【jupyter-lab】实战经验积累(一)
#数据分析常用python包
#numpy:科学计算工具包
#pandas:数据分析工具包
#malplotlib:图表绘制工具包
#improt语句:加载工具包
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib as mpl
import matplotlib.pyplot as plt
#加上这句话在表格显示中文时才不会出错
plt.rcParams['font.sans-serif']=['SimHei']
%matplotlib inline
#读取当前记载的数据集目录 用pandas包读取数据,使用print(data)验证读取结果 ,engine = 'python'
#data=pd.read_csv('文件路径',encoding='gbk',engine = 'python')
#print(data.head(3))
data=pd.read_csv('D:\\filesserver\\jupyexercise.csv')
#查看前五行的数据
print(data.head(9))
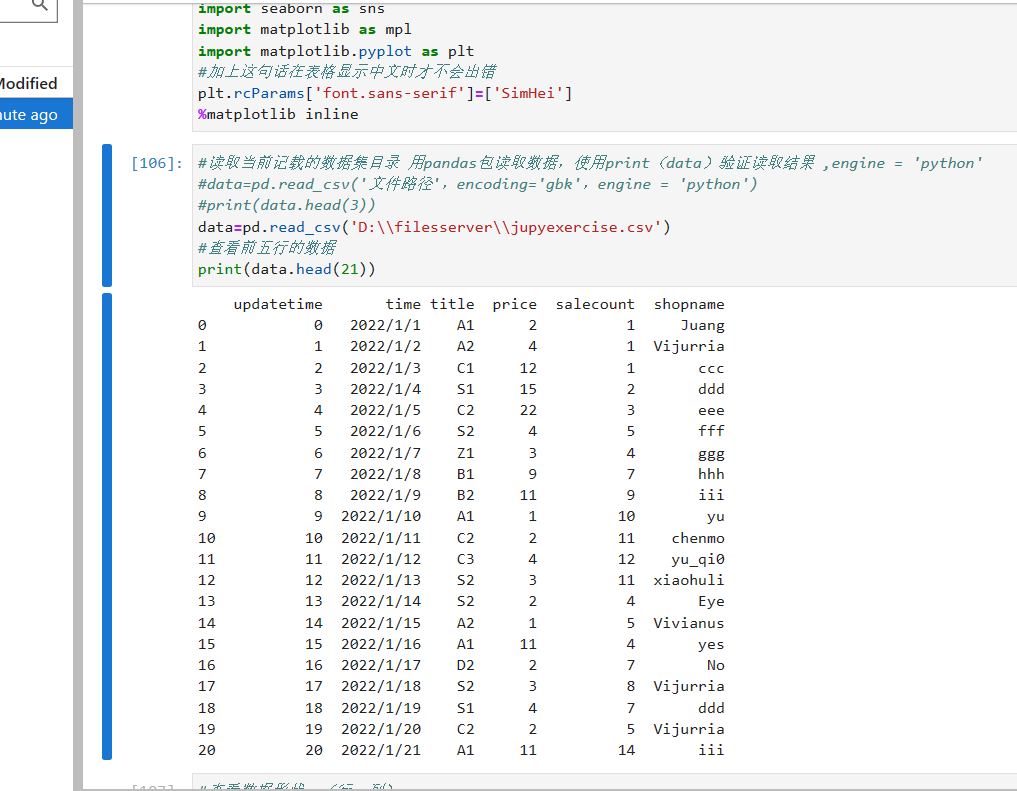
