计算机网络核心
一、网络基础知识
1、OSI 开放式互联参考模型
当前市面上分别存在:四层、五层、七层协议,而国际标准化组织 ISO 制定的 OSI 七层协议模型,是业界提出来的概念性框架:
先自上而下,后自下而上处理数据头部
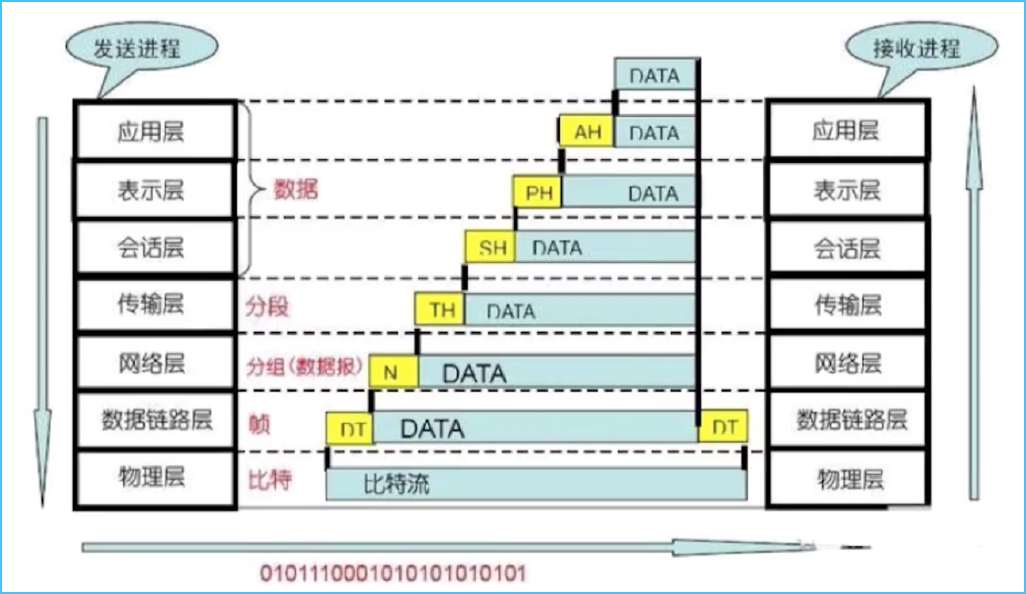
从应用层开始,都会对传输的数据头部进行处理,加上本层的一些信息,最终,由物理层通过以太网、电缆等介质,将数据解析成比特流,在网络中传输。
数据传输到目标地址后,并自底而上的将先前对应的头部解析分离出来,这个就是网络数据处理的流程。
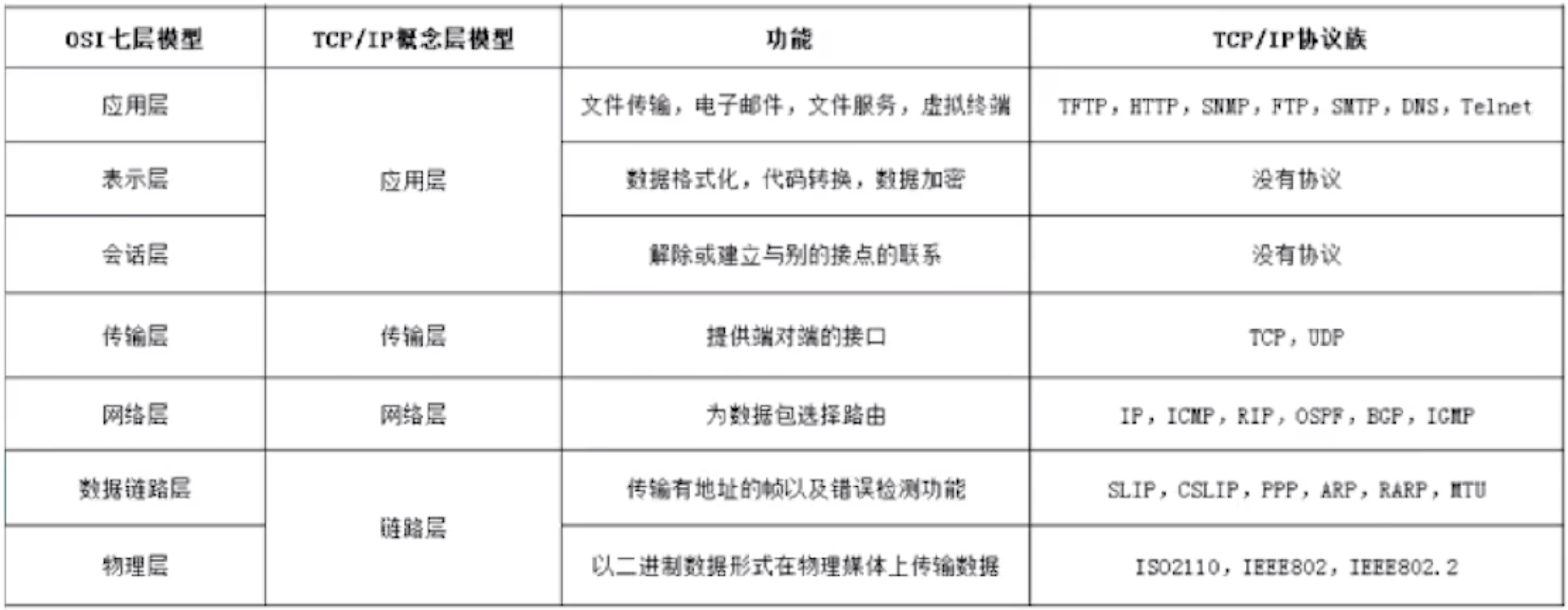
2、TCP/IP
OSI 是一个定义良好的协议规范机制,并有许多可选部分完成类似的任务。它定义了开放系统的层次结构
、层次之间的相互关系、以及各层可包括的可能的任务,是作为一个框架来协调和组织各层所提供的服务。
但是 OSI 参考模型并没有提供一个可以实现的方法,而只是描述了一些概念,用来协调进程间通信标准的制定。所以,OSI 参考模型并不是一个标准,而是一个在自定标准时所使用的概念型框架。
实施的标准时 TCP/IP 四层架构参考模型,虽然 TCP/IP 协议并不完全符合 OSI 的七层参考模型,但我们依然可以将其理解为是对 OSI 的一种实现。
二、TCP的三次握手
1、TCP 报文头

1.1 Source Port 和 Destination Port
首先,Source Port 和 Destination Port 分别表示源端口和目的地端口,它们各站两个字节。
TCP 和 UDP 的数据包,都是不包含 IP 地址信息的,因为那是 IP 层上的事,但是 TCP 和 UDP 均会有源端口和目的地端口。
我们知道两个进程,在计算机内部进行通信,可以由管道、内存共享、信号量、消息队列等方式进行通信,而两个进程要进行通信,最基本的前提就是能够唯一标识一个进程,通过这个唯一标识,找到这个进程。
在本地进程通信中,可以使用 PID 和进程号来唯一标识一个进程,但 PID 只在本地唯一,如果是两台不同的计算机中的进程要进行通信,PID 就不够用了,这就需要另外一个手段:在传输层中使用协议端口号。
IP 层的 IP 地址,可以唯一标识主机,而 TCP 协议和端口号,可以标识主机中的一个进程,这样就可以利用 IP 地址 + 协议 + 端口号,去标识网络中的一个进程。在一些场合,也把这种唯一标识的模式成为 套接字,即 Socket。
1.2 Sequence Number
序号,简称 seq, 它占用四个字节。
TCP 连接中,传送的字节流中的每个字节,都是按顺序去编号的,例如,一段报文的序号字段值是107,而携带的数据,共有100个字段,那么如果有下一个报文段的话,其序号就是107+100,也就是207开始。
1.3 Acknowledgment Number
确认号,简称 ack, 同样占用四个字节,是期望收到对方下一个报文的第一个数据字节的序号。
例如,B 收到了 A 发送过来的报文,其 seq 是301,而数据长度是200字节,这表明了 B 正确收到了 A 发送的到序号500为止的数据,301+200-1=500.
因此,B 期望收到 A 的下一个数据序号,是501,于是,B 在发送给 A 的确认报文段中,会把 ack 确认号置为501.
1.4 Offset
数据偏移。
由于头部有可选字段,长度不固定,因此 Offset 指出 TCP 报文的数据距离 TCP 报文的起始数有多远。
1.5 Reserved
保留域。
保留今后使用的,但目前都会被标位0.
1.6 TCP Flags
控制位,主要有8个标志位组成,每一个标志位表示一个控制功能。
常见的六个:
- URG:紧急指针标志
当它为1时,表示紧急指针有效,为0,则忽略紧急指针。
- ACK:确认序号标志
当它为1时,表示确认号有效,为0,表示报文中不含确认信息,忽略确认号字段。
- PSH:push标志
为1时,表示是带有push标志的数据,指示接收方在接收到该报文段以后,应尽快将这个报文段交给应用程序,而不是在缓冲区排队。
- RST:重置连接标志
