
RealNet:从数据生成到模型训练的最新工业异常检测 | CVPR 2024
论文提出了一种创新的自监督异常检测框架
RealNet,集成了三个核心组件:可控制强度的扩散异常合成(SDAS)、异常感知特征选择(AFS)和重构残差选择(RRS)。这些组件通过协同作用,使RealNet能够有效地利用大规模预训练模型来进行异常检测,同时保持计算开销在合理的低范围内。RealNet为未来利用预训练特征重构技术进行异常检测的研究提供了灵活的基础。通过大量实验,展示了RealNet在处理多样化的实际异常检测挑战方面的能力来源:晓飞的算法工程笔记 公众号
论文: RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection

Introduction
图像异常检测在工业生产中是一项关键任务,广泛应用于质量控制和安全监测。虽然自监督方法在使用合成异常训练模型方面备受关注,但仍然面临着合成逼真和多样化的异常图像的挑战,特别是在生成复杂的结构异常和未知的异常类别方面。由于缺乏可用的异常图像和关于异常类别的先验知识,现有方法依赖于精心设计的数据增强策略或外部数据进行异常合成,导致合成异常与真实异常之间存在显著的分布差异,从而限制了异常检测模型在真实应用中的泛化能力。

为了解决这些问题,论文介绍了一种名为可控强度扩散异常合成(SDAS)的新型合成策略,生成更接近自然分布的多样化样本,并具有灵活控制异常强度的特性。SDAS采用DDPM 对正常样本的分布进行建模,并在抽样过程中引入扰动项,以在低概率密度区域生成样本。如图1所示,这些样本模拟了各种自然异常模式,例如老化、结构变化、异常纹理和颜色改变。
同时,基于特征重构的异常检测是另一个有前途的研究方向,将异常图像的特征重构为正常图像的特征,并通过重构残差进行异常检测和定位。由于其简单的范例,这种方法受到了广泛关注。然而,由于特征重构的高计算需求和缺乏有效的特征选择策略,现有方法要么使用小规模的预训练CNN网络进行异常检测,要么手动从预训练网络中挑选特定的层特征进行重构。最新的工作强调了特征选择的重要性,指出现有的异常检测方法对特征选择非常敏感。对于不同的类别,异常检测的最佳预训练特征子集是不同的。因此,设计一个统一的特征选择方法已经成为推进异常检测的迫切需求。
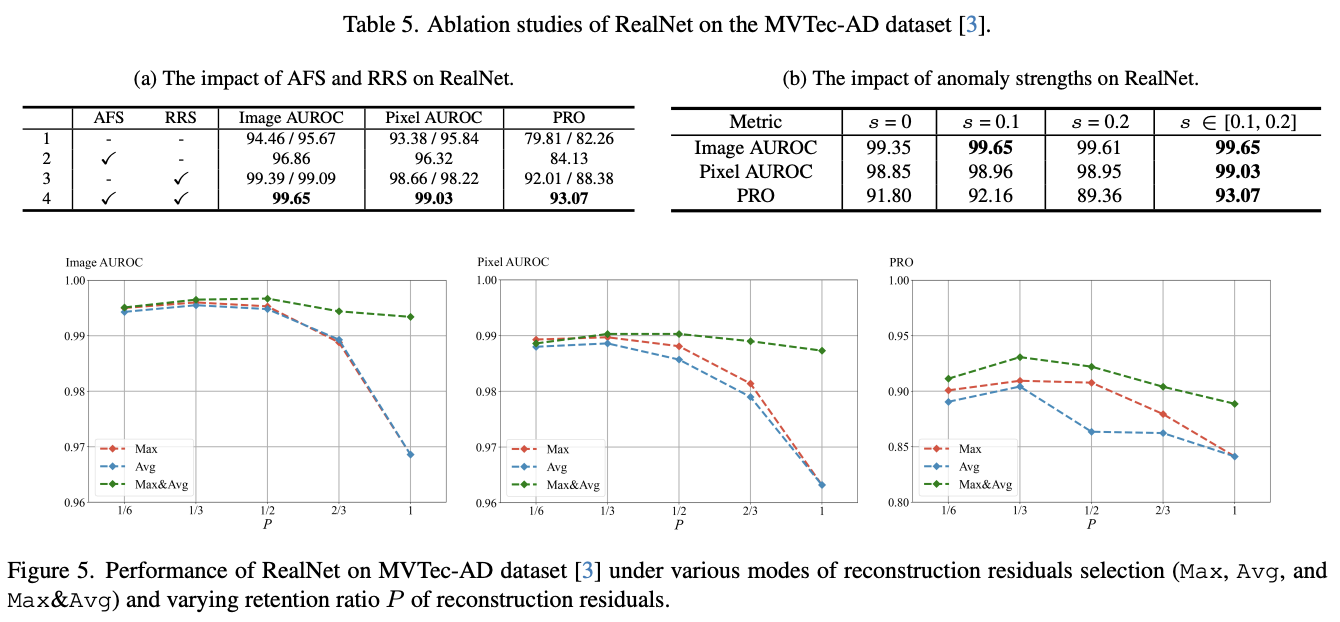
