\) 节课程安排在 \(n\) 个时间段上。在第 \(i\)(\(1 \leq i \leq n\))个时间段上,两节内容相同的课程同时在不同的地点进行,其中,牛牛预先被安排在教室 \(c_i\) 上课,而另一节课程在教室 \(d_i\) 进行。
在不提交任何申请的情况下,学生们需要按时间段的顺序依次完成所有的 \(n\) 节安排好的课程。如果学生想更换第 \(i\) 节课程的教室,则需要提出申请。若申请通过,学生就可以在第 \(i\) 个时间段去教室 \(d_i\) 上课,否则仍然在教室 \(c_i\) 上课。
由于更换教室的需求太多,申请不一定能获得通过。通过计算,牛牛发现申请更换第 \(i\) 节课程的教室时,申请被通过的概率是一个已知的实数 \(k_i\),并且对于不同课程的申请,被通过的概率是互相独立的。
学校规定,所有的申请只能在学期开始前一次性提交,并且每个人只能选择至多 \(m\) 节课程进行申请。这意味着牛牛必须一次性决定是否申请更换每节课的教室,而不能根据某些课程的申请结果来决定其他课程是否申请;牛牛可以申请自己最希望更换教室的 \(m\) 门课程,也可以不用完这 \(m\) 个申请的机会,甚至可以一门课程都不申请。
因为不同的课程可能会被安排在不同的教室进行,所以牛牛需要利用课间时间从一间教室赶到另一间教室。
牛牛所在的大学有 \(v\) 个教室,有 \(e\) 条道路。每条道路连接两间教室,并且是可以双向通行的。由于道路的长度和拥堵程度不同,通过不同的道路耗费的体力可能会有所不同。 当第 \(i\)(\(1 \leq i \leq n-1\))节课结束后,牛牛就会从这节课的教室出发,选择一条耗费体力最少的路径前往下一节课的教室。
现在牛牛想知道,申请哪几门课程可以使他因在教室间移动耗费的体力值的总和的期望值最小,请你帮他求出这个最小值。
输入格式
第一行四个整数 \(n,m,v,e\)。\(n\) 表示这个学期内的时间段的数量;\(m\) 表示牛牛最多可以申请更换多少节课程的教室;\(v\) 表示牛牛学校里教室的数量;\(e\) 表示牛牛的学校里道路的数量。
第二行 \(n\) 个正整数,第 \(i\)(\(1 \leq i \leq n\))个正整数表示 \(c_i\),即第 \(i\) 个时间段牛牛被安排上课的教室;保证 \(1 \le c_i \le v\)。
第三行 \(n\) 个正整数,第 \(i\)(\(1 \leq i \leq n\))个正整数表示 \(d_i\),即第 \(i\) 个时间段另一间上同样课程的教室;保证 \(1 \le d_i \le v\)。
第四行 \(n\) 个实数,第 \(i\)(\(1 \leq i \leq n\))个实数表示 \(k_i\),即牛牛申请在第 \(i\) 个时间段更换教室获得通过的概率。保证 \(0 \le k_i \le 1\)。
接下来 \(e\) 行,每行三个正整数 \(a_j, b_j, w_j\),表示有一条双向道路连接教室 \(a_j, b_j\),通过这条道路需要耗费的体力值是 \(w_j\);保证 \(1 \le a_j, b_j \le v\),\(1 \le w_j \le 100\)。
保证 \(1 \leq n \leq 2000\),\(0 \leq m \leq 2000\),\(1 \leq v \leq 300\),\(0 \leq e \leq 90000\)。
保证通过学校里的道路,从任何一间教室出发,都能到达其他所有的教室。
保证输入的实数最多包含 \(3\) 位小数。
输出格式
输出一行,包含一个实数,四舍五入精确到小数点后恰好 \(2\) 位,表示答案。你的输出必须和标准输出完全一样才算正确。
测试数据保证四舍五入后的答案和准确答案的差的绝对值不大于 \(4 \times 10^{-3}\)。(如果你不知道什么是浮点误差,这段话可以理解为:对于大多数的算法,你可以正常地使用浮点数类型而不用对它进行特殊的处理)
样例 #1
样例输入 #1
3 2 3 3 2 1 2 1 2 1 0.8 0.2 0.5 1 2 5 1 3 3 2 3 1样例输出 #1
2.80提示
样例 1 说明
所有可行的申请方案和期望收益如下:
- 不作申请,耗费的体力值的期望为 \(8.0\)。
申请通过的时间段 出现的概率 耗费的体力值 无 \(1.0\) \(8\)
- 申请更换第 \(1\) 个时间段的上课教室,耗费的体力值的期望为 \(4.8\)。
申请通过的时间段 出现的概率 耗费的体力值 \(1\) \(0.8\) \(4\) 无 \(0.2\) \(8\)
- 申请更换第 \(2\) 个时间段的上课教室,耗费的体力值的期望为 \(6.4\)。
申请通过的时间段 出现的概率 耗费的体力值 \(2\) \(0.2\) \(0\) 无 \(0.8\) \(8\)
- 申请更换第 \(3\) 个时间段的上课教室,耗费的体力值的期望为 \(6.0\)。
申请通过的时间段 出现的概率 耗费的体力值 \(3\) \(0.5\) \(4\) 无 \(0.5\) \(8\)
- 申请更换第 \(1,2\) 个时间段的上课教室,耗费的体力值的期望为 \(4.48\)。
申请通过的时间段 出现的概率 耗费的体力值 \(1,2\) \(0.16\) \(4\) \(1\) \(0.64\) \(4\) \(2\) \(0.04\) \(0\) 无 \(0.16\) \(8\)
- 申请更换第 \(1,3\) 个时间段的上课教室,耗费的体力值的期望为 \(2.8\)。
申请通过的时间段 出现的概率 耗费的体力值 \(1,3\) \(0.4\) \(0\) \(1\) \(0.4\) \(4\) \(3\) \(0.1\) \(4\) 无 \(0.1\) \(8\)
- 申请更换第 \(2,3\) 个时间段的上课教室,耗费的体力值的期望为 \(5.2\)。
申请通过的时间段 出现的概率 耗费的体力值 \(2,3\) \(0.1\) \(4\) \(2\) \(0.1\) \(0\) \(3\) \(0.4\) \(4\) 无 \(0.4\) \(8\) 因此,最优方案为:申请更换第 \(1,3\) 个时间段的上课教室。耗费的体力值的期望为 \(2.8\)。
提示
- 道路中可能会有多条双向道路连接相同的两间教室。 也有可能有道路两端连接的是同一间教室。
- 请注意区分 \(n,m,v,e\) 的意义, \(n\) 不是教室的数量, \(m\) 不是道路的数量。
数据范围与说明
