


EfficientNetV2:谷歌又来了,最小的模型,最高的准确率,最快的训练速度 | ICML 2021
论文基于training-aware NAS和模型缩放得到EfficientNetV2系列,性能远优于目前的模型。另外,为了进一步提升训练速度,论文提出progressive learning训练方法,在训练过程中同时增加输入图片尺寸和正则化强度。从实验结果来看,EfficientNetV2的效果非常不错。
来源:晓飞的算法工程笔记 公众号
论文: EfficientNetV2: Smaller Models and Faster Training

- 论文地址:https://arxiv.org/abs/2104.00298
- 论文代码:https://github.com/google/automl/tree/master/efficientnetv2
Introduction
随着模型大小和数据集规模的增加,训练效率成了深度学习中很重要的一环。近期也有越来越多致力于提高训练效率的研究,但很难有兼顾准确率、训练效率和参数规模的网络。
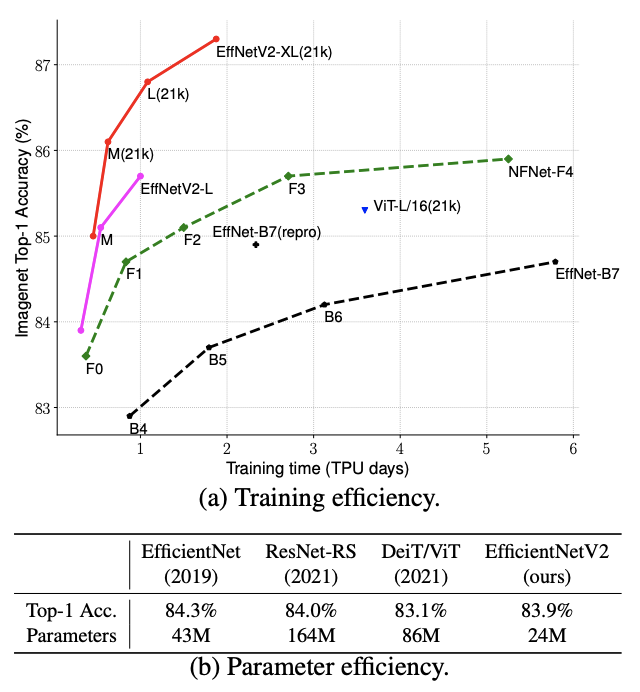
论文尝试分析了参数高效的EfficientNet的训练瓶颈,主要有三点:1)图片输入尺寸过大会导致训练较慢。2)深度卷积放在网络前部分会较慢。3)对网络所有stage进行同等scaling并不是最优的。基于上面的分析,论文设计了更精简的搜索空间,使用training-aware NAS(neural architecture search)和scaling来同时提高模型准确率、训练效率和参数效率,提出了EfficientNetV2系列网络。
