


WTConv:小参数大感受野,基于小波变换的新型卷积 | ECCV'24
近年来,人们尝试增加卷积神经网络(
CNN)的卷积核大小,以模拟视觉Transformer(ViTs)自注意力模块的全局感受野。然而,这种方法很快就遇到了上限,并在实现全局感受野之前就达到了饱和。论文证明通过利用小波变换(WT),实际上可以获得非常大的感受野,而不会出现过参数化的情况。例如,对于一个 的感受野,所提出方法中的可训练参数数量仅以 进行对数增长。所提出的层命名为WTConv,可以作为现有架构中的替换,产生有效的多频响应,且能够优雅地随着感受野大小的变化而扩展。论文在ConvNeXt和MobileNetV2架构中展示了WTConv层在图像分类中的有效性,以及作为下游任务的主干网络,并且展示其具有其它属性,如对图像损坏的鲁棒性以及对形状相较于纹理的增强响应。来源:晓飞的算法工程笔记 公众号,转载请注明出处
论文: Wavelet Convolutions for Large Receptive Fields

Introduction
在过去十年中,卷积神经网络(CNN)在许多计算机视觉领域占主导地位。尽管如此,随着视觉Transformer(ViTs)的出现(这是一种用于自然语言处理的Transformer架构的适应),CNN面临着激烈的竞争。具体而言,ViTs目前被认为相较于CNN具有优势的原因,主要归功于其多头自注意力层。该层促进了特征的全局混合,而卷积在结构上仅局限于特征的局部混合。因此,最近几项工作尝试弥补CNN和ViTs之间的性能差距。有研究重构了ResNet架构和其训练过程,以跟上Swin Transformer。“增强”的一个重要改进是增加卷积核的大小。然而,实证研究表明,这种方法在 的卷积核大小处就饱和了,这意味着进一步增加卷积核并没有帮助,甚至在某个时候开始出现性能恶化。虽然简单地将大小增加到超过 并没有用,但RepLKNet的研究已经表明,通过更好的构建可以从更大的卷积核中获益。然而,即便如此,卷积核最终仍然会变得过参数化,性能在达到全局感受野之前就会饱和。
在RepLKNet分析中,一个引人入胜的特性是,使用更大的卷积核使得卷积神经网络(CNN)对形状的偏向性更强,这意味着它们捕捉图像中低频信息的能力得到了增强。这个发现有些令人惊讶,因为卷积层通常倾向于对输入中的高频部分作出响应。这与注意力头不同,后者已知对低频更加敏感,这在其他研究中得到了证实。
上述讨论引发了一个自然的问题:能否利用信号处理工具有效地增加卷积的感受野,而不至于遭受过参数化的困扰?换句话说,能否使用非常大的滤波器(例如具有全局感受野的滤波器),同时提升性能?论文提出的方法利用了小波变换(WT),这是来自时频分析的一个成熟工具,旨在有效扩大卷积的感受野,并通过级联的方式引导CNN更好地响应低频信息。论文将解决方案基于小波变换(与例如傅里叶变换不同),因为小波变换保留了一定的空间分辨率。这使得小波域中的空间操作(例如卷积)更加具有意义。
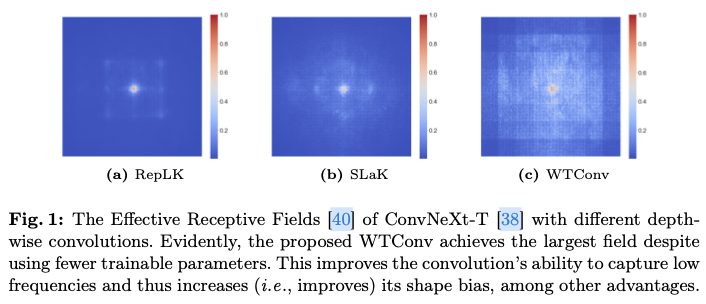
