MaxCompute的odps cmd、odps tunnel使用
配置文件odps_config.ini需要修改的内容
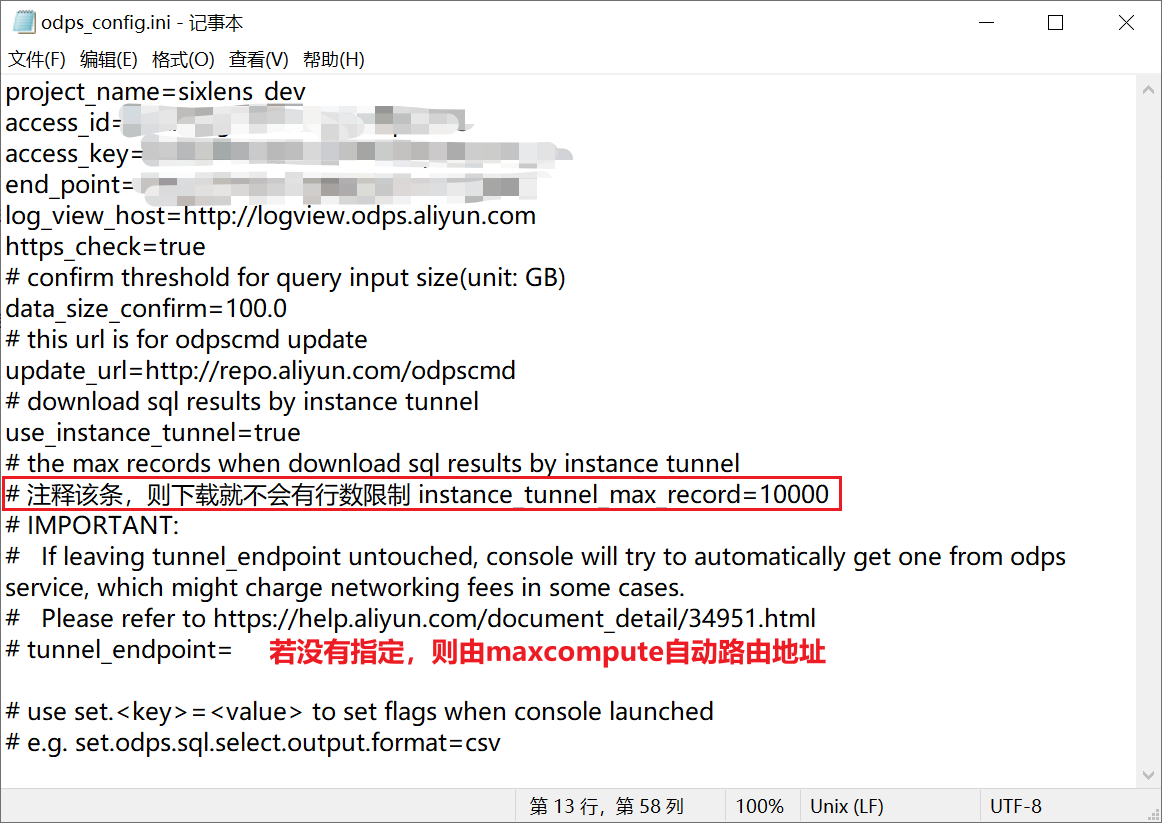
下载download的参考
sixlens_dev>tunnel download -cf true [-threads ?] sixlens_dev.tmp_cwy_dwd_jss_industry_fc_nv D:\download\tmp_cwy_dwd_jss_industry_fc_nv.csv; 会拆分成多个文件对应多个线程 sixlens_dev>tunnel download instance://<[project_name/]test_instance> <path> sixlens_dev>tunnel download -h true -cf true instance://sixlens_dev/20220329031048178gumx85t32 C:\Users\HR\Desktop\weekReport\工作日周三.csv;
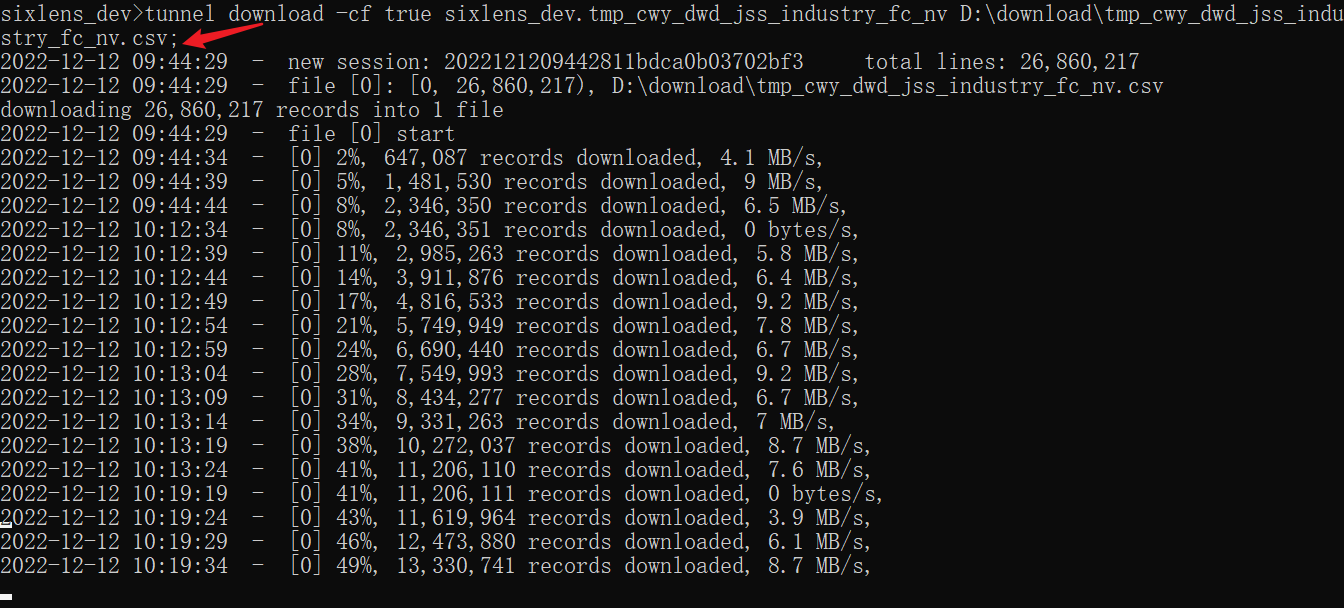
Tunnel
Tunnel通常用来将本地的数据上传到maxcompute或将maxcompute数据下载到本地
1、MaxCompute数据的上传和下载
MaxCompute系统上传/下载数据包括两种方式
DataHub实时数据通道 Tunnel批量数据通道
OGG插件 大数据开发套件
Flume插件 DTS
LogStash插件 Sqoop
Fluentd插件 Kettle插件
MaxCompute客户端Tunnel查看帮助信息
不带参数的tunnel或tunnel help查看帮助信息
也可tunnel help upload