当csv文件中含有中文时,使用encoding='gbk'便可完美解决
#读取当前记载的数据集目录 用pandas包读取数据,使用print(data)验证读取结果 ,engine = 'python'
#data=pd.read_csv('文件路径',encoding='gbk',engine = 'python')
#print(data.head(3))
data=pd.read_csv('D:\\filesserver\\mifen.csv',encoding='gbk')
#查看前五行的数据
print(data.head(9))
#查看数据形状:(行,列)
data.shape
#查看各字段信息
data.info()
#查看店名的数量
data.shopname.value_counts()
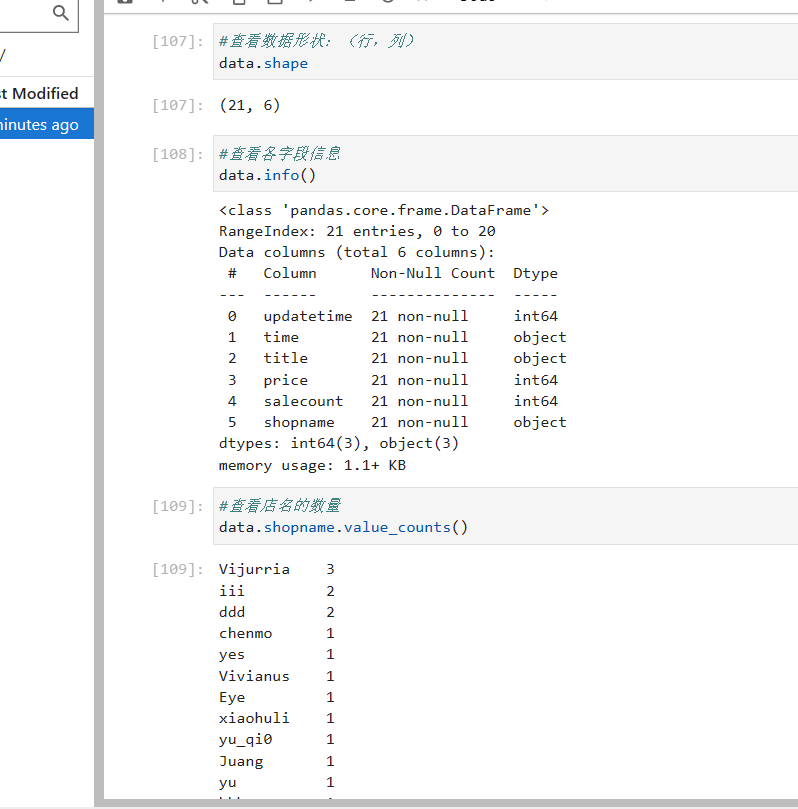
#查看缺失值(看的是每一列的缺少有效填充的数量)
data.isnull().sum()
#查看数据结构(count每一列的总数;unique去重后的数量;top最大含量的值;freq频数;mean平均值;std;min最小值;25%;50%;75%;max最大值)
