
YOLOF:单层特征检测也可以比FPN更出色 | CVPR 2021
论文通过分析发现FPN的成功在于divide-and-conquer策略解决了目标检测的优化问题,借此研究设计了仅用单层特征预测的高效检测网络YOLOF。YOLOF在结构上没有很多花哨的结构,却在准确率、推理速度和收敛速度上都有不错的提升,相对于眼花缭乱的FPN魔改结构,十分值得学习
来源:晓飞的算法工程笔记 公众号
论文: You Only Look One-level Feature

Introduction
在当前的目标检测算法中,特征金字塔是必备的组件,一般通过FPN来实现,主要带来两个收益:1)multi-scale feature fusion:融合高低分辨率特征来取得更好的特征表达;2)divide-and-conquer:不同大小的目标在对应大小的特征图上检测。目前人们普遍认为FPN带来的提升主要得益于multi-scale feature,于是设计了一系列复杂的特征融合结构和方法,完全忽略了divide-and-conquer的作用。
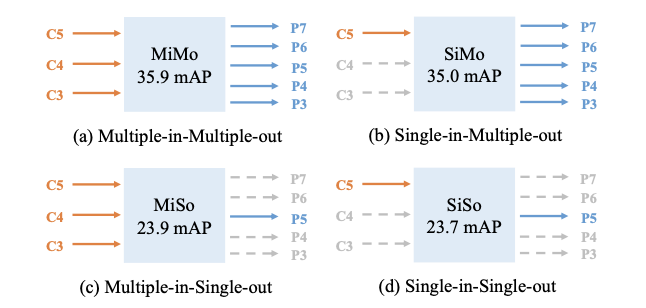
本篇论文的主要目的就是在one-stage检测算法上验证FPN的两个收益的影响,对这两种收益进行不同的组合,设计了Multiple-in-Multiple-out (MiMo)、Single-inMultiple-out (SiMo)、Multiple-in-Single-out (MiSo)和Single-in-Single-out (SiSo)四种encoder结构,如上图所示。将上述四种结构嵌入到RetinaNet中进行实验对比,其中MiMo就是原版的RetinaNet。比较意外的是,SiMo encoder的性能居然和MiMo encoder相差不到1mAP,而SiSo encoder与MiSo encoder则相差12mAP以上。