Available subcommands:
upload
支持文件或目录(只一级目录)的上传;
每一次上传只支持数据上传到一个表或表的一个分区;
有分区的表一定要指定上传的分区,示例如下:
tunnel upload d:testp1.txt yunxiang_01.t_test_p/gender='male'
tunnel upload d:test yunxiang_01.t_test_p/gender='male' --scan=only
注释:yunxiang_01为项目; t_test_p为表;gender='male'为分区类;--scan=only表示只扫码数据不导入数据。
download
只支持下载到单个文件
每一次下载只支持一个表或者一个分区
有分区的表一定要指定下载的分区
例子:
tunnel download yunxiang_01.t_test_p/gender='male' d:testp_download.txt
resume
因为网络原因或者tunnel服务的原因造成的错误,使用该子命令续传;目前仅支持上传数据续传;
用法:tunnel resume [session_id]
show
显示历史任务
用法:tunnel show history [options]
purge
清除历史任务
用法:tunnel purge [n]
help
2、常用参数和Tunnel命令
-c: 数据文件字符编码,默认为UTF-8,也可以自行指定,如下:
tunnel upload log.txt test_table -c "gbk"
-ni: NULL数据标志符,默认为""(空字符串),也可指定如下:
tunnel upload log.txt test_table -ni "NULL"
-fd: 本地数据文件的列分割符,默认为逗号;
-rd: 本地数据文件的行分割符,默认为rn.
