


ScaleDet:AWS 基于标签相似性提出可扩展的多数据集目标检测器 | CVPR 2023
论文提出了一种可扩展的多数据集目标检测器(
ScaleDet),可通过增加训练数据集来扩大其跨数据集的泛化能力。与现有的主要依靠手动重新标记或复杂的优化来统一跨数据集标签的多数据集学习器不同,论文引入简单且可扩展的公式来为多数据集训练产生语义统一的标签空间,通过视觉文本对齐进行训练,能够学习跨数据集的标签语义相似性来进行标签分配。经过训练后,ScaleDet可以很好地泛化任意具有可见和不可见类的上游和下游数据集来源:晓飞的算法工程笔记 公众号
论文: Training data-efficient image transformers & distillation through attention

Introduction
计算机视觉的重大进步是由大规模数据集推动的,大规模数据集对于训练具有良好泛化能力的识别模型至关重要。但收集大量带标注的数据集既费钱又费时,为了在没有额外标注成本的情况下利用更多训练数据,最近的研究集中于统一多个数据集。从更多视觉类别和更多样化的视觉领域中学习,然后进行检测和分割。
要跨多个数据集训练目标检测器,需要应对几个挑战:
- 多数据集训练需要统一跨数据集的异构标签空间,来自两个数据集的标签可能指代相同或相似的对象。
- 数据集之间的训练设置可能不一致,不同大小的数据集通常需要不同的数据采样策略和学习计划。
- 多数据集模型应该比单数据集模型表现更好,但异构的标签空间、数据集之间的域差异以及对较大数据集的过拟合风险使得这一目标的实现更难。
为了解决上述挑战,现有研究大多手动重新标记类或训练多个特定于数据集的分类器。但这些方法缺乏可扩展性,随着数据集的增加,手动重新标记工作量和训练多个分类器的复杂性迅速增加。

与上述研究不同,ScaleDet是可扩展的多数据集目标检测器,主要有两个创新点:
- 可扩展的公式统一多个标签空间。
- 新颖的损失公式学习跨数据集的硬标签和软标签分配:硬标签用于消除类标签的歧义,而软标签作为正则化器关联相似类标签。
