
AIGC时代,仅用合成数据训练模型到底行不行?来一探究竟 | CVPR 2024
首个针对使用合成数据训练的模型在不同稳健性指标上进行详细分析的研究,展示了如
SynCLIP和SynCLR等合成克隆模型,其性能在可接受的范围内接近于在真实图像上训练的对应模型。这一结论适用于所有稳健性指标,除了常见的图像损坏和OOD(域外分布)检测。另一方面,监督模型SynViT-B在除形状偏差外的所有指标上均被真实图像对应模型超越,这清楚地表明了对更好监督合成克隆的需求。通过详细的消融实验,作者发现使用描述或CLIP模板可以产生更稳健的合成克隆。重要的是,将真实数据与合成数据混合可以改善大多数指标上的稳健性衡量。来源:晓飞的算法工程笔记 公众号
论文: Is Synthetic Data all We Need? Benchmarking the Robustness of Models Trained with Synthetic Images

Introduction
现代机器学习方法的性能瓶颈主要受到标签数据的质量和数量的限制。多个研究表明,神经网络的泛化误差遵循与数据集大小相关的神经缩放法则,即测试误差随着数据集大小的对数线性减少。此外,数据集的多样性和公平性也是影响现代神经网络泛化性能的重要因素。不幸的是,整理多样、公平且规模庞大的数据集既耗时又昂贵。
大规模图像生成模型的出现,如Stable Diffusion,重新激发了利用生成图像训练模型以执行各种下游任务的兴趣,期望减轻对高质量注释的需求。有研究仅使用来自Stable Diffusion生成的图像对下游分类器进行监督训练,还有的研究仅使用合成图像和提示训练自监督模型(如SimCLR)和多模态模型(如CLIP)。这些模型在下游任务(如分类和分割)中能够与基于真实数据训练的模型相媲美或超越,作者将只使用生成数据进行训练的这类模型称为合成克隆(synthetic clones)。
现代机器学习模型越来越多地被应用于解决诸如自动驾驶和自动医疗辅助等现实问题。随着合成数据在训练模型中的快速进展,必须了解这些模型在现实世界中部署前的鲁棒性。关于合成克隆的最新研究尚未集中于评估这些模型的鲁棒性。然而,已知在合成或生成数据集上训练的模型会遭遇一些缺陷,例如模型崩溃,即模型遗忘长尾类别或学习到与训练数据集不同的分布。
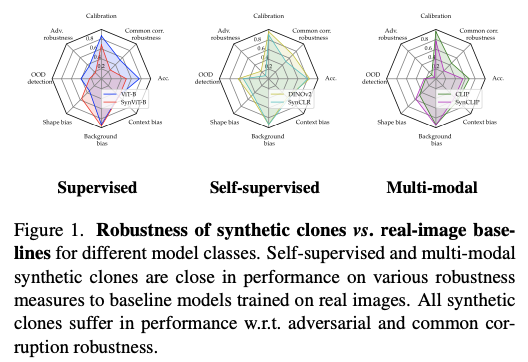
作者旨在提供一个综合基准,以评估合成克隆模型与在真实图像数据集上训练的最先进(SOTA)基线模型的鲁棒性。将三类合成克隆模型——监督型、自监督型和多模态模型——与九个使用真实图像训练的强基线模型进行基准测试。作者评估了与形状、背景和上下文偏差相关的鲁棒性指标,还将这些模型与对抗性攻击和常见图像破坏进行基准测试。最后,作者测试了这些模型与使用真实数据训练的模型相比,在校准方面的表现,如图1所示。