1、支持多个字符的列分隔符和行分隔符
2、支持控制字符等不可见字符做分隔符
3、列分隔符不能包含行分割符
4、转义字符分隔符,在命令行模式下只支持r,n和t
分隔符示例:
tunnel upload d:p.txt t_test_p/gender='male' -fd "||" -rd "rn"
tunnel download t_test_p/gender='male' d:p_download.txt -fd "||||" -rd "&&"
错误语句如下:
tunnel upload d:p.txt t_test_p/gender='male' -fd "b" -rd "t"
-dfp: DateTime类型数据格式,默认为yyyy-MM-dd HH:mm:ss如下
tunnel upload log.txt test_table -dfp "yyyy-MM-dd HH:mm:ss"
常见日期格式:
"yyyyMMddHHmmss": 数据格式"20140209101000"
"yyyy-MM-dd HH:mm:ss"(默认):数据格式"2014-02-09 10:10:00"
"yyyy年MM月dd日":数据格式"2014年09月01日"
-sd:设置session目录,通过session id可以对上传、下载数据进行监控、续传(resume命令)等操作。执行过程由于数据问题,提示失败会给出session id及错误信息。
例子:
tunnel u d:data.txt sale_detail/sale_date=201312,region=hangzhou -s false
根据session id进行断点续传:
tunnel resume 201506101639224880870a002ec60c --force;
-te: 指定tunnel的Endpoint;
-threads:指定threads的数量,默认为1;
-tz:指定时区。默认为本地时区:Asia/Shanghai,说明Datetime类型默认支持时区为GMT+8
-acp: 如果目标表分区不存在,自动创建目标分区,默认关闭;
-bs: 每次上传至Tunnel的数据块大小,默认值: 100MiB(MiB=1024*1024B)
-cp: 指定是否在本地压缩后再上传,减少网络流量,默认开启;
-dbr: 是否忽略脏数据(多列,少列,列数据类型不匹配等情况):
当值为true时,将全部不符合表定义的数据忽略
当值为false时,若遇到脏数据,则给出错误提示信息,即目标表内的原始数据不会被污染-s: 是否扫描本地数据文件,默认为false,具体如下:
值为true时,先扫描数据,若数据格式正确,再导入数据。
值为false时,不扫描数据,直接进行数据导入。
值为only时,仅进行扫描本地数据,扫描结束后不继续导入数据其他下载参数:
-ci: 指定列索引(从0)下载,使用逗号分隔;
-cn: 指定要下载的列名称,使用逗号分隔每个名称;
-cp: 指定是否压缩,减少网络流量,默认开启;
-e:当下载double值时,如果需要,使用指数函数表示,否则最多保留20位;
-h: 数据文件是否包含表头,如果为true,则dship会跳过表头从第二行开始下载数据。注意,-h=true和threads>1即多线程不能一起使用
-limit: 指定要下载的文件数量
tunnel的一些特点:
tunnel命令是对tunnel模块的SDK封装,具有tunnel的一些特点:
支持对表的读写,不支持视图;
写表是追加(Append)模式
采用并发以提高整体吞吐量
避免频繁提交3、Tunnel SDK相关知识
Tunnel SDK中的几个概念:
基本含义:
session 完成对一张表或partition上传下载的的过程,称为一个session
request 在一个session内,请求一次tunnel RESTful API的过程
writer 当request为上传数据时,需要打开一个writer,将数据序列化的写入odps后台cfile文件:
Block 当并发上传数据时,blockID就是不同的writer的标识,其对应后台的一个cfile。相互关系:
session由一到多个request完成
同一个upload session中,用户可以同时打开多个cfile文件中的writer,多线程或多进程的并发上传数据
由于每一个block对应后台一个cfile文件,所以同一个session,两次打开同一个block就会导致覆盖行为,即只保留最后一次close writer对应的数据。主要接口:
tabletunnel:访问tunnel服务的入口类,用来对maxcompute和tunnel进行访问
uploadsession:上传会话,包括会话的各种属性、动作以及通过会话进行写操作的方法
downloadsession:下载会话,包括会话的各种属性、动作以及通过会话进行读操作的方法TableTunnel接口定义:
生命周期:从TableTunnel实例被创建开始,一直到程序结束。
提供方法:创建Upload对象和Download对象的方法
createDownloadSession:创建下载会话对象
createUploadSession:创建上传会话对象
getDownloadSession:获取下载对话对象句柄
getUploadSession:获取上传会话对象句柄
注:无论表有无分区,均有两个方法对应
setEndpoint:设置服务接入点UploadSession接口定义:
commit:上传会话完成、提交
getBlocklist:得到成功上传的Block的列表
getID:得到上传会话的ID
getSchema:得到上传表的schema
getStatus:得到上传状态
newRecord:创建Record类型的记录
openRecordWriter:打开记录写入器Java+eclipse环境配置
Step01:官网导航中找到并下载odps-sdk-core
Step02:下载eclipse并安装、配置
Step03:在eclipse中新建Java Project
Step04:将1中下载的压缩包中的jar包添加到项目的路径中。简单上传实例:
处理流程:
创建阿里云账号->创建表通道->创建上传会话->读取文件->写入记录->上传会话提交
需要处理:
1、提供输入参数,通过run configuration的arguments,添加到program arguments里。
-f <source_file> -c <config_file> -t <odps table> -p <partition_spec> -fd <field_delimiter>
2、建表,增加分区
在maxcompute中建表,创建相应分区
3、上传完成后,检查表中的结果。简单下载实例
处理流程:
创建阿里云账号->创建表通道->创建下载会话->读取记录->写入文件
需要处理:
1、提供输入参数,通过run configuration中的arguments,添加到program arguments里:
-f <target_file> -c <config_file> -t <odps_table> -p <partition_spec> -fd <field_delimiter>
2、下载完成后,找到对应文件,检查文件内容是否正确多线程上传实例
处理流程:
提供配置信息-创建阿里云账号-创建表通道-创建上传会话-创建线程池-将待插入记录分给不同线程写入-关闭线程池-将每个线程写入的块提交
需要我们做的:
1、将配置参数写入java脚步(参照odps的配置文件)
2、建表,增加分区
3、上传完成后检查表中的结果多线程下载实例
处理流程:
提供配置信息-创建阿里云账号-创建表通道-创建下载会话-创建线程池-分配待下载记录给不同的线程-执行下载任务-关闭线程池
需要我们做的:
1、将配置参数写入java脚本(参照odps的配置文件)
2、建表,增加分区
3、下载完成后,输入到屏幕的结果常见问题:
1、一个session的超时时间:24小时
2、writer close时,将相对应的cfile文件从tmp目录挪移到data目录
3、session commit时,tunnel server将相应session data目录下的所有cfile文件挪移到相应表所在目录,即数据进表中,可以通过SQL进行读取
4、同一个session中,有一个block id对应的block上传失败,需要重传shi,使用相同的blockid
5、对于tunnel server,一个session对应一个目录。所以不同的session会产生不同的目录。这就是不同的session上传数据互不影响的原因
6、对同一个表上传数据,只有一台机器时,基本使用多线程并发就可以了,当需要更多带宽来支持上传数据时,使用不同机器不同进程上传(需要做数据切分)
7、在带宽最大能达到100M/s时,16-64个线程并发,太多的并发将消耗更多的CPU切换。
4、【ODPS】TableTunnel单线程简单下载事例
ODPS Tunnel是ODPS的数据通道,用户可以通过Tunnel向ODPS中上传或者下载数据。目前Tunnel仅支持表(不包括视图View)数据的上传下载。
|
主要接口 |
描述 |
| TableTunnel | 访问ODPS Tunnel服务的入口类。用户可以通过公网或者阿里云内网环境对ODPS 及其Tunnel进行访问。当用户在阿里云内网环境中,使用Tunnel内网连接下载数据时,ODPS不会将该操作产生的流量计入计费。此外内网地址仅对杭州域的云产品有效。 |
| TableTunnel.UploadSession | 表示一个向ODPS表中上传数据的会话。 |
|
TableTunnel.DownloadSession |
表示一个向ODPS表中下载数据的会话。 |
接口定义:
public class DownloadSession { DownloadSession(Configuration conf, String projectName, String tableName, String partitionSpec) throws TunnelException DownloadSession( Configuration conf, String projectName, String tableName, String partitionSpec, String downloadId) throws TunnelException public String getId() public long getRecordCount() public TableSchema getSchema() public DownloadSession.Status getStatus() public RecordReader openRecordReader(long start, long count) public RecordReader openRecordReader(long start, long count, boolean compress) }
Download对象:
- 生命周期:从创建Download实例到下载结束
- 创建Download实例,可以通过调用构造方法创建,也可以通过TableTunnel创建;
- 请求方式:同步
- Server端会为该Download创建一个session,生成唯一downloadId标识该Download,客户端可以通过getId获取
- 该操作开销较大,server端会对数据文件创建索引,当文件数很多时,该时间会比较长;
- 同时server端会返回总Record数,可以根据总Record数启动多个并发同时下载
- 下载数据:
- 请求方式:异步
- 调用openRecordReader方法,生成RecordReader实例,其中参数start标识本次下载的record的起始位置,从0开始,取值范围是 >= 0, count标识本次下载的记录数,取值范围是>0。
- 查看下载:
- 请求方式:同步
- 调用getStatus可以获取当前Download状态
- 4种状态说明:
- UNKNOWN, server端刚创建一个session时设置的初始值
- NORMAL, 创建Download对象成功
- CLOSED, 下载结束后
- EXPIRED, 下载超时
说明:分区表下载必须指定分区
单线程下载参考代码
import java.io.BufferedWriter; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; import java.util.Date; import com.aliyun.odps.Column; import com.aliyun.odps.Odps; import com.aliyun.odps.PartitionSpec; import com.aliyun.odps.TableSchema; import com.aliyun.odps.account.Account; import com.aliyun.odps.account.AliyunAccount; import com.aliyun.odps.data.Record; import com.aliyun.odps.data.RecordReader; import com.aliyun.odps.tunnel.TableTunnel; import com.aliyun.odps.tunnel.TunnelException; /** * @program: * @author: cwy * @description: tunnel单线程下载模板类 * @createTime: 2022-12-06 * @version: 1.0 */ public class SingleDownloadSample { private static final String ACCESS_ID = "<your access id>"; private static final String ACCESS_KEY = "<your access Key>"; private static final String PROJECT_NAME = "<your project>"; private static final String TUNNEL_URL = "<your tunnel endpoint>"; private static final String ODPS_URL = "<your odps endpoint>"; public static void main(String args[]) throws Exception {