在训练速度方面,论文通过在训练过程逐步提高输入尺寸来进一步加速训练。先前也有类似的在训练过程逐步增加输入图片尺寸来加速的研究,但这些研究在修改输入图片尺寸的同时没有改变训练设置,导致准确率下降。论文认为,输入图片尺寸不同的网络的容量不同,应该使用不同程度的正则化方法。为此,论文提出了progressive learning,在训练初期使用较小的图片尺寸和较弱的正则化,然后逐步提高图片尺寸和正则化强度,可以做到加速训练又不掉点。
论文的主要贡献如下:
- 组合training-aware NAS和scaling提出EfficientNetV2系列网络,比之前的网络的规模更小、速度更快。
- 提出progressive learning自适应根据图片尺寸调整正则化强度,加速训练的同时提高准确率。
- 在多个训练集上进行实验,验证训练效率能提高11倍,模型规模能降低6.8倍。
EfficientNetV2 Architecture Design
Review of EfficientNet
EfficientNet是优化计算量和参数量的系列网络,先通过NAS搜索准确率和速度折中的基线模型EfficientNet-B0,再通过混合缩放策略获得B1-B7模型。

尽管现在很多研究声称在训练或推理速度上取得很大进步,但他们通常在计算量和参数量上差于EfficientNet,而本文正是想同时提升训练速度和优化模型参数量。
Understanding Training Efficiency
论文对EfficientNetV1的训练瓶颈进行了分析,发现以下几个主要问题。
-