为克服仅使用合成数据带来的某些缺陷,作者进行广泛的消融实验,研究合成克隆的鲁棒性如何随着以下因素而变化:(i)与合成数据和真实数据的联合训练;(ii)合成样本数量的增加;以及(iii)在使用Stable Diffusion生成图像时提示的影响。
作者的发现可总结为:在许多鲁棒性指标(校准、背景偏差、形状偏差等)方面,使用合成数据训练的自监督和多模态模型的表现与其在真实图像上训练的模型相当。
Background: Synthetic Clones
在下面分析各种合成克隆模型之前,简要回顾一下如何使用Diffusion模型生成合成图像,以及各种类别的模型是如何在这些合成图像上进行训练的。
-
Synthetic data generation
合成克隆模型中的合成图像通常是使用大规模预训练的图像生成模型生成的,例如Stable Diffusion或Imagen。生成模型的输入是高斯噪声和条件文本提示。合成克隆可以分为三类,即监督合成模型、自监督合成模型和多模态合成模型。
-
Supervised models using generated data
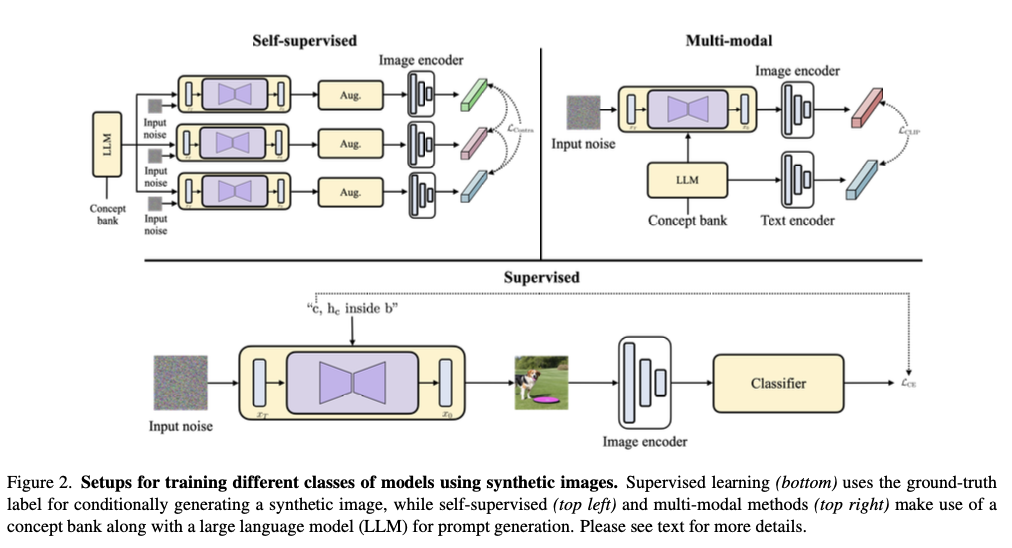
为了训练一个有监督的分类器,首先使用Stable Diffusion生成一幅图像,条件是提示“c, \(\text{h}_\text{c}\) inside b”。这里,c 是从数据集(例如ImageNet-1K)的所有类标签中随机采样得到的真实类别名称, \(\text{h}_\text{c}\) 是与 c 相关联的上义词(hypernym),b 表示Places365数据集中的365个类别之一。在WordNet层次结构中,c 的上义词是 c 在层次结构中的父节点。然后用生成图像的预测标签和用于生成图像的采样真实类别标签之间交叉熵损失( \(\mathcal{L}_\text{CE}\) )对分类器进行端到端训练,如图1(底部)。有研究创建了120万这样的提示,并生成相应图片来训练一个ResNet50模型。同样地,还有研究只使用类名c来生成1600万张图片,然后用生成图片和真实类别标签来训练ViT-B模型。
-
Self-supervised models using generated data