// 多表下载String[] tablesName = {"xxx", "xxx", ...}; String tableName = "point_z"; // 表名 /* 先构建阿里云帐号 */ Account account = new AliyunAccount(ACCESS_ID, ACCESS_KEY); /* Odps类是ODPS SDK的入口 */ Odps odps = new Odps(account); odps.setDefaultProject(PROJECT_NAME); // 指定默认使用的Project名称 odps.setEndpoint(ODPS_URL); // 设置ODPS服务的地址 /*訪问ODPS Tunnel服务的入口类*/ TableTunnel tunnel = new TableTunnel(odps); tunnel.setEndpoint(TUNNEL_URL); // 设置TunnelServer地址 // 多表下载 for(String tableName : tablesName) {将try代码块包括起来即可} try { /*此处表point_z为分区表。下载时必须指定分区 * 指定下载分区 * */ PartitionSpec partitionSpec = new PartitionSpec(); partitionSpec.set("z", "1"); System.out.println("开始单线程下载mc中表" + tableName + "数据........."); File file = new File("D:\\mc-download\\" + tableName + ".csv"); // 亦可设置为txt格式 if (file.exists()) { file.delete(); } file.createNewFile(); long startTime = System.currentTimeMillis(); /* 在分区表上创建下载会话(分区表必须指定分区,非分区表不用) */ TableTunnel.DownloadSession downloadSession = tunnel .createDownloadSession(PROJECT_NAME, tableName, partitionSpec); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); RecordReader recordReader = downloadSession.openRecordReader(0, count); Record record; while ((record = recordReader.read()) != null) { consumeRecord(record, downloadSession.getSchema(), file); } recordReader.close(); long endTime = System.currentTimeMillis(); System.out.println("总共耗时:" + (endTime - startTime) / 1000 + " s"); System.out.println("-------------------------------------------------"); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e1) { e1.printStackTrace(); } } private static void consumeRecord(Record record, TableSchema schema, File file) throws IOException { BufferedWriter out = new BufferedWriter(new OutputStreamWriter( new FileOutputStream(file, true), "utf-8")); String writeStr = ""; String str = null; for (int i = 0; i < schema.getColumns().size(); i++) { Column column = schema.getColumn(i); String colValue = null; switch (column.getType()) { case BIGINT: { Long v = record.getBigint(i); colValue = v == null ? null : v.toString(); break; } case BOOLEAN: { Boolean v = record.getBoolean(i); colValue = v == null ? null : v.toString(); break; } case DATETIME: { Date v = record.getDatetime(i); colValue = v == null ? null : v.toString(); break; } case DOUBLE: { Double v = record.getDouble(i); colValue = v == null ? null : v.toString(); break; } case STRING: { String v = record.getString(i); colValue = v == null ? null : v.toString(); break; } default: throw new RuntimeException("Unknown column type: " + column.getType()); } str = colValue == null ? "null" : colValue; if (i != schema.getColumns().size() - 1) { // str = schema.getColumn(i).getName() + ":" + str + ", "; str = str + ","; } else { // str = schema.getColumn(i).getName() + ":" + str; str = str; } writeStr = writeStr + str; } str = str + System.getProperty("line.separator"); writeStr = writeStr + System.getProperty("line.separator"); out.write(writeStr); out.close(); } }