总体而言,论文的贡献如下:
- 论文提出了一种用于目标检测的新型可扩展多数据集训练方法,利用文本编码根据语义相似性来统一和关联跨数据集的标签,通过视觉文本对齐训练单个分类器来学习硬标签分配和软标签分配。
- 论文通过大量实验证明
ScaleDet在多数据集训练中具有令人信服的可扩展性、通用性以及性能。 - 论文评估了
ScaleDet在具有挑战性的Object Detection in the Wild基准上的可转移性,证明其在下游数据集上具有不错的泛化能力。
ScaleDet: A Scalable Multi-Dataset Detector
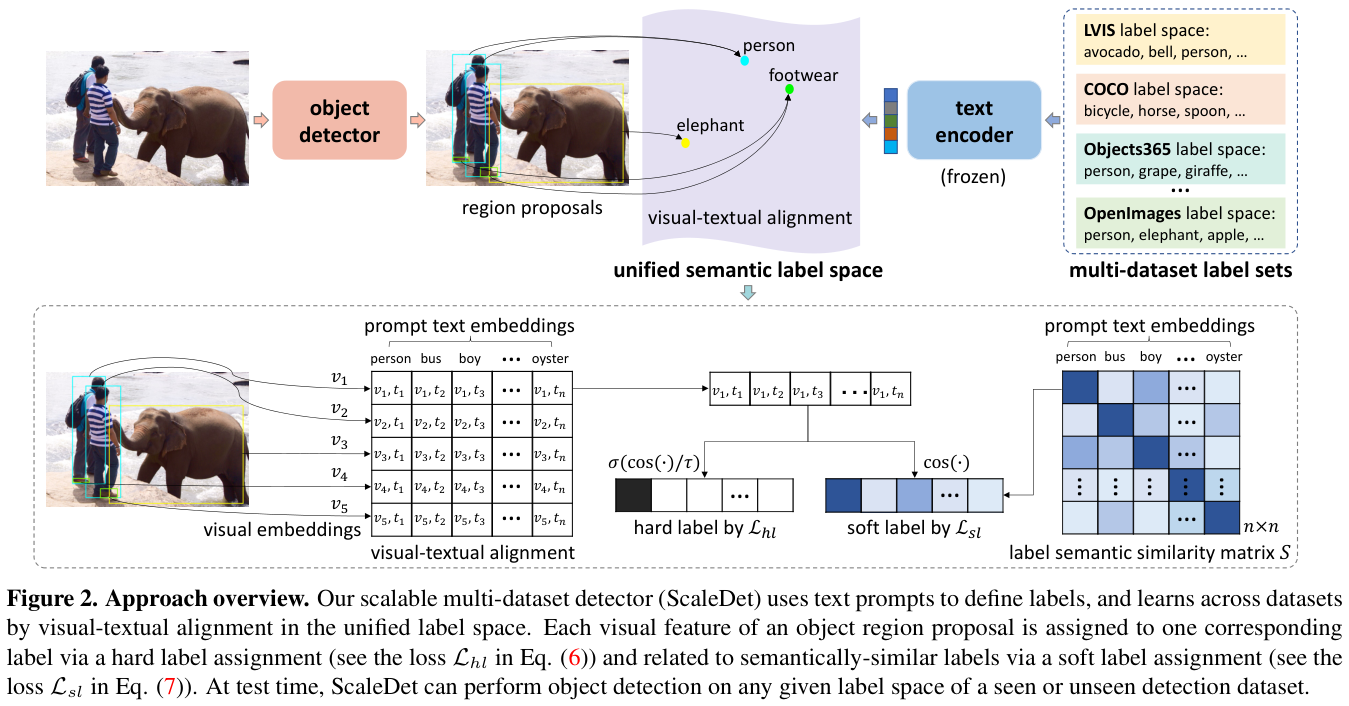
ScaleDet通过统一不同的标签集以形成统一的标签语义空间(图2顶部)进行跨数据集学习,并通过硬标签和软标签分配实现视觉文本对齐来进行训练(图2底部)。
Preliminaries and problem formulation
-
Standard object detection
典型的对象检测器旨在预测对象的边界位置以及在给定个类中的类标签。给定图像 ,检测器的图像编码器(例如 CNN 或 Transformer)提取框特征和视觉特征,将其送到边界框回归器 和视觉分类器 进行预测。检测器通过最小化边界框损失 和分类损失 来学习边界框的预测以及框特征和视觉特征对应的类标签,即,
现有的目标检测器通常采用一级或二级框架,其中可能包含额外损失项。单级检测器使用回归损失来回归对象位置的属性,如中心性,两阶段检测器则改为使用包含专用损失函数的RPN网络来预测每个框是目标的概率。
在这项工作中,论文专注于重新制定分类损失,在两级检测器之上解决多数据集训练问题。
-
Multi-dataset object detection
给定一组 数据集 及标签空间 ,论文的目标是训练一个可扩展的多数据集检测器,该检测器可以很好地泛化上游和下游检测数据集。
之前的多数据集学习器手动将跨数据集的相似标签关联或合并到联合标签,而论文提出了一个简单但可扩展的公式来进行标签统一,无需手动合并任何标签。
