


1p-frac:已开源,仅用单张分形图片即可媲美ImageNet的预训练效果 | ECCV 2024
分形几何是一个数学分支,主要应用于作图方面。一般来说,分形经过无数次递归迭代后的结果。比如取一条线段,抹去中间的三分之一,会得到长度是原三分之一长的两条线段,中间隔着相同长度的间隙。然后重复这个动作,直到所有的线段都被抹掉,就将会得到被以固定模式出现的间隙隔开的无限多的点,这就是康托尔集合。
目前有许多研究通过生成分形图像进行模型的预训练,完全不用真实图片甚至训练图片与下游任务完全不相干的,也能达到大规模数据集的预训练效果。
论文寻找一个最小的、纯合成的预训练数据集,这个数据集能够实现与
ImageNet-1k的100万张图像相当的性能。论文从单一的分形中生成扰动来构建这样的数据集,仅包含1张分形图片。来源:晓飞的算法工程笔记 公众号
论文: Scaling Backwards: Minimal Synthetic Pre-training?

Abstract
预训练和迁移学习是当前计算机视觉系统的重要构建块。虽然预训练通常是在大规模的真实世界图像数据集上进行的,但在本论文中,我们提出了一个重要的问题——是否真正有必要使用这样的数据集。为此,我们通过这些工作,我们的主要贡献表现如下三个发现。
(i)即使具有非常有限的合成图像,我们也能证明预训练仍然有效,全量微调时性能与使用大规模预训练数据集如ImageNet-1k相当。
(ii)我们研究了在构建数据集的单个参数中用于构建人工类别的方式。我们发现尽管形状差异在人类看来几乎无法区分,但正是这些差异对于获得强大性能至关重要。
(iii)最后,我们研究了成功的预训练的最小要求。令人惊讶的是,从1k个合成图像大幅减少到仅1个,甚至可能使预训练性能得到提升,这激发了我们进一步探索“逆向缩放”的可能性。
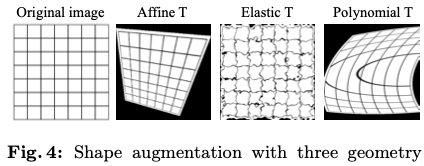
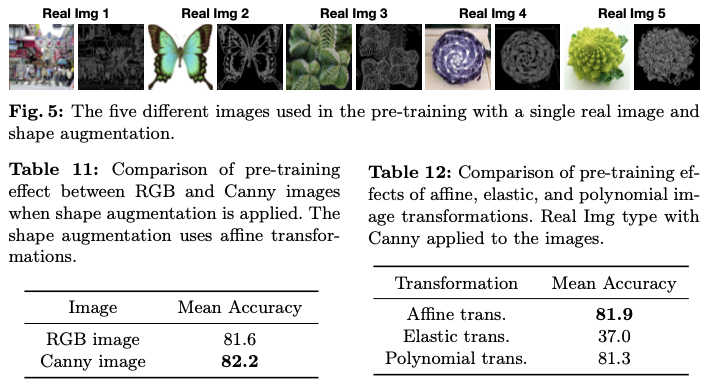
最后,我们从合成图像扩展到真实图像尝试发现,即使单张真实图像通过形状增强也能展现类似的预训练效果。我们发现使用灰度图像以及仿射变换甚至使真实图像也能够进行有效的“逆向缩放”。源代码已开放在https😕/github.com/SUPER-TADORY/1p-frac上。
Introduction
在图像识别中,预训练可以帮助发现下游任务应用的基本视觉表示,提高了视觉任务的性能并可以利用小规模的特定任务数据集。最近,预训练已被用作构建基于超过数亿张图像进行训练的基础模型的关键技术。在某些情况下,基础模型可以进行零样本识别的调整,而无需额外数据。
