最小公共祖先lca
3、神秘国度的爱情故事 题目要求:某个太空神秘国度中有很多美丽的小村,从太空中可以想见,小村间有路相连,更精确一点说,任意两村之间有且仅有一条路径。小村 A 中有位年轻人爱上了自己村里的美丽姑娘。
每天早晨,姑娘都会去小村 B 里的面包房工作,傍晚 6 点回到家。年轻人终于决定要向姑娘表白,他打算在小村 C 等着姑娘路过的时候把爱慕说出来。问题是,他不能确定小村 C 是否在小村 B 到小村 A 之间的路径上。你可以帮他解决这个问题吗? 输入要求:输入由若干组测试数据组成。每组数据的第 1 行包含一正整数 N ( l 《 N 《 50000 ) ,
代表神秘国度中小村的个数,每个小村即从0到 N - l 编号。接下来有 N -1 行输入,每行包含一条双向道路的两个端点小村的编号,中间用空格分开。
之后一行包含一正整数 M ( l 《 M 《 500000 ) ,代表着该组测试问题的个数。接下来 M 行,每行给出 A 、 B 、 C 三个小村的编号,中间用空格分开。当 N 为 O 时,表示全部测试结束,不要对该数据做任何处理。 输出要求:对每一组测试给定的 A 、 B 、C,在一行里输出答案,即:如果 C 在 A 和 B 之间的路径上,输出 Yes ,否则输出 No。
这是我们一个期末的数据结构课设题。
虽然很简单但是我们老师要求还蛮多的,不准手动输入要求随机输入而且还有满足最大极限条件。最后一天下午才告诉这是拿优的必须条件。
然后肝了一晚上还要补完实验报告直接通宵。
主要用的是LCA(最近公共祖先)的概念:简单来说就是把村子的路径变成一棵树,然后算A村和C村的最小公共祖先是不是B村,如果不是,我们再看看B村是不是仅为A村或仅为C村的祖先,如果是则B村在A、C村的路径上,小伙子有救了,否则我们就说小伙子他已经凉了
关于LCA更具体的可以去这个博客看:https://www.cnblogs.com/JVxie/p/4854719.html
贴部分主要公式与备注:(运行TarjanDFS
前需要先执行ALG_DFSvisited[0] = true;)
int find(int x)
{
while (x != f[x])
{
x = f[x];
}
return x;
}
void unite(int u, int v)//合并集合
{
int x = find(u);
int y = find(v);
if (x != y)
f[x] = y;
}
//找最近公共祖先
void TarjanDFS(ALGraph &G_Full,ALGraph &G_Search, int root, int anc)
{
ArcNode *p = G_Full.vertices[root].firstarc;
while (p)
{
if (ALG_DFSvisited[p->adjvex] == false && p->adjvex != anc)
{
TarjanDFS(G_Full, G_Search,p->adjvex, root);
unite(p->adjvex,root);//将子节点并入到父节点所在的集合中
}
p = p->nextarc;
}
ALG_DFSvisited[root] = true; //如果退出遍历则标记为访问
ArcNode *q = G_Search.vertices[root].firstarc; //在搜索图中查找该结点是否有查询(查找有无出度)
while (q)
{
if (ALG_DFSvisited[q->adjvex] == true) //查找到且已被标记
{
q->anc = find(q->adjvex);//将q的祖先即当前结点的祖先保存在anc中
ArcNode *r = G_Search.vertices[q->adjvex].firstarc;//将r的祖先即另一对应结点的祖先
while (r) {
if (r->adjvex == root) //如果另一结点的祖先为该结点当前的祖先
{
r->anc = q->anc;
break;
}
r = r->nextarc;
}
}
q = q->nextarc;
}
}
主要是通过一次DFS遍历把村庄的路径图G_Full的同时把已遍历的结点归入并查集的同时检查该结点G_Search是否有存在查询关系,有的话把当前的公共祖先存入对应查询关系结果中。
输入方面:
在路径输入通过随机函数分别通过两个数组的判断处理能否组成一棵树,这里通过加多了一个数组简单优化了一下把这部分运行时间提高了一点点,查询输入就是在n的范围呢完全随机了
queue<int>r_u;
queue<int>r_v;
int r=1;
bool rand1[MVNum],rand2[MVNum];
memset(rand1, false, sizeof(rand1));
memset(rand2, false, sizeof(rand2));
rand1[0] = true;
srand((unsigned)time(NULL));
int num1 = 0;
rr[0] = 0;
int num2;
while (r_u.size() < n - 1)
{
num2 = rand() % n;
while (rand1[num1] && rand2[num2])
{
num2 = rand() % n;
}
if (!rand1[num2])
{
rand1[num2] = true;
rr[r] = num2;
r++;
}
if (!rand2[num2])rand2[num2] = true;
r_u.push(num1);
r_v.push(num2);
srand((unsigned)time(NULL));
num1 = rr[(rand() % r)];
}
结果的判断主要通过一个巧妙的方式:如果ab的最近公共祖先即b本身是ac的公共祖先或者bc的最近公共祖先即b本身是ac的公共祖先即满足条件b在ac的路径上
//获得ABC任意两者的公共祖先
void GetLca(ALGraph &G_Search, int a, int b, int c, int i)
{
ArcNode *ab = G_Search.vertices[a].firstarc;
ArcNode *bc = G_Search.vertices[b].firstarc;
ArcNode *ac = G_Search.vertices[a].firstarc;
while (ab)
{
if (ab->adjvex == b)
{
lca[i].lca_ab = ab->anc;
break;
}
else ab = ab->nextarc;
}
while (bc)
{
if (bc->adjvex == c)
{
lca[i].lca_bc = bc->anc;
break;
}
else bc = bc->nextarc;
}
while (ac)
{
if (ac->adjvex == c)
{
lca[i].lca_ac = ac->anc;
break;
}
else ac = ac->nextarc;
}
}
//检查C是否在AB的路径上
void CanMeet(ALGraph &G_Search)
{
for (int i = 0; i < question_number; i++)
{
if ((lca[i].lca_ab == lca[i].lca_ac&&lca[i].lca_bc == lca[i].C) || (lca[i].lca_ab == lca[i].lca_bc&&lca[i].lca_ac == lca[i].C))
{
cout << "Yes!" << endl;
}
else
{
cout << "No!" << endl;
}
}
}
最后直接输出
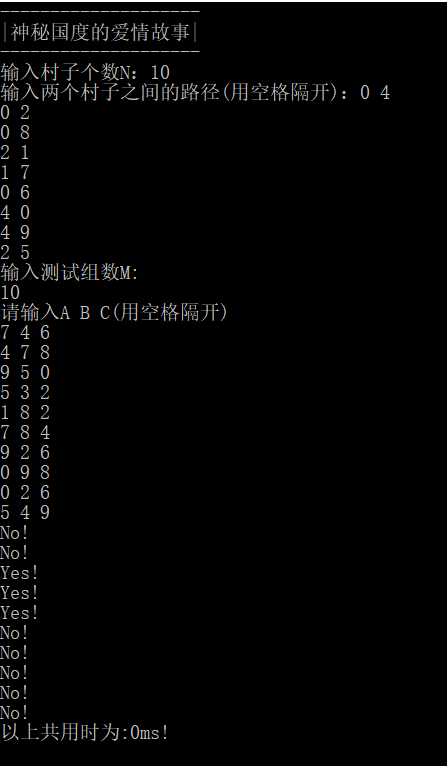
小例子测试成功,因为数据量小运行时间可以忽略不计。
在结点数量为5000时:(时间由于每次树的结构的不同可能会有不同幅度的波动)
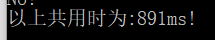
大例子数据太多无法截图,最后在测试在5W个村子是一样可以运行,但是在时间上运行会比较久。
运行时间可以通过下列代码实现:
#include<windows.h> DWORD start_time = GetTickCount(); DWORD end_time = GetTickCount();
总体来说我在这方面就是牺牲了大量空间来换取时间的做法了,看大佬用了倍增的方法似乎还更快,自己还是太渣了呀。
ps:最后运行了几十遍花了快一小时还得在excel上把曲线列出来分析写总结才完事真的是累人呀,50W的数据等得真的是久。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号