合成自监督模型即SynCLR和StableRep,首先从一个概念库中随机抽样一个概念标签。这个概念库通常是使用WordNet提取的同义词集或来自Wikipedia的常见单词、双字词组和标题构建的。然后将这个抽样的概念标签输入到一个大型语言模型(LLM)中,用于生成额外的上下文信息。最终提示由概念标签和上下文信息连接而成。然后使用这个提示来生成 \(n\) 张图像。之后,还会应用一些在SimCLR模型中也使用的增强(Aug.)。SynCLR模型使用多正对比损失( \(\mathcal{L}_\text{Contra}\) )进行训练,如图1(左上角)。
-
Multi-modal model using generated data
多模态合成CLIP模型也使用从概念库中随机抽样的概念标签。这个概念标签连同从Places365数据集的类别中随机抽样的一个随机地点标签一起输入到一个LLM中,用于生成一个标题,随后用于条件图像生成。这些图像用于使用生成的图像和用于生成图像的提示之间的对比损失来训练CLIP模型,如图1(右上角)所示。
Robustness Analysis
Setup
将要分析的模型分为监督模型、自监督模型和多模态模型。
对于合成的监督模型,使用了来自于现有合成监督研究的ResNet50和ViT-B模型,这些模型在大约1M使用提示生成的图像上进行训练。用于创建提示的类标签是从ImageNet-1K数据集的类中抽样得到的。为清晰起见,将它们在所有实验中称为SynResNet50和SynViT-B。将这些模型与在真实ImageNet-1K数据集上训练的强监督模型进行比较,如ResNet50、ViT-B、DeiT-III、Swin变换器和Conv-NeXt,所有基线模型均来自PyTorch图像模型库。
在自监督的情况下,使用了SynCLR模型,该模型在600M合成图像上进行了训练。使用诸如DINOv2、MAE和MOCOv3(在ImageNet-1K上训练)的最先进自监督模型作为自监督基线,所有基线模型的检查点均来自timm库。为了公平比较,对所有模型使用具有16的块大小的ViT-B骨干网络。对所有自监督模型进行线性探测,在这些模型的顶部训练一个单层线性分类头,使用ImageNet-1k数据集进行90个周期的训练。我们搜索了十个学习率,以找到每个模型的最佳线性分类器。
最后,对于多模态的情况,分析了来自于的合成CLIP模型,称之为SynCLIP,该模型在371M合成图像上进行了训练。将此模型与来自OpenCLIP的CLIP实现进行比较,该实现是在400M真实图像上训练的。使用ViT-B骨干网络来允许公平比较。对于CLIP和SynCLIP,我们报告了零样本结果。
Calibration