预训练通常被解释为在大规模数据集中发现通用结构,从而后续有助于适应下游任务。论文挑战了这种解释,提供一个由单个分形(fractal)生成的最小预训练数据集,其实现了类似的下游性能。论文研究的核心问题是:预训练可能只是更好的权重初始化,而不是有用视觉概念的发现。如果属实,进行数亿张图像昂贵的预训练可能并非必要,还可以使得预训练免受授权或道德问题影响。
自从深度神经网络的兴起以来,ImageNet数据集一直是最常用的预训练数据集之一。最初,预训练是通过使用人工提供的标注进行监督学习(SL)来进行的。然而,现在已经明确,通过自监督学习(SSL)也可以实现预训练,而无需人工提供的标签。
在这种情况下,Asano等人成功地获得了视觉表示,同时大大减少了所需图像的数量。他们得出结论,SSL即使只有一个训练示例,也可以产生足够的图像表示,但仅适用于识别模型的较早层。然而,目前尚不清楚这些发现如何转化为现代架构和表示学习方法。基于此,视觉变换器(ViT)通过实例判别(instance discrimination)学习信号,仅使用 个真实图像即可进行预训练。
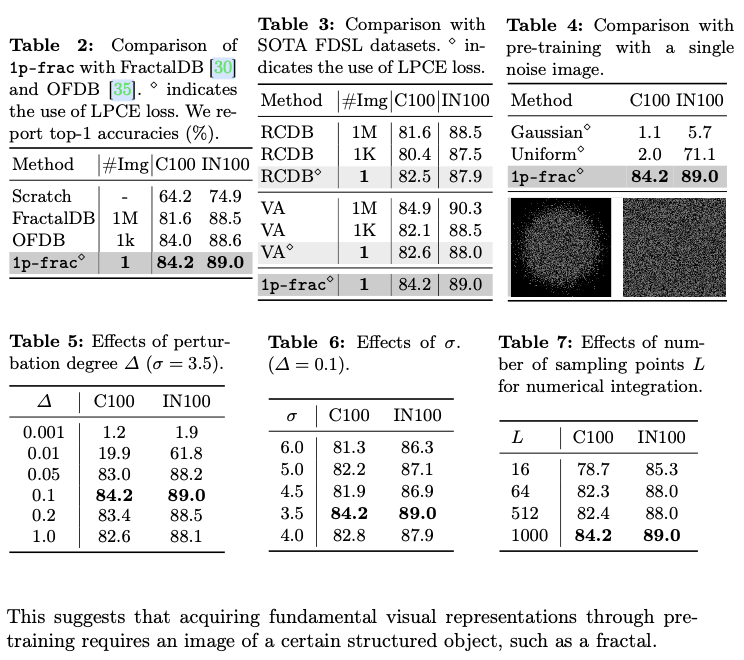
最近的研究表明,即使不使用真实图像和人工提供的标签,也可以获得基本的视觉表示,生成标注图像用于合成预训练的趋势正在上升。基于公式的监督学习(FDSL)从生成公式中生成图像,并从其参数中生成标签。在FDSL框架下,可以通过改变公式来调整合成预训练图像数据集。虽然FractalDB构建了一个百万级别的图像数据集,但论文发现合成预训练其实可以减少到更少的分形图像。
受到这些发现的启发,论文相信找到图像识别预训练的关键要点是可能的。有研究仅使用 个人工生成的图像来完成ViT训练,因此,论文相信即使用更少的图像也可以达到相同的性能。随着接近在图像识别中最小化合成预训练数据集,这一考虑无疑非常重要,这与基础模型朝着增加数据集规模的趋势相悖。

在本文中,作者引入了一个最小化合成数据集,即1-parameter Fractal as Data(1p-frac),如图1所示,它包括了单一分形以及用于预训练的损失函数。
论文关于极简合成预训练的贡献如下:
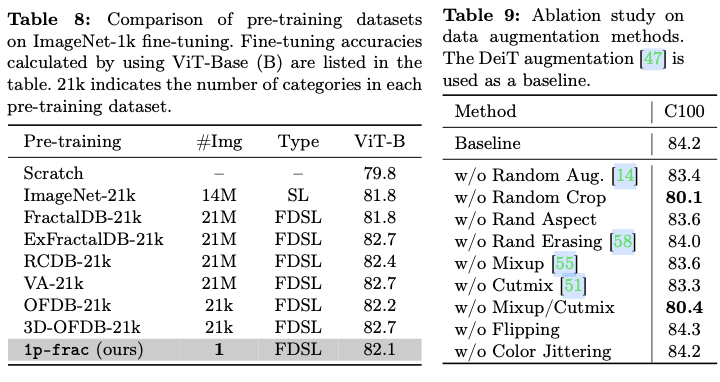