论文提出了一个名为RealNet的特征重构框架,集成了异常感知特征选择(AFS)和重构残差选择(RRS)。RealNet充分利用了大规模预训练CNN网络的区分能力,同时减少特征冗余和预训练偏差,增强了异常检测性能并有效控制了计算需求。对于不同的类别,RealNet选择了不同的预训练特征子集进行异常检测,确保了最佳的异常检测性能,同时灵活控制了模型的大小。此外,RealNet通过自适应丢弃缺乏异常信息的重构残差,有效减少了漏检,并显著提高了异常区域的召回率。
总之,论文的贡献有以下四方面:
- 提出
RealNet,这是一个特征重构网络,通过自适应地选择预训练特征和重构残差,有效地利用多尺度预训练特征进行异常检测。RealNet在解决先前方法所遇到的计算成本限制的同时,取得了最先进的性能。 - 介绍了一种名为可控强度扩散异常合成(
SDAS)的新型异常合成策略,能够生成与自然分布密切相关的逼真且多样化的异常样本。 - 在四个数据集(
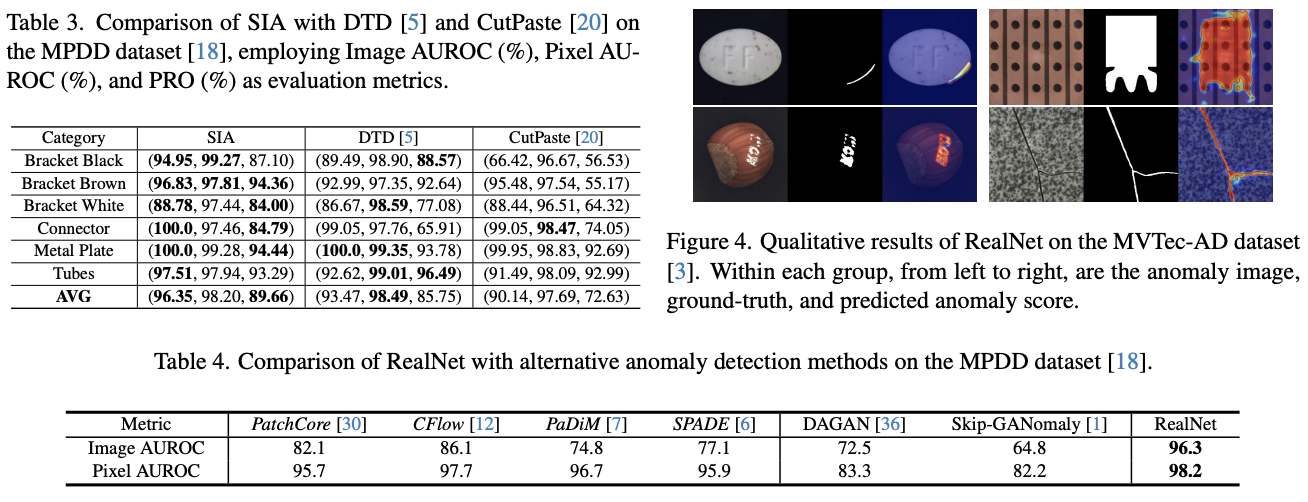
MVTec-AD、MPDD、BTAD和VisA)上对RealNet进行了评估,使用相同的网络架构和超参数集合在不同的数据集上超越了现有的最先进方法。 - 提供了合成工业异常数据集(
SIA),由SDAS生成的,包含了来自36个工业产品类别的总共36,000张异常图像。SIA可以方便地用于异常合成,以促进自监督异常检测方法的应用。
Related work
无监督的异常检测和定位方法仅使用正常图像进行模型训练,没有任何异常数据。这些方法大致可以分为四个主要类别:基于重构的方法、自监督学习方法、基于深度特征嵌入的方法和基于单类分类的方法。论文关注基于重构和自监督学习的方法,这与RealNet框架特别相关。
- Reconstruction-based methods
基于重构的方法遵循一个相对一致的范式,即在正常图像上训练一个重构模型。由于无法有效地重构输入图像中的异常区域,通常需要通过比较原始图像和重构图像来实现异常检测和定位。在这种情况下,研究者探索了各种重构技术,如Autoencoder、GAN、Transformer和Diffusion model。然而,管理网络的重构能力仍然具有挑战性。在复杂的图像结构或纹理的情况下,网络可能会产生一个简化的拷贝,而非选择性的重构。此外,原始图像和重构图像之间固有的风格差异可能会导致误报或未检测到的异常。
最近的研究主要集中在通过对预先训练的图像特征进行重构来进行异常检测。相较于图像级别的重构,预先在ImageNet上训练好的多尺度特征展现出了增强的区分能力,能够检测各种尺度范围和不同的图像模式中的异常。然而,由于高维特征中的固有特征冗余以及由分类任务引入的预训练偏差,大规模预先训练网络的异常检测能力尚未得到充分利用。
