
RepPoints:微软巧用变形卷积生成点集进行目标检测,创意满满 | ICCV 2019
RepPoints的设计思想十分巧妙,使用富含语义信息的点集来表示目标,并且巧用可变形卷积来进行实现,整体网络设计十分完备,值得学习
来源:晓飞的算法工程笔记 公众号
论文: RepPoints: Point Set Representation for Object Detection

Introduction
经典的bounding box虽然有利于计算,但没有考虑目标的形状和姿态,而且从矩形区域得到的特征可能会受背景内容或其它的目标的严重影响,低质量的特征会进一步影响目标检测的性能。为了解决bounding box存在的问题,论文提出了RepPoints这种新型目标表示方法,能够进行更细粒度的定位能力以及更好的分类效果。
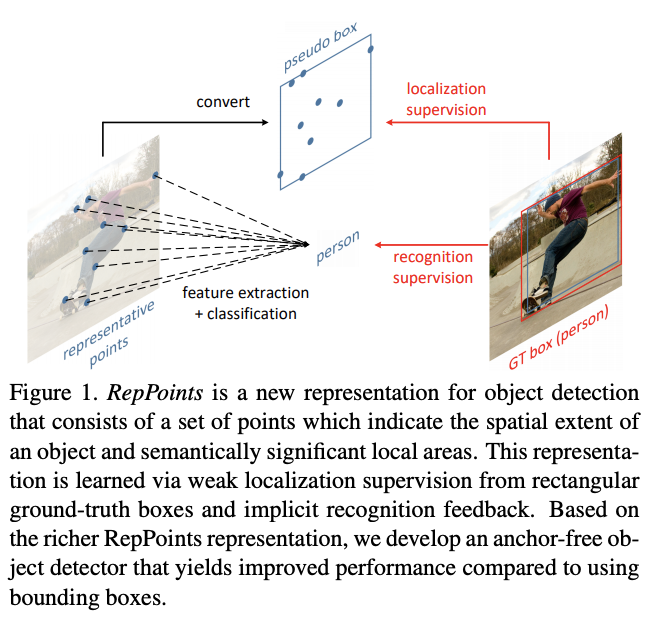
如图1所示,RepPoints是一个点集,能够自适应地包围目标并且包含局部区域的语义特征。RepPoints的训练由目标定位和目标分类共同驱动,能够约束RepPoints紧紧地包围目标以及引导检测器正确地分类目标。这种自适应的表示方法是可微的,能够连续地用在检测器的多个阶段中,并且不需要额外设置的anchor来生成大量的初始框。
The RepPoints Representation
如上面提到的,bounding box只是粗粒度的目标位置表示方法,只考虑了目标的矩形空间,没有考虑形状、姿态以及语义丰富的局部区域,而语义丰富的局部区域能够帮助网络更好的定位以及特征提取。为了解决上述的缺点,RepPoints使用一组自适应的采样点表示目标:
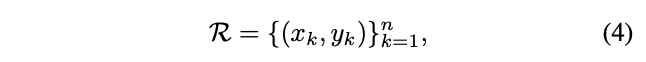
\(n\)为表示目标的采样点总数,论文默认设置为9。
RepPoints refinement
逐步调整bounding box定位和特征提取是multi-stage检测器成功的重要手段,对于RepPoints,调整可简单地表示为:
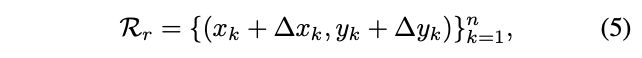
\(\{(\Delta x_k, \Delta y_k)\}^{n}_{k=1}\)为预测的新采样点相对与旧采样点的偏移值,采样点调整的尺寸都是一样的,不会像bouning box那样需要解决中心点坐标和边框长度的尺寸不一致问题。
Converting RepPoints to bounding box
为了利用bounding box的标注信息进行训练以及验证RepPoint-based检测算法的性能,使用预设的转化方法\(\mathcal{T}=\mathcal{R}_P\to \mathcal{B}_P\)将RepPoints转化成伪预测框,共有三种转化方法:
- \(\mathcal{T}=\mathcal{T}_1\): Min-max function,对所有的RepPoints进行min-max操作来获取预测框\(\mathcal{B}_p\)
- \(\mathcal{T}=\mathcal{T}_2\):Partial min-max function,对部分的RepPoints进行min-max操作获取预测框\(\mathcal{B}_p\)
- \(\mathcal{T}=\mathcal{T}_3\):Moment-based function,通过RepPoints的均值和标准差计算中心点位置以及预测框尺寸得到预测框\(\mathcal{B}_p\),尺寸通过全局共享的可学习参数\(\lambda_x\)和\(\lambda_y\)相乘得到
这些函数都是可微的,可加入检测器中进行end-to-end的训练。通过实验验证,这3个转化方法效果都不错。
RPDet: an Anchor Free Detector
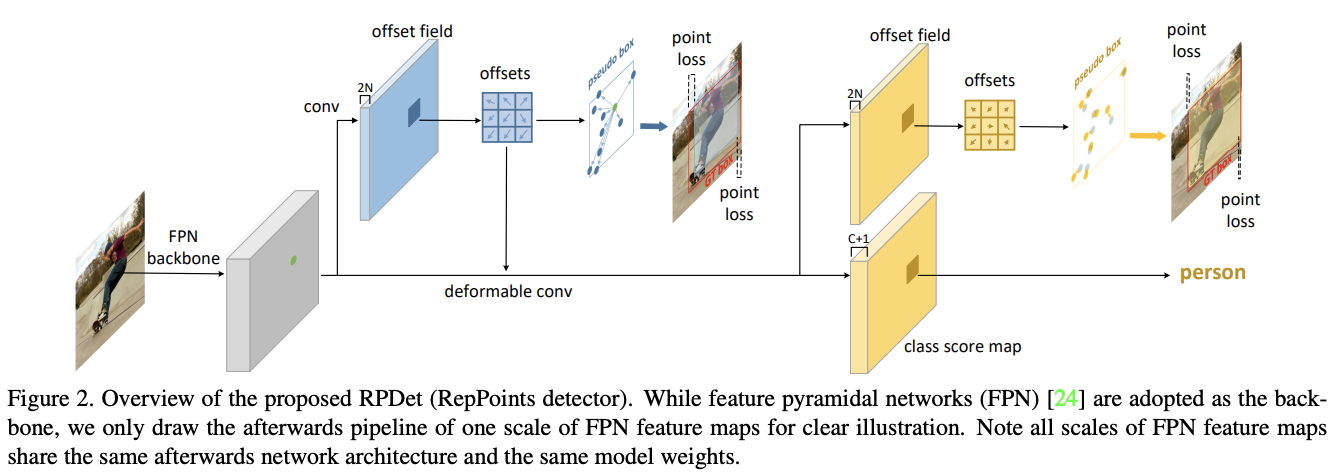
论文基于RepPoints设计了anchor-free目标检测算法RPDet,包含两个识别阶段。因为可变形卷积可采样多个不规则分布的点进行卷积输出,所以可变形卷积十分适合RepPoints场景,能够根据识别结果的反馈进行采样点的引导。
Center point based initial object representation
RPDet将中心点作为初始的目标表示,然后逐步调整出最终的RepPoints,中心点也可认为是特殊的RepPoints。当两个目标存在于特征图同一位置时,这种基于中心点的方法通常会出现识别目标歧义的问题。此前的方法在同一位置设置多个预设的anchor来解决此问题,而RPDet则利用FPN来解决此问题:
- 不同大小的目标由不同level的特征负责识别
- 小物体对应level的特征图一般较大,减少了同一物体存在同一位置的可能性
论文统计发现,当使用上述FPN约束后,COCO数据集中仅1.1.%存在上述的问题。
Utilization of RepPoints
如图2所示,RepPoints是RPDet的基础目标表示方法,从中心点开始,第一组RepPoints通过回归中心点的偏移值获得。第二组RepPoints代表最终的目标位置,由第一组RepPoints优化调整得到。RepPoints的学习主要由两个目标驱动:
- 伪预测框和GT框的左上角点和右上角点的距离损失
- 后续的目标分类损失
第一组RepPoints由距离损失和分类损失引导,第二组RepPoints仅使用距离损失进行引导,主要为了学习到更精准的目标定位。