Scalable unification of multi-dataset label space
如图2上部分所示,每次训练都从多个训练集中随机抽取一小批图像一起提取视觉特征 ,其中 是 维向量。每个视觉特征 通过标签分配与一组文本编码 进行匹配。
-
Define labels with text prompts
论文用扩展的文本提示来表示每个类标签,例如,标签 人 可以用文本提示 一个人的照片 来表示。论文从预训练的 CLIP 或 OpenCLIP 的文本编码器中提取提示文本的编码,然后将所有文本编码进行均值操作。
-
Unify label spaces by concatenation
给定来自所有数据集的类标签的文本编码,多数据集训练的一个关键问题是统一不相同的标签空间,这可以通过将相似的标签关联并合并来解决。然而,如果没有仔细的人工检查,标签定义的模糊性会导致模型训练中传播错误的风险。因此,论文不进行跨数据集的标签合并,而是先直接通过并集来统一不同的标签空间:
其中 表示并集, 是来自数据集 的标签 。除了简单之外,这个统一语义标签空间 最大限度地保留了所有标签的语义,从而为训练提供了更丰富的词汇。
-
Relate labels by semantic similarities
当使用文本编码来表示类标签时,可以在统一标签空间中关联相似语义的标签。为了展示跨数据集的标签关系,论文基于提示文本编码来计算语义相似性。对于给定的类标签 ,用余弦相似性计算与所有标签的语义相似性,并在 0 和 1 之间归一化:
其中 是两个标签 的文本编码 之间的语义相似度。
编码所有类标签之间的标签关系,得到标签语义相似度矩阵 :
其中是一个矩阵,每个行向量编码标签相对于所有 类标签的语义关系。
有了这些标签语义相似性,论文可以引入显式约束,使检测器能够在具有编码标签语义相似性的统一语义标签空间上学习。重要的是,相似性和标签空间都是离线计算的,这不会为训练和推理增加任何计算成本,在扩大训练数据集的数量时也不需要重新制定模型。