最近的研究使用小规模预训练网络来确保可控的重构成本,而其他研究则手动选择来自预训练网络的部分层特征进行异常检测。然而,用于异常检测的最佳特征子集在不同类别之间变化较大,因此这些手动选择的方法往往是特定于数据集且次优的,导致性能显著下降。
与以往的解决方案不同,RealNet提出了一种有效的特征选择策略和优化重构过程的创新组合,有效提升了异常检测性能,同时保持了计算效率。
- Self-supervised learning-based methods
自监督学习方法旨在通过设定适当的代理任务,避免需要异常图像的标签。在这一领域中,一些著名的工作包括CutPaste,通过将图像补丁从一个位置移植到另一个位置来产生异常,尽管这样产生的异常区域的连续性不够理想。NSA 使用Poisson图像编辑实现无缝图像粘贴,合成更自然的异常区域。DRAEM利用纹理数据集DTD合成各种纹理异常,并实现了先进的自监督异常检测性能,但在面对特定的结构性异常,例如部分丢失或错位的元素时表现不佳。
自监督异常检测方法的性能取决于代理任务与真实异常检测任务的紧密程度。作为异常检测中的基础研究,异常合成尚未受到广泛的探索。最近的研究使用StyleGAN2进行图像编辑,生成异常图像。然而,该方法依赖于真实的异常图像,无法生成未见过的异常类型。
相比之下,SDAS在概率空间中运作,不受数据增强规则或现有数据的限制,能够有效控制异常的强度,并且仅使用正常图像就能生成逼真且多样化的异常图像。
Method
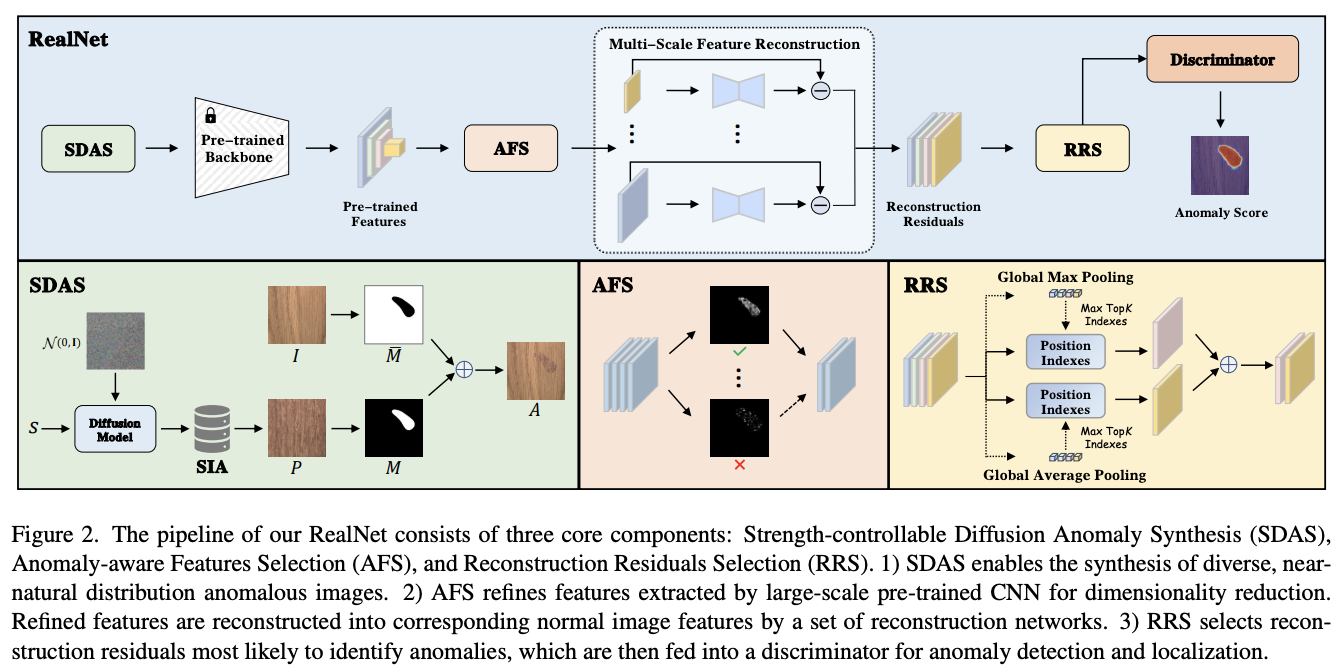
论文提出的特征重构框架RealNet,由三个关键组成部分组成:可控强度扩散异常合成(SDAS)、异常感知特征选择(AFS)和重构残差选择(RRS)。
Strength-controllable Diffusion Anomaly Synthesis
去噪扩散概率模型(DDPM)采用正向扩散过程,逐步向原始数据分布 \(q(x_0)\) 添加噪声 \(\mathcal N(0,\textbf{I})\) 。在时间 \(t\) ,噪声数据 \(x\_t\) 的条件概率分布为 \(q(x\_t|x_{t-1})=\mathcal N(x_t;\sqrt{1-\beta\_t}x_{t-1},\beta_t\textbf{I})\) ,其中 \({\beta\_t}_{t=1}^T\) 是固定的方差时序, \({x_t}_{t=1}^T\) 是潜在变量。