Tensorflow学习笔记No.5
tf.data卷积神经网络综合应用实例
使用tf.data建立自己的数据集,并使用CNN卷积神经网络实现对卫星图像的二分类问题。
数据下载链接:https://pan.baidu.com/s/141zi1BvDU6rHsq5VKgRl4Q 提取码:2kbc
1.使用tf.data建立数据集
使用tf.data将已有的图片打上标签,并将数据分为训练集与测试集用于训练神经网络。
下面将逐步介绍如何建立数据集。
1.1读取windows下的文件路径
首先,头文件走一波(python中应该叫导入模块)
1 import tensorflow as tf 2 import numpy as np 3 import matplotlib.pyplot as plt 4 import pathlib 5 %matplotlib inline
注:我一直在使用jupyter notebook编写程序,展示的代码也是基于notebook,使用本文中提供的代码时也尽量使用notebook,不使用notebook的小伙伴请去掉第五行代码!(想了解notebook的小伙伴可以自行百度或者参考我以前的博客Tensorflow学习笔记No.0)
模块导入完成后,我们先定位到数据文件所在的目录,并将路径存入data_dir变量中。
1 data_dir = 'C:/Users/18083/Desktop/新建文件夹/opencv/卫星图像识别数据/2_class'
注意,路径要使用自己电脑上'2_class'文件所在的路径,并且路径分隔符要使用'/'而非'\'。
获取到文件的路径后我们使用pathlib.Path()方法,将data_dir从字符串变为一个WindowsPath类型的数据,便于后续的子目录读取操作。
1 data_root = pathlib.Path(data_dir)
这是在notebook中的执行结果,我们看到data_root已经是一个WindowPath类型的文件了。

我们可以使用以下代码来便利data_root目录下的所有子目录
1 for item in data_root.iterdir(): 2 print(item) 3 #遍历data_root目录下的所有子目录
运行结果如下:

我们可以看到'2_class'目录下所有的子目录,也就是我们即将要进行分类的两类图片的储存位置。
下面我们就着手获取我们所要进行分类的全部图片的路径。
对WindowPath对象使用.glob()方法来遍历目录下特定类型的文件或文件夹。
1 all_image_path = list(data_root.glob('*/*')) 2 #获取所有路径,'*/*'指所有子目录下的所有文件,并转换为list
我们创建一个all_image_path变量来存储所有的图片的路径。
对data_root使用.glob()方法,参数指定为'*/*',‘*'指代该目录下的全部文件,也就是'2_class'文件夹下的'airplane'文件夹和'lake'文件夹,'*/*'就指代了data_root目录的所有子目录中的所有文件,也就是我们要获取的图片文件。并使用list()将其转换为列表便于存储。
随后我们使用列表推导式将其转换为字符串,让它可以作为路径参数从而进行读取文件内容,即图片的数据。
1 all_image_path = [str(path) for path in all_image_path] 2 #使用列表推导式将windowpath转换成字符串
1.2对图像数据使用label进行类别标记
首先导入random模块,对路径进行乱序便于后面将数据分割为训练集和测试集。
乱序是为了防止数据之间产生强依赖关系而影响训练结果。
1 import random 2 random.shuffle(all_image_path) 3 #对数据进行乱序处理 4 image_count = len(all_image_path) 5 #图像总数 6 image_count
对数据进行乱序处理并获得图像总数。
然后我们从子目录中获得标签名。
1 label_name = sorted([item.name for item in data_root.glob('*/')]) 2 #从子目录中提取标签名
使用列表推导式将data_root下的所有子目录名字存入列表中,并按照字典序排序。
结果如下:

这样我们便获得了两个类别的名称,也就是存储图片的文件夹的名字。
然后我们使用这个列表构建一个字典,将名字映射为分类的类别编号0,1便于神经网络的分类器进行分类。
1 label_to_indx = dict((name, indx) for indx, name in enumerate(label_name)) 2 #enumerate()返回列表的下标和内容 3 #将label编号 并转为字典型
得到一个字典:
下一步,我们使用这个字典和之前得到的路径,将所有的图片分类,编号0或1。
1 all_image_label = [label_to_indx[pathlib.Path(p).parent.name] for p in all_image_path] 2 #从all_iamge_path中读取路径字符串,转换为windowpath对象 3 #调用.parent.name方法获得父亲目录的名字,并用字典映射为对应编号
我们使用path.Path()方法将路径字符串p转换成一个可执行对象,并调用.parent.name方法来获得它的父目录的名字,并使用刚刚建立的字典对其进行编号。
随机取三张图片验证一下all_image_label标签的正确性:
1 import IPython.display as display
导入模块用于通过路径显示图片。
1 for n in range(3):#随机取三张图片 2 image_indx = random.choice(range(image_count)) 3 #从所有图片中随机选择一个编号 4 display.display(display.Image(all_image_path[image_indx])) 5 #通过路径播放图片 6 print(indx_to_label[all_image_label[image_indx]]) 7 #path和label一一对应,所以可以获得图片的l 通过字典获得图片名 8 print()
结果如下:



标签与图片一致
1.3读取图片数据并创建数据集
经过了前面许许多多复杂步骤的铺垫,我们终于到了读取数据并创建数据集的时刻!
我们先对单一的图片进行读取~
随便找个图片试试水!
1 img_path = all_image_path[0]
通过tf.io.read_file()读取图片数据
1 img_raw = tf.io.read_file(img_path) 2 #读取图片
注意,此时得到的img_raw是图片的16进制编码,而不是我们平时所使用的RGB三通道uint8编码,所以要进行解码。使用tf.image.decode_image_jpeg()进行解码,tf.image中提供了针对不同类型图片的多种解码方式,根据需要自行选择。
1 img_tensor = tf.image.decode_image(img_raw, channels = 3) 2 #解码转换成tensor array
由于我们要将0~255的色彩空间映射到0~1的浮点数,所以要将数据从uint8类型转换为float32。
1 img_tensor = tf.cast(img_tensor, tf.float32) 2 #转换数据类型 3 img_tensor = img_tensor / 255 4 #标准化
这样我们就处理好了一张图片。。。
但。。。我们有整整1400张图片。。。
不可能这样一张张的处理下去,所以我们写个函数来执行这一操作。
1 def load_preprosess_image(path): 2 img_raw = tf.io.read_file(path) 3 img_tensor = tf.image.decode_jpeg(img_raw, channels = 3) 4 img_tensor = tf.image.resize(img_tensor, [256, 256]) 5 #resize_with_crop_or_pad填充与裁剪 6 img_tensor = tf.cast(img_tensor, tf.float32) 7 img = img_tensor / 255 8 return img 9 #加载和预处理图片
随后,我们使用tf.data.Dataset中的.from_tensor_slices()方法,将all_image_path进行切片,变成一个dateset类型的数据,并使用函数和map()将路径一一映射为处理好的图片数据。
1 path_ds = tf.data.Dataset.from_tensor_slices(all_image_path) 2 image_dataset = path_ds.map(load_preprosess_image)
此时,all_image_path与all_image_label仍是一一对应的,所以我们对label也进行切片操作转换成dataset类型的数据,并用tf.data.Dataset.zip()方法将其合并成为完整的数据集!(天哪~~!终于建好了!!)
1 label_dataset = tf.data.Dataset.from_tensor_slices(all_image_label) 2 dataset = tf.data.Dataset.zip((image_dataset, label_dataset))
(右侧进度条告诉你事情没有这么简单~)
数据集虽然建好了,但是。。。
还要数据集还要分为训练集和测试集,还要分别对数据进行一些处理。。。
我们首先按照4:1的比例将数据分为训练集和测试集。
1 test_count = int(image_count * 0.2) #280张 2 train_count = image_count - test_count #1120张
分配训练集和测试集的图片数量,然后对数据集进行分割。
使用.skip()获得后280张作为测试集
使用.take()获得前1120张作为训练集
1 train_dataset = dataset.skip(test_count) 2 test_dataset = dataset.take(test_count)
设置一个batch_size神经网络防止一次读取的图片过度导致内存爆炸,这一点非常重要哦。
1 BATCH_SIZE = 32
对训练集进行乱序和重复处理,并按照BATCH_SIZE分配好数据。
对测试集分配好BATCH_SIZE即可。
1 train_dataset = train_dataset.shuffle(train_count).repeat().batch(BATCH_SIZE) 2 test_dataset = test_dataset.batch(BATCH_SIZE)
到这里,我们就使用tf.data创建了一个自定义的数据集,并且随时可以放到神经网络中进行训练了!(完结撒花*★,°*:.☆( ̄▽ ̄)/$:*.°★*),撒个鬼,还没训练呢 !
2.使用CNN模型进行预测
上一篇博客中已经讲过了如何构建CNN模型并介绍了需要用到的API,这里不再赘述,不了解的小伙伴可以看看上一篇博客(Tensorflow学习笔记No.4.2)
这里直接上代码!网络模型如下:
大致结构为:每两层卷积设置一层池化层,最后加入全连接层以及分类器进行分类。
1 model = tf.keras.Sequential() 2 model.add(tf.keras.layers.Conv2D(64, (3, 3), input_shape = (256, 256, 3), activation = 'relu')) 3 model.add(tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu')) 4 model.add(tf.keras.layers.MaxPooling2D()) 5 model.add(tf.keras.layers.Conv2D(128, (3, 3), activation = 'relu')) 6 model.add(tf.keras.layers.Conv2D(128, (3, 3), activation = 'relu')) 7 model.add(tf.keras.layers.MaxPooling2D()) 8 model.add(tf.keras.layers.Conv2D(256, (3, 3), activation = 'relu')) 9 model.add(tf.keras.layers.Conv2D(256, (3, 3), activation = 'relu')) 10 model.add(tf.keras.layers.MaxPooling2D()) 11 model.add(tf.keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 12 model.add(tf.keras.layers.MaxPooling2D()) 13 model.add(tf.keras.layers.Conv2D(512, (3, 3), activation = 'relu')) 14 model.add(tf.keras.layers.MaxPooling2D()) 15 model.add(tf.keras.layers.Conv2D(1024, (3, 3), activation = 'relu')) 16 model.add(tf.keras.layers.GlobalAveragePooling2D()) 17 model.add(tf.keras.layers.Dense(1024, activation = 'relu')) 18 model.add(tf.keras.layers.Dense(256, activation = 'relu')) 19 model.add(tf.keras.layers.Dense(1, activation = 'sigmoid'))
模型详细参数如下: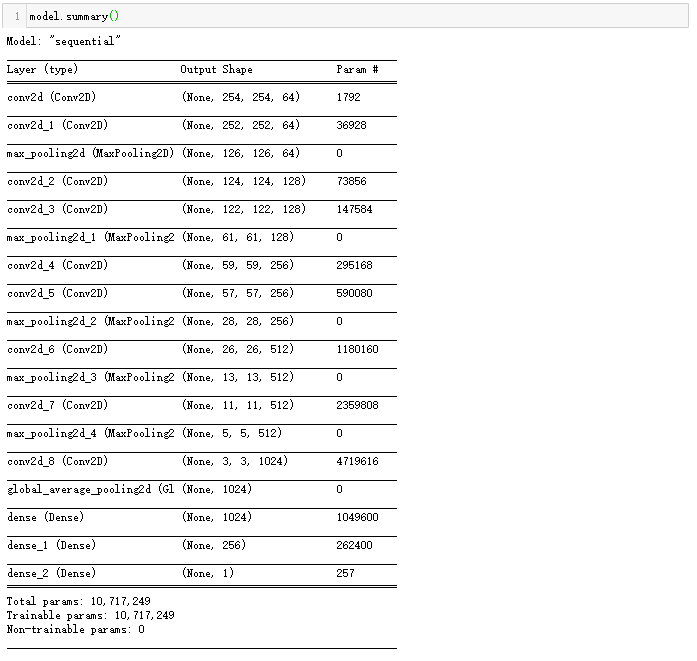
虽然模型相对复杂,但是我们的数据量很少,使用GPU训练起来还是不慢的。
设置好训练方式,然后开始训练!
1 model.compile(optimizer = 'adam', 2 loss = 'binary_crossentropy', 3 metrics = ['acc'] 4 ) 5 6 steps = train_count // BATCH_SIZE 7 valid_steps = test_count // BATCH_SIZE 8 9 history = model.fit(train_dataset, epochs = 30, 10 steps_per_epoch = steps, 11 validation_data = test_dataset, 12 validation_steps = valid_steps 13 )
这里的steps以及valid_steps对应了BATCH_SIZE,也是为了防止数据和内存溢出而加入的限制手段。
训练部分过程如下:

可以看出模型的拟合效果还是非常不错的,在训练过程中测试集上的正确率一度达到过98%。
绘制出训练过程的图像:
1 plt.plot(history.epoch, history.history.get('acc'), label = 'acc') 2 plt.plot(history.epoch, history.history.get('val_acc'), label = 'val_acc') 3 plt.legend()
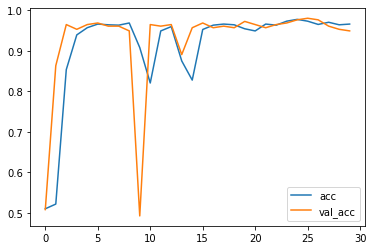
使用.evaluate()方法验证一下模型准确率。
1 model.evaluate(test_dataset)

在测试集上的准确率也达到了不错的95%
最后我们随便从数据集中随便找几张图片预测一下~
这里我用了测试集中的前三张
1 for i in list(model.predict(test_dataset))[:3]: 2 if i < 0.5: 3 print('airplane') 4 else : 5 print('lake')
运行结果:
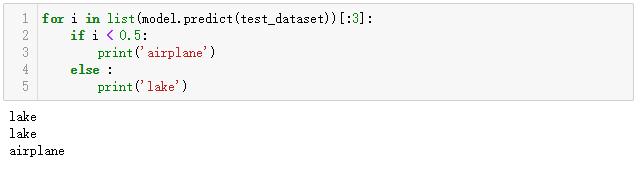
把这三张图片放出来看看~ 看一下预测的是否正确~
1 test_img = list(test_dataset)[:1] 2 i, j = test_img[0] 3 plt.imshow(i[0])

1 plt.imshow(i[1])

1 plt.imshow(i[2])

与预测结果一致!
这次我们的模型预测的很成功!
Tensorflow tf.data与卷积神经网络综合实例到这里就结束了~
完结撒花~!o(* ̄▽ ̄*)ブ❀❀❀

 浙公网安备 33010602011771号
浙公网安备 33010602011771号