Tensorflow学习笔记No.4.2
使用CNN卷积神经网络(2)
使用Tensorflow搭建简单的CNN卷积神经网络对fashion_mnist数据集进行分类
不了解是那么是CNN卷积神经网络的小伙伴可以参考上一篇博客(Tensorflow学习笔记No.4.1)
2.Tensorflow卷积神经网络相关API简介
2.1.keras.layers.Conv2D()二维卷积层
例如:
model.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu', padding = 'same')
向model中添加一个二维卷积层,第一个参数是filter,也就是卷积核的个数,决定了这层卷积层输出的数据有多少个通道。第二个参数是卷积核的大小,这里使用的是3×3的卷积核。activation是激活函数,不再赘述。
padding则是卷积层的填充模式。简单来说,设卷积核的尺寸为k×k,输入数据的尺寸为size×size,若填充模式为‘same’,则卷积层输出的尺寸与输入时相同,为size×size,若为默认模式‘valid’,则输出的尺寸为(size-(k-1))×(size-(k-1))。
strides参数(示例中没有出现),它是卷积核每次移动的跨度,默认为(1, 1),分别是在x和y轴上移动的跨度,若调整为(2, 2)则卷积层的输出尺寸会将变为原来的1/2,即(size/2)×(size/2),同理,若为(k, k)则输出尺寸变为(size/k)×(size/k),使用这个参数会严重减少输出信息,虽然能明显减少网络容量,但是容易造成关键特征的丢失,慎重使用!
2.2.keras.layers.MaxPool2D()二维卷积的池化层
例如:
1 model.add(keras.layers.MaxPool2D()) 2 model.add(keras.layers.AveragePooling2D()) 3 model.add(keras.layers.GlobalAveragePooling2D())
向model中添加二维池化层。
池化层默认尺寸pool_size参数为2×2,会把数据的尺寸缩小至原来的1/2,并且不改变深度。
示例中的三种池化层分别为最大值池化,均值池化与全局均值池化。
最大值池化,选择pool_size×pool_size范围内的最大值作为当前位置的值,每次移动pool_size个单位,若size无法被整除则自动填充。均值池化同理,计算范围内的均值作为当前位置的值。全局池化有所不同,它是将全部数据进行池化压缩,将数据的尺寸size×size缩小为1×1,不改变深度,通常放在全连接层之前。
3.使用Tensorflow搭建简单的卷积神经网络模型
使用tensorflow建立一个简单的CNN网络模型,对fashion_mnist数据集进行分类,是一个较为简单的10分类问题。
首先导入需要用到的模块
1 from tensorflow import keras 2 import matplotlib.pyplot as plt 3 import numpy as np 4 import pandas as pd
3.1加载并处理数据
加载fashion_mnist数据集,并分为训练集和测试集。
fashion_mnist = keras.datasets.fashion_mnist
(train_image, train_label), (test_image, test_label) = fashion_mnist.load_data()
此时的train_image与test_image的尺寸分别为(6000, 28, 28), (1000, 28, 28),分别对应图片数,图片的长和宽。
但是卷积神经网络的输入时图片,图片应该有三个维度,长宽以及通道数(channel),fashion_mnist数据集中均为灰度图像,所以只有一个通道,我们给测试集和训练集分别加上这一维度以便作为神经网络的输入。
1 train_image = np.expand_dims(train_image, -1) 2 test_image = np.expand_dims(test_image, -1)
这里使用了numpy的.expand_dims()方法扩展了数据集的通道,数据尺寸的最后方加入了一个维度。
现在数据的尺寸变为(num, 28, 28, 1),即num个28×28的单通道灰度图像。
3.2建立网络模型
使用keras.Sequential()方法建立一个Sequential模型。
1 model = keras.Sequential()
首先向其中添加输入层,我们要尽量保留数据的特征,所以第一层就直接选用处理图像效果较好的Conv2D卷积层,尽可能的获取图像特征。
1 model.add(keras.layers.Conv2D(32, (3, 3), 2 input_shape = (28, 28, 1), 3 activation = 'relu', 4 padding = 'same' 5 ))
Conv2D()中的主要参数在2.1中均有提及,这里不再赘述。
input_shape参数与之前建立的Sequential模型类似,表示输入数据的尺寸,这里为28×28的单通道灰度图像,所以input_shape应该为(28, 28, 1)。
随后向网络中添加池化层,提取主要特征并缩小数据规模。
规模缩小到过程也是扩大感受野的过程,随着特征规模的缩小,单个卷积核单次所能覆盖的图像特征范围逐渐扩大,这是一个逐渐从提取局部特征转变为提取全局特征的过程。
1 model.add(keras.layers.MaxPool2D())
继续添加卷积层与池化层,最后添加全连接层输出分类结果,最终的模型为:
1 model = keras.Sequential() 2 model.add(keras.layers.Conv2D(32, (3, 3), 3 input_shape = (28, 28, 1), 4 activation = 'relu', 5 padding = 'same' 6 )) 7 #32个卷积核,每个卷积核大小为3*3,输入规格,激活函数,填充为使输出与原尺寸相同,默认(valid)为不填充 8 model.add(keras.layers.MaxPool2D()) 9 #默认为2*2池化层 10 model.add(keras.layers.Conv2D(64, (3, 3), activation = 'relu')) 11 model.add(keras.layers.GlobalAveragePooling2D()) 12 #全局平均池化 13 model.add(keras.layers.Dense(10, activation = 'softmax')) 14 #输出层,10分类
这样就搭建好了一个简单的卷积神经网络。
3.3使用.compile()方法与.fit()方法训练模型
这里与之前的训练方式相同,不熟悉的小伙伴可以翻翻之前的博客(Tensorflow学习笔记No.1)进行查看,代码如下:
1 model.compile(optimizer = 'adam', 2 loss = 'sparse_categorical_crossentropy', 3 metrics = ['acc'] 4 ) 5 6 history = model.fit(train_image, train_label, epochs = 30, validation_data = (test_image, test_label))
训练过程:

如果你使用的是notebook类的环境,训练完成后插入以下代码(Tensorflow学习笔记No.0中有相关介绍)即可查看训练的正确率图像:
1 %matplotlib inline 2 plt.plot(history.epoch, history.history.get('acc'), label = 'acc') 3 plt.plot(history.epoch, history.history.get('val_acc'), label = 'val_acc') 4 plt.legend()
图像如下图所示:
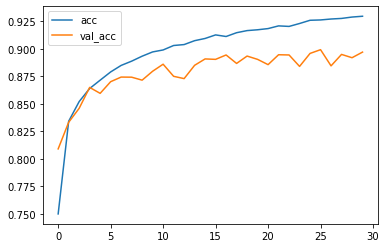
4.优化已有网络模型
以下内容是由本人经过多次试验和验证得到的:
从刚刚训练的网络模型的训练图像中可以看出:
训练集的正确率仅有92.5%,说明模型的拟合性不够;测试集与训练集正确率相差较大,说明在后续训练中可能出现过拟合问题。
(注:过拟合是指在训练集达到非常好的正确率而在测试集上的正确率并不理想,这里出现的情况是训练集和测试集上的正确率均不理想,所以不能称之为过拟合,但通过图像不难看出,我们的模型继续训练下去极有可能出现过拟合现象。)
所以我们的优化方式从这两个角度出发,首先,增加隐藏单元(卷积核)数量,加深模型深度,以增加模型的拟合度。然后,为了抑制可能出现的过拟合现象,在适当位置加入Dropout层抑制过拟合。
改进后的模型如下:
1 model_ = keras.Sequential() 2 model_.add(keras.layers.Conv2D(64, (3, 3), 3 input_shape = (28, 28, 1), 4 activation = 'relu', 5 padding = 'same' 6 )) 7 model_.add(keras.layers.Conv2D(64, (3, 3), activation = 'relu', padding = 'same')) 8 #添加两层Conv2D以提高拟合能力 9 model_.add(keras.layers.MaxPool2D()) 10 model_.add(keras.layers.Dropout(0.25)) 11 #添加Dropout抑制过拟合 12 model_.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu', padding = 'same')) 13 model_.add(keras.layers.Conv2D(128, (3, 3), activation = 'relu', padding = 'same')) 14 model_.add(keras.layers.MaxPool2D()) 15 model_.add(keras.layers.Dropout(0.25)) 16 model_.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu', padding = 'same')) 17 model_.add(keras.layers.Conv2D(256, (3, 3), activation = 'relu', padding = 'same')) 18 model_.add(keras.layers.Dropout(0.25)) 19 model_.add(keras.layers.GlobalAveragePooling2D()) 20 model_.add(keras.layers.Dense(256, activation = 'relu')) 21 #添加Dense层进行过渡 22 model_.add(keras.layers.Dense(10, activation = 'softmax'))
经过调整后的模型得到如下结果:
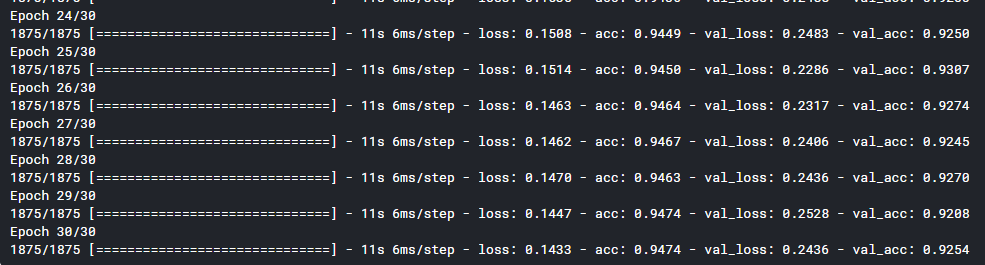
模型的正确率图像如下:
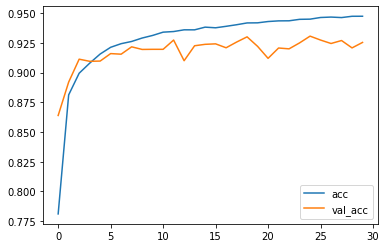
经过调整后的模型,拟合度有了较为明显的提高,在测试集上可以达到接近95%的正确率,在测试集上也能达到较为满意的效果,正确率约92.5%。
后续将会对模型进行改进,争取达到更高的准确率!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号