用于重置由于主机崩溃或其他原因,而出现的错误连接,或者用于拒绝非法的报文段,和拒绝连接请求。
- SYN:同步序号,用于建立连接过程
在建立连接时使用,用来同步序号。当 SYN=1, ACK=0 时,表示这是一个请求建立连接的报文段;当 SYN=1, ACK=1 时,表示对方同意建立连接。
SYN=1,说明这是一个请求建立连接或同意建立连接的报文。只有在前两次握手中 SYN 才置为1.
- FIN:finish标志,用于释放连接
为1时,表示发送方已经没有数据发送了,即关闭本方数据流。
以上,红色的标志,需要特别留意。
1.7 Window
指的是滑动窗口的大小,用来告知发送端、接收端的缓存大小,以此控制发送端发送数据的速率,从而达到流量控制。
1.8 Checksum
校验和,指的是即有校验。
此校验和是对整个的 TCP 报文段、包括 TCP 头部和 TCP 数据,以16位进行计算所得,由发送端计算和存储,并由接收端进行验证。
1.9 Urgent Pointer
紧急指针。
只有当 TCP Flags 中的 URG 为1的时候才有效,指出本报文段中的紧急数据的字节数。
1.10 TCP Options
可选项,其长度可变,定义一些其他的可选参数。
2、三次握手
当应用程序希望通过 TCP 与另一个应用程序通信时,它会发送一个通信请求,这个请求必须被发送到一个确切的地址,在双方握手之后,TCP 将在两个应用程序之间建立一个全双工的通信,这个全双工的通信,将占用两个计算机之间的通信线路,直到它被一方或双方关闭为止。
什么是全双工?就是说计算机 A 可以给 B 去发送信息,在发送信息的同时,B 也可以给 A 回发信息。
三次握手的流程如下:
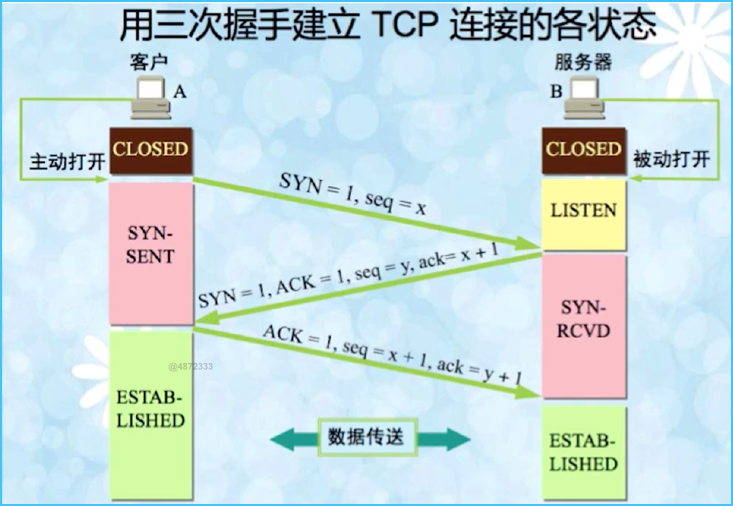
A 和 B 首次进行通信,一开始的时候,客户端和服务器都是处于关闭状态。这里假设,主动打开连接的是客户端,被动打开连接的是服务端。
刚开始的时候,TCP 服务器进程先创建传输控制块 TCB,时刻准备接收其他客户端进程发送过来的连接请求。此时,服务端进入了 Listen 即监听的状态。
而此时,TCP 客户端进程也是先创建一个传输控制块 TCB,然后向服务器发出连接请求报文。
第一次握手: 客户端向服务器发出连接请求报文,会有 SYN=1,就是报文头里的 TCP Flags 中的同步序号,同时,选择一个初始序号,seq=x,这个 x 可以是一个任意的正整数。此时,TCP 客户端进程就进入了一个 SYN_SENT 这么一个同步已发送的状态。这一次发送的数据包(即报文段)会被称为 SYN ['sɪn] 包,是一个请求建立连接的报文段,是不能携带数据的,但是要消耗掉一个序号,这便是第一次握手。
第二次握手: 当服务器接收到请求报文之后,如果同意连接,则发出确认报文。即 SYN + ACK 包。确认报文中,包含了 TCP Flags 中的两个字段,即:ACK=1,以及 SYN=1。
那它的确认号,就是 ack=x+1,因为在之前的 SYN 报文里面指定了 seq=x,那么作为回应,要回应跟 x 相关的信息,并且由于上面的一个报文消耗掉了一个序号,因此这里的 ack=x+1,同时自己这边也要初始化一个序列号,即:seq=y,此时,服务器就进入到了 SYN_RCVD,即同步收到的状态。这个报文也是不能携带数据的,且同样消耗掉一个序号。
第三次握手: 当 TCP 客户端进程收到确认报文之后,还要再向服务器发送一个 ACK 包,因为是确认报文,所以 ACK=1,此时,小的 ack=y+1,原因是因为刚刚服务器发过来了一个序号 seq=y,同时这个报文也会消耗掉一个序号,那么这里作为回应,回应过去的就是 ack=y+1。
同时,由于刚刚服务器告知客户端,序号已经被+1了:ack=x+1,因此在这里,seq=x+1。
此时,TCP 连接建立,客户端就进入了 established [ɪˈstæblɪʃt] 已建立连接的状态。TCP 规定,这个 ACK 报文段是可以携带数据的,前两个是不可以携带的。当然也可以不携带,如果不携带数据,就不会消耗序号。
当服务器收到了客户端的确认后,也会进入到 established 的状态,然后双方就可以开始通信了。这便是第三次握手。

3、为什么需要三次握手才能建立起连接?
