
OpenPSG:离AGI再进一步,首个开放环境关系预测框架 | ECCV'24
全景场景图生成(
PSG)的目标是对对象进行分割并识别它们之间的关系,从而实现对图像的结构化理解。以往的方法主要集中于预测预定义的对象和关系类别,因此限制了它们在开放世界场景中的应用。随着大型多模态模型(LMMs)的快速发展,开放集对象检测和分割已经取得了重大进展,但PSG中的开放集关系预测仍然未被探索。论文专注于开放集关系预测任务,并将其与一个预训练的开放集全景分割模型结合,以实现真正的开放集全景场景图生成(
OpenPSG)。OpenPSG利用LMMs以自回归的方式实现开放集关系预测,引入了一个关系查询变换器,以高效地提取对象对的视觉特征,并估计它们之间关系的存在。后者可以通过过滤不相关的对来提高预测效率。最后,论文设计了生成和判断指令,以自回归的方式在PSG中执行开放集关系预测。大量实验表明,该方法在开放集关系预测和全景场景图生成方面取得了最先进的性能。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: OpenPSG: Open-set Panoptic Scene Graph Generation via Large Multimodal Models

Introduction
全景场景图生成(PSG)的目标是对图像中的对象进行分割并识别它们之间的关系,从而构建一个全景场景图,以实现对图像的结构化理解。鉴于其在视觉问答、图像描述和具身导航等应用中的重大潜力,自从出现以来,PSG就吸引了研究人员的广泛关注。
以往的PSG方法仅能够预测封闭集对象和关系类别,而无法识别超出预定义类别的对象/关系。近年来,随着CLIP、BLIP-2等大型多模态模型(LMMs)的出现,出现了大量用于对象检测和分割的开放集预测方法,这得益于LMMs对语言的丰富理解以及视觉和语言之间的强关联。然而,开放集的关系预测迄今为止仍未被探索。
与开放集对象检测和分割相比,开放集关系预测更为复杂:模型不仅需要理解不同的对象,还需要基于它们的交互识别对象对之间的关系。尤其是,后者的计算可能呈指数级增长。为了解决这个问题,论文聚焦于开放集关系预测。
大型语言模型(LLMs)在各种多模态任务中展示了卓越的语义分析和理解能力。特别是在文本处理方面,LMMs不仅擅长解析名词(即表示对象),还对谓词(即表示对象之间的关系)给予了相当的关注,从而确保它们生成的内容具有足够的一致性。受到这一点的启发,论文提出了开放集全景场景图生成架构OpenPSG,利用一个大型多模态模型(例如,BLIP-2)来实现开放集关系预测。
具体而言,模型包括三个部分。首先是开放集全景分割器,适配了一个现有模型(例如,OpenSeeD),该模型能够从整个图像中提取开放集对象类别、掩码和视觉特征,形成对象对和对掩码。其次是关系查询变换器,它具有两个功能:基于对掩码提取对象对的视觉特征,并特别专注于对象之间的交互;判断对象对之间潜在的关系。这两个功能通过两组查询实现,即对特征提取查询和关系存在估计查询。只有那些被判断为可能有关系的对象对才会被送入第三部分,即多模态关系解码器。该解码器直接继承自LMM,以自回归的方式预测给定对象对的开放集关系,前提是特定设计的文本指令和预先提取的对视觉特征。
论文是首个提出开放集全景场景图生成任务的研究,能够实现对象掩码和关系的开放集预测。大量实验表明,OpenPSG在闭集设置中达到了最先进的结果,并在开放集设置中表现出色。
Task Definition
