Tensorflow学习笔记No.10
多输出模型
使用函数式API构建多输出模型完成多标签分类任务。
数据集下载链接:https://pan.baidu.com/s/1JtKt7KCR2lEqAirjIXzvgg 提取码:2kbc
1.读取数据并构建数据集
详细的API介绍在Tensorflow学习笔记5.0中均有提及,这里只简单讲述方法流程并展示代码。
1.1图片数据读取
首先导入需要的模块(运行环境为jupyternotebook)。
1 import tensorflow as tf 2 import numpy as np 3 import pathlib 4 import matplotlib.pyplot as plt 5 import random 6 %matplotlib inline
创建地址为数据所在位置的根目录,所创建的data_root为一个WindowsPath类型的变量。。
1 data_dir = 'E:/BaiduNetdiskDownload/多输出模型数据集(同时预测物品和颜色)/multi-output-classification/dataset' 2 data_root = pathlib.Path(data_dir)
读取该目录下所有的jpg/jpeg文件,图片存储位置为dataset/(标签文件夹)/*,所以使用.glob('*/*')来获取所有的图片文件。
1 all_image_path = list(data_root.glob('*/*')) 2 image_count = len(all_image_path) #共计2525张图片
1.2标签读取
在读取完图片之后,我们还要读取图片对应的标签信息。
我们所进行的是一个衣服分类任务,每件衣服都有颜色和类型两个标签,我们需要提取出每张图片对应的标签。
图片存储在名字为“颜色_类型”的文件夹下,对应了这些图片的颜色和类型,所以我们对文件夹名字进行处理即可。
首先我们获取所有含有标签信息的文件夹名称。
1 label_names = sorted(item.name for item in data_root.glob('*') if item.is_dir())
label_names中包含了所有的标签名称——['black_jeans', 'black_shoes', 'blue_dress', 'blue_jeans', 'blue_shirt', 'red_dress', 'red_shirt']。总共七种类别,为三种颜色类别和四种衣服类型的组合。
下一步奖颜色和类型标签分别提取出来,使用.split('_')对字符串进行分割,得到每个复合标签对应的两个基本标签。
1 color_label = set(name.split('_')[0] for name in label_names) 2 item_label = set(name.split('_')[1] for name in label_names)
然后我们通过这两个存有标签的集合构建从标签字符串映射到数字编号的字典。
1 color_to_indx = dict((name, indx) for indx, name in enumerate(color_label)) 2 item_to_indx = dict((name, indx) for indx, name in enumerate(item_label))
现在我们仅仅是获得了字典,而没有获得与图片对应的基本标签,下一步我们着手制作这些标签,一个图片应该对应两个标签。
首先获取每个图片与之对应的复合类别标签(颜色_类型标签)。
使用.parent.name方法获得WindowsPath对象的父文件夹名字,即图片的标签。
1 all_image_label = list(pathlib.Path(path).parent.name for path in all_image_path)
然后通过两个字典构建出每个图片的两个数字标签。
1 color_label = list(color_to_indx[label.split('_')[0]] for label in all_image_label) 2 item_label = list(item_to_indx[label.split('_')[1]] for label in all_image_label)
1.3数据集的构建
在获取完标签和图像地址后,我们利用这些信息来制作一个标准的数据集。
首先定义一个图像处理函数,用于读取并解码图像,同时归一化为统一的尺寸。
1 def load_pregrosess_image(path): 2 image = tf.io.read_file(path) 3 image = tf.image.decode_jpeg(image, channels = 3) 4 image = tf.image.resize(image, [224, 224]) 5 image = tf.cast(image, tf.float32) 6 image = image / 255 7 #image = image * 2 - 1 8 return image
使用tf.data中提供的方法对图片地址进行切片操作,变成一个dateset类型的数据,然后使用.map方法利用刚刚定义的函数将地址处理为图像。
1 train_image_ds = tf.data.Dataset.from_tensor_slices(all_image_path) 2 image_data = train_image_ds.map(load_pregrosess_image)
同样的把两个标签也切片封装为dataset类型的文件,最后再把图片和标签合并变成完整的数据集。