其实并没有 YY 的那么复杂,主要是为了初始化 Sequence Number 的初始值,通信的双方需要互相通知对方自己初始化的 Sequence Number,这个序号要作为以后的数据通信的序号,以保证应用层接收到的数据不会因为网络上的传输问题而乱序,即 TCP 会用这个序号来拼接数据。
因此,在第二次握手之后,还需要发送确认报文给服务器,告知服务器说:客户端已经收到你的初始化的 Sequence Number 了。
4、首次握手的隐患——SYN超时
在第一次握手的时候,有一个隐患,即:SYN 的超时问题。
- 如果 Server 收到了 Client 的 SYN 包后,回 SYN-ACK 包,会了之后 Client 就掉线了,此时,Server 端没有收到 Client 端发送过来的 ACK 包的确认,那么这个连接就会处于一个中间状态,即没有成功,也没有失败。
- 于是,Server 端在一定时间内没有收到 Client 端的确认,它就会重发 SYN-ACK,在 Linux 下,默认重试次数为5次,重试间隔从1秒开始,每次都翻倍。因此,五次的重试时间就是31秒,且在第五次发出去之后,还需要等待32秒,才能够被判定为超时,所以,要等到63秒的时候,TCP 才会断开连接。
那这样会造成什么后果?就是可能会使得服务器遭到 SYN Flood 攻击的风险。恶意程序会给服务器发一个 SYN 包,发了之后就下线,于是服务器默认需要63秒才会断开这个连接,这样,攻击者就可以把服务器的 SYN 连接队列耗尽,让正常的连接请求不能处理。
于是,Linux 下,就给了一个 tcp_syncookies 的参数来应对这个事。
当 SYN 队列满了之后,再有 SYN 请求进来,TCP 就会通过原地址端口、目标地址端口和时间戳打造出一个特别的 Sequence Number 回发回去,这个 Sequence Number 简称 SYN Cookie。如果是攻击者,是不会有响应的。如果是正常连接,则会把这个 SYN Cookie 发回来,然后服务端可以通过 Cookie 建立连接。
通过 SYN Cookie,即便此时 SYN 队列满了,本次连接请求不在队列中,依然能建立连接,进而解决了该问题的发生。
三、TCP的四次挥手
所谓『挥手』,即终止 TCP 连接,就是指断开一个 TCP 连接时,需要客户端和服务端总共发出四个包,已确认连接的断开。
在 Socket 编程中,这一过程由客户端或服务端任意一方执行 Close 来触发。
这里假设,由客户端主动触发 Close:
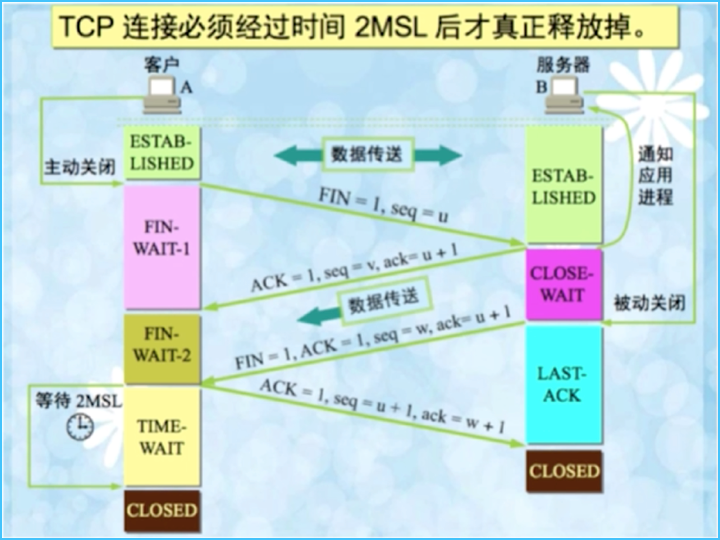
最开始,客户端和服务端都处于 Established 的状态,然后客户端主动关闭,服务端被动关闭。
第一次挥手: 首先,客户端进程发出连接释放报文,并且停止发送数据,在该数据包的报头中,TCP Flags 中的 FIN 就为1,假设,此时的客户端定义的序列号 seq=u,该值等于前面 Established 状态下数据最后一次传送到服务端的数据的最后字节的序号+1,此时客户端就进入了 FIN_WAIT_1 这么一个终止等待的状态。TCP 规定,即使 FIN 报文段不携带数据,也要消耗掉一个序号。
第二次挥手: 服务器收到 FIN 包后,也要发出 ACK 确认报文,这里最为回应,小写的 ack=u+1,同样也携带上了自己的序列号。此时服务端进入了 CLOSE_WAIT 这么一个关闭等待的状态。
这个状态比较重要,TCP 服务器通知高层的应用进程,客户端要释放跟服务器通信的连接了,这时候会处于半关闭的状态,即客户端已经没有数据要发送了,但是服务端又要发送数据,客户端还是能够接收的。这个状态还要持续一段时间。
客户端收到服务器的确认请求后,此时,客户端就进入了 FIN_WAIT_2 这个状态,等待服务器发送释放连接报文。因此在这段时间内,客户端有可能还要接受服务器发送的最后的数据。
第三次挥手: 服务器将最后的数据发送完毕,就会想客户端发送连接释放报文,这里 FIN=1, ACK=1。而 ack 还是等于 u+1.
由于在半关闭的状态,服务器有可能还发送了一些数据,假定此时的序号就变为了 w.
此时,服务器就进入了 LAST_ACK 这么一个最后确认的状态,等待客户端的最终确认。