随着神经网络开始应用于像自动驾驶和医疗保健这样的安全关键任务,不仅要预测准确,还要准确报告其预测的置信度。校准可以帮助理解模型预测的可靠性以及最终用户是否可以信任模型的输出。神经网络的校准通常使用期望校准误差(ECE)来衡量。ECE衡量了模型置信度与模型准确性之间的期望绝对差异。在作者的研究中,研究了与使用真实数据训练相比,在合成图像上训练对模型校准的影响。
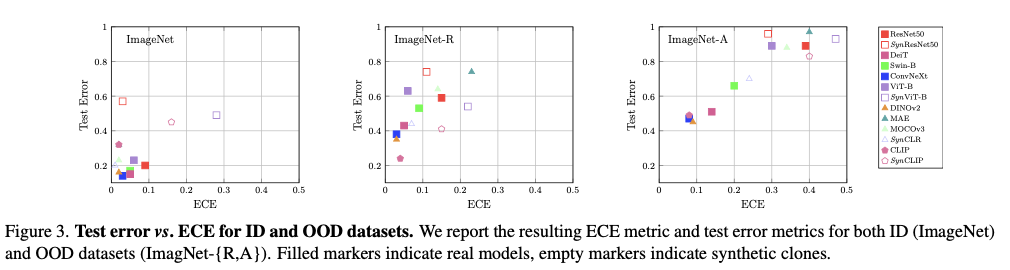
ECE指标的结果如图3所示,分别为在ImageNet-1k数据集上进行分布内(ID)校准(训练和测试分集来自同一数据集)的结果,以及在ImageNet-R和ImageNet-A 数据集上进行分布外(OOD)校准(训练和测试分集来自不同数据集)的结果。可以得出以下结论:
Observation 1: 合成克隆在分布内情况下大多数是校准良好的,甚至在某种程度上也适用于在
ImageNet-R上的分布外。但是在ImageNet-A上,合成克隆的外部分布校准效果较差。
这可能是因为从预训练Diffusion模型(在从网络上抓取的数据上进行训练)生成的合成数据已经捕捉到了ImageNet(从网络上抓取的图像)和ImageNet-R(由丰富的卡通和素描组成,这些内容在互联网上广泛存在)数据集的分布。另一方面,ImageNet-A数据集包含了在互联网上很难找到的自然对抗示例。因此,合成克隆和基线模型在这个数据集上都表现出较差的校准结果。然而,使用真实数据集训练的模型通常对ImageNet-A的校准效果更好,可能是由于数据集中固有的噪音造成的。
-
Out of distribution (OOD) detection
OOD检测对增强最终用户对模型的安全性和可靠性的信任至关重要,因此需要评估在合成数据上训练对模型OOD检测能力的影响,确定一个模型在多大程度上能够区分来自训练数据分布(ID)的样本和来自另一种分布的样本。
OOD检测任务可以被表述为模型预测概率上的二分类任务。对于权重为 \(\theta\) 的模型 \(F\),如果该样本的最大预测概率高于预定义的阈值 \(\tau\) ,即 \(\max F_\theta (x_i) \geq \tau\) ,则将输入样本 \(x_i\) 分类为ID;如果 \(\max F_\theta (x_i) < \tau\) ,则分类为OOD。OOD检测可以使用二分类的标准指标进行评估,例如AUROC。另外,作者还报告了在分布内样本的真正例率为95%时OOD样本的假阳性率(FPR@95)。
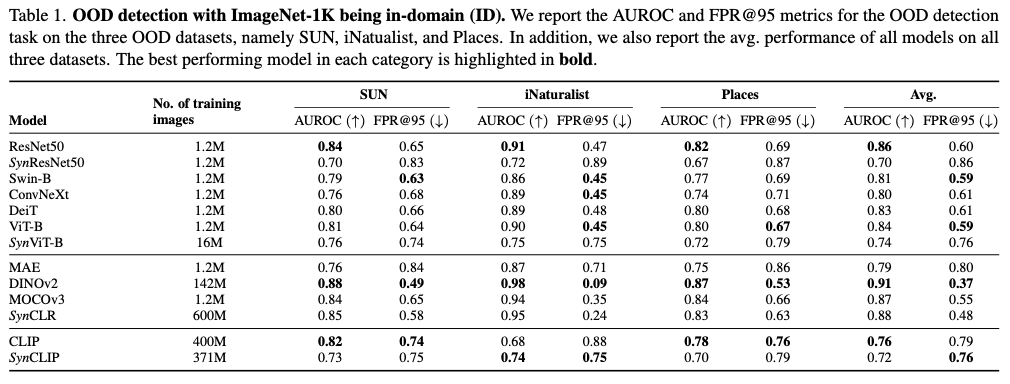
表1显示了所有模型在三个OOD数据集上的结果,即SUN397、Places365和iNaturalist,其中ImageNet-1K是ID数据集。可以得出以下结论:
Observation 2:在