从上面的现象可以得到以下两个结论:
- C5特征有足够的上下文用于检测不同尺寸的目标,使得SiMo encoder依然能有不错的表现。
- multi-scale feature fusion带来的提升远低于divide-and-conquer,所以multi-scale feature fusion可能不是FPN的最重要收益。而divide-and-conquer则与目标检测的优化过程有关,将复杂的检测问题根据目标尺寸分解成多个子问题,加速了优化过程。
上面的结论表明,FPN的主要作用是解决目标检测的优化问题。虽然divide-and-conquer是很不错的解决方法,但会带来过多的内存消耗,导致检测模型的结构变复杂。既然C5特征已经包含了足够多的上下文信息,那应该可以用更简单的方法来解决优化问题。
为此,论文提出了YOLOF(You Only Look One-level Feature),仅使用C5特征进行检测。为了缩小SiSo encoder与MiMo encoder之间的性能差异,论文设计了dilated encoder用于提取不同大小目标的多尺度上下文信息,弥补multiple-level features的缺少,再通过uniform matching来解决预设anchor过于稀疏带来的正样本不平衡问题。
论文的贡献如下:
- 证明FPN带来的提升主要得益于divide-and-conquer解决了检测问题的优化问题,而非multi-scale feature fusion功能。
- 提出不含FPN的YOLOF模型,包含两个关键模块:Dilated Encoder和Uniform Matching,能够缩小SiSo encoder和MiMo encoder的性能差异。