第四次挥手: 客户端在收到服务器的连接释放报文之后,必须发出确认,即:ACK=1,此时,客户端就进入了 TIME_WAIT 即时间等待的状态。
注意此时,客户端的 TCP 连接还没有释放,必须经过 2 * MSL 的时间后,这个连接才真正的释放,才进入到 CLOSED 的状态。
MSL 即最长报文段寿命,RFC 793 定义了 MSL 的值为2分钟,而 Linux 则设置成了30秒。
而服务器,只要收到了客户端的确认,立即就进入了 CLOSED 的状态。
1、为什么会有 TIME_WAIT 状态?
这是为了确保有足够的时间让对方收到 ACK 包。
- 如果被动关闭的那方没有收到 ACK 包,就会触发被动端重发 FIN 包,一来一去,正好是两个 MSL.
- 避免新旧连接混淆。有足够的时间让这个连接不会跟后面的连接混在一起。
2、为什么需要四次挥手才能断开连接?
同样没有 YY 的那么复杂。
前面说过,全双工的意思是允许数据在两个方向上同时传输。
因为 TCP 是全双工的,发送方和接收方都需要 FIN 报文和 ACK 报文,也就是说,发送方和接收方各自需两次挥手即可,只不过有一方是被动的,所以看上去就成了所谓的四次挥手。
3、服务器出现大量 CLOSE_WAIT 状态的原因
问题的其中一个表现,是客户端一直在请求,但是返回给客户端的信息是异常的,或者说压根没有返回信息。
通过上图可以看到,服务器保持大量的 CLOSE_WAIT 只有一种情况,那就是在对方发送一个 FIN 报文之后,程序这边没有进一步发送 ACK 包,或者 FIN+ACK 包。
换句话说,就是在对方关闭 Socket 连接后,程序没有检测到,或者更程序本身就已经忘了这个时候需要关闭连接,于是这个资源就一直被程序占用着。
遇到这种情况,多数是程序中有 bug,通常是某些连接没有及时释放导致的,或者是某些配置,如线程池中的配置不合理。
获取当前服务器处于各个状态下的连接数:
$ netstat -n | awk '/^tcp/{++S[$NF]}END{for(a in S) print a,S[a]}'
一旦 CLOSE_WAIT 很多,比如有几千的话,就需要排查问题了。
四、TCP 的滑动窗口
首先要理解两个概念:
-
RTT
Round-Trip Time, 即往返时延,指发送一个数据包到收到对应的 ACK, 所花费的时间; -
RTO
Retransmission TimeOut, 即重传时间间隔。
TCP 在发送一个数据包之后,会启动一个重传定时器,而 RTO 就是这个定时器的重传时间。
TCP 会将数据拆分成段进行发送,出于效率和传输速度的考虑,我们不可能等一段一段数据去发送,等到上一段数据被确认之后再发送下一段数据,这个效率是非常低的。要实现对数据的批量发送,那么 TCP 久必须要解决批量传输、以及包乱序的问题。
所以 TCP 需要知道网络实际的处理带宽,或是数据处理速度,这样才不会引起网络拥塞,导致丢包。
TCP 使用滑动窗口做流量控制与乱序重排,TCP 的滑动窗口主要有两个作用:
- 保证 TCP 的可靠性;
- 保证 TCP 的流控特性。
在前面学习的 TCP 报文头里,有一个字段:Window,用于接收方通知发送方自己还有多少缓冲区可以接收数据,发送方根据接收方的处理能力来发送数据,不会导致接收方处理不过来。这便是流量控制。
同时,滑动窗口机制,还提现了 TCP 面向字节流的设计思路。
窗口数据的计算过程
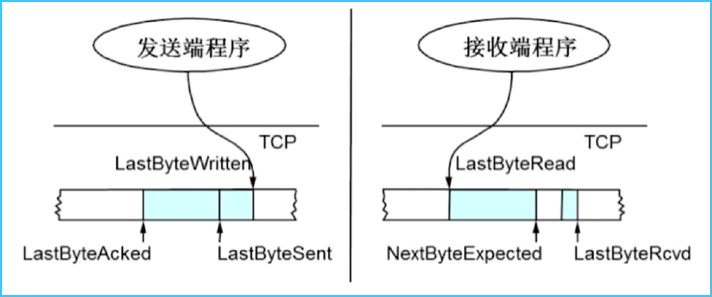
如图所示,左图是 TCP 协议的发送端缓冲区,右图是接收端缓冲区。
左边往右边发数据,两个图中,下面的长方形表示要发送的数据流,里面假设装满了数据,并且需要按照顺序从左往右发送、接收,我们假设,对应的数据段位置序号也是从左到右去增长的,对于发送方来讲,LastByteAcked 指向收到的连续最大的 ACK 的位置,也就是从左端算起,连续已经被接收端的程序发送 ACK 回执确认已收到的 Sequence Number, 而 LastByteSent 指向已发送的最后一个字节的位置,该位置只是发出去了,但是还没收到 ACK 的回应,而 LastByteWritten 指向上层应用已写完的最后一个字节的位置,即当前程序已经准备好的需要发送的最新的数据段。