测试点编号 \(n\le\) \(m\le\) \(v\le\) 是否具有特殊性质 1 是否具有特殊性质 2 1 \(1\) \(1\) \(300\) \(\times\) \(\times\) 2 \(2\) \(0\) \(20\) \(\times\) \(\times\) 3 \(2\) \(1\) \(100\) \(\times\) \(\times\) 4 \(2\) \(2\) \(300\) \(\times\) \(\times\) 5 \(3\) \(0\) \(20\) \(\surd\) \(\surd\) 6 \(3\) \(1\) \(100\) \(\surd\) \(\times\) 7 \(3\) \(2\) \(300\) \(\times\) \(\times\) 8 \(10\) \(0\) \(300\) \(\surd\) \(\surd\) 9 \(10\) \(1\) \(20\) \(\surd\) \(\times\) 10 \(10\) \(2\) \(100\) \(\times\) \(\times\) 11 \(10\) \(10\) \(300\) \(\times\) \(\surd\) 12 \(20\) \(0\) \(20\) \(\surd\) \(\times\) 13 \(20\) \(1\) \(100\) \(\times\) \(\times\) 14 \(20\) \(2\) \(300\) \(\surd\) \(\times\) 15 \(20\) \(20\) \(300\) \(\times\) \(\surd\) 16 \(300\) \(0\) \(20\) \(\times\) \(\times\) 17 \(300\) \(1\) \(100\) \(\times\) \(\times\) 18 \(300\) \(2\) \(300\) \(\surd\) \(\surd\) 19 \(300\) \(300\) \(300\) \(\times\) \(\surd\) 20 \(2000\) \(0\) \(20\) \(\times\) \(\times\) 21 \(2000\) \(1\) \(20\) \(\times\) \(\times\) 22 \(2000\) \(2\) \(100\) \(\times\) \(\times\) 23 \(2000\) \(2000\) \(100\) \(\times\) \(\times\) 24 \(2000\) \(2000\) \(300\) \(\times\) \(\times\) 25 \(2000\) \(2000\) \(300\) \(\times\) \(\times\) 特殊性质 1:图上任意不同的两点 \(u,v\) 间,存在一条耗费体力最少的路径只包含一条道路。
特殊性质 2:对于所有的 \(1≤ i≤ n,\ k_i= 1\)。
换,还是不换?这由 \(dp\) 说的算!
\(V \in [20,300]\) 果断 floyd
求出 \(dis\) 数组,然后考虑设计状态(为表示方便,后面用 \(g\) 表示最短路)
无非 换不换 的问题,用 \([0/1]\) 表示
换的个数有限制,用 \([0 \sim m]\) 描述
总课程有限,用 \([0\sim n]\) 描述
所以 \(dp\) 状态为 \(f_{i:0\sim n,j:0\sim m,0/1}\),表示 前 \(i\) 次课程,已经换了 \(j\) 次,本次换没换的期望值
考虑转移!
本次不换的转移:
本次换的转移:
注意初始化,\(f_{1,0,0} = f_{1,1,1} = 0\)
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int V = 305,N = 2005;
int n,m,v,e;
int dis[V][V];
int c[N],d[N];
double k[N];
double f[N][N][2];
signed main() {
memset(dis,0x3f,sizeof(dis));
n = rd(),m = rd(),v = rd(),e = rd();
for(int i = 1;i<=n;i++) c[i] = rd();
for(int i = 1;i<=n;i++) d[i] = rd();
for(int i = 1;i<=n;i++) scanf("%lf",&k[i]);
for(int i = 1;i<=e;i++) {
int u = rd(),v = rd(),w = rd();
dis[u][v] = dis[v][u] = min(dis[u][v],w);
}
for(int i = 1;i<=v;i++) dis[i][i] = 0;
for(int k = 1;k<=v;k++)
for(int i = 1;i<=v;i++)
for(int j = 1;j<=v;j++)
dis[i][j] = min(dis[i][j],dis[i][k] + dis[k][j]);
for(int i = 1;i<=v;i++) dis[i][0] = dis[0][i] = 0;
for(int i = 0;i<=n;i++)
for(int j = 0;j<=m;j++)
f[i][j][0] = f[i][j][1] = 1e18;
f[1][0][0] = f[1][1][1] = 0;
for(int i = 2;i<=n;i++){
f[i][0][0] = f[i - 1][0][0] + dis[c[i - 1]][c[i]];
for(int j = 1;j<=min(i,m);j++) {
f[i][j][0] = min(f[i][j][0],f[i - 1][j][0] + dis[c[i - 1]][c[i]]);
f[i][j][0] = min(f[i][j][0],f[i - 1][j][1] + dis[c[i - 1]][c[i]] * (1 - k[i - 1]) + dis[d[i - 1]][c[i]] * k[i - 1]);
f[i][j][1] = min(f[i][j][1],(f[i - 1][j - 1][0]) + dis[c[i - 1]][c[i]] * (1 - k[i]) + dis[c[i - 1]][d[i]] * k[i]);
f[i][j][1] = min(f[i][j][1],(f[i - 1][j - 1][1]) + dis[c[i - 1]][c[i]] * (1 - k[i - 1]) * (1 - k[i]) + dis[d[i - 1]][c[i]] * k[i - 1] * (1 - k[i]) + dis[c[i - 1]][d[i]] * (1 - k[i - 1]) * k[i] + dis[d[i - 1]][d[i]] * k[i - 1] * k[i]);
}
}
double ans = (double)(1e18);
for(int i = 0;i<=m;i++) ans = min(ans,min(f[n][i][0],f[n][i][1]));
printf("%.2lf",ans);
return 0;
}
/*
3 2 3 3
2 1 2
1 2 1
0.8 0.2 0.5
1 2 5
1 3 3
2 3 1
*/
2024/08/29
明天就要报到了,累(作业还没写完
P7075 [CSP-S2020] 儒略日
题面:
题目描述
为了简便计算,天文学家们使用儒略日(Julian day)来表达时间。所谓儒略日,其定义为从公元前 4713 年 1 月 1 日正午 12 点到此后某一时刻间所经过的天数,不满一天者用小数表达。若利用这一天文学历法,则每一个时刻都将被均匀的映射到数轴上,从而得以很方便的计算它们的差值。
现在,给定一个不含小数部分的儒略日,请你帮忙计算出该儒略日(一定是某一天的中午 12 点)所对应的公历日期。
我们现行的公历为格里高利历(Gregorian calendar),它是在公元 1582 年由教皇格里高利十三世在原有的儒略历(Julian calendar)的基础上修改得到的(注:儒略历与儒略日并无直接关系)。具体而言,现行的公历日期按照以下规则计算:
- 公元 1582 年 10 月 15 日(含)以后:适用格里高利历,每年一月 \(31\) 天、 二月 \(28\) 天或 \(29\) 天、三月 \(31\) 天、四月 \(30\) 天、五月 \(31\) 天、六月 \(30\) 天、七月 \(31\) 天、八月 \(31\) 天、九月 \(30\) 天、十月 \(31\) 天、十一月 \(30\) 天、十二月 \(31\) 天。其中,闰年的二月为 \(29\) 天,平年为 \(28\) 天。当年份是 \(400\) 的倍数,或日期年份是 \(4\) 的倍数但不是 \(100\) 的倍数时,该年为闰年。
- 公元 1582 年 10 月 5 日(含)至 10 月 14 日(含):不存在,这些日期被删除,该年 10 月 4 日之后为 10 月 15 日。
- 公元 1582 年 10 月 4 日(含)以前:适用儒略历,每月天数与格里高利历相同,但只要年份是 \(4\) 的倍数就是闰年。
- 尽管儒略历于公元前 45 年才开始实行,且初期经过若干次调整,但今天人类习惯于按照儒略历最终的规则反推一切 1582 年 10 月 4 日之前的时间。注意,公元零年并不存在,即公元前 1 年的下一年是公元 1 年。因此公元前 1 年、前 5 年、前 9 年、前 13 年……以此类推的年份应视为闰年。
输入格式
第一行一个整数 \(Q\),表示询问的组数。
接下来 \(Q\) 行,每行一个非负整数 \(r_i\),表示一个儒略日。输出格式
对于每一个儒略日 \(r_i\),输出一行表示日期的字符串 \(s_i\)。共计 \(Q\) 行。 \(s_i\) 的格式如下:
- 若年份为公元后,输出格式为
Day Month Year。其中日(Day)、月(Month)、年(Year)均不含前导零,中间用一个空格隔开。例如:公元
2020 年 11 月 7 日正午 12 点,输出为7 11 2020。- 若年份为公元前,输出格式为
Day Month Year BC。其中年(Year)输出该年份的数值,其余与公元后相同。例如:公元前 841 年 2 月 1 日正午 12
点,输出为1 2 841 BC。样例 #1
样例输入 #1
3 10 100 1000样例输出 #1
11 1 4713 BC 10 4 4713 BC 27 9 4711 BC样例 #2
样例输入 #2
3 2000000 3000000 4000000样例输出 #2
14 9 763 15 8 3501 12 7 6239样例 #3
样例输入 #3
见附件中的 julian/julian3.in样例输出 #3
见附件中的 julian/julian3.ans提示
【数据范围】
测试点编号 \(Q =\) \(r_i \le\) \(1\) \(1000\) \(365\) \(2\) \(1000\) \(10^4\) \(3\) \(1000\) \(10^5\) \(4\) \(10000\) \(3\times 10^5\) \(5\) \(10000\) \(2.5\times 10^6\) \(6\) \(10^5\) \(2.5\times 10^6\) \(7\) \(10^5\) \(5\times 10^6\) \(8\) \(10^5\) \(10^7\) \(9\) \(10^5\) \(10^9\) \(10\) \(10^5\) 年份答案不超过 \(10^9\)
有点大的模拟,放在 CSP-D2T1 恐怖如斯.
我们看到 "年份答案不超过 \(10^9\)" 这句话,意味着我们肯定用二分,其他方法我赛场上多半想不到吧.
二分年份,但是分讨,分为公元前和公元后,公元后又分为 \(1582\) 年以前,\(1582\) 年以后.
公元前注意刚开始的 \(BC\) \(4713\) 年 \(1\) 月份 只有 \(30\) 天,且闰年为 \(\{x | [4 \mid (x - 1)]\}\)
我们可以通过另起一个程序暴力计算公元前的天数为 :\(1721423\),
由于 \(1582\) 年前 闰年为 \({x | [4 \mid x]}\),\(1582\) 年后 闰年为 \(\{x | [(4 \mid x \bigwedge 100 \nmid x)\bigvee(400 \mid x)]\}\),且 \(1582\) 年的 \(10\) 月 消失了 \(5 \sim 14\) 这 \(10\) 天
所以,新建一个程序算出公元 \(1 \sim 1582\) 年 (含 \(1582\) 年) 共计 \(577815\) 天
判断闰年的时候,公元前 \(4713\) 本身就是闰年,但是他的 \(1\) 月份只有 \(30\) 天,所以他这年本身还是 \(365\) 天
其中分讨时,公元前闰月(除去 \(4713\) 年)有 \(\frac{4713 - T - 1}{4}\) 个(\(T\) 为终止年份),公元 \(1582\) 年以前有 \(\frac{T}{4}\),
公元 \(1582\) 年后的 \(1584\) 年是第一个闰年,请以此为基准进行计算,在 \(1584\) 年之后、\(1600\) 年之前 有 \(\frac{T - 1584}{4} + 1\) 个闰年,
公元后 \(1600\) 年之后,用容斥计算,有 \(\frac{T - 1584}{4} + 1 - \frac{T - 1600}{100} - 1 + \frac{T - 1600}{400} + 1 = \frac{T - 1584}{4} - \frac{T - 1600}{100} + \frac{T - 1600}{400} + 1\) 个闰年。
闰月的计算先告一段落,来谈谈二分
我已经被所谓万能二分搞崩溃了,决心还是不用了
请正常二分,设计 \(check\) 函数,求到达目前年份 \(1\) 月 \(1\) 日的总天数,尤其是上面的闰年的计算需要重点关注!
因为公元没有 \(0\) 世纪,所以二分的 \(mid\) 是要减一计算的。
然后是月份计算,先判断重要月份,预处理出 \(BC\ 4713\) 年的月份天数前缀和,\(1582\) 年的月份天数前缀和,闰年的月份天数前缀和,非闰年的月份天数前缀和,和它们每个月的天数
int _m[13] = {0,31,28,31,30,31,30,31,31,30,31,30,31};
int yeapm[13] = {0,31,29,31,30,31,30,31,31,30,31,30,31};
int _sm[13] = {0,31,59,90,120,151,181,212,243,273,304,334,365};
int yeap_sm[13] = {0,31,60,91,121,152,182,213,244,274,305,335,366};
int _1852[13] = {0,31,28,31,30,31,30,31,31,30,21,30,31};
int _s1852[13] = {0,31,59,90,120,151,181,212,243,273,294,324,355};
int _4713[13] = {0,30,29,31,30,31,30,31,31,30,31,30,31};
int _s4713[13] = {0,30,59,90,120,151,181,212,243,273,304,334,365};
然后针对 \(1582\),\(BC\ 4713\),闰年,非闰年 分讨;我校学长经典名言:分分分 \(\times\times\times\) 讨讨讨 \(\sqrt{}\sqrt{}\sqrt{}\)
注意!有一组数据是
input:
...
0
...
output:
...
1 1 4713 BC
...
请不要输出
...
0 0 4713 BC
...