扩散过程被定义为一个马尔科夫链,具有联合概率分布 \(q(x_{1:T}|x\_0)=\prod_{t=1}^{T}q(x_t|x_{t-1})\) 。根据高斯随机变量的总和规则,时间 \(t\) 时 \(x_t\) 的条件概率分布为 \(q(x\_t|x\_0)=\mathcal N(x\_t;\sqrt{\bar{\alpha}\_t}x\_0, (1-\bar{\alpha}\_t)\textbf{I})\) ,其中 \(\alpha\_t=1-\beta\_t\) , \(\bar{\alpha}\_t=\prod_{i=1}^{t}\alpha\_i\) 。
反向过程被描述为另一个马尔科夫链,其中反向过程的均值和方差由 \(\theta\) 参数化,即 \(p_\theta(x_{t-1}|x_t)=\mathcal N(x_{t-1};\mu_\theta(x\_t,t),\Sigma_\theta(x_t,t))\) 。有多种方法可以对 \(\mu_\theta(x_t,t)\) 进行建模,通常情况下,使用神经网络 \(\epsilon_\theta(x_t,t)\) 对扩散过程中的噪声 \(\epsilon\) 进行建模,从而得到 \(\mu_\theta(x_t,t)=\frac{1}{\sqrt{\alpha\_t}}(x\_t-\frac{\beta\_t}{\sqrt{1-\bar{\alpha}\_t}}\epsilon_\theta(x\_t,t))\) 。
在训练阶段,目标是最小化负对数似然的变分上界,从而得到简化的目标函数:
为了生成逼真的异常图像,首先训练一个扩散模型,使用公式1来学习正常图像的分布。在由 \(p_\theta(x_{t-1}|x_{t})=\mathcal N(x_{t-1};\mu_\theta(x\_t,t),\Sigma_\theta(x_t,t))\) 描述的逆扩散过程中, \(x_{t-1}\) 是在时间 \(t-1\) 获得的正常图像。由于异常图像位于靠近正常图像的低密度区域,引入了一个额外的扰动 \(s\Sigma\) 来采样异常图像,得到 \(p(x_{t-1}'|x_{t-1})=\mathcal N(x_{t-1}';x_{t-1},s\Sigma)\) ,其中 \(\Sigma\) 是引入的额外方差,标量 \(s\) 控制异常强度 \((s \geq 0)\), \(x_{t-1}'\) 是在时间 \(t-1\) 获得的异常图像。为了简化异常合成过程,设置 \(\Sigma=\Sigma_\theta(x_t,t)\) ,由此异常图像 \(x_{t-1}'\) 的条件概率分布可以写成以下形式:
为了确保生成的异常图像接近于正常图像的分布,将 \(s \rightarrow 0\) 得到 \(x_{t-1}' \approx x_{t-1}\) ,然后将 \(x_{t-1}'\) 用于反向扩散过程的下一个时间,最终形式为 \(p_\theta(x_{t-1}'|x_{t}')=\mathcal N(x_{t-1}';\mu_\theta(x_t',t),(1+s)\Sigma_\theta(x\_t',t))\) 。

论文将这个过程称为可控强度的扩散异常合成(Strength-controllable Diffusion Anomaly Synthesis,SDAS),详见算法1。具体而言,如果将 \(s\) 设置为0,SDAS将生成正常图像。
为了在训练异常检测模型时将这些异常图像纳入考虑,遵循Draem中提出的方法,利用Perlin噪声生成器来捕捉各种异常形状,并将其二值化为异常掩模 \(M\) 。将正常图像表示为 \(I\) ,由SDAS生成的异常图像表示为 \(P\) ,通过图像混合合成局部异常的图像表示为 \(A\) :
其中, \(\overline{M}=1-M\) , \(\odot\) 表示逐元素相乘操作, \(\delta\) 是图像混合中的不透明度。

为了确保生成的异常区域位于前景中,使用了基于自适应阈值的前景分割二值化方法。图3a显示了在不同异常强度下由SDAS生成的图像,而图3b则比较了不同方法合成的局部异常区域的图像。 \(s\) 值越大,生成图像与正常图像之间的分布差异越大,经过图像混合后获得的异常区域也就越明显。当 \(s\) 非常小时,可以合成难以察觉的异常区域。与替代的合成方法相比,SDAS生成的异常是更为连续的,可以具有非常逼真的结构异常。
Anomaly-aware Features Selection
RealNet中的Anomaly-aware Features Selection(AFS) 模块是一种用于预训练特征选择的自监督方法,减少特征的维度和消除预训练偏差,同时管理重构成本。首先,定义一组 \(N\) 个三元组 \({A_n,I\_n,M\_n}_{n=1}^N\) ,其中 \(A_n,I\_n\in R^{h\times w\times 3}\) 表示由__SDAS__合成的异常图像和原始正常图像, \(M\_n\in R^{h\times w}\) 表示相应的异常掩码。