也就是说,从 LastByteAcked 到 LastByteSent, 这段是发送出去,但是还没有收到确认的;
从最左边到 LastByteAcked 这段,是发送出去且已经收到接收端的确认的。
可以看到,从 LastByteAcked 到 LastByteWritten 都是没有出现间隔的,都是连续的,对于接收方来讲:
LastByRead 指向上层应用已经读完的最后一个字节的位置,也就是说收到了发送方的数据,且已处理并给他回执了的数据的最后一个字节,而 NextByteExpected 指向收到的连续最大的 Sequence Number 的位置,也就是说,从 LastByRead 到 NextByteExpected 这一段,是收到了,但是还没给发送方发送回执。而 LastByteRcvd 是指向已收到的最后一个字节的位置,可以看到 NextByteExpected 到 LastByteRcvd 中间有一些 Sequence Number 还没有到达,对应的是空白的区域,此时,可以根据上面的数值计算出接收方的 Advertised window (即接收方还能处理的数据量)的大小,之后,回发给发送方让其计算出发送方的剩余可发送的数据大小,即 Effective Window(即发送还发可以发送的数据量) 的大小。
- Advertised Window = MaxRcvBuffer - (LastByteRcvd - LastByteRead)
- MaxRcvBuffer: 指接收方能接收的最大数据量,也可以理解为接收方缓存池的大小。
- Effective Window = AdvertisedWindow - (LastByteSent - LastByteAcked)
五、TCP和UDP的区别
1、UDP 报文头
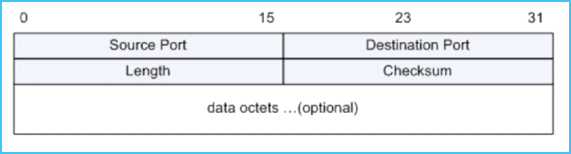
可以看到,相比 TCP 报文,UDP 的报文的域相对少了很多,有源端口、目标端口、数据包长度、校验和、和用户数据来组成。
2、UDP 的特点
简单的报文结构,也就意味着 UDP 不像 TCP 那样支持错误重传、滑动窗口等精细控制,其特点如下:
-
面向无连接
UDP 是一个无连接的协议,连接之前,源端和终端之间不建立连接,当它想传送时,就简单的去抓取来自应用程序的数据,并尽可能快的把它扔到网络上。
在发送端,UDP 传送数据的速度仅仅是受应用程序生成数据的速度、计算机的能力、和传输带宽的限制;
在接收端,UDP 把每个消息段放在队列中,应用程序每次从队列中读取一个消息段。 -
不维护连接状态,支持同时向多个客户端传输相同的消息
由于传输数据不建立连接,因此也就不需要维护连接状态,包括收发状态。
因此,一台服务器可同时向多个客户机传输相同的消息。 -
数据包报头只有8个字节,额外开销较小
相对于 TCP 的20个字节,UDP 包的额外开销小很多。 -
吞吐量只受限于数据生成速率、传输速率以及机器性能
吞吐量不受拥挤控制算法的调节,只受限于数据生成速率、传输带宽、源端和终端主机性能的限制。 -
尽最大努力交付,不保证可靠交付,不需要维持复杂的链接状态表
-
面向报文,不对应用程序提交的报文信息进行拆分或者合并
发送方的 UDP 对应用程序交下来的报文,在添加首部后,就向下交付给 IP 层,既不拆分,也不合并,而是保留这些报文的边界。因此,应用程序需要选择合适的报文大小。
3、结论
TCP 和 UDP 是 OSI 模型中的运输层中的协议,TCP 提供可靠的通信传输,而 UDP 则常被用于让网络和细节控制交给应用层的通信传输,两者区别如下:
-
面向连接 VS 面向无连接
TCP 有三次握手的连接过程,UDP 适合消息的多播发步,从单个点向多个点传输信息。 -
可靠性
-
有序性
-
速度
-
量级
五、HTTP 简介
HTTP 即超文本传输协议,是属于应用层的协议,是一个基于请求与响应模式的无状态的应用层的协议,常基于 TCP 的连接方式。
HTTP 目前正处于多个版本共存的情况,包括仍被广泛采用的 1.0, 主流最为广泛的 1.1, 还有应用较少、NB 吹的最大的 2.0.