本人就是因为这个没有过第一个点。
然后减去前面月份的天数前缀和,
再对 \(1582\) 年的 \(10\) 月份和 \(BC\ 4713\) 的 \(1\) 月份进行特判即可!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
namespace workspace{
int y,m,d;
bool BC = false;
const int bef = 1721423;
int getytd(int yr) {
int re = 0,ypyr = 0;
if(!BC) {
yr--;
if(yr >= 1582) {
re += 577815;
if(yr >= 1584) ypyr += (yr - 1584) / 4 + 1;
if(yr >= 1600) ypyr -= (yr - 1600) / 100 + 1,ypyr += (yr - 1600) / 400 + 1;
yr -= 1582;
}else ypyr = yr / 4;
}else {
yr = 4713 - yr;
ypyr += (yr - 1) / 4;
}
re = ypyr + yr * 365 + re;
return re;
}
bool yeap(int yr) {
if(BC) return ((yr - 1) % 4 == 0);
else if(yr <= 1582) return (yr % 4 == 0);
return ((yr % 4 == 0 && yr % 100 != 0)|| yr % 400 == 0);
}
int _m[13] = {0,31,28,31,30,31,30,31,31,30,31,30,31};
int yeapm[13] = {0,31,29,31,30,31,30,31,31,30,31,30,31};
int _sm[13] = {0,31,59,90,120,151,181,212,243,273,304,334,365};
int yeap_sm[13] = {0,31,60,91,121,152,182,213,244,274,305,335,366};
int _1852[13] = {0,31,28,31,30,31,30,31,31,30,21,30,31};
int _s1852[13] = {0,31,59,90,120,151,181,212,243,273,294,324,355};
int _4713[13] = {0,30,29,31,30,31,30,31,31,30,31,30,31};
int _s4713[13] = {0,30,59,90,120,151,181,212,243,273,304,334,365};
void getday(int yr,int mon,int dy) {
if(!BC && yr == 1582 && mon == 10) {
if(dy <= 4) d = dy;
else d = dy + 10;
}else if(BC && yr == 4713 && mon == 1){
d = dy + 1;
}else d = dy;
}
void getmonth(int yr,int dy) {
int &mon = m;
if(!BC && yr == 1582) {
while(mon++ < 12) if(_s1852[mon] > dy) break;
dy -= _s1852[mon - 1];
if(dy == 0) dy = _1852[--mon];
}else if(BC && yr == 4713) {
while(mon++ < 12) if(_s4713[mon] > dy) break;
dy -= _s4713[mon - 1];
if(dy == 0) dy = _4713[--mon];
}else if(yeap(yr)) {
while(mon++ < 12) if(yeap_sm[mon] > dy) break;
dy -= yeap_sm[mon - 1];
if(dy == 0) dy = yeapm[--mon];
}else {
while(mon++ < 12) if(_sm[mon] > dy) break;
dy -= _sm[mon - 1];
if(dy == 0) dy = _m[--mon];
}
if(m == 0) dy = 0,m++;
getday(y,m,dy);
}
void getyear(int dy) {
int del = 0;
if(!BC) {
int l = 1,r = 1e9+5;
while(l < r) {
int mid = (l + r + 1) >> 1;
int t = getytd(mid);
if(t >= dy) r = mid - 1; //本年份不计算
else l = mid,del = t;
}
y = l;
}else {
int l = 1,r = 4713;
while(l < r) {
int mid = (l + r) >> 1;
int t = getytd(mid);
if(t >= dy) l = mid + 1;
else r = mid,del = t;
}
y = r;
}
getmonth(y,dy - del);
}
void print() {
wt(d),putchar(' ');
wt(m),putchar(' ');
wt(y),putchar(' ');
if(BC) putchar('B'),putchar('C');
putchar('\n');
}
void solve(){
y = m = d = 0;
int r = rd();
BC = r < bef;
getyear(BC ? r : r - bef);
print();
}
}
signed main() {
int q = rd();
while(q--) workspace::solve();
return 0;
}
/*
良心数据,检查你是否也在这些数据上栽了
2
2000000
3000000
1
154059721
2
3251
8793
1
2378588
1
1721236
*/
模拟还是一如既往的简单但难写
2024/08/30
模拟不要怎么搞都暴搜!
P4050 [JSOI2007] 麻将
题面:
题目描述
麻将是中国传统的娱乐工具之一。麻将牌的牌可以分为字牌(共有东、南、西、北、中、发、白七种)和序数牌(分为条子、饼子、万子三种花色,每种花色各有一到九的九种牌),每种牌各四张。
在麻将中,通常情况下一组和了的牌(即完成的牌)由十四张牌组成。十四张牌中的两张组成对子(即完全相同的两张牌),剩余的十二张组成三张一组的四组,每一组须为顺子(即同花色且序数相连的序数牌,例如条子的三、四、五)或者是刻子(即完全相同的三张牌)。一组听牌的牌是指一组十三张牌,且再加上某一张牌就可以组成和牌。那一张加上的牌可以称为等待牌。
在这里,我们考虑一种特殊的麻将。在这种特殊的麻将里,没有字牌,花色也只有一种。但是,序数不被限制在一到九的范围内,而是在1到n的范围内。同时,也没有每一种牌四张的限制。一组和了的牌由3m + 2张牌组成,其中两张组成对子,其余3m张组成三张一组的m组,每组须为顺子或刻子。现给出一组3m + 1张的牌,要求判断该组牌是否为听牌(即还差一张就可以和牌)。如果是的话,输出所有可能的等待牌。
输入格式
包含两行。第一行包含两个由空格隔开整数n, m (9<=n<=400, 4<=m<=1000)。第二行包含3m + 1个由空格隔开整数,每个数均在范围1到n之内。这些数代表要求判断听牌的牌的序数。
输出格式
输出为一行。如果该组牌为听牌,则输出所有的可能的等待牌的序数,数字之间用一个空格隔开。所有的序数必须按从小到大的顺序输出。如果该组牌不是听牌,则输出"NO"。
样例 #1
样例输入 #1
9 4 1 1 2 2 3 3 5 5 5 7 8 8 8样例输出 #1
6 7 9
暴搜只能喜提 \(10 \sim 20\) 分
缺字,我们补上,判断是否合法。(摈弃一些正向思维)
我们再来看牌型的影响,对子、刻子 影响的是本身,而顺子影响的是连续的 \(3\) 个数.
由于牌中只能有一个对子,我们考虑扣掉,枚举对子,判断是否合法
当我们判断到 \(x\) 时,如果 \(x\) 可以凑成刻子,毫不犹豫凑成,因为他不影响到 \(x + 1,x + 2\) 这些位置,
我们枚举顺子的起点为 \(i\) ,
因为 如果到 \(x + 1\) 后,\(x\) 位置还没有清完,说明失败了!