给定图像 \(I \in \mathbb{R}^{H \times W \times 3}\) ,开放集全景场景图生成的目标是从图像 \(I\) 中提取开放集全景场景图 \(G = \{O, R\}\) ,其中 \(H\) 和 \(W\) 是图像的高度和宽度。
-
\(O = \{o_i\}_{i=1}^{N}\) 表示从图像中分割出的 \(N\) 个对象,每个对象定义为 \(o_i = \{c, m\}\) ,其中 \(c\) 是对象类别,可以属于预定义的基础对象类别 \(C_{base}\) 或未定义的新奇对象类别 \(C_{novel}\) 。 \(m\) 表示对象在 \(\{0, 1\}^{H \times W}\) 中的二进制掩码。
-
\(R = \{r_{i,j} \mid i,j \in \{1, 2, \ldots, N\}, i \neq j\}\) 表示对象之间的关系,其中 \(r_{i,j}\) 表示 \(o_i\) 和 \(o_j\) 之间的关系,其中 \(o_i\) 是主语, \(o_j\) 是宾语。每个关系 \(r\) 可以属于预定义的基础关系类别 \(K_{base}\) 或未定义的新奇关系类别 \(K_{novel}\) 。
Method
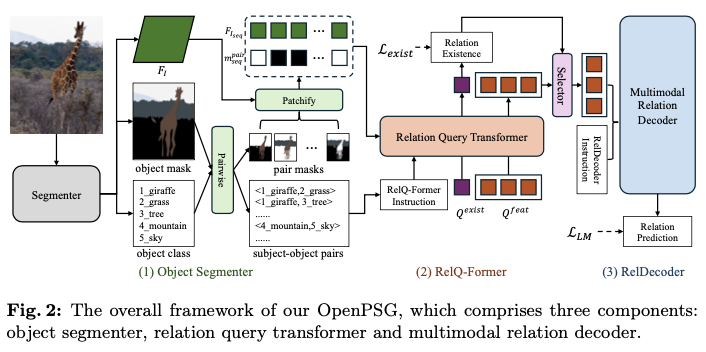
如图2所示,OpenPSG包含三个组件:对象分割器、关系查询变换器 (RelQ-Former) 和多模态关系解码器 (RelDecoder)。
对于对象分割器,利用预训练的开放集全景分割模型将输入图像转换为对象类别和掩码,以及表示整个图像的视觉特征。随后,将对象类别、掩码和视觉特征输入到RelQ-Former中。通过两组可学习的查询,并结合设计的指令,获得与LMM输入格式兼容的对象对的视觉特征,以及对潜在关系存在的判断。最后,只有那些被判断可能存在关系的对象对才会被送入RelDecoder进行开放集关系预测,最终生成开放集全景场景图。
Object Segmenter
给定一幅图像 \(I\) ,利用预训练的开放集对象分割器(例如,OpenSeeD)预测图像中的对象 \(O\) 以及整个图像的视觉特征 \(F_I \in \mathbb{R}^{h \times w \times D}\) 。这里, \(h\) 和 \(w\) 分别表示 \(F_I\) 的高度和宽度, \(D\) 表示特征维度。
分割器的架构与Mask2Former类似,包括一个像素解码器。整个图像的视觉特征 \(F_I\) 指的是由像素解码器输出的视觉特征。论文开发了patchify模块和pairwise模块来处理分割器的输出,生成RelQ-Former的输入。
-
Patchify Module
Patchify模块旨在对视觉特征 \(F_I\) 和对象掩码 \(m\) 进行序列化,使它们能够作为输入被RelQ-Former处理。
类似于视觉变换器(ViT)的输入patchify层,利用单个卷积层将提取的 \(F_I\) 转换为视觉标记序列 \(F_{Iseq} \in \mathbb{R}^{L \times D}\) ,其中 \(L\) 是patch的数量, \(D\) 是特征维度。当卷积层的卷积核大小和步幅均为 \(p\) 时, \(L\) 的计算公式为 \(L = \frac{h}{p} \times \frac{w}{p}\) 。
同时,对每个提取对象的掩码 \(m_i\) 采用最近邻插值,其中 \(m_i\) 的大小为高度 \(\frac{h}{p}\) 和宽度 \(\frac{w}{p}\) ,然后将其重塑为长度为 \(L\) 的一维向量。通过以相同方式处理所有掩码,为所有对象获得掩码序列 \(m_{seq} \in \{0, 1\}^{N \times L}\) 。