Training with very large image sizes is slow
输入图片尺寸过大会导致显存占用的显著提高,由于GPU的显存是固定的,导致必须减少batch size和增加迭代次数进行训练,训练也就变慢了。

如表2所示,较小的尺寸大约能提升2.2倍训练速度,还能小幅提升模型性能。为此,论文参考FixRes的动态增加训练图片尺寸提出更高效的训练方法,在训练过程逐步增加图片尺寸以及正则化强度。
-
Depthwise convolutions are slow in early layers but effective in later stages
EfficientNet的另一个训练瓶颈在于depthwise卷积的使用,depthwise卷积虽然有更少的参数和计算量,但不能使用目前的GPU加速方案。
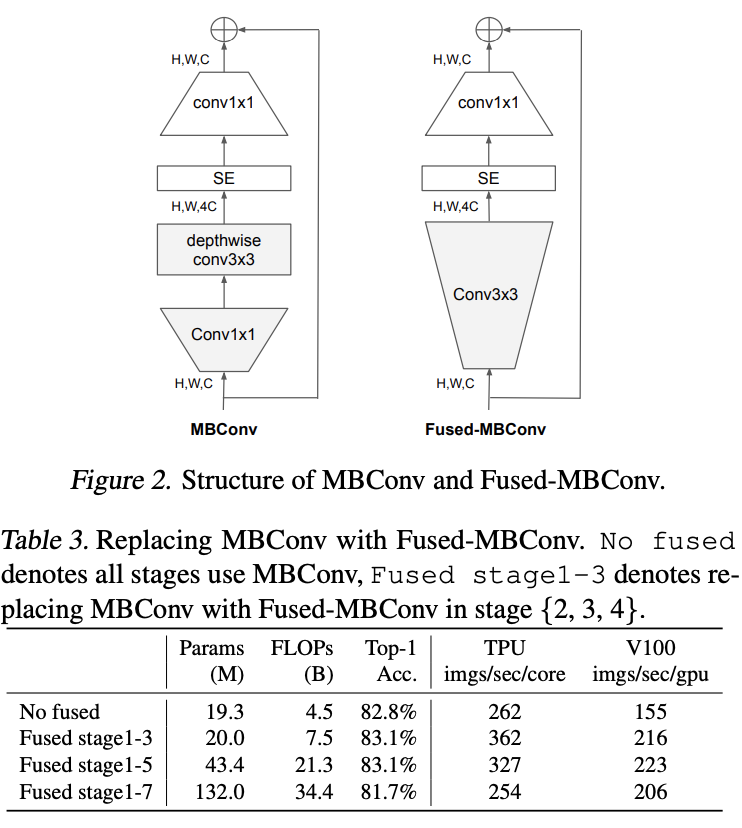
最近有研究提出MBConv的替代结构Fused-MBConv,如图2所示,将depthwise conv3x3和conv1x1合并为常规的conv3x3。为了对比两者的性能差异,论文逐步替换stage进行实验。从表3的结果可以看出,恰当地使用Fused-MBConv可以在不带来过多参数量和计算量的前提下提升训练速度。至于如何是恰当,就靠NAS来自动搜索了。
-
Equally scaling up every stage is sub-optimal
EfficientNet使用简单的混合缩放规则相等地放大所有stage,但实际上不同的stage对训练速度和参数量的影响是不同的。为此,论文只放大网络后面的stage,同时减小输入图片尺寸的放大比例。