所以我们会不惜一切代价将凑完刻子的剩余 \(x\) 牌用来凑顺子,如果凑不出来,就说明失败了
注意这些就可以在 \(\mathcal{O}(n^3)\) 下跑过
AC-code:
#include<bits/stdc++.h>
using namespace std;
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
int n,m,card[405];
namespace workplace{
int a[405];
bool check() {
for(int i = 1;i<=n;i++) {
if(card[i] >= 2) {
card[i] -= 2;
bool ok = true;
for(int j = 1;j<=n + 2;j++) a[j] = card[j];
for(int j = 1;j<=n + 2;j++) {
if(a[j] < 0) {
ok = false;
break;
}
a[j] %= 3;
a[j + 1] -= a[j];
a[j + 2] -= a[j];
}
card[i] += 2;
if(ok) return true;
}
}
return false;
}
void solve() {
bool non = 0,re = false;
for(int i = 1;i<=n;i++) {
card[i]++;
non |= (re = check());
if(re)
wt(i),putchar(' ');
card[i]--;
}
if(!non) puts("NO");
}
}
signed main() {
n = rd(),m = rd();
for(int i = 1;i<=3 * m + 1;i++) card[rd()]++;
workplace::solve();
return 0;
}
P8865 [NOIP2022] 种花
非常优质的签到题
题面:
题目描述
小 C 决定在他的花园里种出 \(\texttt{CCF}\) 字样的图案,因此他想知道 \(\texttt C\) 和 \(\texttt F\) 两个字母各自有多少种种花的方案;不幸的是,花园中有一些土坑,这些位置无法种花,因此他希望你能帮助他解决这个问题。
花园可以看作有 \(n\times m\) 个位置的网格图,从上到下分别为第 \(1\) 到第 \(n\) 行,从左到右分别为第 \(1\) 列到第 \(m\) 列,其中每个位置有可能是土坑,也有可能不是,可以用 \(a_{i,j} = 1\) 表示第 \(i\) 行第 \(j\) 列这个位置有土坑,否则用 \(a_{i,j} = 0\) 表示这个位置没土坑。
一种种花方案被称为 \(\texttt{C-}\) 形的,如果存在 \(x_1, x_2 \in [1, n]\),以及 \(y_0, y_1, y_2 \in [1, m]\),满足 \(x_1 + 1 < x_2\),并且 \(y_0 < y_1, y_2 \leq m\),使得第 \(x_1\) 行的第 \(y_0\) 到第 \(y_1\) 列、第 \(x_2\) 行的第 \(y_0\) 到第 \(y_2\) 列以及第 \(y_0\) 列的第 \(x_1\) 到第 \(x_2\) 行都不为土坑,且只在上述这些位置上种花。
一种种花方案被称为 \(\texttt{F-}\) 形的,如果存在 \(x_1, x_2, x_3 \in [1, n]\),以及 \(y_0, y_1, y_2 \in [1, m]\),满足 \(x_1 + 1 < x_2 < x_3\),并且 \(y_0 < y_1, y_2 \leq m\),使得第 \(x_1\) 行的第 \(y_0\) 到第 \(y_1\) 列、第 \(x_2\) 行的第 \(y_0\) 到第 \(y_2\) 列以及第 \(y_0\) 列的第 \(x_1\) 到第 \(x_3\) 行都不为土坑,且只在上述这些位置上种花。
样例一解释中给出了 \(\texttt{C-}\) 形和 \(\texttt{F-}\) 形种花方案的图案示例。
现在小 C 想知道,给定 \(n, m\) 以及表示每个位置是否为土坑的值 \(\{a_{i,j}\}\),\(\texttt{C-}\) 形和 \(\texttt{F-}\) 形种花方案分别有多少种可能?由于答案可能非常之大,你只需要输出其对 \(998244353\) 取模的结果即可,具体输出结果请看输出格式部分。
输入格式
第一行包含两个整数 \(T, id\),分别表示数据组数和测试点编号。如果数据为样例则保证 \(id = 0\)。
接下来一共 \(T\) 组数据,在每组数据中:
第一行包含四个整数 \(n, m, c, f\),其中 \(n, m\) 分别表示花园的行数、列数,对于 \(c, f\) 的含义见输出格式部分。
接下来 \(n\) 行,每行包含一个长度为 \(m\) 且仅包含 \(0\) 和 \(1\) 的字符串,其中第 \(i\) 个串的第 \(j\) 个字符表示 \(a_{i,j}\),即花园里的第 \(i\) 行第 \(j\) 列是不是一个土坑。
输出格式
设花园中 \(\texttt{C-}\) 形和 \(\texttt{F-}\) 形的种花方案分别有 \(V_C\) 和 \(V_F\) 种,则你需要对每一组数据输出一行用一个空格隔开的两个非负整数,分别表示 \((c \times V_C) \bmod 998244353\),\((f \times V_F ) \bmod 998244353\) ,其中 \(a \bmod P\) 表示 \(a\) 对 \(P\) 取模后的结果。
样例 #1
样例输入 #1
1 0 4 3 1 1 001 010 000 000样例输出 #1
4 2提示
【样例 1 解释】
四个 \(\texttt{C-}\) 形种花方案为:
**1 **1 **1 **1 *10 *10 *10 *10 **0 *** *00 *00 000 000 **0 ***其中 \(\texttt*\) 表示在这个位置种花。注意 \(\texttt C\) 的两横可以不一样长。
类似的,两个 \(\texttt{F-}\) 形种花方案为:
**1 **1 *10 *10 **0 *** *00 *00【样例 2】
见附件下的 \(\texttt{plant/plant2.in}\) 与 \(\texttt{plant/plant2.ans}\)。
【样例 3】
见附件下的 \(\texttt{plant/plant3.in}\) 与 \(\texttt{plant/plant3.ans}\)。
【数据范围】
对于所有数据,保证:\(1 \leq T \leq 5\),\(1 \leq n, m \leq 10^3\),\(0 \leq c, f \leq 1\),\(a_{i,j} \in \{0, 1\}\)。