data.describe(include='all')
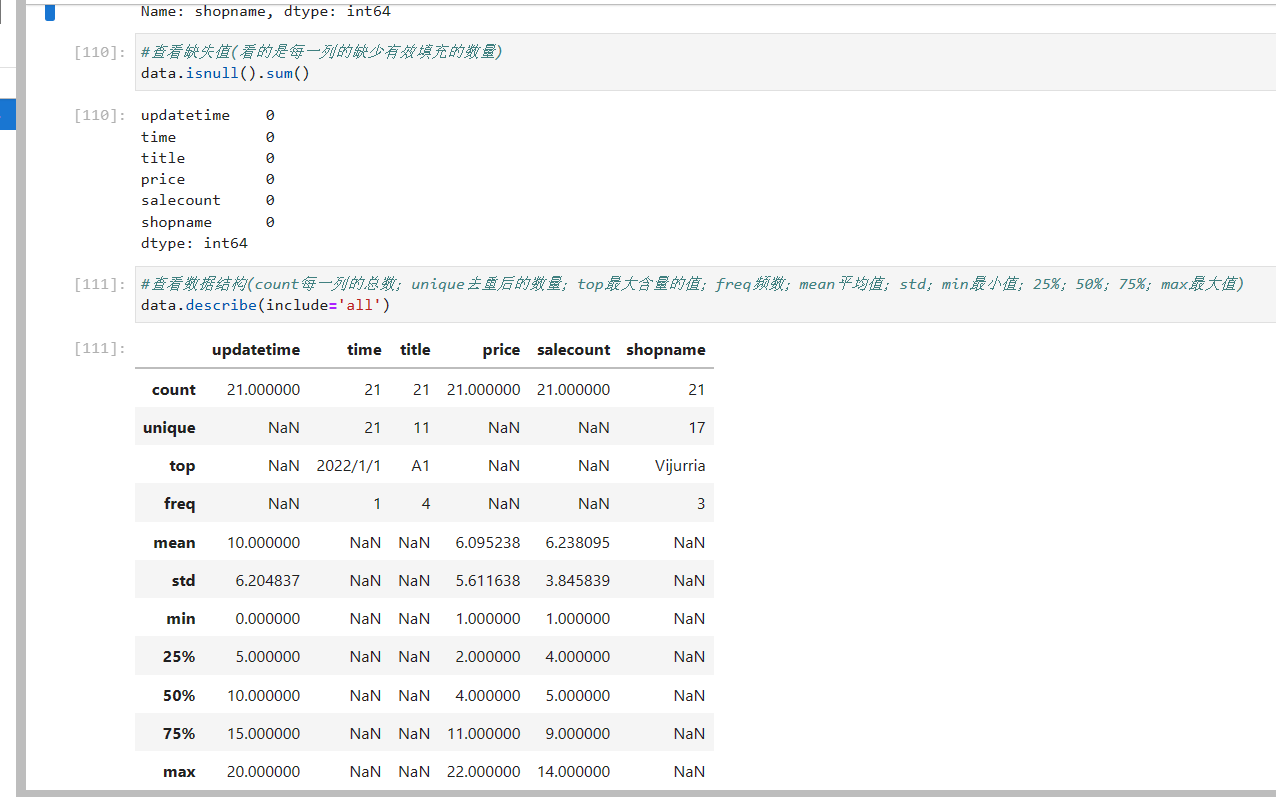
#查看某一列的众数
model_01=data.shopname.mode()
print(model_01)
#用0来填充缺失值
data=data.fillna(0)
data.isnull().sum()
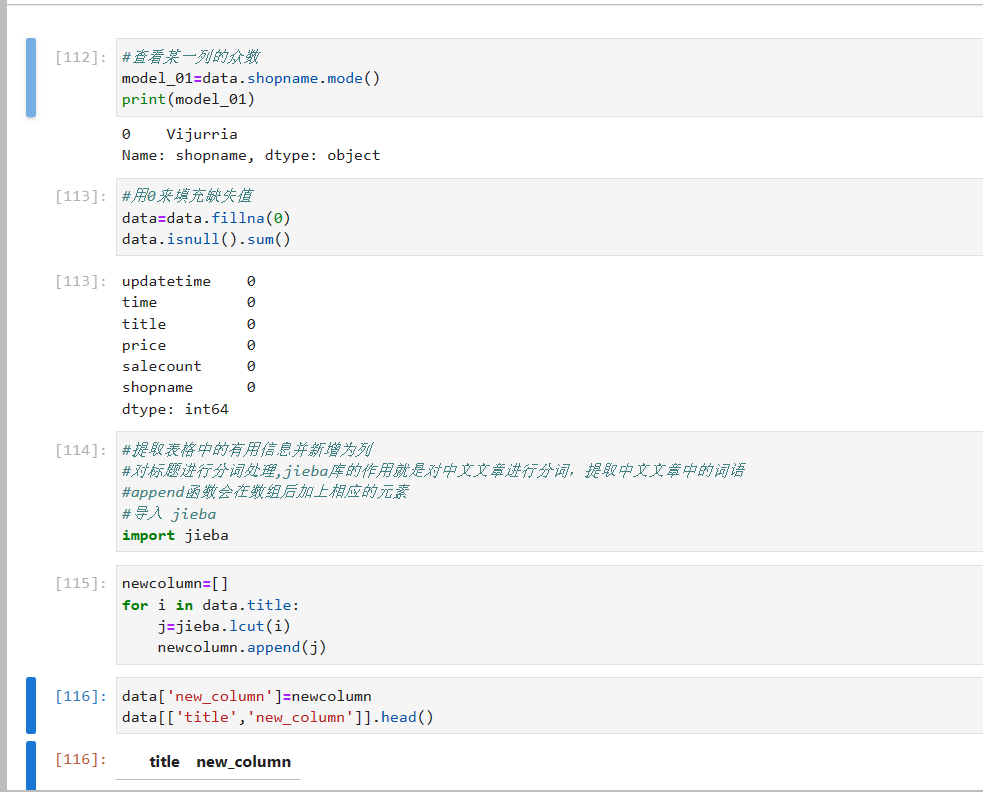
#提取表格中的有用信息并新增为列
#对标题进行分词处理,jieba库的作用就是对中文文章进行分词,提取中文文章中的词语
#append函数会在数组后加上相应的元素
#导入 jieba
import jieba
newcolumn=[]
for i in data.title:
j=jieba.lcut(i)
newcolumn.append(j)
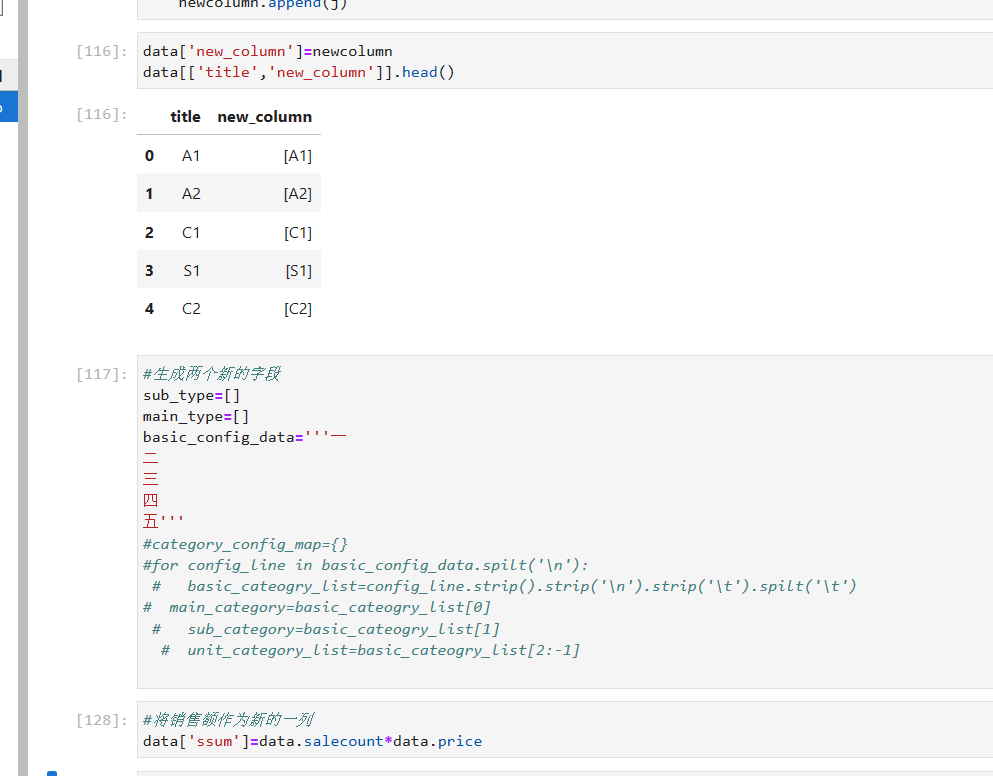
data['new_column']=newcolumn
data[['title','new_column']].head()

#将销售额作为新的一列