Training with visual-language alignment
为了在统一语义标签空间 上进行训练,论文通过硬标签和软标签分配将视觉特征与文本编码 对齐。
-
Visual-language similarities
给定对象区域提案的视觉特征,论文首先计算 和所有文本编码之间的余弦相似度:
有了这些相似度分数,论文可以根据以下损失项将视觉特征 与的文本编码对齐。
-
Hard label assignment
每个视觉特征 都有其真实标签 ,因此可以通过硬标签分配与的文本编码 匹配:
其中 是二元交叉熵损失, 是 sigmoid 激活函数, 是温度超参数。
上述公式虽然确保视觉特征 与文本嵌入 对齐,但没有明确地学习跨数据集的标签关系。因此,论文引入软标签分配来学习语义标签关系。
-
Soft label assignment
论文通过语义相似度分数将单个标签与所有标签关联,同样地,视觉特征也可以通过使用语义相似度分数与所有文本编码关联。为此,论文在视觉特征 上引入了软标签分配:
其中, 是均方误差, 表示标签 和所有 类标签之间的语义相似性(标签语义相似性矩阵 的第 行)。
-
Remark
硬标签分配可以在概率空间消除不同类别标签的歧义,而软标签分配则可以在语义相似性空间中将每个视觉特征以不同的语义相似度分配给不同的文本编码,充当正则化器来关联跨数据集的相似类标签。
-
Training with semantic label supervision
基于硬标签和软标签分配,论文通过将视觉特征与统一语义标签空间中的文本编码对齐来对不同区域提议进行分类,从而训练检测器。即将原来检测器中的分类损失 被替换为:
其中 是平衡超参数。由于上述损失使用语言监督将图像映射到文本,可以实现对不可见标签的零样本检测。
-
Overall objective
论文不改变原检测器中的检测损失,训练 ScaleDet 的总体目标是:
使用 进行训练后,ScaleDet 可部署在包含可见或未见类的任何上游或下游数据集上。对于任何给定的测试数据集的标签空间,替换统一标签空间 后,ScaleDet 可以根据视觉语言相似性分配标签。当测试数据集包含未见过的类时,整体评估设置即为zero-shot检测或open-vocabulary对象检测。在任何给定的数据集上进行测试时,可以直接评估 ScaleDet 或在评估之前对其进行微调。
Experiments
Training with a growing number of datasets
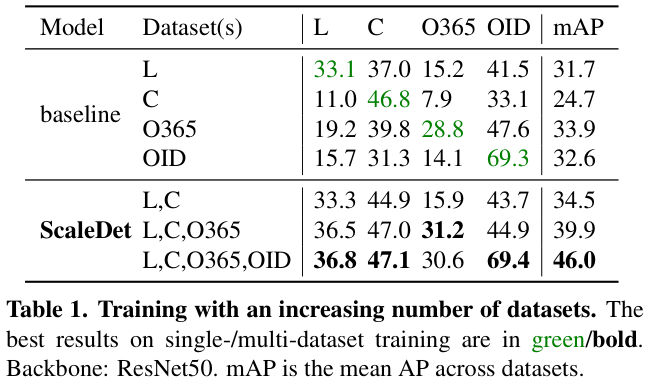
表 1 展示了在增加数据集数量时对上游数据集的影响:1) 增加训练数据集的数量始终会带来更好的模型性能。2)多数据集使用 ScaleDet 进行训练通常优于单数据集训练。这表明 ScaleDet 在异构标签空间、不同数据集的不同领域中学习得很好,并且不会过度拟合任何特定数据集。
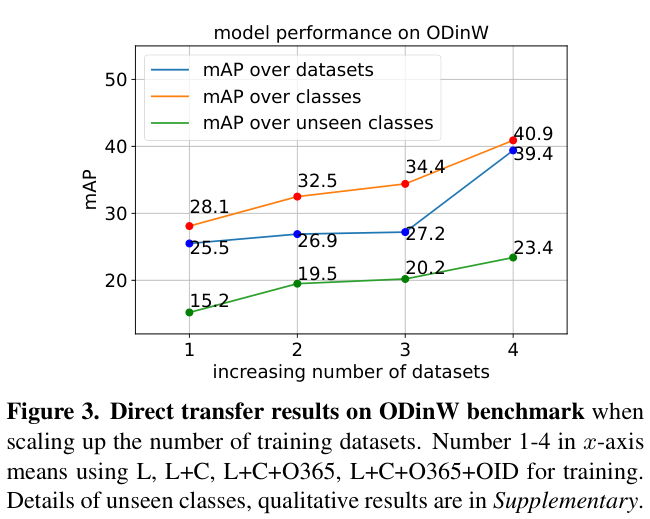
图 3 展示了在 ODinW 基准测试中直接迁移的性能。值得注意的是,扩大 ScaleDet 训练数据集的数量显着提高了下游数据集的准确性。
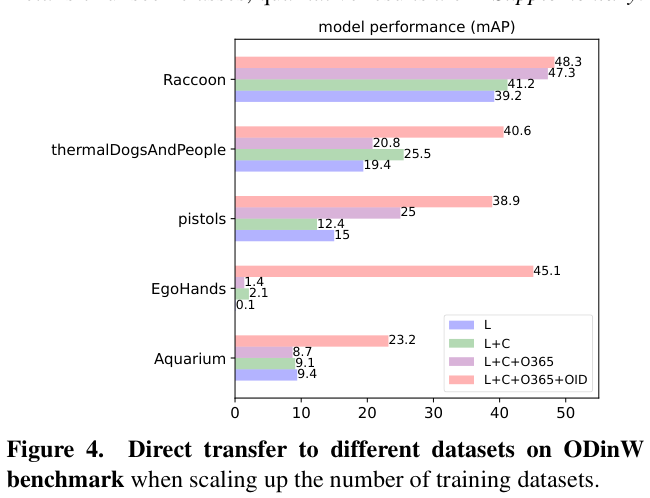
图 4 进一步可视化了 ScaleDet 在 ODinW 中的一些下游数据集上的性能。这些数据集要么包含看不见的类,要么来自与用于训练的那些非常不同的视觉域。重要的是,ScaleDet 在这两种情况下都表现良好。
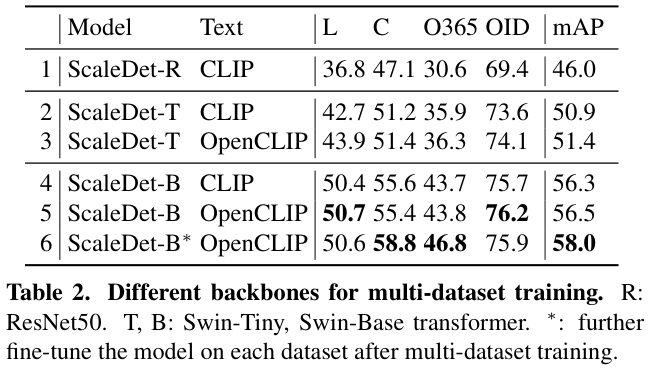
表 2 展示了使用不同的骨干和文本编码的测试结果。
Comparison to SOTA multi-dataset detectors
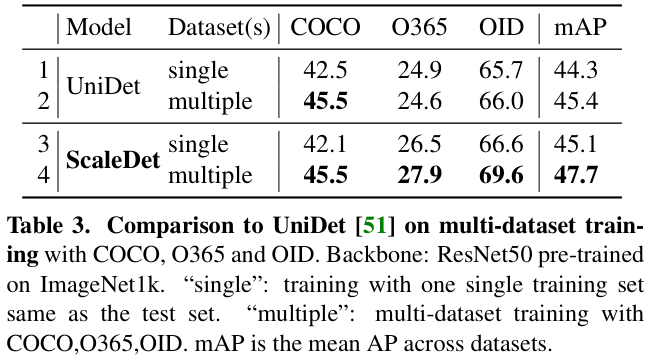
表 3 展示了遵循 UniDet 的设置并在相同的数据集上训练 ScaleDet的性能。UniDet 训练了多个特定于数据集的分类器,而 ScaleDet 则由一个分类器使用语义标签进行训练。