1.1 相交于 1.0 最明显的区别是引入了 keep-alive 这项长连接技术,2.0 虽然更合理、更先进,但其推广不开来的原因也是因为 1.1 完全能够满足目前的应用,并且升级上 2.0 的成本太大所导致的,这里主要以 1.1 为准。
1、HTTP 的特点
绝大多数的 Web 开发,都是构建在 HTTP 协议之上的 Web 应用,HTTP 的主要特点可概括如下:
-
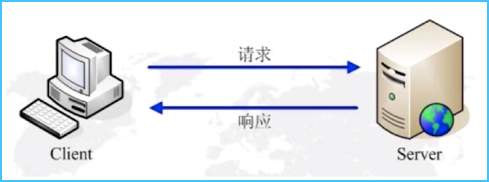
支持客户 / 服务器模式
![image_1cvd2cch01ocl1de4dlkce78ntm.png-76.3kB]()
HTTP 协议工作于客户端、服务端架构之上,浏览器作为 HTTP 客户端,通过 URL 向 HTTP 服务端及 Web 服务器发送所有请求。
-
简单快速
请求时只需请求方法和路径,请求方法常用的有:GET、POST. -
灵活
允许传输任意类型的数据对象。 -
无连接
无连接的含义是:限制每次连接,只处理一个请求。
服务器处理完客户的请求,并受到客户的应答之后,即断开连接,采用这种方式可以节省传输时间。 -
无状态
无状态是指协议对于事务处理没有记忆能力,缺少状态意味着如果后续处理需要先前的信息,则必须被重传。
2、HTTP 结构
2.1 HTTP 请求结构

客户端发送一个 HTTP 请求到服务器的请求消息结构,如图,主要有四个部分组成:
-
请求行
- 请求方法
- url
- 协议版本
-
请求头
请求头由若干个报头组成的,每个报头的结构,都是:- 头部字段名(名字)
- 值
这些报头,用来设置 HTTP 请求的一些参数,例如:host, 表示被请求资源的主机和端口号。
-
空行
-
请求正文
数据体,只在 POST 请求中用到,表示要上传的数据。
数据体和头部之间是有一个空行的。
请求结构分析:
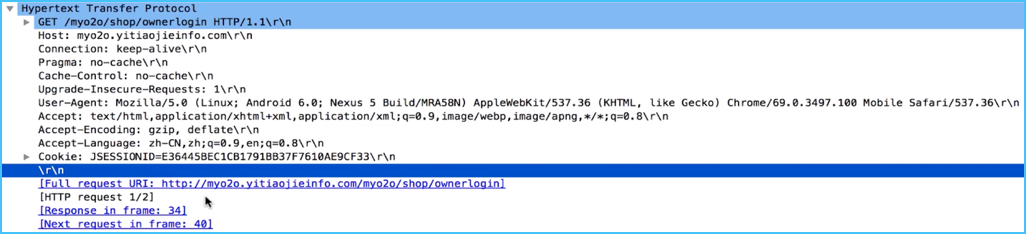
从 Host 到 Cookie 都是请求头;
请求头之后,不管请求正文有没有数据,都会要空一行。
2.2 HTTP 响应结构
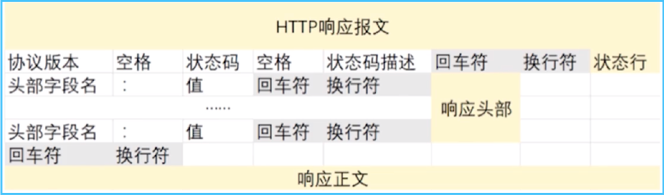
响应报文主要有三个部分:
-
状态行
- 协议版本
- 状态码
- 状态码描述
-
响应头部
用来说明客户端要使用的一些附加信息的- 头部字段名
- 值
比如说,Date 是用来生成响应的日期和时间,Content-Type 就指定了 MIME 类型的 HTML.
-
空行
-
响应正文
响应结构分析:
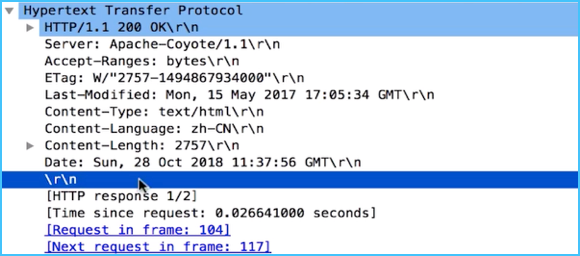
3、HTTP 请求 / 响应的步骤
-
客户端连接到 Web 服务器
一个 HTTP 客户端,通常是浏览器与 Web 服务器的 HTTP 端口,默认端口号是80, 建立一个 TCP 套接字连接。 -
发送 HTTP 请求
即通过 TCP 套接字,客户端向 Web 服务器发送一个文本的请求报文 -
服务器接受请求并返回 HTTP 响应
-
释放连接 TCP 连接
如果连接模式为 Close, 则服务器主动关闭 TCP 连接,客户端被动关闭连接,释放 TCP 连接;
如果连接模式为 keep-alive, 则该链接会保持一段时间,在改时间内,可以继续接受请求。 -
客户端浏览器解析 HTML 内容
4、在浏览器地址栏键入 URL, 按下回车之后经历的流程
-
DNS 解析
首先,浏览器会依据 URL 逐层查询 DNS 服务器缓存,解析 URL 中的域名所对应的 IP 地址。
DNS 缓存从近到远,依次是:浏览器缓存、系统缓存、路由器缓存、IPS 服务器缓存、根域名服务器缓存、顶级域名服务器缓存、主域名服务器缓存。从哪个缓存找到对应的 IP, 则直接返回,不再查询后面的缓存。 -
TCP 连接
根据 IP 地址和对应端口(默认是80端口)和服务器建立 TCP 连接(三次握手)。 -
发送 HTTP 请求
-
服务器处理请求并返回 HTTP 报文
-
浏览器解析并渲染页面
-
浏览器释放 TCP 连接(四次挥手)
其中,第五步和第六步可以认为是同时发生的,哪一步在前没有特别的要求。
5、GET 请求和 POST 请求的区别
从三个层面来解答:
- HTTP 报文层面: GET 将请求信息放在 URL, POST 放在报文体中。虽然 POST 放在报文体,但通过抓包依然是可以很轻松的获取到信息的,所以从安全性上来讲,两者并没有太多的区别,HTTP 也并不是安全的,具体要解决传输过程中的安全问题,还要靠 HTTPS. GET 有长度限制,POST 则无。
- 数据库层面: GET 符合幂等性和安全性,POST 不符合。幂等性的定义就是对数据库的一次操作、和多次操作,获得的结果是一致的;安全性则是对数据库的操作没有改变数据库的数据。GET 请求是用来做查询操作的,因此不会改变数据库中原有的数据,而 POST 请求则是提交数据,因此会改变数据库中的数据,其次,POST 请求方式每次获得的结果都有可能不一样,因为 POST 请求是作用在上一级的 URL 上的,则每一次请求都会添加一份新资源,这也是 POST 和 PUT 的最大区别。PUT 是幂等的。
- 其他层面: GET 可以被缓存、被存储,而 POST 不行。GET 请求会保存在浏览器的浏览记录中,以 GET 请求的 URL 可以保存为浏览器书签,而 POST 不具备这些功能。
6、Cookie 和 Session 的区别
因为 HTTP 是无状态的,也就意味着我们每次访问某个有登录需求的页面,都要输入一次账号和密码。
但是现实中并没有出现这样的场景,这是因为我们引入了某些机制,让 HTTP 具备了状态,其中的两个便是 Cookie 和 Session.