Ordinal minimalism:引入局部扰动交叉熵(LPCE)损失进行基于单个分形的预训练,利用扰动的分形图像进行训练,神经网络学习对小扰动进行分类。在实验中,论文展示了即使只有一个分形也可以进行预训练。而且,1p-frac的预训练效果可与百万级标记图像数据集相媲美。Distributional minimalism:引入具有可控扰动程度 的局部整合经验(LIEP)分布 ,以研究合成图像的概率密度分布的最小支撑。论文观察到,即使通过产生人类无法区分的形状差异的小 ,也能产生积极的预训练效果。论文还展示了如果 太小,视觉预训练会崩溃。基于这些观察,论文建立了从数学公式生成良好预训练图像的通用界限。Instance minimalism:根据实验结果,合成图像不应仅包含复杂形状,应该在视觉预训练中应用类似于自然界中的对象的递归图像模式。通过对真实图像进行增强分类的实验表明,通过对灰度图像中的边缘突出对象执行“仿射变换”,可以实现良好的预训练效果。这些操作几乎与所提出的1p-frac的配置是同义的。
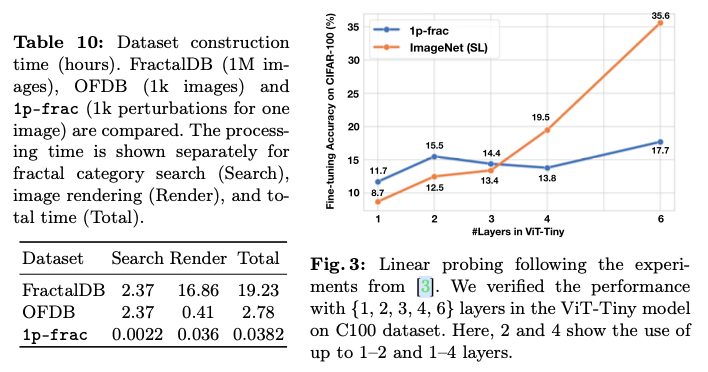
总之,论文将预训练数据集的大小显著减小,从原来的100万张图像(分形数据库(FractalDB))或1000张图像(单实例分形数据库(OFDB)),减少到只有1张,并且表明这甚至改善了预训练效果,这激励了scaling backwards的想法。
Scaling Backwards with a Single Fractal
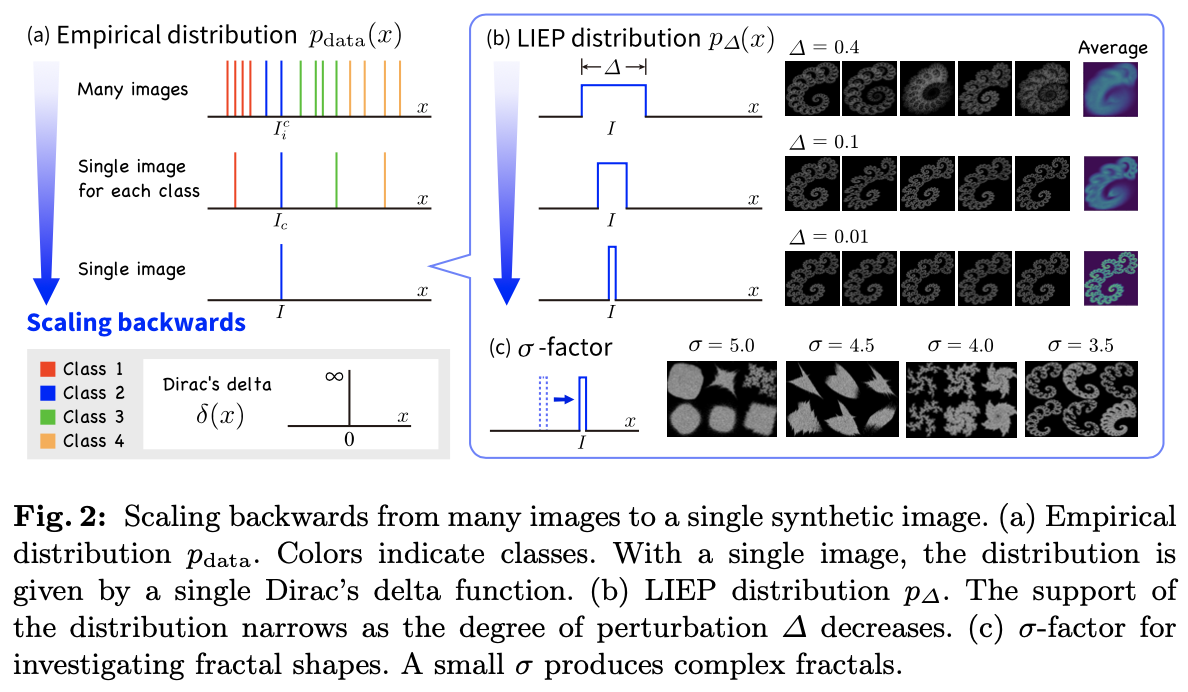
1-parameter Fractal as Data(1p-frac)仅包含一个单独的分形,并提出了一种在其上对神经网络进行预训练的方法。关键思想是引入局部整合经验(LIEP)分布 ,使得即使只有一个分形图像,也能进行预训练。由于LIEP分布设计成在扰动程度 趋近于零时,收敛到单个图像 的经验分布 ,可以通过减小 来缩小分布的支撑范围,如图2a所示。
Preliminary
-
FractalDB
FractalDB可以有效地利用FractalDB对神经网络进行预训练,该数据库是由迭代函数系统(IFSs)生成的一组分形图像。具体而言,FractalDB的 包括一百万个合成图像: ,其中 是一个IFS, 是由 生成的分形图像, 是分形类别的数量, 是每个类别的图像数量。每个IFS专门生成一个分形类别 ,并定义如下:
其中 是预定义的二维仿射变换,里面的参数从均匀分布 中采样生成。 是从候选数中随机抽样得到的数,决定当前IFS的仿射变换数量。 是一个根据 计算的概率质量分布,和为1,代表 被抽到的概率。 定义为
每个分形图像 是由 不断画点渲染的一个二维图像,其中点 由一个递归关系确定,即 对于 。这里,初始点设为 ,索引 在每个 时独立地从概率质量分布 中抽样。