- 通过COCO数据集上的实验证明YOLOF各模块的重要性,YOLOF不仅准确率比得上RetinaNet、DETR和YOLOv4,速度还更快。
Cost Analysis of MiMo Encoders

MiMo encoder使得检测器更复杂,带来更大内存使用,造成检测速度下降。为了弄清楚这一影响,论文基于RetinaNet对MiMo encoder进行了量化分析,将检测过程分解成了上图的3个关键模块。
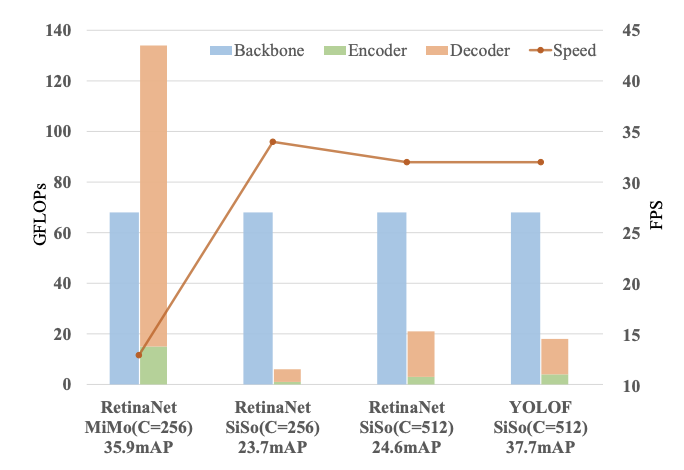
多种模式下,各模块的量化结果如上图所示。对比SiSo encoder,MiMo encoder带来了巨大的内存使用(134G vs. 6G)以及造成运行速度大幅下降(13FPS vs. 34 FPS)。速度的下降主要在于高分辨率特征图(如C3)上的目标检测。基于上述MiMo encoder的缺点,论文尝试在保持检测器简单、准确和快速的同时,找到替代的方法来解决优化问题。
Method
虽然C5特征包含了足够的上下文信息,但用SiSo encoder替换MiMo encoder并不是简单的事,直接替换会造成大幅性能下降。经过分析,造成性能下降的原因主要有两个:1)limited scale range:C5特征的感受域是固定的,妨碍多尺度目标的检测性能。2)imbalance problem on positive anchors:anchor分布稀疏造成正样本不平衡。
Limited Scale Range

MiMo或SiMo encoder构造了不同感受域的多层特征(P3-P7),根据目标尺寸在不同的特征上进行目标检测。而SiSo encoder则只有单层特征,其特征的感受域是固定的,如图a所示,只能覆盖有限的尺寸范围。需要找到一个方法来增加特征的感受域范围,弥补多层特征的缺失。
