
模拟登录
登录博客
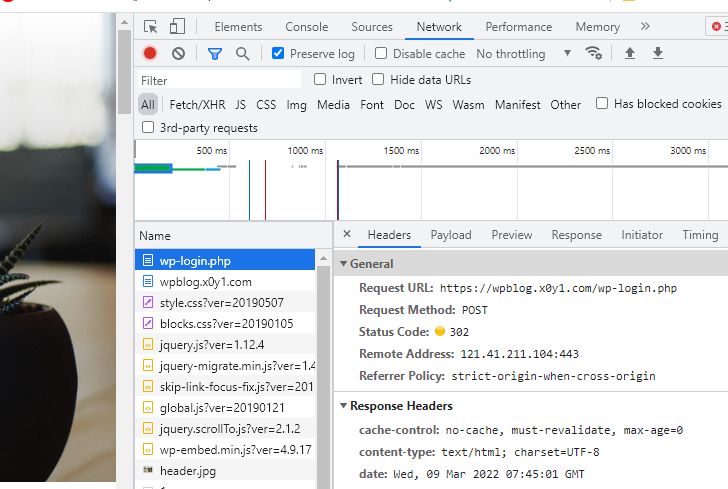
POST 请求
和 GET 一样,POST 也是请求方式的一种。除此之外还有 PUT、DELETE 等方式,但最常用的还是 GET 和 POST。
那么它俩的区别是什么呢?下面我给你从本质和形式上进行对比:
GET 和 POST 本质上的区别是:
- GET 用于获取数据,比如刷微博;
- POST 用于提交数据,比如登录微博。
GET 和 POST 形式上的区别是:
- GET 的参数显示在请求地址里;
- POST 的参数隐藏在 Form Data 里。
cookie
简单地说,cookie 是浏览器储存在用户电脑上的一小段文本文件。该文件里存了加密后的用户信息,过期时间等,且每次请求都会带上 cookie。所以,你登录过某网站后,下次再次打开该网站便不再需要登录。
因为 cookie 有过期时间,因此一段时间之后,cookie 便会失效,需要你再次重新登录,生成新的 cookie。cookie 就像一张通行证,当没有或通行证过期了,就无法通过,需要重新办理通行证才行。
抓取文章
登录成功后,我们用 Python 做一些只有登录后才能进行的操作,来验证我们登录真的成功了。博客中的文章内容需要登录后才能查看并抓取,我们可以用它试一试。


import requests from bs4 import BeautifulSoup headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' } # 登录参数 login_data = { 'log': 'codetime', 'pwd': 'shanbay520', 'wp-submit': '登录', 'redirect_to': 'https://wpblog.x0y1.com', 'testcookie': '1' } login_req = requests.post('https://wpblog.x0y1.com/wp-login.php', data=login_data, headers=headers) shared_cookies = login_req.cookies # 将登录后的 cookies 传递给 cookies 参数用于获取文章页面内容 res = requests.get('https://wpblog.x0y1.com/?cat=2', cookies=shared_cookies, headers=headers) # 解析页面 soup = BeautifulSoup(res.text, 'html.parser') # 选择所有的代表标题的 a 标签 titles = soup.select('h2.entry-title a') # 先打印结果看看 for i in titles: print(i)
对于每个 a 标签,我们都需要取出其 href 属性中的链接。BeautifulSoup 解析结果中,每个标签都可以通过 标签.attrs 的方式,将标签属性以字典的格式返回,我们以第一个 a 标签 为例:
# 省略上面获取所有标题 a 标签的代码 # 获取第一个标签 title = titles[0] # 打印标签文本 print(title.text) # 打印标签属性 print(title.attrs) ''' 输出: 2006年~2019年中国国内生产总值 (GDP) 统计 {'href': 'https://wpblog.x0y1.com/?p=199', 'rel': ['bookmark']} '''
我们可以借助列表生成式,将所有 titles 中所以标题链接放进一个列表中。
.....省略登录代码 # 将登录后的 cookies 传递给 cookies 参数用于获取文章页面内容 res = requests.get('https://wpblog.x0y1.com/?cat=2', cookies=shared_cookies, headers=headers) # 解析页面 soup = BeautifulSoup(res.text, 'html.parser') # 选择所有的代表标题的 a 标签 titles = soup.select('h2.entry-title a') links = [i.attrs['href'] for i in titles] print(links) ''' 输出: ['https://wpblog.x0y1.com/?p=199', 'https://wpblog.x0y1.com/?p=43', 'https://wpblog.x0y1.com/?p=34', 'https://wpblog.x0y1.com/?p=8'] '''
session
因为 HTTP 是无状态的,在一次请求、响应结束过后,连接就断开了。再次发起请求时,之前的状态全都丢失了,服务器也不再“认识你”。
有了 cookie 之后,我们可以将一些信息存到其中,比如用户身份信息等。但因为 cookie 容量有限,只有 4KB。因此,不可能将所有的用户信息都存到里面。这时候,session 就出现了。
session 相当于在服务器上建立的一份用户档案,cookie 中只要存储用户的身份信息,服务器通过身份信息在 session 中查询用户的其他信息。这样一来,我们的所有操作都会被保留。比如我们添加到购物车的商品,重新打开页面后仍会被保留。
这么好用的东西,requests 库当然也支持。
我们可以通过 requests.Session() 创建一个 session,注意 S 要大写。然后我们就可以像使用 requests 一样使用 session 对象了,get()、post() 等方法统统都有,只需将原先的 requests 替换成我们创建的 session 即可。
有了 session,多个请求之间就可以共享 cookie 了,后续请求便不再需要传 cookies 参数。
除了 cookies 参数每次都要传很麻烦,headers 参数每次都要传也很麻烦。如果想要共享 headers 的话,可以像下面这样写:
import requests session = requests.Session() headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' } # 设置 session 的全局 headers session.headers.update(headers) # 默认使用全局的 headers session.get('https://wpblog.x0y1.com') # 自定义 headers custom_headers = { 'referer': 'https://wpblog.x0y1.com' } session.get('https://wpblog.x0y1.com', headers=custom_headers) # 既有全局的 user-agent 也有自定义的 referer
使用Session后更为简洁的代码:
import requests from bs4 import BeautifulSoup headers = { 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36' } # 登录参数 login_data = { 'log': 'codetime', 'pwd': 'shanbay520', 'wp-submit': '登录', 'redirect_to': 'https://wpblog.x0y1.com', 'testcookie': '1' } session = requests.Session() session.headers.update(headers) # 使用 session 登录 login_req = session.post('https://wpblog.x0y1.com/wp-login.php', data=login_data) # 使用 session 获得 Python 分类文章 comment_req = session.get('https://wpblog.x0y1.com/?cat=2') # 解析页面 soup = BeautifulSoup(comment_req.text, 'html.parser') # 选择所有的代表标题的 a 标签 titles = soup.select('h2.entry-title a') # 获取四篇文章的链接 links = [i.attrs['href'] for i in titles] for link in links: # 获取文章页面内容 res_psg = session.get(link) # 解析文章页面 soup_psg = BeautifulSoup(res_psg.text, 'html.parser') # 获取文章内容的标签 content = soup_psg.select('div.entry-content')[0] # 打印文章内容 print(content.text)

