Tensorflow学习笔记No.11
图像定位
图像定位是指在图像中将我们需要识别的部分使用定位框进行定位标记,本次主要讲述如何使用tensorflow2.0实现简单的图像定位任务。
我所使用的定位方法是训练神经网络使它输出定位框的四个顶点的坐标,通过这四个坐标来定位需要识别对象的位置。
数据集:https://pan.baidu.com/s/1dv-r19KixYhA1CfX2n06Hg 提取码:2kbc (数据集中的压缩文件需要解压)
1.数据读入
1.1图片读入
图片的读入在前面的博客中已经展示过很多次了,这里不再赘述,详情可以参考Tensorflow学习笔记No.5,里面详细介绍了读取图片的过程。
图像定位数据集的标签与之前的分类任务不同,是一个xml文件,我们需要使用爬虫从文件中爬取需要的信息。
导入需要的库
1 import tensorflow as tf 2 import numpy as np 3 import matplotlib.pyplot as plt 4 from lxml import etree 5 import glob 6 %matplotlib inline 7 import pathlib 8 from matplotlib.patches import Rectangle
首先设置路径
1 image_root = pathlib.Path("E:/BaiduNetdiskDownload/图片定位与分割数据集/images") 2 label_root = pathlib.Path('E:/BaiduNetdiskDownload/图片定位与分割数据集/annotations/xmls')
通过.glob()方法获得所有的图片和标签路径,并转换为字符串的形式。
1 all_image_path = list(image_root.glob('*.jpg')) 2 all_label_path = list(label_root.glob('*.xml')) 3 4 all_image_path = [str(p) for p in all_image_path] 5 all_label_path = [str(p) for p in all_label_path]
然后简单展示一下我们的数据集是什么样子的,同时简单讲解一下如何使用爬虫爬取需要的信息。
随便找一找图片作为例子。
1 path = all_image_path[0] 2 path_ = all_label_path[0] 3 4 #path E:\\BaiduNetdiskDownload\\图片定位与分割数据集\\images\\Abyssinian_1.jpg 5 #path_ E:\\BaiduNetdiskDownload\\图片定位与分割数据集\\annotations\\xmls\\Abyssinian_1.xml
首先解码并输出这张图片(我使用的是jypyter notebook进行可视化)
1 img = tf.io.read_file(path) 2 img = tf.image.decode_jpeg(img) 3 plt.imshow(img)
得到如下图片:

1.2xml文件解析与数据爬取
我们本次的图像定位任务是定位动物的头部,也就是说我们得到的输出结果是把动物的头部框起来。
接下来对xml文件进行解析,文件内容如下:
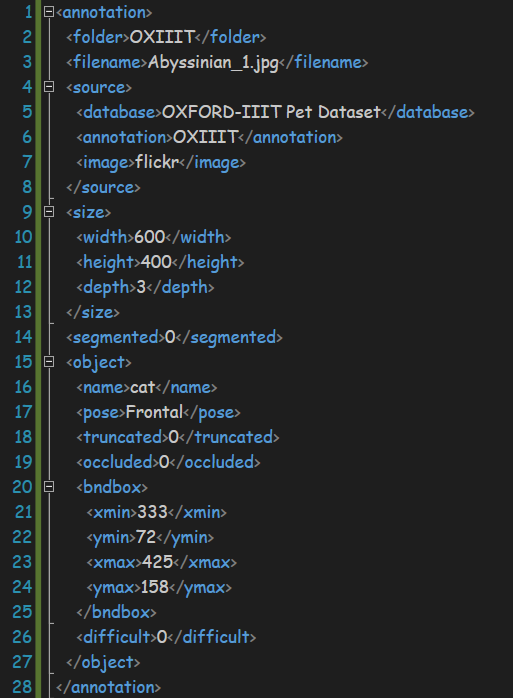
文件中是非常整齐的xml格式
<name>和</name>就相当于一对括号把其中的内容括起来,里面的内容就属于这个标签之下。例如上图中的annotation就是最大的标签,里面包含了folder、source等标签(有点类似电脑里的文件夹?)。
我们可以使用爬虫来访问这种整齐格式之中的内容
首先使用python自带的open方法打开这个xml文件
1 xml = open(path_).read()
然后创建一个选择器来对内容进行访问
1 sel = etree.HTML(xml)
sel.xpath()方法可以访问xml文件中某个目录下的内容,我们用这个方法获得其中的文本信息。
例如,我们可以获得长宽信息,width和height位于size标签下,用text()访问其中的文本内容,内容会以字符串列表的形式返回。
由于只有一个长宽信息,我们直接取列表的首位元素转换成int类型即可。
1 width = int(sel.xpath('//size/width/text()')[0]) 2 height = int(sel.xpath('//size/height/text()')[0])
同样的我们获取其他需要的信息。
1 xmin = int(sel.xpath('//bndbox/xmin/text()')[0]) 2 ymin = int(sel.xpath('//bndbox/ymin/text()')[0]) 3 xmax = int(sel.xpath('//bndbox/xmax/text()')[0]) 4 ymax = int(sel.xpath('//bndbox/ymax/text()')[0])
事实上我们只需要知道左上和右下的顶点坐标即可确定一个矩形框,xmin,ymin代表左上角的坐标,xmax,ymax代表右上角的坐标。
我们把这个框展示在图片中看一下效果
1 plt.imshow(img) 2 rect = Rectangle((xmin, ymin), (xmax - xmin), (ymax - ymin), fill = False, color = 'blue') 3 pimg = plt.gca() 4 pimg.axes.add_patch(rect)
得到如下所示图片:

可以看到猫猫的头部被框起来了(爱猫人士表示强烈谴责),这就是我们最终想要得到的效果。我们希望神经网络能够识别出动物的头像并把它框出来。
事实上我们的图片大小各不相同,但神经网络的输入尺寸是固定的,所有我们要把图片和lable坐标转换到同一尺度上,即224×224。
方法如下,同时输出效果图:
1 img = tf.image.resize(img, (256, 256)) 2 img = img / 255 3 plt.imshow(img) 4 5 xmin = xmin / width * 256 6 xmax = xmax / width * 256 7 ymin = ymin / height * 256 8 ymax = ymax / height * 256 9 10 plt.imshow(img) 11 rect = Rectangle((xmin, ymin), (xmax - xmin), (ymax - ymin), fill = False, color = 'blue') 12 pimg = plt.gca() 13 pimg.axes.add_patch(rect)


1.3数据集构建
我们的数据集中并非每一张图片都有对应的xml文件,所以我们只用有label的数据作为训练集和验证集。(共3686张可训练数据)
首先我们把标签的文件名从路径中分割出来,图片与标签名称一致,通过这种方式来筛选出我们需要的图片。
1 names = [x.split('\\')[-1].split('.xml')[0] for x in all_label_path] 2 train_image = [i for i in all_image_path if i.split('\\')[-1].split('.jpg')[0] in names] 3 train_image.sort(key=lambda x: x.split('\\')[-1].split('.jpg')[0]) 4 all_label_path.sort(key=lambda x: x.split('\\')[-1].split('.xml')[0])
通过排序可以保证label和图片一一对应
然后我们将之前爬取并处理数据尺寸的方法写成函数
1 def to_label(path): 2 xml = open(r'{}'.format(path)).read() 3 sel = etree.HTML(xml) 4 width = int(sel.xpath('//size/width/text()')[0]) 5 height = int(sel.xpath('//size/height/text()')[0]) 6 xmin = int(sel.xpath('//bndbox/xmin/text()')[0]) 7 ymin = int(sel.xpath('//bndbox/ymin/text()')[0]) 8 xmax = int(sel.xpath('//bndbox/xmax/text()')[0]) 9 ymax = int(sel.xpath('//bndbox/ymax/text()')[0]) 10 return [xmin / width, ymin / height, xmax / width, ymax / height]
我们用这个函数来处理数据的标签部分,同时分为四部分,对应了两个顶点的xy坐标,也就是神经网络的四个输出。
1 labels = [to_label(p) for p in all_label_path] 2 out1, out2, out3, out4 = list(zip(*labels))
下面进行乱序处理(这一步非常重要,否则模型训练的效果非常差,我一开始训练的时候拟合效果差就是因为没乱序。。。嘤嘤嘤ε(┬┬﹏┬┬)3)
1 index = np.random.permutation(len(train_image)) 2 images = np.array(train_image)[index] 3 4 out1 = np.array(out1)[index] 5 out2 = np.array(out2)[index] 6 out3 = np.array(out3)[index] 7 out4 = np.array(out4)[index]
使用index列表来保证乱序后图片和标签依然一一对应。
然后将其封装为dataset类型的数据
1 label_data = tf.data.Dataset.from_tensor_slices((out1, out2, out3, out4))
下面就是对图片的尺寸变换和封装处理了
1 def load_image(path): 2 img = tf.io.read_file(path) 3 img = tf.image.decode_jpeg(img, channels = 3) 4 img = tf.image.resize(img, (224, 224)) 5 img = tf.cast(img, tf.float32) 6 img = img / 127.5 - 1 7 return img 8 9 image_data = tf.data.Dataset.from_tensor_slices(images) 10 image_data = image_data.map(load_image)
完成后再将image_data和label_data合并成为一个dataset,然后分成训练集和验证集。