先通过堆叠dilated convolutions来增大感受域,覆盖的尺寸范围会偏移到较大尺寸,如图b所示。然后将原本的特征与增大后的特征合并,得到新的能覆盖全部尺寸范围的特征,如图c所示。
-
Dilated Encoder
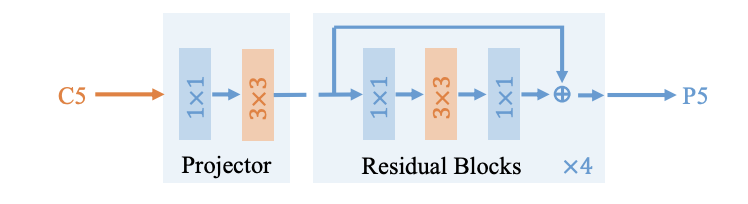
为了实现上述目的,论文设计了Dilated Encoder,分为Projector和Residual Blocks两部分。Projector结构跟FPN一样,先通过\(1\times 1\)卷积降低维度,然后通过\(3\times 3\)卷积来修复上下文信息,此处的卷积后跟BN层。随后堆叠连续4个不同dilation rates的dilated residual blocks,生成包含多种感受域大小的特征,此处的卷积后跟BN层+ReLU层。
-
Discussion
在目标检测中,使用dilated convolution来增大特征感受域是一种常见的做法。TridentNet使用参数共享的dilated convolution来生成多尺寸特征,DetNet则使用dilated convolution来生成分辨率不变而感受域增大的主干特征。而论文使用的dilated convolution的目的则跟上面的都不太一样,主要为了在单层特征上检测所有尺寸的目标。
Imbalance Problem on Positive Anchors
正样本的定义是优化目标检测问题的关键,目前大多数anchor-based检测器都采用Max-IoU匹配。对于MiMo encoder,先在多个特征层上密集地平铺anchor,根据GT尺寸在对应的层选择正样本。基于divide-and-conquer策略,Max-IoU匹配使得不同大小的GT都能产生足够多的正样本。