Training-Aware NAS and Scaling
-
NAS Search
论文跟EfficientNet一样利用MnasNet的多目标神经结构搜索进行网络搜索,调整评价指标同时优化准确率、参数量和训练速度。以EfficientNet作为主干,构造stage-based的搜索空间来对每个stage进行搜索。搜索的选项包括卷积类型{MBConv, Fused-MBConv}、层数、卷积核大小{3x3, 5x5},block中间的膨胀比例{1, 4, 6}。
另外,论文也从以下几点减少了搜索空间大小:
- 去掉不必要的搜索选项,比如pooling skip算子,这个没有在EfficientNet用到过。
- 复用主干网络的每个stage的channel数,这部分已经在EfficientNet中搜索过了。
由于搜索空间精简了,可以直接用强化学习和随机搜索来生成跟EfficientNet-B4差不多大小的网络。论文共采样1000个网络结构,每个训练大概10个周期。搜索的平均指标包含模型准确率、归一化的训练耗时和参数量,使用加权乘积进行最终得分计算,其中和是通过实验确定的平衡超参数。
-
EfficientNetV2 Architecture
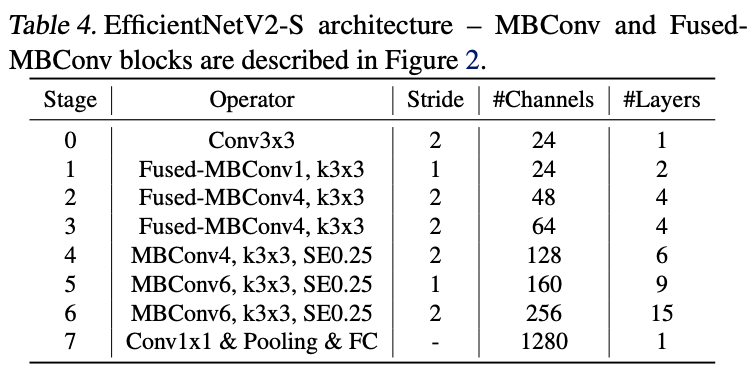
EfficientNetV2-S结构如表4所示,Conv后接的数字是膨胀率。对比EfficientNet,主要有以下区别:
- 使用MBConv的同时,在网络前几个阶段也使用了fused-MBConv。
- EfficientNetV2倾向于选择较小的膨胀比例,这样能减少内存访问耗时。