-
Pairwise Module
成对模块旨在构建主语-谓语对。给定图像 \(I\) 中的 \(N\) 个对象,将所有对象 \(O\) 成对组合为主语-谓语对 \(P = \{(o_i, o_j) | i, j \in \{1, 2, \ldots, N\}, i \neq j\}\) 。 \(P\) 中的主语-谓语对的数量为 \(N \times (N - 1)\) ,随着 \(N\) 的增加,此数量呈指数增长。因此,还获得了组合的主语-谓语对类别集 \(c^{pair} \in \{(c_i, c_j) | i, j \in \{1, 2, \ldots, N\}, i \neq j\}\) 。
通过对每一对主语-谓语使用逻辑OR操作(对两个对象的 \(m_{seq}\)),从 \(m_{seq}\) 中构建对应于索引 \(i\) 和 \(j\) 的两个对象的掩码序列。该操作适用于所有主语-谓语对,从而得到主语-谓语对的成对掩码序列 \(m_{seq}^{pair} \in \{0, 1\}^{N \times (N-1) \times L}\) ,其中 \(L\) 是patch的数量。
Relation Query Transformer
关系查询变换器利用获得的 \(F_{Iseq}\) 、 \(c^{pair}\) 和 \(m_{seq}^{pair}\) ,采用两种不同类型的查询,即成对特征提取查询和关系存在估计查询,并结合定制的指令。这种方法有助于提取主语-谓语对特征,并评估哪些主语-谓语对可能存在关系。
-
Pair Feature Extraction Query
成对特征提取查询的目标是基于主语-谓语对掩码,从整个图像视觉特征中提取对应的主语-谓语对特征。
常见的提取方法包括掩码池化,它为目标的主语-谓语对提取特征,平等地对待主语-谓语对上的每个区域。然而,用于关系预测的特征应更关注对象之间发生交互的区域。通过利用注意力机制,论文促进了代表主语-谓语对视觉特征序列 \(F_{Iseq}\) 中不同区域的视觉标记之间的交互。这种方式可以增强对关系预测至关重要的区域。此外,受到先前研究的启发,论文设计了一条指令以帮助这个可学习查询理解其提取主语-谓语对特征的目的。
具体而言,对于每一对主语-谓语对 \((o_i, o_j)\) ,首先将成对特征提取查询 \(Q^{feat} \in \mathbb{R}^{E \times D}\) 输入到自注意力层 ( \(SA(\cdot)\) ),同时加入专门为成对特征提取查询设计的成对指令。这个成对指令经过分词器层处理,以得到 \(F_{Inst}^{feat} \in \mathbb{R}^{X^{feat} \times D}\) ,其指定了成对特征提取查询的功能,即“根据掩码从视觉特征中提取主语-谓语 ( \(c_i\) , \(c_j\) ) 特征”。这里 \(E\) 是成对特征提取查询的标记数量, \(X^{feat}\) 是成对指令的标记数量。需要注意的是,还将主语和谓语的类别名称 \((c_i, c_j)\) 纳入这个成对指令中。此操作可表示为
其中 \(Concat(\cdot)\) 表示拼接操作, \(Trunc(\cdot)\) 表示截断操作,而在该截断操作中 \(E\) 表示仅提取前 \(E\) 个特征,即与成对特征提取查询对应的特征。
接下来,使用掩码交叉注意力层 ( \(MaskCA(\cdot)\) ),将 \(F_{SA}^{feat}\) 作为查询,将 \(F_{Iseq}\) 作为键和值,将 \(m_{seq}\) 作为掩码,提取与主语-谓语对对应的特征