利用FractalDB进行预训练,可以使用交叉熵损失函数:
其中 是由神经网络预测的类别分布,而 是一组可学习的参数。样本数据集上的联合经验分布 可以如下定义:
其中 代表Dirac’s delta函数。在这样的数据集上预训练的模型,在某些下游任务中的性能可以与在Real-world图像数据集(如ImageNet-1k和Places365)上进行预训练的模型相当。
-
OFDB
OFDB这个数据集由1,000张分形图像组成。具体来说,OFDB的 只涉及每个类别的一个代表性图像,即 。因此,联合经验分布简化为:
在这个数据集上预训练的模型的表现甚至优于或与在FractalDB上预训练的模型相当。这项工作表明,存在一小部分关键的图像用于视觉预训练。然而,将分形图像的数量 减少到小于1,000会降低性能。
Pre-training with a Single Fractal
-
Scaling backwards
为了进一步促进对成功视觉预训练所需最少图像的分析,论文提出了1p-frac,最终将IFSs和图像数量减少到一个,即 。使用这个数据集时,经验分布如下:
然而,论文注意到,使用交叉熵损失函数训练神经网络并不有效,因为 会导致损失最小化的平凡解。为了解决这个问题,引入了局部扰动交叉熵(LPCE)损失 ,这是一种基于LIEP分布定义的交叉熵损失的变体。
Definition 1:让 是一个受扰动的图像,其中 是图像集合, 是一个满足 的小扰动, 是原始图像。通过以下方式定义LIEP分布:
其中 是包含原点的集合, 是其体积,阶数为 。
Definition 2:通过以下方式定义LPCE损失:
其中 是LIEP分布。
如果 是一个小的超立方体或超球体,当 趋近于零时, 逼近于公式6的经验分布。因此,这种损失允许通过将分布的支撑缩小到单个图像周围来分析视觉预训练效果。
基于1p-frac,对仿射变换进行扰动。这样,扰动 就在 中。通过带噪声的仿射变换得到一个受扰动的图像 :
其中 是一个边长为 的超立方体, 。请注意,在实践中使用了公式7的数值积分,这是通过在 中均匀采样 个点得到的近似值,其中默认设置 。
-
Visualization
图3b展示了用于计算LPCE损失的受扰动图像的示例。虽然大多数形状差异对人类来说是无法区分的,但神经网络通过最小化LPCE损失来学习区分应用于单个图像的扰动。
-
Complexity of
使用 因子来评估IFS的复杂性。如图3c所示,较小的 值会产生复杂的分形形状。
Experiments


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!