1 dataset = tf.data.Dataset.zip((image_data, label_data)) 2 3 image_count = len(train_image) 4 train_count = int(image_count * 0.8) 5 test_count = image_count - train_count 6 train_dataset = dataset.take(train_count) 7 test_dataset = dataset.skip(train_count) 8 9 BATCH_SIZE = 8 10 STEPS_PER_EPOCH = train_count // BATCH_SIZE 11 VALIDATION_STEPS = test_count // BATCH_SIZE 12 13 train_dataset = train_dataset.shuffle(train_count).repeat().batch(BATCH_SIZE) 14 train_dataset = train_dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE) 15 test_dataset = test_dataset.batch(BATCH_SIZE)
数据集构建完毕,下一步就是模型的构建。
2.模型构建与训练
不难发现这次的任务依然需要多输出模型来完成。我们选用预训练的Xception-Net的卷积部分作为卷积基来构建多输出模型。
迁移学习请参考Tensorflow学习笔记No.8,多输出模型请参考Tensorflow学习笔记No.10
模型如下:
1 xception = tf.keras.applications.Xception(weights='imagenet', 2 include_top=False, 3 input_shape=(224, 224, 3)) 4 5 xception.trianable = False 6 7 inputs = tf.keras.layers.Input(shape=(224, 224, 3)) 8 9 x = xception(inputs) 10 11 x = tf.keras.layers.GlobalAveragePooling2D()(x) 12 13 x = tf.keras.layers.Dense(2048, activation='relu')(x) 14 x = tf.keras.layers.Dense(256, activation='relu')(x) 15 16 out1 = tf.keras.layers.Dense(1)(x) 17 out2 = tf.keras.layers.Dense(1)(x) 18 out3 = tf.keras.layers.Dense(1)(x) 19 out4 = tf.keras.layers.Dense(1)(x) 20 21 predictions = [out1, out2, out3, out4] 22 23 model = tf.keras.models.Model(inputs=inputs, outputs=predictions)
由于输出的是坐标,是一个大于0的数字,所以输出层可以直接去掉激活函数。
随后对模型进行训练,损失函数选择均方误差MSE
1 model.compile(optimizer = tf.keras.optimizers.Adam(lr = 0.0001), 2 loss = 'mse', 3 metrics = ['mae'] 4 ) 5 6 history = model.fit(train_dataset, 7 epochs=10, 8 steps_per_epoch=STEPS_PER_EPOCH, 9 validation_steps=VALIDATION_STEPS, 10 validation_data=test_dataset)
训练结果如图所示:
1 loss = history.history['loss'] 2 val_loss = history.history['val_loss'] 3 4 epochs = range(10) 5 6 plt.figure() 7 plt.plot(epochs, loss, 'r', label='Training loss') 8 plt.plot(epochs, val_loss, 'bo', label='Validation loss') 9 plt.title('Training and Validation Loss') 10 plt.xlabel('Epoch') 11 plt.ylabel('Loss Value') 12 plt.ylim([0, 0.15]) 13 plt.legend() 14 plt.show()

可以发现loss最初下降的很快然后逐渐减缓,最终的拟合效果也不错。
然后我们找一组图片试试模型效果。
1 plt.figure(figsize = (8, 8)) 2 for img, _ in test_dataset.skip(1).take(1): 3 out1, out2, out3, out4 = model.predict(img) 4 for i in range(0, 6): 5 plt.subplot(2, 3, i + 1) 6 plt.imshow(tf.keras.preprocessing.image.array_to_img(img[i])) 7 xmin, ymin, xmax, ymax = out1[i] * 224, out2[i] * 224, out3[i] * 224, out4[i] * 224, 8 rect = Rectangle((xmin, ymin), (xmax - xmin), (ymax - ymin), fill = False, color = 'red') 9 ax = plt.gca() 10 ax.axes.add_patch(rect)

效果还不错,嘿嘿ヾ(≧▽≦*)o
本次对图像定位的介绍到这里就结束了,Bey~ o(* ̄▽ ̄*)ブ

 浙公网安备 33010602011771号
浙公网安备 33010602011771号