特征 \(F_{CA}^{feat}\) 通过前馈网络 ( \(FFN(\cdot)\) ) 进一步精炼,表示为 \(F_{FFN}^{feat} = FFN(F_{CA}^{feat})\) 。
通过重复这个过程两次,获得要输入到多模态关系解码器中的主语-谓语对的视觉特征 \(F_{I}^{pair(i,j)} \in \mathbb{R}^{E \times D}\) 。对所有主语-谓语对并行执行这些操作,以获得所有对的相应特征。
-
Relation Existence Estimation Query
除了成对特征提取查询,论文还设计了一种关系存在性估计查询,以确定主体 \(o_i\) 和对象 \(o_j\) 之间是否可能存在关系,而不预测具体的关系类别。其目的是过滤掉不相关的主语-谓语对,以节省后续LMM解码的计算。
具体来说,对于每一个主语-谓语对 \((o_i, o_j)\) ,关系存在性估计查询 \(Q^{exist} \in \mathbb{R}^{1 \times D}\) ,类似于成对特征提取查询,被输入到自注意力、掩蔽交叉注意力和前馈网络层,分别与 \(F_{Iseq}\) 、 \(m_{seq}\) 以及特别设计的关系指令进行交互。关系指令的目的是指导关系存在性估计查询以确定主语-谓语对中是否可能存在关系,例如“ \(o_i\) 和 \(o_j\) 之间是否存在关系?”在经过分词器处理后,关系指令产生 \(F_{Inst}^{exist} \in \mathbb{R}^{X^{exist} \times D}\) ,其中 \(X^{exist}\) 表示标记的数量。
最终,提取的特征被输入到一个关系存在性预测层,该层包括一个2层的多层感知机(MLP),并使用sigmoid函数将预测得分标准化到 \([0, 1]\) 范围内。值得注意的是,论文使用二进制标签进行训练,以指示对象之间是否存在关系,并在推理过程中利用下面指定的选择模块进行过滤。
-
Selector
由2层多层感知机(MLP)实现的选择模块被设置为过滤不相关的主语-谓语对。只有得分高于阈值 \(\theta\) 的对才能被输入到多模态关系解码器中。与对所有主语-谓语对进行预测相比,可以实现\(20 \times\) 的加速。
Multimodal Relation Decoder
多模态关系解码器的目标是利用上述模块提取的主语-谓语对特征 \(F_I^{i, j}\) ,结合指导其进行开放集关系预测的指令。受到先前研究的启发,首先设计了一种生成指令,以自回归的方式执行开放集关系预测。这种方法效果良好,但发现它在一定程度上倾向于更常见的关系。因此,论文进一步设计了一种判断指令,利用LMM的强大分析和判断能力。判断指令同样采用自回归的方法,但用于判断对象之间是否存在特定关系,从而简化开放集关系预测的复杂性。接下来,将分别细化这两种指令。
-
Generation Instruction
对于生成指令,遵循开放集物体识别中使用的指令设计,利用“ \(c_i\) 和 \(c_j\) 之间有哪些关系?”, \(c_i\) 和 \(c_j\) 分别指主语和谓语的名称。使用分词器将该指令转换为特征 \(F_{inst}^{gen} \in \mathbb{R}^{X^{gen} \times D}\) ,其中 \(X^{gen}\) 是生成指令的标记数。将生成指令的特征 \(F_{inst}^{gen}\) 与主语-谓语对特征 \(F_{I}^{pair(i,j)}\) 一起输入到多模态关系解码器 \(Dec(\cdot)\) 中,以自回归的方式预测所有可能的关系,公式形式为:
如果预测到多个关系,它们将通过分隔符 "[SEP]" 分开。
-
Judgement Instruction
与生成指令不同,判断指令指导关系解码器根据给定的关系名称判断该关系是否存在于主语和谓语之间。例如,“请判断 \(c_i\) 和 \(c_j\) 之间是否存在关系 \(r_k\) ”。在这种情况下,只需要多模态关系解码器回答“是”或“否”来确定该关系的存在。值得注意的是,将每个关系的完整判断指令输入解码器可能会非常复杂。因此,将关系名称放在指令的末尾。在推理过程中,将判断指令分为两部分:在关系名称之前的部分,通过分词器转换为 \(F_{inst}^{judge}\) ,而关系名称本身则处理为 \(F_{inst}^{rel}\) 。
借助自回归方式进行开放集关系预测,首先将主语-谓语对特征 \(F_{I}^{pair(i,j)}\) 与 \(F_{inst}^{judge}\) 输入多模态关系解码器,公式形式为:
随后该结果会被缓存,以便对每个关系进行后续计算。对于每个关系 \(r_k\) ,多模态关系解码器只需要处理 \(F_{prefix}\) 和 \(F_{inst}^{rel(k)}\) 以实现关系预测,公式形式为:
其中 \(J_{i,j,k}\) 表示对三元组 \((o_i, r_k, o_j)\) 的判断。当 \(J_{i,j,k}\) 为“是”时,表示关系 \(r_k\) 存在于 \(o_i\) 和 \(o_j\) 之间;否则,则表示该关系不存在。通过这种方法,可以保持与生成指令相同的预测时间。
对所有可能存在关系的主语-谓语对执行上述过程,最终实现开放集关系预测。对于使用生成指令的方法,将其称为OpenPSG-G,而对于使用判断指令的方法,则称为OpenPSG-J,而OpenPSG默认指的是后者。
Loss Function
在模型训练过程中,涉及两个损失函数:用于通过关系查询变换器中的关系存在估计查询来估计关系存在性的二元交叉熵损失 \(\mathcal{L}_{exist}\) ,以及与多模态关系解码器使用的语言模型训练一致的交叉熵损失 \(\mathcal{L}_{LM}\) 。总损失为: \(\mathcal{L} = \lambda \mathcal{L}_{exist} + \mathcal{L}_{LM}\) ,其中 \(\lambda\) 是一个权重因子。
Implementation details
在实验中,使用预训练的OpenSeeD作为开放集对象分割器。pathify模块的patch大小 \(p\) 设置为8。在关系查询变换器中,配对特征提取查询的长度 \(E\) 为32,用于过滤主语-宾语对的阈值 \(\theta\) 设置为0.35。在多模态关系解码器中,采用BLIP-2的解码器。在模型训练期间,损失的权重因子 \(\lambda\) 设置为10。采用与以前的方法相同的数据增强策略。使用AdamW优化器,学习率为 \(1e^{-4}\) ,权重衰减为 \(5e^{-2}\) 。总共训练12个周期,在第 \(8\) 个周期将学习率降低到 \(1e^{-5}\) 。实验使用四个A100 GPU。需要注意的是,在训练期间,冻结对象分割器和多模态关系解码器的参数,仅训练提出的RelQ-Former。
Experiments
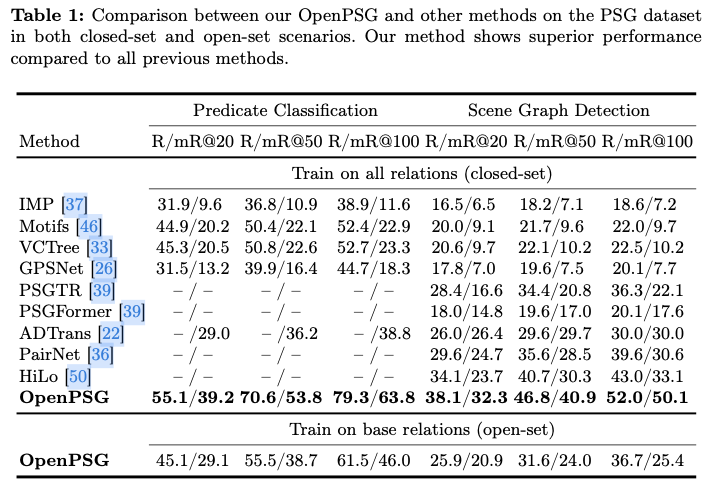
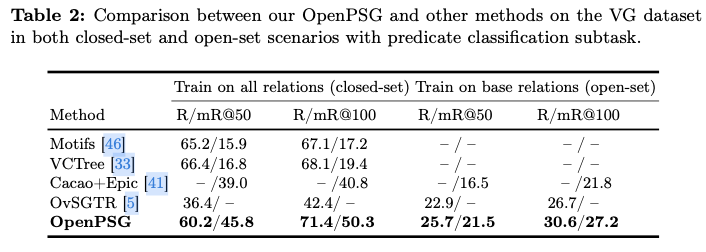

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号