将预训练网络表示为 \(\phi\_k\) , \(\phi\_k(A\_n)\in R^{h\_k\times w\_k\times c\_k}\) 表示从 \(A\_n\) 中提取的第 \(k\) 层预训练特征,其中 \(c\_k\) 表示通道数。对于第 \(i\) 个特征图, \(\phi_{k,i}(A\_n)\in R^{h\_k\times w\_k}\) ,AFS选择 \(m\_k\) 个特征图进行重构( \(m\_k \leq c\_k\) )。具体而言,索引为 \(k\) 的特征图来自于ResNet-like架构,例如ResNet50或WideResNet50,其中 \(k \in {1,2,3,4}\) 表示具有不同空间分辨率的块的最后一层输出。
对于第 \(k\) 层的预训练特征,定义以下AFS损失用于评估第 \(i\) 个特征图:
其中 \(F(\cdot)\) 是一个执行归一化操作并将 \(\phi_{k,i}(A\_n)-\phi_{k,i}(I\_n)^2\) 的分辨率对齐到 \(M_n\) 的函数。给定对异常图像的特征重构过程,训练一个重构网络来基于 \(\phi_{k,i}(A_n)\) 推断 \(\phi_{k,i}(I_n)\) ,从而通过 \([\phi_{k,i}(A_n)-\phi_{k,i}(I_n)]^2\) 实现异常的检测和定位。理想情况下, \([\phi_{k,i}(A_n)-\phi_{k,i}(I_n)]^2\) 应该与 \(M\_n\) 非常接近。 \(\mathcal{L}_{AFS}(\phi_{k,i})\) 表示 \(\phi_{k,i}\) 识别异常区域的能力。
由于真实异常样本不可用,使用合成异常来进行特征选择。对于预训练特征的第 \(k\) 层,AFS选择具有最小 \(\mathcal{L}\_{AFS}\) 的 \(m\_k\) 个特征图进行重构。将AFS表示为 \(\varphi\_k(\cdot)\) ,其中 \(\varphi\_k(A\_n) \in R^{h\_k\times w\_k\times m\_k}\) ,其中 \(m\_k \leq c\_k\), 分别在每个预训练特征层上执行AFS,并最终得到选定的多尺度特征 \({\varphi\_1(A\_n),...,\varphi\_K(A\_n)}\) 。在此过程中,每个层的特征维度 \({m\_1,...,m\_K}\) 作为一组超参数。具体而言,在RealNet中,AFS操作仅在每层的预训练特征上执行一次,并将所选的特征图索引缓存以供后续的训练和推断使用。