- EfficientNetV2比较喜欢较小的3x3卷积,但会添加更多的层数来弥补减少的感受域。
- 去掉EfficientNet中最后stride-1的stage,可能由于其参数量和计算量太大了。
这里有一点比较奇怪,上面NAS部分说会复用EfficientNet的通道数来缩小搜索空间,但是看表4的通道数貌似跟EfficientNet没有关系。这要等作者补充更多的NAS细节看看,具体各模型的参数可以去github看看。
-
EfficientNetV2 Scaling
论文通过放大EfficientNetV2-S得到EfficientNetV2-M/L,使用类似于EfficientNet的混合缩放策略来,有以下区别:
-
限制最大的推理图片尺寸为480,节省内存和训练速度消耗。
-
逐步添加更多的层给后面的stage,比如表4中的stage5和stage6,在增加网络容量的同时不会带来过多运行消耗。
-
Training Speed Comparison
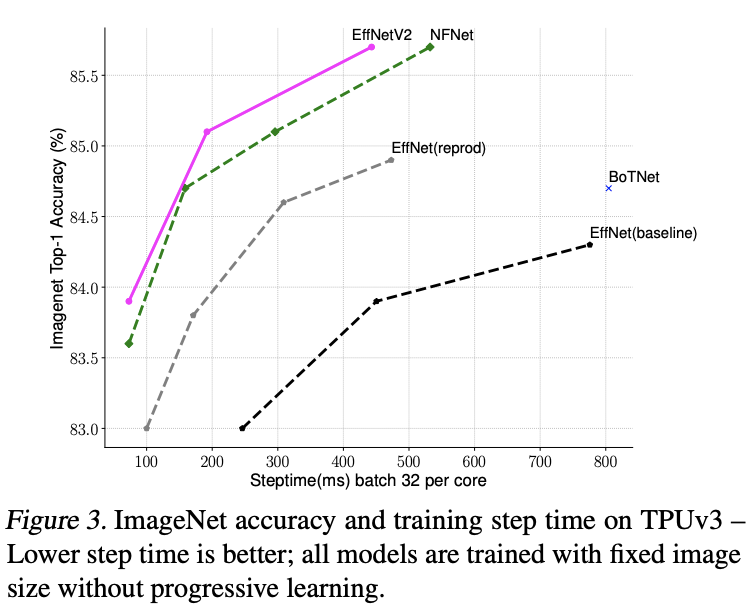
图3对比了各网络的训练耗时,其中EfficientNet有原版和训练时缩小30%图片尺寸的版本,缩小版本的输入尺寸跟EfficientNetV2以及NFNet一致。使用相同训练周期和固定图片尺寸进行训练,EfficientNet仅缩小训练尺寸就能得到很大的性能提升,而EffcientNetV2凭借论文提出training-aware NAS和缩放策略,性能远超其它网络。
Progressive Learning
-
Motivation
