数据库中数据表索引情况使用及分析
select distinct db_name(database_id) as N'数据库名称',
object_name(a.object_id) as N'表名',
b.name N'索引名称',
user_seeks N'用户索引查找次数',
user_scans N'用户索引扫描次数',
last_user_seek N'最后查找时间',
last_user_scan N'最后扫描时间',
rows as N'表中的行数'
from sys.dm_db_index_usage_stats a join
sys.indexes b
on a.index_id = b.index_id
and a.object_id = b.object_id
join sysindexes c
on c.id = b.object_id
where database_id=db_id('数据表所属数据库名') ---改成要查看的数据库
and object_name(a.object_id) = '要进行分析的表名'
order by user_seeks desc
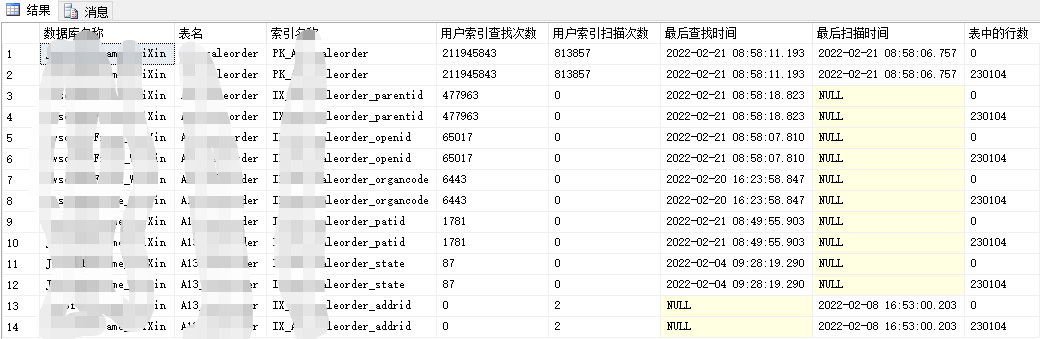
上面语句可以查看数据库的索引的使用情况。方便我们分析表的索引建立是否合理,表的索引命中次数等等。
- user_seeks :指出访问数据的过程中B树结构被使用了多少次。无论B-树结构是被用来从各层级上读取几个页面进而只获取一个数据行,还是近乎一半的索引页被读取进而从基础表中读取几G的数据。所以你可以期望所有对应索引的查找都落在这个类别里。
- user_scans :指出在数据层不使用B-树结构去获取数据时对表的访问次数。对于未定义任何索引的表,就可能是这种scan的情况。对于表上已经定义了索引的情况,如果查询未使用创建在表上的任何索引,scan也会发生。
- Lookup:它表示因非聚集索引指针指向聚集索引而引起的聚集索引对数据的查找。这个场景在SQL Server2000及更在版本中被称书签查找(Bookmark lookup)。它呈现了这样一种场景:一个非聚集索引被用来去访问某个表,并且这个非聚集索引并没有涵盖select查询中的所有列,并且这个列被定义在了where谓词中。SQL Server会为非聚集索引增加user_seeks这个列中的值并加上作为聚集索引入口的user_lookups列中的值。如果表上定义了很多的非聚集索引,这个和值会变得很高。如果用户在表的某一个索引上seek的次数很高,那么用户lookups的次数也会很高,并且如果用户对某一个非聚集索引的访问次数也很高,你就应该考虑让非聚集索引帮助解决聚集索引高数量使用的问题。
在开发、测试环境中,可以单独执行某个语句,通过查看user_seeks 的变化得知该语句命中了哪些索引

 浙公网安备 33010602011771号
浙公网安备 33010602011771号