AFS自适应地从所有可用层中选择特征的子集进行异常检测,与传统方法(这些方法从部分层中选择所有特征)相比,具有以下优势:
AFS减少了层内特征的冗余性,并减轻了预训练偏差,增强了特征的代表性和可区分性,从而提高了异常检测性能。AFS扩大了感受野,增强了多尺度异常检测能力。AFS区分了用于异常检测的预训练特征的维度,确保了对计算成本的有效控制和模型大小的灵活定制。
在RealNet中,设计了一组重构网络 \({G_1,...,G\_K}\) ,用于将选择的合成异常特征 \({\varphi\_1(A\_n),...,\varphi\_K(A\_n)}\) 重构为各种分辨率的原始图像特征 \({\varphi\_1(I\_n),...,\varphi\_K(I\_n)}\),损失函数 \(\mathcal{L}_{recon}\) 定义如下:
在重构过程中,有意放弃了将多尺度特征对齐的操作,以保持最佳性能。这个选择是受到对齐低分辨率特征的潜在缺点的启发,通过下采样对齐低分辨率特征有可能损害网络的检测分辨率,并增加误判异常的风险。另一方面,使用上采样对齐高分辨率特征可能导致不必要的特征冗余,导致重构成本增加。
Reconstruction Residuals Selection
重构残差选择(RRS)模块表示为 \({E_1(A\_n),...,E\_K(A\_n)}\) ,其中 \(E\_k(A\_n)=\varphi\_k(A\_n)-G\_k(\varphi\_k(A\_n))^2\) 。为了获得全局重构残差 \(E(A\_n)\in R^{h'\times w'\times m'}\) ,对低分辨率的重构残差进行上采样,然后以通道方式进行级联,其中 \(m'=\sum_{k=1}^Km\_k\) , \(h'=max(h\_1,...,h\_K)\) , \(w'=max(w\_1,...,w\_K)\) 。
\(E(A\_n)\) 中的重构残差是从重构相应层的预训练特征中获得的,相同分辨率的特征仅能够有效地捕捉在一定范围内的异常。例如,细微的低级纹理异常仅能通过从低级特征重构残差中得到有效捕获。因此,RRS仅选择包含最多异常信息的重构残差子集,用于生成异常得分,以实现对异常区域的最大回忆率。