OOD检测方面,SynCLR和SynCLIP与其类别中的基准模型相媲美。即使比基准模型多16倍的数据,SynViT-B在OOD检测方面仍明显落后于用真实数据训练的监督模型。
Robustness
-
Adversarial robustness
对抗学习旨在了解模型对于由对手操纵的例子的鲁棒性,这些例子在人眼看来似乎相似,但会改变模型的预测。作者想要探究在合成数据上训练的模型是否更容易受到对抗性攻击,使用了两种流行的白盒攻击方法,即快速梯度符号法(FGSM)和投影梯度下降(PGD)攻击。这些白盒攻击需要对手了解模型的梯度。FGSM攻击通过模型的预测梯度相对于其输入的缩小步长 \(\epsilon\) 来扰乱输入图像,可以写成 \(\hat{x}_{i} = x_{i} + \epsilon \nabla_{x_{i}} J(\theta, x_{i}, y_{i})\) ,其中 \(x_{i}\) 表示输入图像, \(\nabla_{x_{i}} J\) 表示损失函数相对于 \(x_{i}\) 的梯度, \(y_{i}\) 表示输入图像 \(x_{i}\) 的标签。PGD攻击是FGSM攻击的迭代版本,随后将对抗性输入的投影限制在围绕输入 \(x\) 的 \(\epsilon\) 球内。 \(\epsilon\) 值表示允许的最大扰动。作者在PGD和FGSM攻击中使用 \(\epsilon\) 值为1/255,PGD攻击的步数设置为20。
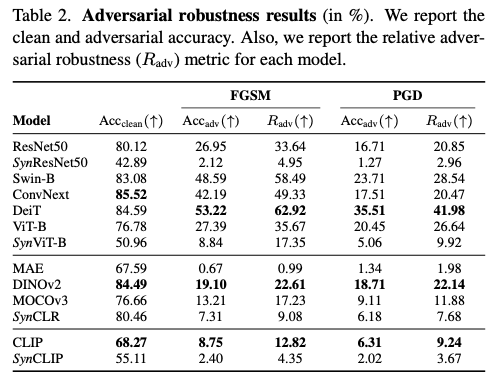
作者报告了测试集中干净和对抗性样本的准确率,将对抗鲁棒性指标 \(R_{\text{adv}}\) 定义为对抗性和清洁样本之间相对准确率,公式为 \(R_{\text{adv}} = \frac{\text{Acc}_{\text{adv}}}{\text{Acc}_{\text{clean}}}\) ,其中 \(\text{Acc}_{\text{adv}}\) 是对抗性样本的准确率, \(\text{Acc}_{\text{clean}}\) 是清洁样本的准确率。可以得出以下结论:
Observation 3:合成克隆模型在面对对抗性示例时明显更易受攻击,尤其是监督式合成克隆模型,相比于用真实数据训练的模型。通过大量合成数据训练的自监督合成克隆模型,即
SynCLR,在其相应类别中与真实图像基准模型略有可比。
作者发现MAE在所有模型(包括合成模型和真实模型)中表现最差,这表明训练目标以及训练数据集的大小是决定模型对抗鲁棒性的重要因素。
-
Robustness against common corruptions