测试点编号 \(n\) \(m\) \(c=\) \(f=\) 特殊性质 测试点分值 \(1\) \(\leq 1000\) \(\leq 1000\) \(0\) \(0\) 无 \(1\) \(2\) \(=3\) \(=2\) \(1\) \(1\) 无 \(2\) \(3\) \(=4\) \(=2\) \(1\) \(1\) 无 \(3\) \(4\) \(\leq 1000\) \(=2\) \(1\) \(1\) 无 \(4\) \(5\) \(\leq 1000\) \(\leq 1000\) \(1\) \(1\) A \(4\) \(6\) \(\leq 1000\) \(\leq 1000\) \(1\) \(1\) B \(6\) \(7\) \(\leq 10\) \(\leq 10\) \(1\) \(1\) 无 \(10\) \(8\) \(\leq 20\) \(\leq 20\) \(1\) \(1\) 无 \(6\) \(9\) \(\leq 30\) \(\leq 30\) \(1\) \(1\) 无 \(6\) \(10\) \(\leq 50\) \(\leq 50\) \(1\) \(1\) 无 \(8\) \(11\) \(\leq 100\) \(\leq 100\) \(1\) \(1\) 无 \(10\) \(12\) \(\leq 200\) \(\leq 200\) \(1\) \(1\) 无 \(6\) \(13\) \(\leq 300\) \(\leq 300\) \(1\) \(1\) 无 \(6\) \(14\) \(\leq 500\) \(\leq 500\) \(1\) \(1\) 无 \(8\) \(15\) \(\leq 1000\) \(\leq 1000\) \(1\) \(0\) 无 \(6\) \(16\) \(\leq 1000\) \(\leq 1000\) \(1\) \(1\) 无 \(14\) 特殊性质 A:\(\forall 1 \leq i \leq n, 1 \leq j \leq \left\lfloor \frac{m}{3} \right\rfloor\),\(a_{i, 3 j} = 1\);
特殊性质 B:\(\forall 1 \leq i \leq \left\lfloor \frac{n}{4} \right\rfloor, 1 \leq j \leq m\),\(a_{4 i, j} = 1\);
简单计数题:
先看到数据规模:\(n \leq 1000,m \leq 1000,T \leq 5\),告诉我们复杂度大概是 \(\mathcal{O}(Tnm)\)
先考虑 \(C\) 形,
我们可以确定 \(C\) 形的左上角 \(\mathcal{O}(nm)\),
然后,我们的目标是:
- 求出 \(C\) 第一行长度的可能结果数
- 求出 \(C\) 第一列的可取长度的范围
- 求出 \(C\) 每一列长度对应的行的可能结果数
- 目标 \(1\) 和 目标 \(3\) 相乘累加到答案中
以上的步骤全部需要 \(\mathcal{O}(1)\) 完成,所以我们考虑预处理
对于 目标 \(1\),我们可以预处理出 位置 \((i,j)\) 离右手边最近的障碍的距离。
对于 目标 \(3\),一个个算肯定是 武则天丧夫 没理智的,但是我们求的是一个区间结果,这个时候就该考虑前缀和
我们用新的数组存储(我们预处理的右手边最近障碍距离)的前缀和,在执行目标 \(3\) 时用前缀和作差求出结果。
但是 差 是多少?
我们可以再预处理 位置 \((i,j)\) 离正下方最近障碍的距离。那么我们询问的区间就是 \((x + 2,j) \sim (x + dis(x),j)\)
自此 \(C\) 形就解决了!
再考虑 \(F\) 形:
ta 和 \(C\) 有什么区别呢?不就是第一列可以有个小尾巴嘛!
如果我们已经确定了 \(F\) 形的第二 横,那么可以得到累加多少结果呢?
很显然是 小尾巴 的长度。那么我们对于每一个可能的横都可以预处理出带上小尾巴的结果数,
然后还是熟悉的区间结果查询,我们依旧对上述结果做前缀和。
注意多测!清空 + 换行!
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
void wt(int x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
int T,id;
namespace workspace{
const int N = 1005,mod = 998244353;
int n,m,c,f;
char d[N];
int s[N][N],h[N][N];
int ss[N][N],_s[N][N];
void init() {
memset(s,0,sizeof(s));
memset(ss,0,sizeof(ss));
memset(h,0,sizeof(h));
memset(_s,0,sizeof(_s));
}
void solve() {
init();
n = rd(),m = rd(),c = rd(),f = rd();
for(int i = 1;i<=n;i++) {
scanf("%s",d + 1);
for(int j = 1;j<=m;j++)
s[i][j] = d[j] - '0';
}
for(int j = 1;j<=m;j++)
for(int i = n,k = n + 1;i>=1;i--)
if(s[i][j]) k = i,h[i][j] = k - i - 1;
else h[i][j] = k - i - 1;
for(int i = 1;i<=n;i++)
for(int j = m,k = m + 1;j >= 1;j--)
if(s[i][j]) k = j,s[i][j] = k - j - 1;
else s[i][j] = k - j - 1;
for(int j = 1;j<=m;j++) {
for(int i = n;i>=1;i--){
ss[i][j] = ss[i + 1][j] + s[i][j];
_s[i][j] = s[i][j] * h[i][j];
_s[i][j] = _s[i + 1][j] + _s[i][j];
}
}
int C = 0,F = 0;
for(int j = 1;j<=m;j++) {
int k = 1,re = 0;
while(k + 2 <= n) {
while((s[k][j] == -1 || s[k + 1][j] == -1 || s[k + 2][j] == -1) && k <= n) k++;
if(k >= n - 1) break;
re = s[k][j];
(C += re * (ss[k + 2][j] - ss[k + h[k][j] + 1][j])) %= mod;
if(k + 3 <= n && ~s[k + 3][j])
(F += re * (_s[k + 2][j] - _s[k + h[k][j] + 1][j])) %= mod;
k++;
}
}
wt(c * C),putchar(' '),wt(f * F);
putchar('\n');
}
}
signed main() {
T = rd(),rd();
while(T--) workspace::solve();
return 0;
}
2024/08/31
炼石计划 NOIP模拟 #1
A. 北极星
题目描述
输入格式
输出格式
样例
数据范围与提示
正着想,肯定不得好死,后面的操作影响前面的数字
但是反着想,我们的行为变成了:
每次可以对队列最后的数字进行 \(-1\)、\(\div 2\ 且会使前面的数字整体\ +1\) 等操作
如何构造使得队列中元素都变成 \(0\)
这就很好想:我们从后往前一个个消灭,每一次 \(+\) 操作给全局tag \(+1\)
这道题成功在赛时唐出来了——(难绷
AC-code:
#include<bits/stdc++.h>
using namespace std;
#define int long long
int tag = 0;
string t = "";
string opt[2] = {"1+","c+"};
void get(int x) {
string s = "";
int p = x;
x >>= 1;
bool flag = true;
while(x) {
s = opt[1] + s;
tag++;