1 label_data = tf.data.Dataset.from_tensor_slices((color_label, item_label)) 2 dataset = tf.data.Dataset.zip((image_data, label_data))
随后按照8:2分为训练集和验证集即可。
1 BATCHSIZE = 8 2 train_count = int(image_count * 0.8) 3 test_count = image_count - train_count 4 5 train_dataset = dataset.take(train_count) 6 test_dataset = dataset.skip(train_count) 7 8 train_dataset = train_dataset.shuffle(train_count).repeat().batch(BATCHSIZE) 9 test_dataset = test_dataset.repeat().batch(BATCHSIZE)
至此数据集构建完毕,下一步将搭建模型并进行训练。
2.多输出模型
由于我们要预测图片的两个属性,颜色和衣服类型,同样的我们也需要两个输出,然而线性模型显然无法满足我们的需求。所以我们使用函数式API构建非线性模型来完成目标。
2.1构建模型
我们的模型结构为一个卷积神经网络和两个分类器,如图所示。(3D画图随手一画很丑见谅(。﹏。*))
由卷积神经网络提取特征,然后通过两个分类器输出图片在两个不同标签上的分类结果。
我们采用预训练的Mobile-Net作为卷积部分并冻结其可训练参数,使用函数式API搭建模型,注意这里有两个输出层,在keras.Model方法中用列表形式作为输入,同时给两个输出层添加name参数进行命名便于区分和后续调用。
函数式API在Tensorflow学习笔记No.2中有详细介绍这里也不再做赘述,预训练网络的使用在Tensorflow学习笔记No.8中有相关介绍。
1 input = tf.keras.Input(shape = (224, 224, 3)) 2 3 mobile_net = tf.keras.applications.MobileNetV2(weights = 'imagenet', input_shape = (224, 224, 3), include_top = False) 4 mobile_net.trianable = False 5 6 x = mobile_net(input) 7 x = tf.keras.layers.GlobalAveragePooling2D()(x) 8 x1 = tf.keras.layers.Dense(1024, activation = 'relu')(x) 9 x2 = tf.keras.layers.Dense(1024, activation = 'relu')(x) 10 output_color = tf.keras.layers.Dense(3, activation = 'softmax', name = 'output_color')(x1) 11 output_item = tf.keras.layers.Dense(4, activation = 'softmax', name = 'output_item')(x2) 12 13 model = tf.keras.Model(inputs = input, outputs = [output_color, output_item])
将全连接层和softmax组合在一起作为分类器,按照上图所示方式进行连接即可。
得到的模型如下图所示,使用model.summary()进行查看:

2.2模型训练
不熟悉model.complie()和model.fit()方法的小伙伴可以翻看Tensorflow学习笔记No.1进行学习这里也不在赘述(主要是因为懒)。
注意,因为有两个分类器,所以对每个分类器要单独规定一个损失函数,使用字典的方式按照{输出层名称:损失函数,......}的格式指定分类器,前面对卷积命名也是方便此步骤的进行。
steps_per_epoch和validation_steps代表了训练集和验证集每一个epoch需要训练多少步,也就是数据总数/BATCH_SIZE。
注意学习率设置为0.0001等较小的学习率,使用较大的学习率会导致loss异常增大。
1 model.compile(optimizer = tf.keras.optimizers.Adam(learning_rate=0.0001), 2 loss = {'output_color':'sparse_categorical_crossentropy', 3 'output_item':'sparse_categorical_crossentropy'}, 4 metrics = ['acc'] 5 ) 6 7 history = model.fit(train_dataset, 8 steps_per_epoch = train_count//BATCHSIZE, 9 epochs = 5, 10 validation_data = test_dataset, 11 validation_steps = test_count//BATCHSIZE, 12 )
由于使用了预训练模型,只需要5个epochs便可以达到90%以上的准确率,得到如下所示结果(仅供参考)。
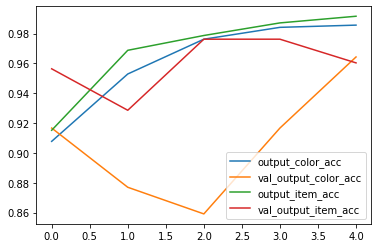
到这里多输出模型的实例就结束了,前段时间由于事情较多断更了一段时间,后续会继续更新Tensorflow的学习笔记。由于本人正在参加AI算法竞赛(入门菜鸡),后续可能会分享一些与竞赛有关的内容,撒悠娜拉 Bey~ o(* ̄▽ ̄*)ブ。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号