接下来,评估所有模型在现实世界中常见的噪声损坏下的表现,在ImageNet-C和ImageNet-3DCC数据集上进行评估。ImageNet-C包含19种自然发生的图像损坏,如高斯噪声、爆发噪声、运动模糊、弹性变换等。比如ImageNet-3DCC包含12种常见的考虑了深度因素的损坏,例如 \(z\) 轴模糊、远近聚焦误差等。
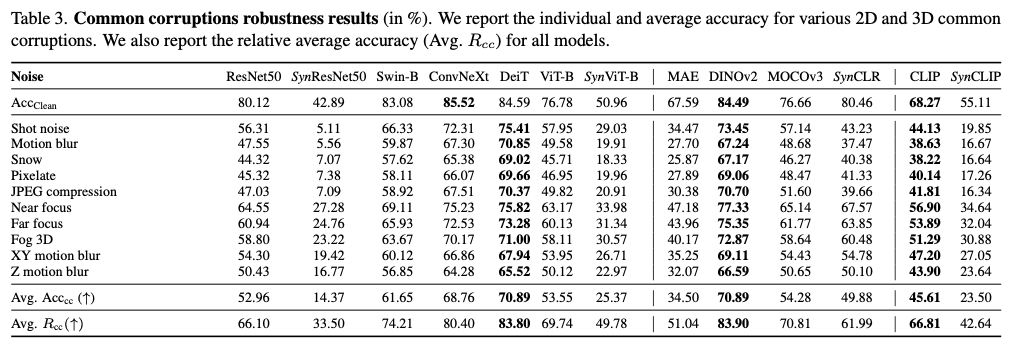
由于时间和资源的限制,作者仅报告十个常见损坏任务的结果(每个数据集各五个),分别清晰样本和损坏样本的准确率以及所有损坏的平均准确率。作者还报告平均 \(R_\text{cc}\) 指标,该指标定义为清晰样本与所有损坏平均准确率之间的相对准确率,即 \(AVG. R_\text{cc}=\frac{\text{Avg. Acc}_\text{cc}}{\text{Acc}_{\text{clean}}}\) 。结果见表3,可以得出以下结论:
Observation 4:与用真实图像训练的基准模型相比,合成克隆在图像常见损坏方面明显不够稳健。
所有类别的模型中,合成克隆的平均 \(R_\text{cc}\) 明显较低。真实数据集中的图像本身就存在这些常见的损坏,因此在真实数据上训练已经能够使得结果模型对噪声更加稳健。目前合成图像缺乏这些损坏,使得合成克隆对常见图像损坏非常敏感。
Biases
-
Context bias
定义上下文偏差为模型倾向于使用上下文线索,例如位置来对物体进行分类,而不是实际使用物体外观。这种上下文偏差存在是因为大多数大规模数据集由从互联网上获取的未加筛选的数据组成。例如,与飞机在跑道上相比,飞机在森林中的图像几乎不可能存在。使用FOCUS(Familiar Objects in Common and Uncommon Settings)数据集来评估上下文偏差,该数据集包含大约21,000张图像。数据集中的每个图像都带有对象类别、时间、位置和天气标签的注释。
FOCUS将数据集分成常见样本和不常见样本的子集。不常见样本在现实世界中很少见,例如“飞机在森林中”,或者在ImageNet数据集中由于用于构建的标签而罕见(例如,ImageNet中没有海上飞机的标签)。数据集被划分为互斥的分区 \(P_k\) ,其中 \(k\) 是不常见属性的数量。总数据集被划分为四个分区,从 \(P_0\) (仅包含常见对象) 到 \(P_3\) (包含三个不常见属性)。
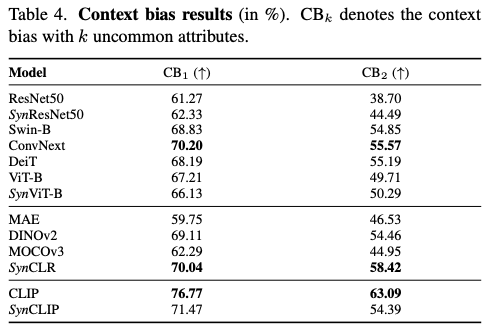