如之前所描述的,图片尺寸对训练效率的影响非常大。除了FixRes,还有很多其他在训练期间动态调整图片尺寸的研究,但这些研究通常都会出现性能下降的情况。论文认为,性能下降的主要原因在于正则化没有匹配动态调整的图片尺寸。较小的输入尺寸应该使用较弱的正则化强度,相反,较大的输入尺寸则应该使用较强的正则化强度。

为了验证这个猜想,论文将不同输入图片尺寸和不同正则化强度进行组合测试。从表5的结果来看,基本验证了论文的猜想。于是论文提出了progressive learning,在训练过程中根据动态调整的图片尺寸自适应正则化强度。
-
Progressive Learning with adaptive Regularization

论文提出的progressive learning如图4所示,先用较小的图片尺寸和较弱的正则化进行训练,随后逐步增加图片尺寸和正则化强度。

假设完整的训练共次迭代,目标图片尺寸为,目标正则化超参数为,其中表示其中一种正则化方法,比如dropup比例或mixup比例。将训练分为个阶段,对于每个阶段,模型训练的图片尺寸为,正则化超参数为,最后一个阶段的图片尺寸为和正则化超参数为。为了简单化,初始化图片尺寸和正则化超参数为和,通过线性插值来决定每个阶段对应参数,整体逻辑如算法1所示。
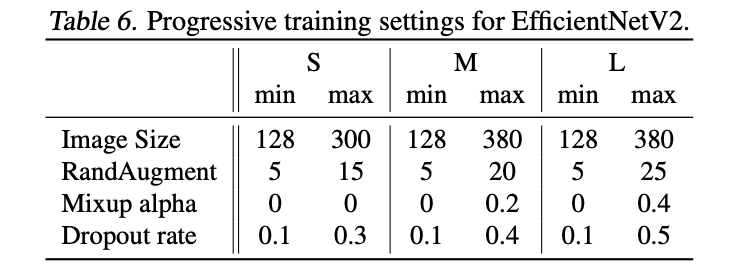
论文共使用三种正则化方法:Dropout、RandAugment和Mixup,各网络的参数设置如表6所示。
Experiment
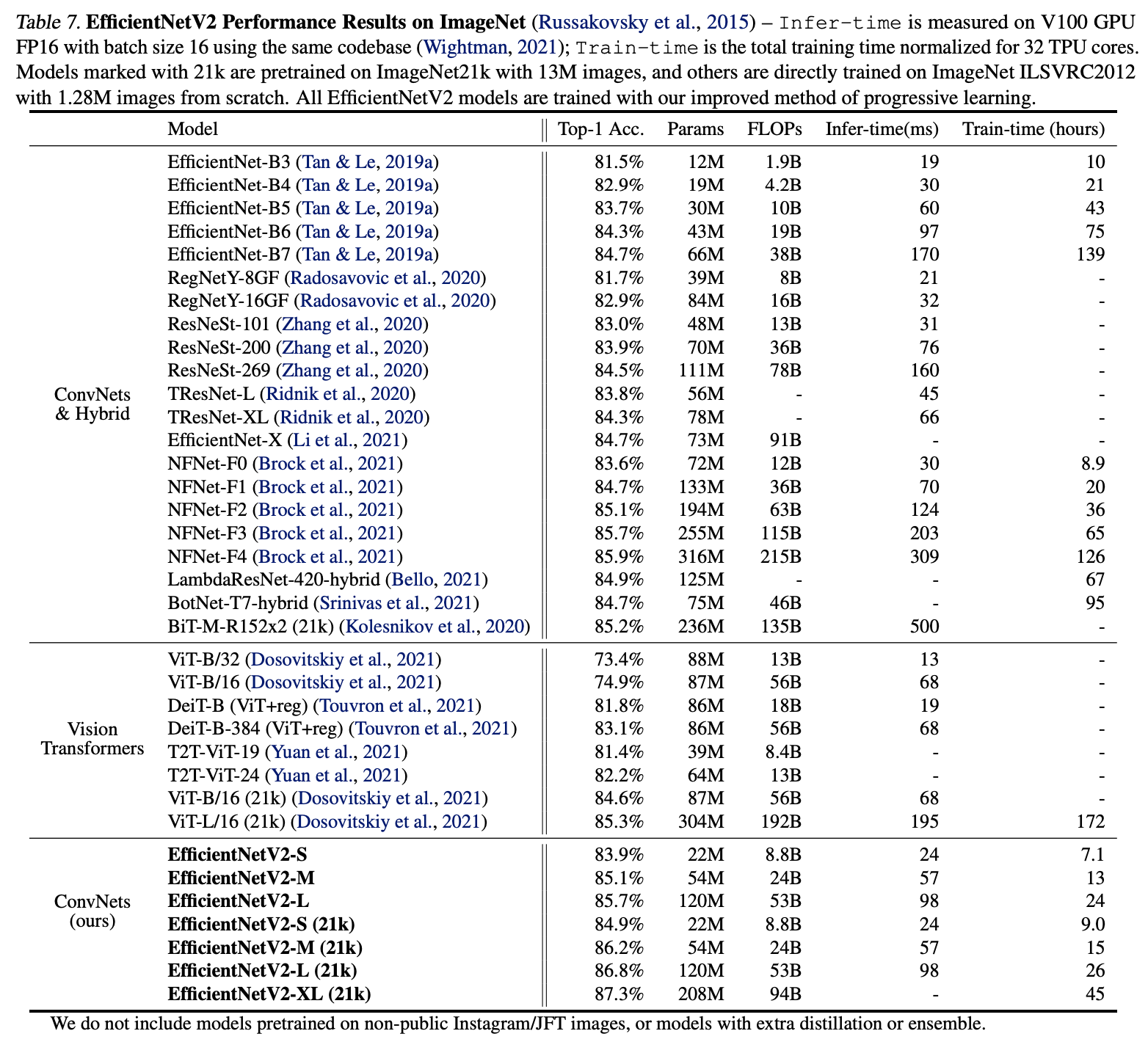
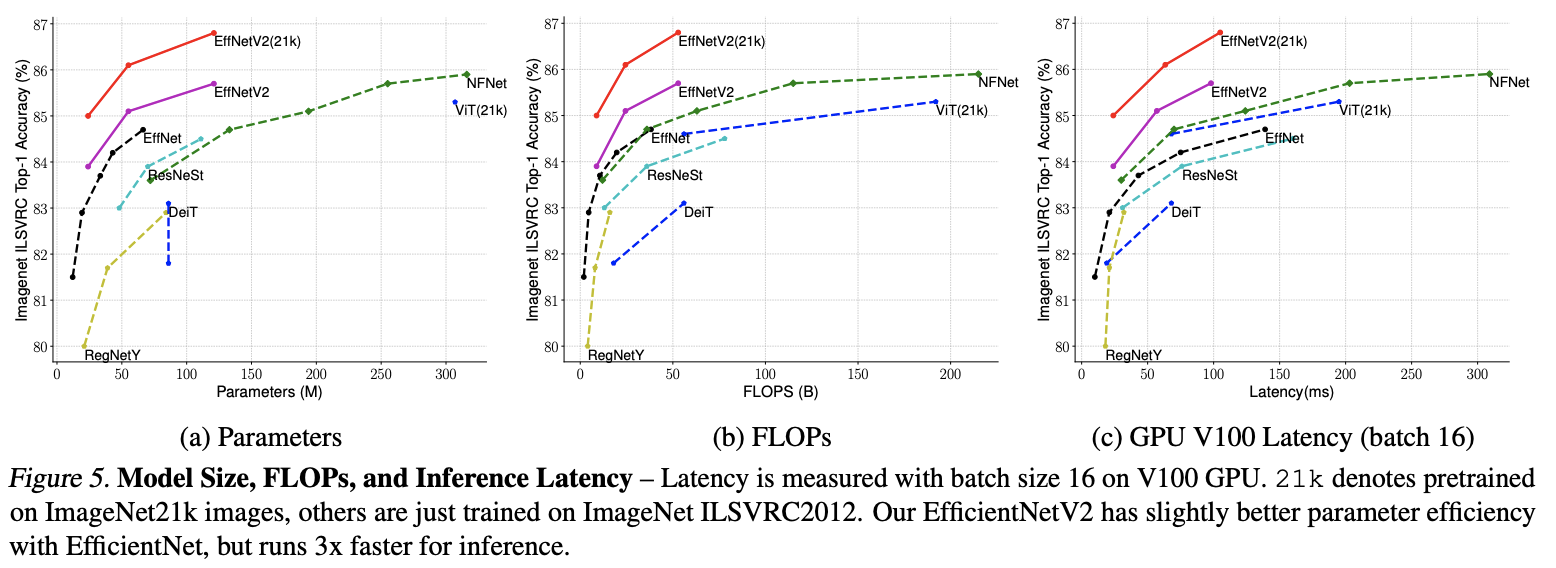