if(x & 1 && x > 1) s = opt[0] + s,tag++;
x >>= 1;
}
if(p & 1) s = s + "1+",tag++;
s = "1" + s;
t = s + t;
}
signed main() {
ios::sync_with_stdio(false);
cin.tie(nullptr);cout.tie(nullptr);
freopen("polaris.in","r",stdin);
freopen("polaris.out","w",stdout);
int n;
cin>>n;
vector<int> b(n + 1);
for(int i = 1;i<=n;i++)
cin>>b[i];
for(int i = n;i >= 1;i--)
get(b[i] + tag);
cout<<t;
return 0;
}
P3960 [NOIP2017 提高组] 列队
题面:
题目背景
NOIP2017 D2T3
题目描述
Sylvia是一个热爱学习的女孩子。前段时间,
Sylvia参加了学校的军训。众所周知,军训的时候需要站方阵。Sylvia 所在的方阵中有 \(n \times m\) 名学生,方阵的行数为 \(n\),列数为 \(m\)。
为了便于管理,教官在训练开始时,按照从前到后,从左到右的顺序给方阵中 的学生从 \(1\) 到 \(n \times m\) 编上了号码(参见后面的样例)。即:初始时,第 \(i\) 行第 \(j\) 列 的学生的编号是 \((i-1)\times m + j\)。
然而在练习方阵的时候,经常会有学生因为各种各样的事情需要离队。在一天 中,一共发生了 \(q\) 件这样的离队事件。每一次离队事件可以用数对 \((x,y) (1 \le x \le n, 1 \le y \le m)\) >描述,表示第 \(x\) 行第 \(y\) 列的学生离队。
在有学生离队后,队伍中出现了一个空位。为了队伍的整齐,教官会依次下达 这样的两条指令:
- 向左看齐。这时第一列保持不动,所有学生向左填补空缺。不难发现在这条 指令之后,空位在第 \(x\) 行第 \(m\) 列。
- 向前看齐。这时第一行保持不动,所有学生向前填补空缺。不难发现在这条 指令之后,空位在第 \(n\) 行第 \(m\) 列。
教官规定不能有两个或更多学生同时离队。即在前一个离队的学生归队之后, 下一个学生才能离队。因此在每一个离队的学生要归队时,队伍中有且仅有第 \(n\) 行 第 \(m\) 列一个空位,这时这个学生会自然地填补到这个位置。
因为站方阵真的很无聊,所以
Sylvia想要计算每一次离队事件中,离队的同学 的编号是多少。注意:每一个同学的编号不会随着离队事件的发生而改变,在发生离队事件后 方阵中同学的编号可能是乱序的。
输入格式
输入共 \(q+1\) 行。
第一行包含 \(3\) 个用空格分隔的正整数 \(n, m, q\),表示方阵大小是 \(n\) 行 \(m\) 列,一共发 生了 \(q\) 次事件。
接下来 \(q\) 行按照事件发生顺序描述了 \(q\) 件事件。每一行是两个整数 \(x, y\),用一个空 格分隔,表示这个离队事件中离队的学生当时排在第 \(x\) 行第 \(y\) 列。
输出格式
按照事件输入的顺序,每一个事件输出一行一个整数,表示这个离队事件中离队学生的编号。
样例 #1
样例输入 #1
2 2 3 1 1 2 2 1 2样例输出 #1
1 1 4提示
【输入输出样例 \(1\) 说明】
\[\begin{matrix} \begin{bmatrix} 1 & 2 \\ 3 & 4 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} & 2 \\ 3 & 4 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & \\ 3 & 4 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 4 \\ 3 & \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 4 \\ 3 & 1 \\ \end{bmatrix} \\[1em] \begin{bmatrix} 2 & 4 \\ 3 & 1 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 4 \\ 3 & \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 4 \\ 3 & \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 4 \\ 3 & \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 4 \\ 3 & 1 \\ \end{bmatrix}\\[1em] \begin{bmatrix} 2 & 4 \\ 3 & 1 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & \\ 3 & 1 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & \\ 3 & 1 \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 1 \\ 3 & \\ \end{bmatrix} & \Rightarrow & \begin{bmatrix} 2 & 1 \\ 3 & 4 \\ \end{bmatrix} \end{matrix}\]列队的过程如上图所示,每一行描述了一个事件。 在第一个事件中,编号为 \(1\) 的同学离队,这时空位在第一行第一列。接着所有同学 向左标齐,这时编号为 \(2\) 的同学向左移动一步,空位移动到第一行第二列。然后所有同 学向上标齐,这时编号为 \(4\) 的同学向上一步,这时空位移动到第二行第二列。最后编号为 \(1\) 的同学返回填补到空位中。
【数据规模与约定】
测试点编号 \(n\) \(m\) \(q\) 其他约定 \(1\sim 6\) \(\le 10^3\) \(\le 10^3\) \(\le 500\) 无 \(7\sim 10\) \(\le 5\times 10^4\) \(\le 5\times 10^4\) \(\le 500\) 无 \(11\sim 12\) \(=1\) \(\le 10^5\) \(\le 10^5\) 所有事件 \(x=1\) \(13\sim 14\) \(=1\) \(\le 3\times 10^5\) \(\le 3\times 10^5\) 所有事件 \(x=1\) \(15\sim 16\) \(\le 3\times 10^5\) \(\le 3\times 10^5\) \(\le 3\times 10^5\) 所有事件 \(x=1\) \(17\sim 18\) \(\le 10^5\) \(\le 10^5\) \(\le 10^5\) 无 \(19\sim 20\) \(\le 3\times 10^5\) \(\le 3\times 10^5\) \(\le 3\times 10^5\) 无 数据保证每一个事件满足 \(1 \le x \le n,1 \le y \le m\)。
填坑了,2024.7 动态开点线段树熟练运用
除了保险没全开long long导致只拿了 \(55\) 分,基本上是一遍过
线段树上二分是关键!
我们想到模拟 \(n\) 行队列,
但是一个致命的问题摆在我们面前:指令 \(2\) 怎么实现?