6.1 Cookie
Cookie 是客户端的解决方案。
- 是有服务器发送给客户端的特殊信息,以文本形式存放在客户端
- 客户端再次请求的时候,会把 Cookie 回发
- 服务器接收到后,会解析 Cookie 生成与客户端相对应的内容
6.2 Session
- 服务器端的机制,在服务器上保存的信息
- 当程序要为某个客户端的请求创建一个 session 的时候,服务器先检查这个客户端的请求里是否包含了
session标识,称为session id,如果包含,则说明以前已经为此客户端创建过 session,服务器直接根据session id检索出来使用。如果客户端请求不包含session id,则为此客户端创建一个 session, 并生成一个与此相关的session id - 把 session 信息回发给客户端,进行保存
**Session 的实现方式,主要有两种:**
- 使用 Cookie 来实现
- 使用 url 回写来实现
6.3 区别
- Cookie 数据存放在客户的浏览器上,Session 数据放在服务器上
- Session 相对于 Cookie 更安全
- 若考虑减轻服务器负担,应当使用 Cookie
六、HTTPS 简介
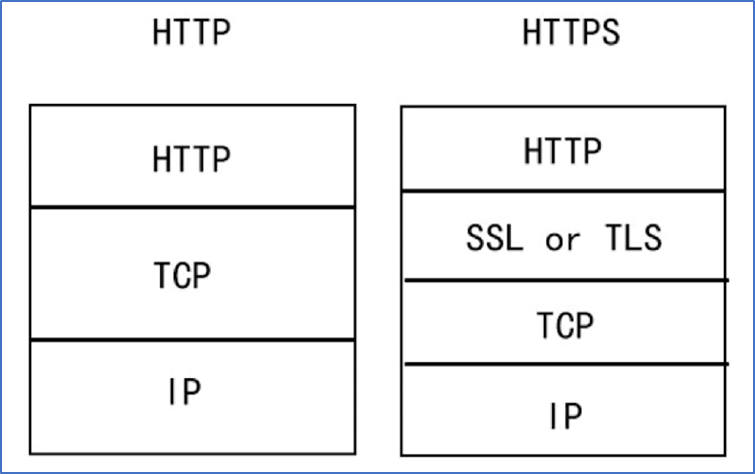
在 HTTP 下面,加入了一个 SSL 层,从而具有了保护交换数据隐私、完整性、提供对网站服务器身份认证的功能。
简单来说,HTTPS 就是安全版的 HTTP.
1、SSL(Security Sockets Layer, 安全套接层)
- 为网络通信提供安全及数据完整性的一种安全协议
- 位于 TCP 与各应用层之间,是操作系统对外提供的 API, SSL3.0 后更名为 TLS
- 是如何保证网络通信安全和数据完整性?身份认证,和数据加密
- 采用身份验证和数据加密保证网络通信的安全和数据的完整性
2、加密的方式
在前面学习 HTTP 的时候,通过抓包看了相关的协议,发现,不管是 GET 还是 POST, 客户端和服务端之间没有任何身份确认的过程,数据全部明文传输,客户端发出的请求很容易被黑客截获,如果此时黑客冒充服务器,则可返回任意信息给客户端而不被客户端察觉,这便是所谓的劫持。
如何给数据裹上一层外套?人们便想到了加密,加密主要有以下几种方式:
- 对称加密: 加密和解密都使用同一个秘钥,相对于非对称加密,效率要高很多
- 非对称加密: 加密使用的秘钥和解密使用的秘钥是不相同的,分别称为:公钥、私钥。公钥和算法都是公开的,私钥是保密的。非对称算法性能较低,但是安全性超强。但由于加密特性,能加密的数据长度也是有限的
- 哈希算法: 将任意长度的信息转换为固定长度的值,算法不可逆。就比如 MD5 算法
- 数字签名: 签名,便是在信息的后面加上一段内容,这些内容,是经过哈希后的值,可以证明信息是某个人发出/认同的,且没有被修改过。哈希值一般都会加密后,也就是签名之后,再和信息一起发送,以保证这个哈希值不被修改。
但是在实际的执行中,人们发现,仅使用其中的某种加密方式,并不能满足生产要求。
要么非对称加密性能过低,要么对称加密秘钥容易泄露,因此,HTTPS 使用的是证书配合各种加密手段的方式,打出一套相对安全的组合拳。
3、HTTPS 数据传输流程
HTTPS 在进行数据传输之前,会与网站服务器和 WEB 浏览器进行一次握手,在握手时,确定双方的加密密码信息,具体过程如下:
- 浏览器将支持的加密算法信息发送给服务器;
- 服务器选择一套浏览器支持的加密算法,以证书的形式回发浏览器;
- 浏览器验证证书合法性,并结合证书公钥加密信息发送给服务器;
- 服务器使用私钥解密信息,验证哈希,加密响应消息回发浏览器;
- 浏览器解密响应消息,并对消息进行验证,之后进行加密交互数据。
4、HTTP 和 HTTPS 的区别
- HTTPS 需要到 CA 机构申请证书,需要一定的费用,HTTP 不需要
- HTTP 是超文本传输协议,信息明文传输;而 HTTPS 则是具有安全性的 SSL 加密传输协议,因此是密文传输
- 使用完全不同的连接方式。HTTPS 默认使用 443 端口,HTTP 默认使用 80 端口
- HTTP 是无状态的,SSL 是有状态的,因此可以理解为:HTTPS = HTTP + 加密 + 认证 + 完整性保护
5、HTTPS 真的很安全吗?