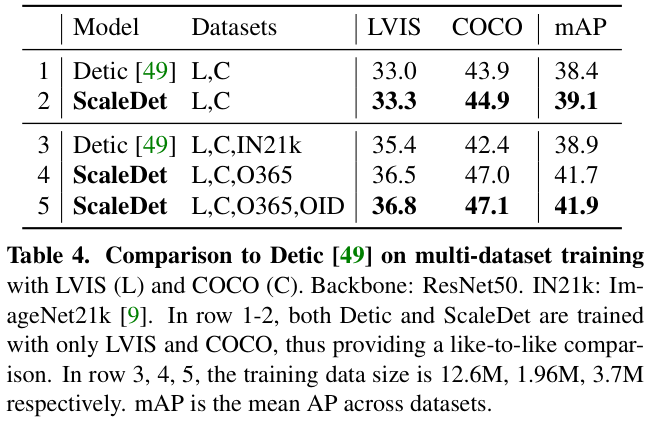
在表 4 展示了遵循 Detic 的设置执行多数据集训练的性能对比。在 Detic 中,LVIS 和 COCO 的统一标签空间包含 1203 个类标签,通过将两个标签集与 wordnet 同义词集合并获得,而 ScaleDet 将它们的标签(1203+80)“扁平化”为 1283。
Comparison to SOTA detectors on COCO
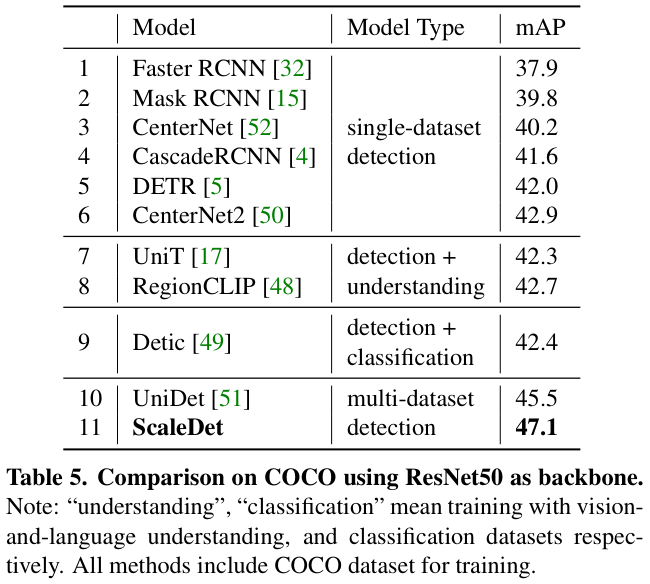
表 5 展示了基于 LVIS、COCO、O365、OID 训练论文的 ScaleDet 与其他模型的检测性能对比,其中所有模型都使用 ResNet50 主干训练。
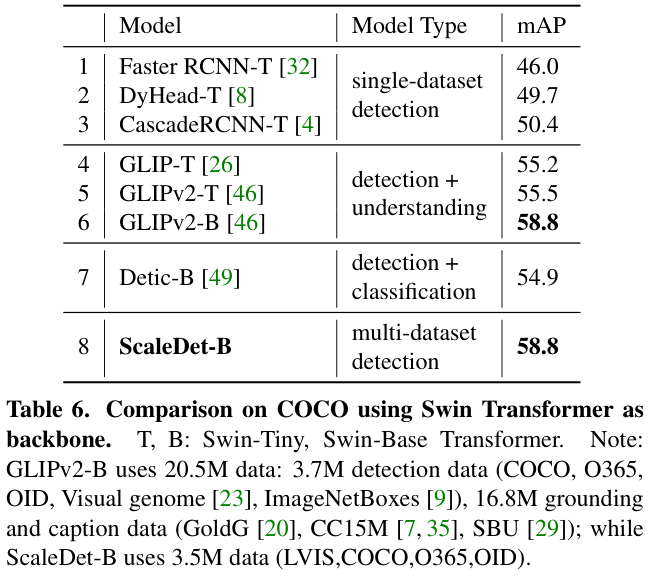
表 6 展示了使用 Swin Transformers 作为主干网络的性能对比。
Comparison of SOTA on ODinW
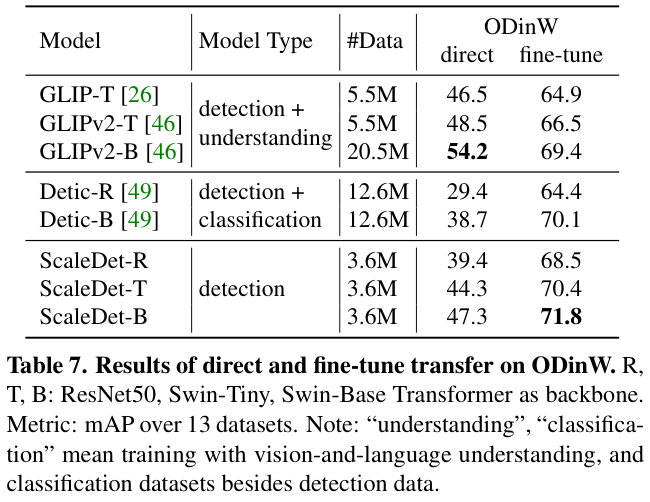
表 7 展示了 3 种检测器在 ODinW 上的性能比较。
Ablation study
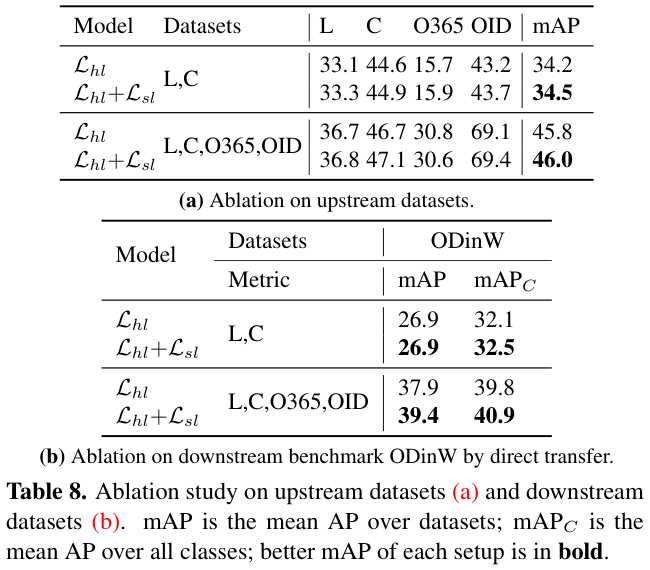
表 8 展示了 ScaleDet 的组件的消融实验结果。
Conclusion
论文介绍了一种简单但可扩展且有效的多数据集目标检测训练方法ScaleDet,在统一的语义标签空间中跨多个数据集学习,通过硬标签和软标签分配进行优化以对齐视觉和文本编码。 ScaleDet 在多个上游数据集(LVIS、COCO、Objects365、OpenImages)和下游数据集(ODinW)上实现了最新的性能。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 通过 API 将Deepseek响应流式内容输出到前端
· 因为Apifox不支持离线,我果断选择了Apipost!