我们试着模拟一下过程,如图:
如果有 \((x,y)\) 要离队,
那么他所在行的 \((x , y + 1 \sim n)\) 要补上去(即蓝色部分)

此时队尾(黄色处)出现空缺,那么 \(m\) 列的 \((x + 1 \sim n,m)\) 要顶上去(即红色部分),且这个时候离队归队(绿色部分)了:

我们可以看到,如果把最后一列也单独开一个线段树便可以维护了,
可能还是有些人会一头雾水,在此,我把 每个线段树维护的队列标注出来:
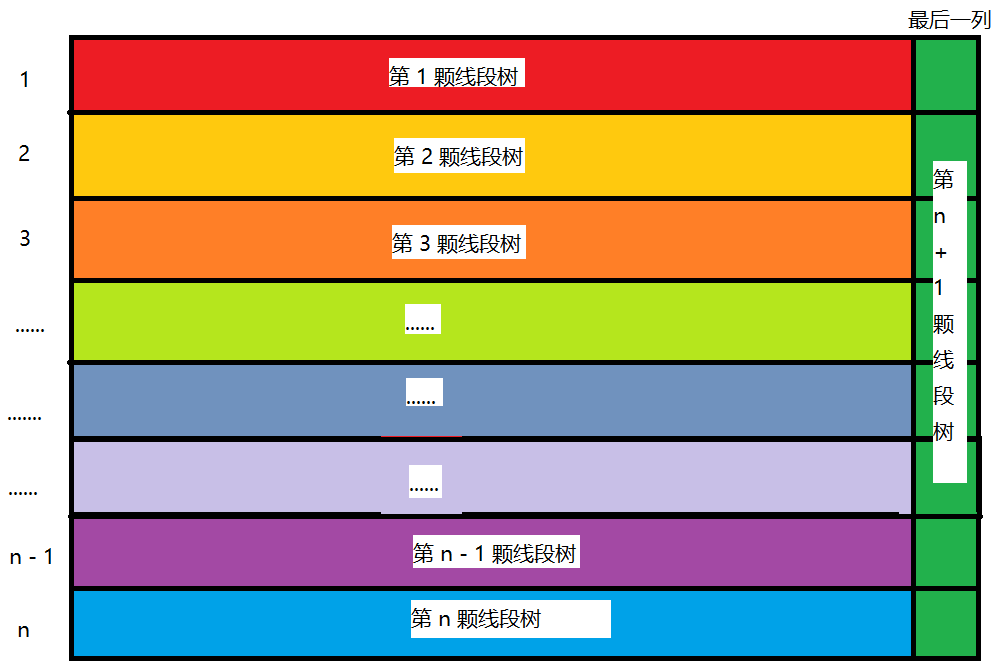
考察操作实现:
以下的“取出”操作表示:“先查询出来后删除”
当 \((x,y)\) 的同学离队时,分讨:
-
如果 \(y = m\),
我们将 第 \(n + 1\) 颗线段树(维护的是最后一列)中的 第 \(x\) 个元素取出(节点大小和元素值设为 \(0\)),
然后,以队列第 \(n\) 个元素添加进 第 \(n + 1\) 颗线段树。 -
如果 \(y < m\)
我们将 第 \(x\) 颗线段树中 第 \(y\) 个元素 取出,
然后执行指令 \(1\),我们将第 \(n + 1\) 颗线段树中 第 \(x\) 个元素 取出,以队列第 \(m - 1\) 个元素(队尾)添加到 \(x\) 颗线段树中
最后执行指令 \(2\),我们将在第一步取出的元素在第 \(n + 1\) 颗线段树上以 \(n\) 个元素(队尾)添加到队列
本题就这样解决了!......吗?
动态开点线段树的细节:
直接 build() 建点完全是痴人说梦!
如果这样建点,一共要建 \(3 \times 10 ^ 5 \times 3 \times 10 ^ 5 = 9 \times 10 ^{10}\) ,空间爆炸!
所以我们大部分点都是虚点(本文指不存在的点)
但是他们在线段树上确确实实占了空间和大小!
所以初始化需要和建点结合!
并且二分的时候,是依靠左右儿子的大小二分的。
所以我们必须在访问之前建出左右儿子,且push_up()
由于询问有 \(q \in 3 \times 10^5\) ,加上原队列长度 \(n/m \in 3 \times 10 ^ 5\),合计 \(6 \times 10^5\),以这个为大小存点。
根据每个线段树的不同,初始化的元素值也需要计算出来!
最后的问题:为什么初始化的时候能直接计算出来元素值呢?
因为没有初始化的节点说明没有修改过,所以里面的元素是可以推出的,
后面来了一些点,这些点在初始化的时候大抵根本不存在这个列队中,但是这些点很快被我们赋予的权值给顶掉了,所以没有任何影响!
当这些都完成的时候,此题就完美 \(AC\) 了!
AC-code:
#include<bits/stdc++.h>
using namespace std;
using ll = long long;
#define int long long
int rd() {
int x = 0, w = 1;
char ch = 0;
while (ch < '0' || ch > '9') {
if (ch == '-') w = -1;
ch = getchar();
}
while (ch >= '0' && ch <= '9') {
x = x * 10 + (ch - '0');
ch = getchar();
}
return x * w;
}
template<class T = ll>
void wt(T x) {
static int sta[35];
int f = 1;
if(x < 0) f = -1,x *= f;
int top = 0;
do {
sta[top++] = x % 10, x /= 10;
} while (x);
if(f == -1) putchar('-');
while (top) putchar(sta[--top] + 48);
}
const int N = 3e5+5,O = 6e5 + 5;
int n,m,q;
int rt[N];
namespace sgt{
int ls[N * 50],rs[N * 50];
int sz[N * 50];
ll val[N * 50],cnt;
#define mid ((pl + pr) >> 1)
void push_up(int p) {sz[p] = sz[ls[p]] + sz[rs[p]];}
void getnode(int &p,int pl,int pr,int o) {
if(!p) {
p = ++cnt;
sz[p] = (pr - pl + 1);
if(pl == pr && o == n + 1) val[p] = pl * m;
else if(pl == pr) val[p] = (o - 1) * m + pl;
}
}
void update(int &p,int pl,int pr,int k,int upd,int o) {
getnode(p,pl,pr,o);
if(pl ^ pr) getnode(ls[p],pl,mid,o);
if(pl ^ pr) getnode(rs[p],mid+1,pr,o);
if(pl ^ pr) push_up(p);
if(pl == pr) {
sz[p] = (upd > 0) ? 1 : 0;
val[p] = (upd > 0) ? upd : 0;
return;
}
if(k <= sz[ls[p]]) update(ls[p],pl,mid,k,upd,o);
else update(rs[p],mid+1,pr,k - sz[ls[p]],upd,o);
push_up(p);
}
int query(int &p,int pl,int pr,int k,int o) {
getnode(p,pl,pr,o);
if(pl ^ pr) getnode(ls[p],pl,mid,o);
if(pl ^ pr) getnode(rs[p],mid+1,pr,o);
if(pl ^ pr) push_up(p);
if(pl == pr) return val[p];
if(k <= sz[ls[p]]) return query(ls[p],pl,mid,k,o);
else return query(rs[p],mid+1,pr,k - sz[ls[p]],o);
}
}
// 1 ~ n 是 第1行到第n行的队列
// n + 1 是 第m列的队列
signed main() {
n = rd(),m = rd(),q = rd();
while(q--) {
int x = rd(),y = rd(),re = 0,tl = 0;
if(y == m) {
re = sgt::query(rt[n + 1],1,O,x,n + 1);
sgt::update(rt[n + 1],1,O,x,0,n + 1);
sgt::update(rt[n + 1],1,O,n,re,n + 1);
wt(re);putchar('\n');
}else {
re = sgt::query(rt[x],1,O,y,x);
sgt::update(rt[x],1,O,y,0,x); // 删除 (x,y) -> line x
tl = sgt::query(rt[n + 1],1,O,x,n + 1);
sgt::update(rt[n + 1],1,O,x,0,n + 1);// 删除 (x,m) -> col m
sgt::update(rt[x],1,O,m-1,tl,x);//添加 (x,m) -> line x
sgt::update(rt[n + 1],1,O,n,re,n + 1);//添加 (x,y) -> col m
wt(re),putchar('\n');
}
}
return 0;
}
八月结束力!团长救一下啊!