那倒未必。
由于用户习惯,通常准备访问某个网站时,在浏览器中,只会输入一个域名,比如,访问百度,就只会输入:www.baidu.com,不会在域名前面加上 http:// 或 https://,都是由浏览器自动填充。
当前所有浏览器默认填充都是 http://,一般情况,网站管理员会采用 301、302 跳转的方式由 HTTP 跳转到 HTTPS. 但是在这个过程中,会使用到 HTTP, 因此在这一步容易发生劫持。
这个时候,可以使用 HSTS(HTTP Strict Transport Security) 优化,即:HTTP 严格传输安全。
HSTS 目前正在推行中,并未成为主流。
七、Socket 简介
我们知道,两个进程如果需要进行通信,最基本的前提,是能唯一的标识一个进程。
在本地进程通信中,可以使用 PID 来唯一标识一个进程。但在网络中,就要另辟蹊径了。
IP 层的 IP 地址,可以唯一标识主机,而 TCP 协议和端口号,可以标识主机中的一个进程。这样就可以利用 IP 地址 + 协议 + 端口号,去标识网络中的一个进程。能够唯一标识网络中的一个进程后,它们就可以利用 Socket 进行通信。
1、什么是 Socket?
Socket 跟 TCP/IP 协议没有必然的联系,Socket 是对 TCP/IP 协议的抽象,是操作系统对外开放的接口:
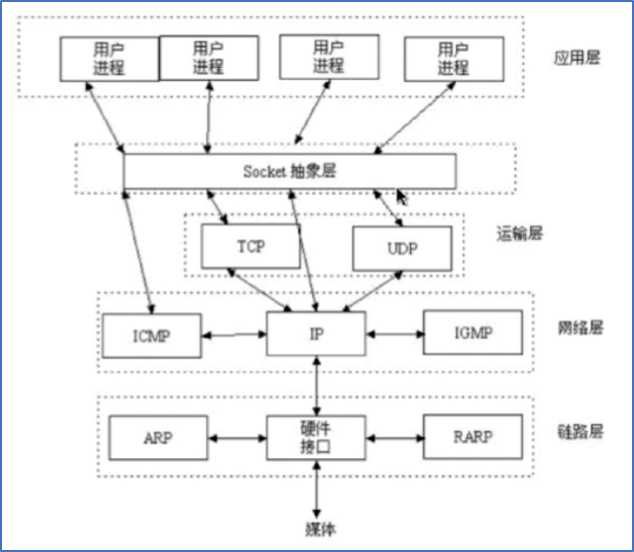
Socket 编程接口在设计之初,就希望能适应其他的网络协议,所以,Socket 的出现,只是使得程序员更方便的使用 TCP/IP 协议栈而已,是对 TCP/IP 协议的抽象,从而形成了我们知道的最基本的函数接口,比如:create、listen 等,Socket 起源于 Unix, 而 Unix 是遵从『一切皆文件』的哲学,Socket 是基于一种:从打开、到读和写、再到关闭的这种模式去实现的。服务器和客户端各自维护一个文件,在建立连接打开后,可以向自己文件写入内容,供对方读取,或者读取对方的内容。
在通信结束时,就会关闭文件。
2、Socket 通信流程
前面说过,Socket 是基于:从打开、到读和写、再到关闭的这种模式去实现的,这里以使用 TCP 协议通信的 Socket 为例,其通信流程如下:
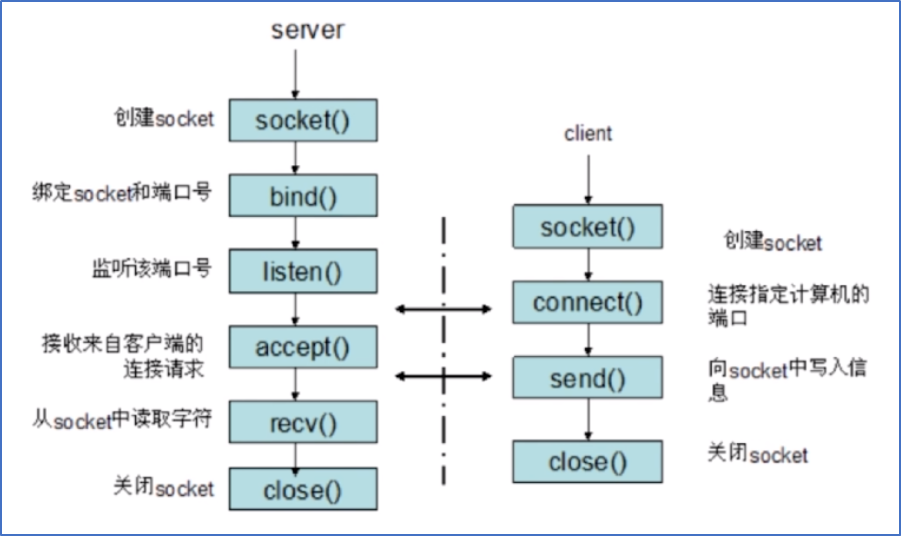
无论什么编程语言,Java 也好,C++ 也罢,使用 Socket 的流程,基本和上图是相同的。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号