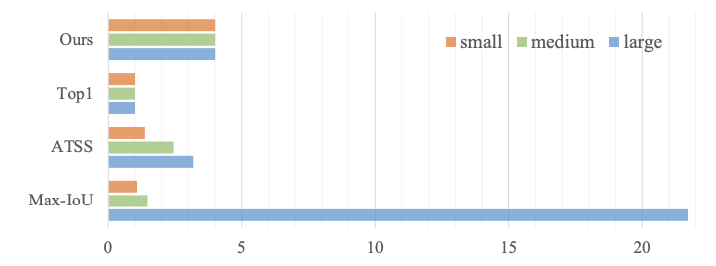
但由于SiSo encoder只有单层特征,anchor数从100k下降到了5k,而且C5下采样率较大,在C5上预设的anchor映射回原图就显得较为“稀疏”。如上图所示,大目标相对于小目标匹配到更多正样本,造成正样本不平衡的问题。不平衡问题使得检测器在训练时会更关注大目标的学习,忽略了小目标。
-
Uniform Matching
为了解决正样本不平衡的问题,论文提出了Uniform Matching策略。该策略直接选择k个最近的anchor作为正样本,保证每个GT都能匹配到相同数量的anchor,在训练中得到平等对待。此外,根据Max-IoU匹配,忽略IoU较大(>0.7)的负样本以及IoU较小(<0.15)的正样本。
-
Discussion
在匹配中选择topk并不是新鲜事,比如ATSS先在每层选择topk anchor作为候选,再根据动态阈值过滤出正样本。但ATSS关注的是自适应区分正负样本,而论文关注的是少anchors下的正样本平衡问题,出发点不一样。
YOLOF
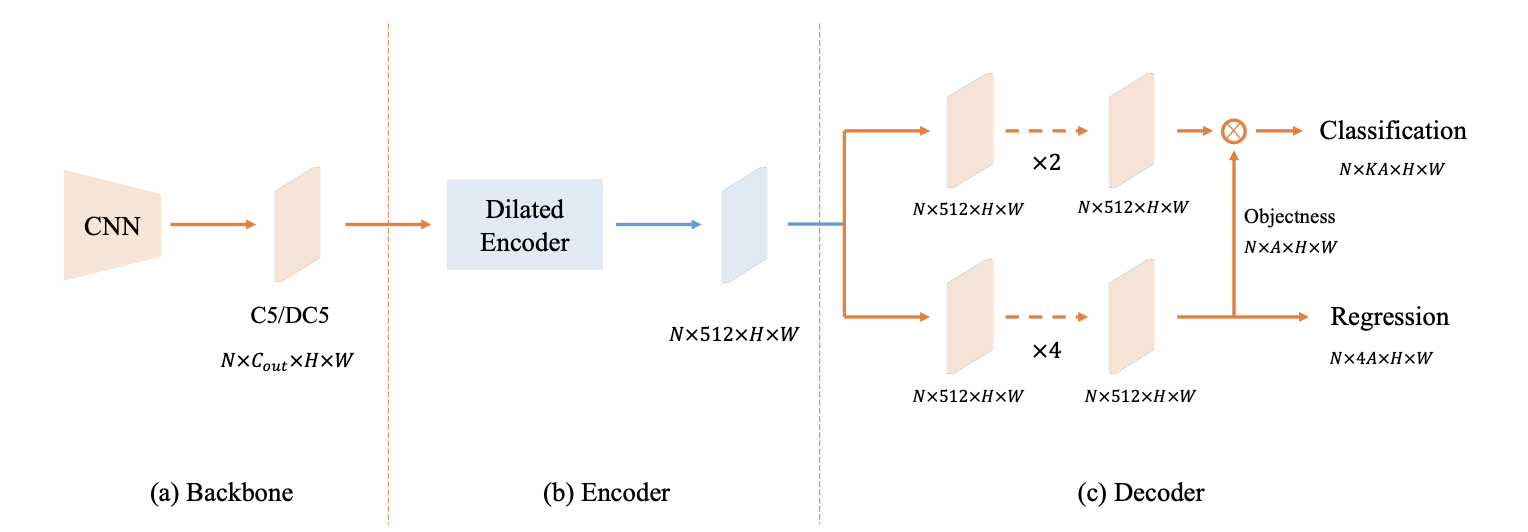
基于上述的分析,论文提出简洁的基于单层特征的检测器YOLOF,结果如上图所示,包含以下模块:
- Backbone:采用预训练的ResNet和ResNeXt系列作为主干网络,主干输出为C5特征,特征维度和下采样率分别为2048和32。为了公平比较,BN层默认是冻结的。
- Encoder:采用dilated encoder结构,projector输出维度为512,后续经过连续的dilated residual blocks处理,其中的\(1\times 1\)卷积下采样率为4。