Backbone and head architectures
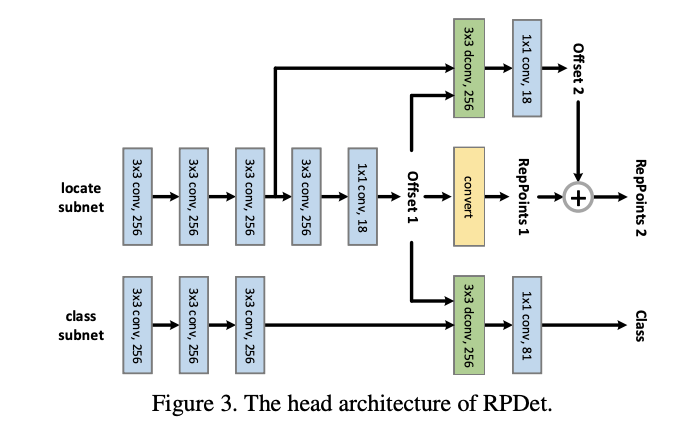
FPN主干网络包含5层特征金字塔level,从stage3(下采样8倍)到stage7(下采样128倍)。Head的结构如图3,Head在不同的level中是共享的,包含两个独立的子网,分别负责定位(RepPoints的生成)和分类:
- 定位子网首先使用3个256-d \(3\times 3\)卷积提取特征,每个卷积都接group normalization层,然后连续接两个小网络计算两组RepPoints的偏移值。
- 分类子网首先使用3个256-d \(3\times 3\)卷积提取特征,每个卷积都接group normalization层,然后将定位子网输出的第一组RepPoints的偏移值输入到256-d \(3\times 3\)可变形卷积中进一步提取特征,最后输出分类结果。
尽管RPDet采用了两阶段定位,但其性能甚至比单阶段的RetinaNet要高,主要是anchor-free的设计使得分类层的计算减少了,覆盖了额外的定位阶段带来的少量消耗。
Localization/class target assignment
定位包含两个阶段,第一阶段从中心点得到第一组RepPoints,第二阶段则从第一组RepPoints调整得到第二组RepPoints,不同的阶段的正样本定义不同:
- 对于第一阶段,特征点被认为是正样本需满足:1) 该特征点所在的特征金字塔level等于\(s(B)=\lfloor log_2 (\sqrt{W_Bh_B}/4)\rfloor\)。2) 目标的中心点在特征图上映射位置对应该特征点。
- 对于第二阶段,只有特征点对应的第一阶段产生的伪预测框与目标的IoU大于0.5才被认为是正样本。与当前的anchor-based方法有点类似,将第一阶段的输出当作anchor。
由于目标的分类只考虑第一组RepPoints,所以,特征点对应的第一组RepPoints产生的伪预测框于目标的IoU大于0.5即认为是正样本,小于0.4则认为是背景类,其它则忽略。
Experiments
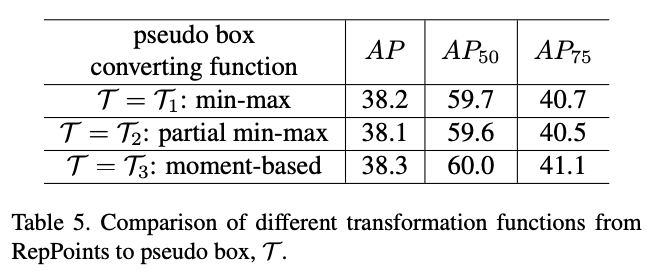
对比不同的伪预测框生成方法的性能。

与其它SOTA检测方法对比性能。
Conclusion
RepPoints的设计思想十分巧妙,使用富含语义信息的点集来表示目标,并且巧用可变形卷积来进行实现,整体网络设计十分完备,值得学习。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】


 浙公网安备 33010602011771号
浙公网安备 33010602011771号