作者报告了 \(\text{CB}_k\) 指标(具有 \(k\) 个不常见属性的上下文偏差),它定义为在没有不常见属性的分区 \(P_0\) 上的准确率与具有 \(k\) 个不常见属性的分区 \(P_k\) 上的准确率之间的相对准确率,即 \(\text{CB}_k = \frac{\text{Acc}_{P_k}}{\text{Acc}_{P_0}}\) 。例如, \(\text{CB}_2\) 衡量了 \(P_0\) 和 \(P_2\) 之间的相对准确率。结果见表4,可以得出以下结论:
Observation 5:与用真实数据训练的基准监督模型和自监督模型相比,自监督合成克隆对上下文变化具有更强的稳健性。监督合成克隆
SynViT-B的性能与在真实数据上训练的ViT-B模型相当。同时,SynCLIP对上下文变化更为敏感,但其性能仍可与DINOv2和ConvNeXt等模型相媲美。
-
Shape-texture bias
儿童学会根据形状辨认和组织物体,并更偏向于物体形状而非颜色和纹理。已经证明,将网络偏向形状可以增强其对常见失真的鲁棒性。这表明,神经网络的鲁棒性通常受益于将物体以形状而非纹理进行分类的偏好。生成自生成对抗网络(GANs)的图像通常具有高频率伪影(表明高纹理偏差)。Diffusion模型也表现出类似的模式,尽管这些模式更加淡化。这些伪影与真实图像形成鲜明对比,真实图像中不包含这些高频率伪影。为了解是否在Stable Diffusion的合成图像上训练会使网络偏向纹理,作者使用了cue conflict数据集。该数据集包含大约1200张图像,属于16个类别,其中图像的纹理和形状相互冲突。
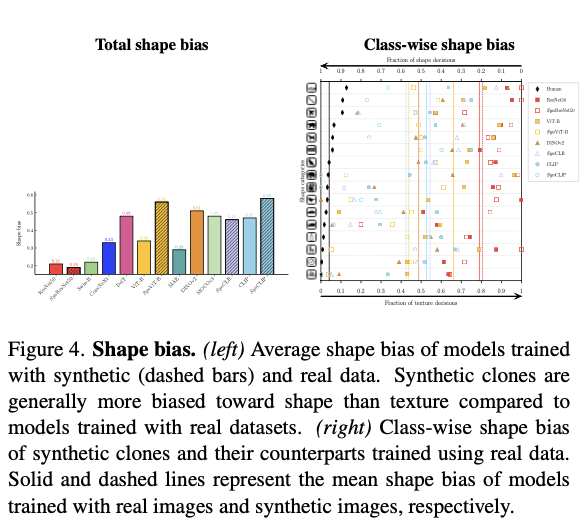
图4展示了所有模型的分类平均形状偏差,作者还展示了合成克隆和一些基准模型的类别形状偏差结果。可以得出以下结论:
Observation 6:合成克隆在形状偏差上往往比在纹理偏差上更为明显。特别是,
SynCLIP在形状偏差指标上优于所有模型,而SynViT-B在所有分类和自监督模型中表现最佳。SynCLR模型的性能与MOCOv3模型comparable,并在形状偏差指标上优于MAE模型。
在StyleGANv2的合成数据中也观察到了类似的结果。作者的结果表明,合成数据在形状上具有多样性,导致合成克隆模型更倾向于形状偏差,但这可能表明生成的图像缺乏纹理的多样性,使网络更依赖形状进行分类。
-
Background bias
模型的背景偏好可以用来确定模型是否利用图像的背景而不是利用对象本身来做出分类决策。了解模型是否偏向于背景是一种有效的方式,可以帮助我们了解模型是否学习了捷径而非为给定类别学习良好的特征。为了评估模型的背景偏好,利用来自IN-9L数据集的Mixed-Rand和Mixed-Same分区。Mixed-Rand数据集将图像中的前景对象进行分割,并将原始背景与不同类别标签的随机背景进行替换,而Mixed-Same分区则将分割的前景对象放置在相同类别标签的随机背景上。
