
CLIPFit:不绕弯子,直接微调比提示微调和适配器微调更好 | EMNLP'24
来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Vision-Language Model Fine-Tuning via Simple Parameter-Efficient Modification

创新点
- 提出了一种
CLIPFit方法以高效地微调CLIP模型,从而揭示经典模型微调在视觉语言模型(VLMs)上的潜力。 - 与现有的提示调整或适配器调整方法不同,
CLIPFit不引入任何外部参数,而仅微调CLIP固有参数中的一个小特定子集。
内容概述

微调视觉语言模型(VLMs)方面的进展见证了提示调优和适配器调优的成功,而经典模型在固有参数上的微调似乎被忽视了。有人认为,使用少量样本微调VLMs的参数会破坏预训练知识,因为微调CLIP模型甚至会降低性能。论文重新审视了这一观点,并提出了一种新视角:微调特定的参数而不是全部参数将揭示经典模型微调在VLMs上的潜力。
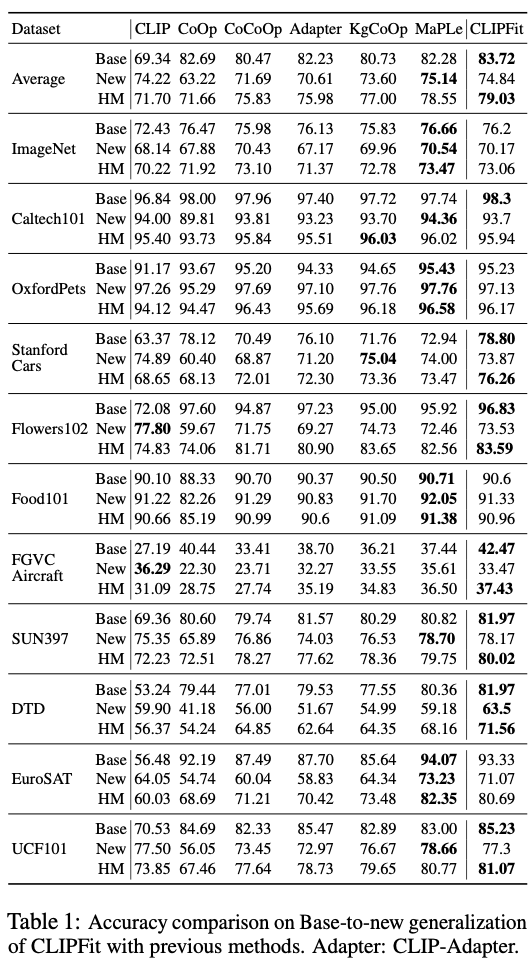
通过细致研究,论文提出了ClipFit,可以在不引入额外参数开销的情况下微调CLIP。仅通过微调特定的偏置项和归一化层,ClipFit可以将零样本CLIP的平均调和均值准确率提升7.27%。
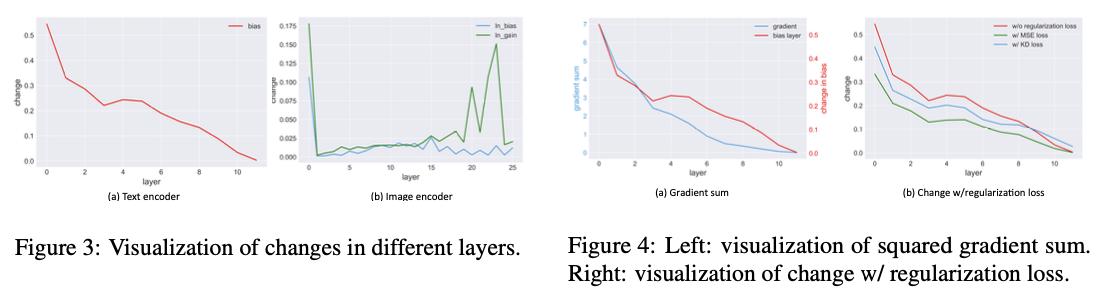
为了理解CLIPFit中的微调如何影响预训练模型,论文进行了广泛的实验分析以研究内部参数和表示的变化。在文本编码器中,当层数增加时,偏置的变化减少。在图像编码器中,LayerNorm也有同样的结论。进一步的实验表明,变化较大的层对知识适应更为重要。
CLIPFit
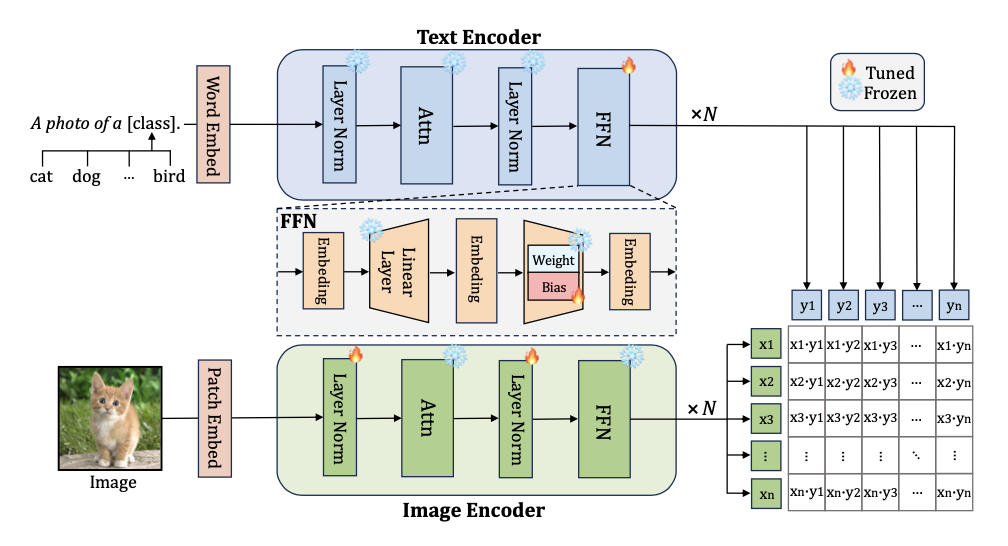
在不引入任何外部参数的情况下,CLIPFit仅对文本编码器中FNN的投影线性层的偏置项进行微调,并更新图像编码器中的LayerNorm。
文本编码器
对于文本编码器,CLIPFit并不是对所有偏置项进行微调,而仅对文本编码器中FFNs的投影线性层(即第二层)的偏置项进行微调。仅微调部分偏置项将减少训练参数的数量,相较于微调所有偏置项。此外,实验表明,微调部分偏置项可以实现比微调所有偏置项更好的性能。