data['ssum']=data.salecount*data.price
#转换时间的格式
data['time']=pd.to_datetime(data['time'])
#将时间作为index
data=data.set_index('time')

#添加天为一列
data['day']=data.index.day
#移除数据 del(移除完之后就不要再运行了,再运行的话就需要把这一条删除过后再运行)
#del data['new_column']
data.head()
#可视化分析(查看每一个表头)
data.columns
#matplotlib画柱状图📊 - plt.bar()、plt.barh()
#plt.bar():正常柱状图📊📊,常见的统计图;
#plt.barh():横向的柱状图,可以理解为正常柱状图旋转了90°。
plt.figure(figsize=(10,6))
#计算各店铺的商品数量
data.shopname.value_counts().sort_values(ascending=False).plot.bar(width=0.8,color='lime',align='center')
#主标题 侧标题
plt.title('各品牌数目')
plt.ylabel('商品数目')
plt.show()
#同类的归成一组groupby
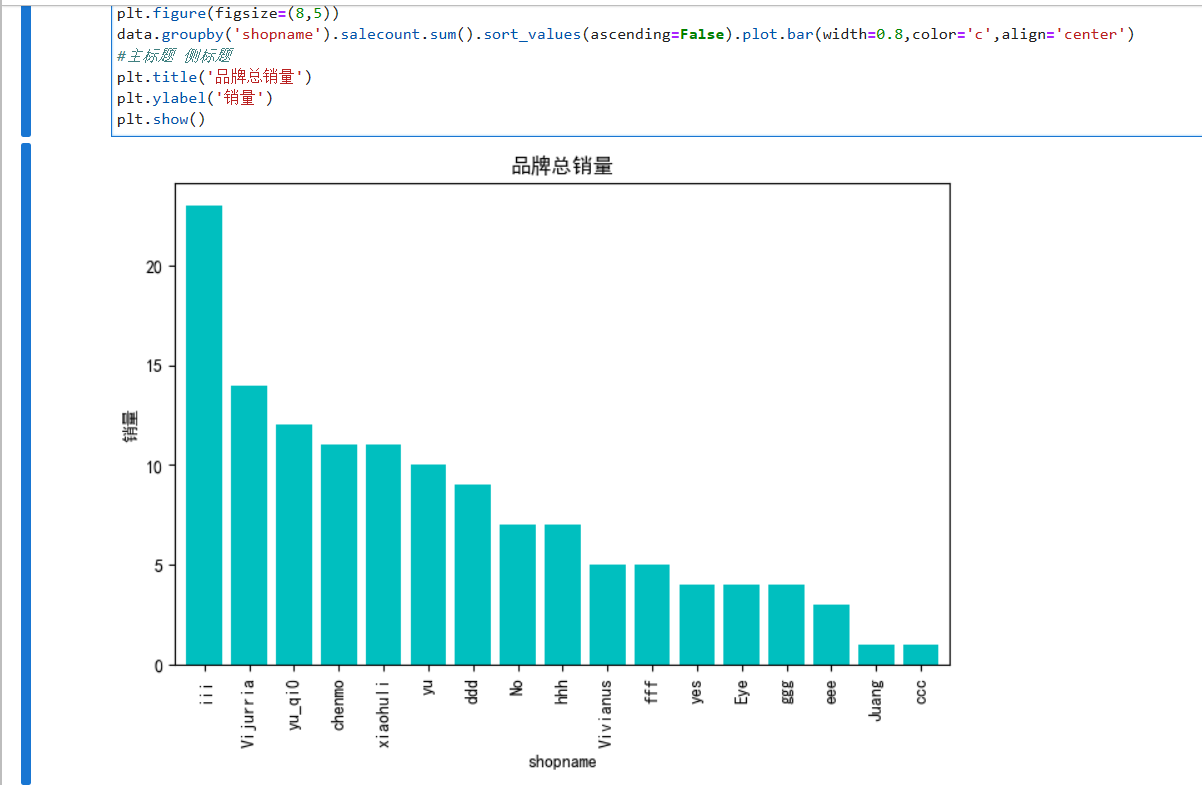
plt.figure(figsize=(8,5))
data.groupby('shopname').salecount.sum().sort_values(ascending=False).plot.bar(width=0.8,color='c',align='center')
#主标题 侧标题
plt.title('品牌总销量')
plt.ylabel('销量')
plt.show()
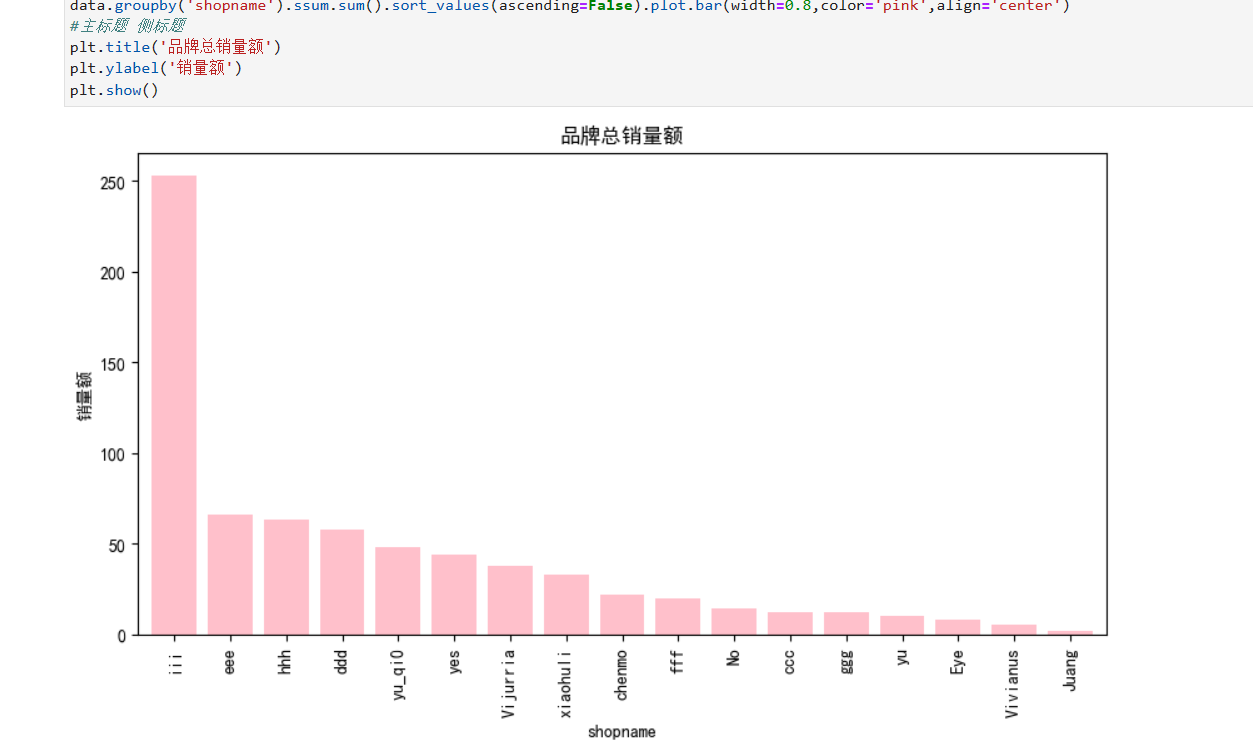
#同类的归成一组groupby
plt.figure(figsize=(10,5))
data.groupby('shopname').ssum.sum().sort_values(ascending=False).plot.bar(width=0.8,color='pink',align='center')
#主标题 侧标题
plt.title('品牌总销量额')
plt.ylabel('销量额')
plt.show()