多线程下载代码
import java.io.BufferedWriter; import java.io.File; import java.io.FileOutputStream; import java.io.IOException; import java.io.OutputStreamWriter; import java.util.ArrayList; import java.util.List; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; import com.aliyun.odps.Odps; import com.aliyun.odps.PartitionSpec; import com.aliyun.odps.account.Account; import com.aliyun.odps.account.AliyunAccount; import com.aliyun.odps.data.RecordReader; import com.aliyun.odps.tunnel.TableTunnel; import com.aliyun.odps.tunnel.TunnelException; import java.util.Date; import com.aliyun.odps.Column; import com.aliyun.odps.TableSchema; import com.aliyun.odps.data.Record; /** * @program: * @author: cwy * @description: tunnel多线程下载模板类 * @createTime: 2022-12-12 * @version: 1.0 */ public class MultipleDownloadSample { private static final String ACCESS_ID = "<your access id>"; private static final String ACCESS_KEY = "<your access Key>"; private static final String PROJECT_NAME = "<your project>"; private static final String TUNNEL_URL = "<your tunnel endpoint>"; private static final String ODPS_URL = "<your odps endpoint>"; public static void main(String[] args) {
// 多表下载 String[] tablesName = {"", "", ...}; 分区表考虑使用map String tableName = "point_z";//表名 /* 先构建阿里云帐号 */ Account account = new AliyunAccount(ACCESS_ID, ACCESS_KEY); /* Odps类是ODPS SDK的入口 */ Odps odps = new Odps(account); odps.setDefaultProject(PROJECT_NAME); // 指定默认使用的Project名称 odps.setEndpoint(ODPS_URL); // 设置ODPS服务的地址 /* 访问ODPS Tunnel服务的入口类 */ TableTunnel tunnel = new TableTunnel(odps); tunnel.setEndpoint(TUNNEL_URL); // 设置TunnelServer地址
// 多表下载 for(String tableName:tablesName) {将try代码块包括起来即可} try { /* 此处表point_z为分区表,下载时必须指定分区,指定下载分区 */ PartitionSpec partitionSpec = new PartitionSpec(); partitionSpec.set("z", "1"); System.out.println("开始多线程下载mc中表" + tableName + "数据........."); File file = new File("D:\\mc-download\\" + tableName + ".csv"); // 亦可设置为txt格式 if (file.exists()) { file.delete(); } file.createNewFile(); BufferedWriter out = new BufferedWriter(new OutputStreamWriter( new FileOutputStream(file, true), "utf-8")); long startTime = System.currentTimeMillis(); TableTunnel.DownloadSession downloadSession = tunnel .createDownloadSession(PROJECT_NAME, tableName, partitionSpec); long count = downloadSession.getRecordCount(); System.out.println("RecordCount is: " + count); int threadNum = 6; ExecutorService pool = Executors.newFixedThreadPool(threadNum); ArrayList<Callable<Long>> callers = new ArrayList<Callable<Long>>(); long step = count / threadNum; for (int i = 0; i < threadNum - 1; i++) { RecordReader recordReader = downloadSession.openRecordReader( step * i, step); callers.add(new DownloadThread(i, recordReader, downloadSession .getSchema(), out)); } RecordReader recordReader = downloadSession.openRecordReader(step * (threadNum - 1), count - ((threadNum - 1) * step)); callers.add(new DownloadThread(threadNum - 1, recordReader, downloadSession.getSchema(), out)); Long downloadNum = 0L; List<Future<Long>> recordNum = pool.invokeAll(callers); for (Future<Long> num : recordNum) downloadNum += num.get(); System.out.println("DownLoad Count is: " + downloadNum); pool.shutdown(); out.close(); long endTime = System.currentTimeMillis(); System.out.println("总共耗时:" + (endTime - startTime) / 1000 + " s"); System.out.println("-------------------------------------------------"); } catch (TunnelException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } catch (InterruptedException e) { e.printStackTrace(); } catch (ExecutionException e) { e.printStackTrace(); } } } class DownloadThread implements Callable<Long> { private long id; private RecordReader recordReader; private TableSchema tableSchema; private BufferedWriter out; public DownloadThread(int id, RecordReader recordReader, TableSchema tableSchema, BufferedWriter out) { this.id = id; this.recordReader = recordReader; this.tableSchema = tableSchema; this.out = out; } @Override public Long call() throws Exception { Long recordNum = 0L; try { Record record; while ((record = recordReader.read()) != null) { recordNum++; consumeRecord(record, tableSchema, out, id); } recordReader.close(); } catch (IOException e) { e.printStackTrace(); } return recordNum; } private static void consumeRecord(Record record, TableSchema schema, BufferedWriter out, long id) throws IOException { String writeStr = ""; String str; for (int i = 0; i < schema.getColumns().size(); i++) { Column column = schema.getColumn(i); String colValue = null; switch (column.getType()) { case BIGINT: { Long v = record.getBigint(i); colValue = v == null ? null : v.toString(); break; } case BOOLEAN: { Boolean v = record.getBoolean(i); colValue = v == null ? null : v.toString(); break; } case DATETIME: { Date v = record.getDatetime(i); colValue = v == null ? null : v.toString(); break; } case DOUBLE: { Double v = record.getDouble(i); colValue = v == null ? null : v.toString(); break; } case STRING: { String v = record.getString(i); colValue = v == null ? null : v.toString(); break; } default: throw new RuntimeException("Unknown column type: " + column.getType()); } str = colValue == null ? "null" : colValue; if (i != schema.getColumns().size() - 1) { // str = schema.getColumn(i).getName() + ":" + str + ", "; str = str + ","; } else { // str = schema.getColumn(i).getName() + ":" + str; str = str; } writeStr = writeStr + str; } // writeStr = "【Thread " + id + "】" + writeStr + System.getProperty("line.separator"); writeStr = writeStr + System.getProperty("line.separator"); out.write(writeStr); } }