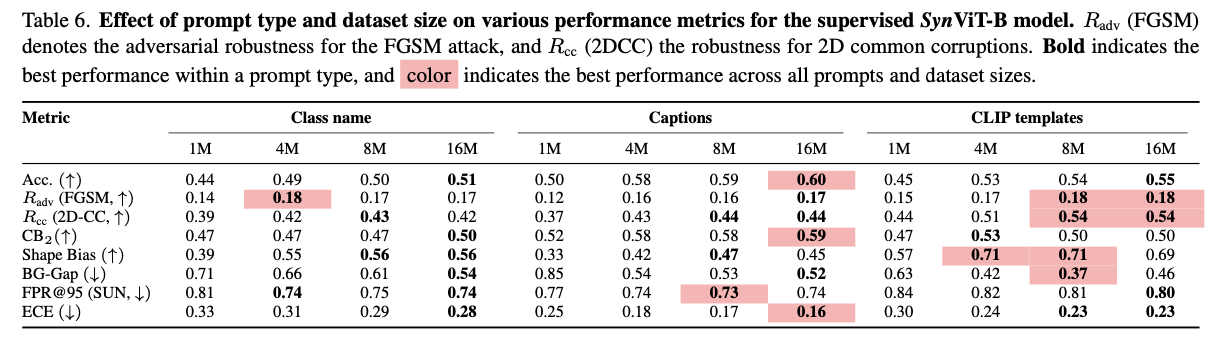
表6显示了所有模型在IN-9L数据集的原始、Mixed-Rand和Mixed-Same分区上的准确率,以及BG-Gap。BG-Gap衡量了在Mixed-Rand和Mixed-Same数据集上准确率之间性能差异,并评估了通过将背景更改为与前景不同类别来操纵决策的可能性。可以得出以下结论:
Observation 7:合成克隆模型在背景偏差方面与使用真实数据训练的
SOTA基线模型表现相当。
总的来说,作者发现所有模型(合成和真实)对于背景变化都非常稳健。
Ablations
通过消融实验(包括所有CLIP模型)分析影响合成克隆模型稳健性的三个重要因素。
-
Effect of prompts
在这里,分析了提示对合成克隆模型稳健性的影响。表7显示了使用不同提示(例如:(i)类别名称,(ii)80个CLIP模板,例如“{类别名称}的高质量照片”,用于评估CLIP模型的零样本分类性能,以及(iii)类别名称与来自BLIP2生成的标题组合,例如“Tench[类别标签],一个拿着鱼的人”训练的SynViT-B合成图像模型的结果。从表6可以看出,与仅使用类别名称相比,标题和CLIP模板更适合创建稳健的合成克隆模型。这可以归因于生成了更多描述性文本的多样化图像。
-
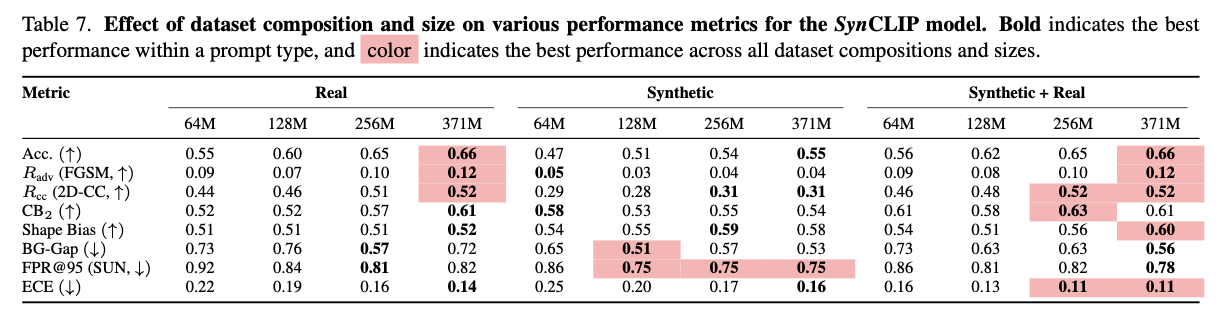
Effect of adding real data
接下来,研究在CLIP模型的稳健性上使用真实图像和合成图像数据混合的影响。我们对CLIP模型进行了训练,使用固定的数据集大小(例如371M张图像),其中真实和合成图像被随机选择以创建一个包含真实和合成图像的子集,然后用于训练CLIP模型。表7显示,根据建议添加真实数据可以改善许多关键指标(如ECE、对抗性准确度、形状偏差),同时在其他指标上保持可比性。此外,作者发现仅使用合成图像或合成与真实图像结合进行训练可创建比仅针对真实数据进行训练更稳健的模型。
-
Size of generated data
作者评估了数据集大小对合成克隆训练的影响。通常情况下,增加数据有助于提高SynViT-B和SynCLIP模型的稳健性。在某些情况下,增加更多数据可能会稍微降低性能,这可能是由于增加数据集大小导致数据集多样性减少,以及模型过度拟合于较少多样化的数据造成的。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号