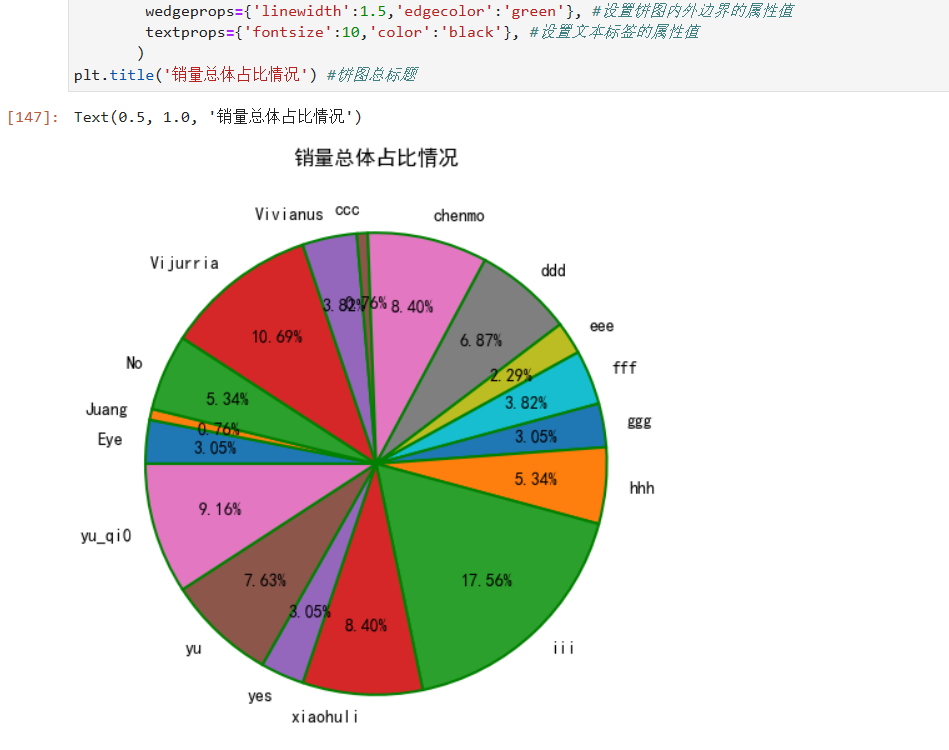
#绘制饼图
plt.figure(figsize=(10,6))
plt.pie(x=data['salecount'].groupby(data['shopname']).sum(),#绘图数据
autopct='%.2lf%%', #设置百分比的格式,这里保留2位小数
pctdistance=0.7, #设置百分比标签与圆心的距离
labels=data['salecount'].groupby(data['shopname']).sum().index,
labeldistance=1.1,#设置标签与圆心的距离
startangle=180, #设置饼图的初始角度
radius=1, #设置饼图的半径
counterclock=False, #是否逆时针,这里设置为顺时针方向
wedgeprops={'linewidth':1.5,'edgecolor':'green'}, #设置饼图内外边界的属性值
textprops={'fontsize':10,'color':'black'}, #设置文本标签的属性值
)
plt.title('销量总体占比情况') #饼图总标题