在ImageNet上与其它网络进行对比。
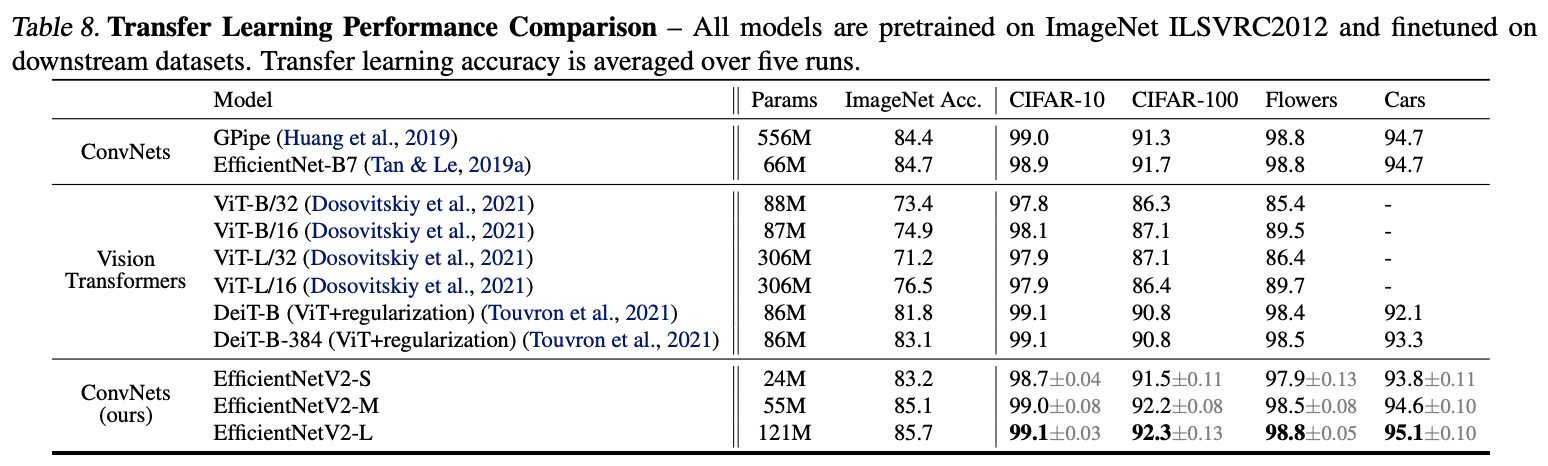
迁移能力对比。
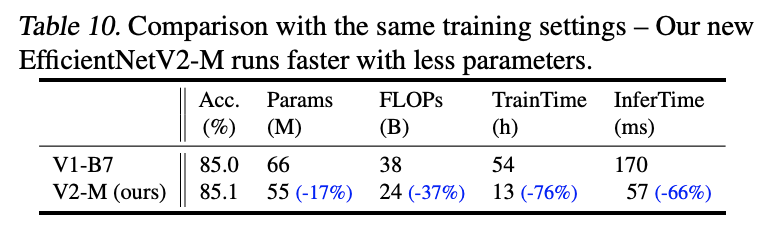
相同训练配置下的EfficientNet对比。
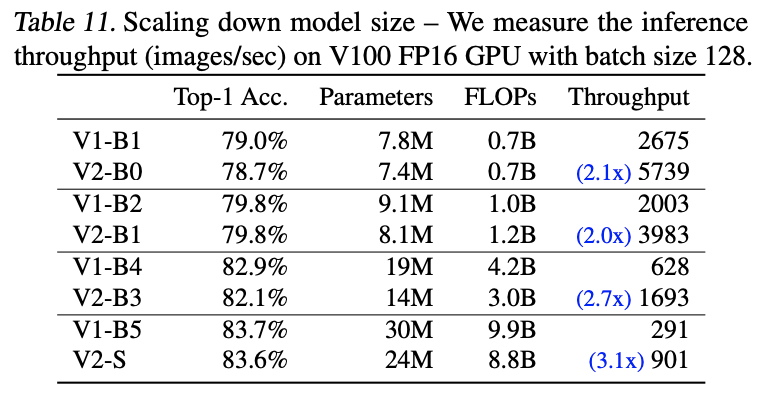
缩小EfficientNetV2的模型大小与对标的EfficientNetV1,对比准确率和速度。
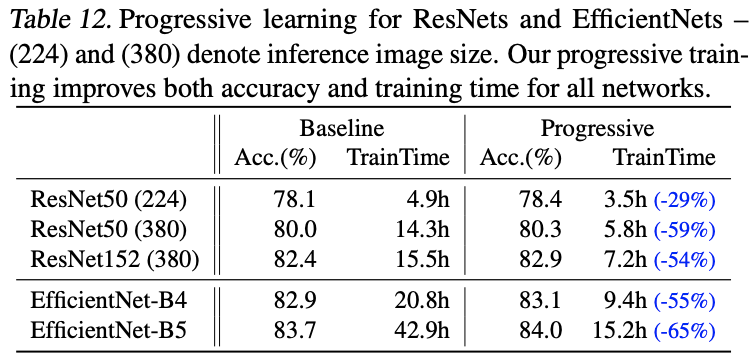
对比不同网络使用progressive learning的效果。
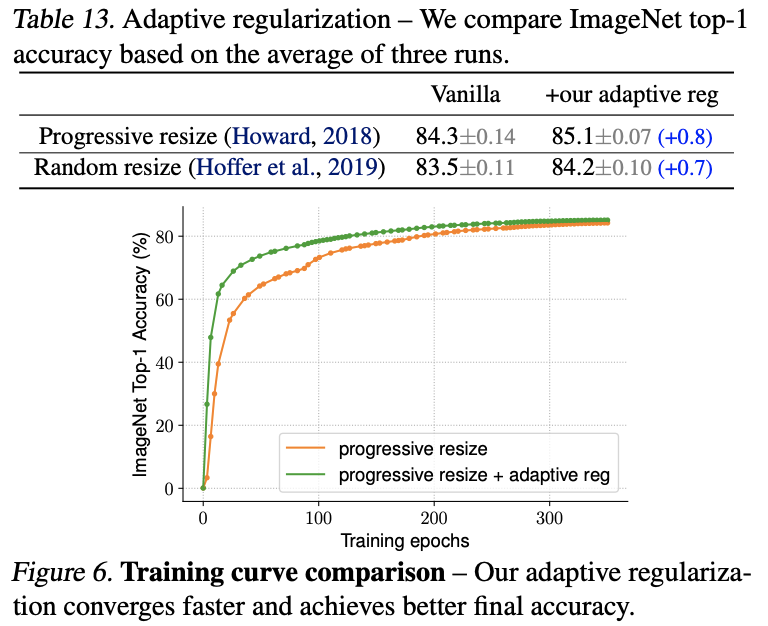
对比自适应正则化强度的效果。
Conclusion
论文基于training-aware NAS和模型缩放得到EfficientNetV2系列,性能远优于目前的模型。另外,为了进一步提升训练速度,论文提出progressive learning训练方法,在训练过程中同时增加输入图片尺寸和正则化强度。从实验结果来看,EfficientNetV2的效果非常不错。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
2020-03-31 Light-Head R-CNN : 旷世提出用于加速two-stage detector的通用结构,速度达102fps
2020-03-31 NASNet : Google Brain经典作,改造搜索空间,性能全面超越人工网络,继续领跑NAS领域 | CVPR 2018