图像编码器
BitFit证明了在不引入任何新参数的情况下,仅微调预训练语言模型中的偏置项可以与完全微调的表现相媲美。然而,BitFit是为大型语言模型(LLM)微调设计的,直接将BitFit应用于视觉语言模型(VLM)微调可能会损害模型的泛化能力。
为此,CLIPFit并没有对图像编码器的偏置项进行微调,而是对LayerNorm进行微调。在LayerNorm中,两个可学习参数增益 \(\boldsymbol{g}\) 和偏置 \(\boldsymbol{b}\) 用于对标准化输入向量 \(\boldsymbol{x}\) 进行仿射变换,以进行重新中心化和重新缩放,这有助于通过重新塑形分布来增强表达能力。在训练过程中,不同的数据分布应该在LayerNorm中产生不同的增益和偏置,以实现分布的重新塑形。
如果在推理过程中应用偏移的增益和偏置,可能会导致次优解。因此,CLIPFit对图像编码器中的LayerNorm进行微调。
损失函数
在微调阶段,通用的预训练知识很容易被遗忘。因此,论文探索了两种不同的策略来减轻这种遗忘。
第一种策略是使用知识蒸馏损失来指导CLIPFit从原始的零样本CLIP中学习。设 \(\{\boldsymbol{w}_i^\mathrm{clip}\}_{i=1}^K\) 为原始CLIP的文本特征, \(\{\boldsymbol{w}_{i}\}_{i=1}^K\) 为CLIPFit的文本特征。CLIPFit的训练损失和知识蒸馏损失定义为:
第二种策略是使用均方误差(MSE)损失来惩罚文本编码器的变化。设 \(\{\boldsymbol{b}_i^\mathrm{clip}\}_{i=1}^L\) 为来自预训练CLIP的未固定文本偏置项, \(\{\boldsymbol{b}_i\}_{i=1}^L\) 为来自CLIPFit的未固定文本偏置项,其中 \(L\) 是未固定偏置层的数量。均方误差损失定义为:
这两种策略都能缓解遗忘问题,而知识蒸馏损失的效果更佳。因此,选择将知识蒸馏损失作为CLIPFit的最终解决方案。
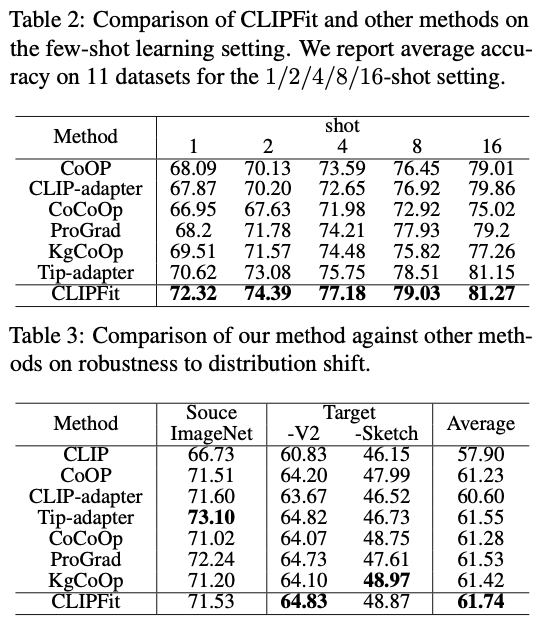
主要实验
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号