
Hadoop组件
---------Hive--------------------------zooKeeper-------------------------------kafka-----------------------------------sqoop-------------------------------flume-------------------------------------------------------------------------------------Hbase-----------------------------------------------------------------------
Your present circumstances don't determine where you can go; they merely determine where you start.
Hive
https://hive.apache.org/
Hive:由Facebook开源用于解决海量结构化日志的数据统计。 Version :apache-hive-1.2.2-bin
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
本质:将HQL转化成Map Reduce程序
=========Hive处理的数据储存在HDFS
Hive分析数据底层的实现是Map Reduce
执行程序运行在YARN上
Zookeeper
https://zookeeper.apache.org/
Zookeeper:是一个开源的分布式的,为分布式应用提供协调服务的Apache项目。版本:zookeeper-3.4.10
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经
在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式
ZooKeeper = 文件系统 + 通知机制
提供的服务:分布式消息同步和协调机制、
服务器节点动态上下线、
统一配置管理、
负载均衡、
集群管理等。
每个znode默认能够存储1MB的数据,znode是其路径的唯一标识
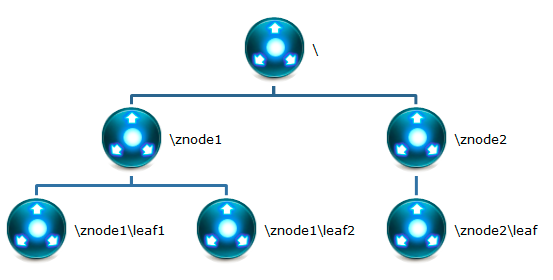
节点类型:
ephemeral(短暂):客户端和服务器断开连接后,创建的节点自己删除
persistent(持久):客户端和服务器断开连接后,创建的表还在
特点
ZooKeeper是一个leader,多个follower组成的集群
集群中只要半数以上的节点存活,zooKeeper集群就能正常服务
全局数据一致:每个服务端保存一份相同的数据副本,客户端 无论连接到哪个server,数据都是一致的
数据更新原子性,一次数据更新要么成功,要么失败
实时性,在一定时间范围内,client能读到最新数据。
Kafka
https://kafka.apache.org/
在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算。
1)Apache Kafka是一个开源消息系统,由Scala写成。是由Apache软件基金会开发的一个开源消息系统项目。
2)Kafka最初是由LinkedIn公司开发,并于2011年初开源。2012年10月从Apache Incubator毕业。该项目的目标是为处理实时数据提供一个统一、高通量、低等待的平台。
3)Kafka是一个分布式消息队列。Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。
4)无论是kafka集群,还是producer和consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
kafka的特性:
高吞吐量,低延迟:kafka每秒可以处理几十万条消息,它的延迟最低时只有几毫秒。每个 topic 可以分多个partition,
consumer group对 partition 进行consume操作。
可扩展性:Kafka集群支持热扩展
持久性,可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
容错性:允许集群中节点失败(若副本数为 3 ,则允许 2个节点毁坏)
高并发:支持数千个客户端同时读写
1.2 消息队列内部实现原理
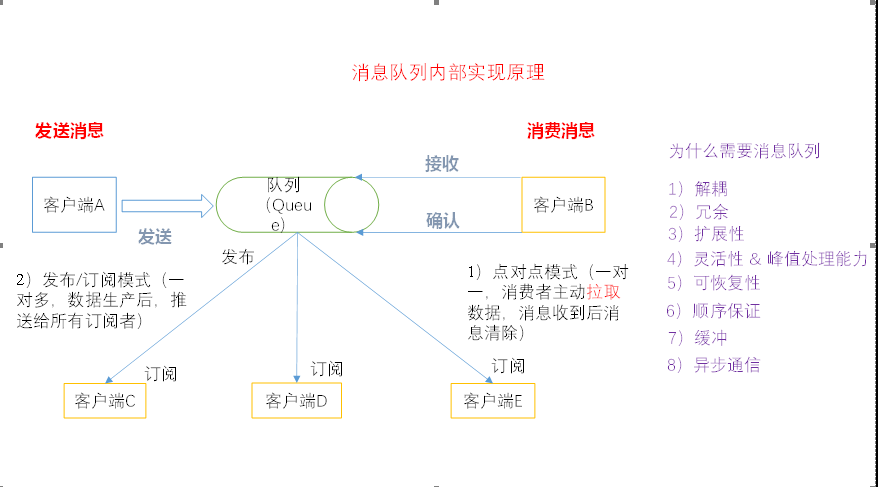
1):点对点模式式(一对一,消费者主动拉取数据,消息收到后消息清除)
点对点模型通常是一个基于拉取或者轮询的消息传送模型,
这种模型从队列中请求信息,而不是将消息推送到客户端。这个模型的特点是发送到队列的消息被一个且只有一个接受者接受处理,即使有多个监听者也是如此。
2):
发布/订阅模式(一对多,数据生产后,推送给所有订阅者)
发布订阅模型则是一个基于推送的消息传送模型。发布订阅模型可以有多种不同的订阅者,临时订阅者只在主动监听主题时才接收消息,而持久订阅者则监听主题的所有消息,即使当前订阅者不可用,处于离线状态。
1.3 为什么需要消息队列
1)解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2)冗余:
消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
3)扩展性:
因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。
4)灵活性 & 峰值处理能力:
在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5)可恢复性:
系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
6)顺序保证:
在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka保证一个Partition内的消息的有序性)
7)缓冲:
有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
8)异步通信:
很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
SQOOP
https://sqoop.apache.org/
一、什么是Sqoop
Sqoop是一个在结构化数据和Hadoop之间进行批量数据迁移的工具,结构化数据可以是Mysql、Oracle等RDBMS(关系型数据库) 。Sqoop底层用MapReduce程序实现抽取、转换、加载,MapReduce天生的特性保证了并行化和高容错率,而且相比Kettle等传统ETL
【ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过萃取(extract)、转置(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。】
工具,任务跑在Hadoop集群上,减少了ETL服务器资源的使用情况。在特定场景下,抽取过程会有很大的性能提升。
如果要用Sqoop,必须正确安装并配置Hadoop,因依赖于本地的hadoop环境启动MR程序;mysql、oracle等数据库的JDBC
【JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API,可以为多种关系】
驱动也要放到Sqoop的lib目录下。本文针对的是Sqoop1,不涉及到Sqoop2,两者有大区别,感兴趣的读者可以看下官网说明。
Flume
https://flume.apache.org/
一 :简介
二 : 代表角色
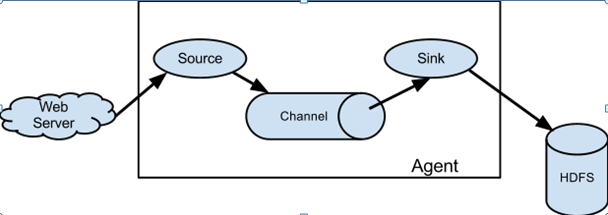
2.1 、Source
用于采集数据,Source 是产生数据流的地方,同时 Source 会将产生的数据流传输到 Channel,这个有点类似于Java IO 部分的 Channel。
2.2 、Channel
用于桥接 Sources 和 Sinks,类似于一个队列。
2.3 、Sink
从Channel 收集数据,将数据写到目标(可以是下一个 Source,也可以是 HDFS 或者 HBase)。
2.4 、Event
传输单元,Flume 数据传输的基本单元,以事件的形式将数据从源头送至目的地。
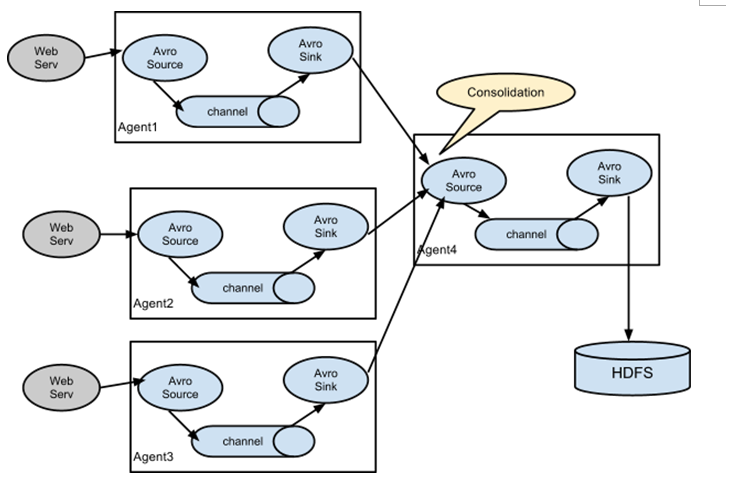
案例:Flume 与 Flume 之间数据传递,多 Flume 汇总数据到单 Flume
Hbase
https://hbase.apache.org/
1.1 、HBase 的角色
1.2.1、Hmaster
功能:
1)监控 RegionServer
2)处理 RegionServer 故障转移
3)处理元数据的变更
4)处理region 的分配或移除
5)在空闲时间进行数据的负载均衡
6)通过 Zookeeper 发布自己的位置给客户端
1.2.2、RegionServer
功能:
1)负责存储 HBase 的实际数据
2)处理分配给它的 Region
3)刷新缓存到 HDFS
4)维护Hlog Write-Ahead Log
5)执行压缩
6)负责处理 Region 分片
HBase 的工作原理

在上面的图中,我们需要注意几个我们之前没有提到的概念:Store、MemStore、StoreFile 以及 HFile。带着这几个新的概念,我们完整的梳理下整个 HBase 的工作流程。
首先我们需要知道 HBase 的集群是通过 Zookeeper 来进行机器之前的协调,也就是说 HBase Master 与 Region Server 之间的关系是依赖 Zookeeper 来维护。当一个 Client 需要访问 HBase 集群时,Client 需要先和 Zookeeper 来通信,然后才会找到对应的 Region Server。每一个 Region Server 管理着很多个 Region。对于 HBase 来说,Region 是 HBase 并行化的基本单元。因此,数据也都存储在 Region 中。这里我们需要特别注意,每一个 Region 都只存储一个 Column Family 的数据,并且是该 CF 中的一段(按 Row 的区间分成多个 Region)。Region 所能存储的数据大小是有上限的,当达到该上限时(Threshold),Region 会进行分裂,数据也会分裂到多个 Region 中,这样便可以提高数据的并行化,以及提高数据的容量。每个 Region 包含着多个 Store 对象。每个 Store 包含一个 MemStore,和一个或多个 HFile。MemStore 便是数据在内存中的实体,并且一般都是有序的。当数据向 Region 写入的时候,会先写入 MemStore。当 MemStore 中的数据需要向底层文件系统倾倒(Dump)时(例如 MemStore 中的数据体积到达 MemStore 配置的最大值),Store 便会创建 StoreFile,而 StoreFile 就是对 HFile 一层封装。所以 MemStore 中的数据会最终写入到 HFile 中,也就是磁盘 IO。由于 HBase 底层依靠 HDFS,因此 HFile 都存储在 HDFS 之中。这便是整个 HBase 工作的原理简述。