更具体地说,论文提出了WTConv,这是一个使用级联小波分解的层,并执行一组小卷积核的卷积,每个卷积专注于输入的不同频率带,并具有越来越大的感受野。这个过程能够在输入中对低频信息给予更多重视,同时仅增加少量可训练参数。实际上,对于一个 的感受野,可训练参数数量只随着 的增长而呈对数增长。而WTConv与常规方法的参数平方增长形成对比,能够获得有效的卷积神经网络(CNN),其有效感受野(ERF)大小前所未有,如图1所示。
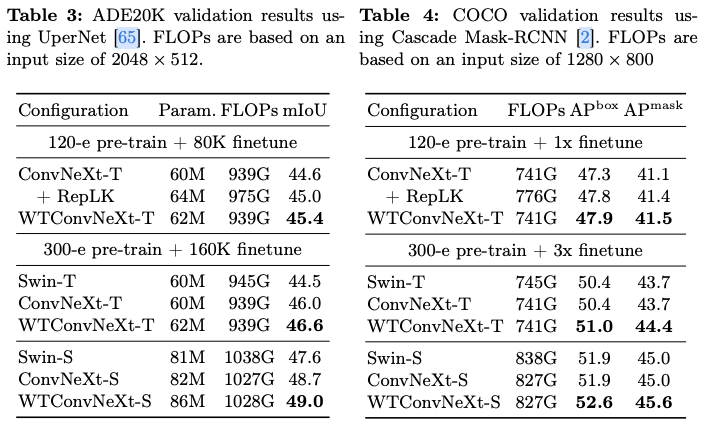
WTConv作为深度可分离卷积的直接替代品,可以在任何给定的卷积神经网络(CNN)架构中直接使用,无需额外修改。通过将WTConv嵌入到ConvNeXt中进行图像分类,验证了WTConv的有效性,展示了其在基本视觉任务中的实用性。在此基础上,进一步利用ConvNeXt作为骨干网络,扩展评估到更复杂的应用中:在UperNet中进行语义分割,以及在Cascade Mask R-CNN中进行物体检测。此外,还分析了WTConv为CNN提供的额外好处。
论文的贡献总结如下:
-
一个新的层
WTConv,利用小波变换(WT)有效地增加卷积的感受野。 -
WTConv被设计为在给定的卷积神经网络(CNN)中作为深度可分离卷积的直接替代。 -
广泛的实证评估表明,
WTConv在多个关键计算机视觉任务中提升了卷积神经网络(CNN)的结果。 -
对
WTConv在卷积神经网络(CNN)的可扩展性、鲁棒性、形状偏向和有效感受野(ERF)方面贡献的分析。
Method
Preliminaries: The Wavelet Transform as Convolutions
在这项工作中,采用Haar小波变换,因为它高效且简单。其他小波基底也可以使用,尽管计算成本会有所增加。
给定一个图像 ,在一个空间维度(宽度或高度)上的一层Haar小波变换由核为 和 的深度卷积组成,之后是一个缩放因子为2的标准下采样操作。要执行2D Haar小波变换,在两个维度上组合该操作,即使用以下四组滤波器进行深度卷积,步距为2:
注意, 是一个低通滤波器,而 是一组高通滤波器。对于每个输入通道,卷积的输出为
输出具有四个通道,每个通道在每个空间维度上的分辨率为 的一半。 是 的低频分量,而 分别是其水平、垂直和对角线的高频分量。
由于公式1中的核形成了一个标准正交基,逆小波变换(IWT)可以通过转置卷积实现:
级联小波分解是通过递归地分解低频分量来实现的。每一层的分解由以下方式给出:
其中 ,而 是当前的层级。这导致较低频率的频率分辨率提高,以及空间分辨率降低。
Convolution in the Wavelet Domain
增加卷积层的核大小会使参数数量呈平方级增加,为了解决这个问题,论文提出以下方法。
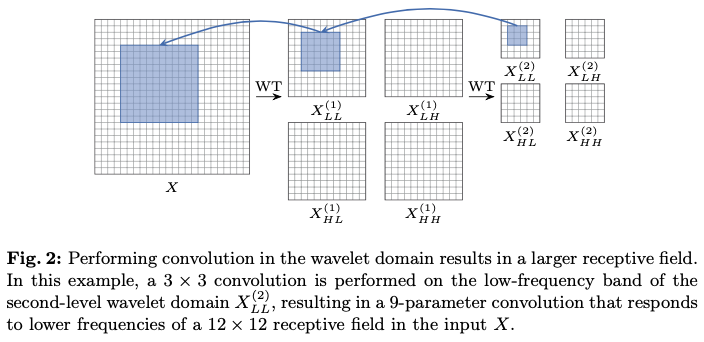
首先,使用小波变换(WT)对输入的低频和高频内容进行过滤和下采样。然后,在不同的频率图上执行小核深度卷积,最后使用逆小波变换(IWT)来构建输出。换句话说,过程由以下给出:
其中 是输入张量, 是一个 深度卷积核的权重张量,其输入通道数量是 的四倍。此操作不仅在频率分量之间分离了卷积,还允许较小的卷积核在原始输入的更大区域内操作,即增加了相对于输入的感受野。
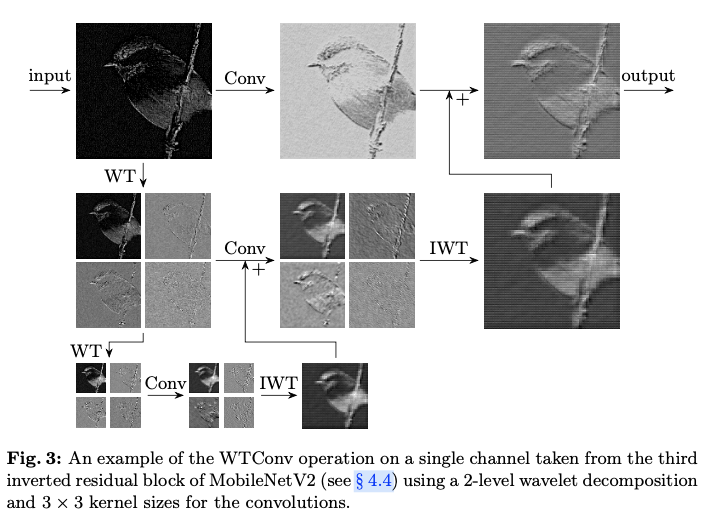
采用这种1级组合操作,并通过使用公式4中相同的级联原理进一步增加它。该过程如下所示:
其中 是该层的输入, 表示第 级的所有三个高频图。
为了结合不同频率的输出,利用小波变换(WT)及其逆变换是线性操作的事实,这意味着 。因此,进行以下操作:
这将导致不同级别卷积的求和,其中 是从第 级及之后的聚合输出。这与RepLKNet一致,其中两个不同尺寸卷积的输出被相加作为最终输出。
与RepLKNet不同,不能对每个 进行单独归一化,因为这些的单独归一化并不对应于原始域中的归一化。相反,论文发现仅进行通道级缩放以权衡每个频率分量的贡献就足够了。
The Benefits of Using WTConv
在给定的卷积神经网络(CNN)中结合小波卷积(WTConv)有两个主要的技术优势。
- 小波变换的每一级都会增加层的感受野大小,同时仅小幅增加可训练参数的数量。也就是说,
WT的 级级联频率分解,加上每个级别的固定大小卷积核 ,使得参数的数量在级别数量上呈线性增长( ),而感受野则呈指数级增长( )。 - 小波卷积(
WTConv)层的构建旨在比标准卷积更好地捕捉低频。这是因为对输入的低频进行重复的小波分解能够强调它们并增加层的相应响应。通过对多频率输入使用紧凑的卷积核,WTConv层将额外的参数放置在最需要的地方。
除了在标准基准上取得更好的结果,这些技术优势还转化为网络在以下方面的改进:与大卷积核方法相比的可扩展性、对于损坏和分布变化的鲁棒性,以及对形状的响应比对纹理的响应更强。
Computational Cost
深度卷积在浮点运算(FLOPs)方面的计算成本为:
其中 为输入通道数, 为输入的空间维度, 为卷积核大小, 为每个维度的步幅。例如,考虑一个空间维度为 的单通道输入。使用大小为 的卷积核进行卷积运算会产生 FLOPs,而使用大小为 的卷积核则会产生 FLOPs。考虑WTConv的卷积集,尽管通道数是原始输入的四倍,每个小波域卷积在空间维度上减少了一个因子2,FLOP计数为:
其中 是WT层级的数量。继续之前输入大小为 的例子,对一个3层WTConv使用大小为 的多频卷积(其感受野为 )会产生 FLOPs。当然,还需要添加WT计算本身的成本。当使用Haar基底时,WT可以以非常高效的方式实现。也就是说,如果使用标准卷积操作的简单实现,WT的FLOP计数为:
因为这四个卷积核的大小为 ,在每个空间维度上的步幅为2,并且作用于每个输入通道。同样,类似的分析表明,IWT的FLOP计数与WT相同。继续这个例子,3层WT和IWT的额外成本为 FLOPs,总计为 FLOPs,这仍然在相似感受野的标准深度卷积中有显著的节省。
Results

如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!