首先,RRS对 \(E(A_n)\) 执行全局最大池化(GMP)和全局平均池化(GAP),分别获得 \(E_{GMP}(A_n)\) 、 \(E_{GAP}(A_n) \in R^{m'}\) 。然后,从 \(E_{GMP}(A_n)\) 和 \(E_{GAP}(A_n)\) 中选取最大的 \(r\) 个元素来索引 \(E(A\_n)\) 的位置,并得到 \(E_{max}(A_n,r)\) 和 \(E_{avg}(A\_n,r) \in R^{h' \times w' \times r}\) ,分别代表了具有最大和平均值的TopK重构残差。为了避免因分辨率不足而导致的漏检,RRS会丢弃具有不足异常信息的重构残差。
由于GMP和GAP在空间上分别代表局部和全局特性, \(E_{max}\) 在捕捉小区域的局部异常方面更有效,而 \(E_{avg}\) 注重选择具有大范围的异常,将 \(E_{max}\) 和 \(E_{avg}\) 结合在一起可以增强RRS对不同尺度的异常的捕获能力。将RRS操作符定义为 \(E_{RRS}(A\_n,r) \in R^{h'\times w' \times r}\) ,通过 \(E_{RRS}(A_n,r)\) 将 \(E_{max}(A_n,r/2)\) 和 \(E_{avg}(A_n,r/2)\) 级联起来,最后将 \(E_{RRS}(A_n,r)\) 输入一个判别器,将重构残差映射到图像级分辨率,获得最终的异常得分。异常得分中的最大值被用作图像级的异常得分,使用交叉熵损失 \(\mathcal{L}_{seg}(A,M)\) 来监督判别器的训练。RealNet的整体损失函数为:
Synthetic Industrial Anomaly Dataset
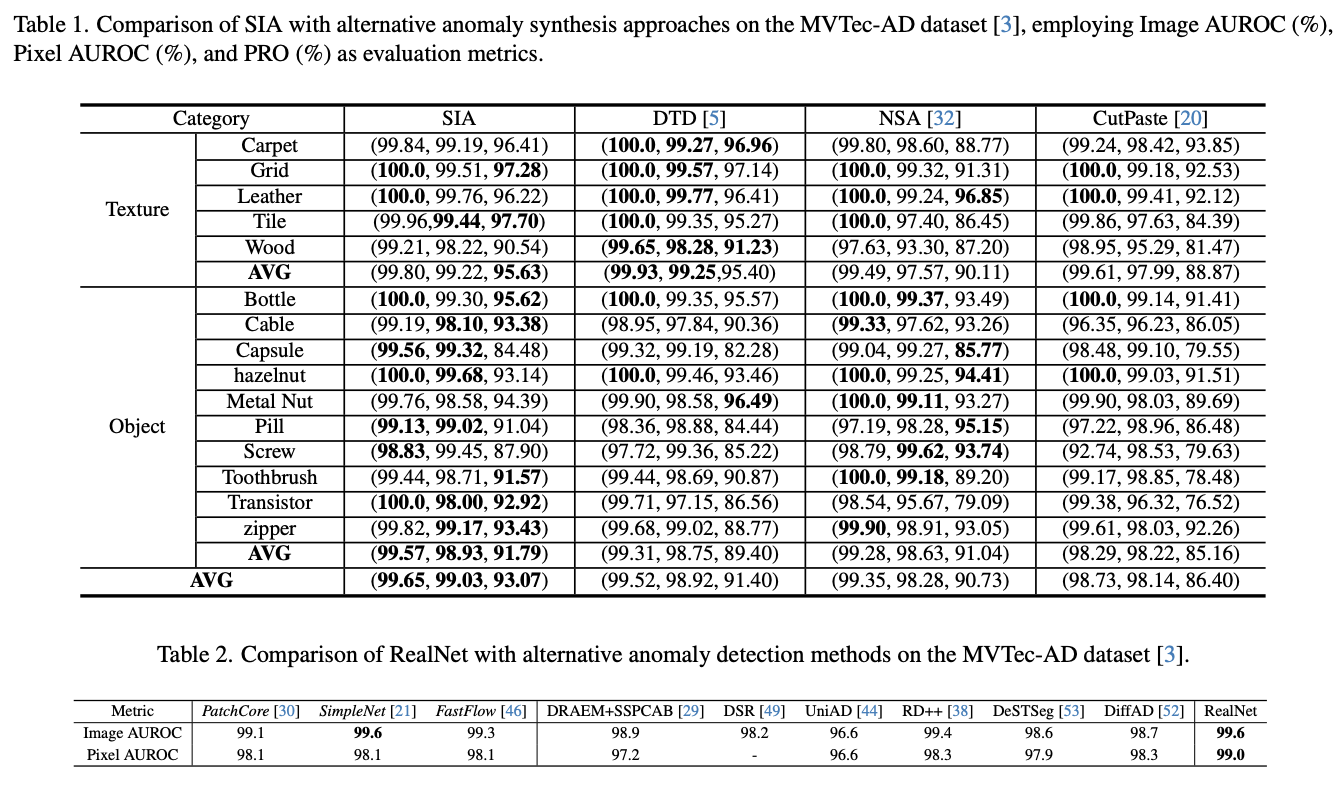
为了方便SDAS对生成的异常图像的重用,论文构建了合成工业异常数据集(SIA)。SIA包括来自四种工业异常检测数据集的36个类别的异常图像,包括MVTec-AD、MPDD、BTAD和VisA。为每个类别生成了分辨率为 \(256 \times 256\) 的10,000个异常图像,异常强度 \(s\) 在0.1和0.2之间均匀采样。通过图像混合,SIA可以方便地用于合成异常图像,并可以作为广泛使用的DTD数据集的有效替代品。
Experiment
如果本文对你有帮助,麻烦点个赞或在看呗~undefined更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号