- Decoder:采用RetinaNet的设计,包含并行的task-specific heads:classification head和regression head。这里做了两个小修改:1)根据DETR的FFN设计修改两个head的卷积数,regression head包含4个卷积+BN+ReLU结构,classification head仅包含2个。2)根据Autoassign,在regression head为每个anchor增加无直接监督的显式objectness预测,最后的分数为分类分数和objectness分数的乘积。
- Other Details:由于YOLOF预设的anchor较稀疏,降低了GT和anchor之间的匹配质量,论文提出随机偏移来回避这个问题。该操作将图片随机向四个方向偏移最多32像素,为目标的位置引入噪声,增大目标匹配到高质量anchor的概率。此外,论文发现,在只有单层特征预测时,限制anchor中心的回归修正在32像素内也对最终的分类有帮助。
Experiment
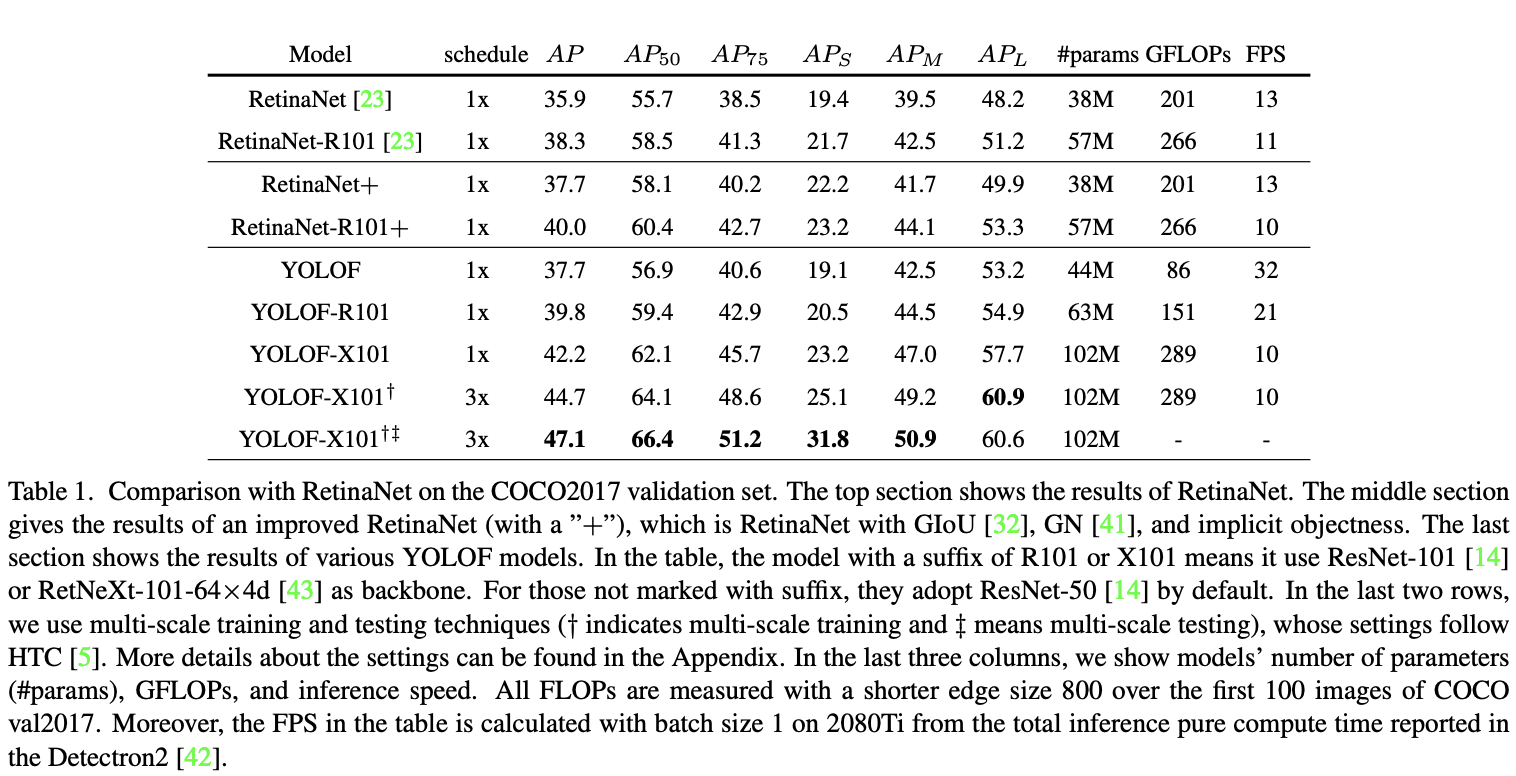
与RetinaNet进行对比。
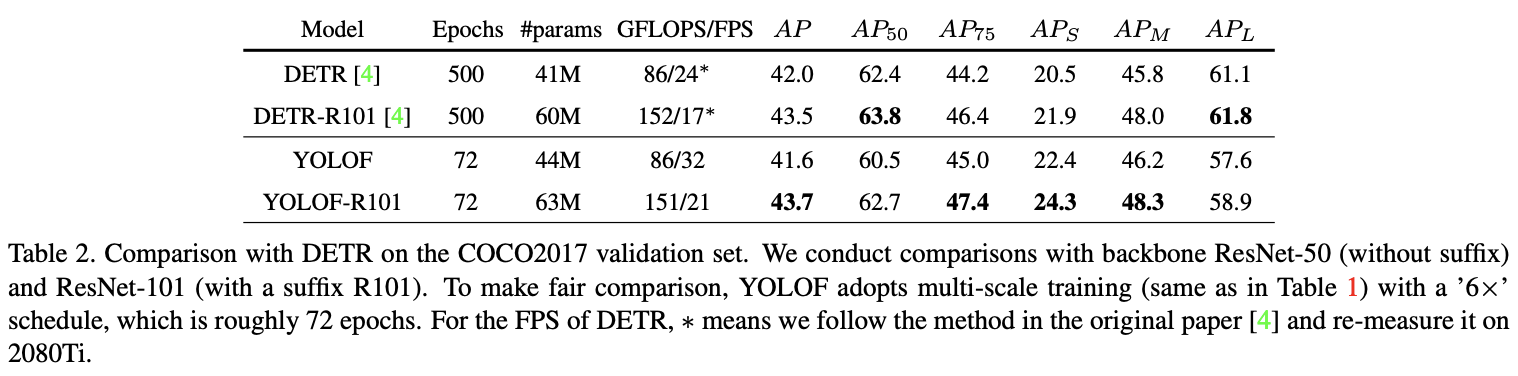
与DETR进行对比。
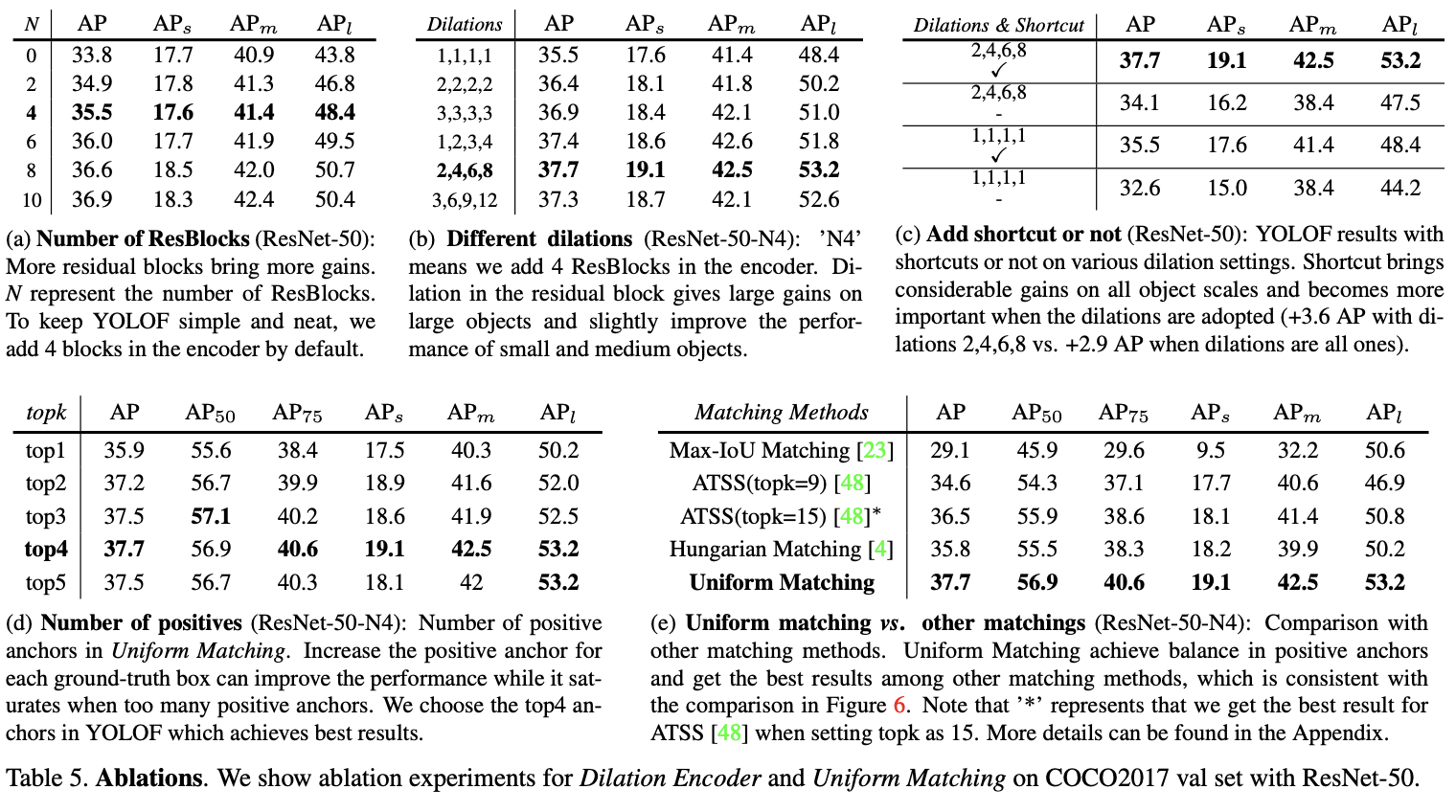
各组件的对比实验。
Conclusion
论文通过分析发现FPN的成功在于divide-and-conquer策略解决了目标检测的优化问题,借此研究设计了仅用单层特征预测的高效检测网络YOLOF。YOLOF在结构上没有很多花哨的结构,却在准确率、推理速度和收敛速度上都有不错的提升,相对于眼花缭乱的FPN魔改结构,十分值得学习。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号