
SoftPool:基于Softmax加权的池化操作 | 2021新文
SoftPool使用softmax进行加权池化,能够保持特征的表达性并且是可微操作。从性能和准确率来看,SoftPool是目前的常规池化方法的一个不错的替代品
来源:晓飞的算法工程笔记 公众号
论文: Refining activation downsampling with SoftPool

Introduction
池化层是当今卷积神经网络的基础算子,用于降低特征图的大小以及网络的计算量,能够达成平移不变性以及增大后续卷积的感受域。目前的池化方法大多基于最大池化或平均池化,虽然计算很快内存占用少,但其有很大的提升空间,主要在于更好地维持特征图的重要信息。
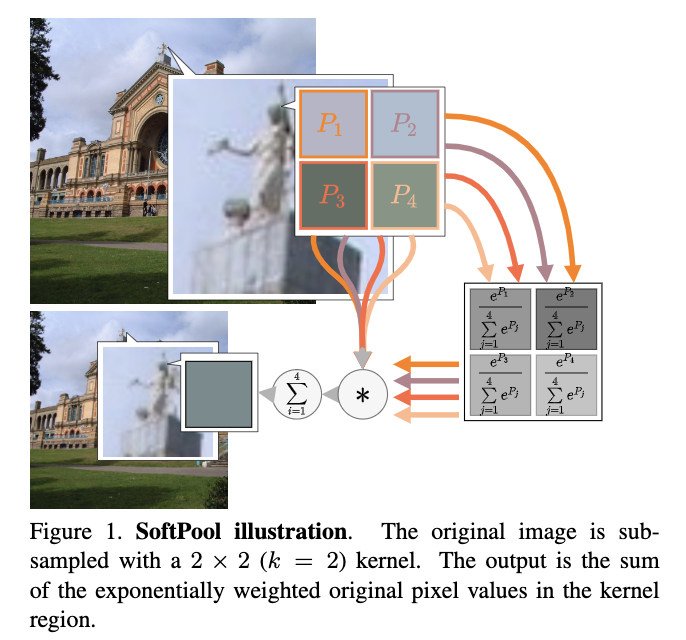
为此,论文提出了SoftPool,基于softmax加强进行特征图的池化操作。从实验结果来看,SoftPool在保持计算和内存高效的情况下,能够很好的保留特征图的重要信息,提升模型的准确率。
SoftPool Downsampling
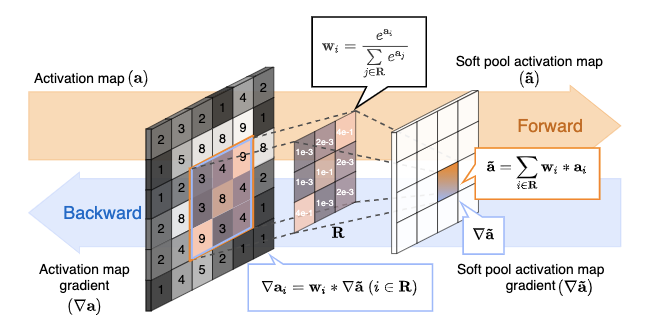
定义大小为\(C\times H\times W\)的特征图\(a\)的局部区域\(R\),\(R\)为2D空间区域,大小等同于池化核大小\(|R|=k^2\),输出为\(\tilde{a}_R\),对应的梯度为\(\Delta \tilde{a}_i\)。
Exponential maximum kernels
SoftPool的核心思想在于softmax的利用,根据特征值非线性地计算区域\(R\)的特征值权重:
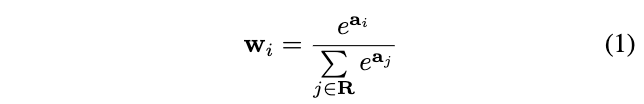
权重\(w_i\)能够保证重要特征的传递,区域\(R\)内的特征值在反向传递时都至少会有预设的最小梯度。在得到权重\(w_i\)后,通过加权区域\(R\)内的特征值得到输出:
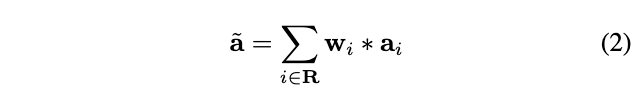
SoftPool能够很好地参照区域内的激活值分布,服从一定的概率分布,而基于最大池化和平均池化的方法的输出则是无分布的。
Gradient calculation
SoftPool是可微的,在反向传播计算时,SoftPool梯度根据前向时的激活值比例进行计算,若梯度过小,将直接赋予预设的非零最小梯度值。
Feature preservation
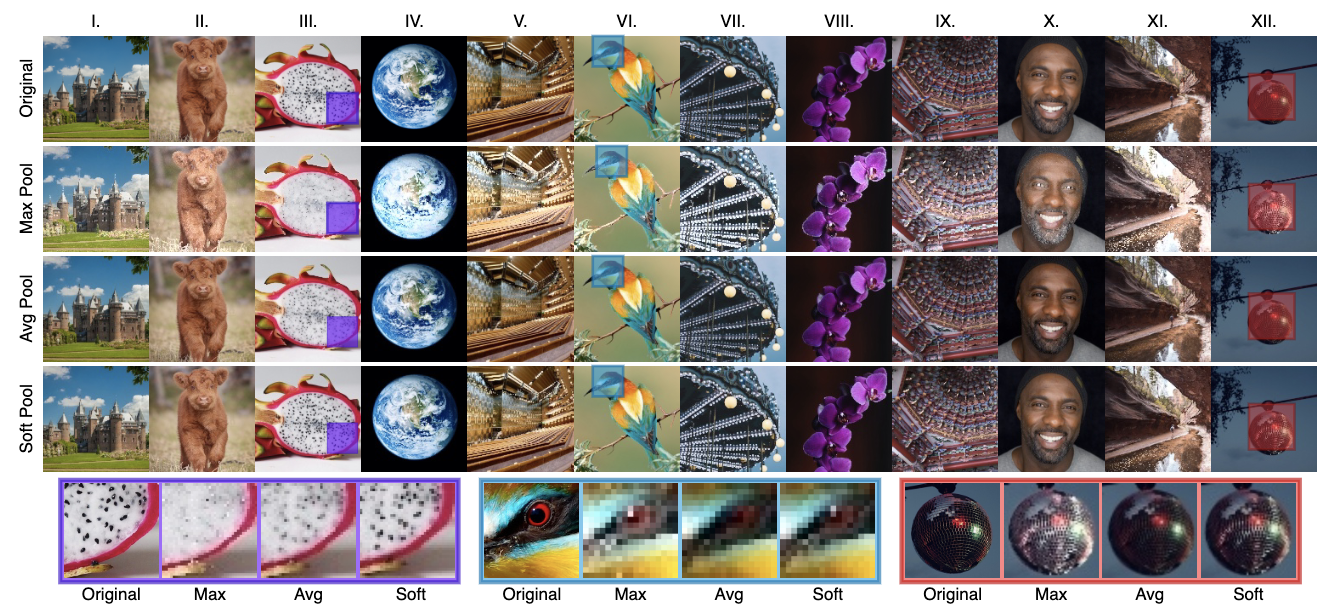
下采样的目的是在保持特征表达的同时降低分辨率,如果损失了特征的表达,势必会降低整体网络的性能。而论文通过可视化发现,相对于其它池化操作,SoftPool能够很好的保留特征表达,算是最大池化和平均池化的折中。
Spatio-temporal kernels
论文提到,CNN网络可以扩展处理3D输入,SoftPool也可以进行对应的适配。假设输入的特征维度为\(C\times H\times W\times T\),\(T\)为时间维度,SoftPool的处理区域则从原来的2D区域加上时间维度。
Experiment
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uvngvuyN-1651209067982)(https://upload-images.jianshu.io/upload_images/20428708-9a069801e6686a6c.png?imageMogr2/auto-orient/strip|imageView2/2/w/1240)]
SSI、Pix Sim和EMD为3种不同的相似度度量方法,这里主要对比特征的丢失以及计算性能。SoftPool虽然加入了softmax加权,但其速度依然很快。在实现时,先对整图计算\(e^x\),然后将得到的图特征图与原图进行element-wise相乘,然后进行平均池化。
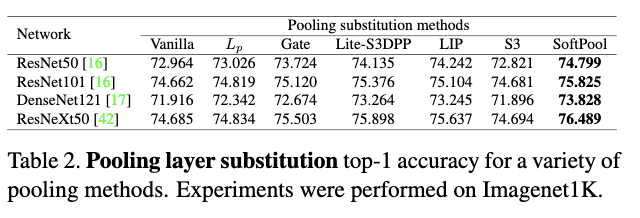
多种池化方法的对比。
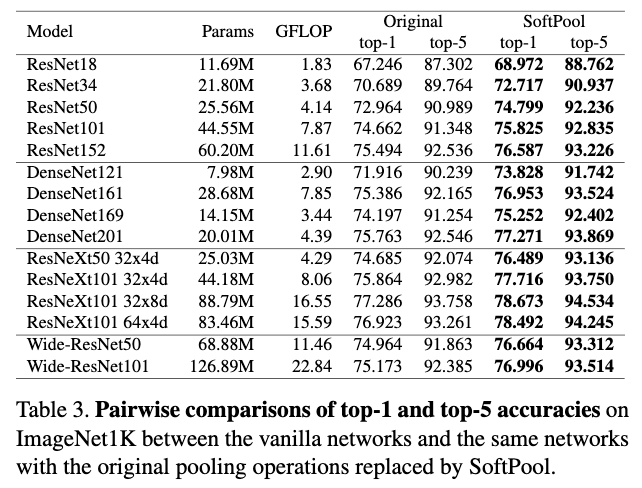
多个主干网络上的分类准确率对比。
Discussion
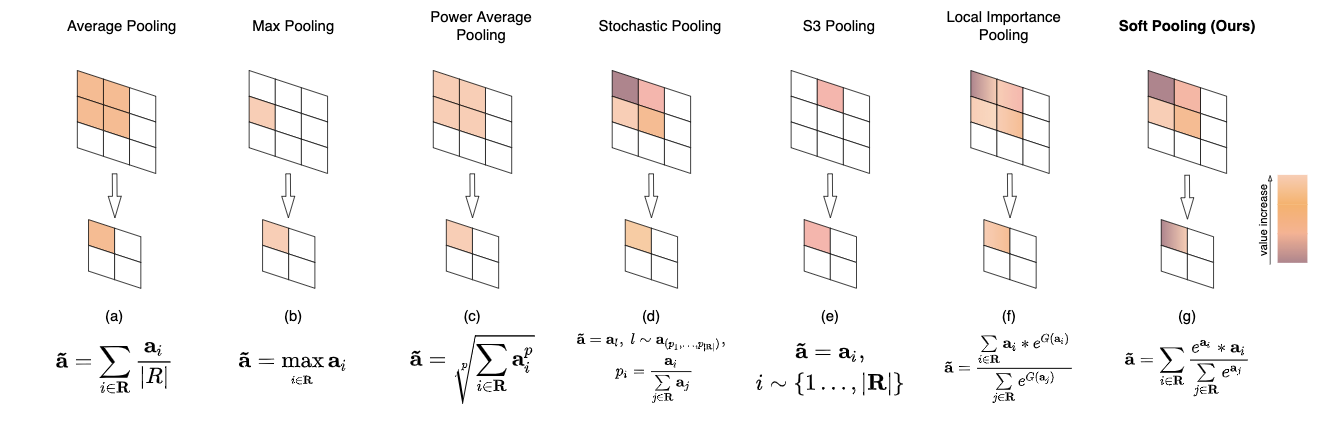
论文列举了许多池化操作的示意图,从图中可以看到,其实SoftPool和早前提出的LIP很像,都是用到了softmax加权,只是LIP额外加了一个小网络对激活值进行线性变换,这么看来,SoftPool可以算是LIP的一个特例。感觉整体论文的内容以及亮点不够多,另外实验部分的baseline的准确率有点低,不知道作者是怎么得来的。
Conclusion
SoftPool使用softmax进行加权池化,能够保持特征的表达性并且是可微操作。从性能和准确率来看,SoftPool是目前的常规池化方法的一个不错的替代品。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号